
Atualizações de Produto | Novo Recurso de Perfil
Advanced Data Extraction Specialist
Para aprimorar a praticidade e estabilidade do Scraping Browser em cenários de sessões cruzadas, lançamos oficialmente o recurso de Perfil para dados de usuário persistentes. Este recurso armazena dados do navegador (como cookies, armazenamento, cache e estados de login) na nuvem, permitindo o compartilhamento e reutilização contínuos entre diferentes sessões — eliminando a necessidade de fazer login repetidamente. Ele simplifica significativamente a depuração e melhora a eficiência dos scripts de automação.
Por que Introduzir Perfis?
Em processos de captura ou interação automatizados reais, os usuários frequentemente precisam “lembrar o status de login”, “reutilizar cookies de uma captura específica” e “sincronizar caches de página entre tarefas”. Navegadores headless tradicionais iniciam em um ambiente completamente novo toda vez e não podem reter nenhum contexto histórico. O novo recurso de Perfil resolve esse problema, permitindo que o Scraping Browser suporte:
- Retenção a longo prazo do status de login, eliminando a necessidade de reautenticação a cada vez
- Identidade de usuário consistente em múltiplas requisições ao mesmo site
- Reutilização do contexto do navegador entre sessões durante a depuração de scripts
Destaques desta Atualização
Página de Criação e Gerenciamento de Perfis Agora Está Ativa
Você agora pode ir a “Para Scraping → Perfis” para:
- Criar/Editar/Copiar/Excluir
- Ver o tamanho dos dados do arquivo, hora da última utilização
- Pesquisar Perfil alvo por nome ou ID
- Copiar IDs com um clique para referência de scripts ou equipe.
Página de Detalhes do Perfil: Visibilidade Completa da Configuração e Histórico de Uso
Acesse qualquer Perfil para visualizar sua configuração completa e registros de uso, incluindo:
- Informações Básicas: Nome do Perfil, ID, tamanho dos dados, hora da última utilização e contagem total de uso (ou seja, quantas vezes foi utilizado em Sessões);
- Registros de Sessão Associados:
-
Lista de Sessões Ativas: Sessões em tempo real que estão atualmente usando este Perfil;
-
Lista de Histórico de Sessões: Todas as sessões históricas nas quais este Perfil foi utilizado, com entradas clicáveis para visualização detalhada.
-
Isso torna o processo de depuração mais transparente e ajuda a reproduzir e rastrear problemas de forma mais eficiente.
Integração Profunda com o Sistema de Sessão
Adicionamos também exibição de informações de Perfil e navegação rápida nas seguintes interfaces:
- Sessões Ativas: Mostra o Perfil em uso (clicável para saltar para a página de detalhes do Perfil)
- Histórico de Sessão: Exibe o Perfil associado a cada sessão
- Detalhe da Sessão: Permite que você veja qual Perfil foi usado durante a execução específica
Demonstração Funcional
Caso 1: Login Persistente + Velocidade de Carregamento Aprimorada
Objetivo: Abrir automaticamente páginas que requerem login sem digitar seu nome de usuário e senha toda vez.
Passos:
1. Configure e salve o estado de login pela primeira vez.
Formas de Criar um Perfil:
- Criação Manual via Painel: Crie Perfis manualmente através do Painel.
- Criação via API: Crie Perfis automaticamente usando a API de Criar Perfil.
- Criação via SDK: Crie Perfis usando o método SDK.
NodeJS
import { Scrapeless } from "@scrapeless-ai/sdk"
const scrapeless = new Scrapeless({
apiKey: "SUA_API_KEY"
})
// cria um novo perfil
const profile = await scrapeless.profiles.create("scrapeless_profile")
console.log("id do perfil:", profile.profileId)Inicie uma sessão, especifique o profile_id e habilite a persistência, e faça login manualmente uma vez. O estado de login (como cookies e tokens) será automaticamente salvo no Perfil da nuvem.
NodeJS
import puppeteer from "puppeteer-core"
import { Scrapeless } from "@scrapeless-ai/sdk"
const scrapeless = new Scrapeless({
apiKey: "SUA_API_KEY"
});
async function main() {
const proxy= "SEU_PROXY"
const profileId = "SEU_PROFILE_ID" // substitua pelo seu profileId
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "QUALQUER",
proxy_url: proxy,
session_ttl: "900",
session_name: "Perfil de Teste",
profile_id: profileId,
profile_persist: true,
});
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://the-internet.herokuapp.com/login", {
timeout: 30000,
waitUntil: "domcontentloaded",
})
const username = "seu nome de usuário"
const password = "sua senha!"
await page.type('[name="username"]', username)
await page.type('[name="password"]', password)
await Promise.all([
page.click('button[type="submit"]'),
page.waitForNavigation({ timeout: 15000 }).catch(() => { }),
])
const successMessage = await page.$(".flash.success")
if (successMessage) {
console.log("✅ Login bem-sucedido!")
} else {
console.log("❌ Login falhou.")
}
await browser.close()
}
main().catch(console.error)2. Reutilização Automática das Informações de Login
- Reutilize o mesmo profileId em scripts ou tarefas subsequentes
- Inicie uma nova sessão referenciando o profileId criado anteriormente, faça login automaticamente em https://the-internet.herokuapp.com/ e abra a página inicial pessoal
Caso 2: Bypass Automático de Anti-Bot para Melhorar a Taxa de Sucesso do Script de Automação
Objetivo: Em processos de login que envolvem medidas anti-bot e CAPTCHAs, contorne os CAPTCHAs através da persistência do perfil para reduzir interrupções.
Site de Teste: https://www.leetchi.com/fr/login
Etapas:
1. Passar pelos CAPTCHAs e salvar o estado
- Crie um novo perfil com persistência do navegador habilitada
- Faça login manualmente e complete os CAPTCHAs humanos (por exemplo, clicando em um CAPTCHA, selecionando imagens, etc.)
- Todos os resultados dos CAPTCHAs e estados de login serão salvos neste perfil
2. Reutilizar Resultados de Verificação para Login Automático
- Inicie uma nova sessão no script usando o mesmo profile_id
- A sessão irá contornar os CAPTCHAs e fazer login automaticamente sem qualquer ação do usuário
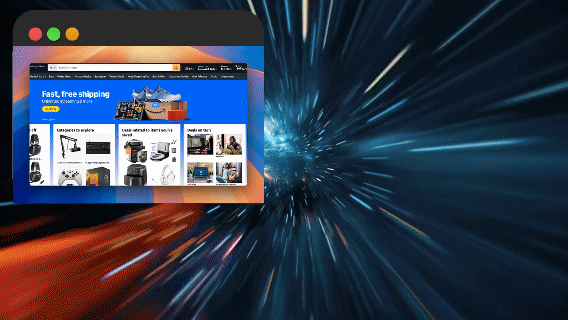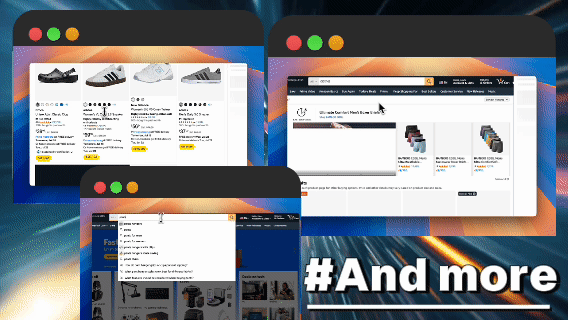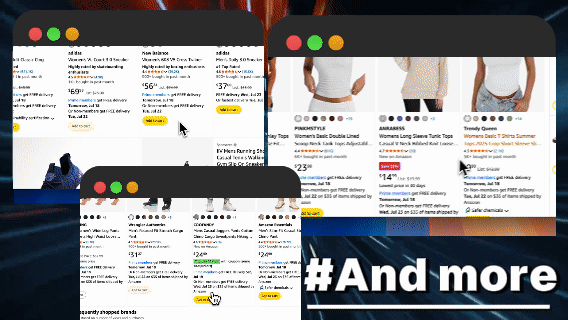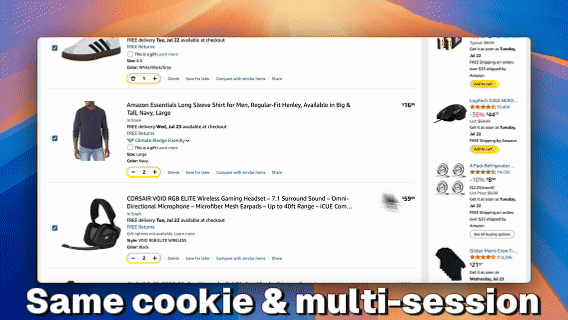
Caso 3: Compartilhamento de Cookies em Múltiplas Sessões
Objetivo: Múltiplas sessões compartilham uma única identidade de usuário para realizar operações simultâneas, como adicionar itens ao carrinho de compras.
Caso de Uso: Gerenciar múltiplos navegadores para acessar simultaneamente plataformas como Amazon e realizar diferentes tarefas sob a mesma conta.
Etapas:
1. Configuração de Identidade Unificada
- Crie um Perfil compartilhado no console
- Faça login na Amazon inserindo seu nome de usuário e senha, e salve os dados da sessão após o login bem-sucedido
NodeJS
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function loginToAmazonWithSessionProfile() {
const token = "SUA_CHAVE_API"; // Chave API
const proxy = "SEU_PROXY"
const amazonAccountEmail = "SEU_EMAIL"
const amazonAccountPassword = "SUA_SENHA"
const profileName = "amazon";
const scrapeless = new Scrapeless({ apiKey: token });
let profile;
let profileId = "";
// tentar obter perfil existente ou criar um novo
const profiles = await scrapeless.profiles.list({
name: profileName,
page: 1,
pageSize: 1,
});
if (profiles?.docs && profiles.docs.length > 0) {
profile = profiles.docs[0];
} else {
profile = await scrapeless.profiles.create(profileName);
}
profileId = profile?.profileId;
if (!profileId) {
return;
}
console.log(profile)
// Construir URL de conexão para o navegador Scrapeless
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "QUALQUER",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: "Login na amazon",
profile_id: profileId, // profileId específico
profile_persist: true, // persistir dados do navegador no perfil
})
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await browser.newPage();
await page.goto("https://amazon.com", { waitUntil: "networkidle2" });
// Clique em "Continuar comprando" se presente
try {
await page.waitForSelector("button.a-button-text", { timeout: 5000 });
await page.evaluate(() => {
const buttons = Array.from(document.querySelectorAll("button.a-button-text"));
const btn = buttons.find(b => b.textContent.trim() === "Continuar comprando");
if (btn) btn.click();
});
console.log("clicou no botão 'Continuar comprando'.");
} catch (e) {
console.log("botão 'continuar comprando' não encontrado, continuar...");
}
// Clique no botão "Entrar"
await page.waitForSelector("#nav-link-accountList", { timeout: 5000 });
await page.click("#nav-link-accountList");
console.log("clicou no botão 'Entrar'.");
// Insira o email
await page.waitForSelector("#ap_email_login", { timeout: 5000 });
await page.type("#ap_email_login", amazonAccountEmail, { delay: Math.floor(Math.random() * 91) + 10 });
console.log("insere o email.");
// Clique em "Continuar"
await page.waitForSelector("#continue-announce", { timeout: 5000 });
await page.click("#continue-announce");
console.log("clicou no botão 'Continuar'.");
// Insira a senha com atraso aleatório por caractere
await page.waitForSelector("#ap_password", { timeout: 5000 });
for (const char of amazonAccountPassword) {
await page.type("#ap_password", char, { delay: Math.floor(Math.random() * 91) + 10 });
}
console.log("insere a senha.");
// Clique no botão de envio "Entrar"
await page.waitForSelector("#signInSubmit", { timeout: 5000 });
await page.click("#signInSubmit");
console.log("clicou no botão de envio 'Entrar'.");
Opcionalmente: await page.waitForNavigation();
await browser.close();
}
(async () => {
await loginToAmazonWithSessionProfile();
})();2. Chamadas concorrentes com Identidade Consistente
-
Inicie várias sessões (por exemplo, 3), todas referenciando o mesmo
profile_id -
Todas as sessões operam sob a mesma identidade de usuário
-
Realize diferentes ações na página separadamente, como adicionar os produtos A, B e C ao carrinho de compras
-
Sessão 1 pesquisa por
sapatose os adiciona ao carrinho
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "SUA_CHAVE_API"
const proxy = "SEU_PROXY"
const profileId = "SEU_PROFILE_ID"
const search = "sapatos"
const scrapeless = new Scrapeless({
apiKey: token
})
// criar sessão do navegador
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "QUALQUER",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `produtos ${search}`,
profile_id: profileId,
profile_persist: false, // desabilitar persistência da sessão
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
```javascript
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Buscar produtos
console.log(`buscar produtos: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Clicar em produtos
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicou em produtos`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Clicar em adicionar ao carrinho
await buttons[0].click();
console.log(`clicou em adicionar ao carrinho`);
}
await client.close();
} catch (e) {
console.log("Falha ao adicionar ao carrinho de compras.", e);
}
}
(async () => {
await addGoodsToCart()
})()- A sessão 2 busca por
roupase as adiciona ao carrinho
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "SUA_CHAVE_API"
const proxy = "SEU_PROXY"
const profileId = "SEU_ID_DE_PERFIL"
const search = "roupas"
const scrapeless = new Scrapeless({
apiKey: token
})
// criar sessão do navegador
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "QUALQUER",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `produtos ${search}`,
profile_id: profileId,
profile_persist: false, // desabilitar persistência da sessão
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Buscar produtos
console.log(`buscar produtos: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Clicar em produtos
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicou em produtos`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Clicar em adicionar ao carrinho
await buttons[0].click();
console.log(`clicou em adicionar ao carrinho`);
}
await client.close();
} catch (e) {
console.log("Falha ao adicionar ao carrinho de compras.", e);
}
}
(async () => {
await addGoodsToCart()
})()- A sessão 3 busca por
calçase as adiciona ao carrinho
import { Scrapeless } from "@scrapeless-ai/sdk"
import puppeteer from "puppeteer-core"
async function addGoodsToCart() {
const token = "SUA_CHAVE_API"
const proxy = "SEU_PROXY"
const profileId = "SEU_ID_DE_PERFIL"
const search = "calças"
const scrapeless = new Scrapeless({
apiKey: token
})
// criar sessão do navegador
const { browserWSEndpoint } = scrapeless.browser.create({
proxy_country: "QUALQUER",
proxy_url: proxy,
session_recording: true,
session_ttl: 900,
session_name: `produtos ${search}`,
profile_id: profileId,
profile_persist: false, // desabilitar persistência da sessão
})
const client = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint
})
const page = await client.newPage()
try {
await page.goto("https://www.amazon.com", { waitUntil: "networkidle2" })
await page.waitForSelector('input[id="twotabsearchtextbox"]', { timeout: 5000 })
// Buscar produtos
console.log(`buscar produtos: ${search}`);
await page.type('input[id="twotabsearchtextbox"]', search, { delay: Math.floor(Math.random() * 91) + 10 });
await page.keyboard.press('Enter');
await page.waitForSelector('button[id="a-autoid-3-announce"]', { timeout: 10000 })
// Clicar em produtos
await page.click('button[id="a-autoid-3-announce"]')
console.log(`clicou em produtos`);
await page.waitForSelector('div[id="a-popover-content-2"]', { timeout: 10000 })
await new Promise((resolve) => setTimeout(resolve, 5000))
const buttons = await page.$$('div#a-popover-content-2 button.a-button-text');
if (buttons.length > 0) {
// Clicar em adicionar ao carrinho
await buttons[0].click();
pt
aguarde buttons[0].click();
console.log(`clicou em adicionar ao carrinho`);
}
aguarde client.close();
} catch (e) {
console.log("Adicionar ao carrinho falhou.", e);
}
}
(async () => {
await addGoodsToCart()
})()
Para Quais Cenários Esses Recursos São Adequados?
O lançamento de Perfis melhora significativamente o desempenho do Scraping Browser em ambientes multiusuário, multsessão e de fluxo de trabalho complexos. Abaixo estão casos de uso práticos típicos:
Projetos de Coleta de Dados Automatizada / Crawling
Ao raspar frequentemente websites que exigem login (como plataformas de e-commerce, recrutamento ou redes sociais):
- Persistir estados de login para evitar desencadeamentos frequentes de controle de risco;
- Manter contextos chave como cookies, armazenamento e tokens;
- Atribuir diferentes identidades (Perfis) para diferentes tarefas para gerenciar pools de contas ou pools de identidades.
Colaboração em Equipe / Gestão de Configuração em Múltiplos Ambientes
Dentro de equipes de desenvolvimento, testes e operações:
- Cada membro mantém sua própria configuração de Perfil sem interferências;
- IDs de Perfil podem ser incorporados diretamente em scripts de automação para garantir chamadas consistentes;
- Suporta nomenclatura personalizada e limpeza em massa para manter ambientes limpos e organizados.
QA / Suporte ao Cliente / Reproduzindo Problemas Online
- QA pode pré-definir Perfis associados a casos de teste chave, evitando a reconstrução de estado durante a reprodução;
- Cenários de suporte ao cliente podem restaurar ambientes operacionais de clientes via Perfis para reprodução precisa de problemas;
- Todas as sessões podem estar ligadas a registros de uso de Perfil, facilitando a solução de problemas relacionados ao contexto.
👉 Abra o Playground e experimente agora.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


