
Como Raspar Dados de Perfil do Instagram Rapidamente?
Specialist in Anti-Bot Strategies
O Instagram é uma das plataformas de mídia social mais populares, com milhões de usuários em todo o mundo. A extração de dados de perfis do Instagram é benéfica para empresas, desenvolvedores, especialistas em análise de dados para análise de marketing, pesquisa da concorrência ou gerenciamento de dados pessoais.
Neste artigo, mostraremos o processo de extração de dados de perfis do Instagram a fundo. Explicaremos como criar um rastreador de Instagram para extrair dados de perfis e páginas de postagens do Instagram.
É hora de aprender como extrair dados do Instagram rapidamente usando a conveniente API de Raspagem.
- #Método 1. Crie seu rastreador de perfil do Instagram em Python
- #Método 2. Usando a API de Raspagem, colete dados facilmente
Por que extrair dados de perfis do Instagram?
Os dados públicos do Instagram são enormes e podem fornecer todos os tipos de insights. A extração de dados de perfil pode fornecer informações valiosas sobre usuários populares em todo o mundo, ajudando você a prever tendências, rastrear o conhecimento da marca, entender como melhorar seu desempenho no Instagram ou ajudar empresas a prospectar e alcançar novos clientes conectando-se a perfis populares do Instagram com interesses semelhantes.
Além disso, os dados do Instagram extraídos são um recurso viável para estudos de análise de sentimento. Esses dados podem ser encontrados em postagens e comentários e podem ser usados para coletar a opinião pública sobre tendências e notícias específicas.
Método 1. Rastreador de perfil do Instagram em Python
Vamos começar raspando perfis de usuários do Instagram! A seguir, explicaremos detalhadamente como extrair as informações de perfil da usuária do Instagram ladygaga. Podemos fazer isso seguindo os passos abaixo:
Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como demonstração do processo de rastreamento. Não salvamos nenhuma informação e dados.
Passo 1. Analise a página de destino
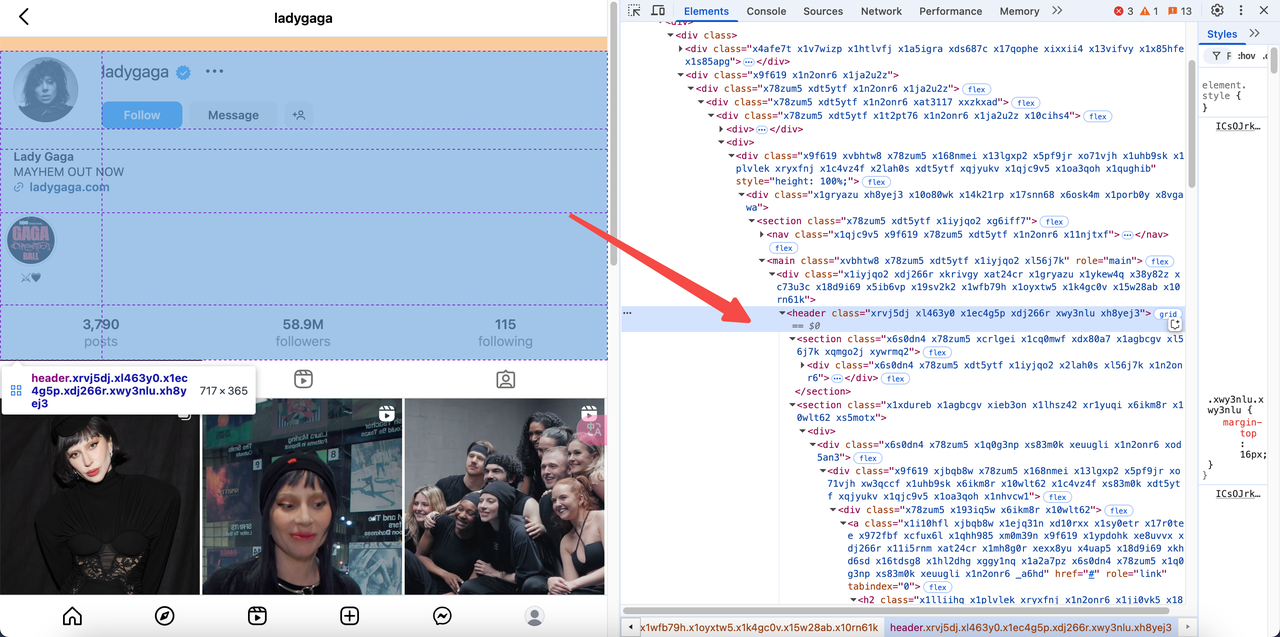
- Visite o URL de destino: https://www.instagram.com/ladygaga/.
- Inspecione o código-fonte da página para localizar os dados JSON incorporados:
- O Instagram incorpora informações do usuário em uma tag
scriptcom o formatowindow._sharedData. - Podemos extrair esses dados analisando o HTML.
Passo 2. Instale as bibliotecas necessárias
Certifique-se de que as seguintes bibliotecas Python estejam instaladas:
pip install requests beautifulsoup4
Passo 3. Defina os cabeçalhos da solicitação
Para simular o acesso do navegador, defina os cabeçalhos User-Agent e Referer para evitar ser bloqueado por mecanismos anti-raspagem.
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}Passo 4. Analise os dados JSON
Precisamos extrair o conteúdo window._sharedData da tag script no HTML e convertê-lo em um dicionário Python.
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Analise os dados JSON
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return NonePasso 5. Extraia os campos necessários
Recupere o nome de usuário, biografia, contagem de seguidores, contagem de postagens e outras informações relevantes dos dados JSON analisados.
Código completo
Abaixo está o código Python completo, que você pode usar diretamente para extrair as informações do perfil da Lady Gaga:
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: Unable to fetch data for {username}. Status code: {response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Analise os dados JSON
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# Exemplo de uso
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Dados do perfil do Instagram:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))Resultados da Raspagem
Após executar o código, a saída profile_data incluirá os seguintes campos:
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}Método 2. API de Raspagem Scrapeless (Recomendado)
Raspar o Instagram é bastante fácil. No entanto, o Instagram é extremamente restritivo em relação ao acesso aos seus dados públicos. Ele permite apenas algumas solicitações por dia para usuários não logados, após o qual ele redireciona as solicitações para a página de login.
Como evitar o bloqueio de rastreadores do Instagram? O Scrapeless é sua ferramenta de rastreamento ideal!
O Scrapeless fornece APIs de rastreamento na web, desbloqueio na web e extração de dados para coleta de dados em larga escala.
- Contorno de proteção anti-bot: Evite ser bloqueado ao rastrear a web!
- Proxies residenciais rotativos: Evite proibições de IP e bloqueio geográfico.
- Renderização JavaScript: Raspe páginas da web dinâmicas por meio de navegadores em nuvem.
- SDKs Python e TypeScript, além de integrações Scrapy.
Esta API de Raspagem do Instagram é gratuita?
Sim. O Scrapeless fornece a você um crédito gratuito de US$ 2. Você pode se inscrever diretamente para reivindicar o crédito gratuito. Com o rastreador de perfil do Instagram, você pode coletar facilmente informações de usuários gratuitamente!
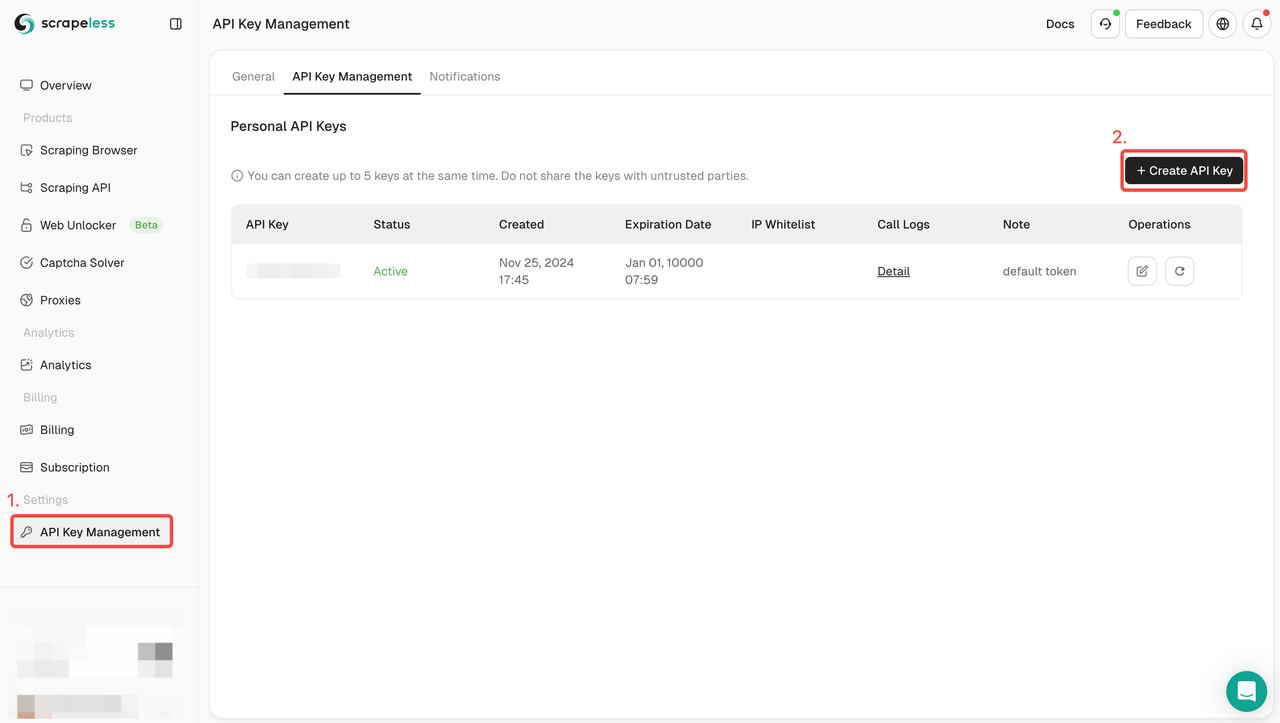
Passo 1. Crie sua chave de API
Para começar, você precisará obter sua chave de API no painel do Scrapeless:
- Faça login no Painel do Scrapeless.
- Navegue até Gerenciamento de chaves de API.
- Clique em Criar para gerar sua chave de API exclusiva.
- Depois de criada, basta clicar na chave de API para copiá-la.
Considerações finais
Neste tutorial, apresentamos 2 maneiras eficientes de obter dados de perfil do Instagram. Mostramos como lidar com a autenticação, fazer solicitações, lidar com respostas e integrar IPs de proxy para melhor estabilidade e segurança.
Seguindo este guia, você pode começar facilmente a extrair dados de perfil do Instagram para uso pessoal ou comercial, mantendo a privacidade e evitando problemas como limites de taxa.
Para melhorar a eficiência da coleta de dados, recomendamos que você use a API de rastreamento avançada, que requer apenas parâmetros de configuração simples para concluir a extração de dados!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


