
Como raspar vendedores online de produtos do Google com Python
Advanced Data Extraction Specialist
Introdução
Na competitiva paisagem do comércio eletrônico atual, monitorar listagens de produtos e analisar o desempenho de vendedores online em plataformas como o Google pode fornecer insights valiosos. A extração de dados de listagens de produtos do Google permite que as empresas reúnam dados em tempo real para comparar preços, rastrear tendências e analisar concorrentes. Neste artigo, mostraremos como extrair dados de vendedores online de produtos do Google com Python, usando uma variedade de métodos. Também explicaremos por que o Scrapeless é a melhor escolha para empresas que buscam soluções confiáveis, escaláveis e legais.
Compreendendo os Desafios da Extração de Dados de Vendedores Online de Produtos do Google
Ao tentar extrair dados de vendedores online de produtos do Google, vários desafios importantes podem surgir:
- Medidas anti-raspagem: Os sites implementam CAPTCHAs e bloqueio de IP para evitar a raspagem automatizada, tornando a extração de dados difícil.
- Conteúdo dinâmico: As páginas de produtos do Google geralmente carregam dados usando JavaScript, que podem ser perdidos por métodos de raspagem tradicionais como Requests & BeautifulSoup ou Selenium.
- Limitação de taxa: Solicitações excessivas em um curto período podem levar ao acesso limitado, causando atrasos e interrupções no processo de raspagem.
Aviso de Privacidade: Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como demonstração do processo de raspagem. Não salvamos nenhuma informação e dados.
Método 1: Extração de Dados de Vendedores Online de Produtos do Google com a API Scrapeless (Solução Recomendada)
Por que o Scrapeless é uma Ótima Ferramenta:
- Extração de Dados Eficiente: O Scrapeless pode contornar CAPTCHAs e medidas anti-bot, permitindo a raspagem de dados suave e ininterrupta.
- Preço Acessível: Com apenas US$ 0,1 por 1.000 consultas, o Scrapeless oferece uma das soluções mais acessíveis para raspagem do Google.
- Raspagem Multi-Fonte: Além de extrair dados de vendedores online de produtos do Google, o Scrapeless permite que você colete dados do Google Maps, Google Hotéis, Google Voos, Google Notícias e muito mais.
- Velocidade e Escalabilidade: Lidar com tarefas de raspagem em larga escala rapidamente, sem lentidão, tornando-o ideal para projetos de pequeno e grande porte.
- Dados Estruturados: A ferramenta fornece dados estruturados e limpos, prontos para uso em suas análises, relatórios ou integração em seus sistemas.
- Facilidade de Uso: Sem configuração complexa — simplesmente integre sua chave de API e comece a extrair dados em minutos.
Como Usar a API Scrapeless:
- Cadastre-se: Cadastre-se no Scrapeless e obtenha sua chave de API. Ao mesmo tempo, você também pode obter uma avaliação gratuita no topo do Dashboard.
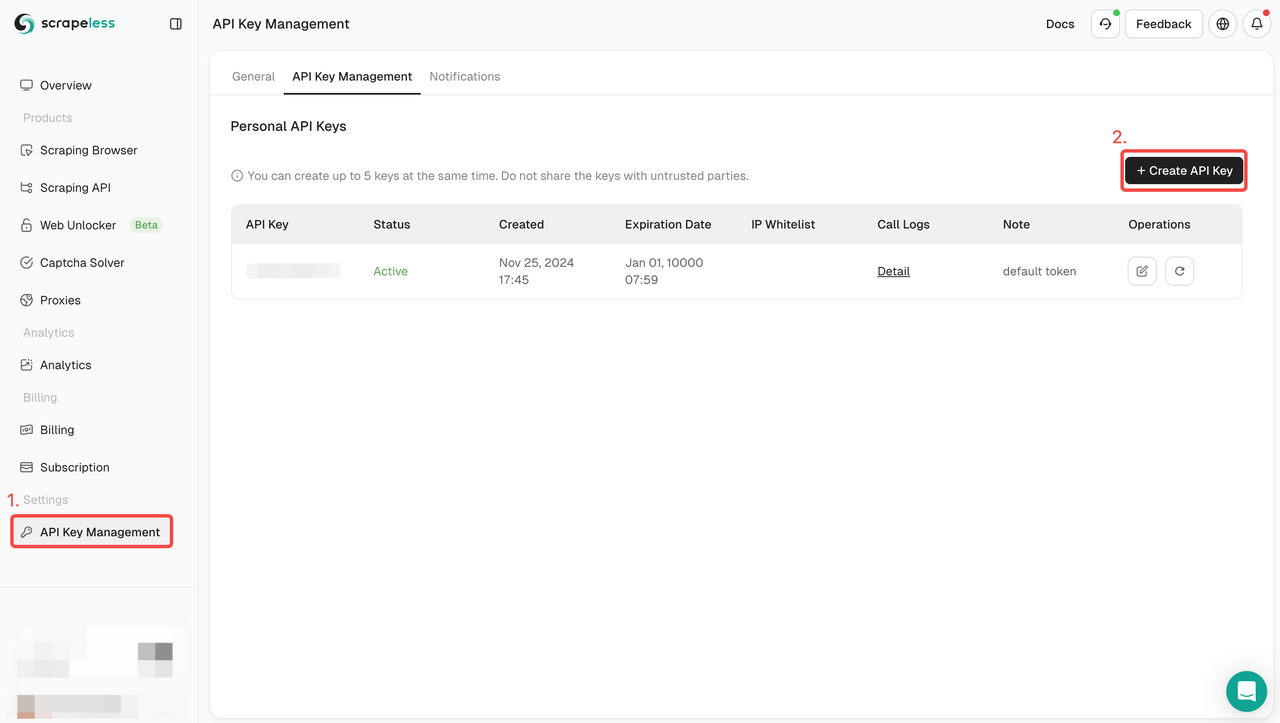
- Integrar API: Inclua a chave de API em seu código para iniciar solicitações ao serviço.
- Comece a Extração de Dados: Agora você pode enviar solicitações GET com URLs de produtos ou consultas de pesquisa, e o Scrapeless retornará dados estruturados, incluindo nomes de produtos, preços, avaliações e muito mais.
- Use os Dados: Aproveite os dados recuperados para análise de concorrentes, rastreamento de tendências ou qualquer outro projeto que exija insights de dados do Google.
Exemplo de Código Completo:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Erro:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Experimente o Scrapeless gratuitamente e veja como nossa API pode simplificar seu processo de extração de dados de vendedores online de produtos do Google. Comece sua avaliação gratuita aqui.
Junte-se à nossa comunidade Discord para obter suporte, compartilhar insights e manter-se atualizado sobre os recursos mais recentes. Clique aqui para participar!
Método 2: Extração de Dados de Listagens de Produtos do Google com Requests & BeautifulSoup
Nesta abordagem, mergulharemos profundamente em como extrair dados de listagens de produtos do Google usando duas poderosas bibliotecas Python: Requests e BeautifulSoup. Essas bibliotecas permitem que façamos solicitações HTTP para páginas de produtos do Google e analisemos a estrutura HTML para extrair informações valiosas.
Etapa 1. Configurando o ambiente
Primeiro, certifique-se de ter o Python instalado em seu sistema. E crie um novo diretório para armazenar o código deste projeto. Em seguida, você precisa instalar beautifulsoup4 e requests. Você pode fazer isso através do PIP:
language
$ pip install requests beautifulsoup4Etapa 2. Use requests para fazer uma solicitação simples
Agora, precisamos extrair os dados dos produtos do Google. Vamos usar o produto com o product_id 4172129135583325756 como exemplo e extrair alguns dados do OnlineSeller.
Primeiro, vamos simplesmente usar requests para enviar uma solicitação GET:
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)Como esperado, a solicitação retorna uma página HTML completa. Agora precisamos extrair alguns dados da página a seguir:
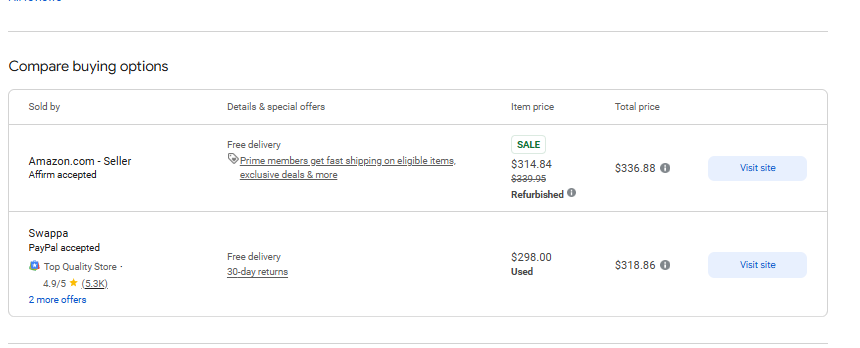
Etapa 3. Obter dados específicos
Como mostrado na figura, os dados que precisamos estão em tr[jscontroller='d5bMlb']:
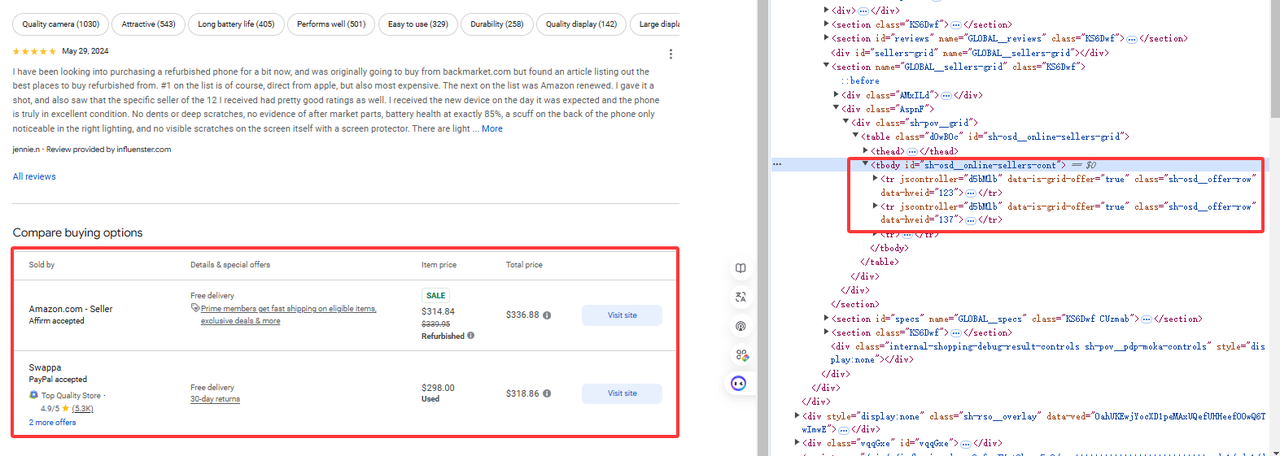
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})Então use BeautifulSoup para analisar a página HTML e obter os elementos relevantes:
Código completo
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)Os resultados da impressão do console são os seguintes:

Limitação
Claro, podemos obter os dados de volta usando o exemplo acima de obter dados parciais, mas existe o risco de bloqueio de IP. Não podemos fazer grandes solicitações, o que acionará o controle de risco do produto do Google.
Método 3: Extração de Dados de Vendedores Online de Produtos do Google com Selenium
Neste método, exploraremos como usar o Selenium, uma poderosa ferramenta de automação da web, para extrair dados de listagens de produtos do Google de vendedores online. Ao contrário do Requests e BeautifulSoup, o Selenium permite que interajamos com páginas dinâmicas que exigem a execução de JavaScript, o que o torna perfeito para extrair dados de listagens de produtos do Google que carregam conteúdo dinamicamente.
Etapa 1: Configurar o ambiente
Primeiro, certifique-se de ter o Python instalado em seu sistema. E crie um novo diretório para armazenar o código deste projeto. Em seguida, você precisa instalar selenium e webdriver_manager. Você pode fazer isso através do PIP:
pip install selenium
pip install webdriver_managerEtapa 2: Inicializar o ambiente selenium
Agora, precisamos adicionar alguns itens de configuração do selenium e inicializar o ambiente.
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)Etapa 3: Obter dados específicos
Usamos o selenium para obter o produto com product_id 4172129135583325756 e capturar alguns dados do OnlineSeller
driver.get(url)
time.sleep(5) #esperar página
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""Código completo
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)Os resultados da impressão do console são os seguintes:

Limitações
O Selenium é uma ferramenta poderosa para automatizar operações de navegador web e é amplamente usado em testes automatizados e raspagem de dados da web. No entanto, ele precisa esperar o carregamento da página, portanto, é relativamente lento no processo de raspagem de dados.
FAQ
Quais são os melhores métodos para extrair dados de listagens de produtos do Google em escala?
O método mais eficaz para raspagem de produtos do Google em larga escala é usar o Scrapeless. Ele fornece uma API rápida e escalável, lidando com conteúdo dinâmico, bloqueio de IP e CAPTCHAs de forma eficiente, tornando-o ideal para empresas.
Como contornar as medidas anti-raspagem do Google ao extrair dados de listagens de produtos?
O Google emprega várias medidas anti-raspagem, incluindo CAPTCHAs e bloqueio de IP. O Scrapeless fornece uma API que ignora essas medidas e garante a extração de dados suave e ininterrupta.
Posso usar bibliotecas Python como BeautifulSoup ou Selenium para extrair dados de listagens de produtos do Google?
Embora o BeautifulSoup e o Selenium possam ser usados para extrair dados de listagens de produtos do Google, eles apresentam limitações, como desempenho lento, risco de detecção e incapacidade de escalar. O Scrapeless oferece uma solução mais eficiente que lida com todos esses problemas.
Conclusão
Neste artigo, discutimos três métodos para extrair dados de vendedores online de produtos do Google: Requests & BeautifulSoup, Selenium e Scrapeless. Cada método oferece vantagens distintas, mas quando se trata de lidar com raspagem em larga escala, o Scrapeless é, sem dúvida, a melhor escolha para as empresas.
- Requests & BeautifulSoup são adequados para tarefas de raspagem em pequena escala, mas enfrentam limitações ao lidar com conteúdo dinâmico ou ao aumentar a escala. Essas ferramentas também correm o risco de serem bloqueadas por medidas anti-raspagem.
- Selenium é eficaz para páginas renderizadas em JavaScript, mas consome muitos recursos e é mais lento do que outras opções, tornando-o menos ideal para raspagem em larga escala de listagens de produtos do Google.
Por outro lado, o Scrapeless aborda todos os desafios associados aos métodos tradicionais de raspagem. É rápido, confiável e legal, garantindo que você possa extrair dados de vendedores online de produtos do Google de forma eficiente em escala, sem se preocupar com bloqueios ou outros obstáculos.
Para empresas que buscam uma solução simplificada e escalável, o Scrapeless é a ferramenta ideal. Ele contorna todos os obstáculos dos métodos convencionais e proporciona uma experiência suave e sem complicações para coletar dados de produtos do Google.
Experimente o Scrapeless hoje com uma avaliação gratuita e descubra como é fácil escalar suas tarefas de extração de dados de produtos do Google. Comece sua avaliação gratuita agora.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


