
Como raspar dados da Expedia com Python?
Expert Network Defense Engineer
Expedia é o site ideal para viajantes! Os usuários podem facilmente encontrar informações abrangentes e precisas sobre viagens nele: de preços de passagens aéreas a aluguéis de férias e aluguel de carros. Além da recuperação de informações, a Expedia também permite que os usuários reservem voos, acomodações e aluguéis diretamente em seu site, tornando-o um recurso valioso para dados relacionados a viagens.
No entanto, a Expedia não fornece uma API de scraping, o que dificulta o scraping direto de uma grande quantidade de informações de voo. Devido ao grande número de páginas, não é prático coletar esses dados manualmente.
Vamos aprender mais sobre como raspar facilmente informações precisas de voos na Expedia neste artigo.
Comece a ler agora!
Por que os dados da Expedia são tão importantes?
Ao rastrear os dados da Expedia, você pode obter informações ricas do mercado para ajudar as empresas a tomar decisões mais inteligentes na indústria de viagens. Seja otimizando estratégias operacionais ou fornecendo aos clientes opções mais econômicas, esses dados podem desempenhar um papel importante.
- Análise de mercado: Analise as tendências do mercado e os preços competitivos para ajudar as agências de viagens a desenvolver estratégias mais competitivas.
- Comparação de preços: Compare os preços em diferentes plataformas em tempo real para garantir a melhor escolha para os clientes.
- Monitoramento de estoque: Acompanhe o estoque de voos, hotéis e aluguel de carros e ajuste o fornecimento a tempo para atender à demanda.
- Previsão de tendências: Preveja tendências de viagens com base em dados históricos e planeje recursos com antecedência.
Por que é difícil raspar dados da Expedia?
Como a maioria dos sites modernos, a Expedia é um site dinâmico que usa muito JavaScript para renderizar conteúdo e lidar com interações do usuário. Portanto, é difícil raspar usando ferramentas tradicionais de web scraping baseadas em HTML, como Beautiful Soup e Cheerio, porque elas não conseguem executar JavaScript.
2 Métodos para raspar dados da Expedia usando Python
Método 1. Scrapeless Scraping API (Melhor escolha)
Scrapeless é um kit de ferramentas completo, poderoso e eficiente para extrair dados da Expedia e outros sites relacionados a viagens. Ele oferece uma maneira perfeita de coletar informações valiosas sem os desafios técnicos de construir seu próprio scraper.
O Scrapeless fornece um serviço de API de scraping da Expedia acessível, estável e seguro. Ele ajuda você a obter detalhes de voos e hotéis em 3 segundos. Você só precisa configurar os parâmetros e inserir seu token de API.
- Extração abrangente de dados: O Scrapeless pode raspar dados de viagens, incluindo voos, preços de hotéis, aluguel de carros e muito mais, garantindo que você obtenha todas as informações de que precisa.
- Soluções personalizáveis: Soluções de scraping personalizadas estão disponíveis para atender às necessidades específicas do seu negócio, seja para análise de mercado, preços competitivos ou monitoramento de estoque.
- Lidando com conteúdo dinâmico: Técnicas avançadas para gerenciar sites com uso intensivo de JavaScript garantem a extração completa e precisa de dados.
- Escalonável e confiável: Capaz de lidar com scraping de dados em larga escala para entregar projetos de forma confiável e eficiente, fornecendo dados oportunos e consistentes.
- Transferência de dados: Você pode transferir o código Scrapeless diretamente para seu banco de dados, garantindo uma integração perfeita com seus sistemas existentes. O Scrapeless suporta retornos e exportações em formato JSON.
- Conformidade e ética: O Scrapeless garante a conformidade com as diretrizes legais e éticas, respeitando os termos de serviço do site e os regulamentos de privacidade de dados.
Método 2. Construa seu próprio scraper da Expedia em Python
Desvantagens:
- Criar sua própria ferramenta de scraping do Google Maps consome muito tempo.
- Você pode enfrentar desafios como bloqueio de IP, verificação CAPTCHA, configuração de vários proxies e gerenciamento de limites de solicitação.
Raspe dados da Expedia usando Scrapeless com Python
A seguir, explicaremos detalhadamente como combinar Python e Scrapeless API para rastrear dados de voos da Expedia.
Ao desenvolver sem a API Scrapeless, rastrear o site da Expedia pode exigir consideração da velocidade da solicitação, proxy, controle de risco, envio de dados e outros problemas, mas agora, usando a API Scrapeless, você só precisa configurar e editar a configuração dos dados que precisa e, em seguida, executar o programa, você pode obter os dados que precisa.
Nota: O código e a configuração relevantes serão mostrados mais tarde
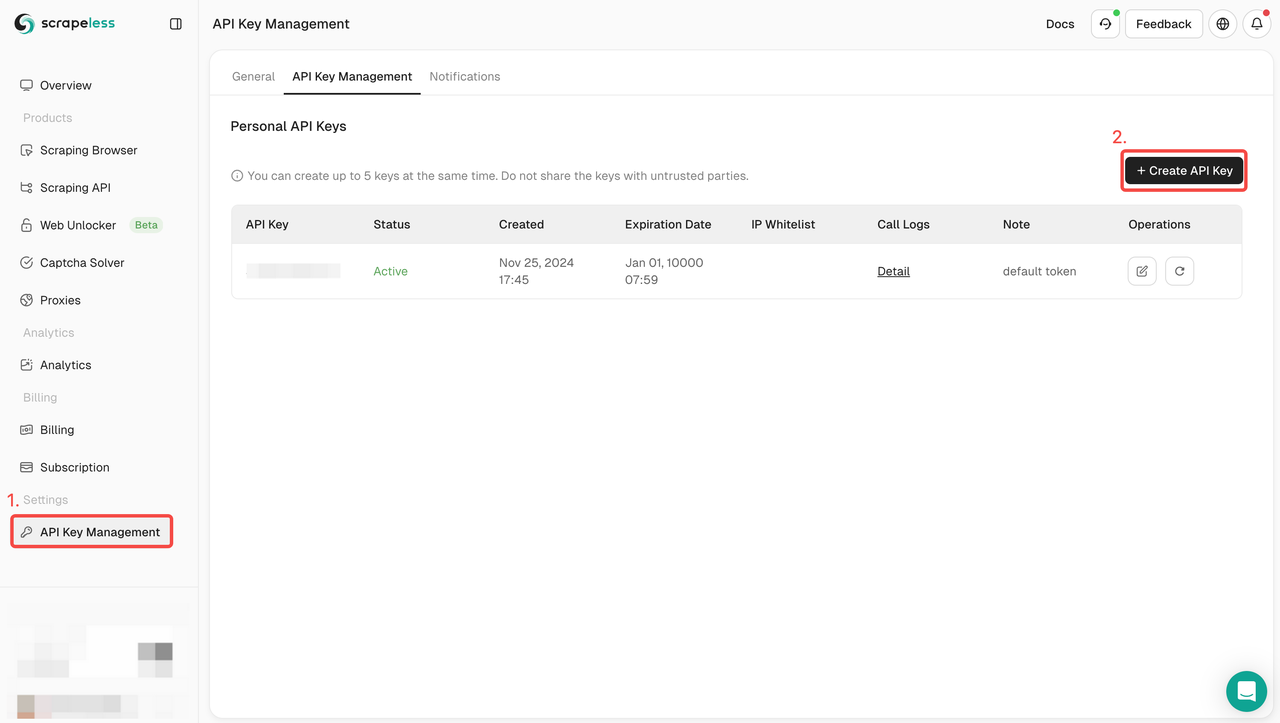
Passo 1. Obtenha sua chave de API
Para começar, você precisará obter sua chave de API no painel do Scrapeless:
- Faça login no Painel do Scrapeless.
- Navegue até Gerenciamento de chave de API.
- Clique em Criar para gerar sua chave de API exclusiva.
- Depois de criado, basta clicar na chave de API para copiá-la.
Assim que você concluir seu registro no Scrapeless, você receberá um saldo de pesquisa grátis de US$ 2.
Passo 2. Escreva o código de solicitação da API Scrapeless
O seguinte é o código de solicitação de referência que escrevi. Você pode ajustar os valores específicos conforme necessário:
Python
payload = {
"actor": "scraper.expedia", # Serviço a ser chamado
"input": {
"origin": "Tóquio (e arredores), Prefeitura de Tóquio, Japão", # Endereço de partida
"destination": "Nova York, NY, Estados Unidos da América (Todos os aeroportos de NYC)", # Destino
"date": {"year": 2025, "month": 3, "day": 5}, # Data de partida
"cabin_class": "PREMIUM_ECONOMY", # Classe da cabine
"travelers": {
"adult": 1, # Número de adultos
"children": [], # Idade das crianças de 2 a 17 anos
"infants_on_lap": [], # Idade dos bebês de 0 a 1 ano
"infants_in_seat": [], # Idade dos bebês de 0 a 1 ano
},
"size": 20, # Número de dados retornados por consulta, máximo 20
"page": 0, # Número de páginas consultadas
},
}Passo 3. Integre à API Scrapeless
Lembra da chave de API que acabamos de criar? Precisamos acessar oficialmente o serviço de API Scrapeless após a solicitação ser escrita. Preencha seu token de API no código abaixo:
Python
url = "https://api.scrapeless.com/api/v1/scraper/request"
headers = {"x-api-token": api-key} # Insira sua chave de API
res = requests.post(url, json=payload, headers=headers)A codificação completa:
Python
import time
import requests
api_key = "..."
headers = {"x-api-token": api_key}
payload = {
"actor": "scraper.expedia",
"input": {
"page": 0,
"origin": "Tóquio (e arredores), Prefeitura de Tóquio, Japão",
"destination": "Nova York, NY, Estados Unidos da América (Todos os aeroportos de NYC)",
"date": {"year": 2025, "month": 4, "day": 22},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": [],
},
"size": 20,
"page": 0,
},
}
url = "https://api.scrapeless.com/api/v1/scraper/request"
res = requests.post(url, json=payload, headers=headers)
print(data.text)
data = res.json()
# Se o tempo limite ocorrer, retornamos a ID da tarefa
if "taskId" in data:
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + data["taskId"]
resp = requests.get(url, headers=headers)
if resp.status_code != 200:
print("failed:", resp.text)
break
if "data" in resp.json():
print("succeed:", resp.text)
break
print(resp.text)Referência dos resultados de scraping

Leitura adicional:
Raspe dados da Expedia via APIDocs
Você também pode raspar dados de voo da Expedia diretamente na documentação da API Scrapeless. Consulte as etapas a seguir.
- Passo 1. Crie seu token de API (mencionado anteriormente).
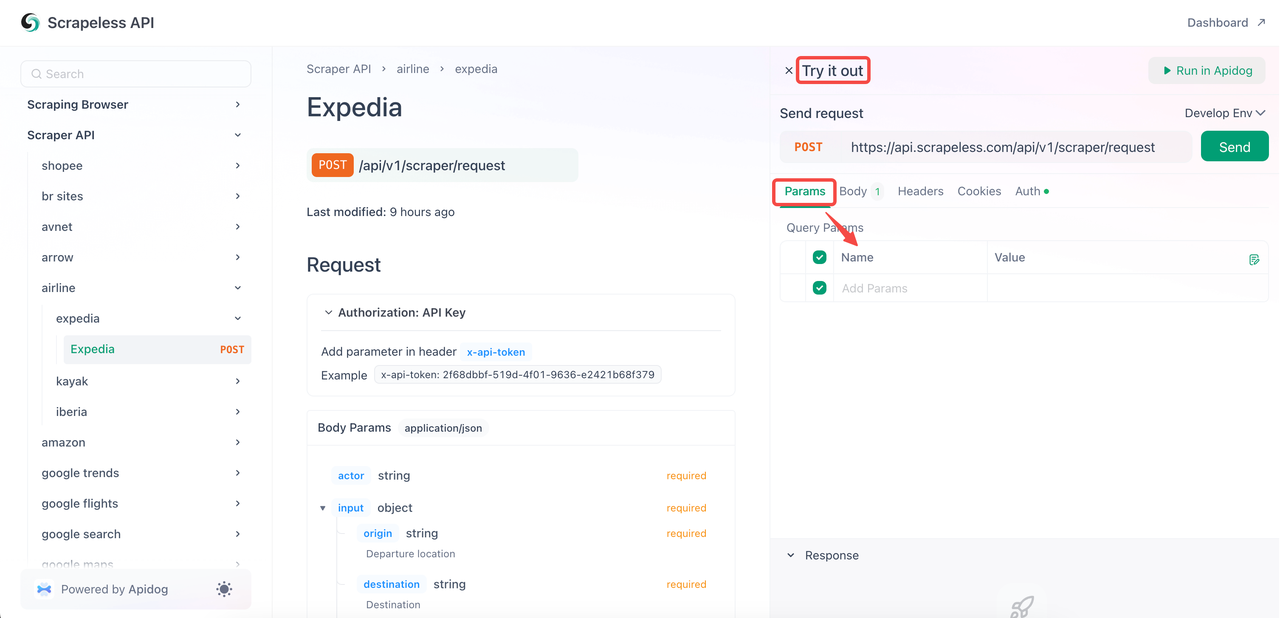
- Passo 2. Vá para a página da Expedia e clique em "Experimente".
- Passo 3. Configure os parâmetros necessários na seção
Parâmetros. Você pode visualizar o conteúdo geral do código noCorpo.
Aqui está o código de solicitação para referência:
Python
{
"actor": "scraper.expedia",
"input": {
"origin": "Tóquio (e arredores), Prefeitura de Tóquio, Japão",
"destination": "Nova York, NY, Estados Unidos da América (Todos os aeroportos de NYC)",
"date": {
"year": 2025,
"month": 3,
"day": 5
},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": []
},
"size": 20,
"page": 0
}
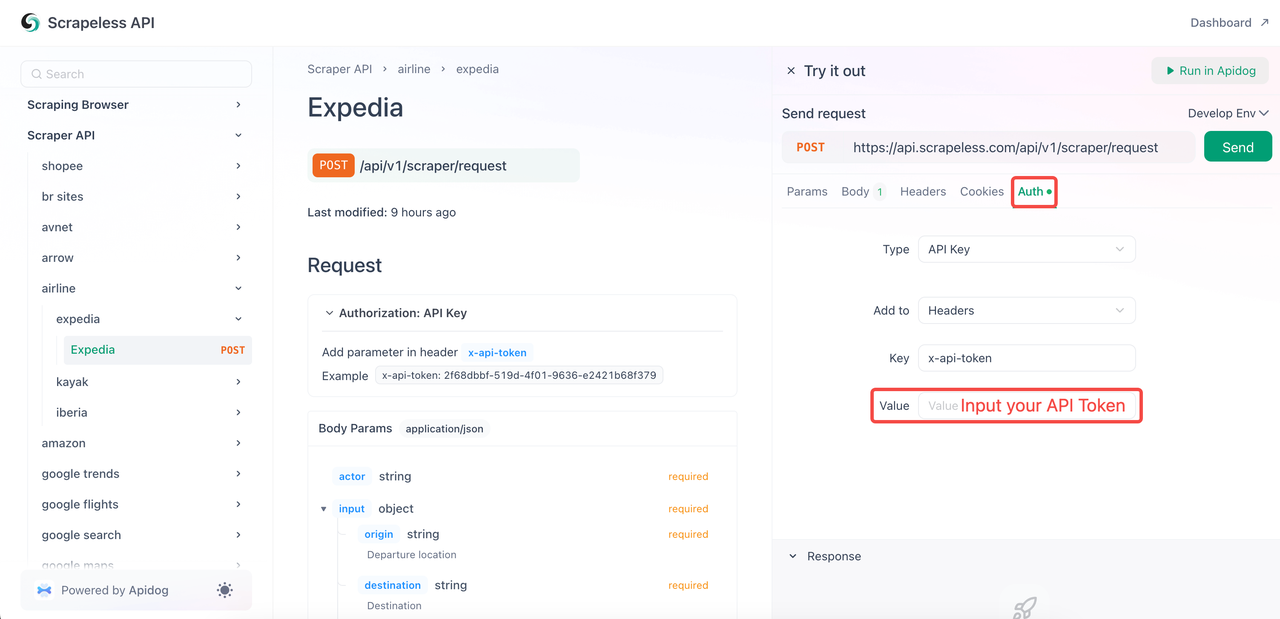
}- Passo 4. O mais importante é clicar em "Autenticação" e colar seu token de API. Finalmente, clique em "Enviar" para raspar os dados!
- Referência de resultados de scraping:
JSON
{
"data": {
"flightsSearch": {
"flightsSheets": null,
"clientMetadata": {
"pageName": "Voos de TYO para NYC",
"pageNameAnalytics": {
"__typename": "FlightsAnalytics",
"linkName": "Página de Pesquisa de Voo Ida",
"referrerId": "page.Flight-Search-Oneway"
},
"responseTags": [
"RESPONSE_SUMMARY_HYBRID",
"UNRECOGNIZED",
"UNRECOGNIZED",
"UNRECOGNIZED",
"RESPONSE_SUMMARY_REFINEMENTS_CACHE_LIVE"
],
"responseMetrics": [
{
"name": "LISTINGS_SUPPLY_RESPONSE_TIME",
"value": "1450"
}
],
"evaluatedExperiments": [
{
"bucket": 0,
"id": "FARES_ON_FSR_VARIANT"
},
{
"bucket": 1,
"id": "RECOMMENDED_SORT_V2_ENABLED"
},
{
"bucket": 0,
"id": "CACHE_HYDRATOR_FEATURE"
},
{
"bucket": 0,
"id": "TEST_SEARCH_STACK"
},
{
"bucket": 0,
"id": "NONSTOP_ENABLED"
},
{
"bucket": 1,
"id": "VERTICAL_SLICING_ENABLED"
},
{
"bucket": 0,
"id": "SHARED_UI_LISTINGS_ENABLED"
}
]
},Deep SerpApi do Scrapeless está pronto!
Deep SerpAPi é um mecanismo de busca dedicado projetado para modelos de linguagem grandes (LLMs) e agentes de IA. Ele fornece informações precisas, em tempo real e imparciais, permitindo que aplicativos de IA recuperem e processem dados de forma eficaz:
✅ Possui interfaces integradas de 20+ cenários da API de pesquisa do Google e está conectado aos dados dos principais mecanismos de busca.
✅ Abrange 20+ tipos de dados, como resultados de pesquisa, notícias, vídeos e imagens.
✅ Suporta atualizações de dados históricos nas últimas 24 horas.
Deep SerpApi considerará totalmente as necessidades dos desenvolvedores de IA! Simplificaremos o processo de integração de informações da web dinâmicas em soluções baseadas em IA e, finalmente, realizaremos uma API ALL-in-One que permite a busca e extração de dados da web com um único clique. Além disso, manteremos o preço mais baixo neste campo por muito tempo: US$ 0,1-US$ 0,3/1K consultas.
Não perca nosso Programa de Patrocínio para Desenvolvedores!
Junte-se à nossa comunidade e receba 500 mil créditos grátis agora.
Considerações finais
Construir manualmente um crawler Python pode rastrear dados da Expedia, mas é fácil encontrar vários obstáculos de bloqueio do site. Se você deseja rastrear dados de voo da Expedia de forma mais segura, direta, rápida e precisa, pode experimentar a API Scrapeless Scraping. Apenas a configuração simples de parâmetros e o preenchimento de dados são necessários para concluir perfeitamente o rastreamento de resultados.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


