
Quais parâmetros de resposta você pode obter no Scrapeless?
Senior Web Scraping Engineer
Em cenários modernos de extração de dados da web, simplesmente recuperar páginas HTML muitas vezes não é suficiente para atender às necessidades comerciais ao enfrentar mecanismos sofisticados de contra-raspagem. Na Scrapeless, permanecemos comprometidos em elevar as capacidades do nosso produto a partir da perspectiva do desenvolvedor.
Hoje, estamos entusiasmados em anunciar uma grande atualização em um dos serviços principais da Scrapeless — a API Universal de Extração. O Web Unlocker agora suporta múltiplos formatos de resposta! Essa melhoria aumenta significativamente a flexibilidade da API, proporcionando uma experiência de extração de dados mais adaptável e eficiente para usuários empresariais e desenvolvedores.
Por Que Fazemos uma Atualização?
Anteriormente, a API Universal de Extração retornava por padrão o conteúdo da página HTML, que funcionava bem para acessar rapidamente páginas não criptografadas ou sites com medidas de contra-raspagem mais fracas. No entanto, à medida que as demandas dos usuários por automação cresceram, observamos que muitos usuários ainda precisavam processar manualmente estruturas de dados, limpar conteúdo e extrair elementos após obter o HTML — adicionando uma sobrecarga de desenvolvimento desnecessária. Poderíamos simplificar esse processo para fornecer conteúdo pré-processado em um único passo?
Agora você pode!
Reformulamos a lógica de resposta. Ao configurar o parâmetro response_type, os desenvolvedores podem especificar flexivelmente o formato de dados desejado. Se você precisa de HTML bruto, texto simples ou metadados estruturados, uma simples configuração de parâmetro é tudo o que é necessário.
Agora, Formatos de Resposta Que Você Pode Obter:
Os formatos atualmente suportados incluem, mas não se limitam a:
- Filtros de saída JSON: Use o parâmetro
outputspara filtrar dados formatados em JSON. Os tipos de filtro permitidos incluememail,phone_numbers,headingse 9 outros, com os resultados retornados em JSON estruturado. - Vários formatos de retorno: Além da filtragem JSON, você pode especificar diretamente o formato de resposta adicionando o parâmetro
response_typeà sua solicitação (por exemplo,response_type=plaintext).
Os formatos atualmente suportados incluem:
HTML: Extrai o conteúdo da página em formato HTML (ideal para páginas estáticas).Plaintext: Retorna o conteúdo extraído como texto simples, livre de tags HTML ou formatação Markdown — perfeito para processamento ou análise de texto.Markdown: Extrai o conteúdo da página em formato Markdown (ideal para páginas estáticas baseadas em Markdown), facilitando a leitura e o processamento.PNG/JPEG: Ao definirresponse_type=png, captura uma captura de tela da página alvo e a retorna em formato PNG ou JPEG (com opções para capturas de tela de página inteira).
Nota: O
response_typepadrão é html.
Vamos Ver Exemplos
1. Filtragem de valor de retorno JSON:
Você pode usar o parâmetro outputs para filtrar dados em formato JSON. Uma vez que este parâmetro é definido, o tipo de resposta será fixo em JSON.
O parâmetro aceita uma lista de nomes de filtro separados por vírgulas e retorna os dados em formato JSON estruturado. Os tipos de filtro suportados incluem: phone_numbers, headings, images, audios, videos, links, menus, hashtags, emails, metadata, tables e favicon.
O seguinte código de exemplo demonstra como obter todas as informações de imagem na página inicial do site scrapeless:
JavaScript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- Resultados:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75",
plaintext
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
Plain Text
# API Scrapeless
## Docs
- Navegador de Scraping [API CDP](https://apidocs.scrapeless.com/doc-801748.md):
- API de Scraping > shopee [Lista de Atores](https://apidocs.scrapeless.com/doc-754333.md):
- API de Scraping > amazon [Parâmetros da API](https://apidocs.scrapeless.com/doc-857373.md):
- API de Scraping > pesquisa google [Parâmetros da API](https://apidocs.scrapeless.com/doc-800321.md):
- API de Scraping > tendências google [Parâmetros da API](https://apidocs.scrapeless.com/doc-796980.md):
- API de Scraping > voos google [Parâmetros da API](https://apidocs.scrapeless.com/doc-796979.md):
- API de Scraping > gráfico de voos google [Parâmetros da API](https://apidocs.scrapeless.com/doc-908741.md):
- API de Scraping > mapas google [Parâmetros da API (Google Maps)](https://apidocs.scrapeless.com/doc-834792.md):
- API de Scraping > mapas google [Parâmetros da API (Autocomplete do Google Maps)](https://apidocs.scrapeless.com/doc-834799.md):
- API de Scraping > mapas google [Parâmetros da API (Avaliações de Contribuidores do Google Maps)](https://apidocs.scrapeless.com/doc-834806.md):
- API de Scraping > mapas google [Parâmetros da API (Direções do Google Maps)](https://apidocs.scrapeless.com/doc-834821.md):
- API de Scraping > mapas google [Parâmetros da API (Avaliações do Google Maps)](https://apidocs.scrapeless.com/doc-834831.md):
- API de Scraping > google scholar [Parâmetros da API (Google Scholar)](https://apidocs.scrapeless.com/doc-842638.md):
- API de Scraping > google scholar [Parâmetros da API (Autor do Google Scholar)](https://apidocs.scrapeless.com/doc-842645.md):
- API de Scraping > google scholar [Parâmetros da API (Citação do Google Scholar)](https://apidocs.scrapeless.com/doc-842647.md):
- API de Scraping > google scholar [Parâmetros da API (Perfis do Google Scholar)](https://apidocs.scrapeless.com/doc-842649.md):
- API de Scraping > empregos google [Parâmetros da API](https://apidocs.scrapeless.com/doc-850038.md):
- API de Scraping > compras google [Parâmetros da API](https://apidocs.scrapeless.com/doc-853695.md):
- API de Scraping > hotéis google [Parâmetros da API](https://apidocs.scrapeless.com/doc-865231.md):
- API de Scraping > hotéis google [Tipos de Propriedade de Aluguel de Férias do Google Suportados](https://apidocs.scrapeless.com/doc-890578.md):
- API de Scraping > hotéis google [Tipos de Propriedade de Hotéis do Google Suportados](https://apidocs.scrapeless.com/doc-890580.md):
- API de Scraping > hotéis google [Comodidades de Aluguel de Férias do Google Suportados](https://apidocs.scrapeless.com/doc-890623.md):
- API de Scraping > hotéis google [Comodidades de Hotéis do Google Suportados](https://apidocs.scrapeless.com/doc-890631.md):
- API de Scraping > notícias google [Parâmetros da API](https://apidocs.scrapeless.com/doc-866643.md):
- API de Scraping > lens google [Parâmetros da API](https://apidocs.scrapeless.com/doc-866644.md):
- API de Scraping > finanças google [Parâmetros da API](https://apidocs.scrapeless.com/doc-873763.md):
- API de Scraping > produto google [Parâmetros da API](https://apidocs.scrapeless.com/doc-880407.md):
- API de Scraping [loja google play](https://apidocs.scrapeless.com/folder-3277506.md):
- API de Scraping > loja google play [Parâmetros da API](https://apidocs.scrapeless.com/doc-882690.md):
- API de Scraping > loja google play [Categorias Suportadas do Google Play](https://apidocs.scrapeless.com/doc-882822.md):
- API de Scraping > anúncios google [Parâmetros da API](https://apidocs.scrapeless.com/doc-881439.md):
- API de Scraping Universal [Docs de Renderização JS](https://apidocs.scrapeless.com/doc-801406.md):
## Docs da API
- Usuário [Obter Informações do Usuário](https://apidocs.scrapeless.com/api-11949851.md): Recupere informações básicas sobre o usuário autenticado atualmente, incluindo seu saldo de conta e detalhes do plano de assinatura.
- Navegador de Scraping [Conectar](https://apidocs.scrapeless.com/api-11949901.md):
- Navegador de Scraping [Sessões em execução](https://apidocs.scrapeless.com/api-16890953.md): Obter todas as sessões em execução
- Navegador de Scraping [URL ao vivo](https://apidocs.scrapeless.com/api-16891208.md): Obter a URL ao vivo de uma sessão em execução pelo ID da tarefa da sessão
- API de Scraping > shopee [Produto Shopee](https://apidocs.scrapeless.com/api-11953650.md):
- API de Scraping > shopee [Pesquisa Shopee](https://apidocs.scrapeless.com/api-11954010.md):
- API de Scraping > shopee [Recomendação Shopee](https://apidocs.scrapeless.com/api-11954111.md):
- API de Scraping > sites br [Soluções cnpjreva](https://apidocs.scrapeless.com/api-11954435.md): URL alvo `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- API de Scraping > sites br [Soluções certidaointernet](https://apidocs.scrapeless.com/api-12160439.md): URL alvo `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`- API de Scraping > sites br Servicos receita: url de destino
https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp - API de Scraping > sites br Consopt: url de destino
https://consopt.www8.receita.fazenda.gov.br/consultaoptantes - API de Scraping > amazon produto:
- API de Scraping > amazon vendedor:
- API de Scraping > amazon palavras-chave:
- API de Scraping > pesquisa google Pesquisa Google:
- API de Scraping > pesquisa google Imagens Google:
- API de Scraping > pesquisa google Google Local:
- API de Scraping > tendências google AutoComplete:
- API de Scraping > tendências google Interesse ao longo do tempo:
- API de Scraping > tendências google Quebra Comparada por Região:
- API de Scraping > tendências google Interesse por Sub-região:
- API de Scraping > tendências google Consultas Relacionadas:
- API de Scraping > tendências google Tópicos Relacionados:
- API de Scraping > tendências google Tendências Agora:
- API de Scraping > voos google Ida e Volta:
- API de Scraping > voos google Somente Ida:
- API de Scraping > voos google Múltiplas Cidades:
- API de Scraping > gráfico de voos google gráfico:
- API de Scraping > mapas google Google Maps:
- API de Scraping > mapas google Autocomplete do Google Maps:
- API de Scraping > mapas google Avaliações de Contribuidores do Google Maps:
- API de Scraping > mapas google Direções do Google Maps:
- API de Scraping > mapas google Avaliações do Google Maps:
- API de Scraping > google scholar Google Scholar:
- API de Scraping > google scholar Autor do Google Scholar:
- API de Scraping > google scholar Citar Google Scholar:
- API de Scraping > google scholar Perfis do Google Scholar:
- API de Scraping > google jobs Google Jobs:
- API de Scraping > google shopping Google Shopping:
- API de Scraping > google hotels Google Hotels:
- API de Scraping > google news Google News:
- API de Scraping > google lens Google Lens:
- API de Scraping > google finance Google Finance:
- API de Scraping > google finance Mercados do Google Finance:
- API de Scraping > produto google Produto Google:
- API de Scraping > loja google play Google Play Jogos:
- API de Scraping > loja google play Google Play Livros:
- API de Scraping > loja google play Google Play Filmes:
- API de Scraping > loja google play Produto Google Play:
- API de Scraping > loja google play Aplicativos Google Play:
- API de Scraping > google ads Google Ads:
- API de Scraping Solicitação Scraper:
- API de Scraping Obter Resultado Scraper:
- API de Scraping Universal Render JS:
- API de Scraping Universal Desbloqueador Web:
- API de Scraping Universal Cookie Akamaiweb:
- API de Scraping Universal Sensor Akamaiweb:
- Raspador > Scrape Raspar um único URL:
- Crawler > Scrape Raspar várias URLs:
- Crawler > Scrape Cancelar um trabalho de raspagem em lote:
- Crawler > Scrape Obter o status de uma raspagem:
- Crawler > Scrape Obter o status de um trabalho de raspagem em lote:
- Crawler > Scrape Obter os erros de um trabalho de raspagem em lote:
- Crawler > Crawl Raspar várias URLs com base em opções:
- Crawler > Crawl Cancelar um trabalho de rastreamento:
- Crawler > Crawl Obter o status de um trabalho de rastreamento:
- Crawler > Crawl Obter os erros de um trabalho de rastreamento:
- Público status do ator:
- Público status do ator:
### 4. Markdown
Ao adicionar `response_type=markdown` nos parâmetros da solicitação, a API de Raspagem Universal Scrapeless retornará o conteúdo de uma página específica no formato Markdown.
O exemplo a seguir mostra o efeito markdown da [página de Introdução ao Raspador](https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started). Primeiro usamos a inspeção da página para obter o seletor CSS da tabela.
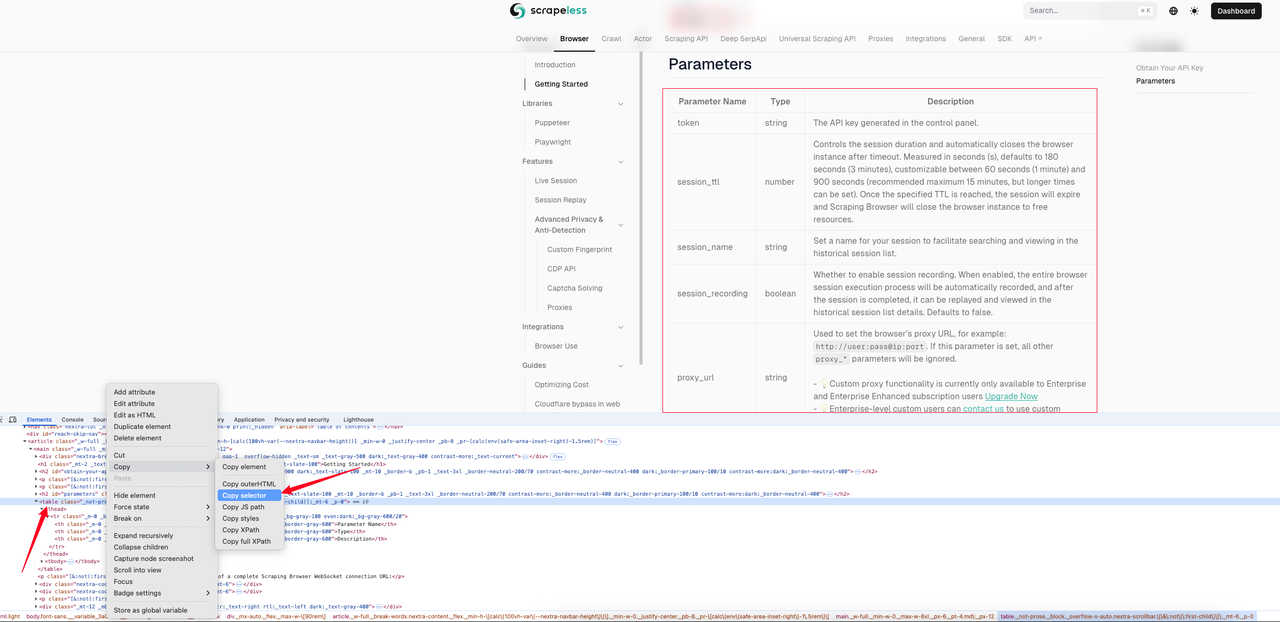
Neste exemplo, o seletor CSS que obtemos é: `#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table`. A seguir está o código de exemplo completo.
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // Seletor CSS do elemento da tabela da página
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "Chave da API",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # Seletor CSS do elemento da tabela da página
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "Chave da API",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])Exibição do texto markdown da tabela raspada:
Markdown
| Nome do Parâmetro | Tipo | Descrição |
| --- | --- | --- |
| token | string | A chave da API gerada no painel de controle. |
| session_ttl | number | Controla a duração da sessão e fecha automaticamente a instância do navegador após o tempo limite. Medido em segundos (s), padrão de 180 segundos (3 minutos), personalizável entre 60 segundos (1 minuto) e 900 segundos (15 minutos recomendado, mas tempo mais longo pode ser definido). Assim que o TTL especificado é atingido, a sessão expira e o Raspador de Páginas fechará a instância do navegador para liberar recursos. |
| session_name | string | Defina um nome para sua sessão para facilitar a busca e visualização na lista de sessões históricas. |
| session_recording | boolean | Se deve habilitar a gravação da sessão. Quando habilitado, todo o processo de execução da sessão do navegador será gravado automaticamente e, após a conclusão da sessão, poderá ser reproduzido e visto nos detalhes da lista de sessões históricas. Padrão é falso. |
| proxy_url | string | Usado para definir a URL do proxy do navegador, por exemplo: http://user:pass@ip:port. Se este parâmetro for definido, todos os outros parâmetros proxy_* serão ignorados.- 💡A funcionalidade de proxy personalizado atualmente está disponível apenas para usuários com assinatura Enterprise e Enterprise Enhanced. Atualize agora.- 💡Usuários empresariais personalizados podem entrar em contato conosco para usar proxies personalizados. || proxy_country | string | Define o país/região de destino para o proxy, enviando solicitações através de um endereço IP daquela região. Você pode especificar um código de país (por exemplo, US para os Estados Unidos, GB para o Reino Unido, ANY para qualquer país). Consulte os códigos de país para todas as opções suportadas. |
| fingerprint | string | Uma impressão digital de navegador é uma “impressão digital digital” quase única criada usando as informações de configuração do seu navegador e dispositivo, que pode ser usada para rastrear sua atividade online mesmo sem cookies. Felizmente, configurar impressões digitais no Scraping Browser é opcional. Oferecemos personalização profunda das impressões digitais do navegador, como parâmetros principais como agente do usuário do navegador, fuso horário, idioma e resolução da tela, e suporte para estender a funcionalidade através de parâmetros de inicialização personalizados. Adequado para gerenciamento de múltiplas contas, coleta de dados e cenários de proteção da privacidade, usar o próprio navegador Chromium da scrapeless evita completamente a detecção. Por padrão, nosso serviço Scraping Browser gera uma impressão digital aleatória para cada sessão. Referência |
### 5. PNG/JPEG
Ao adicionar response_type=png à solicitação, você pode capturar uma captura de tela da página alvo e retornar uma imagem no formato png ou jpeg. Quando o resultado da resposta é definido como png ou jpeg, você pode definir se o resultado devolvido será em tela cheia usando o parâmetro `response_image_full_page=true`. O valor padrão deste parâmetro é falso.
O seguinte exemplo de código mostra como obter uma captura de tela de uma área especificada na [página inicial do Scrapeless](https://www.scrapeless.com/?utm_source=official&utm_medium=blog&utm_campaign=response-formats-update). Primeiro, encontramos o seletor CSS para a área que queremos capturar a imagem.
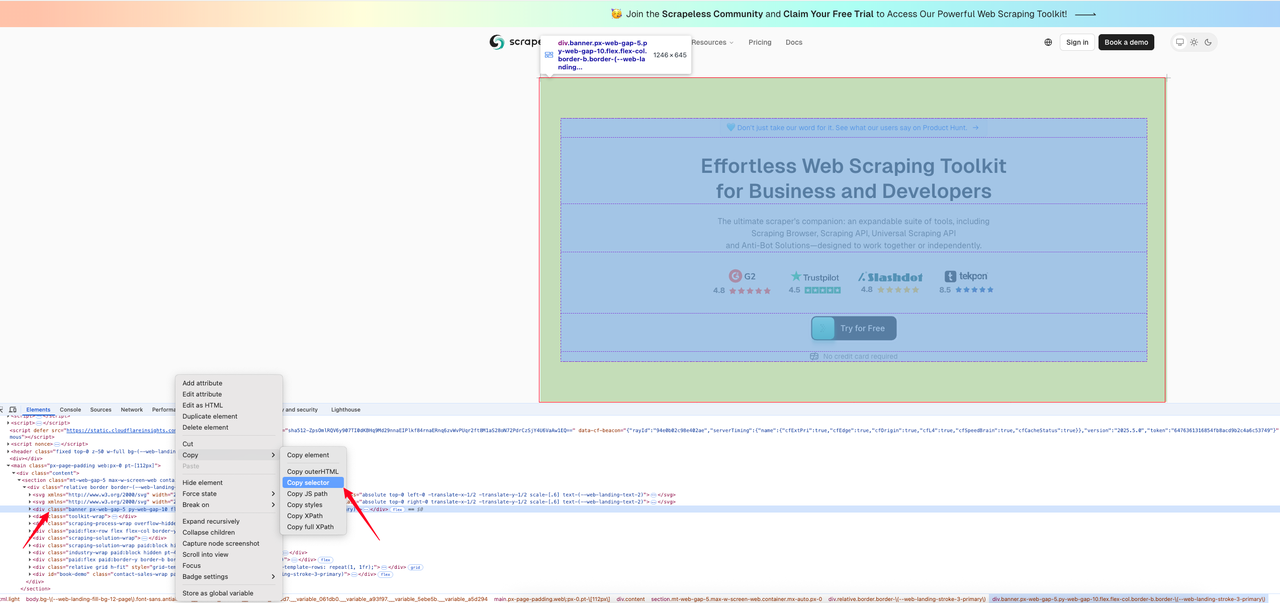
Abaixo está o código de interceptação:
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // Seletor CSS do elemento da tabela da página
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "Chave de API",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # Seletor CSS do elemento da tabela da página
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "Chave de API",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- Resultado do retorno PNG:

👉 Visite Scrapeless Docs para saber mais
👉 Confira a documentação da API agora: JS Render
Cenários de uso totalmente cobertos
Esta atualização é especialmente adequada para:
- Aplicativos de extração de conteúdo (como geração de resumos, coleta de inteligência)
- Crawling de dados de SEO (como análise de meta, dados estruturados)
- Plataforma de agregação de notícias (extração rápida de texto e autor)
- Ferramentas de análise e monitoramento de links (extração de informações href, nofollow)
Se você deseja rapidamente rastrear texto ou quer dados estruturados, essa atualização pode ajudá-lo a obter mais resultados com menos esforço.
Experimente agora
A função foi totalmente lançada no Scrapeless. Nenhuma autorização adicional ou plano de atualização é necessário. Basta limitar o parâmetro de saída ou passar no parâmetro response_type para experimentar o novo formato de retorno de dados!
Scrapeless sempre se comprometeu a construir uma plataforma de dados web inteligente, estável e fácil de usar. Esta atualização é apenas mais um passo à frente. Agradecemos sua experiência e feedback, vamos juntos tornar a aquisição de dados web mais fácil.
🔗 Experimente a API Universal de Scraping do Scrapeless agora
📣 Junte-se à comunidade para receber atualizações e dicas práticas em primeira mão!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


