
Solução GEO: Automatize a Perplexidade com o Navegador Sem Resíduos para Construir um Motor de Análise de Conteúdo
Expert Network Defense Engineer
Transforme respostas de IA em vantagem comercial – soluções GEO da Scrapeless ajudam você a capturar, analisar e agir.
A Otimização do Motor Gerativo (GEO) está se tornando rapidamente uma das tendências mais disruptivas na indústria de busca. À medida que os grandes modelos de linguagem (LLMs) remodelam a forma como os usuários descobrem informações, avaliam marcas e tomam decisões, as empresas não devem apenas ser visíveis nos resultados de busca tradicionais, mas também garantir que seu conteúdo apareça nas respostas geradas por IA.
No entanto, esta é apenas uma faceta de uma mudança de paradigma maior – estamos entrando em uma era de "busca ubíqua": os usuários não dependem mais apenas do Google, mas obtêm respostas em vários motores de IA, aplicativos assistentes e modelos verticais. Nesse cenário competitivo, o Perplexity está subindo a um ritmo impressionante, fornecendo não apenas respostas instantâneas, mas também citações de fontes em tempo real, pipelines de dados e análises aprofundadas, tornando-se uma ferramenta essencial para pesquisa de conteúdo, insights de mercado e monitoramento de concorrentes.
Fonte: Backlinko
Mas o verdadeiro desafio é este: se você ainda está fazendo perguntas ao Perplexity manualmente, uma a uma, sua eficiência simplesmente não consegue acompanhar o ritmo da indústria. Portanto, este artigo revelará como usar o Scrapeless Browser para automatizar o Perplexity, transformando-o em um motor de análise de conteúdo em operação contínua e escalável que lhe dá uma vantagem na era da busca generativa.
1. O que é GEO e por que isso importa?
A Otimização do Motor Gerativo (GEO) é a prática de criar e otimizar conteúdo para que ele apareça nas respostas geradas por IA em plataformas como Google AI Overviews, AI Mode, ChatGPT e Perplexity.
No passado, o sucesso significava ter uma classificação alta nas páginas de resultados dos mecanismos de busca (SERPs). Olhando para o futuro, o conceito de estar "no topo" pode não existir mais. Em vez disso, você precisa se tornar a recomendação preferida — a solução que as ferramentas de IA escolhem apresentar em suas respostas.
Os dados falam por si:
- A base de usuários do Perplexity está crescendo exponencialmente, superando 100 milhões de usuários ativos mensais este ano, já alcançando 1/20 da escala do Google.
- Os Google AI Overviews agora aparecem em bilhões de buscas por mês — cobrindo pelo menos 13% de todos os resultados de busca.
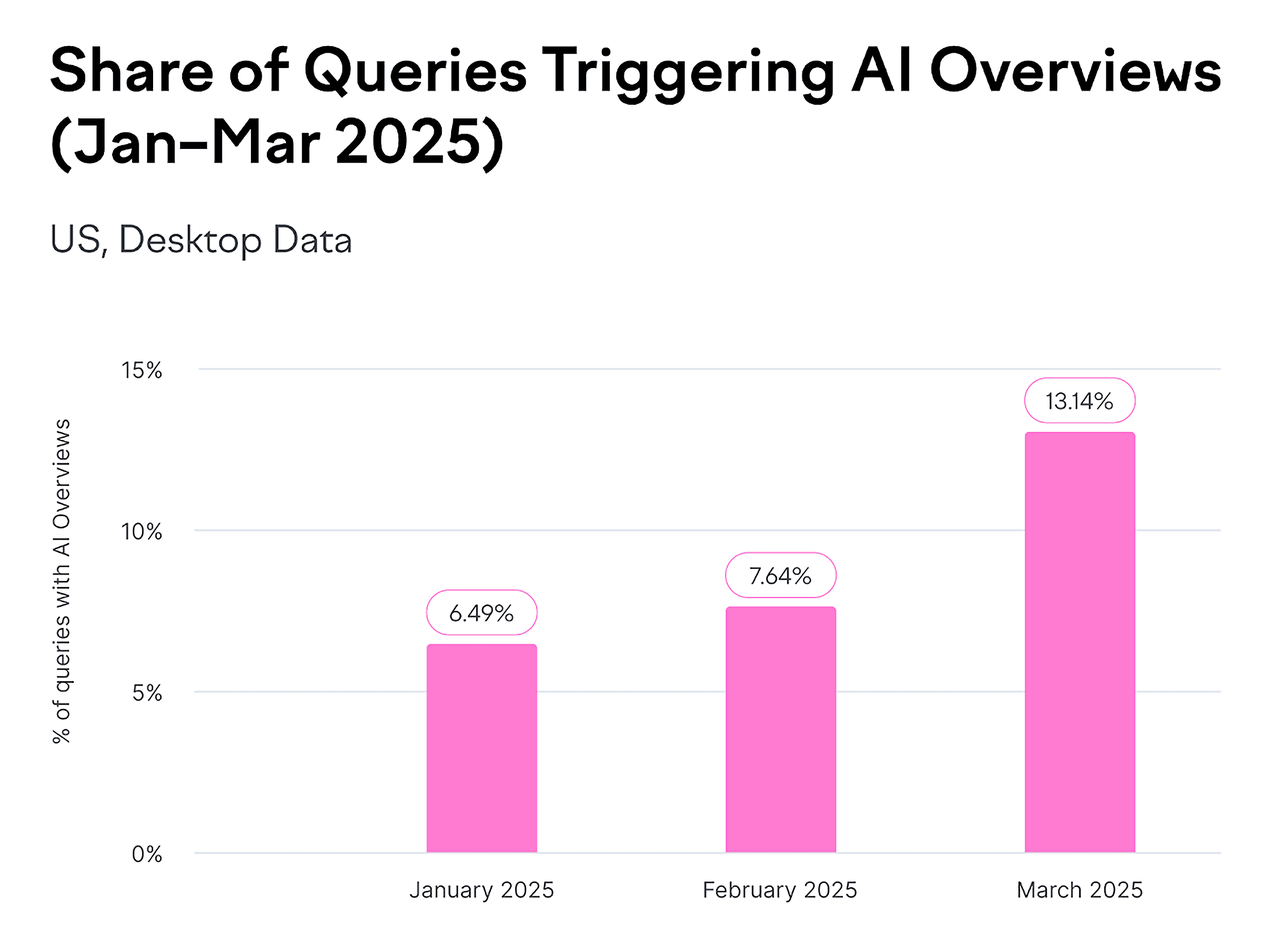
Fonte: Backlinko
Os objetivos principais da otimização GEO não estão mais limitados a gerar cliques, mas se concentram em três métricas chave:
- Visibilidade da Marca: Aumentar a probabilidade de sua marca aparecer em respostas geradas por IA.
- Autoridade da Fonte: Garantir que seu domínio, conteúdo ou dados sejam selecionados pelos modelos como uma referência confiável.
- Consistência Narrativa & Posicionamento Positivo: Fazer com que a IA descreva sua marca de maneira profissional, precisa e positiva.
Isso significa que a lógica tradicional de SEO de "classificação de palavras-chave" está gradualmente cedendo lugar ao mecanismo de citação de fontes da IA.
As marcas devem evoluir de "descobráveis" para "confiáveis, citadas e ativamente recomendadas."
2. Por que prestar atenção ao Perplexity?
O Perplexity AI tem aproximadamente 15 milhões de usuários ativos mensais, com taxas de crescimento contínuas. Especialmente na América do Norte e Europa, tornou-se quase sinônimo de “busca em IA.”
Para as equipes de estratégia de conteúdo, SEO e análise de mercado, o Perplexity não é mais apenas um “mecanismo de busca em IA” – tornou-se um novo “terminal de pesquisa inteligente.”
Você pode usá-lo para:
- Comparar diferenças de conteúdo entre otimizações de motor gerativo
- Ver quais sites são comumente citados para as mesmas palavras-chave em diferentes mercados
- Resumir rapidamente as estratégias de tópicos dos concorrentes
No entanto, existem desafios:
👉 Atualmente, o Perplexity só oferece suporte a registros no exterior, tornando-o inacessível para a maioria dos usuários na China.
👉 A versão gratuita não fornece acesso total à API.
Isso cria uma barreira natural para empresas ou equipes de conteúdo: elas não podem coletar e analisar dados sistematicamente em grande escala.
3. Por que escolher a automação Scrapeless?
O Scrapeless Browser oferece uma abordagem mais inteligente. Não é apenas um simples crawler—é uma instância real de navegador rodando na nuvem. Você não precisa abrir o Chrome localmente ou se preocupar em ser detectado como um bot. Com apenas uma linha de código do Puppeteer, você pode interagir com websites exatamente como um humano faria.
Por exemplo, você pode:
- Abrir
perplexity.ai - Inserir perguntas automaticamente
- Esperar os resultados serem gerados
- Extrair o texto da resposta e links de citação
- Salvar o HTML da página completa, capturas de tela, mensagens de WebSocket e requisições de rede
Vantagens Únicas do Scrapeless Browser
1. Tecnologia Anti-detecção de Nível Empresarial
Sites modernos de IA como o Perplexity possuem fortes proteções contra scraping:
- Verificação Cloudflare Turnstile
- Impressão digital do navegador
- Análise de padrão de comportamento
- Verificações de reputação de IP
Como o Scrapeless lida com isso:
ts
const CONNECTION_OPTIONS = {
proxyCountry: "US", // Usar um IP dos EUA
sessionRecording: "true", // Gravar sessão para depuração
sessionTTL: "900", // Manter sessão por 15 minutos
sessionName: "perplexity-scraper" // Sessão persistente
};- Simula automaticamente o comportamento real do usuário
- Impressões digitais do navegador aleatórias
- Solucionador de CAPTCHA embutido
- Rede de proxies cobrindo 195 países
2. Rede de Proxy Global
As respostas do Perplexity variam de acordo com a localização do usuário:
- 🇺🇸 Usuários dos EUA veem conteúdo local dos EUA
- 🇬🇧 Usuários do Reino Unido veem a perspectiva do Reino Unido
- 🇯🇵 Usuários japoneses veem conteúdo em japonês
Solução Scrapeless:
ts
proxyCountry: "US" // Para perspectiva dos EUA
proxyCountry: "GB" // Para insights do mercado europeu- Executar várias consultas de diferentes países para comparação global
- Suporta 195 nós de proxy e proxies de navegador personalizados
3. Persistência de Sessão + Reprodução de Gravação
Ao desenvolver e depurar scripts de automação, os pontos problemáticos comuns são:
- ❌ Não saber onde ocorreram erros
- ❌ Incapacidade de reproduzir problemas
- ❌ Executar scripts repetidamente para depuração
Sessão ao Vivo Scrapeless:
ts
sessionRecording: "true" // Ativar gravação de sessão- Visualização em tempo real: Assista ao processo de automação no navegador ao vivo
- Reprodução: Reproduza todo o processo se falhar
4. Custo de Manutenção Zero
Soluções tradicionais requerem:
- Puppeteer Local: Manter servidores, atualizar Chrome, lidar com falhas
- Navegador em nuvem auto-hospedado: Equipe de DevOps, monitoramento, escalonamento
- Custo mensal: 2 engenheiros × 20 horas ≈ $2.000
Scrapeless Browser:
- ✅ Hospedado na nuvem, auto-atualizado
- ✅ Garantia de 99,9% de uptime
- ✅ Escalonamento automático, sem preocupações com concorrência
- 💰 Custo: pagamento por uso, aproximadamente $50–200/mês
Comparação de ROI:
- Tradicional: $2.000 (mão de obra) + $200 (servidor) = $2.200/mês
- Scrapeless: $100/mês
- Economia: 95%!
5. Integração Pronta para Uso
O Scrapeless Browser é completamente compatível com bibliotecas de automação populares:
- ✅ Puppeteer (Node.js)
- ✅ Playwright (Node.js / Python)
- ✅ CDP (Protocolo de Ferramentas de Desenvolvedor do Chrome)
Custo de migração é próximo de zero:
ts
import puppeteer from "puppeteer-core"
// Original: Navegador local
// const browser = await puppeteer.launch();
// Migre para o Scrapeless Browser, basta mudar uma linha:
const browser = await puppeteer.connect({
browserWSEndpoint: "wss://browser.scrapeless.com/api/v2/browser?token=YOUR_API_TOKEN"
})
const page = await browser.newPage()
await page.goto("https://google.com")4. Scrapeless Browser + Puppeteer: Guia Detalhado para Capturar Automaticamente Respostas do Perplexity.ai
A seguir, usaremos o Scrapeless Browser + Puppeteer para visitar automaticamente o Perplexity.ai, enviar perguntas e capturar respostas, links de páginas, trechos em HTML e dados da rede.
Nenhuma instalação local do Chrome é necessária—pronto para uso imediato, com suporte para proxies, gravação de sessões e monitoramento de WebSocket.
Passo 1: Configurar Conexão Scrapeless
ts
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
const tokenValue = process.env.SCRAPELESS_TOKEN || "YOUR_API_TOKEN";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY", // Selecionar automaticamente o nó mais rápido
sessionRecording: "true", // Ativar gravação de sessão
sessionTTL: "900", // Manter sessão por 15 minutos
sessionName: "perplexity-scraper", // Nome da sessão
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}- Faça login no Scrapeless para obter seu Token de API.
💡 Pontos Chave:
proxyCountry: "ANY"seleciona automaticamente o nó mais rápido para reduzir a latência.- Se você precisar de conteúdo de uma região específica, por exemplo, notícias dos EUA, mude para
"US". sessionRecordingpermite a reprodução no console para facilitar a depuração.
Passo 2: Conectar ao Navegador na Nuvem
ts
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 }
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}💡 Notas:
puppeteer-coreé leve; conecta-se a um navegador remoto sem baixar o Chromium local.- Definir um User-Agent de desktop ajuda a evitar a detecção básica de anti-scraping.
- Usar
try-catché uma programação defensiva para melhorar a robustez do script.
Passo 3: Monitorar Toda a Atividade de Rede (Fundamental!)
Esta é uma parte crítica do script! Ele captura dois tipos de dados simultaneamente:
3.1 Ouvir as Respostas HTTP
ts
const rawResponses = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<leitura-falhou>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});Conteúdo Capturado:
- Chamadas de API, imagens, CSS, JS, etc.
- Códigos de status de resposta e cabeçalhos HTTP
- Primeiros 20KB do conteúdo da resposta (evita sobrecarga de memória enquanto é suficiente para análise de JSON)
3.2 Ouvir os Quadros WebSocket (Chave!)
ts
const wsFrames = [];
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ?
response.payloadData.slice(0, 20000) :
response.payloadData,
});
} catch (e) {}
});
} catch (e) {
// Se CDP não estiver disponível, ignore silenciosamente
}Por que WebSocket é Importante:
As respostas do Perplexity não são retornadas de uma só vez - elas são transmitidas via WebSocket:
O usuário insere a pergunta
↓
O backend do Perplexity gera a resposta
↓
Resposta enviada caractere por caractere via WebSocket
↓
Exibida no frontend em tempo real (como o efeito de digitação do ChatGPT)Benefícios de Capturar WebSocket:
- Observar todo o processo de geração de respostas
- Analisar a cadeia de raciocínio da IA do Perplexity
- Depurar respostas incompletas ou parciais
Passo 4: Visitar o Site do Perplexity
ts
await page.goto("https://www.perplexity.ai/", {
waitUntil: "domcontentloaded",
timeout: 90000
});Passo 5: Inserir Sua Pergunta Inteligentemente
ts
const prompt = "Oi ChatGPT, você sabe o que é Scrapeless?";
await findAndType(page, prompt);Passo 6: Aguardar Renderização e Capturar Resultados
ts
await page.waitForTimeout(1500);
const results = await page.evaluate(() => {
const pick = el => el ? (el.innerText || "").trim() : "";
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = ['[data-testid*="answer"]','[data-testid*="result"]','.Answer','article','main'];
selectors.forEach(s => {
const el = document.querySelector(s);
if(el){ const t = pick(el); if(t.length>30) out.answers.push({ selector:s,text:t.slice(0,20000) }); }
});
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0,200).map(a=>({ href:a.href, text:(a.innerText||"").trim() }));
out.rawHtmlSnippet = main.innerHTML.slice(0,200000);
return out;
});💡 Notas:
- Captura respostas, links e snippets de HTML
- Mantém dados importantes e trunca conteúdos excessivamente longos para desempenho
Passo 7: Salvar Saídas
ts
await fs.writeFile("./perplexity_results.json", JSON.stringify(results, null, 2));
await fs.writeFile("./perplexity_page.html", await page.content());
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true });- JSON, HTML, quadros WebSocket e capturas de tela são todos salvos
- Facilita a análise, depuração ou reprodução posterior
Passo 8: Fechar o Navegador
ts
await browser.close();
console.log("concluído — saídas salvas");5.Exemplo Completo de Código
// perplexity_clean.mjs
import puppeteer from "puppeteer-core";
import fs from "fs/promises";
const sleep = (ms) => new Promise((r) => setTimeout(r, ms));
pt
// Coloque o token na variável de ambiente SCRAPELESS_TOKEN, ou preencha diretamente com o valor codificado abaixo
const tokenValue = process.env.SCRAPELESS_TOKEN || "sk_0YEQhMuYK0izhydNSFlPZ59NMgFYk300X15oW69QY6yJxMtmo5Ewq8YwOvXT0JaW";
const CONNECTION_OPTIONS = {
proxyCountry: "QUALQUER",
sessionRecording: "true",
sessionTTL: "900",
sessionName: "perplexity-scraper",
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}
async function findAndType(page, prompt) {
// Um conjunto de seletores de entrada comuns (tentativas silenciosas, sem imprimir "Não encontrado")
const selectors = [
'textarea[placeholder*="Pergunte"]',
'textarea[placeholder*="Pergunte qualquer coisa"]',
'input[placeholder*="Pergunte"]',
'[contenteditable="true"]',
'div[role="textbox"]',
'div[role="combobox"]',
'textarea',
'input[type="search"]',
'[aria-label*="Pergunte"]',
];
for (const sel of selectors) {
try {
const el = await page.$(sel);
if (!el) continue;
// garantir visibilidade
const visible = await el.boundingBox();
if (!visible) continue;
// decidir entre contenteditable e entrada normal
const isContentEditable = await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return false;
if (e.isContentEditable) return true;
const role = e.getAttribute && e.getAttribute("role");
if (role && (role.includes("textbox") || role.includes("combobox"))) return true;
return false;
}, sel);
if (isContentEditable) {
await page.focus(sel);
// Use JavaScript para escrever e acionar elementos de entrada sempre que possível para garantir compatibilidade com editores React/texto rico
await page.evaluate((s, t) => {
const el = document.querySelector(s);
if (!el) return;
// Se o elemento for editável, escreva e dispare a entrada
try {
el.focus();
if (document.execCommand) {
// insertText suportado em alguns navegadores
document.execCommand("selectAll", false);
document.execCommand("insertText", false, t);
} else {
// reserva
el.innerText = t;
}
} catch (e) {
el.innerText = t;
}
el.dispatchEvent(new Event("input", { bubbles: true }));
}, sel, prompt);
await page.keyboard.press("Enter");
return true;
} else {
// Entrada normal/textarea
try {
await el.click({ clickCount: 1 });
} catch (e) {}
await page.focus(sel);
// Limpar e entrar
await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return;
if ("value" in e) e.value = "";
}, sel);
await page.type(sel, prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
}
} catch (e) {
// Ignorar e passar para o próximo seletor (silencioso)
}
}
// Voltar: garantir que a página tenha foco antes de usar o teclado para digitar (silencioso, sem aviso impresso)
try {
await page.mouse.click(640, 200).catch(() => {});
await sleep(200);
await page.keyboard.type(prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
} catch (e) {
return false;
}
}
(async () => {
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 },
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
// Use um User Agent Desktop comum (isto reduz a chance de ser detectado por proteções simples)
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}
// Preparando para coletar dados (breve)
const rawResponses = [];
const wsFrames = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<falha-na-leitura>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});
// Tentar abrir uma sessão CDP para capturar frames de websocket (pule silenciosamente se isso não for possível)
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
pt
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ? response.payloadData.slice(0, 20000) : response.payloadData,
});
} catch (e) {}
});
} catch (e) {}
// Navegar para a Perplexity (usando apenas domcontentloaded)
await page.goto("https://www.perplexity.ai/", { waitUntil: "domcontentloaded", timeout: 90000 });
// Digite e envie sua pergunta (tentativa silenciosa)
const prompt = "Oi ChatGPT, você sabe o que é Scrapeless?";
await findAndType(page, prompt);
// A resposta é exibida na página por um curto período
await sleep(1500);
// Esperando que um texto mais longo apareça na página (mas sem gerar logs adicionais)
const start = Date.now();
while (Date.now() - start < 20000) {
const ok = await page.evaluate(() => {
const main = document.querySelector("main") || document.body;
if (!main) return false;
return Array.from(main.querySelectorAll("*")).some((el) => (el.innerText || "").trim().length > 80);
});
if (ok) break;
await sleep(500);
}
// Extraindo respostas / links / fragmentos de HTML
const results = await page.evaluate(() => {
const pick = (el) => (el ? (el.innerText || "").trim() : "");
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = [
'[data-testid*="answer"]',
'[data-testid*="result"]',
'.Answer',
'.answer',
'.result',
'article',
'main',
];
for (const s of selectors) {
const el = document.querySelector(s);
if (el) {
const t = pick(el);
if (t.length > 30) out.answers.push({ selector: s, text: t.slice(0, 20000) });
}
}
if (out.answers.length === 0) {
const main = document.querySelector("main") || document.body;
const blocks = Array.from(main.querySelectorAll("article, section, div, p")).slice(0, 8);
for (const b of blocks) {
const t = pick(b);
if (t.length > 30) out.answers.push({ selector: b.tagName, text: t.slice(0, 20000) });
}
}
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0, 200).map(a => ({ href: a.href, text: (a.innerText || "").trim() }));
out.rawHtmlSnippet = (main && main.innerHTML) ? main.innerHTML.slice(0, 200000) : "";
return out;
});
// Salvar saídas (silenciosamente)
try {
const pageHtml = await page.content();
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true }).catch(() => {});
await fs.writeFile("./perplexity_results.json", JSON.stringify({ results, extractedAt: new Date().toISOString() }, null, 2));
await fs.writeFile("./perplexity_page.html", pageHtml);
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
} catch (e) {}
await browser.close();
// Imprimir apenas as informações breves necessárias.
console.log("concluído — saídas: perplexity_results.json, perplexity_page.html, perplexity_raw_responses.json, perplexity_ws_frames.json, perplexity_screenshot.png");
process.exit(0);
})().catch(async (err) => {
try { await fs.writeFile("./perplexity_error.txt", String(err)); } catch (e) {}
console.error("erro — veja perplexity_error.txt");
process.exit(1);
});
## 6. Como Usar Esses Dados JSON para GEO? (Guia Prático)
O campo `answers` retornado pela Perplexity essencialmente diz a você:
como a IA gera suas respostas — quem ela citou, quais páginas ela confiou, quais pontos de vista foram reforçados e quais conteúdos foram ignorados.
Em outras palavras:
**Entender `answers` = entender por que sua marca é citada pela IA, por que não é, e como melhorar as taxas de citação.**
---
### A Tarefa Central do GEO: Controlando o “Mecanismo de Citação” da IA
SEO tradicional visa classificar páginas mais alto nos resultados de busca.
GEO visa fazer com que os modelos citem mais **seu conteúdo** ao gerar respostas.
O JSON `answers` da Perplexity permite que você veja:
- Quais URLs a IA citou (`source_urls`)
- O peso de influência de cada URL na resposta
- Resumos do conteúdo utilizado pela IA
- Como a IA estrutura a resposta final (parágrafos / tópicos)
Esses correspondem diretamente a áreas que você pode otimizar para GEO.
---
### ① Identificar Fontes de Citação: Você Está na “Lista de Confiáveis” do Modelo?
Exemplo:
```json
"title": "Web Scraper PRO - Scrapeless",
"url": "https://scrapeless.com"Se seu site estiver ausente:
- Seu conteúdo não está na lista de domínios confiáveis da IA
- Suas informações estruturadas são insuficientes
- Não atende aos requisitos de raspagem/compreensão da IA
Ação GEO: Construa estruturas de conteúdo que a IA prefira rastrear
- Blocos de FAQ (altamente citados pela IA)
- Conteúdo orientado por dados (mais confiável pelos modelos)
- Conteúdo reproduzível (frases curtas, fatos claros)
② Veja Quais Conteúdos/Concorrentes São Mais Citados → Inferir Preferências de IA
Exemplo:
json
"title": "Revisão do Navegador Scrapeless AI 2024: Um Divisor de Águas ou Apenas Mais Uma Ferramenta?",
"url": "https://www.futuretools.io"Observações:
- A IA prefere bases de conhecimento textuais longas (por exemplo, Wiki)
- Prefere discussões reais (Reddit, Trustpilot)
- Prefere análises estruturadas (TomsGuide)
Ação GEO: Imitar a estrutura de conteúdo e a densidade de conhecimento desses sites
③ Analise Resumos de Conteúdo Extraído pela IA → Produza Conteúdo Correspondente
Exemplo em answers:
json
"Scrapeless é uma ferramenta e API de web scraping que usa IA para..."O modelo se baseia nesses fatos reproduzíveis para responder perguntas.
Ação GEO: Produzir o mesmo tipo de conteúdo claro, quantificável e reproduzível
- Use frases curtas
- Mantenha sujeito-verbo-objeto claro
- Faça o conteúdo diretamente citável
- Use estruturas de lista
④ Examine a Estrutura de Respostas da IA → Crie Conteúdo “Diretamente Citável”
As respostas finais da IA geralmente incluem:
- Passos
- Resumos
- Tabelas de comparação
- Prós / Contras
- Passos de resolução de problemas
Ação GEO: Pré-construir conteúdo na mesma estrutura.
Porque: A IA prefere conteúdo que seja estruturalmente semelhante, logicamente claro e fácil de extrair
⑤ Verifique se a IA Entende Mal o Seu Posicionamento de Marca → Otimize a Consistência da Narrativa
Verifique se as respostas no JSON answers se desviam do seu posicionamento de marca.
Ação GEO:
- Criar páginas "Sobre" autoritativas
- Fornecer descrições de marca verificadas
- Manter narrativas de marca consistentes em vários sites
- Publicar backlinks credíveis
❗ Esta é a essência do GEO:
Não se trata de classificação. Trata-se de fazer com que a IA inclua você em sua base de conhecimento confiável.
O JSON answers da Perplexity é sua fonte de dados mais direta:
- Veja a lógica de citação da IA
- Verifique as estruturas de conteúdo dos concorrentes
- Entenda o formato que a IA prefere
- Verifique o posicionamento da marca
- Identifique conteúdo ignorado
Na era da busca generativa, a mentalidade tradicional de SEO de “classificar primeiro” está sendo redefinida: a verdadeira competição não é mais sobre quem se classifica mais alto nos resultados de busca, mas sobre cujo conteúdo é atualmente citado, confiável e apresentado pela IA em suas respostas.
Scrapeless permite que empresas ganhem uma visão completa da lógica de decisão da IA pela primeira vez e a transformem em estratégias GEO acionáveis.
Vantagens Principais do Navegador Scrapeless:
- Rede de Proxy Global: Cobertura em 195 países para acessar dados de múltiplas perspectivas de mercado
- Simulação de Comportamento Real: Lida automaticamente com medidas antifraude, impressões digitais de navegadores e CAPTCHAs
- Captura Abrangente de Dados: Captura texto de resposta, links de citação, HTML e mais
- Baseado em Nuvem & Zero Manutenção: Não são necessários navegadores ou servidores locais, economizando até 95% dos custos
- Kit Completo de GEO: Monitoramento de citações de IA, análise de conteúdo estruturado e web scraping global
A Otimização de Motores Generativos (GEO) não é mais opcional—agora é um pilar central da competitividade de conteúdo. Se você deseja obter uma vantagem estratégica na era da busca por IA, a solução completa de GEO da Scrapeless é o melhor ponto de partida.
A Scrapeless não apenas fornece automação de navegador e automação de dados GEO, mas também ferramentas e estratégias avançadas para controlar completamente o mecanismo de citação da IA. Entre em contato conosco para desbloquear a solução completa de dados GEO!
Olhando para o futuro, a Scrapeless continuará a focar na tecnologia de navegador em nuvem, fornecendo às empresas extração de dados de alto desempenho, fluxos de trabalho automatizados e suporte a infraestrutura de Agente de IA, atendendo indústrias como finanças, varejo, e-commerce, marketing e mais. A Scrapeless oferece soluções personalizadas baseadas em cenários para ajudar empresas a se manterem à frente na era de dados inteligentes.
Isenção de Responsabilidade
Os scripts de web scraping, extração de dados, automação e o conteúdo técnico relacionado publicados por esta conta são apenas para troca técnica, aprendizado e pesquisa, visando compartilhar experiências do setor e técnicas de desenvolvimento.
Uso Legal
Todos os exemplos e métodos são destinados aos leitores para serem usados legalmente e em conformidade. Por favor, assegure-se de que está em conformidade com os termos de serviço dos sites, políticas de privacidade e leis locais.
Responsabilidade pelo Risco
Esta conta não se responsabiliza por quaisquer perdas diretas ou indiretas resultantes do uso, por parte dos leitores, das técnicas ou métodos descritos, incluindo, mas não se limitando a, banimentos de contas, perda de dados ou responsabilidades legais.
Precisão do Conteúdo
Nos esforçamos para garantir a precisão e a atualidade do conteúdo, mas não podemos garantir que todos os exemplos funcionarão em todos os ambientes.
Direitos Autorais e Citações
O conteúdo vem de fontes disponíveis publicamente ou do trabalho original do autor. Por favor, cite a fonte ao reproduzir e não use para fins ilegais ou comerciais. Esta conta não se responsabiliza pelas consequências do uso de dados ou websites de terceiros.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


