
O Node Unblocker é suficiente para contornar os desafios de web scraping?
Expert Network Defense Engineer
Os desbloqueadores de nós podem ser personalizados para incluir recursos como rotação de IP, personalização de cabeçalhos e criptografia. Portanto, estamos acostumados a construir desbloqueadores de nós para contornar o bloqueio de sites.
Um desbloqueador de nós se destaca em contornar os desafios dos sites, mas na prática descobrimos que ainda precisamos lidar com alguns de seus problemas inerentes.
Como tornar seu desbloqueador de nós mais poderoso? Existe um método ou ferramenta que possa superar completamente os desafios do site diretamente?
É hora de encontrar a melhor resposta neste artigo!
O que é um desbloqueador de nós?
O desbloqueador de nós é uma ferramenta de proxy da web construída com Node.js que ajuda a contornar restrições de rede ou limitações de acesso a sites. Ele atua como um intermediário entre o usuário e o site de destino, permitindo que o usuário interaja com conteúdo que pode estar bloqueado devido a restrições geográficas, filtros de rede ou firewalls.
Os desbloqueadores fazem isso roteando a solicitação do usuário para um servidor Node.js, que busca o conteúdo desejado e o retorna ao usuário. Geralmente suporta o tratamento de conteúdo dinâmico, tornando-o adequado para aplicativos web modernos.
Como usar o desbloqueador de nós?
Primeiro, criaremos um serviço Node.js básico. Em seguida, discutiremos como usar o desbloqueador de nós para criar middleware, permitindo sua integração em nosso serviço Node. Para obter detalhes adicionais, você pode visitar a documentação do Desbloqueador de nós diretamente.
Pré-requisitos
Antes de começar, você precisa ter o Node.js instalado. Você pode baixar o Node.js aqui.
Agora vamos começar criando um serviço Node.js básico.
- Inicialize um novo projeto Node.js. Se você ainda não possui um projeto, crie um usando os seguintes comandos:
Bash
mkdir node-unblocker-tutorial- Navegue até o diretório do projeto, inicialize o projeto e instale as dependências necessárias:
Bash
cd node-unblocker-tutorial
npm init -y
pnpm add express unblocker- Agora, crie um novo arquivo, index.js, para organizar seu código:
Bash
touch index.jsConfigurando o serviço Node.js básico
- Importe os módulos necessários,
expresseunblocker:
JavaScript
import express from 'express';
import unblocker from 'unblocker';- Em seguida, crie um aplicativo Express:
JavaScript
const app = express();- Inicialize uma instância de Unblocker e defina seu prefixo de proxy:
JavaScript
const unblocker = new Unblocker({
prefix: '/proxy/'
});Certifique-se de integrar a instância do Unblocker ao aplicativo Express usando o método app.use():
JavaScript
app.use(unblocker());- Defina uma porta e inicie o serviço Node.js usando o método
app.listen():
JavaScript
const PORT = process.env.PORT || 9090;
app.listen(PORT, () => {
console.log(`Servidor iniciado na porta ${PORT}`);
});- Aqui está o código completo para a configuração:
JavaScript
import express from 'express';
import Unblocker from 'unblocker';
const app = express();
const unblocker = new Unblocker({ prefix: '/proxy/' });
app.use(unblocker);
const PORT = process.env.PORT || 9090;
app
.listen(PORT, () => {
console.log(`Servidor iniciado na porta ${PORT}`);
})
.on('upgrade', unblocker.onUpgrade);Executando o serviço
Execute o arquivo index.js usando o Node para iniciar o servidor na porta 9090. Teste o proxy anexando a URL de destino ao prefixo do proxy. Para este exemplo, usaremos https://ident.me/ como a página de destino. Abra o seguinte link em seu navegador após executar o serviço:
node index.js
Você verá uma página exibindo o endereço IP do serviço atual, indicando que a configuração está funcionando corretamente:

5 Limitações do desbloqueador de nós
- Gargalos de desempenho
Como o desbloqueador de nós processa solicitações e respostas da web em tempo real, ele pode se tornar um gargalo de desempenho ao lidar com um grande número de solicitações simultâneas ou tráfego intenso.
- Consumo de recursos
O desbloqueador de nós requer recursos do servidor para lidar com solicitações, especialmente ao lidar com arquivos grandes, conteúdo multimídia ou páginas da web altamente dinâmicas. Isso pode levar ao aumento do uso de CPU e memória.
- Capacidades limitadas de bypass
Embora o desbloqueador de nós possa contornar algumas restrições básicas, ele tem dificuldades com sistemas avançados anti-bot, como CAPTCHA, impressão digital de JavaScript ou mecanismos de limitação de taxa baseados em IP.
- Desafios de escalabilidade
O desbloqueador de nós não é inerentemente construído para configurações distribuídas ou alta escalabilidade, o que o torna menos adequado para aplicativos de nível empresarial ou em grande escala sem personalização significativa.
- Falta de inspeção HTTPS
O desbloqueador de nós não descriptografa ou inspeciona o tráfego HTTPS, o que limita sua capacidade de modificar ou analisar dados criptografados durante o processo de proxy.
Quais são algumas das melhores práticas para usar o desbloqueador de nós?
1. Girar cabeçalhos de agente do usuário
Para fazer com que suas atividades de raspagem da web pareçam originárias de usuários diferentes, é essencial girar os cabeçalhos do User-Agent. Essa prática reduz significativamente a probabilidade de um site detectar suas solicitações como automatizadas.
2. Implementar rotação de IP
Contar com um único IP de proxy é quase tão arriscado quanto acessar um site diretamente, pois aumenta as chances de seu IP ser sinalizado ou bloqueado. Implementar a rotação de IP ajuda você a evitar a detecção e garante acesso contínuo para coletar os dados da web necessários.
3. Limitar a frequência das solicitações
A limitação de taxa é uma medida vital para evitar que seu IP seja sinalizado. Enviar rapidamente várias solicitações do mesmo IP em um curto período de tempo pode acionar as proteções anti-bot de um site, potencialmente levando a uma proibição. Ao incorporar atrasos em seu código de raspagem, você pode minimizar esses riscos e manter operações suaves.
4. Tratamento de erros
O tratamento eficaz de erros é crucial para uma raspagem de web bem-sucedida. Incorpore mecanismos em seu código para lidar com cenários em que o site de destino não retorna a resposta esperada, garantindo que seu processo de raspagem permaneça robusto e eficiente.
Integrando o Scrapeless Web Unlocker para recursos avançados
Por que o Scrapeless é eficaz na prevenção de bloqueios?
O Scrapeless Web Unlocker utiliza uma rede global que abrange 195 países, com acesso a mais de 70 milhões de IPs residenciais. Com uma disponibilidade de 99,9% e taxas de sucesso excepcionais, o Scrapeless supera facilmente desafios como bloqueios de IP e CAPTCHA, tornando-se uma solução robusta para automação web complexa e coleta de dados impulsionada por IA.
O Scrapeless é caro?
O Scrapeless oferece uma plataforma de raspagem da web confiável e escalável a preços competitivos, garantindo excelente valor para seus usuários:
- Navegador de raspagem: A partir de US$ 0,09 por hora
- API de raspagem: A partir de US$ 1,00 por 1k de URLs
- Desbloqueio da Web: US$ 0,20 por 1k de URLs
- Resolutor de CAPTCHA: A partir de US$ 0,80 por 1k de URLs
- Proxies: US$ 2,80 por GB
Ao assinar, você pode desfrutar de descontos de até 20% em cada serviço. Você tem requisitos específicos? Entre em contato conosco hoje e forneceremos ainda mais economia adaptada às suas necessidades!
Etapas detalhadas para integrar o Scrapeless ao seu projeto
Pré-requisitos
Antes de começar, você precisa registrar uma conta Scrapeless. Você também pode navegar no site oficial para saber mais sobre o Scrapeless.
Depois de registrado, navegue até o painel do Scrapeless e clique no menu Desbloqueio da Web no painel esquerdo. Aqui, você encontrará uma variedade de opções de configuração, incluindo Proxy, Renderização JS, Método de solicitação e Instruções JS. Esses recursos abordam várias limitações do desbloqueador de nós e você pode personalizá-los de acordo com suas necessidades.
Se você não está familiarizado com essas opções de configuração, pode consulte a documentação detalhada clicando no link "Documentação" na página.
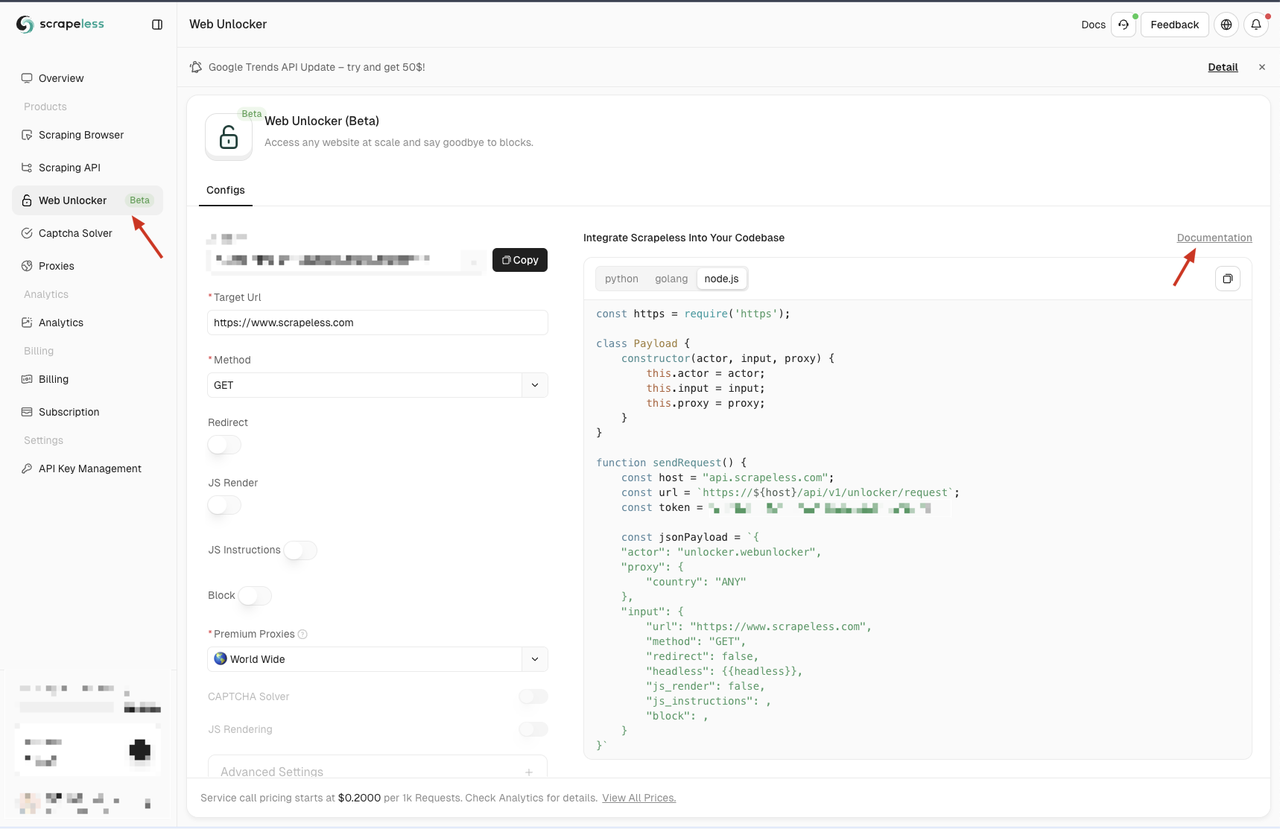
O Scrapeless também fornece exemplos de código em três linguagens de programação: Python, Node.js e Golang. Você pode escolher a linguagem que melhor se adapta às suas necessidades de integração. Neste exemplo, usaremos Node.js.
Contornar CAPTCHAs
O Scrapeless Web Unlocker habilita automaticamente a funcionalidade de bypass de CAPTCHA, eliminando preocupações com desafios de CAPTCHA. Para verificar isso, primeiro, use o Curl para fazer uma solicitação a um site que requer verificação, como:
Bash
curl https://app.ahrefs.com/user/loginNa captura de tela abaixo, a solicitação Curl retorna uma página de verificação de CAPTCHA. Você pode ver os detalhes de verificação do Cloudflare na resposta:
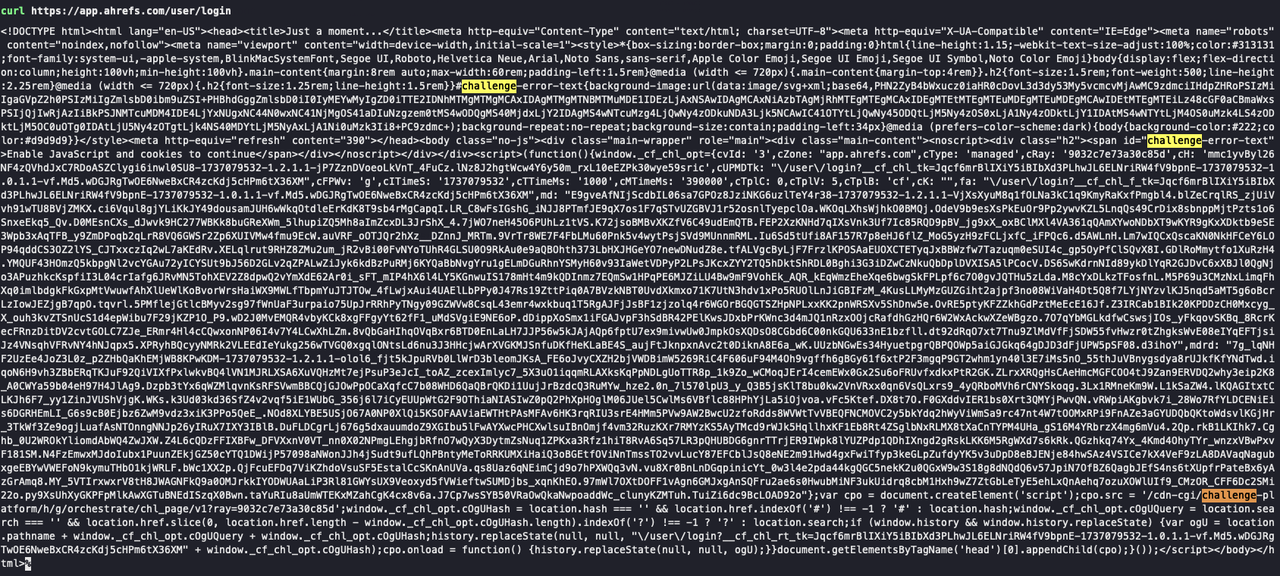
Agora, usando o Scrapeless Web Unlocker para solicitar o mesmo site, siga estas etapas:
- Crie um arquivo scrapeless-web-unlocker.js com o seguinte código:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // seu token
const inputData = {
url: 'https://app.ahrefs.com/user/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`Erro HTTP! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Erro:', error);
}
}
sendRequest();- Executando o código com
node scrapeless-web-unlocker.js.
Podemos ver que a verificação de CAPTCHAs foi contornada com sucesso nos resultados retornados e o conteúdo DOM da página foi obtido. Além disso, o título "Login do usuário - Ahrefs" no código da página também pode ser recuperado com sucesso em nossos resultados.
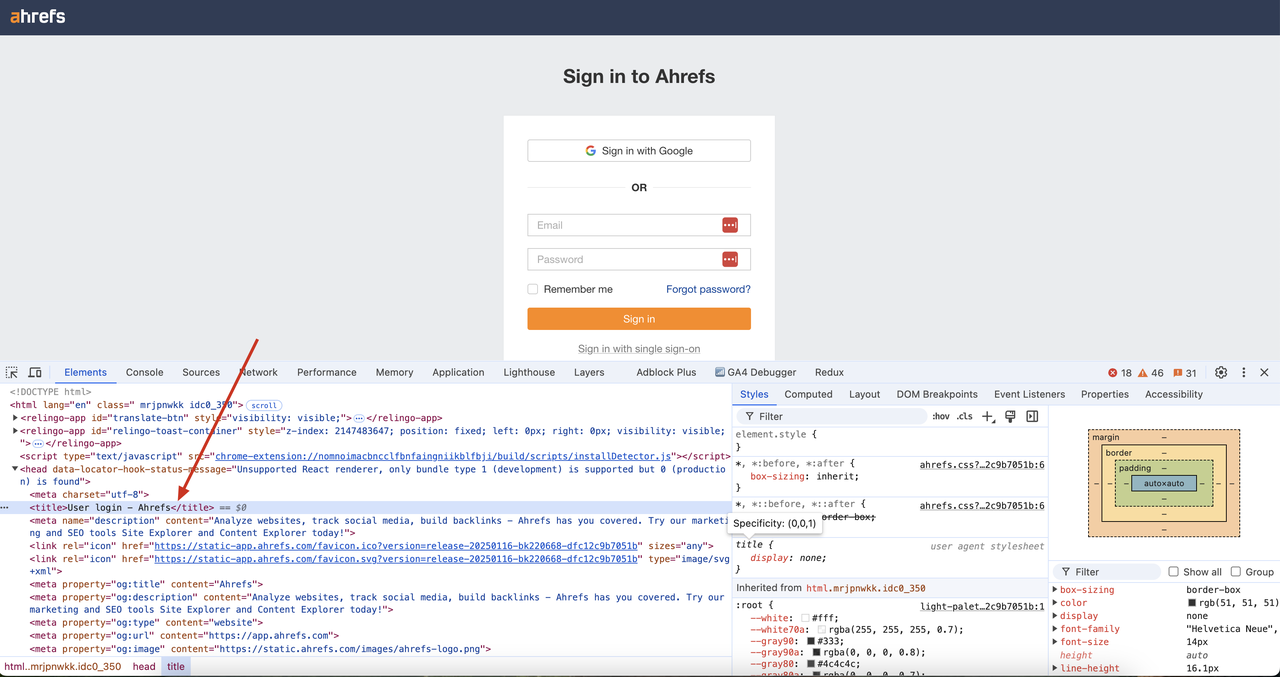

Renderização Javascript
A renderização de JavaScript pode lidar com conteúdo carregado dinamicamente e aplicativos de página única (SPA). Ele habilita um ambiente de navegador completo e suporta interações e requisitos de renderização de página mais complexos. O serviço Web Unlocker do Scrapeless pode resolver o problema de o desbloqueador de nós não conseguir executar JavaScript. Podemos habilitar a função de renderização de JavaScript no Web Unlocker do Scrapeless para que possamos obter o conteúdo da página renderizado pelo JavaScript.
Podemos encontrar um site que usa renderização de JavaScript, como a página de login do painel do Cloudflare. Podemos ver que a tecnologia de framework que ele usa é React.js, e React.js é um framework de aplicativo de página única, e seu conteúdo é renderizado por JavaScript.
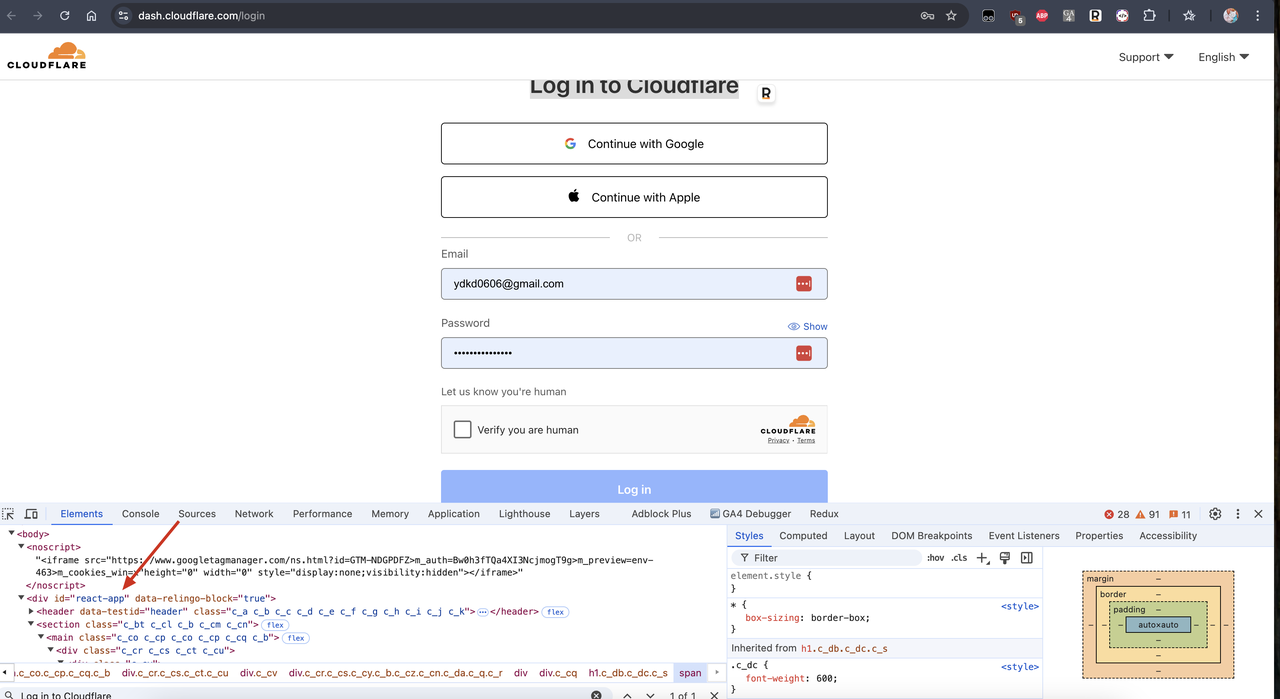
Agora, vamos modificar o código anterior ligeiramente para ver se podemos obter o conteúdo da página de login do painel do Cloudflare sem habilitar a renderização de JavaScript. Modifique o código da seguinte maneira:
JavaScript
...
url: 'https://dash.cloudflare.com/login',
...Podemos ver que o div com id="react-app" no resultado retornado está vazio, o que significa que não obtivemos o conteúdo da página após a renderização do JavaScript:
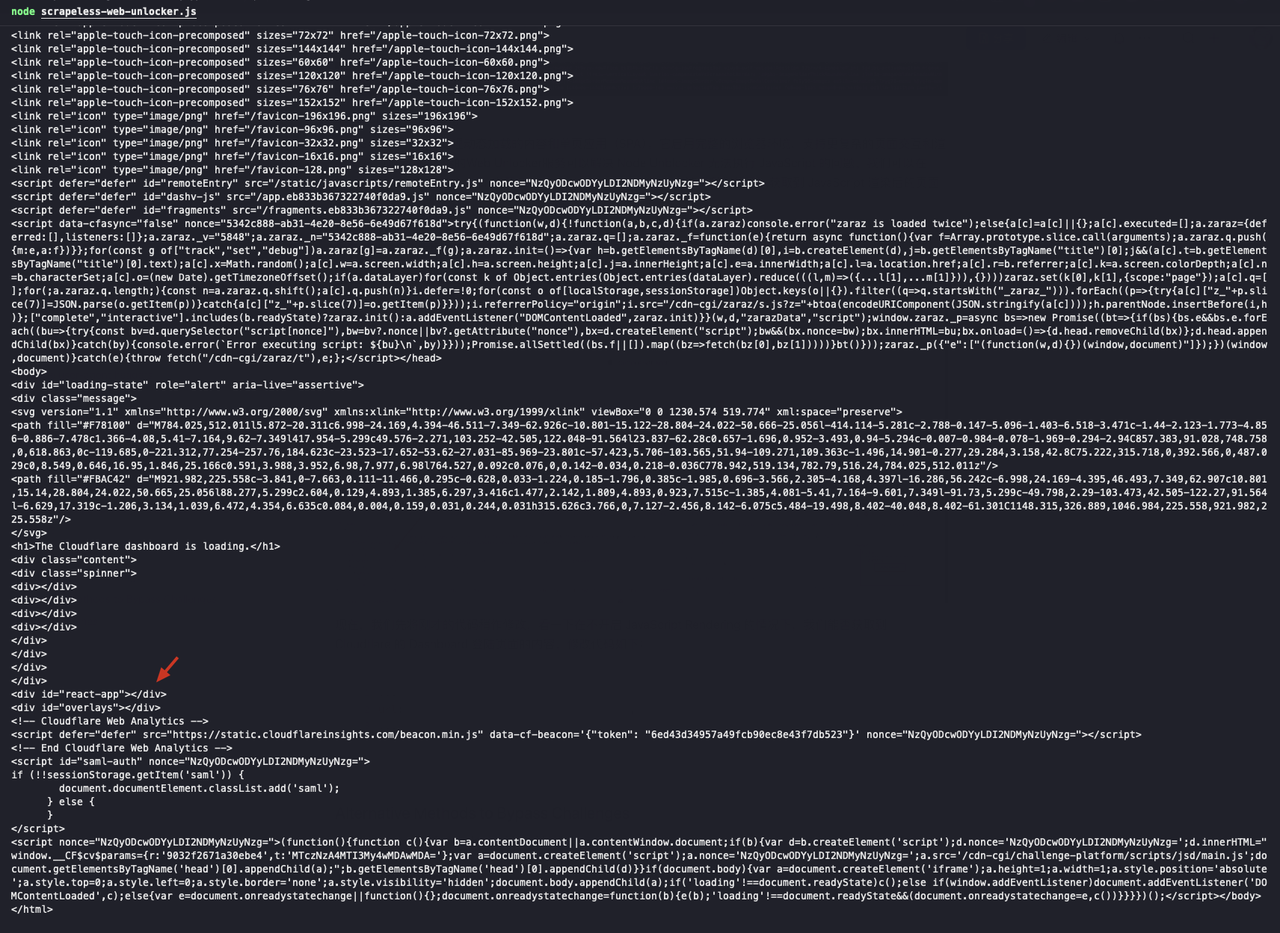
Em seguida, ativamos a função de renderização de JavaScript e modificamos o código da seguinte maneira:
JavaScript
const inputData = {
url: 'https://dash.cloudflare.com/login',
method: 'GET',
redirect: false,
js_render: true, // nova opção
js_instructions: [ // nova opção
{
wait: 20000,
},
],
};No código acima, adicionamos duas novas opções de configuração, js_render e js_instructions. Para mais referências de instruções, consulte Documentação do Scrapeless:
js_renderé usado para ativar a função de renderização de JavaScriptjs_instructionsé usado para definir as instruções para a renderização de JavaScript. Aqui, definimos uma instrução de espera de 20 segundos para retornar o resultado após o carregamento da página.
Observação: Agora, muitos sites possuem um processo de carregamento por padrão, portanto, precisamos esperar um pouco para garantir que a página seja carregada antes de retornar o resultado
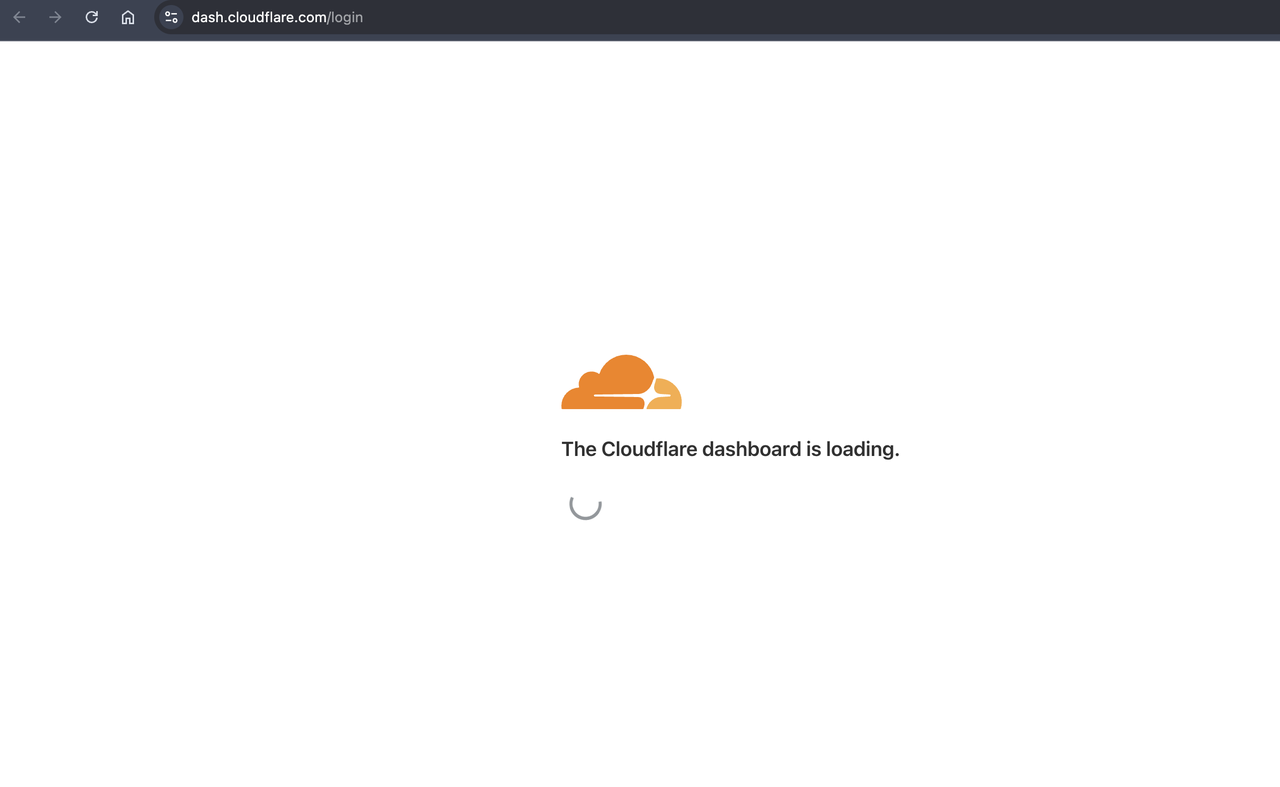
Agora, executamos o código novamente e podemos ver que o conteúdo da página de login do painel do Cloudflare foi obtido com sucesso no resultado retornado. Ao recuperar o texto de "Entrar no Cloudflare", podemos ver que obtivemos com sucesso o conteúdo da página renderizado pelo JavaScript.
Bash
node scrapeless-web-unlocker.js
Conclusões
Os desafios crescentes de acesso ao conteúdo da web exigem novas soluções. Neste artigo, analisamos o desbloqueador de nós, uma biblioteca NodeJS que fornece um proxy da web que processa dados e os encaminha para o cliente.
No entanto, suas limitações impedem que seja uma solução de raspagem da web rentável. Portanto, era necessária uma solução mais eficiente e barata. Como todos concordam - o Scrapeless é o claro vencedor com serviços superiores e preços mais baixos.
Você pode se inscrever agora para obter seu Desbloqueio da Web gratuito!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


