
Como fazer requisições HTTP em Node.js com a API Node-Fetch?
Specialist in Anti-Bot Strategies
Nossos websites atuais geralmente dependem de dezenas de recursos diferentes, como uma coleção monolítica de imagens, CSS, fontes, JavaScript, dados JSON, etc. No entanto, o primeiro website do mundo foi escrito apenas em HTML.
JavaScript, como uma excelente linguagem de script do lado do cliente, desempenhou um papel importante na evolução dos websites. Com a ajuda de objetos XMLHttpRequest ou XHR, JavaScript pode alcançar comunicação entre clientes e servidores sem recarregar a página.
No entanto, este processo dinâmico é desafiado pela Fetch API. O que é a Fetch API? Como usar a Fetch API em Node.js? Por que a Fetch API é uma escolha melhor?
Comece a obter respostas a partir deste artigo agora!
O que são Requisições HTTP em Node.js?
Em Node.js, as requisições HTTP são uma parte fundamental da construção de aplicativos web ou da interação com serviços web. Elas permitem que um cliente (como um navegador ou outro aplicativo) envie dados para um servidor ou solicite dados de um servidor. Essas requisições usam o Protocolo de Transferência de Hipertexto (HTTP), que é a base da comunicação de dados na web.
- Requisição HTTP: Uma requisição HTTP é enviada por um cliente para um servidor, normalmente para recuperar dados (como uma página web ou resposta da API) ou para enviar dados para o servidor (como enviar um formulário).
- Métodos HTTP: As requisições HTTP geralmente incluem um método, que indica qual ação o cliente deseja que o servidor tome. Os métodos HTTP comuns incluem:
- GET: Solicitar dados do servidor.
- POST: Enviar dados para o servidor (por exemplo, enviar um formulário).
- PUT: Atualizar dados existentes no servidor.
- DELETE: Remover dados do servidor.
- Módulo HTTP do Node.js: O Node.js fornece um módulo http integrado para lidar com requisições HTTP. Este módulo permite que você crie um servidor HTTP, ouça requisições e responda a elas.
Por que o Node.js é ideal para web scraping e automação?
O Node.js tornou-se uma das tecnologias preferidas para tarefas de web scraping e automação devido às suas características únicas, ecossistema robusto e arquitetura assíncrona e não bloqueante.
Por que o Node.js é ideal para web scraping e automação? Vamos descobrir!
- I/O assíncrono e não bloqueante
- Velocidade e eficiência
- Rico ecossistema de bibliotecas e frameworks
- Tratamento de conteúdo dinâmico com navegadores headless
- Compatibilidade multiplataforma
- Processamento de dados em tempo real
- Sintaxe simples para desenvolvimento rápido
- Suporte para rotação de proxy e antidetecção
O que é a API Node-Fetch?
Node-fetch é um módulo leve que traz a Fetch API para o ambiente Node.js. Ele simplifica o processo de fazer requisições HTTP e lidar com respostas.
A Fetch API é construída em torno de Promises e é adequada para operações assíncronas, como raspar dados de um website, interagir com uma API RESTful ou automatizar tarefas.
Como usar a Fetch API em Node.JS?
A Fetch API é uma interface moderna baseada em Promises, projetada para lidar com solicitações de rede de maneira mais eficiente e flexível em comparação com o objeto XMLHttpRequest tradicional.
Ela é suportada nativamente em navegadores contemporâneos, o que significa que não há necessidade de bibliotecas ou plug-ins adicionais. Neste guia, exploraremos como utilizar a Fetch API para executar solicitações GET e POST, bem como como gerenciar respostas e erros de forma eficaz.
💬 Nota: Se o Node.js não estiver instalado em seu computador, você precisa instalá-lo primeiro. Você pode baixar o pacote de instalação do Node.js adequado para seu sistema operacional aqui. A versão recomendada do Node.js é 18 e superior.
Passo 1. Inicialize seu projeto Node.js
Se você ainda não criou um projeto, pode criar um novo projeto com o seguinte comando:
Bash
mkdir fetch-api-tutorial
cd fetch-api-tutorial
npm init -yAbra o arquivo package.json, adicione o campo type e defina-o como module:
JSON
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}Passo 2. Baixe e instale a biblioteca node-fetch
Esta é uma biblioteca para usar a Fetch API em Node.js. Você pode instalar a biblioteca node-fetch com o seguinte comando:
Bash
npm install node-fetchApós o download ser concluído, podemos começar a usar a Fetch API para enviar solicitações de rede. Crie um novo arquivo index.js no diretório raiz do projeto e adicione o seguinte código:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));Execute o seguinte comando para executar o código:
Bash
node index.jsVeremos a seguinte saída:
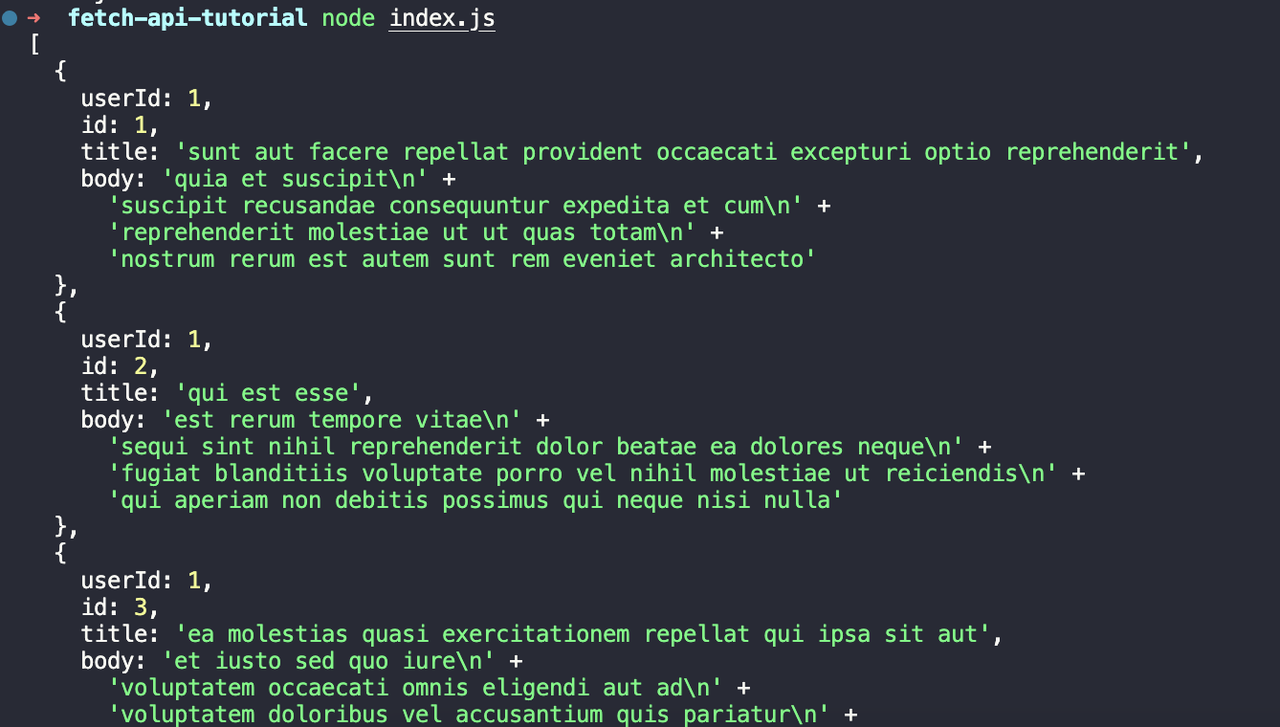
Passo 3. Use a Fetch API para enviar uma solicitação POST
Como usar a Fetch API para enviar a solicitação POST? Consulte o seguinte método. Crie um novo arquivo post.js no diretório raiz do projeto e adicione o seguinte código:
JavaScript
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));Vamos analisar este código:
- Primeiro, definimos um objeto chamado
postData, que contém os dados que queremos enviar. - Então usamos a função
fetchpara enviar uma solicitação POST parahttps://jsonplaceholder.typicode.com/posts, passando um objeto de configuração como segundo parâmetro. - O objeto de configuração contém o
methodda solicitação, osheadersda solicitação e obodyda solicitação.
Execute o seguinte comando para executar o código:
Bash
node post.jsA saída que você pode ver:

Passo 4. Lidando com os resultados e erros da resposta da Fetch API
Precisamos criar um novo arquivo response.js no diretório raiz do projeto e adicionar o seguinte código:
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts-response')
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error(error));No código acima, primeiro preenchemos um endereço de URL incorreto para disparar um erro HTTP. Em seguida, verificamos o código de status da resposta resultante no método then e lançamos um erro se o código de status não for 200. Finalmente, capturamos o erro no método catch e o imprimimos.
Execute o seguinte comando para executar o código:
Bash
node response.jsDepois que o código for executado, você verá a seguinte saída:

3 Desafios Comuns em Web Scraping
1. CAPTCHAs
CAPTCHAs (Completely Automated Public Turing tests to tell Computers and Humans Apart) são projetados para impedir que sistemas automatizados, como web scrapers, acessem websites. Eles geralmente exigem que os usuários provem que são humanos resolvendo quebra-cabeças, identificando objetos em imagens ou inserindo caracteres distorcidos.
2. Conteúdo dinâmico
Muitos websites modernos usam frameworks JavaScript como React, Angular ou Vue.js para carregar conteúdo dinamicamente. Isso significa que o conteúdo que você vê no navegador geralmente é renderizado após o carregamento da página, tornando difícil raspar com métodos tradicionais que dependem de HTML estático.
3. Banimentos de IP
Os websites geralmente implementam medidas para detectar e bloquear atividades de scraping, sendo um dos métodos mais comuns o bloqueio de IP. Isso ocorre quando muitas solicitações são enviadas do mesmo endereço IP em um curto período, fazendo com que o website marque e bloqueie esse IP.
Kit de Ferramentas de Scraping Scrapeless - Ferramenta de Scraping Eficiente
Scrapeless é uma das melhores ferramentas de scraping abrangentes devido à sua capacidade de contornar bloqueios de websites em tempo real, incluindo bloqueio de IP, desafios de CAPTCHA e renderização de JavaScript. Ele suporta recursos avançados como rotação de IP, gerenciamento de impressão digital TLS e solução de CAPTCHA, tornando-o ideal para web scraping em larga escala.
Como Scrapeless aprimora projetos de web scraping Node.js?
Sua fácil integração com o Node.js e alta taxa de sucesso para evitar detecção tornam o Scrapeless uma escolha confiável e eficiente para contornar as defesas anti-bot modernas, garantindo operações de scraping suaves e ininterruptas.
Vantagens de usar um kit de ferramentas de scraping como Scrapeless em vez de scraping manual
- Tratamento eficiente de bloqueios de websites: Scrapeless pode contornar defesas anti-scraping comuns como bloqueios de IP, CAPTCHAs e renderização de JavaScript em tempo real, o que o scraping manual não consegue lidar eficientemente.
- Confiabilidade e taxa de sucesso: Scrapeless usa recursos avançados como rotação de IP e gerenciamento de impressão digital TLS para evitar detecção, garantindo uma taxa de sucesso maior e scraping ininterrupto em comparação com o scraping manual.
- Integração e automação fáceis: Integra-se perfeitamente com Node.js e automatiza todo o fluxo de trabalho de scraping, o que economiza tempo e reduz erros humanos em comparação com a coleta manual de dados.
Basta seguir algumas etapas fáceis, você pode integrar o Scrapeless ao seu projeto Node.js.
É hora de continuar rolando! O que vem a seguir será ainda melhor!
Integrando o Kit de Ferramentas de Scraping Scrapeless ao seu Projeto Node.js
Antes de começar, você precisa registrar uma conta Scrapeless. Você também pode consultar o website oficial para aprender mais sobre o Scrapeless.
Passo 1. Acesse a API de Scraping Scrapeless em Node.js
Precisamos ir para o Dashboard do Scrapeless, clicar no menu "Scraping API" à esquerda e, em seguida, selecionar um serviço que você deseja usar.
Aqui podemos usar o serviço "Amazon"
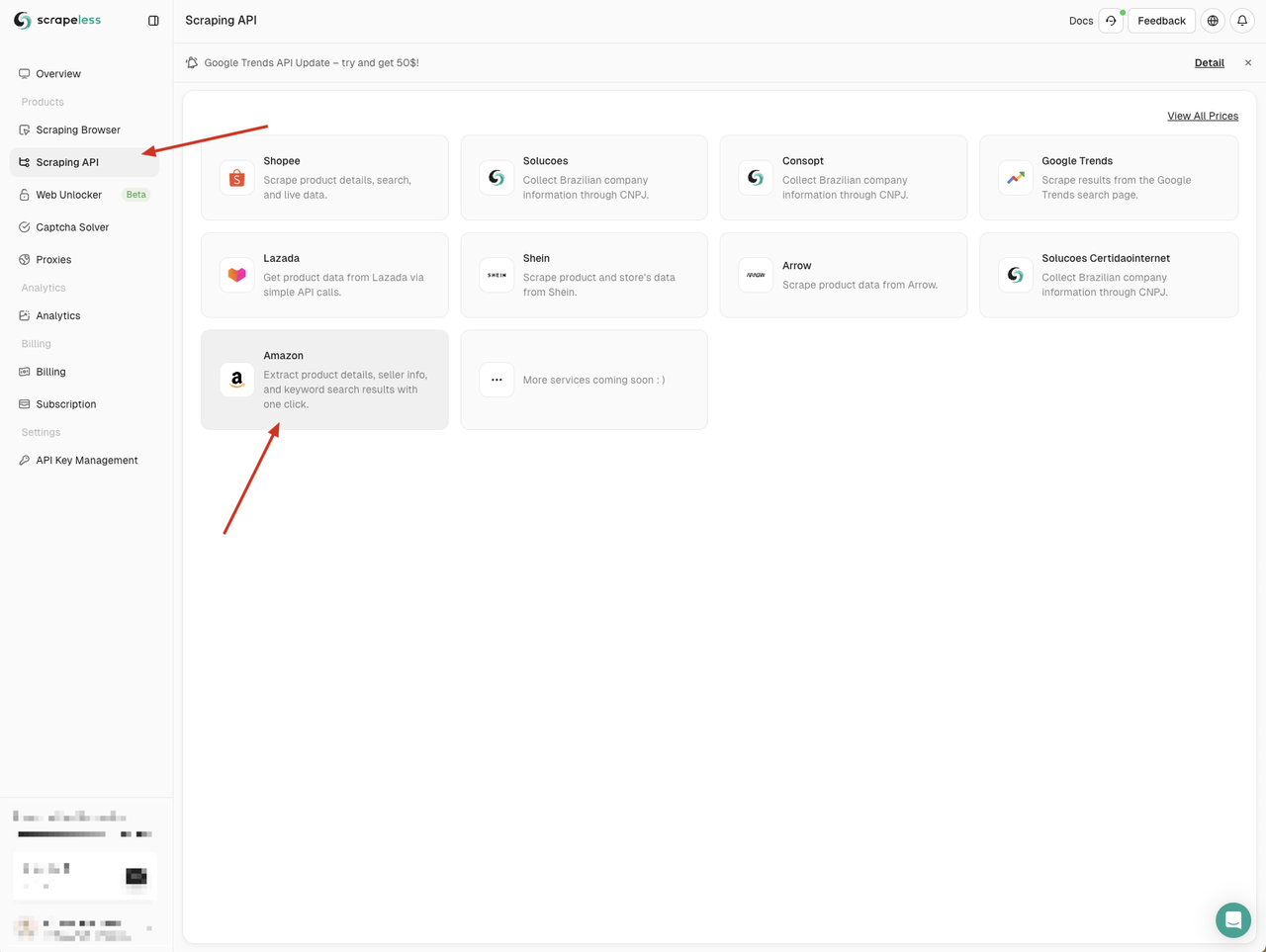
Ao entrar na página da API da Amazon, podemos ver que o Scrapeless nos forneceu parâmetros padrão e exemplos de código em três linguagens:
- Python
- Go
- Node.js
Aqui escolhemos Node.js e copiamos o exemplo de código para nosso projeto:
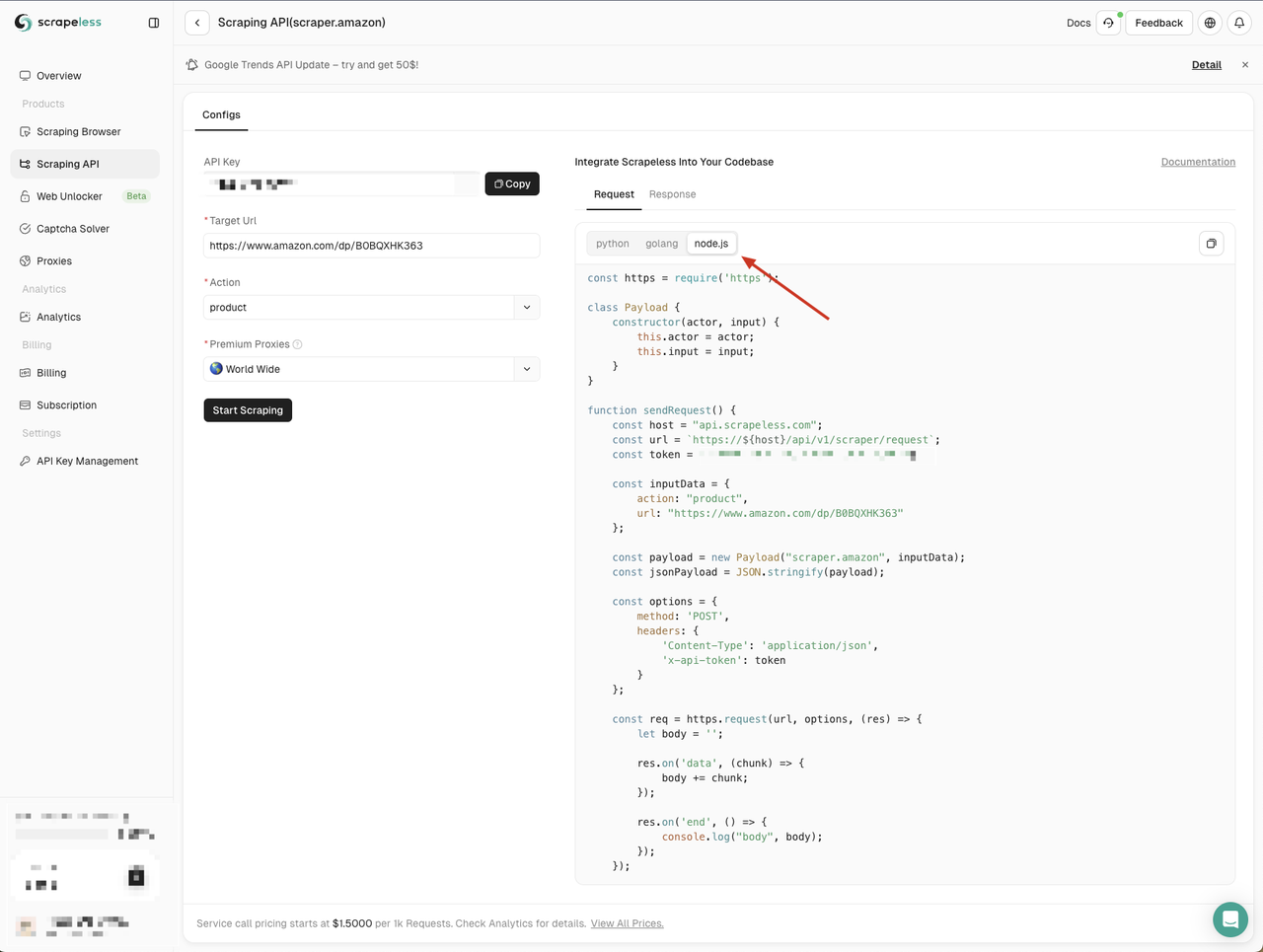
Os exemplos de código Node.js do Scrapeless usam o módulo http por padrão. Podemos usar o módulo node-fetch para substituir o módulo http, para que possamos usar a Fetch API para enviar solicitações de rede.
Primeiro, crie um arquivo scraping-api-amazon.js em nosso projeto e, em seguida, substitua os exemplos de código fornecidos pelo Scrapeless pelos seguintes exemplos de código:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/scraper/request`;
const token = ''; // Your API token
const inputData = {
action: 'product',
url: 'https://www.amazon.com/dp/B0BQXHK363',
};
const payload = new Payload('scraper.amazon', inputData);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Execute o código executando o seguinte comando:
Bash
node scraping-api-amazon.js Veremos os resultados retornados pela API Scrapeless. Aqui simplesmente os imprimimos. Você pode processar os resultados retornados de acordo com suas necessidades.
Passo 2. Aproveitando o Web Unlocker para contornar medidas comuns anti-scraping
Scrapeless fornece um serviço Web unlocker que pode ajudá-lo a contornar medidas comuns anti-scraping, como contorno de CAPTCHA, bloqueio de IP, etc. O serviço Web unlocker pode ajudá-lo a resolver alguns problemas comuns de rastreamento e tornar suas tarefas de rastreamento mais suaves.
Para verificar a eficácia do serviço Web unlocker, podemos primeiro usar o comando curl para acessar um website que requer um CAPTCHA e, em seguida, usar o serviço Scrapeless Web unlocker para acessar o mesmo website para ver se o CAPTCHA pode ser contornado com sucesso.
- Use o comando curl para acessar um website que requer um código de verificação, como
https://identity.getpostman.com/login:
Bash
curl https://identity.getpostman.com/loginObservando os resultados retornados, podemos ver que este website está conectado ao mecanismo de verificação Cloudflare, e precisamos inserir o código de verificação para continuar acessando o website.

- Usamos o serviço Scrapeless Web unlocker para acessar o mesmo website:
- Vá para o Scrapeless Dashboard
- Clique no menu Web unlocker à esquerda
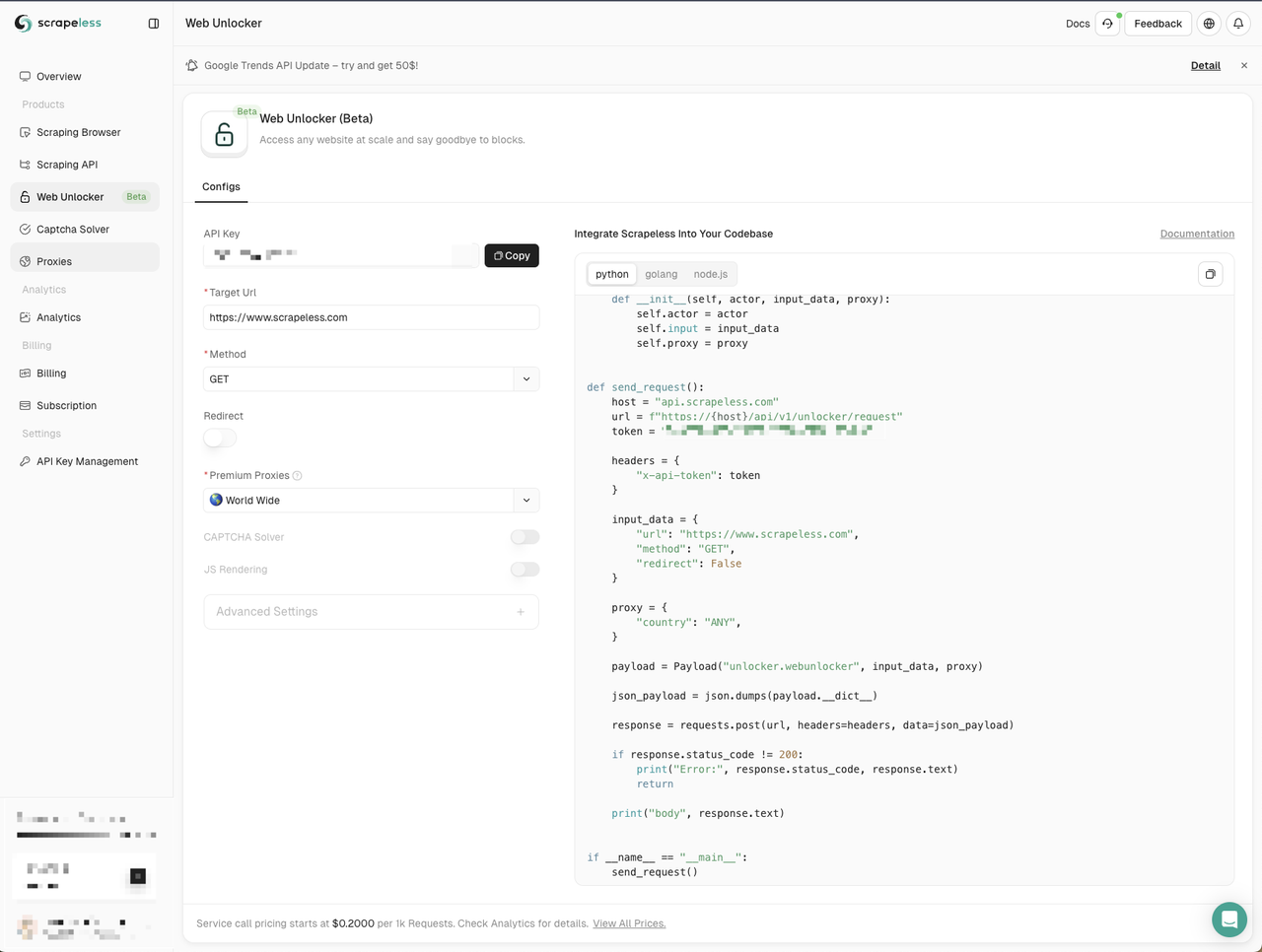
- Copie o exemplo de código Node.js para nosso projeto
Aqui criamos um novo arquivo web-unlocker.js. Ainda precisamos usar o módulo node-fetch para enviar solicitações de rede, então precisamos substituir o módulo http no exemplo de código fornecido pelo Scrapeless pelo módulo node-fetch:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // Your API token
const inputData = {
url: 'https://identity.getpostman.com/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Execute o seguinte comando para executar o script:
JavaScript
web-unlocker.js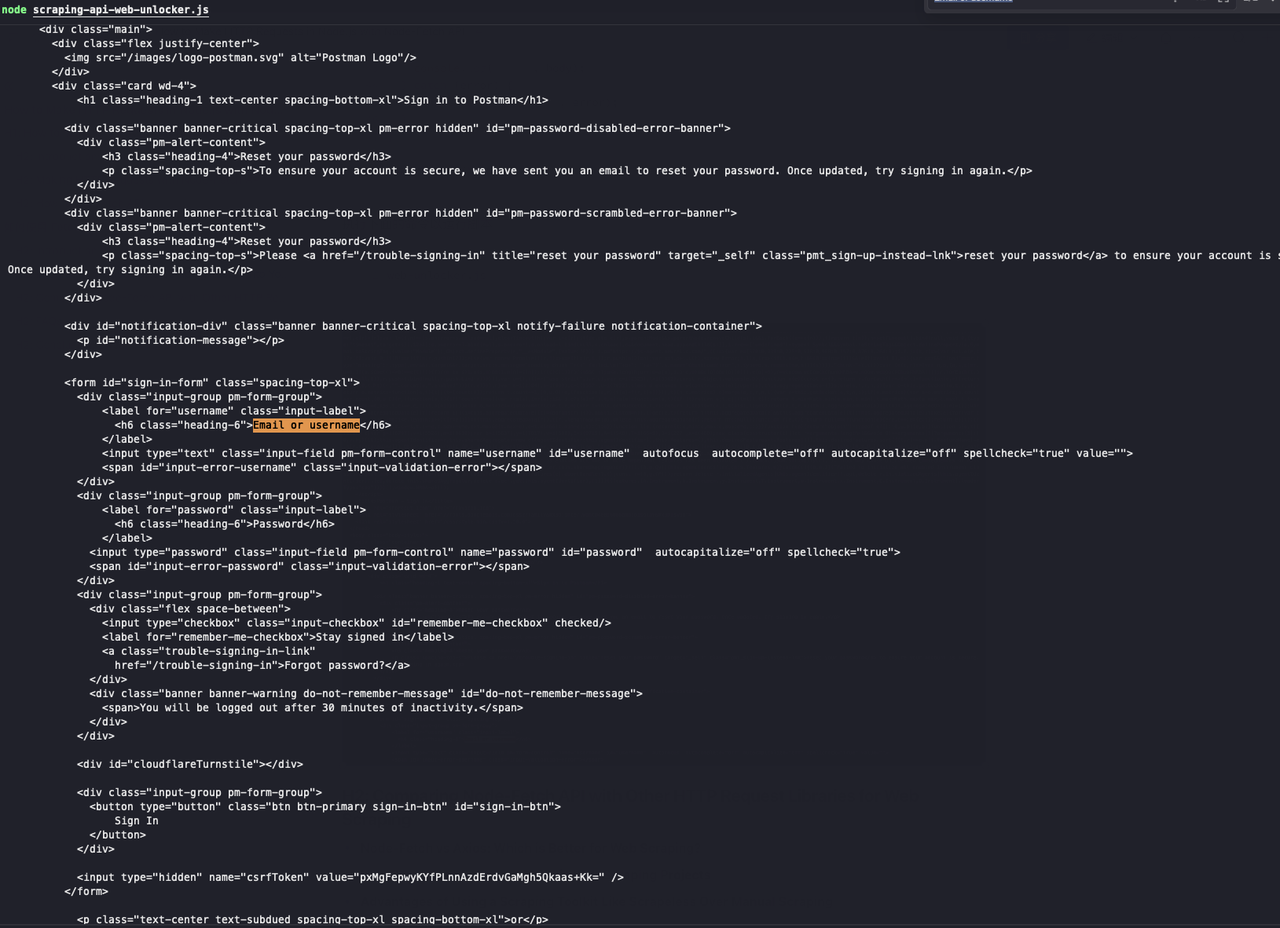
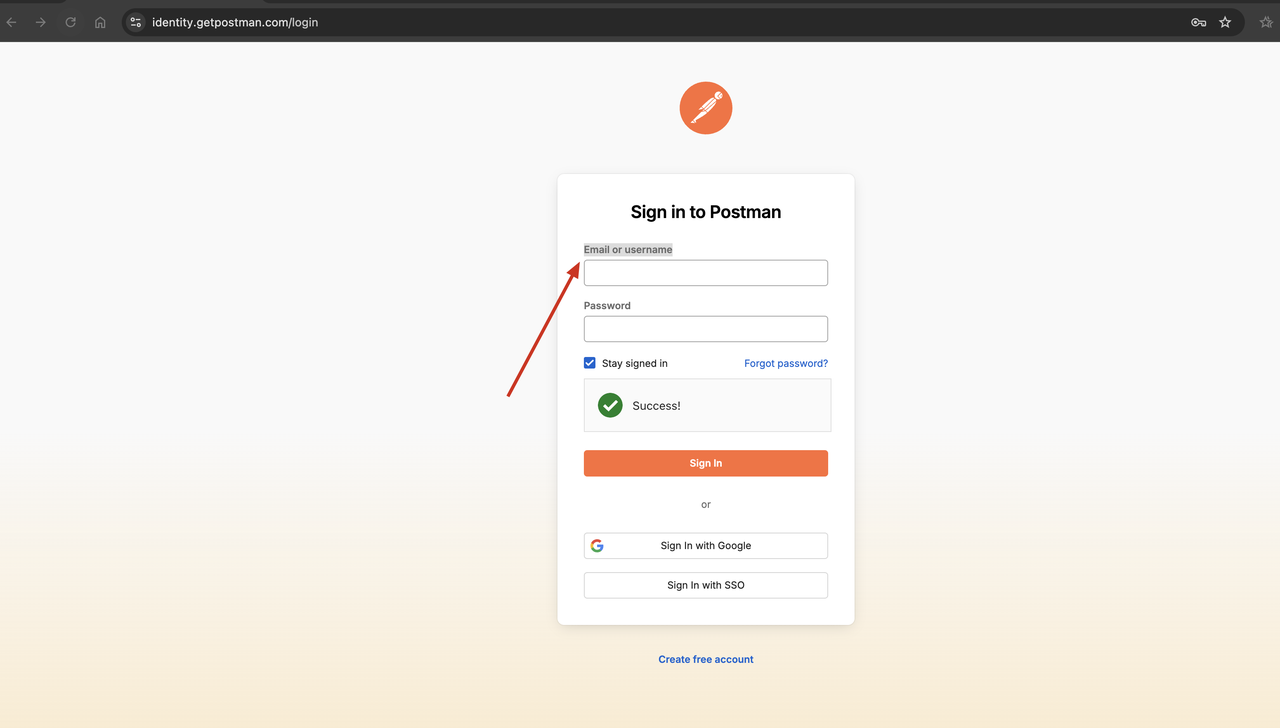
Olhe! O Scrapeless Web unlocker contornou com sucesso o código de verificação, e podemos ver que os resultados retornados contêm o conteúdo da página web de que precisamos.
FAQs
P1. Node-Fetch vs Axios: qual é melhor para web scraping?
Para facilitar sua escolha, Axios e Fetch API têm as seguintes diferenças:
- A Fetch API usa a propriedade body da solicitação, enquanto o Axios usa a propriedade data.
- Com o Axios, você pode enviar dados JSON diretamente, enquanto a Fetch API precisa ser convertida em uma string.
- O Axios pode processar JSON diretamente. A Fetch API requer chamar o método response.json() primeiro para obter uma resposta no formato JSON.
- Para o Axios, o nome da variável de dados de resposta deve ser data; para a Fetch API, o nome da variável de dados de resposta pode ser qualquer um.
- O Axios permite o monitoramento e a atualização fáceis do progresso usando eventos de progresso. Não há método direto na Fetch API.
- A Fetch API não suporta interceptadores, enquanto o Axios sim.
- A Fetch API permite respostas em streaming, enquanto o Axios não.
P2. Node fetch é estável?
O recurso mais notável do Node.js v21 é a estabilização da Fetch API.
P3. A Fetch API é melhor que AJAX?
Para novos projetos, recomenda-se usar a Fetch API devido aos seus recursos modernos e simplicidade. No entanto, se você precisar dar suporte a navegadores muito antigos ou estiver mantendo código legado, o Ajax ainda pode ser necessário.
Conclusões
A adição da Fetch API em Node.js é um recurso há muito aguardado. Usar a Fetch API em Node.js pode garantir que seu trabalho de scraping seja feito facilmente. No entanto, é inevitável encontrar bloqueios de rede sérios ao usar a API Node Fetch.
Quer resolver completamente os banimentos de IP e CAPTCHA? Certifique-se de usar o Scrapeless para contornar facilmente o monitoramento do website e o bloqueio de IP.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


