
8 Extractores Web Gratuitos Sem Código | Melhor Seleção 2025
Senior Web Scraping Engineer
O que são raspadores sem código?
Ferramentas de web scraping sem código, também conhecidas como scraping gerenciado ou hospedado, são um método de web scraping que ajuda você a extrair dados de sites sem precisar construir ou manter infraestrutura de código. Essas ferramentas geralmente são construídas com uma interface visual ou um fluxo de trabalho simplificado que facilita para os usuários configurar e executar tarefas de web scraping.
Um dos principais benefícios do scraping sem código é que ele reduz significativamente o tempo e o esforço necessários para coletar dados da web. Você pode carregar sua URL de destino, usar modelos de scraping pré-construídos para sites populares ou casos de uso comuns e obter dados quase instantaneamente.
Essas ferramentas eliminam a necessidade de codificação manual e gerenciamento de infraestrutura, permitindo que você se concentre mais na análise e na obtenção de insights valiosos dos dados extraídos.
Escalabilidade é outro benefício que acompanha as ferramentas de scraping sem código. Por exemplo, usando o serviço de API da Scrapeless, você pode agendar tarefas de scraping usando trabalhos cron ou intervalos personalizados para maior automação e escalabilidade.
Isso é especialmente útil se você deseja monitorar continuamente seus concorrentes. Sim, eles podem mudar seus preços e palavras-chave de listagem todos os dias, portanto, você deve acompanhar esses desenvolvimentos para manter a competitividade.
Por que devemos escolher um raspador sem código?
- Interface visual: As ferramentas de web scraping sem código geralmente oferecem uma interface de arrastar e soltar ou funcionalidade de apontar e clicar, onde os usuários podem selecionar elementos de um site que desejam raspar, sem precisar saber como escrever código.
- Modelos pré-configurados: Muitos raspadores sem código vêm com modelos pré-construídos para tarefas comuns de web scraping, tornando ainda mais fácil começar.
- Automação: Essas ferramentas geralmente automatizam tarefas repetitivas de scraping, para que os usuários possam agendar ou disparar trabalhos de scraping sem precisar intervir manualmente a cada vez.
- Compatibilidade: Os raspadores sem código podem lidar com dados de sites estáticos e dinâmicos, incluindo aqueles que usam JavaScript, aproveitando navegadores integrados ou ambientes em nuvem para renderizar as páginas.
- Exportação de dados: Eles permitem que os usuários exportem dados raspados em vários formatos, como CSV, Excel ou mesmo integração de API, tornando os dados facilmente acessíveis para análise ou uso em outros sistemas.
- Nenhum conhecimento de programação necessário: O benefício principal é que os usuários podem construir fluxos de trabalho de scraping complexos sem aprender linguagens de programação como Python, JavaScript ou outras.
Critérios de avaliação principais para raspadores sem código
- Facilidade de uso: A operação é intuitiva e direta? Para mim, escolher uma ferramenta que seja fácil de começar é uma prioridade máxima. Se a ferramenta for muito complexa ou difícil de operar, não importa o quão poderosas sejam suas funções, eu me sentiria sobrecarregado. Uma boa ferramenta de web scraping sem código deve ter pelo menos uma interface de usuário limpa e etapas operacionais claras.
- Capacidade de scraping de dados: Ela pode raspar páginas da web dinâmicas complexas? A função mais importante de um raspador da web sem código é sua capacidade de raspar dados da web com precisão e rapidez. Especialmente, pode lidar com sites dinâmicos e páginas renderizadas em JavaScript? Afinal, muitos sites agora carregam conteúdo via JavaScript, que ferramentas comuns geralmente não conseguem processar.
- Capacidade anti-detecção: Ela pode contornar os mecanismos anti-scraping de um site? Quando uso um raspador da web sem código para scraping, muitos sites têm medidas anti-scraping em vigor (como restrições de IP, CAPTCHAs, etc.). Isso geralmente leva a bloqueios ou desafios de CAPTCHA ao usar algumas ferramentas.
- API e automação: Ela suporta integração e tarefas automatizadas? Como alguém que frequentemente precisa raspar dados repetidamente, espero que minha ferramenta suporte APIs, para que eu possa automatizar tarefas de scraping e até mesmo integrá-las aos meus processos de negócios existentes.
- Preços e custo-benefício: O custo da ferramenta é razoável? Normalmente, opto por ferramentas que oferecem um bom custo-benefício. Embora ferramentas gratuitas sejam boas, muitas vezes seus recursos e limitações não atendem às minhas necessidades. Se uma versão paga for rica em recursos e com preço razoável, é um investimento muito valioso.
Classificação: Análise das 8 melhores ferramentas de raspadores sem código
As seguintes são as 8 melhores ferramentas de web scraping sem código que selecionamos cuidadosamente para você. Elas têm funções diferentes e você precisa escolher um produto que atenda às suas necessidades reais.
Comparação geral
| Principais recursos | Plano pago | Teste gratuito | Facilidade de uso | |
|---|---|---|---|---|
| Scrapeless | Completo, estável e de alto sucesso | A partir de US$ 49 | Teste gratuito de um mês para todos os serviços | ⭐⭐⭐⭐⭐ |
| ParseHub | Adequado para usuários não técnicos | A partir de US$ 189 | Com valor de US$ 99 | ⭐⭐⭐⭐⭐ |
| Diffbot | Análise de estrutura da web com IA | A partir de US$ 299 | Longo prazo com limitações funcionais | ⭐⭐⭐⭐ |
| Outscraper | Para dados de categoria de pesquisa do Google | De acordo com suas necessidades | Para as primeiras 500 ações | ⭐⭐⭐⭐ |
| WebHarvy | Perfeito para tarefas de coleta de dados em pequena escala | A partir de US$ 129 | Não suporta | ⭐⭐⭐⭐ |
| DataMiner | Rastreamento de dados estruturados, como tabelas e listas | A partir de US$ 19,99 | O plano gratuito oferece 500 páginas/mês | ⭐⭐⭐ |
| Simplescraper | Para projetos pequenos | A partir de US$ 39 | 100 créditos iniciais gratuitos | ⭐⭐⭐ |
| Browse AI | Ideal para análise da concorrência e rastreamento de preços | A partir de US$ 19 | 50 créditos | ⭐⭐⭐ |
#1 Scrapeless – Um raspador da web sem código abrangente e estável
Scrapeless é uma ferramenta de web scraping baseada em nuvem, alimentada pela tecnologia Browserless, projetada para fornecer aos usuários um ambiente de scraping estável. Ele suporta a circunvenção de restrições de IP por meio de proxies inteligentes, tornando-o especialmente adequado para extração de dados de e-commerce, notícias e SEO.
Para usuários sem habilidades de programação ou aqueles que preferem não gastar muito tempo com codificação, o Scrapeless oferece uma interface de API simples que pode ser rapidamente integrada a sistemas de negócios internos para automatizar tarefas de scraping de dados. A API do Scrapeless suporta totalmente a renderização de JavaScript por meio de suas poderosas capacidades de desenvolvimento. Com apenas alguns cliques e configurações simples, os usuários podem concluir o que normalmente seria uma configuração complexa de raspador.
O Scrapeless também está programado para lançar um serviço de agente de IA. No geral, é ideal para usuários que precisam de scraping de dados em larga escala e a longo prazo, principalmente devido às suas capacidades superiores de anti-detecção em comparação com os raspadores sem código tradicionais.
Como implantar o Scrapeless? Aqui estão as etapas mais claras:
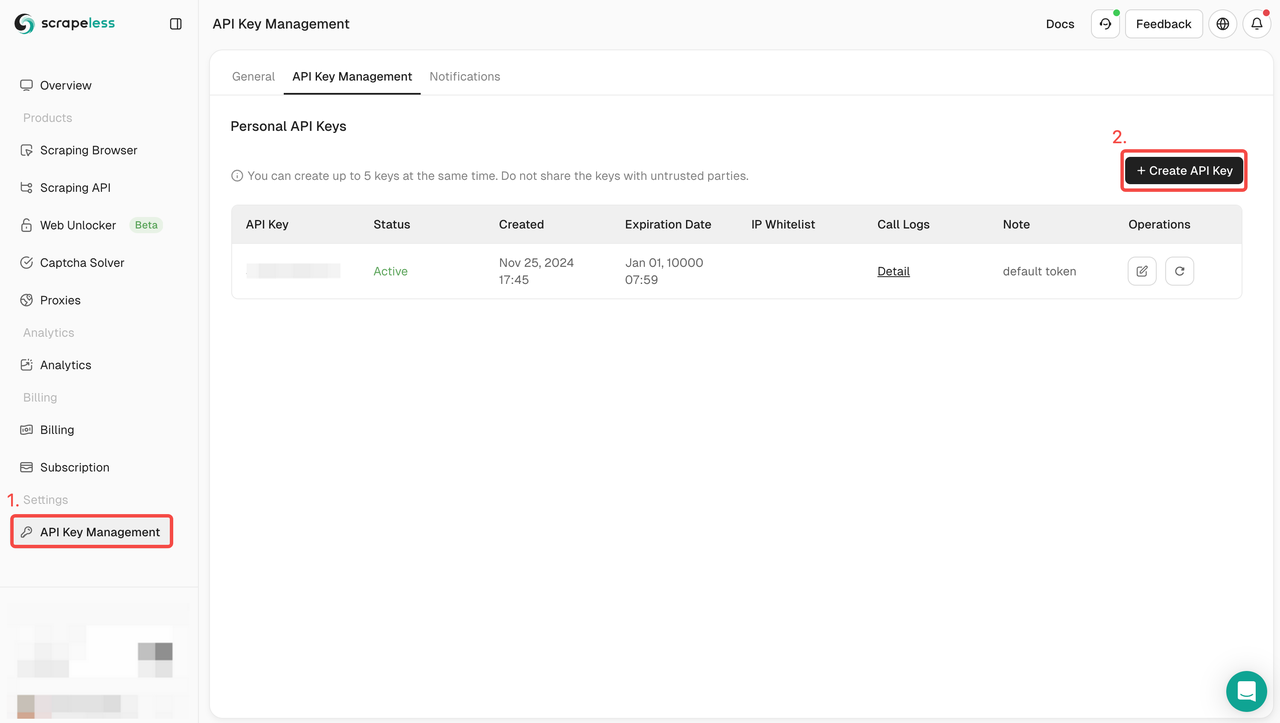
Etapa 1. Obtenha sua chave de API
Para começar, você precisará obter sua chave de API no painel do Scrapeless:
- Faça login no Painel do Scrapeless.
- Navegue até Gerenciamento de chave de API.
- Clique em Criar para gerar sua chave de API exclusiva.
- Depois de criada, basta clicar na chave de API para copiá-la.
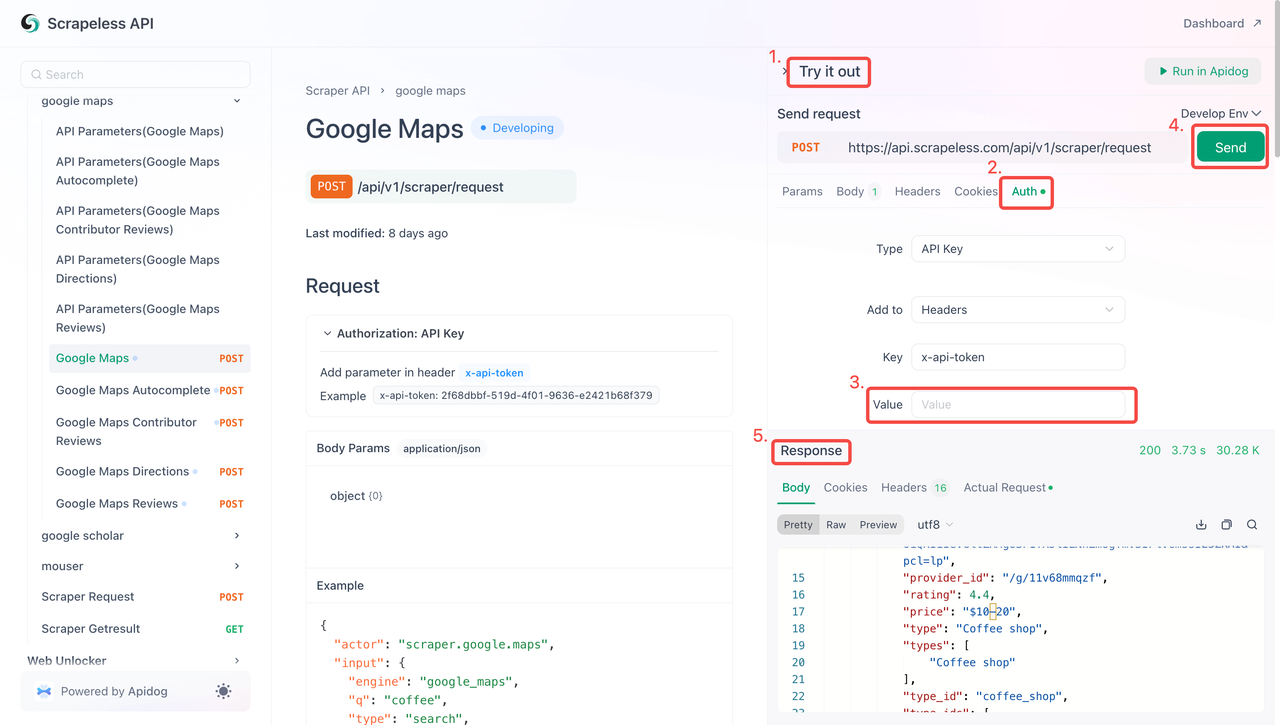
Etapa 2: Use sua chave de API no código
Agora você pode usar sua chave de API para integrar o Scrapeless ao seu projeto. Siga estas etapas para testar e implementar a API:
- Visite a Documentação da API.
- Clique em "Testar" para o endpoint desejado.
- Insira sua chave de API no campo "Autenticação".
- Clique em "Enviar" para obter a resposta de scraping.
Abaixo está um exemplo de snippet de código que você pode integrar diretamente ao seu raspador do Google Maps:
Python
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))JavaScript
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "scraper.google.maps",
"input": {
"engine": "google_maps",
"q": "coffee",
"type": "search",
"ll": "@40.7455096,-74.0083012,14z",
"hl": "en",
"gl": "us"
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/scraper/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));#2 ParseHub – Uma ferramenta de scraping visual para sites complexos
- Principais recursos:
✅ Interface visual, adequada para usuários não técnicos
✅ Agendamento de web scraping
O ParseHub oferece recursos poderosos de coleta de dados visuais, tornando-o uma excelente escolha para usuários sem experiência em programação. Ele também suporta o tratamento de sites renderizados em JavaScript. No entanto, a versão gratuita tem recursos limitados, tornando-a particularmente atraente para entusiastas de dados da web que desejam experimentar o web scraping sem se comprometer totalmente.
#3 Diffbot – Análise de estrutura da web com IA, ideal para scraping de notícias e artigos
- Principais recursos:
✅ Reconhecimento de conteúdo com IA, sem necessidade de definir regras manualmente
✅ Adequado para dados não estruturados, como artigos, comentários, etc.
O Diffbot é uma ferramenta que usa tecnologia de IA para analisar estruturas da web, tornando-o especialmente adequado para extrair dados de conteúdo não estruturado, como sites de notícias e blogs. Com seu poderoso modelo de IA, os usuários podem facilmente extrair as informações necessárias sem ter que definir manualmente as regras de scraping.
#4 Outscraper – Ideal para scraping de dados do Google Search e Maps
- Principais recursos:
✅ Especificamente projetado para dados do Google, excelente desempenho de scraping
✅ Fornece suporte de API para coleta automatizada de dados
✅ Pode extrair dados dos resultados de pesquisa e do Google Maps
O Outscraper concentra-se no scraping de dados relacionados ao Google, como os resultados do Google Maps e do Google Search, tornando-o altamente adequado para análise de dados de negócios locais. Por meio de sua API, os usuários podem integrar e automatizar rapidamente suas tarefas de coleta de dados.
#5 WebHarvy – Ferramenta de web scraping para desktop Windows
- Principais recursos:
✅ Interface amigável, ideal para tarefas de scraping de dados em pequena escala
✅ Uso vitalício após a compra
O WebHarvy é um raspador visual baseado em desktop Windows, perfeito para tarefas de coleta de dados em pequena escala. Sua interface amigável é projetada para usuários não técnicos, permitindo que eles definam facilmente as regras de scraping por meio de uma interface gráfica.
#6 DataMiner – Extensão leve do Chrome para pequenos rastreadores
- Principais recursos:
✅ Pronto para usar após a instalação, baixo nível de conhecimento necessário
✅ Adequado para rastrear dados estruturados, como tabelas e listas
O DataMiner é uma extensão leve do Chrome adequada para tarefas de scraping de dados em pequena escala. É fácil de instalar e usar, tornando-o ideal para extrair dados estruturados, como tabelas e listas.
#7 Simplescraper – Ferramenta de scraping leve e amigável à API
- Principais recursos:
✅ Acesso rápido à API, suporta scraping automatizado
✅ Fácil de usar, adequado para usuários não técnicos
✅ Ideal para projetos pequenos com desempenho estável da API
O Simplescraper oferece uma API amigável, perfeita para usuários de projetos pequenos e médios, permitindo o scraping rápido de dados da web e processamento automatizado. É adequado para desenvolvedores que procuram integrar fluxos de trabalho de scraping em seus sistemas existentes.
#8 Browse AI – Projetado para monitorar mudanças no site
- Principais recursos:
✅ Rastreia automaticamente as mudanças nos dados da web
✅ Ideal para análise da concorrência e rastreamento de preços
✅ Apresenta uma interface de configuração visual
O Browse AI é especializado em monitorar mudanças nos dados do site, tornando-o adequado para tarefas regulares, como rastreamento de preços e vigilância de mercado. Ele pode monitorar automaticamente as atualizações em páginas da web especificadas, atendendo às necessidades de análise da concorrência e monitoramento de dados de SEO.
Conclusão
Os raspadores da web sem código preenchem a lacuna entre a coleta de dados e as equipes não técnicas, mas também podem beneficiar as equipes técnicas, permitindo que elas coletem dados rapidamente sem ter que desenvolver uma infraestrutura complexa do zero.
Navegar na coleta de dados da web pública pode ser uma tarefa difícil. No entanto, com as 8 ótimas ferramentas de web scraping sem código mencionadas acima, os não programadores agora podem facilmente aproveitar o web scraping. Tudo o que resta a fazer é escolher a ferramenta que atende aos requisitos do seu projeto.
Quer saber mais sobre ferramentas de automação e scraping de sites? Leia mais sobre soluções eficazes!
Perguntas frequentes
1. É legal usar raspadores sem código?
Geralmente, raspar dados publicamente disponíveis é legal. No entanto, raspar dados pessoais, propriedade intelectual ou dados atrás de um login pode levantar preocupações legais.
2. Como funciona um raspador sem código?
Os raspadores sem código fornecem uma interface amigável que permite aos usuários extrair dados de sites sem escrever código. Os usuários podem selecionar elementos em uma página da web para definir os dados a serem extraídos. A ferramenta então automatiza o processo de navegação no site, extração dos dados especificados e exportação em um formato estruturado como CSV ou JSON.
3. Posso usar raspadores sem código para raspar dados de qualquer site?
Embora os raspadores sem código possam ser usados em muitos sites, é crucial garantir que suas atividades de scraping estejam em conformidade com os termos de serviço do site e as leis aplicáveis.
4. Os dados obtidos por raspadores sem código são confiáveis?
Sim. Vamos pegar o Scrapeless como exemplo. O Scrapeless garante uma taxa de sucesso e confiabilidade de 99%. A estabilidade e a precisão do scraping do Google Trends atingiram quase 100%!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


