
Como raspar produtos do Naver com a API de raspagem Scrapeless?
Senior Web Scraping Engineer
Com o crescimento das compras online, 24% de todas as vendas no varejo agora vêm de mercados de e-commerce. Até 2025, as vendas globais de varejo por meio de e-commerce devem alcançar $7,4 trilhões.
Naver, o maior motor de busca e gigante da tecnologia da Coreia do Sul, é o coração da vida digital do país. Desde e-commerce e pagamentos digitais até webtoons, blogs e mensagens móveis, captura dados de usuários em mais verticais do que qualquer outra plataforma.
A arquitetura da Naver é projetada para quebrar padrões previsíveis, detectar inconsistências e se adaptar mais rapidamente do que a maioria dos sistemas. Se sua estratégia de scraping depende de scripts estáticos ou proxies de força bruta, já está desatualizada. O scraping de dados do Naver Shop bem-sucedido não se trata apenas de contornar defesas - requer coordenar o comportamento da sessão, lógica de tempo e alinhar-se com as expectativas da plataforma.
Como você pode fazer scraping de dados de produtos do Naver Shop rapidamente, em grande escala e com custo mínimo?
Este guia é para equipes de negócios, proprietários de dados e líderes que enfrentam desafios modernos de scraping no Naver!
💼 Por que fazer scraping de dados do Naver?
- Estratégias de Preços Competitivos: Use o scraping de dados do Naver Shopping para coletar preços de concorrentes, permitindo que você se mantenha à frente no mercado.
- Otimização de Inventário: Monitore os níveis de estoque em tempo real para reduzir escassez e melhorar a eficiência.
- Análise de Tendências de Mercado: Identifique tendências emergentes e preferências dos consumidores para ajustar suas ofertas.
- Listagens de Produtos Aprimoradas: Extraia descrições detalhadas, imagens e especificações para criar listagens atraentes.
- Monitoramento e Ajustes de Preços: Acompanhe mudanças de preços e descontos para otimizar promoções.
- Análise de Concorrentes: Analise as ofertas de produtos dos rivais, preços e promoções para superá-los.
- Marketing Baseado em Dados: Reúna insights sobre o comportamento do consumidor para campanhas direcionadas.
- Melhoria da Satisfação do Cliente: Monitore avaliações e classificações para refiná-los produtos e aumentar a satisfação.
💡 Quais dados de produtos podemos extrair do Naver?
Fazer scraping de preços, status de estoque, descrições, avaliações e descontos garante dados abrangentes e atualizados. Uma ferramenta robusta de scraping do Naver pode extrair:
| Campo | Campo | Campo |
|---|---|---|
| ✅ Nome do Produto | ✅ Avaliações de Clientes | ✅ Promoções |
| ✅ Características do Produto | ✅ Descrições | ✅ Imagens |
| ✅ Avaliações | ✅ Opções de Entrega | ✅ Categorias |
| ✅ Subcategorias | ✅ ID do Produto | ✅ Marca |
| ✅ Tempo de Entrega | ✅ Política de Retorno | ✅ Disponibilidade |
| ✅ Preço | ✅ Informações do Vendedor | ✅ Data de Expiração |
| ✅ Localização da Loja | ✅ Ingredientes | ✅ Preço com Desconto |
| ✅ Preço Original | ✅ Ofertas em Pacote | ✅ Última Atualização |
| ✅ Unidade de Manutenção de Estoque (SKU) | ✅ Peso/Volume | ✅ Percentagem de Desconto |
| ✅ Preço por Unidade | ✅ Informações Nutricionais |
⚠️ Quais são as dificuldades em fazer scraping de informações de produtos do Naver?
Antes de considerar como fazer scraping de dados do Naver, toda empresa deve primeiro refletir sobre os seguintes seis desafios principais:
1. Falta de Pontos de Entrada Estáveis ou Controle de Sessão
O scraping anônimo é um sinal de alerta. O Naver requer comportamento consistente do usuário. Sem simulação de sessão que reflita a atividade do usuário dentro de regiões autorizadas, suas ações parecerão suspeitas, frágeis e rapidamente descartadas.
2. Desafios de Renderização de JavaScript
O JavaScript controla conteúdo e tempos de resposta críticos no Naver. Se sua ferramenta de extração não conseguir renderizar JS com precisão ou detectar mudanças após o carregamento, seus dados serão incompletos, desatualizados ou invisíveis. Ignorar essa complexidade pode levar a falhas ocultas, distorcendo insights para os tomadores de decisão.
3. Validação de Sessão, Bloqueio Geográfico e Atualizações de CAPTCHA
Cada camada de automação traz riscos!
- Se uma camada falhar, sua sessão expira.
- Se duas camadas falharem, surgem suspeitas.
- Se três camadas falharem, você será sinalizado e bloqueado.
Sem uma estratégia de simulação de sessões resiliente, rotacionando IPs regionais e lidando automaticamente com desafios voltados ao usuário (incluindo CAPTCHA), sua infraestrutura se torna um castelo de cartas.
4. Mudanças de Layout e Redesigns de Interface no Naver Shop
As alterações da Naver são sutis, frequentes e imprevisíveis! O que funcionou ontem pode não funcionar hoje. Mudanças na lógica de paginação, movimentações de tags ou reestruturação de cargas podem impactar severamente suas ferramentas de scraping. Sua equipe enfrentará retrabalho constante, e os sistemas devem detectar, responder e se auto-corrigir — ou correr o risco de exaustão de recursos.
5. Limitação de Taxa e Bloqueios
Ao fazer scraping de dados em grande escala, preste atenção ao número de solicitações e ao volume de dados em um curto período de tempo. Especialistas em extração de dados sempre se concentram em operações de página, simulação de comportamento e protocolos de acesso diversificados — essas são configurações fundamentais para aquisição de dados em alto volume.
6. Privacidade de Dados e Regulamentações Legais na Coreia do Sul
Um único ponto cego pode custar milhões! Fazer scraping de dados da Naver do exterior sem entender os requisitos locais de scraping de dados e as leis de propriedade intelectual expõe sua empresa a riscos reputacionais e legais. Recomenda-se fortemente realizar uma pesquisa aprofundada antes de realizar scraping.
🤔 Por que usar o Scrapeless para extrair dados de produtos da Naver?
O Scrapeless emprega tecnologia avançada de scraping de dados da web para garantir a extração de dados de alta qualidade e precisão para atender diversas necessidades empresariais — desde análise de mercado e estratégias de precificação competitiva até gerenciamento de inventário e análise de comportamento do consumidor. Nosso serviço fornece soluções integradas para varejistas, plataformas de e-commerce e analistas de mercado, ajudando-os a obter insights profundos sobre o mercado de bens de consumo de rápida movimentação (FMCG).
Com nossa API de Scraping da Naver, você pode facilmente rastrear tendências de mercado, otimizar estratégias de precificação e manter uma vantagem competitiva na indústria de alimentos em rápida evolução. Confie em nós para fornecer insights acionáveis que impulsionem o crescimento e a inovação do seu negócio.
Principais Recursos
1️⃣ Ultra-Rápido e Confiável: Adquira dados rapidamente sem comprometer a estabilidade.
2️⃣ Campos de Dados Ricos: Inclui detalhes do produto, informações do vendedor, preços, avaliações e mais.
3️⃣ Sistema Inteligente de Rotação de Proxy: Alterna automaticamente IPs de proxy para contornar efetivamente restrições de acesso baseadas em IP.
4️⃣ Tecnologia Avançada de Impressão Digital: Simula dinamicamente características do navegador e padrões de interação do usuário para contornar mecanismos sofisticados de anti-scraping.
5️⃣ Solução Integrada de CAPTCHA: Lida automaticamente com desafios de reCAPTCHA e Cloudflare, garantindo uma coleta de dados tranquila.
6️⃣ Automação: Processo de scraping totalmente automatizado com resposta rápida a atualizações.
⏯️ PLANO-A. Extrair dados de produtos da Naver com API
- Basta configurar o ID da Loja e o ID do Produto.
- A API Naver do Scrapeless extrairá dados detalhados do produto da Naver Shop, incluindo preços, informações do vendedor, análises e mais.
- Você pode baixar e analisar os dados.
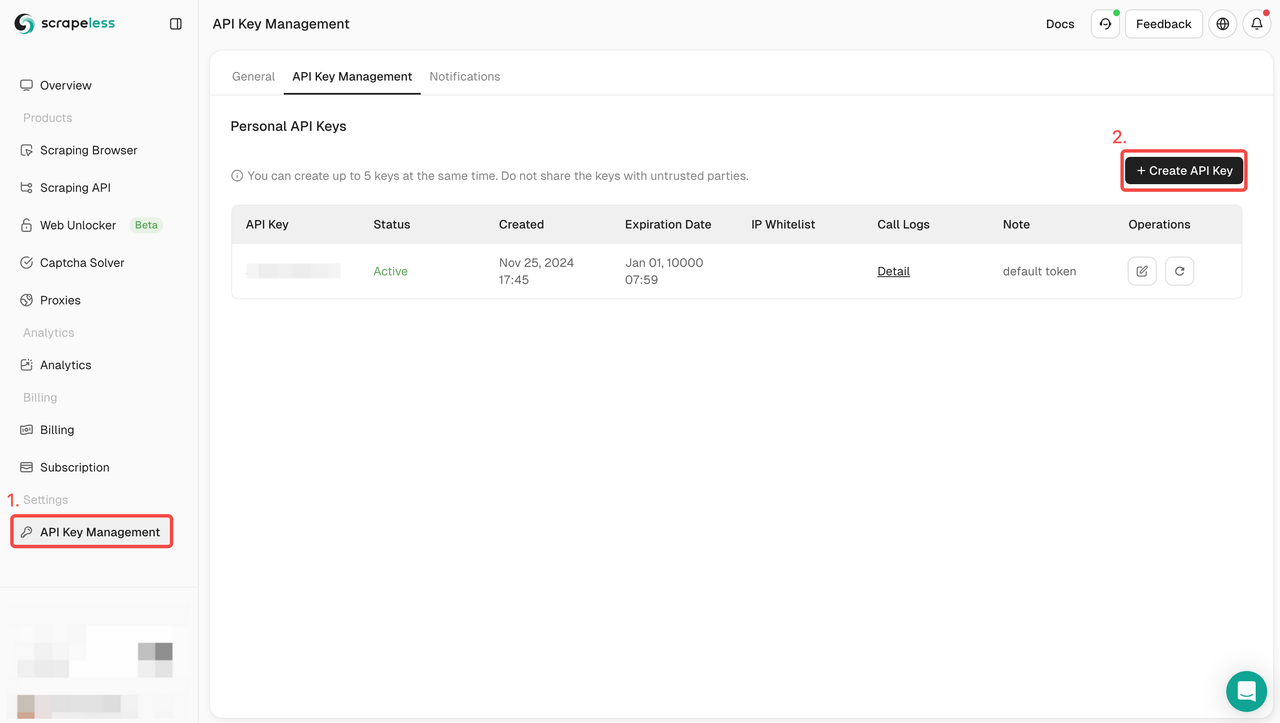
Passo 1: Crie seu Token de API
Para começar, você precisará obter sua Chave de API no Painel do Scrapeless:
- Faça login no Painel do Scrapeless.
- Navegue até Gerenciamento de Chave de API.
- Clique em Criar para gerar sua Chave de API única.
- Uma vez criada, você pode simplesmente clicar na Chave de API para copiá-la.
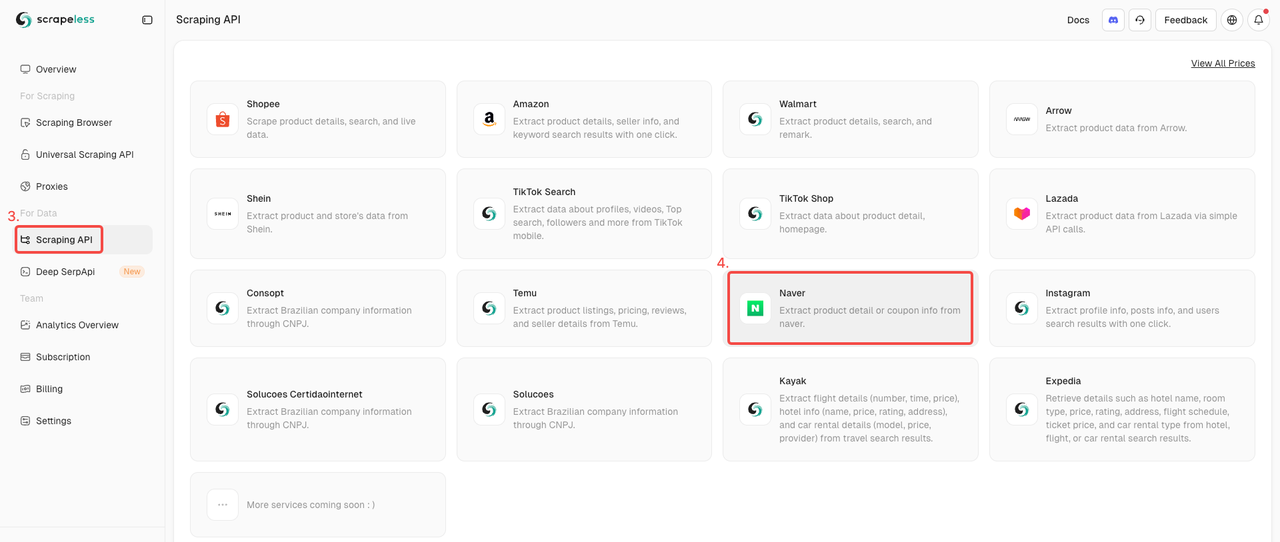
Passo 2. Inicie a API da Naver Shop
- Encontre a API de Scraping na seção Coleta de Dados.
- Basta clicar no ator da Naver Shop para se preparar para fazer scraping dos dados dos produtos.
Passo 3: Defina Seu Alvo
Para fazer scraping de dados de produtos usando a API de Scraping da Naver, você deve fornecer dois parâmetros obrigatórios: storeId e productId. O parâmetro channelUid é opcional.
Você pode encontrar o ID do Produto e o ID da Loja diretamente na URL do produto. Por exemplo:
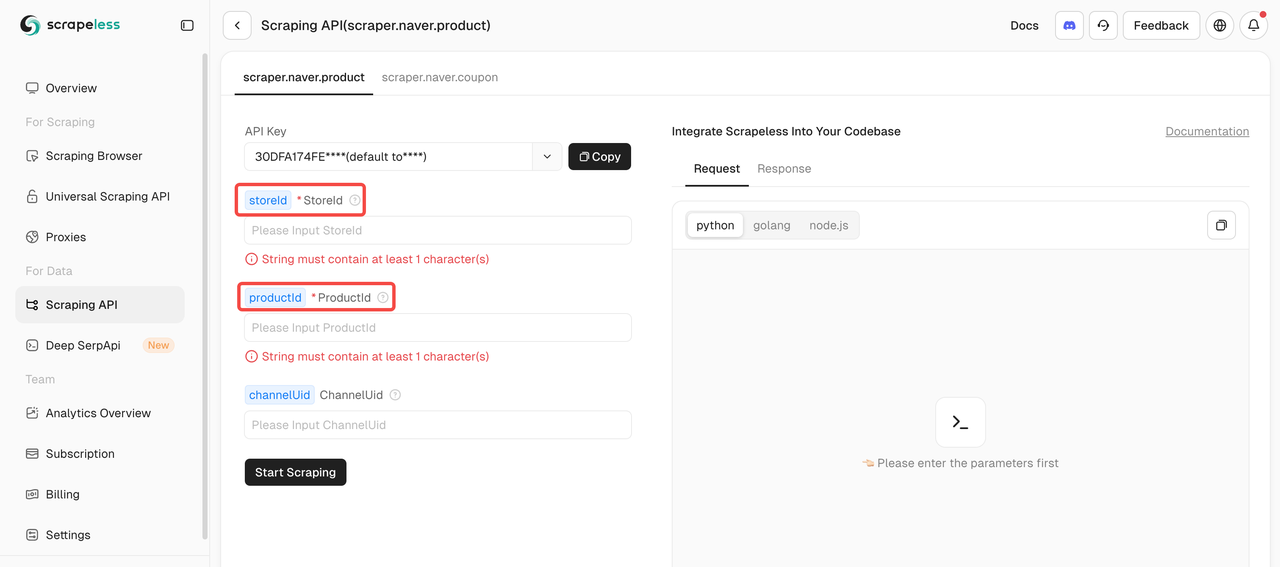
Você pode encontrar o ID do Produto e o ID da Loja diretamente na URL do produto. Vamos pegar [바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등] como exemplo:
- ID da Loja: barudak
- ID do Produto: 4469033180
Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como uma demonstração do processo de crawlagem. Não salvamos nenhuma informação e dados.
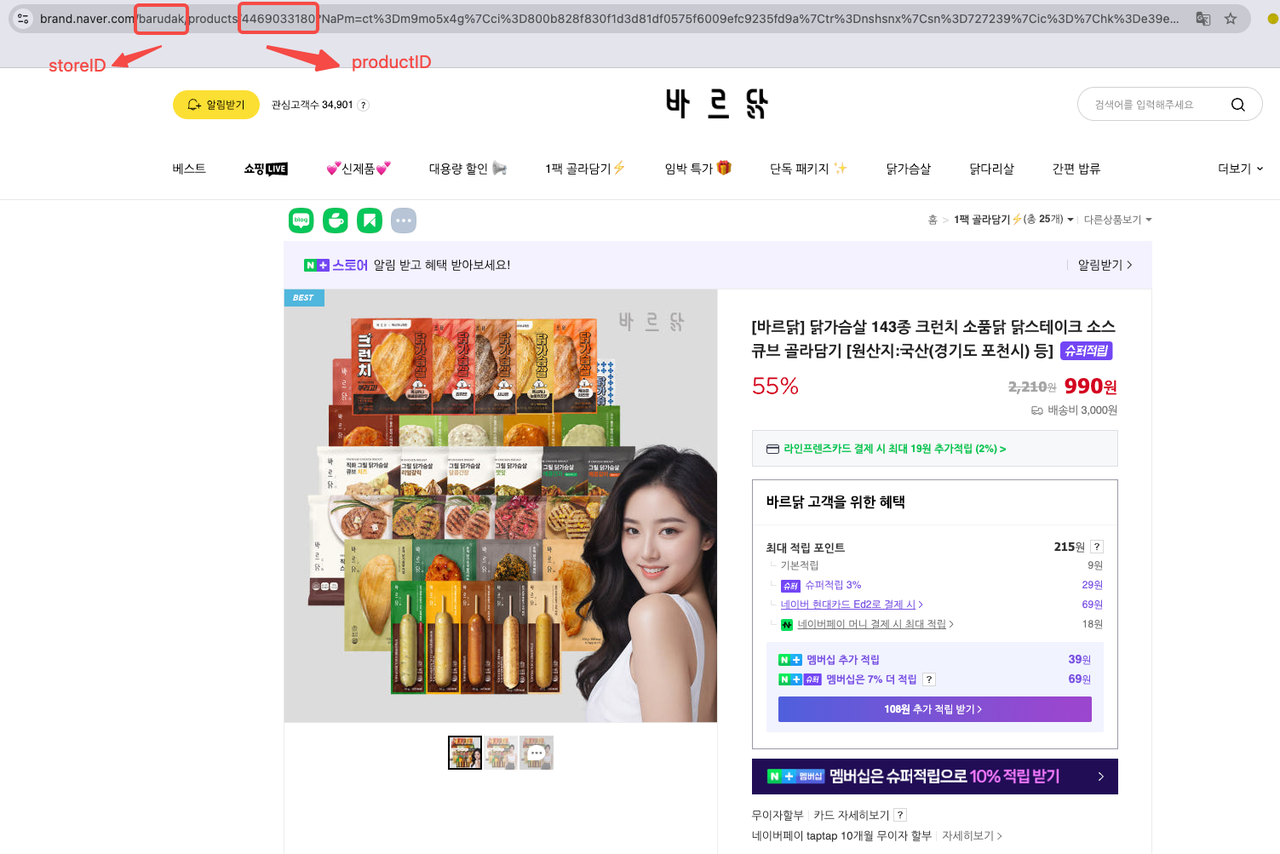
Passo 4: Comece a Fazer Scraping dos Dados de Produtos da Naver
Uma vez que você tenha preenchido os parâmetros obrigatórios, basta clicar em Iniciar Scraping para obter dados abrangentes do produto.
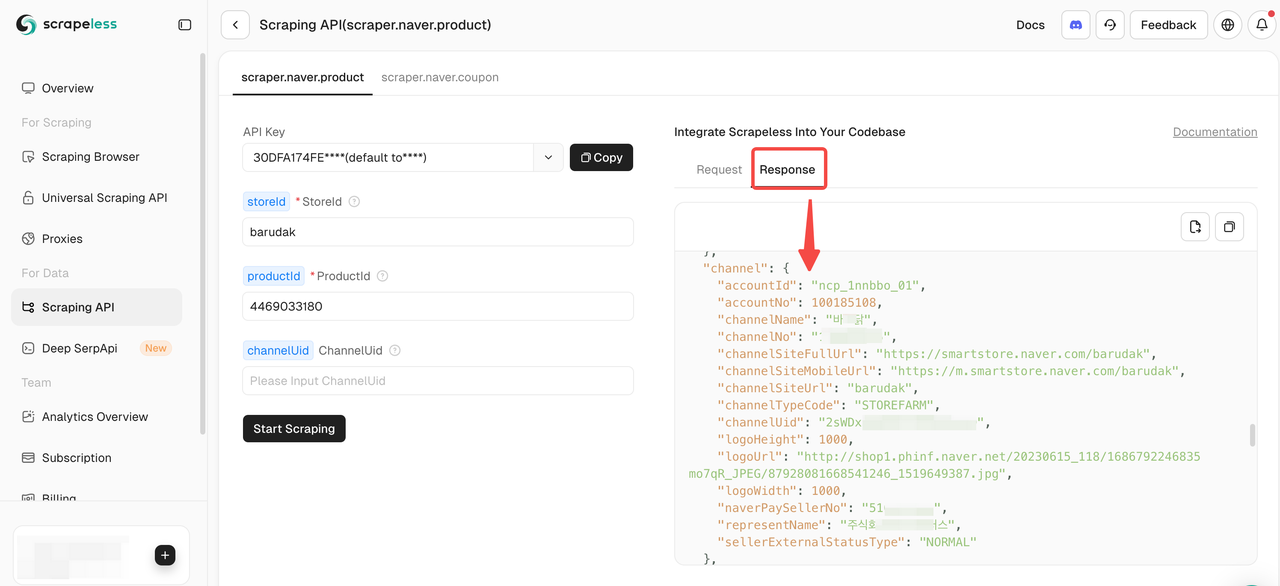
Aqui está um exemplo de código para extrair dados de produtos da Naver. Basta substituir YOUR_SCRAPELESS_API_TOKEN pela sua chave de API real:
Python
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## Opcional
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Erro:", response.status_code, response.text)
return
print("corpo", response.text)
if __name__ == "__main__":
send_request()⏯️ PLANO-B. Extrair dados de produtos da Naver com o Scraping Browser
Se sua equipe prefere programar, o Scraping Browser da Scrapeless é uma excelente escolha. Ele encapsula todas as operações complexas, simplificando a extração eficiente e em grande escala de dados de sites dinâmicos. Ele se integra perfeitamente a ferramentas populares como Puppeteer e Playwright.
Passo 1: Integre-se com o Scraping Browser da Scrapeless
Após entrar no Scraping Browser, basta preencher os parâmetros de configuração à esquerda para gerar automaticamente um script de scraping.
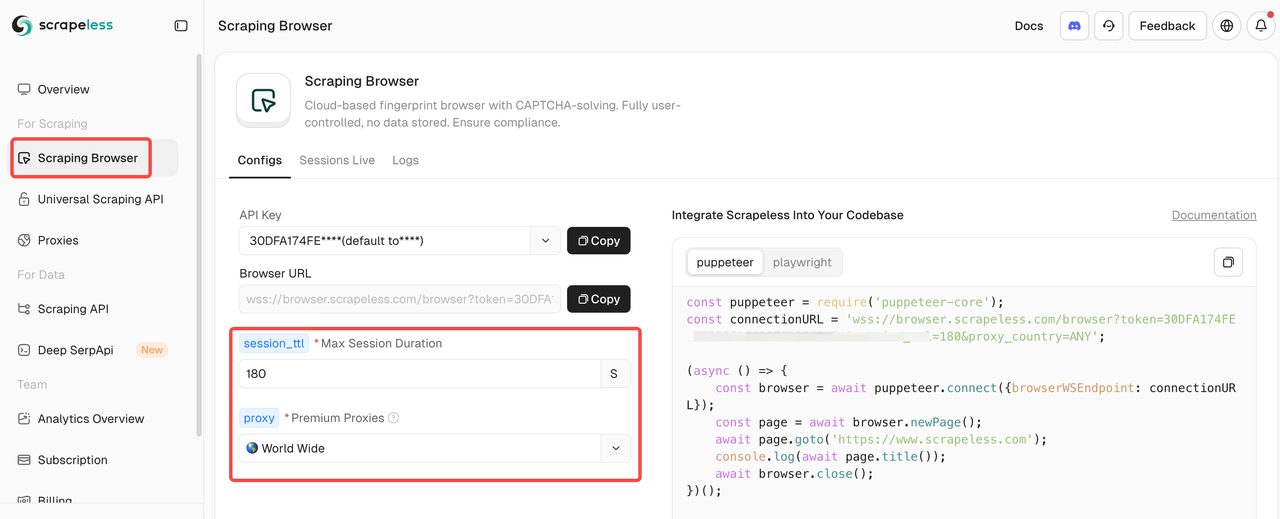
Aqui está um exemplo de código de integração (JavaScript recomendado):
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=" SuaChaveAPI"&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();O Scrapeless combina automaticamente proxies para você, portanto, não há necessidade de configuração adicional ou tratamento de CAPTCHA. Juntamente com a rotação de proxies, gerenciamento de impressão digital do navegador e robustas capacidades de scraping concorrente, o Scrapeless garante a extração em grande escala de dados de produtos da Naver sem detecção, contornando eficientemente bloqueios de IP e desafios de CAPTCHA.
Passo 2: Defina o Formato de Exportação
Agora, você precisa filtrar e limpar os dados extraídos. Considere exportar os resultados no formato CSV para facilitar a análise:
JavaScript
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('Arquivo CSV salvo: naver_product_data.csv');
await browser.close();
})();Leitura adicional: Guia Detalhado do Scraping Browser da Scrapeless
Aqui está nosso script de scraping, como referência:
JavaScript
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { parse } = require('json2csv');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=SuaChaveAPI&session_ttl=180&proxy_country=KR';
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
// Substitua pela URL da página do produto Naver que você realmente deseja rastrear
const url = 'https://smartstore.naver.com/barudak/products/4469033180';
await page.goto(url, { waitUntil: 'networkidle2' });
// Exemplo simples: rastrear título do produto, preço, descrição, etc. (adapte conforme a estrutura real da página)
const productData = await page.evaluate(() => {
const title = document.querySelector('h3._2Be85h')?.innerText || '';
const price = document.querySelector('span._1LY7DqCnwR')?.innerText || '';
const description = document.querySelector('div._2w4TxKo3Dx')?.innerText || '';
return {
title,
price,
description
};
});
console.log('Dados do produto:', productData);
// Exportar para CSV
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('Arquivo CSV salvo: naver_product_data.csv');
await browser.close();
})();Parabéns, você completou com sucesso todo o processo de rastreamento de dados de produtos da Naver!
Considerações Finais
Extrair dados da Naver é um investimento estratégico! No entanto, quando as equipes usam programação para raspar, precisam implementar sistemas adaptativos, coordenar comportamentos de sessão e aderir estritamente às regulamentações da plataforma e às leis de dados da Coreia do Sul. Competir com a arquitetura dinâmica da Naver significa configurar proxies, solucionadores de CAPTCHA e simular operações de usuários reais—todas tarefas que consomem muito trabalho.
Na verdade, não precisamos gastar muito tempo em manutenção! Para alcançar isso, basta aproveitar uma pilha de tecnologia robusta, incluindo ferramentas de automação de navegador e APIs, garantindo a extração de dados de produtos do Naver em escala, de forma escalável e em conformidade, sem se preocupar com bloqueios na web.
Comece seu teste gratuito agora! Por apenas $3 para 1.000 solicitações, é o menor preço da web!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


