
Automatize a Extração de Listagens Imobiliárias com Scrapeless e Fluxos de Trabalho n8n
Advanced Data Extraction Specialist
Na indústria imobiliária, automatizar o processo de coleta das últimas listas de propriedades e armazená-las em um formato estruturado para análise é fundamental para melhorar a eficiência. Este artigo fornecerá um guia passo a passo sobre como usar a plataforma de automação de baixo código n8n, juntamente com o serviço de web scraping Scrapeless, para coletar regularmente listas de aluguel do site imobiliário LoopNet e escrever automaticamente os dados estruturados das propriedades no Google Sheets para fácil análise e compartilhamento.
1. Objetivo e Arquitetura do Fluxo de Trabalho
Objetivo: Buscar automaticamente as últimas listas de venda/aluguel de uma plataforma imobiliária comercial (por exemplo, Crexi / LoopNet) em uma programação semanal.
Contornar mecanismos de anti-scraping e armazenar os dados em um formato estruturado no Google Sheets, facilitando relatórios e visualização de BI.
Arquitetura Final do Fluxo de Trabalho:
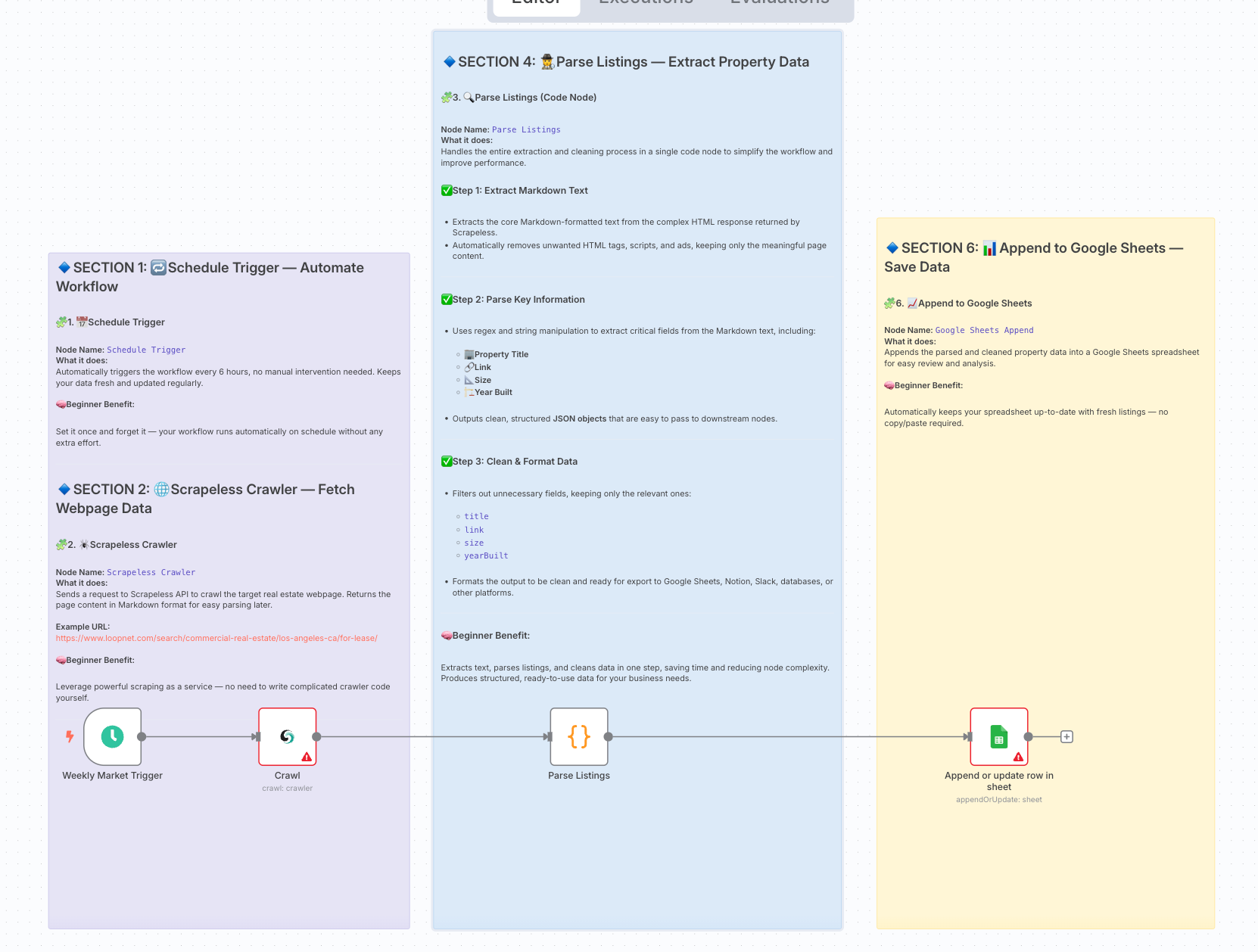
2. Preparação
- Crie uma conta no site oficial da Scrapeless e obtenha sua Chave da API (2.000 requisições gratuitas por mês).
- Faça login no Painel do Scrapeless.
- Em seguida, clique em "Configurações" à esquerda -> selecione "Gerenciamento da Chave da API" -> clique em "Criar Chave da API". Finalmente, clique na Chave da API que você criou para copiá-la.
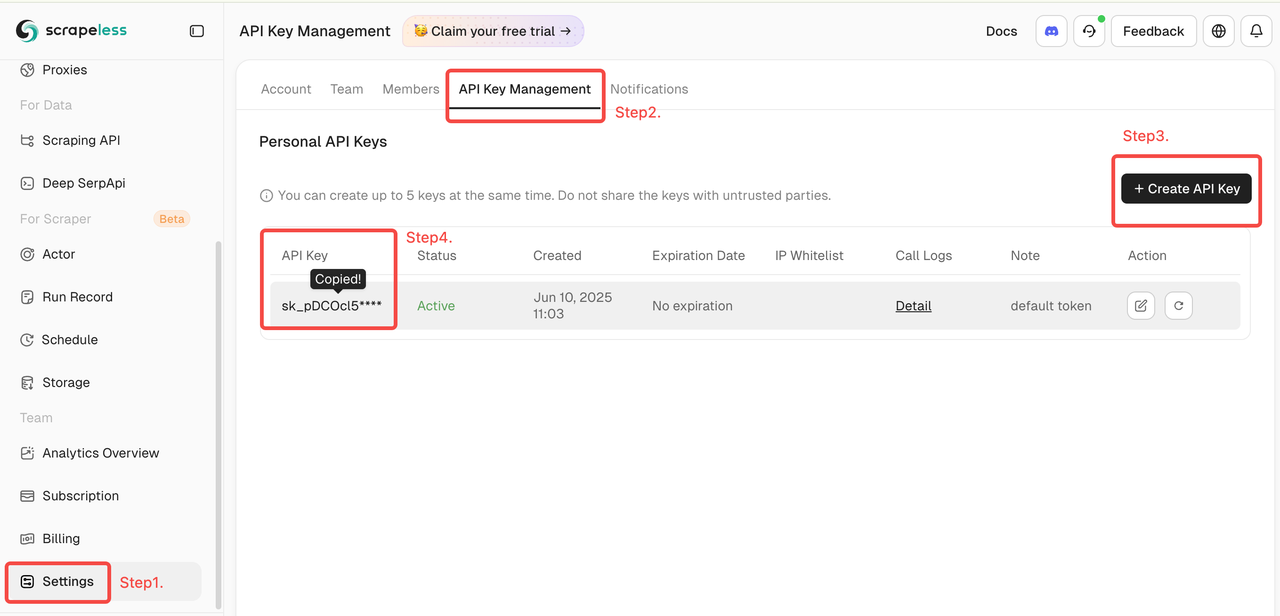
- Certifique-se de ter instalado a versão comunitária do nó Scrapeless no n8n.
- Um documento do Google Sheets com permissões de escrita e as credenciais de API correspondentes.
3. Visão Geral das Etapas do Fluxo de Trabalho
| Etapa | Tipo de Nó | Propósito |
|---|---|---|
| 1 | Gatilho de Programação | Disparar automaticamente o fluxo de trabalho a cada 6 horas. |
| 2 | Raspador Scrapeless | Coletar páginas do LoopNet e retornar o conteúdo coletado em formato markdown. |
| 4 | Nó de Código (Analisar Listagens) | Extrair o campo markdown da saída do Scrapeless; usar regex para analisar o markdown e extrair dados estruturados das listagens de propriedades. |
| 6 | Adicionar ao Google Sheets | Escrever os dados estruturados das propriedades em um documento do Google Sheets. |
4. Configuração Detalhada e Explicação do Código
1. Gatilho de Programação
- Tipo de Nó: Gatilho de Programação
- Configuração: Defina o intervalo para semanal (ou ajuste conforme necessário).
- Propósito: Dispara automaticamente o fluxo de trabalho de coleta de dados conforme programado, sem necessidade de ação manual.
2. Nó de Raspador Scrapeless
- Tipo de Nó: Nó de API Scrapeless (
crawler - crawl) - Configuração:
- URL: Página destino do LoopNet, por exemplo:
https://www.loopnet.com/search/commercial-real-estate/los-angeles-ca/for-lease/ - Chave da API: Insira sua Chave da API do Scrapeless.
- Limitar Páginas: 2 (ajuste conforme necessário).
- URL: Página destino do LoopNet, por exemplo:
- Propósito: Coletar automaticamente o conteúdo da página e emitir a página web em formato markdown.

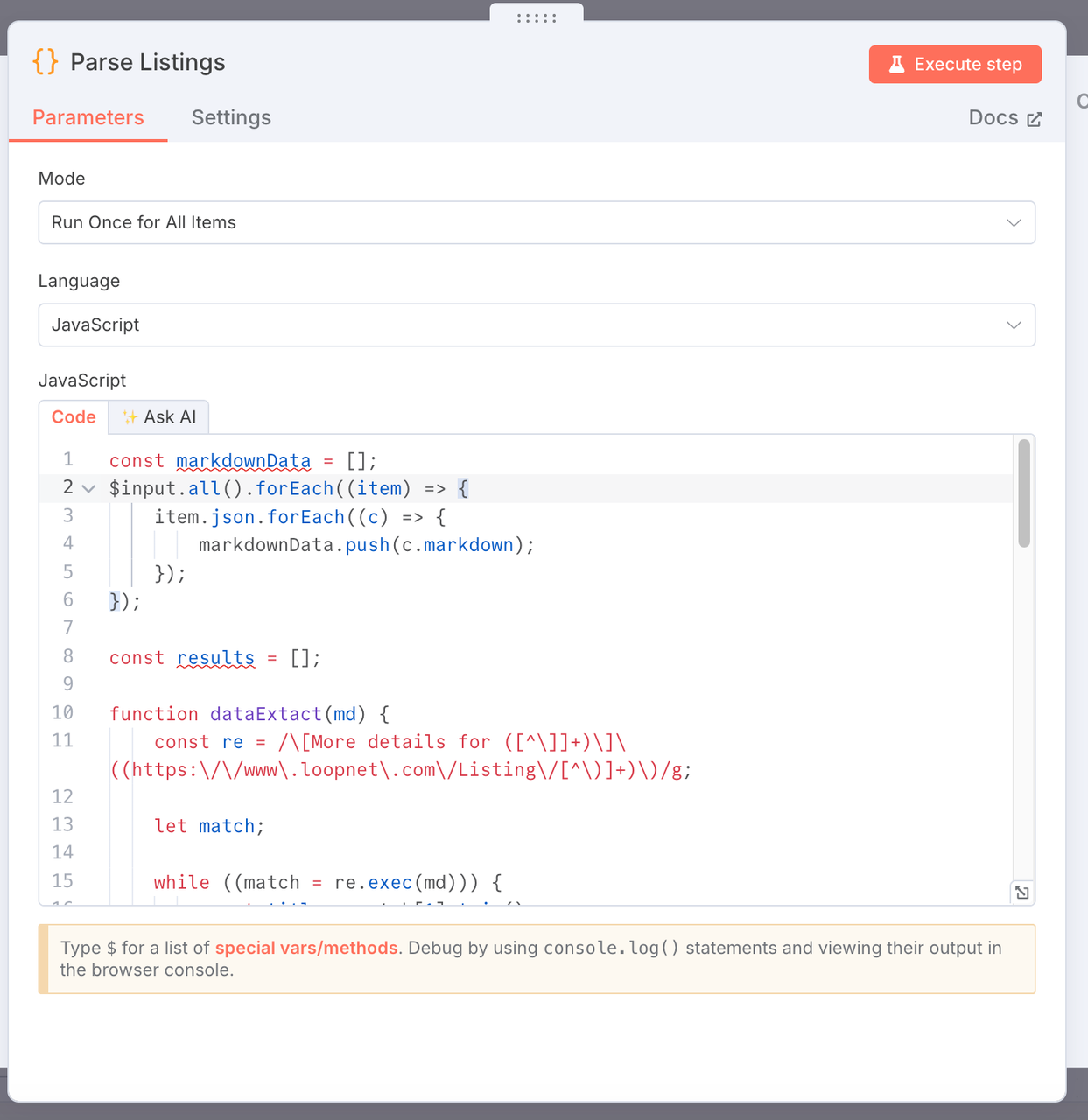
3. Analisar Listagens
- Propósito: Extrair dados-chave sobre imóveis comerciais do conteúdo da página web formatada em markdown coletada pelo Scrapeless e gerar uma lista de dados estruturados.
- Código:
const markdownData = [];
$input.all().forEach((item) => {
item.json.forEach((c) => {
markdownData.push(c.markdown);
});
});
const results = [];
function dataExtact(md) {
const re = /\[Mais detalhes para ([^\]]+)\]\((https:\/\/www\.loopnet\.com\/Listing\/[^\)]+)\)/g;
let match;
while ((match = re.exec(md))) {
const title = match[1].trim();
const link = match[2].trim()?.split(' ')[0];
// Extrair um trecho de contexto ao redor do match
const context = md.slice(match.index, match.index + 500);
// Extrair faixa de tamanho, e.g. "10.000 - 20.000 SF"
const sizeMatch = context.match(/([\d,]+)\s*-\s*([\d,]+)\s*SF/);
const sizeRange = sizeMatch ? `${sizeMatch[1]} - ${sizeMatch[2]} SF` : null;
// Extrair ano de construção, e.g. "Construído em 1988"
const yearMatch = context.match(/Construído em\s*(\d{4})/i);
const yearBuilt = yearMatch ? yearMatch[1] : null;
// Extrair URL da imagemconst imageMatch = context.match(/![[]]*]((https://images1.loopnet.com[)]+))/);
const image = imageMatch ? imageMatch[1] : null;
results.push({
json: {
title,
link,
size: sizeRange,
yearBuilt,
image,
},
});
}
// Retornar o markdown original se nenhuma correspondência for encontrada (para depuração)
if (results.length === 0) {
return [
{
json: {
error: 'Nenhuma listagem correspondente',
raw: md,
},
},
];
}}
markdownData.forEach((item) => {
dataExtact(item);
});
return results;
### 4. Google Sheets Append (Nó Google Sheets)
- **Operação:** Adicionar
- **Configuração:**
- **Selecione o arquivo de planilhas Google desejado.**
- **Nome da Planilha:** Por exemplo, `Relatório do Mercado Imobiliário`.
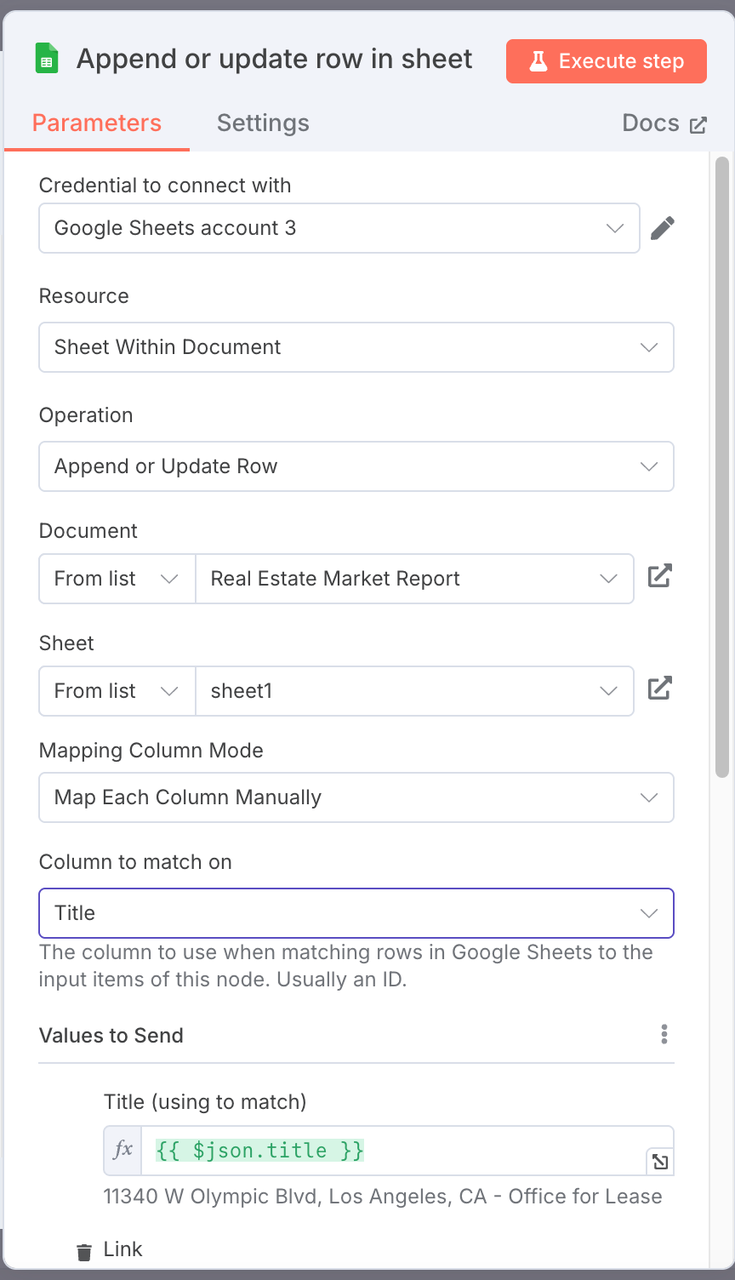
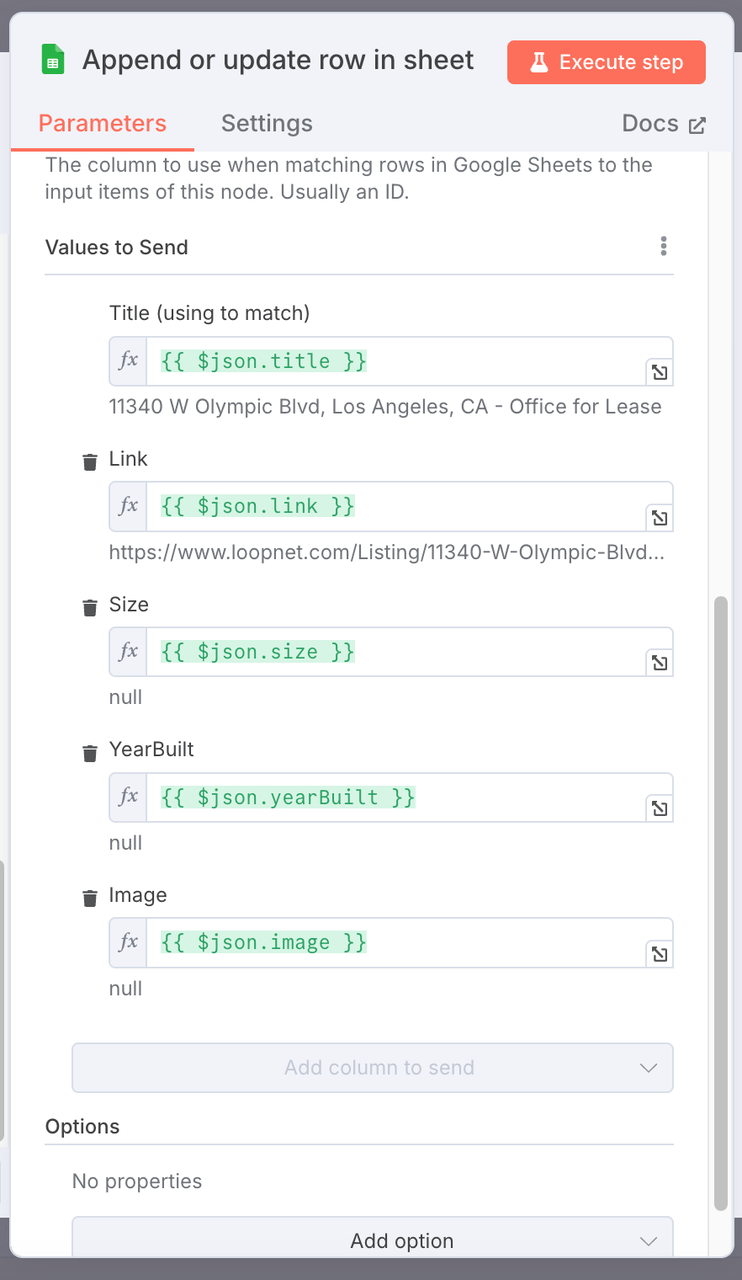
- **Configuração de Mapeamento de Colunas:** Mapeie os campos de dados estruturados da propriedade para as colunas correspondentes na planilha.
| Coluna do Google Sheets | Campo JSON Mapeado |
|-------------------------|-----------------------|
| Título | `{{ $json.title }}` |
| Link | `{{ $json.link }}` |
| Tamanho | `{{ $json.size }}` |
| AnoConstruído | `{{ $json.yearBuilt }}`|
| Imagem | `{{ $json.image }}` |
> Nota:
É recomendado que o nome da sua planilha deve ser consistente com o nosso. Se você precisar modificar um nome específico, precisa prestar atenção na relação de mapeamento.
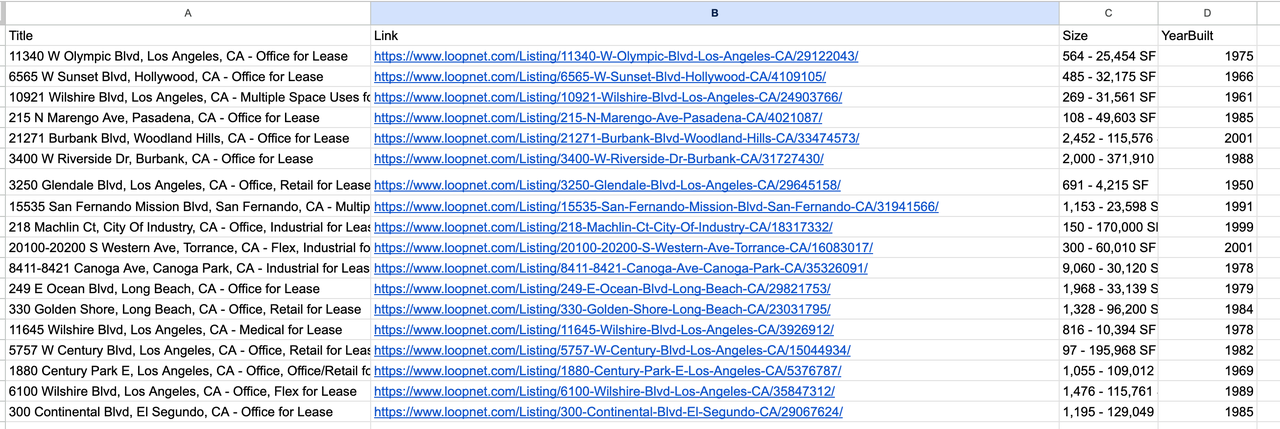
### 5. Saída de Resultados
## 5. Fluxograma do Workflow

## 6. Dicas de Depuração
- Ao executar cada nó **Código**, abra a saída do nó para verificar o formato dos dados extraídos.
- Se o nó **Parse Listings** não retornar dados, verifique se a saída do Scrapeless contém conteúdo markdown válido.
- O nó **Format Output** é principalmente usado para limpar e normalizar a saída para garantir o mapeamento correto dos campos.
- Ao conectar o nó **Google Sheets Append**, certifique-se de que sua autorização OAuth está configurada corretamente.
---
## 7. Otimização Futura
- **Deduplicação:** Evitar escrever listagens de propriedades duplicadas.
- **Filtragem por Preço ou Tamanho:** Adicionar filtros para direcionar listagens específicas.
- **Notificações de Novas Listagens:** Enviar alertas via e-mail, Slack, etc.
- **Automação Multi-Cidade & Multi-Página:** Automatizar a extração em diferentes cidades e páginas.
- **Visualização de Dados & Relatórios:** Criar painéis e gerar relatórios a partir dos dados estruturados.Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


