7 métodos para ignorar o CAPTCHA durante o web scraping
Web Data Collection Specialist
Está a tentar copiar um site, mas o CAPTCHA está a bloqueá-lo? Qualquer esforço de web scraping pode ser prejudicado pelos CAPTCHAs, que são cada vez mais difíceis de resolver.
Felizmente, existem alguns métodos para ignorar o CAPTCHA durante o web scraping, e vamos abordar 7 métodos testados e comprovados neste artigo.
CAPTCHA: O que é isto?
CAPTCHA significa "Teste de Turing Público Completamente Automatizado para Diferenciar Computadores e Humanos". Para proteger os sites de possíveis danos e comportamentos semelhantes aos dos bots, como o scraping, tenta bloquear o acesso de programas automatizados. Antes de visitar um site seguro, o utilizador precisa geralmente de realizar um teste conhecido como CAPTCHA.
Os web scrapers têm dificuldade em contornar os CAPTCHAs porque são difíceis de serem compreendidos pelos robôs, mas fáceis de serem ultrapassados pelos humanos. O utilizador precisa de verificar a sua identidade humana assinalando a caixa da imagem abaixo, por exemplo. Este comando não pode ser obedecido intuitivamente por um bot.
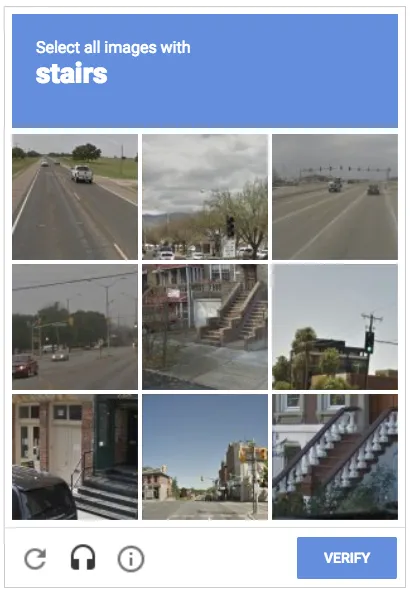
Como é que o Web Scraping é bloqueado pelo CAPTCHA?
A implementação de um website determina as diferentes formas que os CAPTCHAs assumem. Alguns estão sempre presentes quando visita um website, mas a maioria é o resultado de ações automatizadas, como o web scraping.
Um CAPTCHA pode aparecer durante o web scraping por qualquer um dos seguintes motivos:
- Envio de várias consultas num curto espaço de tempo a partir do mesmo IP
- Ações automatizadas que se repetem, como clicar no mesmo link ou visitar as mesmas páginas
- Interações automatizadas suspeitas, incluindo navegar rapidamente em muitas páginas sem interagir, clicar rapidamente ou preencher um formulário rapidamente
- Utilizar sites proibidos e ignorar o ficheiro robots.txt.
É possível ignorar o CAPTCHA?
Embora não seja uma operação simples, também pode ignorar os CAPTCHAs. É aconselhável tentar reenviar o pedido se o CAPTCHA estiver bloqueado e evitar que este apareça.
Também pode responder ao CAPTCHA, mas isso custará muito mais dinheiro e terá uma taxa de sucesso muito mais baixa. A maioria dos serviços de resolução de CAPTCHA utiliza solucionadores humanos para processar consultas e depois entregar a resposta. Este método reduz significativamente a eficácia do seu raspador e abranda-o.
Ignorar CAPTCHAs é mais fiável, pois são necessárias todas as precauções necessárias para interromper os comportamentos automatizados que os causam. Veremos abaixo as melhores formas de superar os CAPTCHAs durante o web scraping para que possa recuperar a informação necessária.
Como ignorar o CAPTCHA quando se faz web scraping
Esta secção irá abordar sete métodos para contornar as irritantes barreiras do CAPTCHA durante a web scraping em Python.
Método1. Girar IPs
A técnica mais fácil para um sistema defensivo interromper o acesso ao desenvolver um rastreador para URL e extração de dados é proibir IPs. Se o servidor receber muitos pedidos do mesmo endereço IP num curto período de tempo, sinalizarão esse endereço.
Para o evitar, utilizar vários endereços IP é a solução mais simples. No entanto, é difícil, senão impossível, modificar isto quando se trata de servidores. Portanto, teria de utilizar um servidor proxy para processar os seus pedidos a fim de alternar os IPs. Com eles, os seus pedidos iniciais não serão alterados, mas o servidor de destino verá o seu endereço IP e não o seu.
Método2. Alternar agentes de utilizador
Uma string que o navegador web de um utilizador envia para um servidor é designada por User Agent (UA). Encontra-se no cabeçalho HTTP e fornece informações sobre o sistema operativo e o tipo e versão do browser. acedido utilizando um browser do lado do cliente e JavaScript.
Embora incluam várias estruturas e dados, a maioria dos navegadores adere normalmente ao mesmo formato:
(<informação do sistema>) Mozilla/5.0 <extensões> <plataforma> (<detalhes da plataforma>)
Para o Chrome (Chromium), por exemplo, uma string de agente de utilizador pode ser Mozilla/5.0 (Windows NT 10.0; Win64; x64). AppleWebKit/537.36 (semelhante ao Gecko em KHTML) 109.0.0.0 Safari/537.36; Cromo. Dividindo, diz como se chama o browser (Chrome), em que versão está a correr (109.0.0.0) e em que sistema operativo está a correr (Windows NT 10.0, CPU de 64 bits).
A utilização de strings UA para scraping pode ajudar a disfarçar o seu spider como um navegador da web, uma vez que ajudam os servidores da web a identificar os tipos de pedidos dos navegadores (e bots).
Tenha cuidado: se empregar um agente de utilizador constituído incorretamente, o seu script de extração de dados será interrompido.
Método3. Utilize um solucionador CAPTCHA
Os serviços conhecidos como solucionadores de CAPTCHA permitem-lhe raspar páginas web continuamente, resolvendo CAPTCHAs automaticamente. Um exemplo bem conhecido é o Scrapeless.
Está cansado de CAPTCHAs e bloqueios contínuos de web scraping?
Scrapeless: a melhor solução completa de raspagem online disponível!
Utilize o nosso formidável kit de ferramentas para libertar todo o potencial da sua extração de dados:
Best CAPTCHA solver
Resolução automatizada de CAPTCHAs complexos para garantir uma raspagem contínua e suave.
Experimente gratuitamente!
Método4. Evite armadilhas ocultas
Sem que saiba, os sites empregam armadilhas astutas para identificar bots. A armadilha do honeypot, por exemplo, engana as máquinas para que interajam com recursos ocultos, como links ou campos de formulários invisíveis.
Os utilizadores humanos não conseguem ver estas armadilhas; apenas os bots os conseguem ver. Quando os utilizadores interagem com estas armadilhas, o site pode identificar atividades incomuns e alertar o endereço IP do bot.
No entanto, pode aprender como reconhecer e operar estas armadilhas. Um método é procurar elementos escondidos no HTML do site e evitar elementos com nomes ou valores estranhos.
Método5. Simular o comportamento humano
A replicação precisa do comportamento humano é necessária para contornar o CAPTCHA durante o web scraping. Por exemplo, o envio de vários pedidos em questão de milissegundos pode levar a uma restrição de IP com limite de taxa.
Adicionar tempo entre pedidos para diminuir a frequência das suas consultas é um método para imitar o comportamento humano. Para tornar mais lógico, pode variar os tempos. A utilização de backoffs exponenciais é uma estratégia adicional para prolongar o período de espera após cada pedido mal sucedido.
Método6. Salvar biscoitos
A sua arma oculta preferida para web scraping podem ser os cookies. Estes pequenos ficheiros contêm informações sobre como interage com um website, como as suas preferências e o estado de login.
Os cookies podem ser úteis se estiver a tentar iniciar sessão, pois evitam o trabalho de iniciar sessão repetidamente e diminuem a possibilidade de ser descoberto. Além disso, os cookies permitem-lhe pausar ou continuar uma sessão de web scraping mais tarde.
Utilizando navegadores headless como o Selenium e clientes HTTP como o Requests, pode guardar e carregar cookies programaticamente e recuperar dados sem ser notado.
Método7. Ocultar indicadores de automatização
Mesmo utilizando um navegador headless, deve ter cuidado, pois os sites podem detetar tráfego automatizado verificando sinais reveladores de automação, como as impressões digitais do navegador.
Plugins como o Selenium Stealth, por outro lado, podem ser utilizados para automatizar movimentos do rato e do teclado que se assemelham aos de uma pessoa, sem chamar a atenção para si.
Resumindo
Embora impedir que os CAPTCHAs impeçam o web scraping seja uma tarefa difícil, agora tem as ferramentas necessárias para enfrentar este problema. As iniciativas de grande escala, no entanto, podem exigir mais tempo e trabalho para executar plenamente as estratégias acima referidas.
Com o Scrapeless, pode obter todas as ferramentas necessárias para contornar CAPTCHAs e outros anti-bots de forma eficiente.
Veja por si mesmo usando Scrapeless gratuitamente!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


