
Servidor MCP-RAG: Guia Completo de Configuração e Uso
Advanced Data Extraction Specialist
Na era das aplicações de IA em rápida evolução, a necessidade de sistemas que possam combinar conhecimento de domínio estático com informações da web em tempo real nunca foi tão grande. Modelos tradicionais de geração aumentada por recuperação (RAG) geralmente dependem de dados pré-indexados, limitando sua capacidade de resposta a novos desenvolvimentos. O MCP-RAG Server preenche essa lacuna integrando busca semântica por vetor (via Qdrant) com capacidades de busca na web em tempo real (via Scrapeless), oferecendo uma base pronta para produção para sistemas inteligentes de resposta a perguntas. Seja você uma empresa construindo agentes de conhecimento internos ou um desenvolvedor experimentando com integração de LLM, este guia o conduzirá pelo processo completo de configuração e uso do MCP-RAG—assegurando que você esteja preparado para implantar um sistema de conhecimento em IA moderno e responsivo.
O que é o MCP-RAG Server?
O MCP-RAG Server é um sistema baseado em TypeScript que combina capacidades de busca por vetor com busca na web em tempo real para criar um sistema aprimorado de conhecimento em IA. Ele fornece três ferramentas principais:
- Recuperação de FAQ com Aprendizado de Máquina - Busca semântica através do seu banco de dados por vetores
- Adição de Documentos - Expanda sua base de conhecimento com novas informações
- Busca na Web - Obtenha informações atuais da internet
Este sistema resolve limitações críticas da IA: conhecimento desatualizado, falta de especialização em domínio e recuperação de informações ineficiente.
Introdução ao Scrapeless: O motor de aprimoramento inteligente da web do RAG
A API de Scraping do Google Search Scrapeless é uma potente API de web scraping que oferece acesso estável aos resultados dos motores de busca sem o risco de ser bloqueado por crawlers tradicionais.
Por que o Scrapeless é essencial para sistemas RAG
Os sistemas RAG tradicionais são limitados por suas bases de conhecimento estáticas. O Scrapeless transforma o MCP-RAG Server ao:
- Recuperação de informações em tempo real: Acesso às informações mais recentes da web
- Aprimoramento da base de conhecimento: Atualize continuamente seu banco de dados por vetores com dados atuais
- Busca complementar: Preencha lacunas quando o conhecimento interno for insuficiente
- Perspectivas diversas: Busque de diferentes regiões geográficas e idiomas
Como o Scrapeless funciona no MCP-RAG?
O Scrapeless integra-se ao MCP-RAG Server através de uma classe de encapsulamento em TypeScript chamada ScrapelessClient para alcançar as seguintes capacidades:
typescript
export class ScrapelessClient {
private api: AxiosInstance;
constructor(config: ScrapelessConfig) {
this.api = axios.create({
baseURL: config.baseURL,
headers: {
"Content-Type": "application/json",
"x-api-token": config.token,
},
});
}
async searchWeb(params: WebSearchParams) {
try {
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// Tratamento de erro...
}
}
}Recursos Avançados Suportados
| Recurso | Descrição |
|---|---|
| Integração com Google Search | Usa o ator scraper.google.search para buscar resultados de pesquisa |
| Geo-Targeting | Controla país/região usando o parâmetro gl |
| Suporte Multilíngue | Retorna resultados em diferentes idiomas usando o parâmetro hl |
| Troca de Domínio de Motor de Busca | Suporta múltiplos domínios como google.de, google.fr, etc. |
| Gerenciamento Automático de Proxy | Habilita rotação de proxy por padrão para evitar bloqueio de IP |
Guia de Implantação do Sistema Inteligente de Resposta a Perguntas (Baseado em Busca por Vetor + Busca na Web em Tempo Real)
Passo 1: Inicializar a estrutura do projeto e instalar dependências
Clone e configure o projeto:
git clone git@github.com:scrapeless-ai/mcp-rag-server.git
cd mcp-rag-serverAnalise a estrutura do projeto:
mcp-rag-server/
├── src/
│ ├── config.ts
│ ├── index.ts
│ ├── server.ts
│ ├── qdrant-client.ts
│ └── scrapeless-client.ts
├── package.json
├── tsconfig.json
└── .envInstale as dependências:
npm install💡Problema Resolvido:
Assegure-se de que o ambiente do projeto TypeScript esteja pronto, as dependências necessárias (como @modelcontextprotocol/sdk, axios, zod, etc.) tenham sido integradas, e as definições de tipo exigidas para o desenvolvimento tenham sido configuradas automaticamente.
Passo 2: Configuração do Ambiente
Crie o arquivo `.env`:
QDRANT_URL=http://localhost:6333
QDRANT_API_KEY=
QDRANT_COLLECTION=ml_faq_collection
SCRAPELESS_KEY=sua_chave_api_scrapeless
SCRAPELESS_BASE_URL=https://api.scrapeless.com
Entendendo a configuração (do config.ts):
const QDRANT_URL = process.env.QDRANT_URL?.trim() || "http://localhost:6333";
const QDRANT_API_KEY = process.env.QDRANT_API_KEY?.trim() || "";
const QDRANT_COLLECTION = process.env.QDRANT_COLLECTION?.trim() || "ml_faq_collection";
const SCRAPELESS_KEY = process.env.SCRAPELESS_KEY?.trim();
const SCRAPELESS_BASE_URL = process.env.SCRAPELESS_BASE_URL?.trim() || "https://api.scrapeless.com"; 💡Problema resolvido:
Fornecer parâmetros de conexão corretos para dependências externas (banco de dados vetorial Qdrant e pesquisa em tempo real Scrapeless). Valores padrão e processamento trim() estão embutidos no código de configuração para evitar erros de formato de variável. Se a Chave do Scrapeless estiver faltando, um aviso será emitido.
Passo 3: Configurar o Banco de Dados Vetorial Qdrant
Iniciar Qdrant com Docker:
# Baixar imagem Qdrant
docker pull qdrant/qdrant
# Executar contêiner Qdrant com persistência de dados
docker run -d \
--name qdrant-server \
-p 6333:6333 \
-p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
Criar uma coleção vetorial de FAQ:
curl -X PUT 'http://localhost:6333/collections/ml_faq_collection' \
-H 'Content-Type: application/json' \
--data-raw '{
"vectors": {
"size": 1536,
"distance": "Cosine"
}
}'
💡Problema resolvido:
Configurar o armazenamento de recuperação de vetores semânticos, usar 1536 dimensões e similaridade cosseno, e ser compatível com a saída do gerador de embeddings e chamadas do QdrantClient.
Passo 4: Integrar pesquisa em tempo real Scrapeless
Obter a Chave da API Scrapeless:
- Visite Scrapeless e crie uma conta
- Recupere seu Token de API no painel
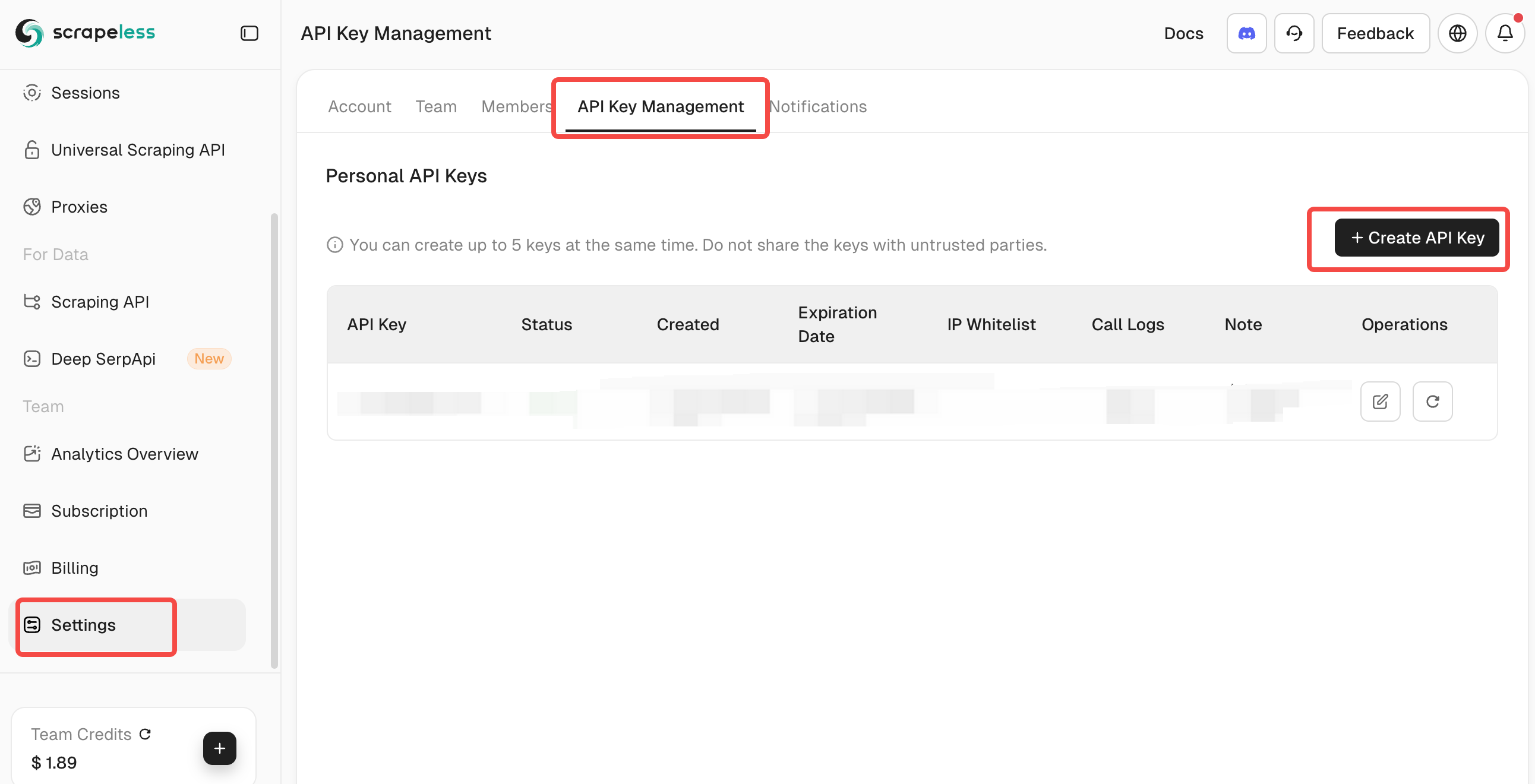
- Adicione-o ao arquivo .env sob SCRAPELESS_KEY
Testar Conexão com Scrapeless:
# Testar conexão com a API (opcional)
curl -X POST 'https://api.scrapeless.com/api/v1/scraper/request' \
-H 'Content-Type: application/json' \
-H 'x-api-token: SUA_CHAVE_API' \
-d '{"actor": "scraper.google.search", "input": {"q": "consulta de teste"}}'
Problema Resolvido: Esta etapa garante que sua API Scrapeless esteja configurada corretamente. O sistema inclui validação para verificar se a chave da API está definida, evitando erros em tempo de execução durante buscas na web.
Passo 5: Construir o Projeto TypeScript
Compilar TypeScript para JavaScript:
npm run build
O que acontece durante a compilação (do package.json):
language
{
"scripts": {
"build": "tsc && chmod 755 build/index.js",
"start": "node build/index.js"
}
} Verificar a saída da compilação:
language
ls build/
# Deve exibir: index.js, server.js, config.js, qdrant-client.js, scrapeless-client.js
Problema Resolvido:
Esta etapa compila TypeScript em JavaScript e garante que o ponto de entrada principal seja executável. O processo de construção gera módulos ES (conforme especificado por "type": "module" no package.json) compatíveis com Node.js.
Passo 6: Iniciar o Servidor MCP
language
Executar o servidor:
npm start O que acontece durante a inicialização (do index.ts):
async function main() {
try {
console.log("Iniciando o Servidor Agentic RAG MCP...");
const transport = new StdioServerTransport();
await server.connect(transport);
console.log("Servidor MCP está rodando na porta 8080");
} catch (error) {
console.error("Erro fatal em main():", error);
process.exit(1);
}
}
Problema Resolvido:
Esta etapa inicia o servidor MCP usando transporte STDIO para comunicação. O servidor se inicializa com tratamento de erros adequado e registro em log.
Ao seguir os seis passos acima, você terá construído um sistema de perguntas e respostas impulsionado por IA com:
- Capacidades de QA semântica (impulsionadas pelo banco de dados vetorial Qdrant)
- Aumento da web em tempo real (via integração com a API Scrapeless)
- Infraestrutura pronta para LLM (baseada no padrão do protocolo MCP)
Isso forma uma base sólida para empresas ou desenvolvedores implantarem rapidamente um sistema RAG (Geração Aumentada por Recuperação) pronto para produção.
Explicação detalhada dos componentes principais
QdrantClient: motor de processamento vetorial
QdrantClient fornece funções de geração de embedding e interação com o banco de dados vetorial. O exemplo usa um método de embedding determinístico simples para demonstração:
private generateEmbedding(text: string): number[] {
const seed = [...text].reduce((sum, char) => sum + char.charCodeAt(0), 0) % 10000;
const vector: number[] = [];
let value = seed;
for (let i = 0; i < 1536; i++) {
value = (value * 48271) % 2147483647;
vector.push((value / 2147483647) * 2 - 1);
}
return vector;
}
Características principais:
- Geração de embedding determinística simples
- Operações de upsert para adicionar documentos
- Busca semântica com limite de pontuação configurável
- Tratamento adequado de erros e respostas de fallback
ScrapelessClient: Interface do motor de busca na web
ScrapelessClient acessa a API Scrapeless para implementar a busca na web e suporta parâmetros avançados de busca:
async searchWeb(params: WebSearchParams) {
try {
if (!this.api.defaults.headers.common["x-api-token"]) {
throw new Error("A chave da API Scrapeless não está definida");
}
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// Tratamento de erro...
}
}Principais recursos:
- Integração de busca do Google via Scrapeless
- País, idioma e domínio configuráveis
- Tratamento abrangente de erros
- Validação da chave da API
Ferramentas do Servidor MCP
O arquivo server.ts define três ferramentas principais:
- recuperação-de-faq-aprendizado-de-máquina:
- Pesquisa no banco de dados vetorial por conceitos de ML
- Usa correspondência de semelhança semântica
- Retorna resultados formatados com pontuações
- adicionar-documento-a-faq:
- Adiciona novos documentos à base de conhecimento
- Suporta metadados (categoria, fonte, tags)
- Tratamento adequado de erros com respostas detalhadas
- busca-web-scrapeless:
- Realiza buscas na web via API Scrapeless
- Parâmetros de busca configuráveis
- Recuperação de informações em tempo real
Guia de Uso: Usando o sistema com Scrapeless
Exemplos Básicos de Uso
Pesquise na base de conhecimento:
Use a recuperação-de-faq-aprendizado-de-máquina para encontrar informações sobre redes neuraisAdicione novas informações:
Use adicionar-documento-a-faq para adicionar isso:
Texto: "Florestas aleatórias são métodos de aprendizado de conjunto..."
Categoria: "Métodos de Conjunto"
Tags: ["florestas aleatórias", "aprendizado de conjunto"]Pesquise na web com Scrapeless:
language
Use busca-web-scrapeless para encontrar desenvolvimentos recentes em IAUso avançado de Scrapeless:
language
Use busca-web-scrapeless com:
Consulta: "últimos recursos do PyTorch"
País: "uk"
Idioma: "en"
Domínio: "google.co.uk"Fluxos de Trabalho Avançados com Integração Scrapeless
Aprimoramento da base de conhecimento:
1. Use busca-web-scrapeless para encontrar "últimos modelos de transformadores 2024"
2. Use adicionar-documento-a-faq para adicionar descobertas relevantes
3. Use recuperação-de-faq-aprendizado-de-máquina para verificar se a informação é pesquisávelVerificação de informações:
1. Use recuperação-de-faq-aprendizado-de-máquina para verificar o conhecimento existente
2. Use busca-web-scrapeless para encontrar informações atuais
3. Compare e atualize a base de conhecimento conforme necessárioConstrução de conhecimento multilíngue:
1. Use busca-web-scrapeless com country="de" e language="de" para encontrar pesquisas de IA em alemão
2. Use adicionar-documento-a-faq para adicionar resumos traduzidos
3. Construa uma base de conhecimento multilíngueIntegração com Claude Desktop
O projeto inclui uma configuração de exemplo para integração com Claude Desktop:
{
"mcpServers": {
"MCP-RAG-app": {
"command": "node",
"args": ["seu-caminho/para/build/index.js"],
"host": "127.0.0.1",
"port": 8080,
"timeout": 30000,
"env": {
"QDRANT_URL": "http://localhost:6333",
"QDRANT_API_KEY": "",
"QDRANT_COLLECTION": "ml_faq_collection",
"SCRAPELESS_KEY": "SCRAPELESS_KEY"
}
}
}
}Problemas e Soluções Comuns
- Erros de construção:
- Garantir que a versão do Node.js seja >= 18
- Verifique a compilação do TypeScript: npx tsc --noEmit
- Erros em tempo de execução:
- Verifique se o Qdrant está em execução: curl http://localhost:6333/health
- Verifique se as variáveis de ambiente estão configuradas corretamente
- Garantir que a chave da API Scrapeless seja válida
- Problemas específicos do Scrapeless:
- Verifique se a chave da API está configurada corretamente no ambiente
- Verifique as cotas e limites da API no painel do Scrapeless
- Assegure-se de que a configuração do endpoint da API esteja correta
- Problemas de conexão:
- Verifique se as portas estão disponíveis (6333 para Qdrant)
- Verifique as configurações do firewall
- Verifique se os contêineres Docker estão em execução
Benefícios do Sistema Combinado
A integração do Scrapeless com o Qdrant cria um poderoso sistema híbrido:
- Conhecimento Estático + Dinâmico: Combine sua base de conhecimento curada com dados da web em tempo real
- Busca Inteligente: Use busca semântica para dados internos e busca por palavra-chave para conteúdo da web
- Aprimoramento Contínuo: Atualize automaticamente sua base de conhecimento com informações novas
- Perspectiva Global: Acesse informações de diferentes regiões e idiomas
- Confiabilidade: O Scrapeless garante acesso contínuo à web sem problemas de bloqueio
Conclusão
O Servidor MCP-RAG e o Scrapeless implementam um sistema inteligente de perguntas e respostas altamente escalável e atualizado em tempo real. Os valores centrais incluem:
- Compreensão semântica: entender o contexto por meio da similaridade vetorial
- Acesso em tempo real às informações: acessar o Scrapeless para obter o conteúdo mais recente da web
- Integração de protocolo padrão: usando o protocolo MCP, é fácil conectar-se a plataformas como Claude.
- Configuração flexível: coleção de base de conhecimento personalizável e ferramentas de pesquisa
- Plataforma inteligente voltada para o futuro: suporte a aprimoramento dinâmico do conhecimento, suporte a vários idiomas e rastreamento inteligente na web.
A adição do Scrapeless faz com que o sistema deixe de ser apenas uma base de conhecimento estática, mas sim um motor de conhecimento em IA com visão global e capacidades de aprendizado contínuo.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


