
Guia de Integração MCP: MCP do Chrome DevTools, MCP do Playwright e MCP do Scrapeless Browser
Expert Network Defense Engineer
Este guia apresenta três servidores do Model Context Protocol (MCP) — Chrome DevTools MCP, Playwright MCP e Scrapeless Browser MCP.
Visão Geral: Escolhendo o MCP Certo
| Tipo de MCP | Stack Tecnológica | Vantagens | Ecossistema Principal | Melhor Para |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | Padrão oficial, robusto, ferramentas de análise de desempenho profundas. | Amplo (Gemini, Copilot, Cursor) | Automação CI/CD, fluxos de trabalho entre IDEs e auditorias de desempenho aprofundadas. |
| Playwright MCP | Node.js / Playwright | Usa árvore de acessibilidade em vez de pixels; determinística e amigável a LLM sem visão. | Amplo (VS Code, Copilot) | Automação confiável e estruturada, menos propensa a falhas devido a pequenas mudanças na UI. |
| Scrapeless Browser MCP | Serviço em Nuvem | Zero configuração local, navegadores em nuvem escaláveis, lida com sites complexos e medidas anti-bot. | Baseado em API (Qualquer cliente) | Tarefas de automação em larga escala e interação com sites que possuem forte detecção de bots. |
Um Navegador em Nuvem, Integrações Infinitas
Os três MCPs — Chrome DevTools MCP, Playwright MCP e Scrapeless Browser MCP — compartilham uma base: todos se conectam ao Scrapeless Cloud Browser.
Ao contrário da automação de navegadores locais tradicionais, o Scrapeless Browser é executado inteiramente na nuvem, oferecendo flexibilidade e escalabilidade incomparáveis para desenvolvedores e agentes de IA.
Aqui está o que o torna realmente poderoso:
- Integração Seamless: Totalmente compatível com Puppeteer, Playwright e CDP, permitindo migração sem esforço de projetos existentes com uma única linha de código.
- Cobertura Global de IP: Acesso a pools de IP residenciais, de ISPs e ilimitados em mais de 195 países, a uma taxa transparente e econômica (US$ 0,6–1,8/GB). Perfeito para automação de dados da web em larga escala.
- Perfis Isolados: Cada tarefa é executada em um ambiente dedicado e persistente, garantindo isolamento de sessão, gerenciamento de múltiplas contas e estabilidade a longo prazo.
- Escalonamento simultâneo ilimitado: Lance instantaneamente 50–1000+ instâncias de navegador com infraestrutura de autoescalonamento — sem configuração de servidor, sem gargalos de desempenho.
- Nós de Edge em Todo o Mundo: Implante em múltiplos nós globais para latência ultra-baixa e iniciação de 2–3× mais rápida do que outros navegadores em nuvem.
- Anti-Detecção: Soluções integradas para reCAPTCHA, Cloudflare Turnstile e AWS WAF, garantindo automação ininterrupta mesmo sob camadas de proteção rigorosas.
- Depuração Visual: Alcançar depuração interativa humano-máquina e monitoramento em tempo real do tráfego de proxy via Live View. Reproduzir sessões página por página através das Gravações de Sessão para identificar rapidamente problemas e otimizar operações.
Chrome DevTools MCP
Chrome DevTools MCP é um servidor Model-Context-Protocol (MCP) que permite que assistentes de codificação em IA — como Gemini, Claude, Cursor ou Copilot — controlem e inspecionem um navegador Chrome ao vivo para automação confiável, depuração avançada e análise de desempenho.
Principais Recursos
- Obter insights de desempenho: Usa o Chrome DevTools para registrar rastreamentos e extrair insights acionáveis de desempenho.
- Depuração avançada de navegador: Analisar solicitações de rede, tirar capturas de tela e verificar o console do navegador.
- Automação confiável: Usa Puppeteer para automatizar ações no Chrome e aguarda automaticamente os resultados das ações.
Requisitos
- Node.js v20.19 ou a versão LTS de manutenção mais recente.
- npm.
Começando
Faça login no Scrapeless e obtenha sua chave de API.
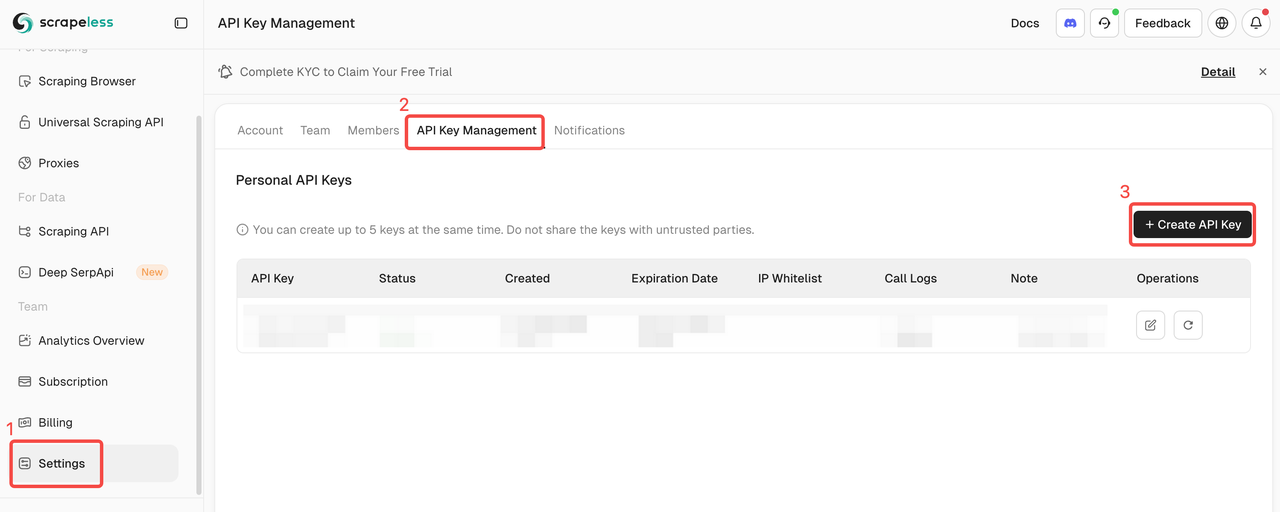
Início Rápido
Esta configuração JSON é usada por um cliente MCP para se conectar ao servidor Chrome DevTools MCP e controlar a instância do navegador em nuvem do Scrapeless remoto.
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"chrome-devtools-mcp@latest",
"--wsEndpoin=wss://browser.scrapeless.com/api/v2/browser?token=scrapeless api key&proxyCountry=US&sessionRecording=true&sessionTTL=900&sessionName=CDPDemo"
]
}
}
}Demonstração
Casos de Uso
- Análise de Desempenho na Web: Registre rastros com CDP e extraia insights acionáveis sobre o carregamento da página, solicitações de rede e execução de JavaScript, permitindo que assistentes de IA sugiram otimizações de desempenho.
- Depuração Automatizada: Capture logs do console, inspecione o tráfego da rede, faça capturas de tela e reproduza automaticamente bugs para uma solução de problemas mais rápida.
- Testes de ponta a ponta: Automatize fluxos de trabalho complexos com Puppeteer, valide interações da página e verifique a renderização de conteúdo dinâmico no Chrome.
- Automação Assistida por IA: LLMs como Gemini ou Copilot podem preencher formulários, clicar em botões ou raspar dados estruturados de páginas do Chrome com confiabilidade e precisão.
Playwright MCP
Playwright MCP é um servidor de Modelo-Contexto-Protocolo (MCP) que fornece capacidades de automação de navegador baseadas no Playwright. Ele permite que grandes modelos de linguagem (LLMs) ou assistentes de codificação por IA interajam com páginas da web.
Principais Recursos
- Rápido e leve. Usa a árvore de acessibilidade do Playwright, não entradas baseadas em pixels.
- Amigável para LLM. Não são necessários modelos de visão, opera puramente em dados estruturados.
- Aplicação de ferramentas determinística. Evita ambiguidade comum em abordagens baseadas em captura de tela.
Requisitos
- Node.js 18 ou mais recente
- VS Code, Cursor, Windsurf, Claude Desktop, Goose ou qualquer outro cliente MCP
Começando
Faça login no Scrapeless e obtenha sua Chave de API.
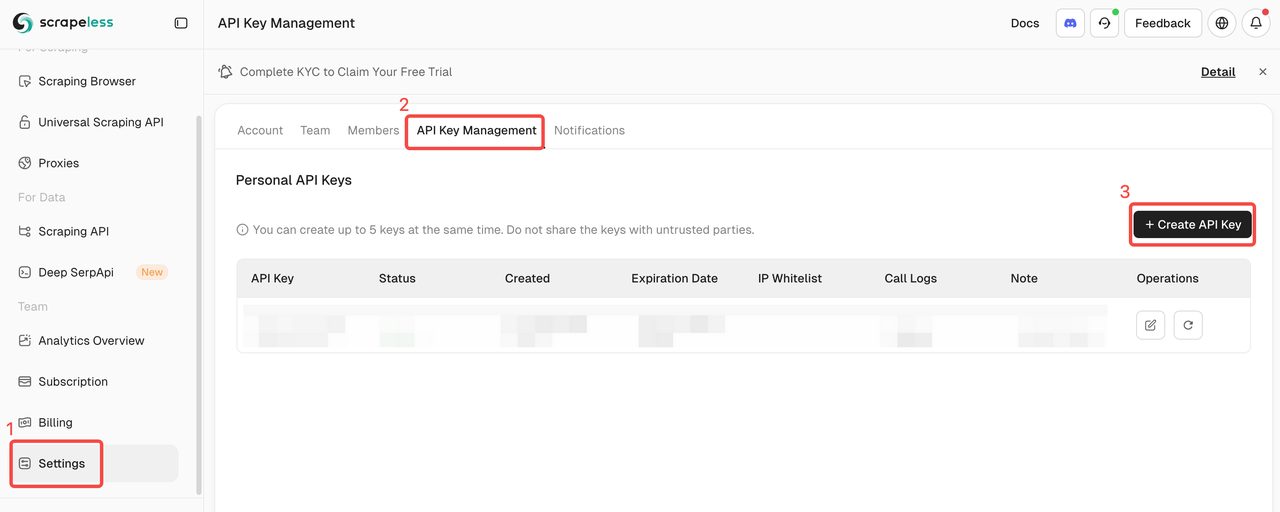
Início Rápido
Esta configuração JSON é usada por um cliente MCP para se conectar ao servidor Playwright MCP e controlar a instância do navegador Scrapeless na nuvem.
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless",
"--cdp-endpoint=wss://browser.scrapeless.com/api/v2/browser?token=Your_Token&proxyCountry=ANY&sessionRecording=true&sessionTTL=900&sessionName=playwrightDemo"
]
}
}
}Demonstração
Casos de Uso
-
Raspagem de Web e Extração de Dados: LLMs alimentados pelo Playwright MCP podem navegar por websites, extrair dados estruturados e automatizar tarefas complexas de raspagem dentro de um ambiente de navegador real. Isso apoia a coleta de informações em larga escala para pesquisa de mercado, agregação de conteúdo e inteligência competitiva.
-
Execução de Fluxos de Trabalho Automatizados: O Playwright MCP permite que agentes de IA realizem fluxos de trabalho repetitivos baseados na web, como entrada de dados, geração de relatórios e atualizações de painéis. É particularmente eficaz para automação de processos de negócios, integração de RH e outras operações de alta frequência.
-
Atendimento ao Cliente e Suporte Personalizado: Agentes de IA podem usar o Playwright MCP para interagir diretamente com portais da web, recuperar dados específicos do usuário e realizar ações de solução de problemas. Isso permite experiências de suporte personalizadas e contextualizadas — por exemplo, obtendo detalhes de pedidos ou resolvendo problemas de login automaticamente.
Browser MCP
Servidor MCP do Navegador Scrapeless conecta perfeitamente modelos como ChatGPT, Claude, e ferramentas como Cursor e Windsurf a uma ampla gama de capacidades externas, incluindo:
- Automação de navegador para navegação e interação em nível de página
- Raspar sites dinâmicos e pesados em JS — exportar como HTML, Markdown ou capturas de tela
Ferramentas MCP Suportadas
| Nome | Descrição |
|---|---|
| browser_create | Criar ou reutilizar uma sessão de navegador na nuvem usando Scrapeless. |
| browser_close | Fecha a sessão atual desconectando o navegador na nuvem. |
| browser_goto | Navegar o navegador para uma URL especificada. |
| browser_go_back | Voltar um passo no histórico do navegador. |
| browser_go_forward | Avançar um passo no histórico do navegador. |
| browser_click | Clicar em um elemento específico na página. |
| browser_type | Digitar texto em um campo de entrada específico. |
| browser_press_key | Simular a pressão de uma tecla. |
| browser_wait_for | Esperar que um elemento específico da página apareça. |
| browser_wait | Pausar a execução por uma duração fixa. |
| browser_screenshot | Capturar uma captura de tela da página atual. |
| browser_get_html | Obter o HTML completo da página atual. |
| browser_get_text | Obter todo o texto visível da página atual. |
| browser_scroll | Rolagem até o final da página. |
| browser_scroll_to | Rolagem de um elemento específico para visualização. |
| scrape_html | Raspar uma URL e retornar seu conteúdo HTML completo. |
| scrape_markdown | Raspar uma URL e retornar seu conteúdo como Markdown. |
| scrape_screenshot | Capturar uma captura de tela de alta qualidade de qualquer página da web. |
Começando
Faça login no Scrapeless e obtenha seu Token da API.
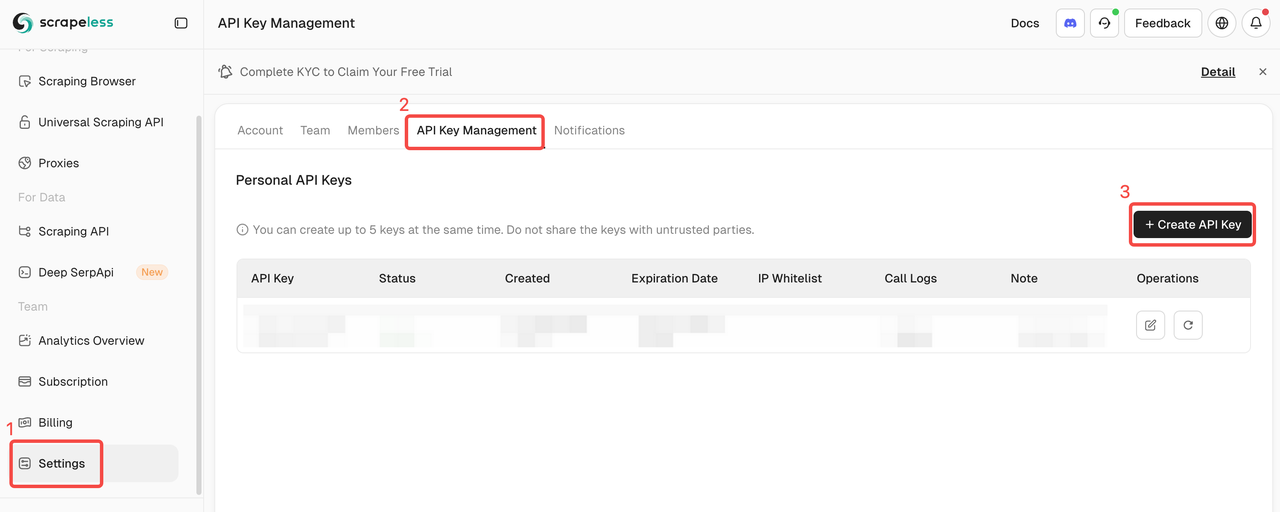
Configure seu Cliente MCP
O Servidor MCP da Scrapeless suporta os modos de transporte Stdio e HTTP Streamable.
🖥️ Stdio (Execução Local)
{
"mcpServers": {
"Servidor MCP Scrapeless": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "SEU_SCRAPELESS_KEY"
}
}
}
}🌐 HTTP Streamable (Modo de API Hospedada)
{
"mcpServers": {
"Servidor MCP Scrapeless": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "SEU_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}Opções Avançadas
Personalize o comportamento da sessão do navegador com parâmetros opcionais. Estes podem ser definidos via variáveis de ambiente (para Stdio) ou cabeçalhos HTTP (para HTTP Streamable):
| Stdio (Var de Env) | HTTP Streamable (Cabeçalho HTTP) | Descrição |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Especifica um ID de perfil de navegador reutilizável para continuidade da sessão. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Habilita armazenamento persistente para cookies, armazenamento local, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Define o tempo limite máximo da sessão em segundos. A sessão expirará automaticamente após essa duração de inatividade. |
Casos de Uso
Raspagem da Web & Coleta de Dados
- Monitoramento de E-commerce: Visitar automaticamente páginas de produtos para coletar preços, status de estoque e descrições.
- Pesquisa de Mercado: Raspar em lote notícias, análises ou páginas de empresas para análise e comparação.
- Agregação de Conteúdo: Extrair conteúdo de páginas, postagens e comentários para coleta centralizada.
- Geração de Leads: Coletar informações de contato e detalhes da empresa de sites corporativos ou diretórios.
Teste & Garantia de Qualidade
- Verificação de Função: Usar cliques, digitação e esperas de elemento para garantir que as páginas se comportem como esperado.
- Teste de Jornada do Usuário: Simular interações reais do usuário (digitação, cliques, rolagem) para validar fluxos de trabalho.
- Suporte a Testes de Regressão: Capturar capturas de tela de páginas-chave e comparar para detectar alterações na UI ou conteúdo.
Automação de Tarefas & Fluxos de Trabalho
- Preenchimento de Formulários: Completar e enviar automaticamente formulários da web (por exemplo, registros, pesquisas).
- Captura de Dados & Geração de Relatórios: Extrair periodicamente dados da página e salvar como HTML ou capturas de tela para análise.
- Tarefas Administrativas Simples: Automatizar operações repetitivas em backend ou baseadas na web usando cliques e digitação simulados.
Demonstração
Caso 1: Automação de Interação Web e Extração de Dados com Claude
Usando o Servidor MCP do Navegador, Claude pode realizar operações web complexas—como navegação, cliques, rolagem e raspagem de dados—por meio de comandos conversacionais, com pré-visualização da execução em tempo real via sessões ao vivo.
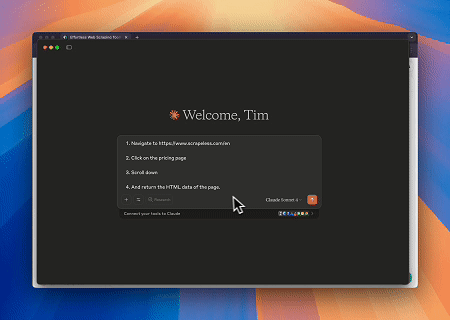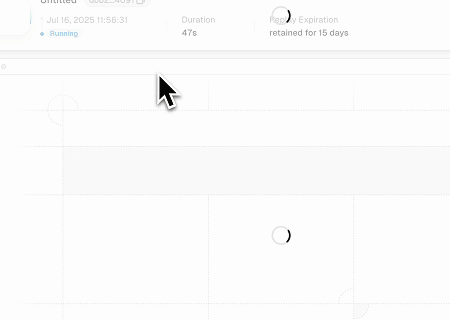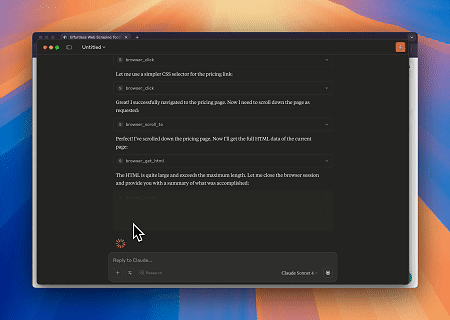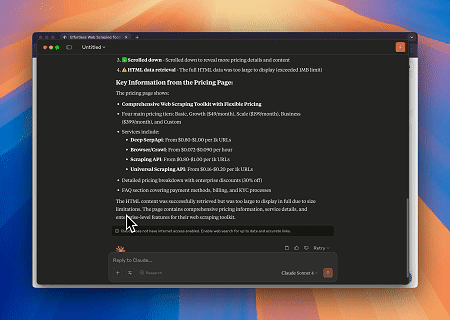
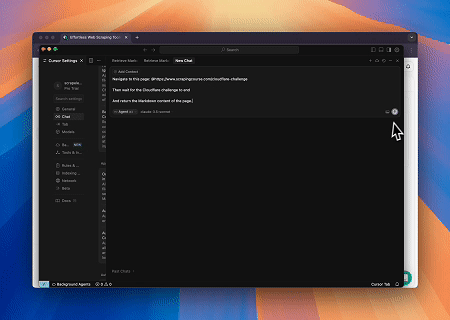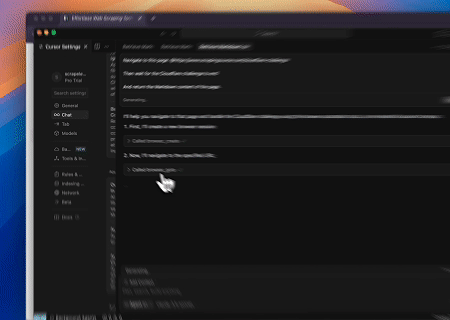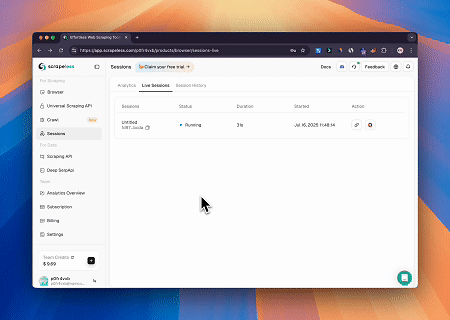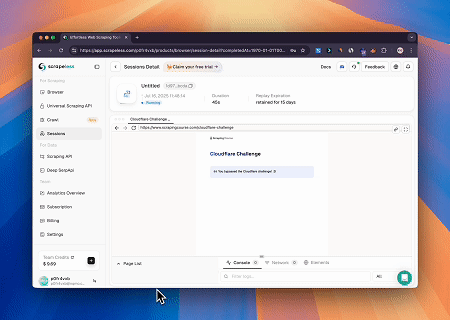
Caso 2: Contornar Cloudflare para Recuperar o Conteúdo da Página Alvo
Usando o Servidor MCP do Navegador, páginas protegidas pelo Cloudflare são acessadas automaticamente, e ao término, o conteúdo da página é extraído e retornado em formato Markdown.
Integrações
Claude Desktop
- Abra Claude Desktop
- Navegue até: Configurações → Ferramentas → Servidores MCP
- Clique em "Adicionar Servidor MCP"
- Cole a configuração Stdio ou Streamable HTTP acima
- Salve e ative o servidor
- Claude agora poderá emitir consultas web, extrair conteúdo e interagir com páginas usando Scrapeless
Cursor IDE
- Abra Cursor
- Pressione Cmd + Shift + P e procure por: Configurar Servidores MCP
- Adicione a configuração Scrapeless MCP usando o formato acima
- Salve o arquivo e reinicie o Cursor (se necessário)
- Agora você pode pedir ao Cursor coisas como:
- “Pesquise no StackOverflow por uma solução para este erro”
- “Extraia o HTML desta página”
- E ele usará o Scrapeless em segundo plano.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


