
Web Crawler com Golang: Tutorial Passo a Passo 2025
Senior Web Scraping Engineer
A maioria dos grandes projetos de web scraping em Go começam descobrindo e organizando URLs usando um web crawler em Golang. Essa ferramenta permite navegar em um domínio alvo inicial (também conhecido como "URL semente") e visitar recursivamente links na página para descobrir mais links.
Este guia irá te ensinar como construir e otimizar um web crawler em Golang usando exemplos do mundo real. E, antes de mergulharmos, você também obterá algumas informações suplementares úteis.
Sem mais delongas, vamos ver o que temos de divertido para você hoje!
O que é Web Crawling?
Web crawling, em sua essência, envolve navegar sistematicamente em sites para extrair dados úteis. Um web crawler (frequentemente chamado de spider) busca páginas web, analisa seu conteúdo e processa as informações para atingir objetivos específicos, como indexação ou agregação de dados. Vamos quebrar isso:
Web crawlers enviam solicitações HTTP para recuperar páginas web de servidores e processar as respostas. Pense nisso como um aperto de mão educado entre seu crawler e o site — “Olá, posso levar seus dados para um passeio?”
Assim que a página é buscada, o crawler extrai dados relevantes analisando o HTML. Estruturas DOM ajudam a dividir a página em partes gerenciáveis, e seletores CSS atuam como um par preciso de pinças, extraindo os elementos que você precisa.
A maioria dos sites distribui seus dados em várias páginas. Os crawlers precisam navegar neste labirinto de paginação, respeitando os limites de taxa para evitar parecer um bot faminto por dados com esteroides.
Por que Golang é perfeito para Web Crawling em 2025
Se web crawling fosse uma corrida, Golang seria o carro esportivo que você desejaria em sua garagem. Seus recursos exclusivos o tornam a linguagem ideal para web crawlers modernos.
- Concorrência: As goroutines do Golang permitem que você faça várias solicitações simultaneamente, raspando dados mais rápido do que você consegue dizer "processamento paralelo".
- Simplicidade: A sintaxe limpa e o design minimalista da linguagem mantêm sua base de código gerenciável, mesmo ao lidar com projetos complexos de crawling.
- Desempenho: Golang é compilado, o que significa que ele roda muito rápido — ideal para lidar com tarefas de web crawling em larga escala sem suar muito.
- Biblioteca padrão robusta: Com suporte integrado para solicitações HTTP, análise JSON e muito mais, a biblioteca padrão do Golang o equipa com tudo o que você precisa para construir um crawler do zero.
Por que lutar com ferramentas desajeitadas quando você pode voar pelos dados como um Gopher com cafeína? Golang combina velocidade, simplicidade e poder, tornando-o a melhor escolha para rastrear a web de forma eficiente e eficaz.
É legal rastrear sites?
A legalidade do web crawling não é uma situação única. Depende de como, onde e por que você está rastreando. Embora a raspagem de dados públicos seja geralmente permitida, violar os termos de serviço ou contornar medidas anti-raspagem pode levar a problemas legais.
Para se manter do lado certo da lei, aqui estão algumas regras de ouro:
- Respeite as diretivas robots.txt.
- Evite raspar informações sensíveis ou restritas.
- Peça permissão se não tiver certeza sobre a política de um site.
Como construir seu primeiro Web Crawler em Golang?
Pré-requisitos
- Certifique-se de ter a versão mais recente do Go instalada. Você pode baixar o pacote de instalação do site oficial do Golang e seguir as instruções para instalá-lo.
- Escolha seu IDE preferido. Este tutorial usa o Goland como editor.
- Escolha uma biblioteca Go de web scraping com a qual você se sinta confortável. Neste exemplo, usaremos o chromedp.
Para verificar sua instalação do Go, digite o seguinte comando no terminal:
PowerShell
go versionSe a instalação for bem-sucedida, você verá o seguinte resultado:
PowerShell
go version go1.23.4 windows/amd64Crie seu diretório de trabalho e, uma vez dentro, digite os seguintes comandos:
- Inicialize o
go mod:
PowerShell
go mod init crawl- Instale a dependência
chromedp:
PowerShell
go get github.com/chromedp/chromedp- Crie o arquivo
crawl.go.
Agora podemos começar a escrever seu código de web scraper.
Obter elementos da página
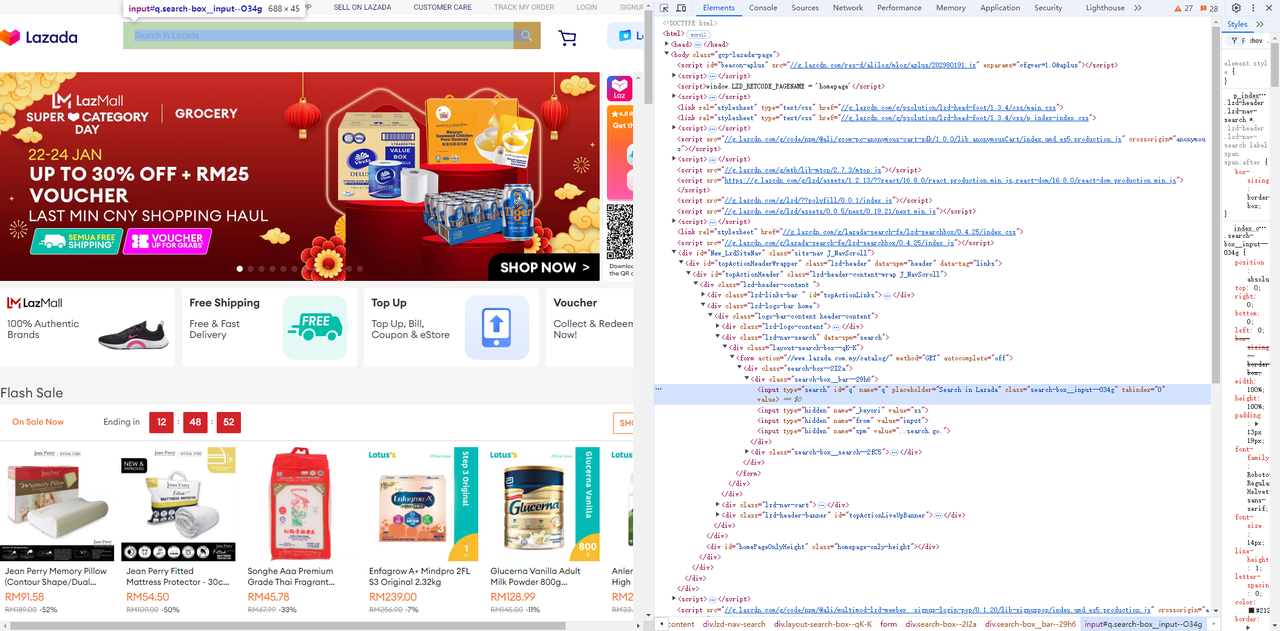
Visite o Lazada e use as ferramentas de desenvolvedor do navegador (F12) para identificar facilmente os elementos e seletores da página que você precisa.
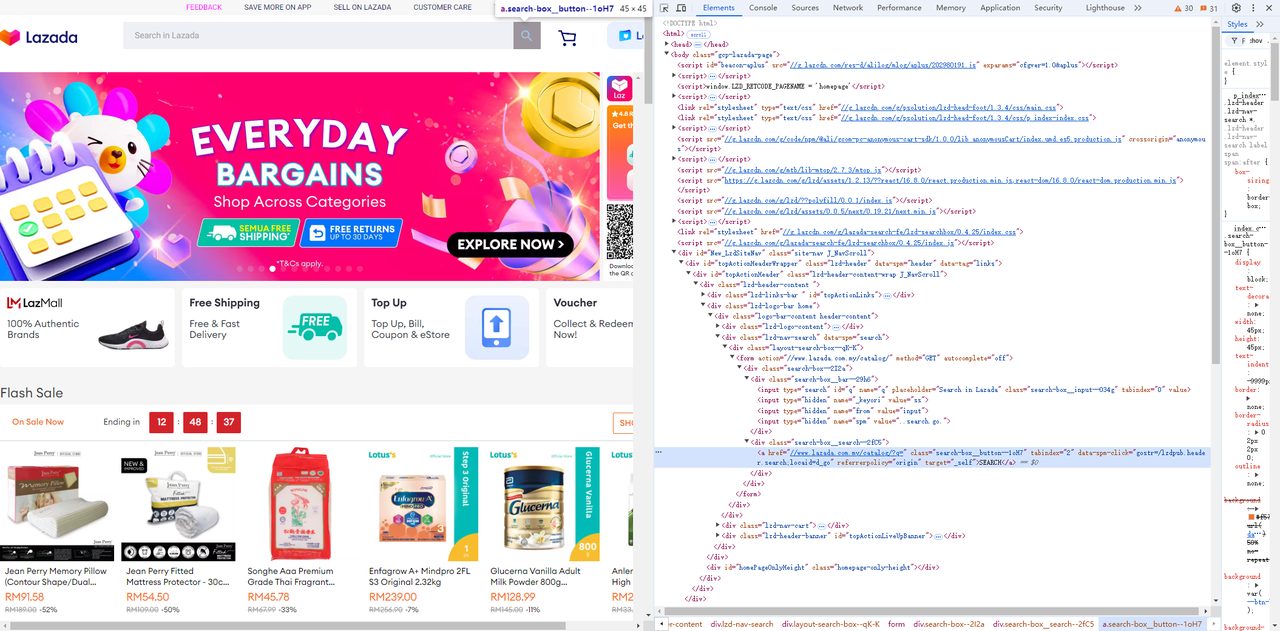
- Obtenha o campo de entrada e o botão de pesquisa ao lado dele:
Go
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// wait for input element is visible
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Enter the searched product.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Click search
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}- Obtenha os elementos de preço, título e imagem da lista de produtos:
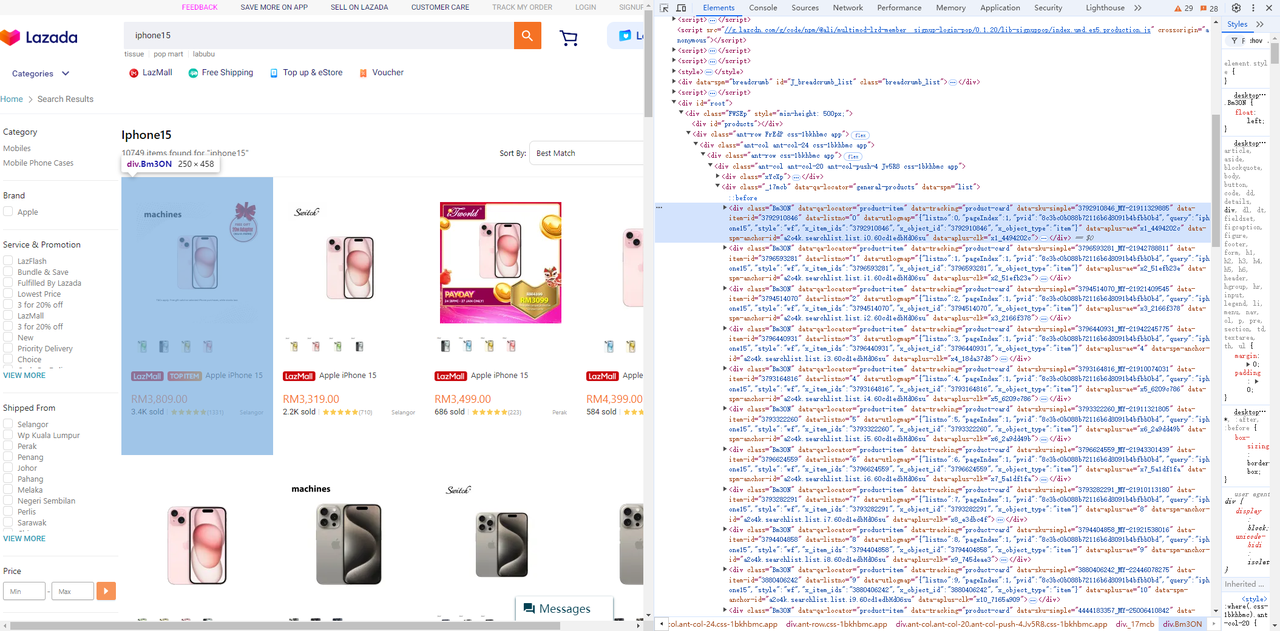
-
Lista de produtos
-
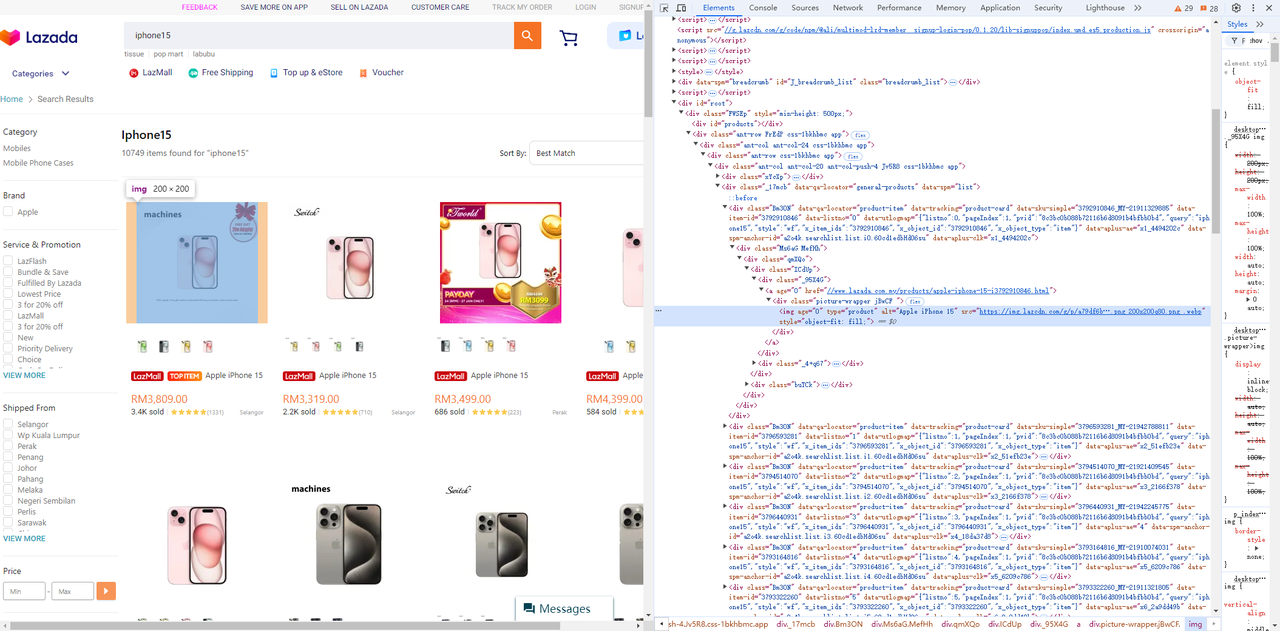
Elemento de imagem
-
Elemento de título
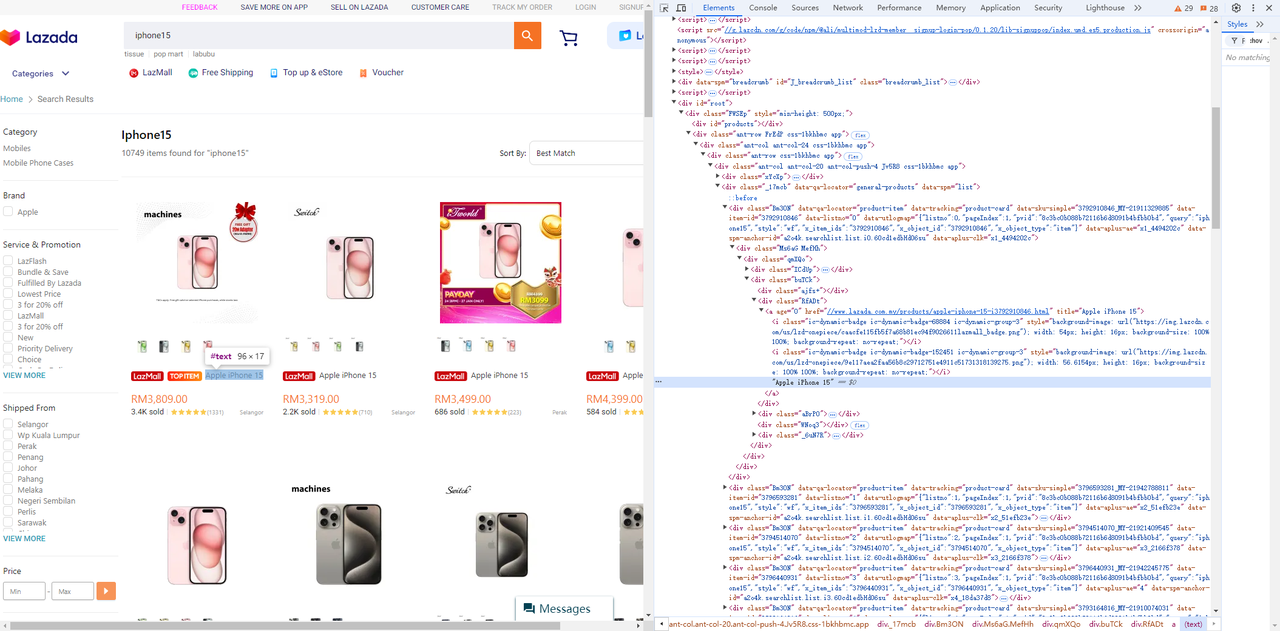
-
Elemento de preço
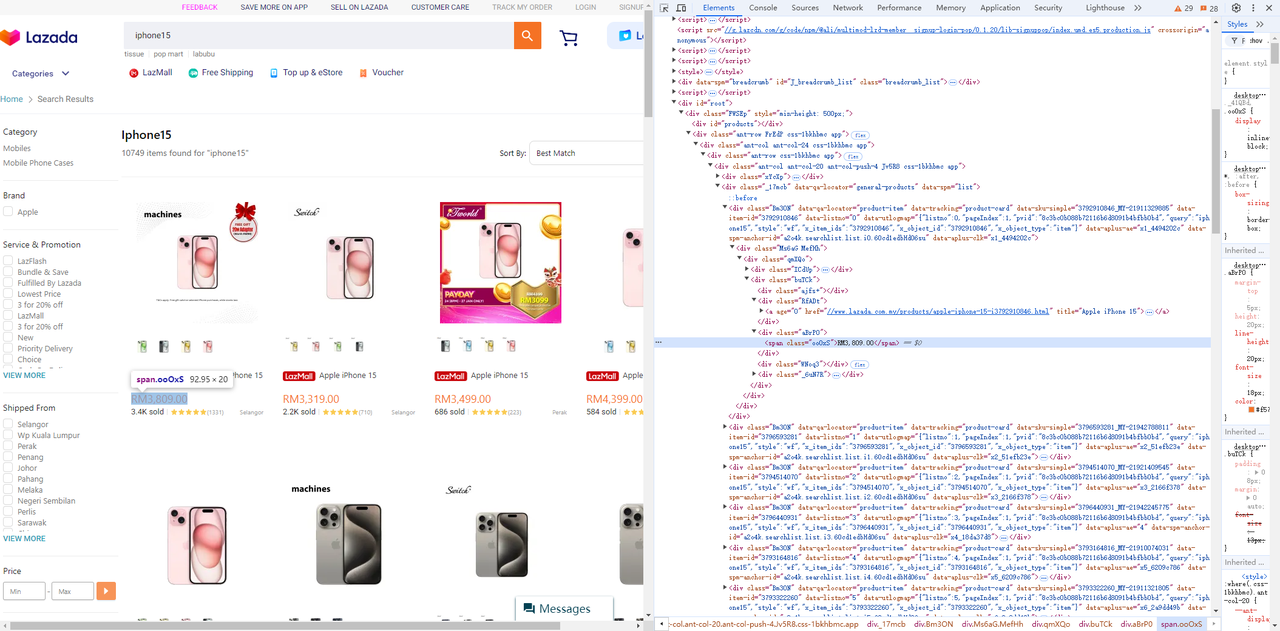
Go
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Scroll to the bottom to ensure that all page elements are rendered.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Scroll repeatedly to ensure that all pictures are loaded.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
return product, nil
}Configurar o ambiente do Chrome
Para facilitar a depuração, podemos iniciar um navegador Chrome no PowerShell e especificar uma porta de depuração remota.
PowerShell
chrome.exe --remote-debugging-port=9223Podemos acessar http://localhost:9223/json/list para recuperar o endereço de depuração remota exposto pelo navegador, webSocketDebuggerUrl.
PowerShell
[
{
"description": "",
"devtoolsFrontendUrl": "/devtools/inspector.html?ws=localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080",
"id": "85CE4D807D11D30D5F22C1AA52461080",
"title": "localhost:9223/json/list",
"type": "page",
"url": "http://localhost:9223/json/list",
"webSocketDebuggerUrl": "ws://localhost:9223/devtools/page/85CE4D807D11D30D5F22C1AA52461080"
}
]Executar o código
O código completo é o seguinte:
Go
package main
import (
"context"
"encoding/json"
"flag"
"log"
"time"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
type Product struct {
ID string `json:"id"`
Img string `json:"img"`
Price string `json:"price"`
Title string `json:"title"`
}
func main() {
product := flag.String("product", "iphone15", "your product keyword")
url := flag.String("webSocketDebuggerUrl", "", "your websocket url")
flag.Parse()
var baseCxt context.Context
if *url != "" {
baseCxt, _ = chromedp.NewRemoteAllocator(context.Background(), *url)
} else {
baseCxt = context.Background()
}
ctx, cancel := chromedp.NewContext(
baseCxt,
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate(`https://www.lazada.com.my/`),
searchProduct(*product),
getNodes(&nodes),
)
products := make([]*Product, 0, len(nodes))
for _, v := range nodes {
product, err := getProductData(ctx, v)
if err != nil {
log.Println("run node task err: ", err)
continue
}
products = append(products, product)
}
if err != nil {
log.Fatal(err)
}
jsonData, _ := json.Marshal(products)
log.Println(string(jsonData))
}
func searchProduct(keyword string) chromedp.Tasks {
return chromedp.Tasks{
// wait for input element is visible
chromedp.WaitVisible(`input[type=search]`, chromedp.ByQuery),
// Enter the searched product.
chromedp.SendKeys("input[type=search]", keyword, chromedp.ByQuery),
// Click search
chromedp.Click(".search-box__button--1oH7", chromedp.ByQuery),
}
}
func getNodes(nodes *[]*cdp.Node) chromedp.Tasks {
return chromedp.Tasks{
chromedp.WaitReady(`div[data-spm=list] .Bm3ON`, chromedp.ByQuery),
scrollToBottom(), // Scroll to the bottom to ensure that all page elements are rendered.
chromedp.Nodes("div[data-spm=list] .Bm3ON", nodes, chromedp.ByQueryAll),
}
}
func scrollToBottom() chromedp.Action {
return chromedp.ActionFunc(func(ctx context.Context) error {
for i := 0; i < 4; i++ { // Scroll repeatedly to ensure that all pictures are loaded.
_ = chromedp.Evaluate("window.scrollBy(0, window.innerHeight);", nil).Do(ctx)
time.Sleep(1 * time.Second)
}
return nil
})
}
func getProductData(ctx context.Context, node *cdp.Node) (*Product, error) {
product := new(Product)
err := chromedp.Run(ctx,
chromedp.WaitVisible(".Bm3ON img[type=product]", chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON img[type=product]", "src", &product.Img, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.AttributeValue(".Bm3ON .RfADt a", "title", &product.Title, nil, chromedp.ByQuery, chromedp.FromNode(node)),
chromedp.TextContent(".Bm3ON .aBrP0 span", &product.Price, chromedp.ByQuery, chromedp.FromNode(node)),
)
if err != nil {
return nil, err
}
product.ID = node.AttributeValue("data-item-id")
return product, nil
}Executando o comando abaixo, você obterá os resultados dos dados raspados:
PowerShell
go run .\crawl.go -product="YOU KEYWORD"-webSocketDebuggerUrl="YOU WEBSOCKETDEBUGGERURL"
JSON
[
{
"id": "3792910846",
"img": "https://img.lazcdn.com/g/p/a79df6b286a0887038c16b7600e38f4f.png_200x200q75.png_.webp",
"price": "RM3,809.00",
"title": "Apple iPhone 15"
},
{
"id": "3796593281",
"img": "https://img.lazcdn.com/g/p/627828b5fa28d708c5b093028cd06069.png_200x200q75.png_.webp",
"price": "RM3,319.00",
"title": "Apple iPhone 15"
},
{
"id": "3794514070",
"img": "https: //img.lazcdn.com/g/p/6f4ddc2693974398666ec731a713bcfd.jpg_200x200q75.jpg_.webp",
"price": "RM3,499.00",
"title": "Apple iPhone 15"
},
{
"id": "3796440931",
"img": "https://img.lazcdn.com/g/p/8df101af902d426f3e3a9748bafa7513.jpg_200x200q75.jpg_.webp",
"price": "RM4,399.00",
"title": "Apple iPhone 15"
},
......
{
"id": "3793164816",
"img": "https://img.lazcdn.com/g/p/b6c3498f75f1215f24712a25799b0d19.png_200x200q75.png_.webp",
"price": "RM3,799.00",
"title": "Apple iPhone 15"
},
{
"id": "3793322260",
"img": "https: //img.lazcdn.com/g/p/67199db1bd904c3b9b7ea0ce32bc6ace.png_200x200q75.png_.webp",
"price": "RM5,644.00",
"title": "[Ready Stock] Apple iPhone 15 Pro"
},
{
"id": "3796624559",
"img": "https://img.lazcdn.com/g/p/81a814a9c829afa200fbc691c9a0c30c.png_200x200q75.png_.webp",
"price": "RM6,679.00",
"title": "Apple iPhone 15 Pro (1TB)"
}
]Técnicas avançadas para escalar seu Web Crawler
Seu web crawling precisa de melhorias! Para coletar dados de forma eficaz sem ser bloqueado ou sobrecarregado, você deve implementar técnicas que equilibrem velocidade, confiabilidade e otimização de recursos.
Vamos explorar algumas estratégias avançadas para garantir que seu crawler se destaque em cargas de trabalho pesadas.
Mantenha sua solicitação e sessão
Ao fazer web crawling, bombardear um servidor com muitas solicitações em pouco tempo é uma maneira garantida de ser detectado e banido. Os sites frequentemente monitoram a frequência das solicitações do mesmo cliente, e um aumento repentino pode disparar mecanismos anti-bot.
Go
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// Create a reusable HTTP client
client := &http.Client{}
// URLs to crawl
urls := []string{
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
}
// Interval between requests (e.g., 2 seconds)
requestInterval := 2 * time.Second
for _, url := range urls {
// Create a new HTTP request
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla/5.0 (compatible; WebCrawler/1.0)")
// Send the request
resp, err := client.Do(req)
if err != nil {
fmt.Println("Error:", err)
continue
}
// Read and print the response
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("Response from %s:\n%s\n", url, body)
resp.Body.Close()
// Wait before sending the next request
time.Sleep(requestInterval)
}
}Evite links duplicados
Não há nada pior do que perder recursos rastreando o mesmo URL duas vezes. Implemente um sistema de desduplicação robusto mantendo um conjunto de URLs (por exemplo, um mapa hash ou um banco de dados Redis) para rastrear páginas já visitadas. Isso não apenas economiza largura de banda, mas também garante que seu crawler funcione de forma eficiente e não perca novas páginas.
Gerenciamento de proxy para evitar proibições de IP.
A raspagem em escala muitas vezes aciona medidas anti-bot, levando a proibições de IP. Para evitar isso, integre a rotação de proxy em seu crawler.
- Use pools de proxy para distribuir solicitações entre vários IPs.
- Rotacionar proxies dinamicamente para fazer suas solicitações parecerem originadas de diferentes usuários e locais.
Priorize páginas específicas
Priorizar páginas específicas ajuda a otimizar seu processo de rastreamento e permite que você se concentre em rastrear links utilizáveis. No crawler atual, usamos seletores CSS para direcionar apenas links de paginação e extrair informações de produtos valiosas.
No entanto, se você estiver interessado em todos os links de uma página e quiser priorizar a paginação, poderá manter uma fila separada e processar os links de paginação primeiro.
Go
package main
import (
"fmt"
"github.com/gocolly/colly"
)
// ...
// create variables to separate pagination links from other links
var paginationURLs = []string{}
var otherURLs = []string{}
func main() {
// ...
}
func crawl (currenturl string, maxdepth int) {
// ...
// ----- find and visit all links ---- //
// select the href attribute of all anchor tags
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// get absolute URL
link := e.Request.AbsoluteURL(e.Attr("href"))
// check if the current URL has already been visited
if link != "" && !visitedurls[link] {
// add current URL to visitedURLs
visitedurls[link] = true
if e.Attr("class") == "page-numbers" {
paginationURLs = append(paginationURLs, link)
} else {
otherURLs = append(otherURLs, link)
}
}
})
// ...
// process pagination links first
for len(paginationURLs) > 0 {
nextURL := paginationURLs[0]
paginationURLs = paginationURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Error visiting page:", err)
}
}
// process other links
for len(otherURLs) > 0 {
nextURL := otherURLs[0]
otherURLs = otherURLs[1:]
visitedurls[nextURL] = true
err := c.Visit(nextURL)
if err != nil {
fmt.Println("Error visiting page:", err)
}
}
}API de Raspagem Scrapeless: Ferramenta de Raspagem Eficaz
Por que a API de Raspagem Scrapeless é mais ideal?
A API de Raspagem Scrapeless foi projetada para simplificar o processo de extração de dados de sites e pode navegar nos ambientes web mais complexos, gerenciando efetivamente conteúdo dinâmico e renderização JavaScript.
Além disso, a API de Raspagem Scrapeless utiliza uma rede global que abrange 195 países, suportada pelo acesso a mais de 70 milhões de IPs residenciais. Com uma disponibilidade de 99,9% e taxas de sucesso excepcionais, a Scrapeless supera facilmente desafios como bloqueios de IP e CAPTCHA, tornando-se uma solução robusta para automação web complexa e coleta de dados impulsionada por IA.
Com nossa API de Raspagem avançada, você pode acessar os dados de que precisa sem ter que escrever ou manter scripts de raspagem complexos!
Vantagens da API de Raspagem
A Scrapeless suporta renderização JavaScript de alto desempenho, permitindo que ela manipule conteúdo dinâmico (como dados carregados via AJAX ou JavaScript) e raspe sites modernos que dependem de JS para entrega de conteúdo.
- Preço acessível: A Scrapeless foi projetada para oferecer valor excepcional.
- Estabilidade e confiabilidade: Com um histórico comprovado, a Scrapeless fornece respostas de API estáveis, mesmo sob altas cargas de trabalho.
- Altas taxas de sucesso: Diga adeus às extrações com falhas e a Scrapeless promete 99,99% de acesso bem-sucedido aos dados do Google SERP.
- Escalabilidade: Lidere milhares de consultas sem esforço, graças à infraestrutura robusta por trás da Scrapeless.
Obtenha agora a API de Raspagem Scrapeless barata e poderosa!
A Scrapeless oferece uma plataforma de web scraping confiável e escalável a preços competitivos, garantindo um excelente valor para seus usuários:
- Navegador de Raspagem: A partir de US$ 0,09 por hora
- API de Raspagem: A partir de US$ 1,00 por 1k de URLs
- Desbloqueador Web: US$ 0,20 por 1k de URLs
- Resolutor de CAPTCHA: A partir de US$ 0,80 por 1k de URLs
- Proxies: US$ 2,80 por GB
Ao se inscrever, você pode aproveitar descontos de até 20% de desconto em cada serviço. Você tem requisitos específicos? Entre em contato conosco hoje, e forneceremos ainda mais economia adaptada às suas necessidades!
Como usar a API de Raspagem Scrapeless?
É muito fácil usar a API de Raspagem Scrapeless para rastrear dados do Lazada. Você só precisa de uma solicitação simples para obter todos os dados que deseja. Como chamar a API Scrapeless rapidamente? Siga meus passos:
- Etapa 1. Faça login na Scrapeless
- Etapa 2. Clique em "API de Raspagem"
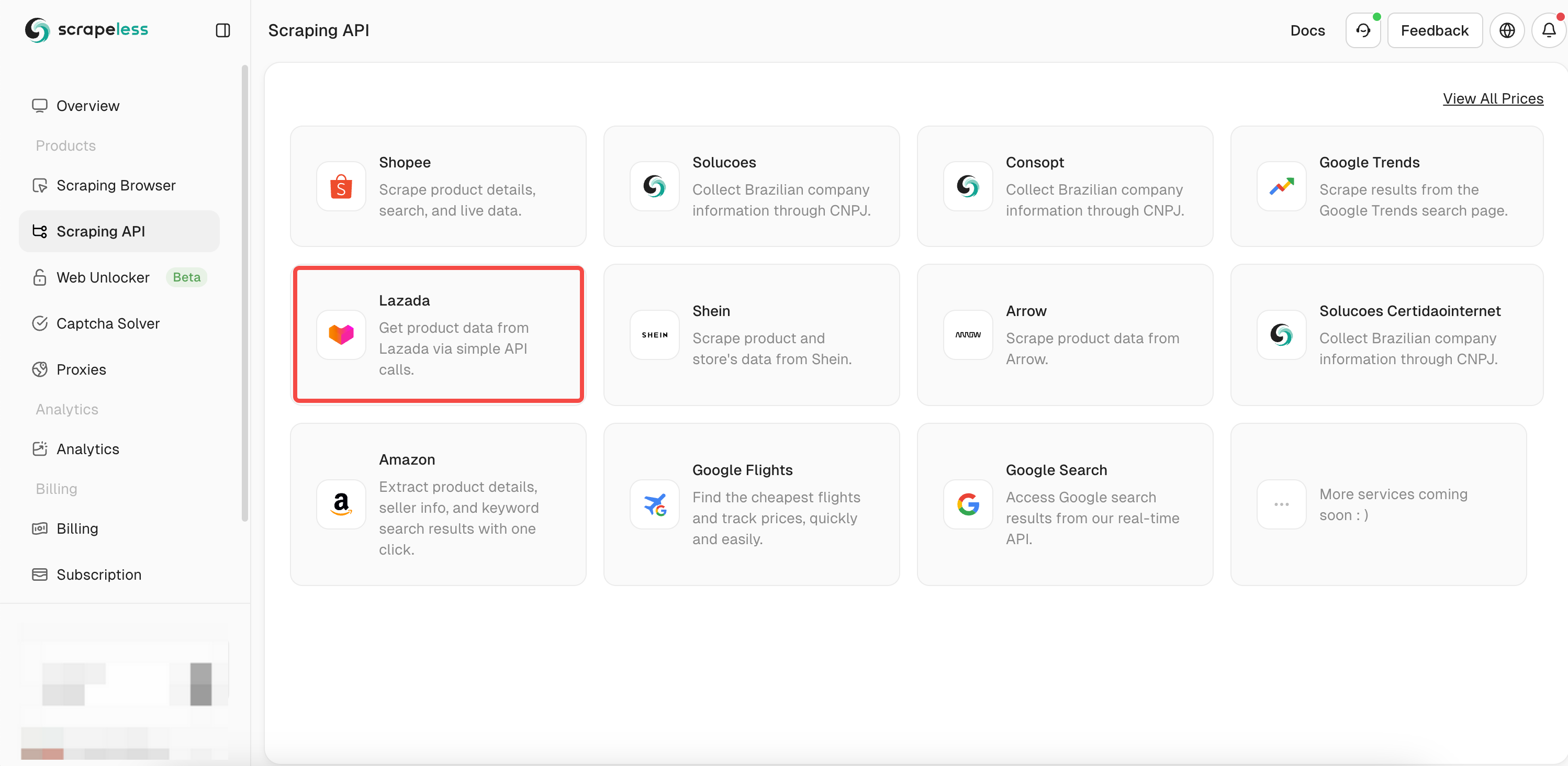
- Etapa 3. Encontre nossa API "Lazada" e insira-a:
- Etapa 4. Preencha as informações completas do produto que você deseja rastrear na caixa de operação à esquerda. Ao usar
chromedppara rastrear dados, você já obteve o ID do produto rastreado. Agora você só precisa adicionar o ID ao parâmetro itemId para obter dados mais detalhados sobre o produto. Em seguida, selecione a linguagem de expressão desejada:
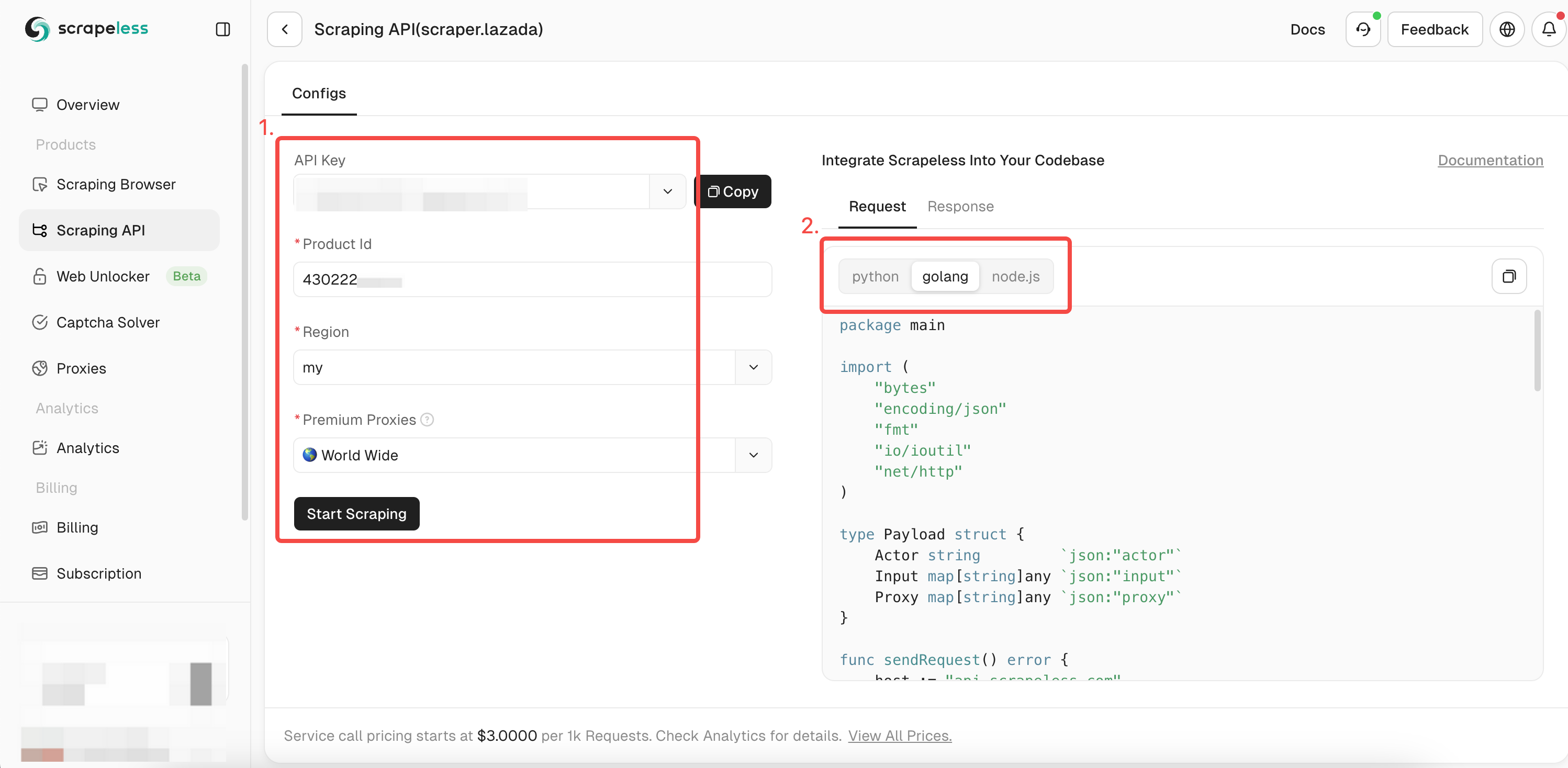
- Etapa 5. Clique em "Iniciar Raspagem" e os resultados de rastreamento do produto aparecerão na caixa de visualização à direita:
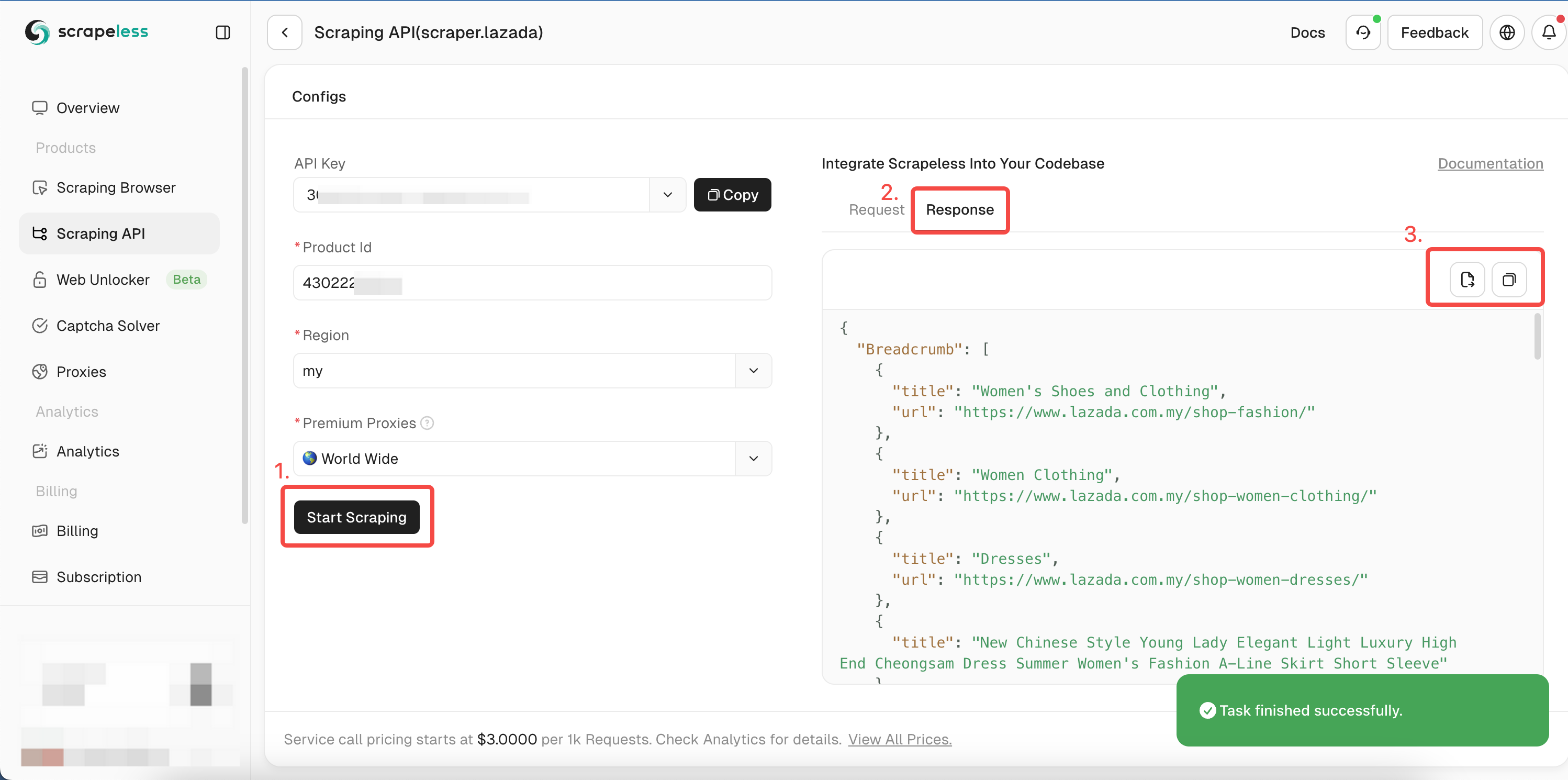
Você pode consultar nosso código de exemplo Golang ou visitar nossa documentação da API para outras linguagens.
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
Proxy map[string]any `json:"proxy"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := "YOU_TOKEN"
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"itemId": "3792910846", // Replace with the itemId you want to obtain.
"site": "my",
}
proxy := map[string]any{
"country": "ANY",
}
payload := Payload{
Actor: "scraper.lazada",
Input: inputData,
Proxy: proxy,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}Após a execução, você obterá os seguintes dados detalhados. Incluindo links, imagens, SKU, avaliações, mesmo vendedor, etc.
Devido a limitações de espaço, mostramos apenas uma parte dos resultados da raspagem aqui. Você pode visitar o nosso Painel e obter um Teste Gratuito para rapidamente realizar a raspagem e obter os resultados completos!
JSON
{
"Breadcrumb": [
{
"title": "Móveis e Tablets",
"url": "https://www.lazada.com.my/shop-mobiles-tablets/"
},
{
"title": "Smartphones",
"url": "https://www.lazada.com.my/shop-mobiles/"
},
{
"title": "Apple iPhone 15"
}
],
"deliveryOptions": {
"21911329880": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "Para itens locais, você pode esperar receber o item em 2-4 dias úteis. <br/>A taxa de envio é determinada pelo tamanho/peso total dos produtos comprados do vendedor.<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">Saiba mais</a>",
"duringTime": "Garantido até 24-27 de janeiro",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "Entrega padrão",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "Pagamento na entrega não disponível",
"type": "noCOD"
}
],
"21911329881": [
{
"badge": false,
"dataType": "delivery",
"deliveryWorkTimeMax": "2025-01-27T23:27+08:00[GMT+08:00]",
"deliveryWorkTimeMin": "2025-01-24T23:27+08:00[GMT+08:00]",
"description": "Para itens locais, você pode esperar receber o item em 2-4 dias úteis. <br/>A taxa de envio é determinada pelo tamanho/peso total dos produtos comprados do vendedor.<br/><br/><a href=\"https://www.lazada.com.my/helpcenter/shipping_delivery/#answer-faq-whatisshippingfee-ans\" target=\"_blank\">Saiba mais</a>",
"duringTime": "Garantido até 24-27 de janeiro",
"fee": "RM4.90",
"feeValue": 4.9,
"hasTip": true,
"title": "Entrega padrão",
"type": "standard"
},
{
"badge": true,
"dataType": "service",
"description": "",
"feeValue": 0,
"hasTip": true,
"title": "Pagamento na entrega não disponível",
"type": "noCOD"
}
],
...Leituras adicionais
- Passos completos para raspar detalhes do produto Shopee
- Como raspar dados do Google Trends de forma rápida e fácil?
- Obtenha as etapas para rastrear voos baratos usando a API do Google Flights!
Melhores práticas e considerações de rastreamento Golang
Rastreamento paralelo e concorrência
Raspar várias páginas sincronicamente pode levar a ineficiências porque apenas uma goroutine pode lidar ativamente com tarefas a qualquer momento. Seu web crawler gasta a maior parte do tempo esperando por respostas e processando dados antes de passar para a próxima tarefa.
No entanto, tirar vantagem das capacidades de concorrência do Go para tentar o rastreamento concorrente pode reduzir significativamente seu tempo total de rastreamento!
No entanto, você deve gerenciar a concorrência adequadamente para evitar sobrecarregar o servidor de destino e disparar restrições anti-bot.
Rastreamento de páginas renderizadas em JavaScript em Go
Embora o Colly seja uma ótima ferramenta de web crawler com muitos recursos integrados, ele não pode rastrear páginas renderizadas em JavaScript (conteúdo dinâmico). Ele só pode buscar e analisar HTML estático, e o conteúdo dinâmico não existe no HTML estático de um site.
No entanto, você pode integrar-se a um navegador sem cabeça ou a um mecanismo JavaScript para rastrear conteúdo dinâmico.
Considerações finais
Você aprendeu como construir um web crawler Golang usando programação avançada. Lembre-se de que, embora construir um web scraper para navegar na web seja um ótimo ponto de partida, você deve superar as medidas anti-bot para acessar sites modernos.
Em vez de lutar com a configuração manual que provavelmente falhará, considere a API de Raspagem Scrapeless, a solução mais confiável para contornar qualquer sistema anti-bot.
Experimente a Scrapeless gratuitamente hoje mesmo para começar!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


