
Como contornar a detecção de anti-bot?
Senior Web Scraping Engineer
Na batalha entre automação e segurança, os mecanismos anti-bot se tornaram os guardiões da web, bloqueando bots indesejados enquanto muitas vezes obstruem a coleta legítima de dados.
Desde páginas de login até sites de comércio eletrônico, essas defesas—especialmente os CAPTCHAs—podem ser um obstáculo frustrante para scrapers web e ferramentas de automação. Existe alguma maneira de contorná-los?
Este artigo mergulha no mundo dos sistemas anti-bot, explora como eles detectam automação e revela estratégias éticas para contornar restrições sem ultrapassar limites legais ou morais.
Vamos começar a ler!
Por que existe a detecção anti-bot?
Bem, vamos aproveitar uma viagem primeiro. Imagine administrar uma loja onde os clientes podem navegar livremente, mas a cada poucos minutos, uma figura mascarada entra correndo, pega todos os seus produtos e desaparece. O que você pensa agora?
É assim que os sites se sentem em relação aos bots! A detecção anti-bot existe para separar usuários reais de scripts automatizados, protegendo contra preenchimento de credenciais, roubo de conteúdo e scraping web agressivo.
De CAPTCHAs a impressão digital de navegador, esses seguranças digitais trabalham incansavelmente para manter os bots ruins do lado de fora—mas às vezes, eles também complicam para desenvolvedores bem-intencionados que apenas estão tentando acessar seus dados.
Então, há uma maneira de superá-los sem quebrar as regras? Podemos descobrir mais.
Mecanismos Comuns Anti-bot
- Validação de Cabeçalho: A validação de cabeçalho analisa os cabeçalhos HTTP recebidos e verifica se devem ser bloqueados.
- Bloqueio de IP: Restringir o acesso com base em endereços IP.
- Limitação de Taxa: Limitar solicitações de um único IP.
- Impressão Digital de Navegador: Analisar atributos e comportamentos do navegador.
- Impressão Digital de TLS: A impressão digital de TLS detecta bots analisando parâmetros de handshake e bloqueando solicitações com valores inesperados.
- Honeypots: Armadilhas invisíveis para atrair bots.
- Desafios CAPTCHA: Desafios projetados para serem fáceis para humanos, mas difíceis para bots.
CAPTCHA: Um Mecanismo Anti-bot Chave
O que é CAPTCHA?
CAPTCHA, abreviação de Completely Automated Public Turing test to tell Computers and Humans Apart, é um mecanismo de segurança projetado para distinguir usuários reais de bots automatizados. Ao apresentar desafios que são fáceis para humanos, mas difíceis para máquinas, o CAPTCHA ajuda a prevenir atividades maliciosas, como spam, preenchimento de credenciais e scraping web automatizado.
Tipos de CAPTCHA:
- CAPTCHA baseado em texto: Os usuários devem reconhecer e inserir texto distorcido ou obscuro, o que é desafiador para bots interpretar.
- CAPTCHA baseado em imagem: Os usuários identificam objetos em imagens, como semáforos ou vitrines, uma tarefa que requer habilidades de reconhecimento visual além da maioria dos bots.
- reCAPTCHA: O sistema CAPTCHA avançado do Google que inclui múltiplas formas—verificações simples de caixa de seleção ("Não sou um robô"), desafios de seleção de imagem e CAPTCHAs invisíveis que analisam o comportamento do usuário sem interação explícita.
- hCAPTCHA: Uma alternativa focada na privacidade ao reCAPTCHA, projetada para minimizar o rastreamento de dados enquanto ainda oferece proteção eficaz contra bots.
Como o CAPTCHA Funciona:
O CAPTCHA opera em um mecanismo de desafio-resposta, onde os usuários devem completar uma tarefa que prova que são humanos. O sistema avalia respostas e comportamentos, como movimentos do mouse, velocidade de digitação ou padrões de interação, para determinar a autenticidade.
Os sistemas de CAPTCHA modernos utilizam aprendizado de máquina para adaptar seus níveis de dificuldade com base nas capacidades de bots em evolução. Eles analisam dados comportamentais, empregam avaliações baseadas em risco e até integram indícios biométricos para melhorar a precisão e a segurança, dificultando cada vez mais que os bots contornem essas defesas.
Melhores Práticas para Contornar Anti-bots
Por que escolher Scrapeless?
Scrapeless oferece um poderoso Solver CAPTCHA, possibilitando a navegação tranquila por sites protegidos por CAPTCHA e garantindo a extração de dados ininterrupta.
- Preços Acessíveis: Scrapeless oferece soluções de resolução de CAPTCHA econômicas sem comprometer a eficiência.
- Estabilidade e Confiabilidade: Com um histórico comprovado, o Scrapeless consistentemente resolve CAPTCHAs sob altas cargas de trabalho, garantindo uma automação suave.
- Altas Taxas de Sucesso: Chega de bloqueios de CAPTCHA—Scrapeless alcança uma taxa de sucesso de 99,99% na superação de desafios CAPTCHA.
- Escalabilidade: Processa facilmente milhares de solicitações protegidas por CAPTCHA, apoiado pela robusta infraestrutura do Scrapeless.
Scrapeless é caro?
Scrapeless oferece uma plataforma de web scraping confiável e escalável a preços competitivos (versus Zenrows e Apify), garantindo excelente valor para seus usuários:
- Solver CAPTCHA: A partir de $0,8 por 1k URLs
- Navegador de Scraping: A partir de $0,09 por hora
- API de Scraping: A partir de $0,8 por 1k URLs
- Desbloqueador Web: $0,2 por 1k URLs
- Proxies: $2,8 por GB
Junte-se à nossa comunidade para Teste Grátis e mais descontos!
Bypass detecção de anti-bot: Guias do Solver de CAPTCHA Scrapeless
- Passo 1. Faça login no Scrapeless.
- Passo 2. Acesse a interface de "Solver de CAPTCHA". Clique no serviço de desbloqueio de reCAPTCHA e selecione o tipo de reCAPTCHA que você precisa adaptar: normal ou empresarial.
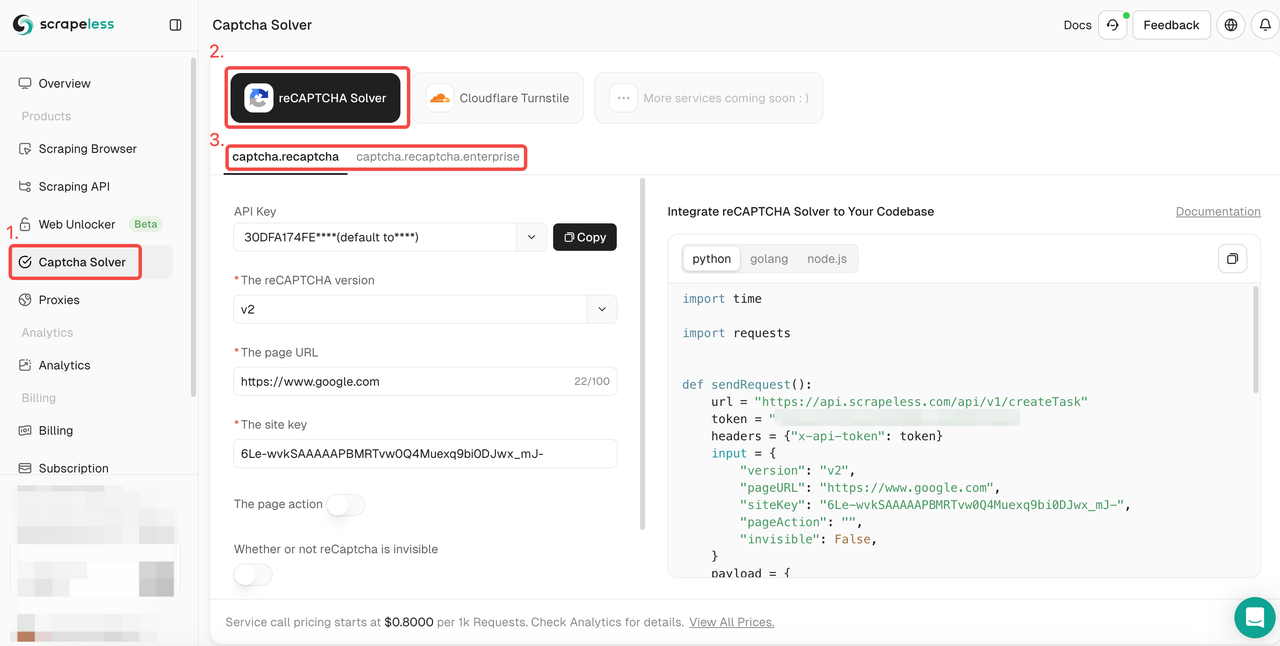
- Passo 3. Configure as informações relevantes que você precisa na caixa de operação à esquerda: versão do reCAPTCHA, URL da página, chave do site, ação, proxy, etc.
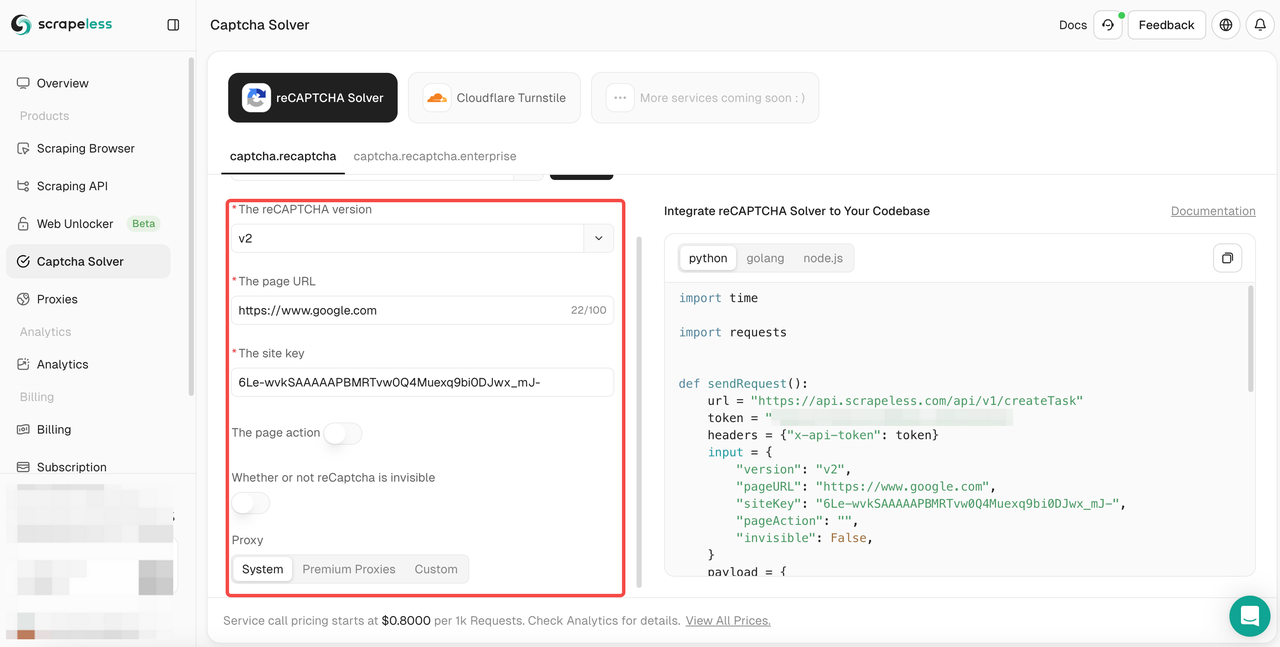
- Passo 4. Após completar a configuração, você pode obter o feedback do código relevante na caixa de código à direita. Você só precisa copiá-lo e integrá-lo ao seu programa. Aqui usamos o exemplo de scraping em scrapeless.com. Vamos desbloquear o reCAPTCHA v2, usar um proxy Premium e configurá-lo para "Cingapura", e definir a ação da página para "Scraping". O seguinte é o feedback do código que obtive:
Python
import time
import requests
def sendRequest():
url = "https://api.scrapeless.com/api/v1/createTask"
token = "xxx"
headers = {"x-api-token": token}
input = {
"version": "v2",
"pageURL": "https://www.scrapeless.com/en",
"siteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-",
"pageAction": "scraping",
"invisible": False,
}
payload = {
"actor": "captcha.recaptcha",
"input": input
}
# Criar tarefa
result = requests.post(url, json=payload, headers=headers).json()
taskId = result.get("taskId")
if not taskId:
print("Falha ao criar tarefa:", result)
return
print(f"Tarefa criada: {taskId}")
# Polling por resultado
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + taskId
resp = requests.get(url, headers=headers)
result = resp.json()
if resp.status_code != 200:
print("tarefa falhou:", resp.text)
return
if result.get("success"):
return result["solution"]["token"]
data = sendRequest()
print(data)actor: O ator da tarefa atualstate: O status da tarefa atualsuccess: Se a tarefa é bem-sucedidataskId: Se a tarefa é criada com sucesso, você receberá um taskId. Em seguida, você precisará usar esse taskId para consultar os resultadossolution: Se a tarefa for bem-sucedida, você receberá a soluçãomessage: Se a tarefa falhar, verifique esta mensagem de erro
Para mais informações, consulte nosso documentação tutorial.
Estratégias Avançadas para Bypass de Anti-bot com Solvers de CAPTCHA
Desviar de medidas anti-bot, como CAPTCHAs, requer uma combinação de scraping respeitoso e técnicas avançadas. Aqui está como permanecer eficiente e ético em suas operações de scraping.
Práticas de Scraping Respeitoso
- Adira ao robots.txt: Sempre verifique o arquivo
robots.txtdo site para seguir as diretrizes sobre o que pode ser extraído. - Limite as Taxas de Solicitação: Introduza atrasos aleatórios entre solicitações para imitar o comportamento de navegação humano, evitando solicitações rápidas e consecutivas que acionam bloqueios.
- Rotacione Agentes de Usuário: Use um pool de agentes de usuário realistas para simular diferentes navegadores e dispositivos, evitando a detecção de cadeias de agente de usuário estáticas.
Técnicas Progressivas
- Proxies Residenciais: Use proxies residenciais para distribuir solicitações entre vários endereços IP, tornando mais difícil para os sites bloqueá-lo.
- Navegadores Sem Cabeça: Ferramentas como Puppeteer e Selenium simulam interações reais do usuário, tornando mais difícil para os sistemas anti-bot detectarem sua atividade de scraping.
- Aprendizado de Máquina para Anti-detecção: Treine bots para replicar o comportamento humano de forma mais próxima, analisando padrões de navegação, reduzindo as chances de ser sinalizado como um bot.
É um Fim
Parabéns! Você aprendeu muito sobre detecção de anti-bot. Você passou do básico para se tornar um mestre em anti-detectação!
Agora você sabe:
- O que são anti-bots.
- Algumas melhores práticas para contornar técnicas anti-bot.
- Alguns dos mecanismos mais populares dos quais os anti-bots dependem.
- Como contornar todos eles.
Você pode descobrir mais técnicas de anti-scraping, mas, não importa quão sofisticado seu scraper seja, algumas técnicas ainda poderão detê-lo.
Todos esses problemas podem ser evitados usando o Scrapeless, uma API de scraping da web com proxies avançados, rotação de IP embutida, capacidade de navegador sem cabeça e capacidades avançadas de contorno de anti-bot. É uma maneira mais simples de fazer scraping na web.
Comece seu teste gratuito agora!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


