
Como Bypass do Desafio Cloudflare em 2025: Guia Completo
Advanced Data Extraction Specialist
Cloudflare está constantemente evoluindo suas medidas de segurança, tornando cada vez mais difícil para métodos tradicionais de scraping contornarem desafios como cloudflare-challenge e Cloudflare Turnstile. Ferramentas de código aberto como FlareSolverr tornaram-se ineficazes devido às atualizações do Cloudflare, deixando os desenvolvedores em busca de novas soluções.
Neste guia, exploraremos os métodos mais eficazes em 2025 para contornar os desafios de segurança do Cloudflare, incluindo:
- Scrapeless Scraping Browser – Uma API de navegador headless para scraping sem interrupções
- Scrapeless Web Unlocker – Uma API robusta para renderização JS e interação
Se você é um especialista em automação na web ou um iniciante, este guia oferece soluções passo a passo para ajudá-lo a extrair dados sem enfrentar barreiras.
PARTE 1: Entendendo os Desafios e Camadas de Segurança do Cloudflare
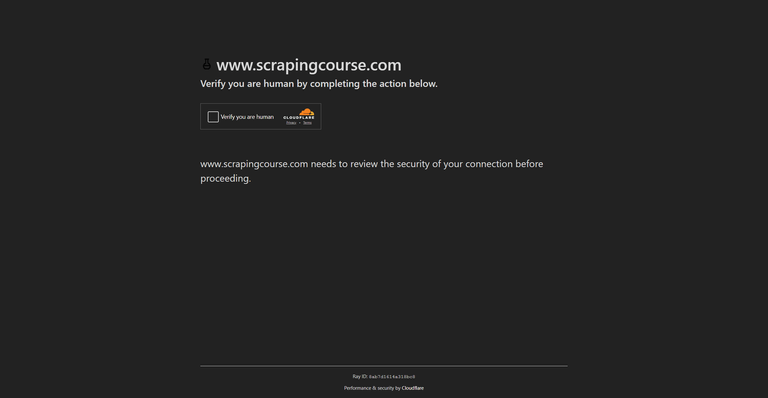
Antes de mergulhar nas soluções, é essencial entender os principais mecanismos de segurança do Cloudflare que bloqueiam solicitações automatizadas:
1. Desafio JS do Cloudflare
O desafio JavaScript do Cloudflare (cloudflare-challenge) exige que os navegadores executem um script antes de acessar a página solicitada. Este script gera um token de liberação armazenado em cookies (cf_clearance). Bots e scrapers sem capacidades de execução de JavaScript falham neste desafio.
2. Cloudflare Turnstile
Turnstile é a alternativa CAPTCHA do Cloudflare, detectando dinamicamente tráfego não humano. Frequentemente exige execução de JavaScript e rastreamento comportamental para ser concluído.
3. Impressão Digital do Navegador
O Cloudflare utiliza impressão digital avançada para detectar interações não humanas. Isso inclui a análise de:
- Impressão digital TLS (assinaturas JA3)
- Cabeçalhos HTTP e ordem
- WebGL, Canvas e Impressão Digital de Áudio
4. Limitação de Taxa e Proibições de IP
Mesmo que você contorne o desafio uma vez, solicitações repetidas do mesmo IP podem acionar proibições ou níveis de segurança aumentados.
PARTE 2: Como o Desafio JS do Cloudflare é Diferente de Outros Desafios?
Diferente do CAPTCHA, que requer interação do usuário, o Desafio JS é executado automaticamente em segundo plano, tornando-o menos intrusivo para usuários legítimos, ao mesmo tempo que bloqueia tráfegos suspeitos. No entanto, para scrapers da web e ferramentas de automação, contornar o Desafio JS pode ser desafiador, uma vez que muitos clientes HTTP básicos e navegadores headless não conseguem executar JavaScript corretamente.
PARTE 3: Contornando o Desafio JS do Cloudflare com Scrapeless Scraping Browser
3.1 O que é Scrapeless Scraping Browser?
Scrapeless Scraping Browser é uma solução de alto desempenho que fornece um ambiente de navegador headless, permitindo que você contorne desafios de JavaScript sem manter sua própria infraestrutura. Ele se integra com Puppeteer e Playwright para automação sem interrupções.
O Scrapeless Scraping Browser é a ferramenta de contorno do Cloudflare mais avançada, fornecendo:
✔️ 99,9% de taxa de sucesso para contornar o desafio do Cloudflare
✔️ Compatibilidade perfeita com Puppeteer / Playwright
✔️ Dirigido por AI, adapta-se automaticamente às últimas políticas de segurança
✔️ Suporte a proxies globais, reduzindo o risco de proibição
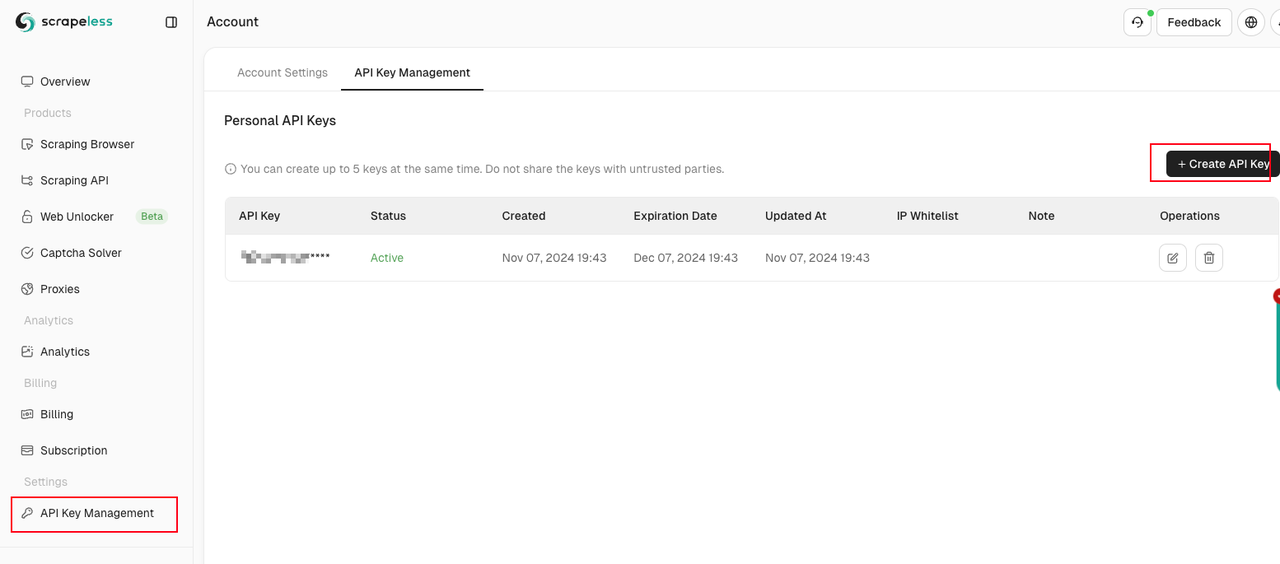
3.2 Configuração e Configuração da Chave da API
Antes de usar o Scrapeless Scraping Browser, obtenha uma chave da API:
- Inscreva-se no painel do Scrapeless
- Recupere sua chave da API na aba de configurações
🎁 Obtenha 10.000 solicitações de API gratuitas para novos usuários! Inscreva-se agora
3.3 Implementando o Contorno do Cloudflare com o Scrapeless Browser
Quando nos conectamos a um navegador para acessar um site-alvo, o Scrapeless detecta e resolve automaticamente os CAPTCHAs. No entanto, precisamos garantir que o CAPTCHA tenha sido resolvido com sucesso. Como podemos conseguir isso? Boas notícias! O Scrapeless Scraping Browser estende o CDP padrão (Protocolo de Ferramentas de Desenvolvimento do Chrome) com um conjunto de funções personalizadas poderosas.
Você pode observar diretamente o status do solucionador de CAPTCHA verificando os resultados retornados da API CDP:
Captcha.detected: CAPTCHA detectadoCaptcha.solveFinished: CAPTCHA resolvido com sucessoCaptcha.solveFailed: Falha na resolução do CAPTCHA
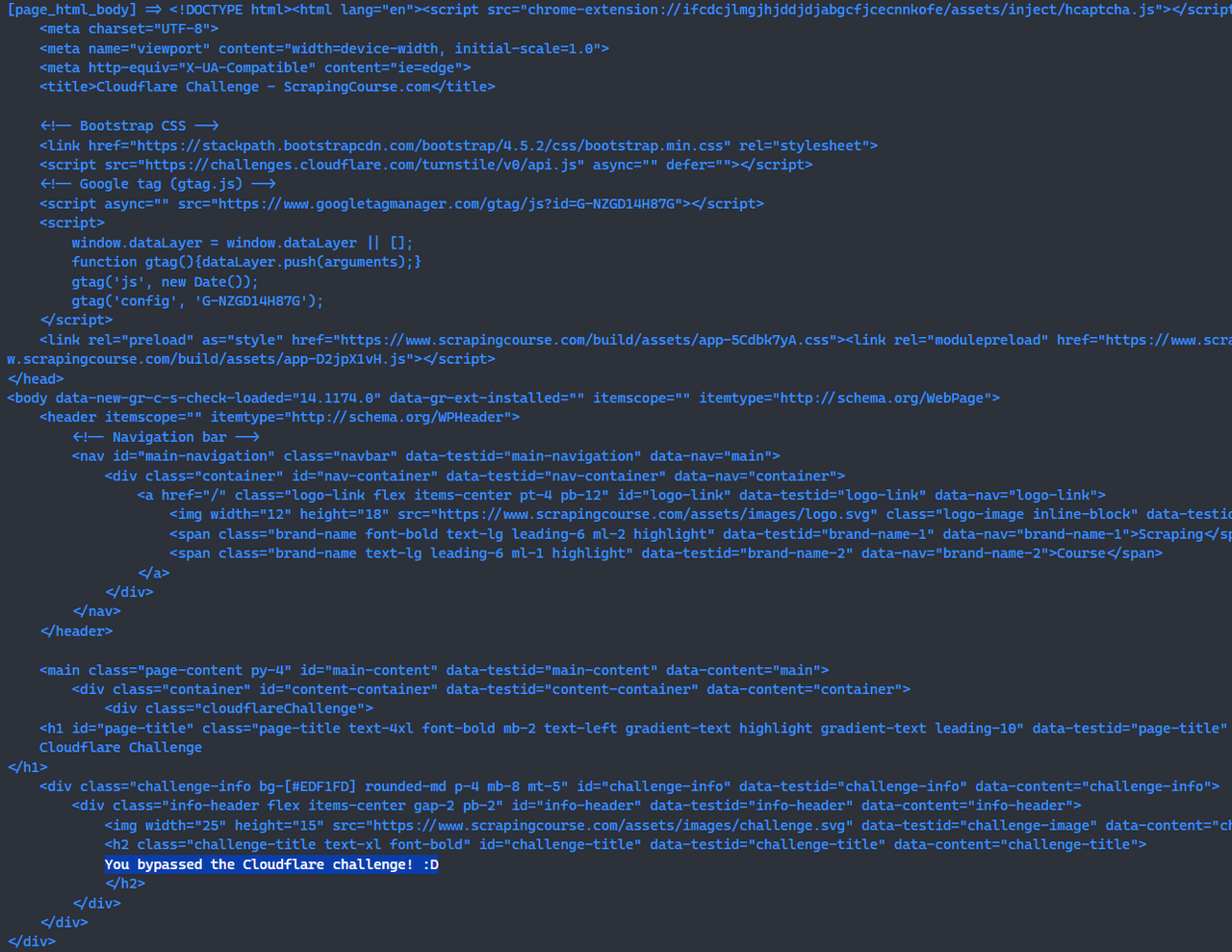
Em seguida, usamos scrapeless browserless para acessar diretamente o site de teste do cloudflare-challenge e adicionar uma captura de tela, o que nos permite ver o efeito de forma muito intuitiva. Antes de tirar a captura de tela, observe que é necessário usar waitForSelector para aguardar os elementos na página, garantindo que o desafio do Cloudflare tenha sido contornado com sucesso.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// Aguardando elementos na página do site, garantindo que o desafio do Cloudflare tenha sido superado com sucesso.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});Parabéns! 🎉 você superou o desafio do cloudflare com o scrapeless browserless.

Recuperando o cookie cf_clearance e Headers
Além disso, após passar pelo desafio do Cloudflare, você também pode recuperar os headers de requisição e o cookie cf_clearance da página de sucesso.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueAtive a interceptação de requisição para capturar os headers de requisição, combinando as requisições da página após o desafio do cloudflare.
await page.setRequestInterception(true);
page.on('request', request => {
// Combinar requisições da página após o desafio do cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});PARTE4: Contornando o Cloudflare Turnstile com o Scrapeless Scraping Browser
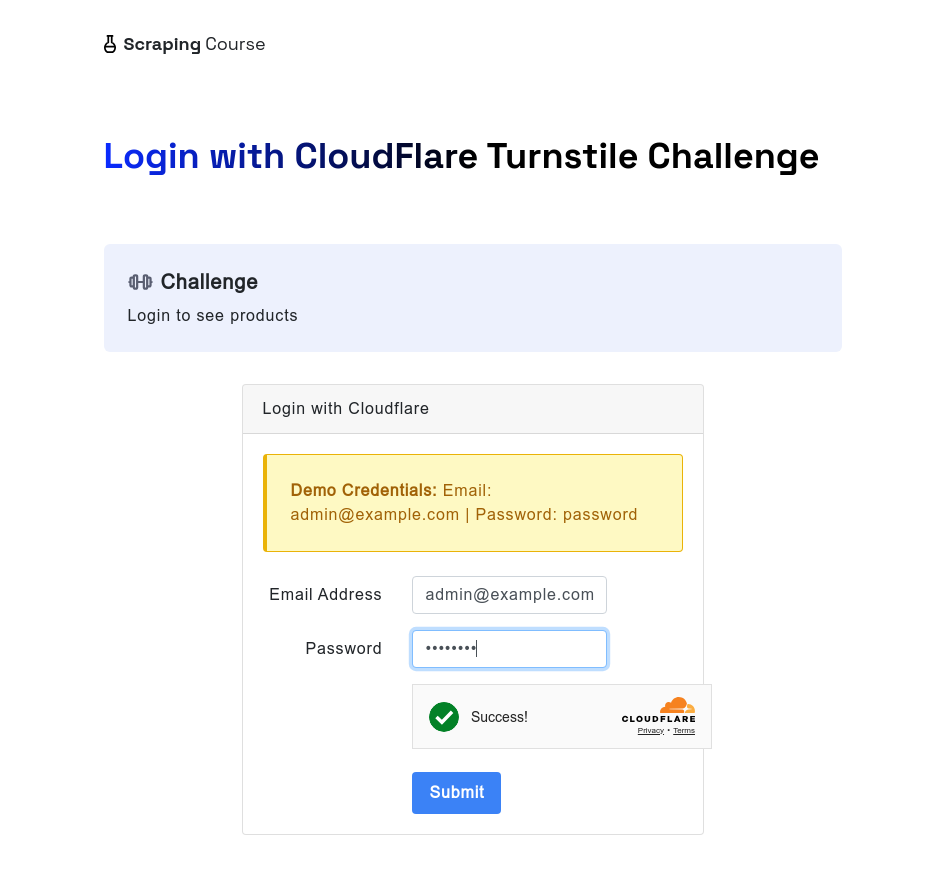
Da mesma forma, ao enfrentar o Cloudflare Turnstile, o scrapeless browser ainda pode lidar com isso automaticamente. O exemplo abaixo visita o site de teste cloudflare-turnstile. Após inserir o nome de usuário e a senha, ele usa o método waitForFunction para aguardar dados de window.turnstile.getResponse(), garantindo que o desafio tenha sido contornado com sucesso. Em seguida, tira uma captura de tela e clica no botão de login para navegar para a próxima página.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Aguardar turnstile desbloquear com sucesso
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Ao executar este script, você poderá ver o efeito de desbloqueio através da captura de tela.
PARTE5: Usando o Scrapeless Web Unlocker para Renderização JavaScript
Scrapeless Web Unlocker permite renderização JavaScript e interações dinâmicas, tornando-se uma ferramenta efetiva para contornar o Cloudflare.
Renderização JavaScript
A renderização JavaScript permite lidar com conteúdo carregado dinamicamente e SPAs (Aplicações de Página Única). Habilita um ambiente de navegador completo, suportando interações de página mais complexas e requisitos de renderização.
js_render=true, usaremos o navegador para solicitar
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}Instruções JavaScript
Fornece um conjunto extenso de diretrizes JavaScript que permitem interagir dinamicamente com páginas da web.
Essas diretrizes permitem que você clique em elementos, preencha formulários, envie formulários ou aguarde a aparição de elementos específicos, proporcionando flexibilidade para tarefas como clicar em um botão “ler mais” ou enviar um formulário.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"js_instructions": [
{
"wait_for": [
".dynamic-content",
30000
]
// Aguardar elemento
},
{
"click": [
"#load-more",
1000
]
// Clique no elemento
},
{
"fill": [
"#search-input",
"termo de busca"
]
// Preencha o formulário
},
{
"keyboard": [
"press",
"Enter"
]
// Simule a pressão da tecla
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Execute JS personalizado
}
]
}
}Exemplo de Bypass de Desafio
O seguinte código de exemplo usa axios para fazer uma solicitação ao serviço Web Unlocker da Scrapeless. Ele ativa js_render e usa a diretiva wait_for do parâmetro js_instructions para esperar por um elemento na página após o desafio do Cloudflare ter sido contornado:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = 'sua_chave_api'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
js_instructions: [
{
wait_for: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Erro:', error);
}
}
sendRequest();🎉 Após executar o script acima, você poderá ver o HTML da página que contornou com sucesso o desafio do Cloudflare no console.
Scrapeless - Uma solução de desbloqueio de sites dinâmicos mais poderosa
Para sites dinâmicos, carregamento via Ajax e aplicações de página única (SPA), a Scrapeless oferece o Web Unlocker, que pode resolver automaticamente os desafios do Cloudflare para evitar ser detectado como um robô.
✅ Bypass automático orientado por IA, adaptando-se às atualizações anti-crawling do Cloudflare
✅ Suporte a pool de proxies global, contorno estável de restrições de IP
✅ Compatibilidade perfeita com Puppeteer / Playwright
💡 Experimente o Scrapeless Web Unlocker agora e obtenha dados de sites dinâmicos com facilidade! 👉 Experimente agora
Perguntas Frequentes sobre o desafio do Cloudflare
Q: O que é um desafio do Cloudflare?
R: Um desafio do Cloudflare é uma medida de segurança usada para proteger sites de atividades maliciosas, como ataques de bots e DDoS. Quando o Cloudflare detecta comportamento suspeito, apresenta um desafio ao visitante para verificar se ele é um usuário legítimo.
Q: Por que estou sendo desafiado em um site protegido pelo Cloudflare?
R: Você pode ser desafiado por várias razões, incluindo uma pontuação de ameaça alta associada ao seu endereço IP, um histórico de atividade suspeita de seu IP, detecção de tráfego automatizado semelhante a bots ou regras específicas definidas pelo proprietário do site que visam sua região ou agente do usuário. O Cloudflare também verifica se seu navegador atende a certos padrões.
Q: Quais são os diferentes tipos de desafios do Cloudflare?
R: O Cloudflare utiliza diferentes tipos de desafios, incluindo Desafios Gerenciados, Desafios JS e Desafios Interativos. Desafios Gerenciados são recomendados, onde o Cloudflare escolhe dinamicamente o tipo apropriado de desafio com base nas características da solicitação. Desafios JS apresentam uma página que requer processamento de JavaScript pelo navegador. Desafios Interativos exigem que o visitante interaja com a página para resolver quebra-cabeças.
Q: O que é um Desafio Gerenciado?
R: Os Desafios Gerenciados são um sistema dinâmico onde o Cloudflare seleciona o tipo de desafio apropriado com base nas características da solicitação. Isso pode incluir páginas de desafio não interativas, desafios interativos personalizados ou Tokens de Acesso Privado. O objetivo é minimizar o uso de CAPTCHAs e reduzir o tempo que os usuários gastam para resolvê-los.
Junte-se à Comunidade Discord da Scrapeless hoje! 🚀 Conecte-se com especialistas em scraping, obtenha dicas exclusivas sobre como contornar desafios do Cloudflare e fique atualizado sobre os últimos recursos. Clique aqui para se juntar agora.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


