
Como contornar a proteção do Cloudflare e o Turnstile usando Scrapeless | Guia completo
Advanced Data Extraction Specialist
Introdução
A extração de dados da web está se tornando cada vez mais difícil devido a mecanismos de segurança avançados como Proteção Cloudflare e Cloudflare Turnstile. Esses desafios são projetados para bloquear o acesso automatizado e dificultar a recuperação de dados por bots. No entanto, com o Scrapeless Scraping Browser, você pode contornar essas restrições de forma eficiente e continuar a extração de dados sem interrupções.
Neste guia, abordaremos três aspectos-chave da superação dos desafios do Cloudflare:
- Como contornar a proteção Cloudflare usando o Scrapeless Browser – Aprenda a contornar medidas de segurança como CAPTCHA e detecção de bots.
- Como recuperar e usar o cookie cf_clearance e os cabeçalhos de solicitação – Entenda como extrair e usar cookies cf_clearance para manter a persistência da sessão.
- Como contornar o Cloudflare Turnstile usando o Scrapeless Browser – Descubra como contornar o desafio Turnstile e automatizar suas tarefas de extração de dados.
Ao final deste tutorial, você terá uma estratégia completa para lidar com a proteção Cloudflare de forma eficaz. Vamos começar!
Parte 1: Como contornar a proteção Cloudflare usando o Scrapeless
Este guia mostrará como usar o Scrapeless e o Puppeteer-core para contornar a proteção Cloudflare em sites.
Etapa 1: Preparação
1.1 Criar uma pasta de projeto
-
Crie uma nova pasta para o projeto, por exemplo, scrapeless-bypass.
-
Navegue até a pasta no seu terminal:
cd path/to/scrapeless-bypass1.2 Inicializar um projeto Node.js
Execute o seguinte comando para criar um arquivo package.json:
npm init -y1.3 Instalar dependências necessárias
Instale o Puppeteer-core, que permite conexões remotas a uma instância do navegador:
npm install puppeteer-coreSe o Puppeteer ainda não estiver instalado no seu sistema, instale a versão completa:
npm install puppeteer puppeteer-coreEtapa 2: Obter a chave API Scrapeless
2.1 Registrar-se no Scrapeless
-
Acesse o Scrapeless e crie uma conta.
-
Navegue até a seção Gerenciamento de Chave API.
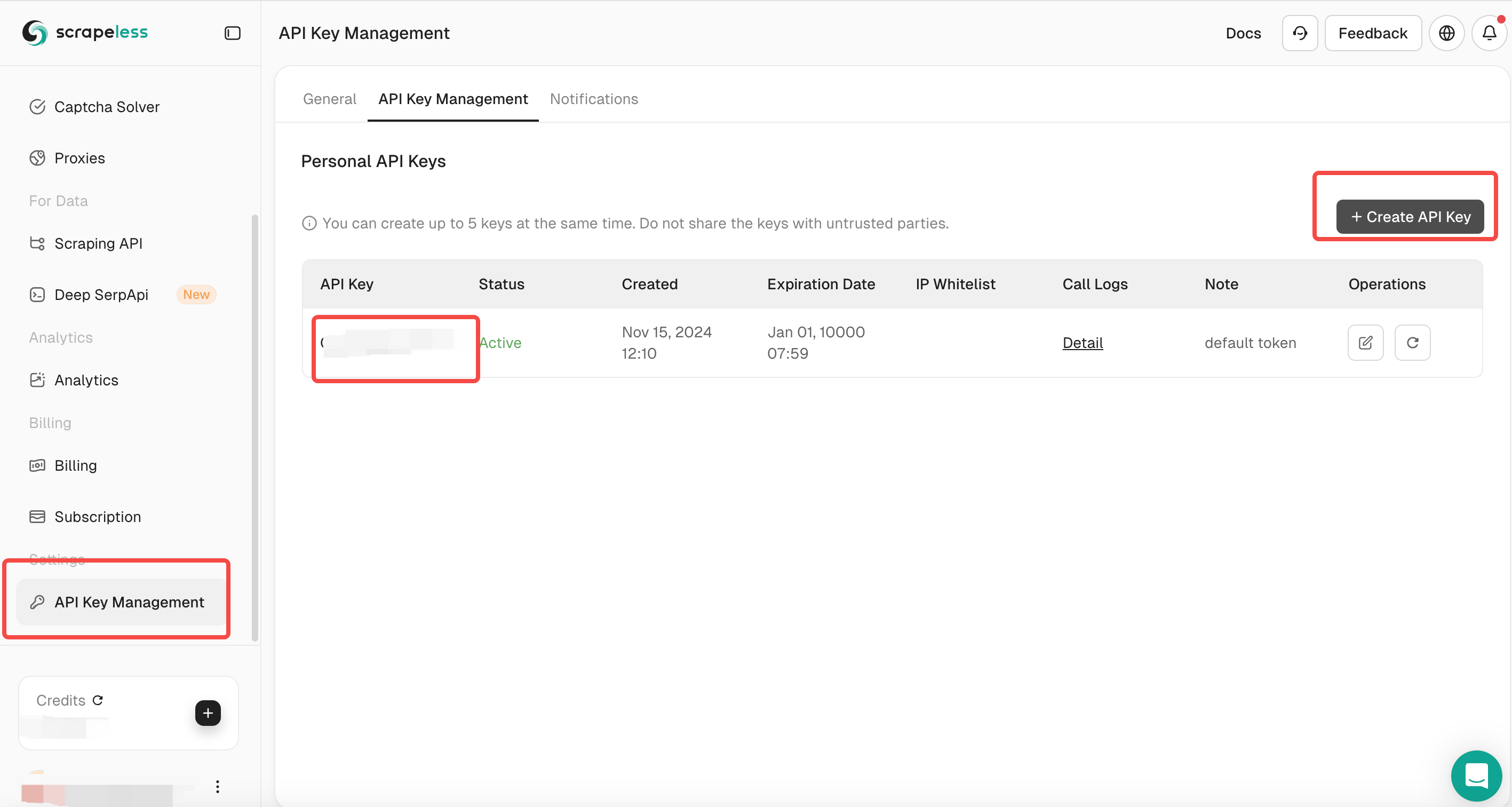
- Gere uma nova chave API e copie-a.
🚀 Pronto para mergulhar mais fundo em contornar as proteções do Cloudflare?
👉 Faça login agora para acessar recursos e tutoriais avançados!
🔒 Precisa de ajuda extra? Junte-se à nossa comunidade Discord para suporte e atualizações em tempo real!
📈 Comece a extrair dados de forma mais inteligente com o Scrapeless Browser hoje mesmo!
Etapa 3: Conectar-se ao Scrapeless Browserless
3.1 Obter a URL de conexão WebSocket
O Scrapeless fornece uma URL de conexão WebSocket para o Puppeteer interagir com um navegador baseado em nuvem.
O formato é:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYSubstitua APIKey pela sua chave API Scrapeless real.
3.2 Configurar os parâmetros de conexão
-
token: Sua chave API Scrapeless
-
session_ttl: Duração da sessão do navegador em segundos (por exemplo, 180 segundos)
-
proxy_country: O código do país para o servidor proxy (por exemplo, GB para o Reino Unido, US para os EUA)
Etapa 4: Escrever o script Puppeteer
4.1 Criar o arquivo de script
Dentro da sua pasta de projeto, crie um novo arquivo JavaScript chamado bypass-cloudflare.js.
4.2 Conectar-se ao Scrapeless e iniciar o Puppeteer
Adicione o seguinte código ao bypass-cloudflare.js:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // Substitua pela sua chave API real
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // Duração da sessão do navegador em segundos
proxy_country: 'GB', // Código do país do proxy
proxy_session_id: 'test_session', // ID da sessão do proxy (mantém o mesmo IP)
proxy_session_duration: '5' // Duração da sessão do proxy em minutos
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Conectado ao Scrapeless');4.3 Abrir uma página web e contornar o Cloudflare
Extenda o script para abrir uma nova página e navegar para um site protegido pelo Cloudflare:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 Aguardar o carregamento dos elementos da página
Certifique-se de que a proteção do Cloudflare seja contornada antes de prosseguir:
javascript
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // Ajuste o seletor conforme necessário4.5 Capturar uma captura de tela
Para verificar a superação bem-sucedida da proteção do Cloudflare, tire uma captura de tela da página:
javascript
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Captura de tela salva como challenge-bypass.png');4.6 Script completo
Aqui está o script completo:
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // Substitua pela sua chave API real
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// Conectar ao Scrapeless
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Conectado ao Scrapeless');
// Abrir uma nova página e navegar para o site de destino
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// Aguardar o carregamento completo da página
await page.waitForTimeout(5000); // Ajuste o atraso se necessário
await page.waitForSelector('main.page-content', { timeout: 30000 });
// Capturar uma captura de tela
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('Captura de tela salva como challenge-bypass.png');
// Fechar o navegador
await browser.close();
console.log('Navegador fechado');
} catch (error) {
console.error('Erro:', error);
}
})();Etapa 5: Executar o script
5.1 Salvar o script
Certifique-se de que o script seja salvo como bypass-cloudflare.js.
5.2 Executar o script
Execute o script usando o Node.js:
node bypass-cloudflare.js5.3 Saída esperada
Se tudo estiver configurado corretamente, o terminal exibirá:
Conectado ao Scrapeless
Captura de tela salva como challenge-bypass.png
Navegador fechadoO arquivo challenge-bypass.png aparecerá na sua pasta de projeto, confirmando que a proteção do Cloudflare foi contornada com sucesso.
🌟 Quer contornar a proteção do Cloudflare com facilidade?
🔑 Faça login aqui e comece a aproveitar as poderosas ferramentas do Scrapeless Browser hoje mesmo!
🚀 Precisa de orientação especializada? Junte-se à nossa comunidade Discord para dicas exclusivas e ajuda para resolução de problemas!
💡 Mantenha-se à frente na extração de dados da web com o Scrapeless Browser — seguro, rápido e confiável!
Etapa 6: Considerações adicionais
6.1 Uso da chave API
-
Certifique-se de que sua chave API seja válida e não tenha excedido sua cota de solicitações.
-
Nunca exponha sua chave API em repositórios públicos (por exemplo, GitHub). Use variáveis de ambiente para segurança.
6.2 Configurações de proxy
-
Ajuste o parâmetro proxy_country para selecionar um local diferente (por exemplo, US para os EUA, DE para a Alemanha).
-
Use um proxy_session_id consistente para manter o mesmo endereço IP em todas as solicitações.
6.3 Seletores de página
-
A estrutura dos sites de destino pode variar, exigindo ajustes em waitForSelector().
-
Use page.evaluate() para inspecionar a estrutura da página e atualizar os seletores de acordo.
Este guia forneceu um método passo a passo para usar o Scrapeless e o Puppeteer-core para contornar a proteção do Cloudflare. Ao aproveitar as conexões WebSocket, as configurações de proxy e o monitoramento de elementos, você pode automatizar eficientemente a extração de dados da web sem ser bloqueado pelo Cloudflare.
Parte 2: Como recuperar e usar o cookie cf_clearance e os cabeçalhos de solicitação
Após contornar com sucesso o desafio do Cloudflare, você pode recuperar os cabeçalhos de solicitação e o cookie cf_clearance da resposta da página bem-sucedida. Esses elementos são cruciais para manter a persistência da sessão e evitar desafios repetidos.
1. Recuperar o cookie cf_clearance
javascript
const cookies = await browser.cookies();
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value;Objetivo:
-
Este código busca todos os cookies, incluindo cf_clearance, que é emitido pelo Cloudflare após passar no seu desafio de segurança.
-
O cookie cf_clearance permite que solicitações subsequentes contornem a proteção do Cloudflare, reduzindo a necessidade de desafios repetidos.
2. Habilitar a interceptação de solicitações e capturar cabeçalhos
javascript
await page.setRequestInterception(true);
page.on('request', request => {
// Corresponder às solicitações da página após o desafio do Cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Objetivo:
-
Habilitar a interceptação de solicitações (setRequestInterception(true)) para monitorar e modificar solicitações de rede.
-
Ouvir eventos de solicitação, acionando sempre que o Puppeteer enviar uma solicitação de rede.
-
Identificar solicitações de desafio do Cloudflare:
-
request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') garante que apenas as solicitações relevantes sejam interceptadas.
-
request.headers()?.['origin'] ajuda a verificar o acesso legítimo.
-
Extrair e imprimir os cabeçalhos de solicitação, que podem ser usados posteriormente para simular solicitações de navegador reais.
-
Continuar a solicitação (request.continue()) para evitar interrupções no carregamento da página.
🔍 Procurando capturar e usar o cookie cf_clearance do Cloudflare de forma eficaz?
💪 Faça login agora para acessar todos os recursos avançados para uma extração de dados mais suave.
3. Por que recuperar cf_clearance e cabeçalhos?
- Persistência da sessão:
-
O cookie cf_clearance permite que solicitações HTTP subsequentes ignorem os desafios do Cloudflare.
-
Este cookie pode ser reutilizado em várias solicitações, minimizando os prompts de verificação.
- Simular solicitações de navegador reais:
-
O Cloudflare examina os cabeçalhos de solicitação, como User-Agent, Referer e Origin.
-
Capturar os cabeçalhos de uma solicitação bem-sucedida garante que as solicitações futuras possam imitar o tráfego legítimo, reduzindo os riscos de detecção.
- Eficiência aprimorada de rastreamento:
- Esses detalhes podem ser armazenados em um banco de dados ou arquivo e reutilizados, evitando desafios desnecessários e otimizando as taxas de sucesso das solicitações.
Ao implementar essas técnicas, você pode melhorar a confiabilidade e a eficiência da extração de dados da web, contornando eficazmente as medidas de segurança do Cloudflare. 🚀
Parte 3: Como contornar o Cloudflare Turnstile usando o Scrapeless Browser
Nesta parte do tutorial, aprenderemos como contornar a proteção do Cloudflare Turnstile usando o Scrapeless Browser com o Puppeteer. O Cloudflare Turnstile é um mecanismo de segurança mais avançado usado para bloquear bots e extração de dados automatizada. Com a ajuda do Scrapeless Browser, podemos contornar essa proteção para interagir com o site como se fossemos um usuário real.
Observação:
"Contornar a proteção do Cloudflare" e "Contornar o Cloudflare Turnstile" têm como alvo mecanismos de segurança diferentes.
- Contornar a proteção do Cloudflare envolve contornar as medidas de segurança gerais do Cloudflare, como CAPTCHA, verificações de JavaScript e limitação de taxa de IP.
- Contornar o Cloudflare Turnstile visa especificamente o Turnstile do Cloudflare, um desafio anti-bot exclusivo que garante a interação humana, sem depender do CAPTCHA tradicional. Contornar o Turnstile derrota esse mecanismo de segurança específico.
Etapa 1: Abrir a página de destino
Começaremos abrindo uma página da web protegida pelo Cloudflare Turnstile, que normalmente exige verificação humana. Abaixo está o código que abre a página da web.
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });Este código usa page.goto() para navegar até a página e aguarda até que o conteúdo DOM seja carregado.
Etapa 2: Preencher as credenciais de login
Assim que a página for carregada, podemos automatizar o processo de preenchimento das credenciais de login (como nome de usuário e senha) para passar na página de login.
javascript
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');Etapa 3: Aguardar o desbloqueio do Turnstile
O Cloudflare Turnstile funciona garantindo que apenas usuários humanos possam prosseguir. Nesta etapa, aguardaremos o desbloqueio do Turnstile verificando se a resposta foi recebida do processo de verificação do Turnstile.
javascript
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});Esta linha de código aguarda a resposta de window.turnstile.getResponse(), o que indica que a verificação do Turnstile foi contornada com sucesso.
💥 Desbloqueie o conteúdo atrás do Cloudflare Turnstile com facilidade.
🔓 Faça login para obter acesso a recursos poderosos de extração de dados.
💬 Junte-se à nossa comunidade Discord para obter ajuda personalizada, dicas e insights do usuário!
🚀 Otimize sua extração de dados da web com o Scrapeless Browser — supere qualquer barreira, incluindo os desafios mais difíceis do Cloudflare!
Etapa 4: Tirar uma captura de tela para verificar
Para confirmar que a contornação foi bem-sucedida, podemos tirar uma captura de tela da página. Isso nos ajuda a verificar se o Turnstile foi contornado com sucesso.
javascript
await page.screenshot({ path: 'challenge-bypass-success.png' });Etapa 5: Clicar no botão de login
Após contornar com sucesso o desafio do Turnstile, podemos simular o usuário clicando no botão de login para enviar o formulário.
javascript
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();Este código clica no botão Enviar e aguarda a navegação da página para a próxima página após o login.
Etapa 6: Tirar outra captura de tela da próxima página
Finalmente, depois de fazer login, tiraremos outra captura de tela para confirmar que a navegação para a próxima página foi bem-sucedida.
javascript
await page.screenshot({ path: 'next-page.png' });Exemplo de código completo
Aqui está o código completo que incorpora todas as etapas descritas acima:
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');
// Aguardar o desbloqueio do Turnstile com sucesso
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
// Tirar captura de tela após a contornação
await page.screenshot({ path: 'challenge-bypass-success.png' });
// Clicar no botão de login
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();
// Tirar captura de tela da próxima página
await page.screenshot({ path: 'next-page.png' });Seguindo este tutorial, você aprendeu com sucesso como contornar a proteção do Cloudflare Turnstile usando o Scrapeless Browser e o Puppeteer. Essa abordagem permite que você interaja com um site, preencha formulários de login e navegue pelo conteúdo enquanto contorna os mecanismos de segurança do Cloudflare. Você pode estender essa técnica para funcionar com outros sites protegidos pelo Turnstile.
Pronto para dominar a contornação do Cloudflare e a extração de dados da web com o Scrapeless Browser?
🚀 Desbloqueie todo o poder do Scrapeless Browser hoje e comece a contornar a proteção do Cloudflare, recuperar cookies e cabeçalhos e contornar os desafios do Turnstile com facilidade!
🔑 Faça login aqui para acessar recursos exclusivos e começar a extrair dados com confiança.
💬 Junte-se à nossa comunidade Discord para se conectar com outros especialistas em extração de dados, obter ajuda para resolução de problemas e manter-se atualizado com as últimas dicas e truques.
💡 Não perca ferramentas e insights poderosos para levar sua extração de dados da web para o próximo nível com o Scrapeless Browser.
Conclusão
Contornar com sucesso a segurança do Cloudflare requer as ferramentas e estratégias certas. Com o Scrapeless Browser, você pode navegar facilmente pelas defesas do Cloudflare, recuperar os cookies e cabeçalhos necessários e superar o desafio do Turnstile sem intervenção manual.
🔑 Inscreva-se agora e leve sua extração de dados da web para o próximo nível!
💬 Precisa de ajuda? Junte-se à nossa comunidade Discord para obter insights de especialistas, suporte para resolução de problemas e manter-se à frente das mais recentes técnicas de extração de dados da web.
Não deixe o Cloudflare te atrasar — desbloqueie a extração de dados perfeita hoje!
FAQ: Contornar o Cloudflare, cookie cf_clearance e desafios do Turnstile
1. O que é a proteção do Cloudflare e por que ela bloqueia os softwares de extração de dados da web?
A proteção do Cloudflare é um serviço de segurança que detecta e mitiga o tráfego automatizado. Ele usa técnicas como CAPTCHAs, desafios de JavaScript e limitação de taxa de IP para impedir que bots acessem conteúdo protegido.
2. O que é cf_clearance e como ele ajuda a contornar o Cloudflare?
O cookie cf_clearance é emitido após um desafio bem-sucedido do Cloudflare. Ele permite que uma sessão do navegador permaneça verificada por um período específico, evitando desafios adicionais. Ao recuperar e reutilizar esse cookie, os softwares de extração de dados podem manter o acesso ininterrupto.
3. Como o Cloudflare Turnstile difere da proteção padrão do Cloudflare?
O Cloudflare Turnstile é um desafio avançado projetado para verificar a presença humana sem CAPTCHAs tradicionais. Ele usa análise de comportamento e outras técnicas de verificação para bloquear bots. Contornar o Turnstile requer fluxos de trabalho automatizados que imitam as interações do usuário real.
4. Usar o Scrapeless Browser é legal para contornar o Cloudflare?
A legalidade de contornar o Cloudflare depende dos termos de serviço e das regulamentações locais do site. Sempre verifique se suas atividades de extração de dados estão em conformidade com as políticas do site e as leis aplicáveis.
5. Como posso começar a usar o Scrapeless Browser para contornar o Cloudflare?
Você pode começar fazendo login no Scrapeless Browser e seguindo as etapas deste guia para implementar soluções de contornação automatizadas.
6. Onde posso obter suporte para o Scrapeless Browser?
Junte-se à nossa comunidade Discord para se conectar com outros desenvolvedores, obter ajuda para resolução de problemas e manter-se atualizado com novos recursos e melhores práticas.
Outros recursos
Como contornar o Cloudflare com o Puppeteer
Aprenda como usar o Puppeteer para contornar as proteções do Cloudflare e acessar o conteúdo da web sem acionar desafios de segurança.
Como usar o Undetected ChromeDriver para extração de dados da web
Descubra técnicas para usar uma instância Undetected ChromeDriver para evitar a detecção durante a extração de dados de sites.
Como extrair dados de preços de hotéis do Google com Node.js
Guia passo a passo sobre a extração de dados de preços de hotéis do Google usando Node.js e o tratamento eficaz de mecanismos anti-bot.
Como extrair dados de cotação de ações do Google Finance em Python
Um tutorial baseado em Python sobre a extração de cotações de ações do Google Finance, incluindo o tratamento de dados renderizados em JavaScript.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


