
Como ignorar o CAPTCHA em Web Scraping usando Python
Advanced Bot Mitigation Engineer
Introdução
Poucas pessoas sabem qual é a forma completa do CAPTCHA.
Na verdade, a abreviatura CAPTCHA significa "Completely Automated Public Turing Test to Tell Computers and Humans Apart".
Os CAPTCHAs são concebidos para identificar utilizadores questionáveis e bots contemporâneos, apresentando problemas difíceis de resolver aos computadores, o que ajuda os proprietários de websites a prevenir a scraping e o rastreio.Devido ao grande número de bibliotecas de terceiros que podem ler texto, interagir com formulários HTML e extrair estruturas HTML sofisticadas, o Python é uma escolha popular para web scraping. Assim, neste artigo iremos explicar como ultrapassar os problemas de CAPTCHA durante o web scraping utilizando Python.
Além de discutirmos soluções práticas anti-CAPTCHA para incorporar nos seus processos de recolha de dados, abordaremos os vários tipos de CAPTCHA que podem ser encontrados no ambiente online atual.
reCAPTCHA
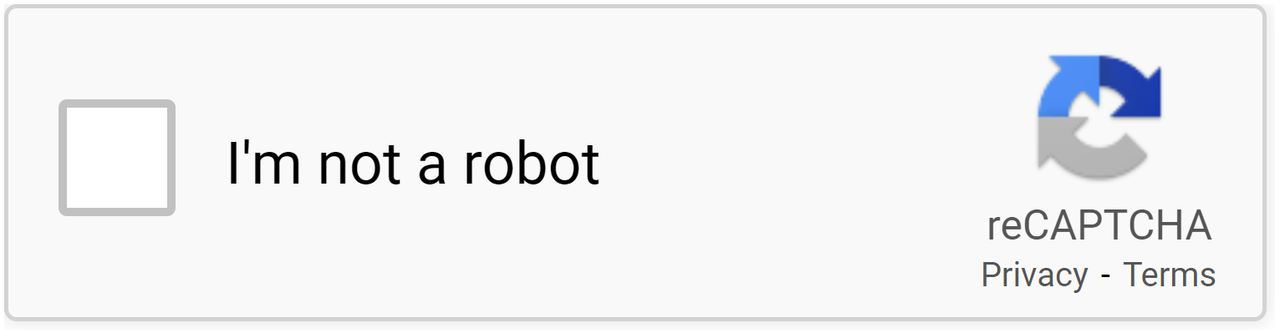
Esta é uma solução CAPTCHA gratuita desenvolvida pela Google que fornece segurança de websites, que emprega métodos de ponta para identificar comportamentos semelhantes aos dos bots, bem como o hCAPTCHA. O Google reCAPTCHA pode agora identificar utilizadores humanos sem qualquer intervenção do utilizador. Utiliza apenas as experiências anteriores do utilizador com outros sites como base para o reconhecimento. A Pesquisa Google, o Maps, o Play, o Shopping e muitos outros serviços e produtos empregam extensivamente o reCAPTCHA.
ImageToText CAPTCHA

Normalmente, o ImageToText CAPTCHA é uma confusão de letras e caracteres não relacionados apresentados num estilo ilegível, com caracteres que foram rodados, redimensionados e distorcidos de diferentes formas.
Áudio CAPTCHA
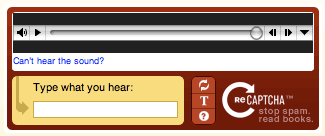
Também chamado de “CAPTCHA baseado no som”, exige que os utilizadores introduzam uma série de letras ou números através de gravações de áudio. Para tornar as coisas mais desafiantes, o áudio é frequentemente complementado por ruído de fundo.
##hCAPTCHA
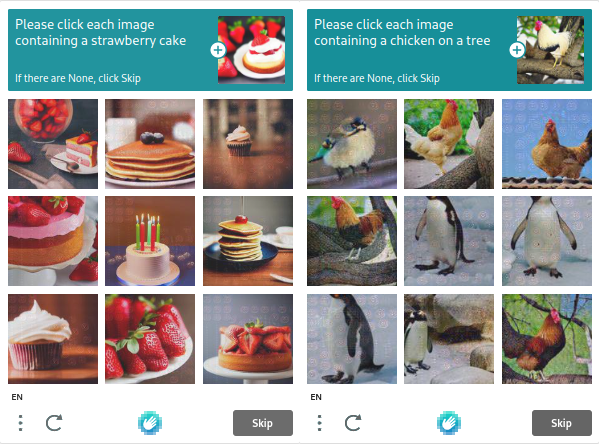
A Intuition Machines é proprietária do hCaptcha, que valoriza a privacidade do utilizador e não recolhe dados desnecessários. Como resultado, a sua popularidade está a aumentar. As tarefas padrão de avaliação de bots, como a verificação de caixas e o reconhecimento de imagens, são realizadas utilizando o hCaptcha. Os testes no hCaptcha são mais complicados do que os do reCAPTCHA, mas pode alterar os parâmetros para os tornar mais difíceis ou mais fáceis.
Web scraping: o que é?
A técnica de obtenção de dados de sites é conhecida por web scraping. Implica a utilização de dispositivos automatizados para extrair dados de sites, por vezes chamados de web scrapers ou crawlers. Estes programas percorrem a hierarquia de um site, obtêm o código HTML e utilizam padrões ou directrizes predefinidos para extrair os dados necessários.
Existem vários usos para o web scraping, incluindo:
- Análise da concorrência: manter um olho na presença e nas táticas dos rivais na Internet
- Recolha de dados: compilação de texto, imagem e outros conteúdos de media de sites
- Monitorização de preços: manter o controlo e contrastar os custos dos produtos de vários comerciantes da Internet
- Agregação de materiais: criação de uma base de dados ou site consolidado, reunindo materiais de várias fontes
- Investigação de mercado: Para compreender a dinâmica do mercado, são analisadas as tendências, o feedback dos consumidores e outros dados pertinentes.
De salientar que o web scraping, embora seja um instrumento potente para a recolha de dados, deve ser executado de forma ética e legal. A recolha de informações privadas ou confidenciais pode ser ilegal, e vários sites têm proibições explícitas contra isso nos seus termos de serviço. Ao participar em atividades de scraping online, certifique-se de que está sempre de acordo com as condições de utilização do site e com quaisquer leis aplicáveis.
Exemplo de Web Scraping
O web scraping é o processo de obtenção de dados de sites, geralmente de forma automática com o recurso a ferramentas ou scripts de programação. Este é um exemplo básico que faz uso do pacote BeautifulSoup, que é uma opção popular para atividades de web scraping, e Python.
Suponhamos por agora que desejamos recuperar os nomes dos artigos mais recentes de uma fonte noticiosa imaginária. A estrutura do HTML pode ser semelhante a esta:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>Vamos agora utilizar o BeautifulSoup e o Python para extrair os títulos destes artigos:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")Para obter o conteúdo HTML, utilizamos a biblioteca requests para realizar um pedido GET ao site. De seguida, o BeautifulSoup é utilizado para analisar o conteúdo HTML ('html. parser' é utilizado neste caso). Para descobrir cada elemento div que contém o artigo da classe, utilizamos o find_all. Localizamos o elemento h2 com o título da classe de cada artigo e recuperamos o seu conteúdo de texto.
Como usar o Scrapeless para ignorar o CAPTCHA durante o web scraping
Farto de constantes bloqueios de web scraping e CAPTCHAs?
Apresentamos o Scrapeless - a solução completa de web scraping definitiva!
Desbloqueie todo o potencial da sua extração de dados com o nosso poderoso conjunto de ferramentas:
Best CAPTCHA solver
Resolva automaticamente CAPTCHAs avançados, mantendo a sua raspagem contínua e ininterrupta.
Experimente a diferença – experimente gratuitamente!
Observações finais
Um dos obstáculos mais frequentes à recolha de dados públicos são os CAPTCHAs, pelo que é fundamental descobrir um método fiável e superior para os ultrapassar. Este artigo abordou os vários tipos de CAPTCHA atualmente disponíveis e forneceu algumas soluções anti-CAPTCHA que pode tentar utilizar nas suas atividades de Web Scraping.
Por favor, utilize o nosso site oficial para entrar em contacto connosco se tiver alguma dúvida sobre este assunto ou quiser mais informações sobre as melhores formas do Scrapeless para contornar os CAPTCHAs, como o Web Unlocker ou o CAPTCHA Solver.
PERGUNTAS FREQUENTES
Como podem os CAPTCHAs ser evitados durante o Web Scraping?
Ao adquirir dados da web, existem várias técnicas para contornar o CAPTCHA. Um truque útil é ajustar a impressão digital do seu scraper modificando os cabeçalhos do User-Agent. Além disso, pode querer considerar o emprego de programas automáticos como o Web Unlocker, que o podem ajudar a resolver problemas de CAPTCHA.
Porque é que os proprietários de sites usam CAPTCHAs para evitar a raspagem?
Os CAPTCHAs são utilizados em sites para distinguir entre bots perigosos e visitantes genuínos. Servem como medida de segurança para evitar comportamentos hostis ou potencialmente destrutivos dos bots, como spam ou transações fraudulentas.
Existe um método para ignorar o CAPTCHA durante o Web Scraping?
Sim, existe uma variedade de serviços disponíveis no mercado feitos especialmente para contornar um CAPTCHA. Os exemplos incluem o Web Unlocker e o solver CAPTCHA. Por exemplo, a ferramenta do Scrapeless seleciona o conjunto apropriado de cabeçalhos, cookies, propriedades do navegador, etc.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


