
Como alcançar um rastreador de Google Trends no Pipedream?
Advanced Data Extraction Specialist
Nos campos de marketing digital, SEO e análise de tendências emergentes, manter-se atualizado com as mudanças nas Tendências do Google é essencial. No entanto, verificar e compilar manualmente os dados de tendências de palavras-chave consome tempo, é propenso a erros e ineficiente. Para resolver isso, desenvolvemos um sistema de relatórios automatizado que integra o Pipedream, a API Scrapeless e o Webhook do Discord para otimizar todo o processo - desde a coleta de palavras-chave e processamento de dados até a entrega de resultados.
Este artigo o guiará pelos componentes e pela implementação deste sistema automatizado em detalhes.
Principais Características
-
Análise Automatizada de Tendências de Palavras-chave: Obtém dados de tendências do último mês usando Scrapeless.
-
Pontuação e Processamento Inteligente: Calcula automaticamente a popularidade média e a flutuação de tendências para cada palavra-chave.
-
Relatórios Analíticos Visuais: Gera relatórios estruturados com visuais e os envia diretamente para o Discord.
Pré-requisitos
- Registrar-se no Scrapeless e obter sua Chave de API.
- Localizar seu Token de API e copiá-lo para uso posterior.
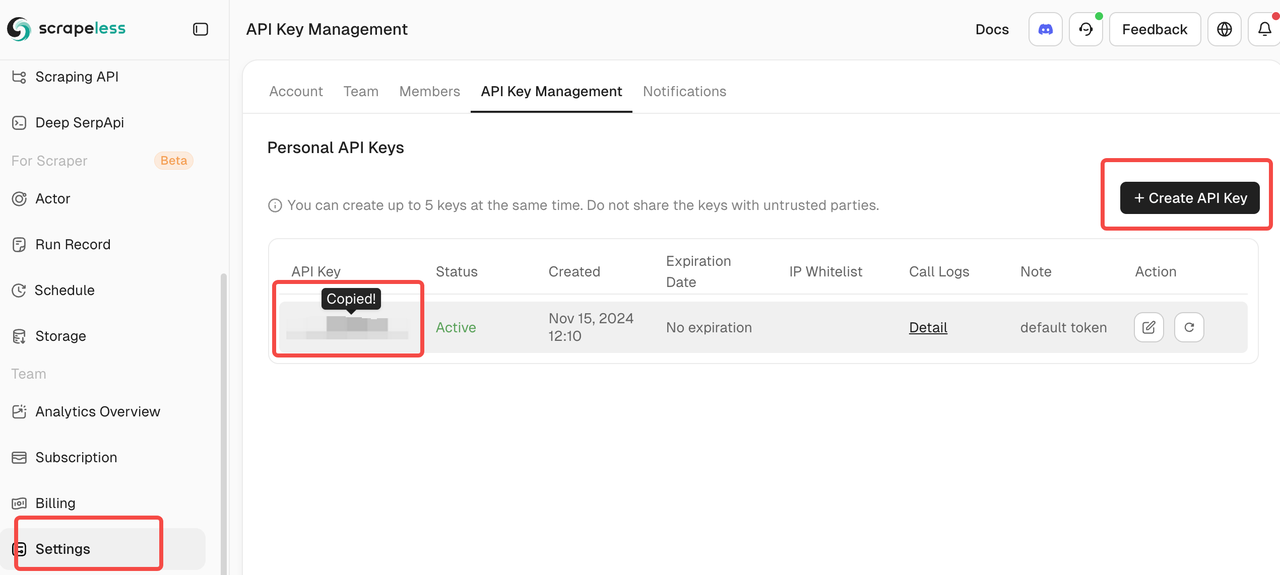
⚠️ Nota: Mantenha seu Token de API seguro e não compartilhe-o com outras pessoas.
- Faça login no Pipedream
- Clique em "+ Novo Fluxo de Trabalho" para criar um novo fluxo de trabalho.
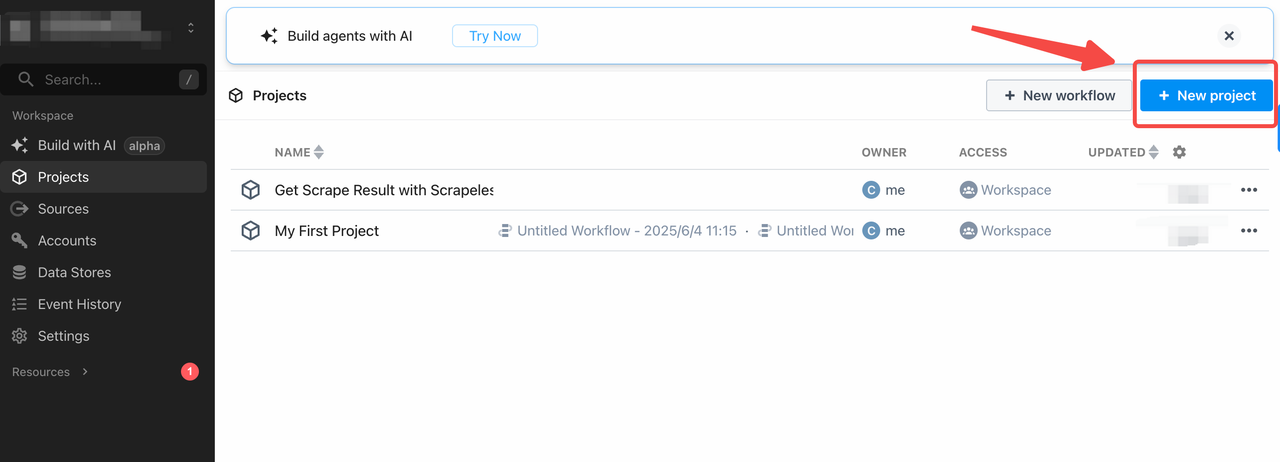
Como Criar um Sistema de Relatórios Automatizado do Google Trends (Pipedream + Scrapeless + Discord)
Estrutura do Fluxo de Trabalho
| Nome da Etapa | Tipo | Função |
|---|---|---|
trigger |
Agendamento | Aciona o fluxo de trabalho em um cronograma (por exemplo, a cada hora) |
http |
Código Node.js | Envia tarefas de raspagem para o Scrapeless e obtém os resultados |
code_step |
Código Node.js | Analisa e processa os dados raspados |
discord_notify |
Código Node.js | Envia os resultados da análise para o Discord via webhook |
Etapa 1: Acionador Agendado
Selecione o tipo de acionador como Agendamento e defina o horário do acionador para executar automaticamente este fluxo de trabalho todos os domingos às 16:00 no horário UTC.
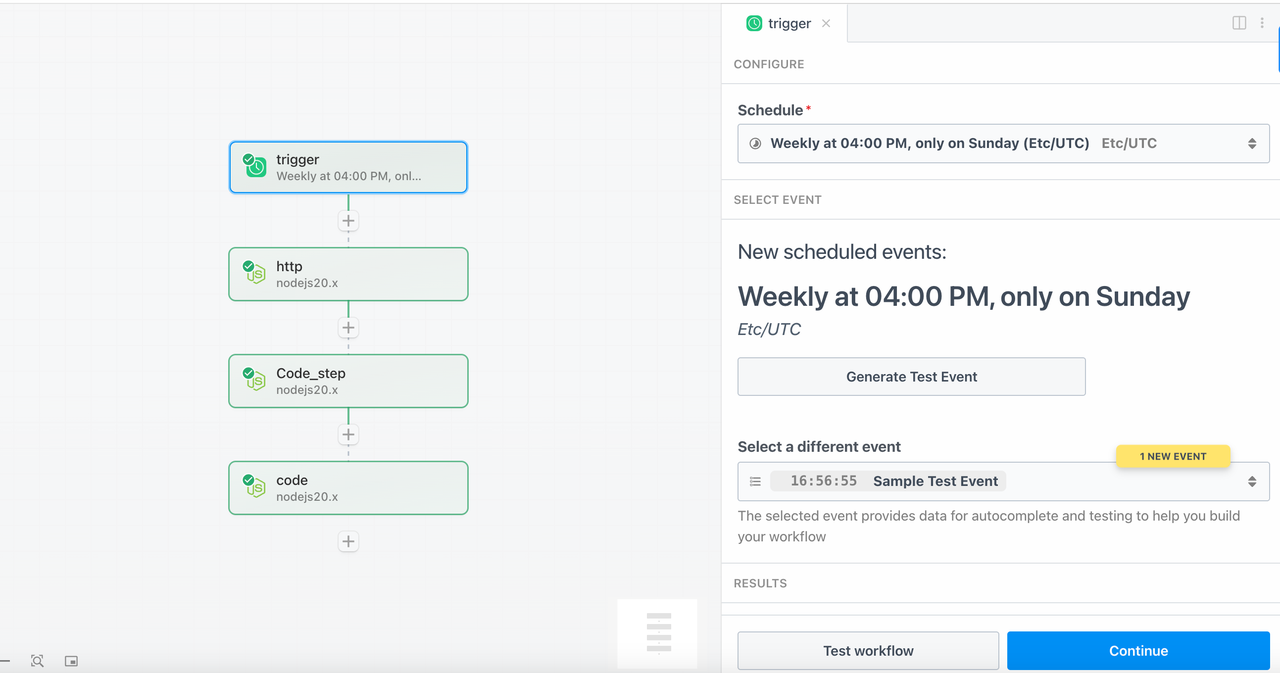
Etapa 2 - http (solicitar ao Scrapeless para rastrear tendências de palavras-chave)
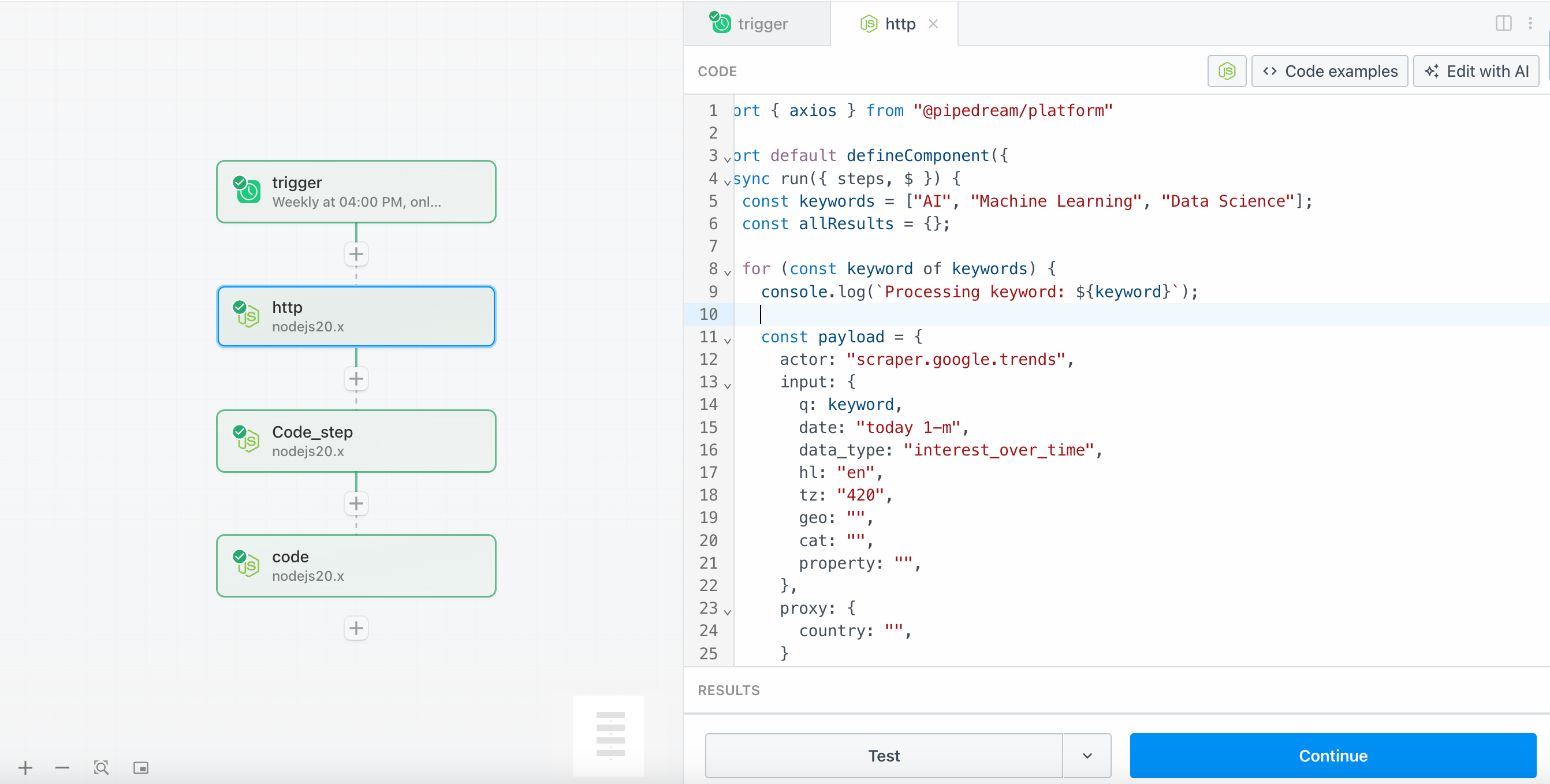
- Adicione uma etapa de código Node.js. O seguinte é um exemplo de código integrando a lógica de chamada da API Scrapeless.
import { axios } from "@pipedream/platform"
export default defineComponent({
async run({ steps, $ }) {
const keywords = ["AI", "Machine Learning", "Data Science"];
const allResults = {};
for (const keyword of keywords) {
console.log(`Processando palavra-chave: ${keyword}`);
const payload = {
actor: "scraper.google.trends",
input: {
q: keyword,
date: "today 1-m",
data_type: "interest_over_time",
hl: "en",
tz: "420",
geo: "",
cat: "",
property: "",
},
proxy: {
country: "",
}
};
try {
const response = await axios($, {
method: 'POST',
url: 'https://api.scrapeless.com/api/v1/scraper/request',
headers: {
'Content-Type': 'application/json',
'x-api-token': 'CHAVE DE API Scrapeless'
},
data: payload
});
console.log(`Resposta para ${keyword}:`, response);
if (response.job_id) {
console.log(`Trabalho criado para ${keyword}, ID: ${response.job_id}`);
let attempts = 0;
const maxAttempts = 12;
let jobResult = null;
while (attempts < maxAttempts) {
await new Promise(resolve => setTimeout(resolve, 10000));
attempts++;
try {
const resultResponse = await axios($, {
method: 'GET',
url: `https://api.scrapeless.com/api/v1/scraper/result/${response.job_id}`,
headers: {
'x-api-token': 'CHAVE DE API Scrapeless'
}
});
console.log(`Tentativa ${attempts} para ${keyword}:`, resultResponse);
if (resultResponse.status === 'completed') {
jobResult = resultResponse.result;
```javascript
console.log(`Trabalho concluído para ${keyword}:`, jobResult);
break;
} else if (resultResponse.status === 'failed') {
console.error(`Trabalho falhou para ${keyword}:`, resultResponse);
break;
} else {
console.log(`Trabalho ainda em execução para ${keyword}, status: ${resultResponse.status}`);
}
} catch (error) {
console.error(`Erro ao verificar o status do trabalho para ${keyword}:`, error);
}
}
if (jobResult) {
allResults[keyword] = jobResult;
} else {
allResults[keyword] = {
error: `Tempo de espera ou falha do trabalho após ${attempts} tentativas`,
job_id: response.job_id
};
}
} else {
allResults[keyword] = response;
}
} catch (error) {
console.error(`Erro para ${keyword}:`, error);
allResults[keyword] = {
error: `Requisição falhou: ${error.message}`
};
}
}
console.log("Resultados finais:", JSON.stringify(allResults, null, 2));
return allResults;
},
})Nota:
- Esta etapa usa o ator
scraper.google.trendsdo Scrapeless para recuperar os dados de "interest_over_time" para cada palavra-chave. - As palavras-chave padrão são:
["AI", "Machine Learning", "Data Science"]. Você pode substituí-las conforme necessário. - Substitua
YOUR_API_TOKENpelo seu token de API real.
Etapa 3 - code_step (processando dados coletados)
- Adicione outra etapa de código Node.js. Aqui está o exemplo de código
export default defineComponent({
async run({ steps, $ }) {
const httpData = steps.http.$return_value;
console.log("Dados HTTP recebidos:", JSON.stringify(httpData, null, 2));
const processedData = {};
const timestamp = new Date().toISOString();
for (const [keyword, data] of Object.entries(httpData)) {
console.log(`Processando ${keyword}:`, data);
let timelineData = null;
let isPartial = false;
if (data?.interest_over_time?.timeline_data) {
timelineData = data.interest_over_time.timeline_data;
isPartial = data.interest_over_time.isPartial || false;
} else if (data?.timeline_data) {
timelineData = data.timeline_data;
} else if (data?.interest_over_time && Array.isArray(data.interest_over_time)) {
timelineData = data.interest_over_time;
}
if (timelineData && Array.isArray(timelineData) && timelineData.length > 0) {
console.log(`Encontrados ${timelineData.length} pontos de dados para ${keyword}`);
const values = timelineData.map(item => {
const value = item.value || item.interest || item.score || item.y || 0;
return parseInt(value) || 0;
});
const validValues = values.filter(v => v >= 0);
if (validValues.length > 0) {
const average = Math.round(validValues.reduce((sum, val) => sum + val, 0) / validValues.length);
const trend = validValues.length >= 2 ? validValues[validValues.length - 1] - validValues[0] : 0;
const max = Math.max(...validValues);
const min = Math.min(...validValues);
const recentValues = validValues.slice(-7);
const earlyValues = validValues.slice(0, 7);
const recentAvg = recentValues.length > 0 ? recentValues.reduce((a, b) => a + b, 0) / recentValues.length : 0;
const earlyAvg = earlyValues.length > 0 ? earlyValues.reduce((a, b) => a + b, 0) / earlyValues.length : 0;
const weeklyTrend = Math.round(recentAvg - earlyAvg);
processedData[keyword] = {
keyword,
average,
trend,
weeklyTrend,
values: validValues,
max,
min,
dataPoints: validValues.length,
isPartial,
timestamps: timelineData.map(item => item.time || item.date || item.timestamp),
lastValue: validValues[validValues.length - 1],
firstValue: validValues[0],
volatility: Math.round(Math.sqrt(validValues.map(x => Math.pow(x - average, 2)).reduce((a, b) => a + b, 0) / validValues.length)),
status: 'success'
};
} else {
processedData[keyword] = {
keyword,
average: 0,
trend: 0,
weeklyTrend: 0,
values: [],
max: 0,
min: 0,
dataPoints: 0,
isPartial: false,
error: "Nenhum valor válido encontrado nos dados da linha do tempo",
status: 'error',
rawTimelineLength: timelineData.length
};
}
} else {
processedData[keyword] = {palavra-chave,
média: 0,
tendência: 0,
tendênciaSemanal: 0,
valores: [],
max: 0,
min: 0,
pontosDeDados: 0,
éParcial: falso,
erro: "Nenhum dado de linha do tempo encontrado",
status: 'erro',
chavesDisponíveis: dados ? Object.keys(dados) : []
};
}
}
const resumo = {
timestamp,
totalPalavrasChave: Object.keys(dadosProcessados).length,
palavrasChaveBemSucedidas: Object.values(dadosProcessados).filter(d => d.status === 'sucesso').length,
período: "hoje 1-m",
dados: dadosProcessados
};
console.log("Dados processados finais:", JSON.stringify(resumo, null, 2));
return resumo;},
})
---
Ele calculará as seguintes métricas com base nos dados retornados pelo Scrapeless:
* **Valor médio**
* **Mudança de tendência semanal** (últimos 7 dias vs. 7 dias anteriores)
* **Valores Máximos / Mínimos**
* **Volatilidade**
**Nota:**
* Cada palavra-chave gerará um objeto de análise detalhada, facilitando a visualização e futuras notificações.
### Etapa 4 - discord_notify (Enviar relatório de análise para o Discord)
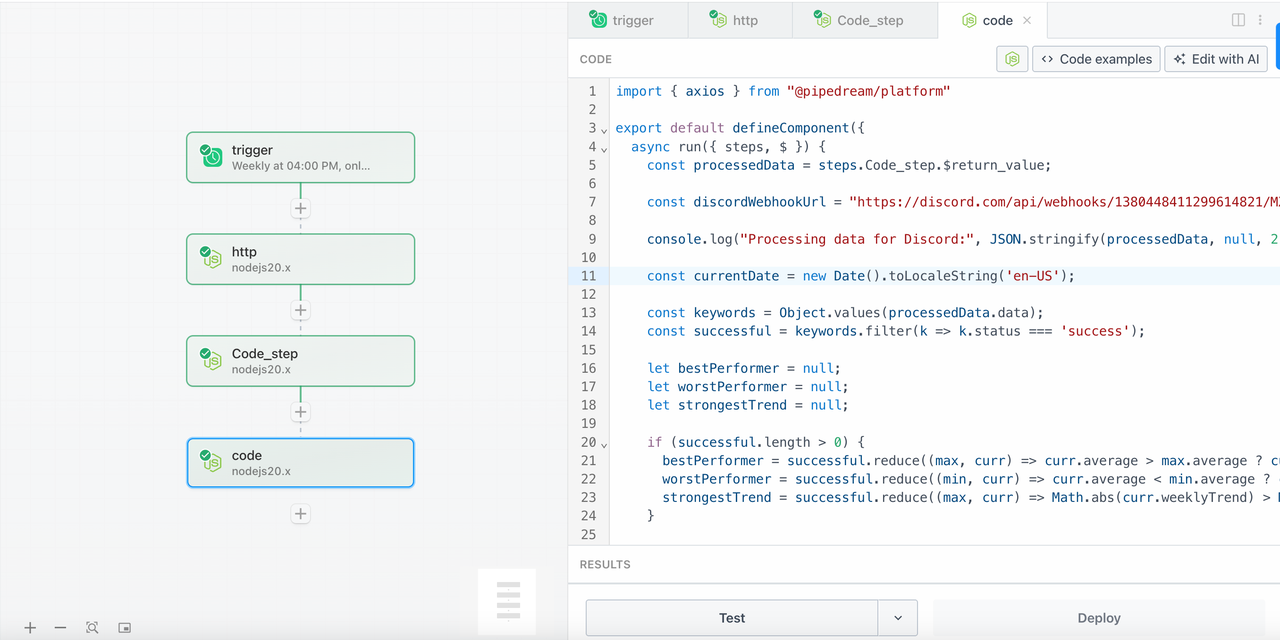
1. Adicione o último passo do Node.js, o seguinte é o exemplo de códigoimport { axios } from "@pipedream/platform"
export default defineComponent({
async run({ steps, $ }) {
const dadosProcessados = steps.Code_step.$return_value;
const urlWebhookDiscord = "https://discord.com/api/webhooks/1380448411299614821/MXzmQ14TOPK912lWhle_7qna2VQJBjWrdCkmHjdEloHKhYXw0fpBrp-0FS4MDpDB8tGh";
console.log("Processando dados para o Discord:", JSON.stringify(dadosProcessados, null, 2));
const dataAtual = new Date().toLocaleString('pt-BR');
const palavrasChave = Object.values(dadosProcessados.dados);
const bemSucedidos = palavrasChave.filter(k => k.status === 'sucesso');
let melhorDesempenho = null;
let piorDesempenho = null;
let tendênciaMaisForte = null;
if (bemSucedidos.length > 0) {
melhorDesempenho = bemSucedidos.reduce((max, curr) => curr.média > max.média ? curr : max);
piorDesempenho = bemSucedidos.reduce((min, curr) => curr.média < min.média ? curr : min);
tendênciaMaisForte = bemSucedidos.reduce((max, curr) => Math.abs(curr.tendênciaSemanal) > Math.abs(max.tendênciaSemanal) ? curr : max);
}
const mensagemDiscord = {
content: `📊 **Relatório do Google Trends** - ${dataAtual}`,
embeds: [
{
title: "🔍 Análise de Tendências",
color: 3447003,
timestamp: new Date().toISOString(),
fields: [
{
name: "📈 Resumo",
value: `**Período:** Último mês\n**Palavras chave analisadas:** ${dadosProcessados.totalPalavrasChave}\n**Sucesso:** ${dadosProcessados.palavrasChaveBemSucedidas}/${dadosProcessados.totalPalavrasChave}`,
inline: false
}
]
}
]
};
if (bemSucedidos.length > 0) {
const detalhesPalavrasChave = bemSucedidos.map(data => {
const iconeTendência = data.tendênciaSemanal > 5 ? '🚀' :
data.tendênciaSemanal > 0 ? '📈' :
data.tendênciaSemanal < -5 ? '📉' :
data.tendênciaSemanal < 0 ? '⬇️' : '➡️';
const iconeDesempenho = data.média > 70 ? '🔥' :
data.média > 40 ? '✅' :
data.média > 20 ? '🟡' : '🔴';
return {
name: `${iconeDesempenho} ${data.palavraChave}`,
value: `**Pontuação:** ${data.média}/100\n**Tendência:** ${iconeTendência} ${data.tendênciaSemanal > 0 ? '+' : ''}${data.tendênciaSemanal}\n**Faixa:** ${data.min}-${data.max}`,
inline: true
};
});
mensagemDiscord.embeds[0].fields.push(...detalhesPalavrasChave);
}
if (melhorDesempenho && bemSucedidos.length > 1) {
mensagemDiscord.embeds.push({
title: "🏆 Principais Destaques",
color: 15844367,
fields: [
{
name: "🥇 Melhor Desempenho",
value: `**${melhorDesempenho.palavraChave}** (${melhorDesempenho.média}/100)`,
inline: true
},
{
name: "📊 Menor Pontuação",
value: `**${piorDesempenho.palavraChave}** (${piorDesempenho.média}/100)`,
inline: true
},
{
name: "⚡ Tendência Mais Forte",
value: `**${tendênciaMaisForte.palavraChave}** (${tendênciaMaisForte.tendênciaSemanal > 0 ? '+' : ''}${tendênciaMaisForte.tendênciaSemanal})`,
inline: true
}
]
});
}
const falhados = palavrasChave.filter(k => k.status === 'erro');
if (falhados.length > 0) {
mensagemDiscord.embeds.push({
title: "❌ Erros",
color: 15158332,
fields: falhados.map(data => ({
name: data.palavraChave,
value: data.erro || "Erro desconhecido",
inline: true
}))
});
javascript
}
console.log("Mensagem do Discord a enviar:", JSON.stringify(discordMessage, null, 2));
try {
const response = await axios($, {
method: 'POST',
url: discordWebhookUrl,
headers: {
'Content-Type': 'application/json'
},
data: discordMessage
});
console.log("Resposta do webhook do Discord:", response);
return {
webhook_sent: true,
platform: "discord",
message_sent: true,
keywords_analyzed: processedData.totalKeywords,
successful_keywords: processedData.successfulKeywords,
timestamp: currentDate,
discord_response: response
};
} catch (error) {
console.error("Erro no webhook do Discord:", error);
const simpleMessage = {
content: `📊 **Relatório do Google Trends - ${currentDate}**\n\n` +
`📈 **Resultados (${processedData.successfulKeywords}/${processedData.totalKeywords}):**\n` +
successful.map(data =>
`• **${data.keyword}**: ${data.average}/100 (${data.weeklyTrend > 0 ? '+' : ''}${data.weeklyTrend})`
).join('\n') +
(failed.length > 0 ? `\n\n❌ **Erros:** ${failed.map(d => d.keyword).join(', ')}` : '')
};
try {
const fallbackResponse = await axios($, {
method: 'POST',
url: discordWebhookUrl,
headers: {
'Content-Type': 'application/json'
},
data: simpleMessage
});
return {
webhook_sent: true,
platform: "discord",
message_sent: true,
fallback_used: true,
discord_response: fallbackResponse
};
} catch (fallbackError) {
console.error("Erro de fallback do Discord:", fallbackError);
return {
webhook_sent: false,
platform: "discord",
error: error.message,
fallback_error: fallbackError.message,
data_summary: {
keywords: processedData.totalKeywords,
successful: processedData.successfulKeywords,
best_performer: bestPerformer?.keyword,
best_score: bestPerformer?.average
}
};
}
}
},- Substitua SUA URL DE WEBHOOK DO DISCORD pelo seu próprio endereço de Webhook.
- Clique em Implantar para executar seu fluxo de trabalho e obter informações em tempo real.
Passo 5 - Receba informações em tempo real do Google Trends
Você pode receber dados para verificar palavras-chave diretamente no Discord:
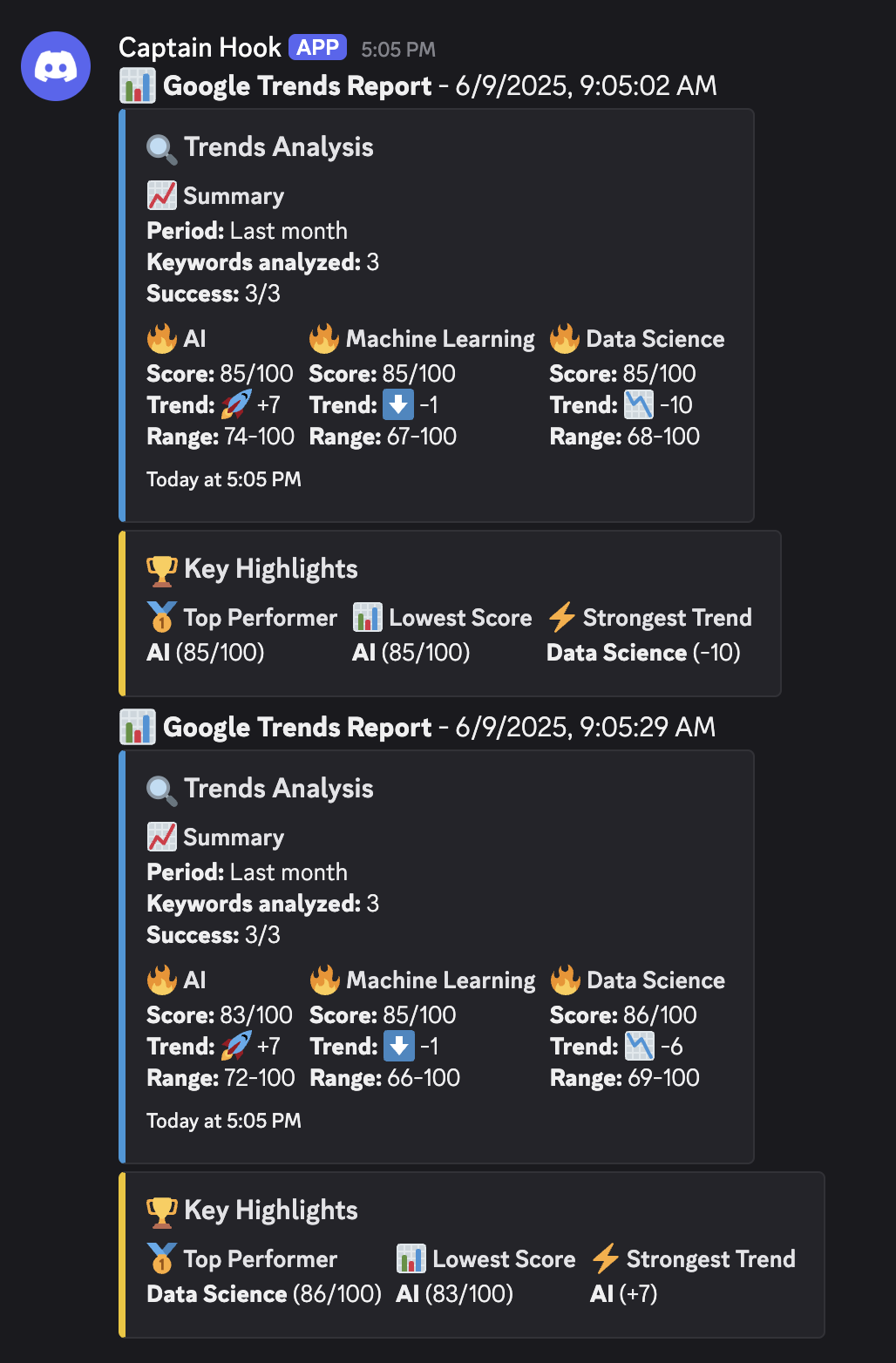
A seguir está o diagrama completo de links:
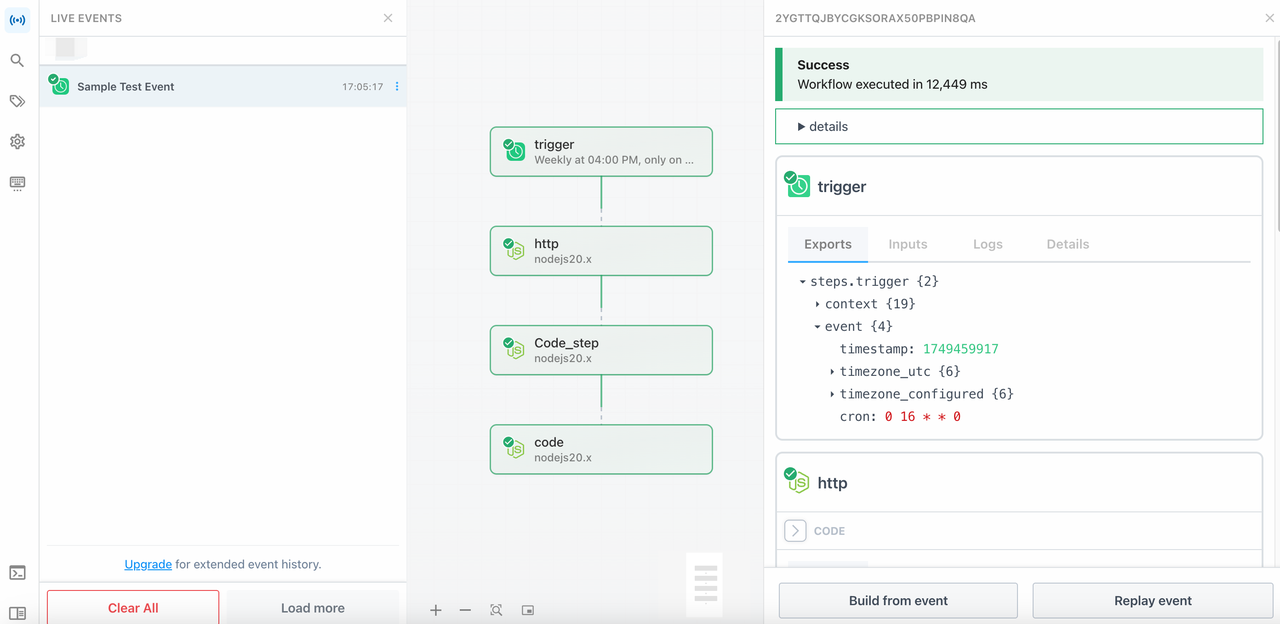
✅ Ao Vivo Agora: Integração Oficial Scrapeless no Pipedream
O Scrapeless agora está oficialmente disponível no hub de integração do Pipedream! Com apenas alguns cliques, você pode chamar nossa poderosa API do Google Trends diretamente de seus fluxos de trabalho do Pipedream—sem configuração, sem servidores necessários.
Se você está construindo painéis em tempo real, automatizando inteligência de marketing ou alimentando análises personalizadas, esta integração oferece o caminho mais rápido para monitoramento de tendências em produção.
👉 Comece a construir instantaneamente: pipedream.com/apps/scrapeless
Arraste, solte e implante seu próximo fluxo de trabalho impulsionado por tendências—hoje.
Perfeito para desenvolvedores, analistas e equipes de crescimento que precisam de insights acionáveis, rapidamente.
Resumo
Através da poderosa combinação de Pipedream, API Scrapeless e Discord, construímos um sistema de relatórios do Google Trends que não requer intervenção manual e é executado automaticamente todos os dias. Isso não apenas melhora muito a eficiência do trabalho, mas também torna as decisões de marketing mais baseadas em dados.
Se você também precisa construir um sistema semelhante de automação e análise de dados, você pode experimentar essa combinação tecnológica!
Scrapeless opera em total conformidade com as leis e regulamentos aplicáveis, acessando apenas dados disponíveis publicamente em conformidade com os termos de serviço da plataforma. Esta solução é projetada para fins legítimos de inteligência de negócios e pesquisa.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


