
Como Construir um Fluxo de Trabalho de Geração de Leads B2B Inteligente com n8n e Scrapeless
Advanced Data Extraction Specialist
Transforme sua prospecção de vendas com um fluxo de trabalho automatizado que encontra, qualifica e enriquece leads B2B usando Pesquisa Google, Crawler e análise de Claude AI. Este tutorial mostra como criar um poderoso sistema de geração de leads usando n8n e Scrapeless.
O Que Vamos Construir
Neste tutorial, vamos criar um fluxo de trabalho inteligente de geração de leads B2B que:
- Aciona automaticamente em um cronograma ou manualmente
- Pesquisa no Google por empresas no seu mercado-alvo usando Scrapeless
- Processa cada URL de empresa individualmente com Listas de Itens
- Navega nos sites das empresas para extrair informações detalhadas
- Usa Claude AI para qualificar e estruturar os dados dos leads
- Armazena leads qualificados no Google Sheets
- Envia notificações para o Discord (adaptável para Slack, email, etc.)
Pré-requisitos
- Uma instância do n8n (nuvem ou auto-hospedada)
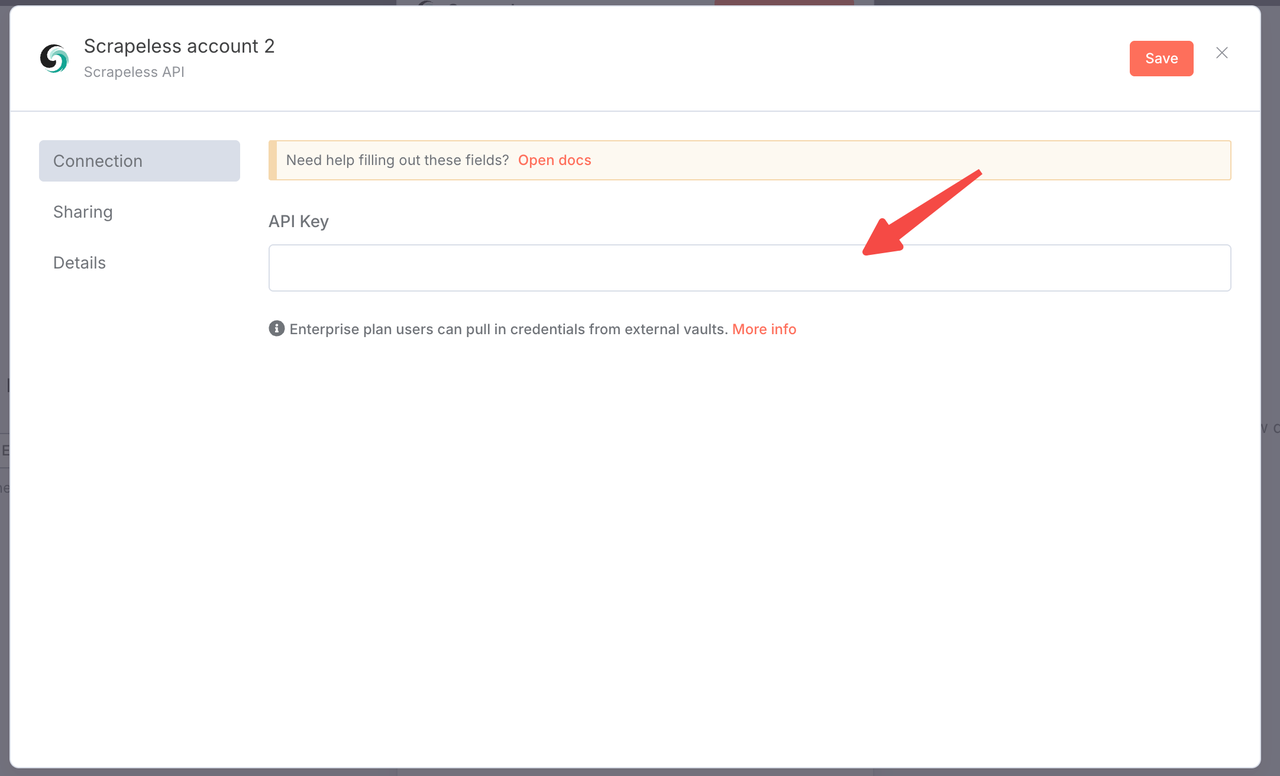
- Uma chave de API do Scrapeless (obtenha uma em scrapeless.com)
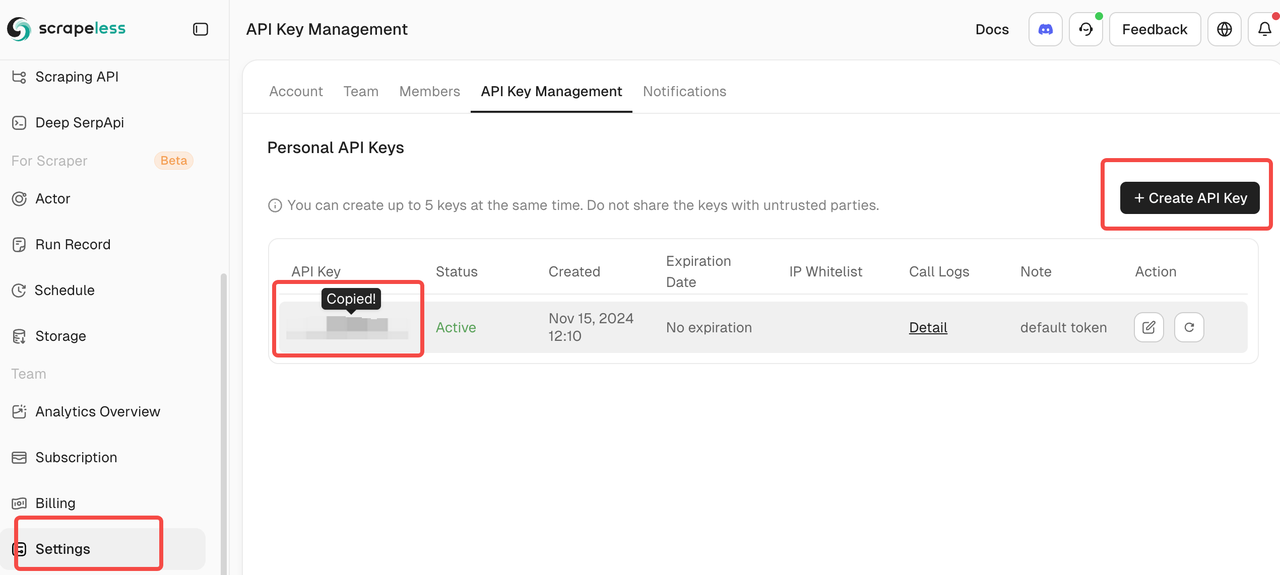
Você só precisa fazer login no painel do Scrapeless e seguir a imagem abaixo para obter sua CHAVE DE API. O Scrapeless lhe dará uma cota de teste gratuita.
- Chave de API do Claude da Anthropic
- Acesso ao Google Sheets
- URL do webhook do Discord (ou seu serviço de notificação preferido)
- Entendimento básico dos fluxos de trabalho do n8n
Visão Geral do Fluxo de Trabalho Completo
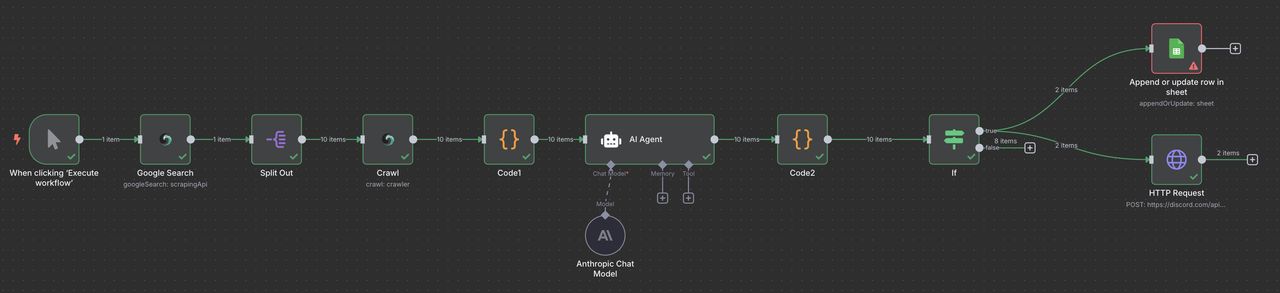
Seu fluxo de trabalho final do n8n ficará assim:
Gatilho Manual → Pesquisa Google Scrapeless → Listas de Itens → Crawler Scrapeless → Código (Processamento de Dados) → Claude AI → Código (Analisador de Respostas) → Filtro → Google Sheets ou/ e Webhook do Discord
Etapa 1: Configurando o Gatilho Manual
Começaremos com um gatilho manual para testes e depois adicionaremos a programação.
- Crie um novo fluxo de trabalho no n8n
- Adicione um nó de Gatilho Manual como seu ponto de partida
- Isso permite que você teste o fluxo de trabalho antes de automatizá-lo
Por que começar manual?
- Testar e depurar cada passo
- Verificar a qualidade dos dados antes da automação
- Ajustar parâmetros com base nos resultados iniciais
Etapa 2: Adicionando a Pesquisa Google Scrapeless
Agora vamos adicionar o nó de Pesquisa Google Scrapeless para encontrar empresas-alvo.
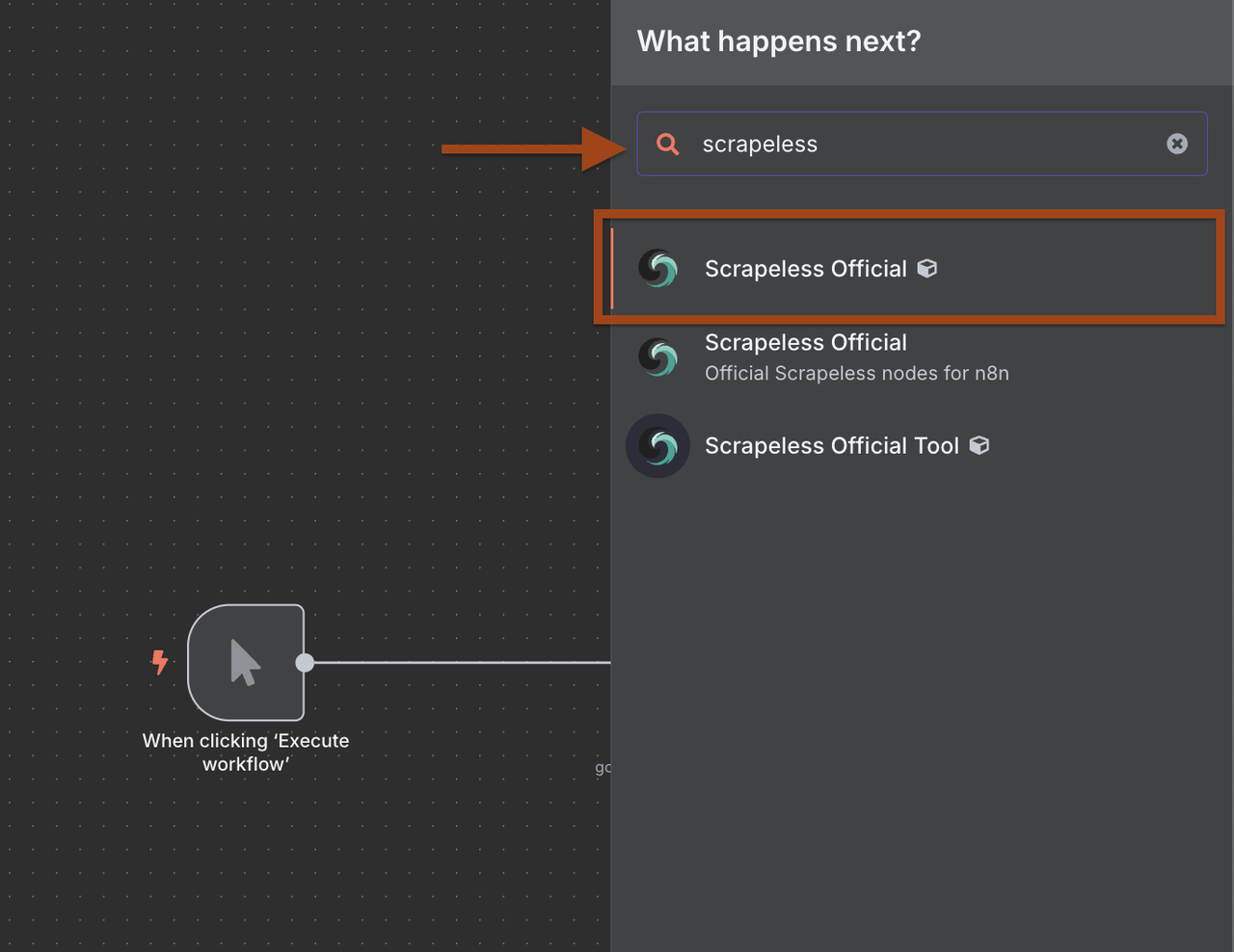
- Clique + para adicionar um novo nó após o gatilho
- Pesquise por Scrapeless na biblioteca de nós
- Selecione Scrapeless e escolha a operação Pesquisar no Google
1. Por que usar Scrapeless com n8n?
Integrar Scrapeless com n8n permite que você crie raspadores da web avançados e resilientes sem escrever código.
Os benefícios incluem:
- Acesso ao Deep SerpApi para buscar e extrair dados da SERP do Google com uma única solicitação.
- Use a API de Raspagem Universal para contornar restrições e acessar qualquer site.
- Use o Crawler Scrape para realizar raspagens detalhadas de páginas individuais.
- Use o Crawler Crawl para navegação recursiva e recuperação de dados de todas as páginas vinculadas.
Essas funcionalidades permitem que você construa fluxos de dados de ponta a ponta que conectam Scrapeless com mais de 350 serviços suportados pelo n8n, incluindo Google Sheets, Airtable, Notion, Slack e muito mais.
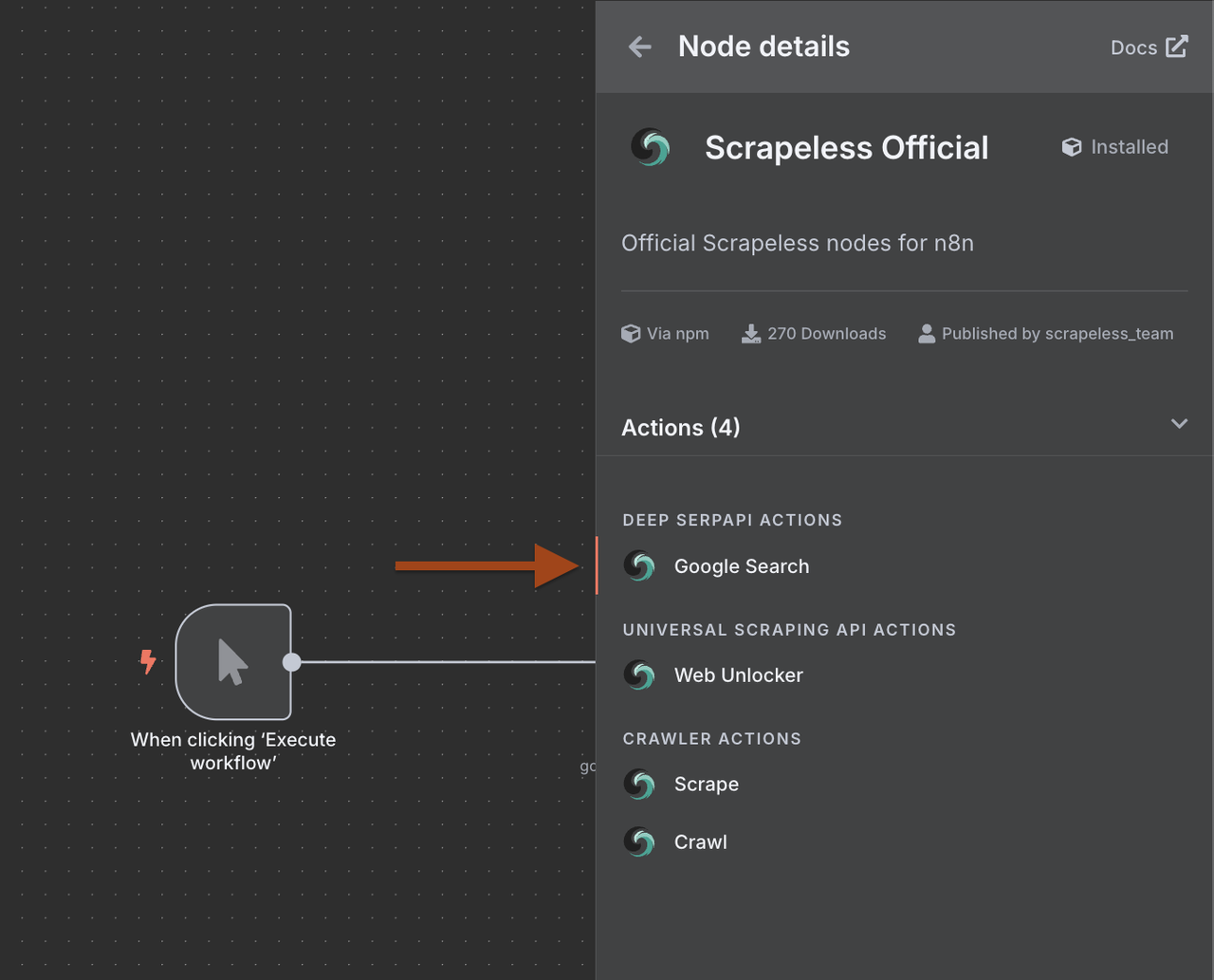
2. Configurando o Nó de Pesquisa Google
A seguir, precisamos configurar o Nó de Pesquisa Google Scrapeless
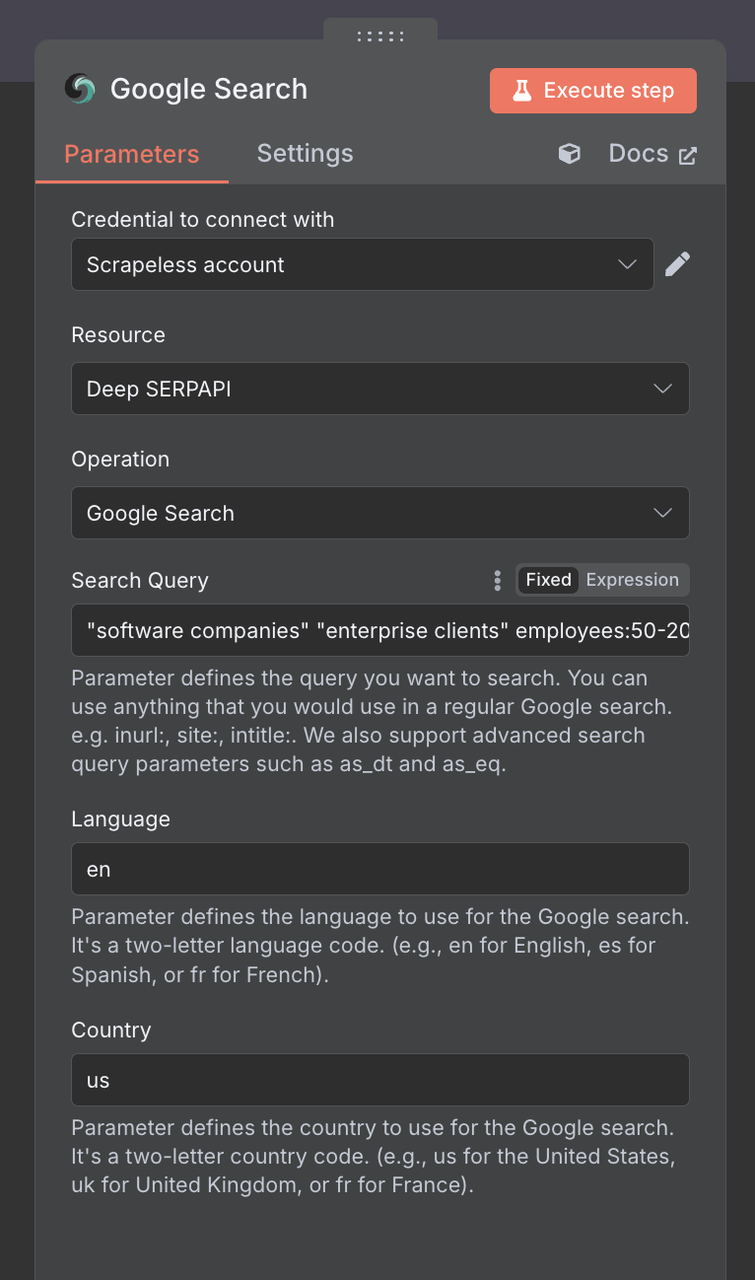
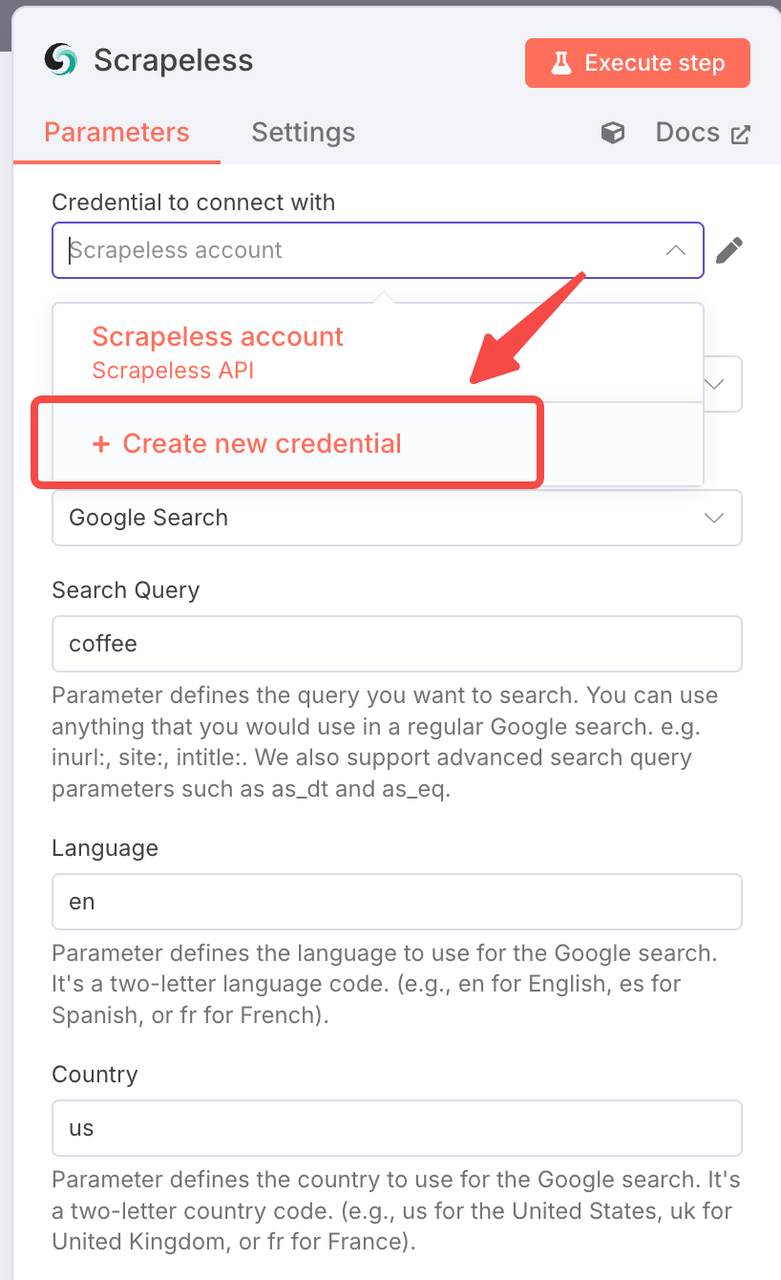
Configuração de Conexão:
- Crie uma conexão com sua chave de API do Scrapeless
- Clique em "Adicionar" e insira suas credenciais
Parâmetros de Pesquisa:
Consulta de Pesquisa: Use termos de pesquisa focados em B2B:
"empresas de software" "clientes corporativos" funcionários:50-200
"agências de marketing" "serviços B2B" "transformação digital"
"startups de SaaS" "série A" "apoio a investimentos"
"empresas de manufatura" "soluções digitais" ISOPaís: EUA (ou seu mercado-alvo)
Idioma: en
Estratégias de Pesquisa B2B Pro:
- Segmentação por tamanho da empresa: funcionários:50-200, "média empresa"
- Estágio de financiamento: "série A", "apoio a investimentos", "auto-financiadas"
- Setor específico: "fintech", "healthtech", "edtech"
- Geográfico: "Nova Iorque", "São Francisco", "Londres"
Etapa 3: Processando Resultados com Listas de Itens
O Google Search retorna um array de resultados. Precisamos processar cada empresa individualmente.
- Adicione um nó de Listas de Itens após a Pesquisa do Google
- Isso irá dividir os resultados da pesquisa em itens individuais
Dicas: Execute o Nó de Pesquisa do Google
1. Configuração das Listas de Itens:
- Operação: "Dividir Itens"
- Campo para Dividir: organic_results - Link
- Incluir Dados Binários: falso
Isso cria um ramo de execução separado para cada resultado da pesquisa, permitindo o processamento paralelo.
Etapa 4: Adicionando o Raspador Scrapeless
Agora iremos rastrear o site de cada empresa para extrair informações detalhadas.
- Adicione outro nó Scrapeless
- Selecione a operação de Rastrear (não WebUnlocker)
Use o Rastrear do Raspador para raspagem recursiva e recuperação de dados de todas as páginas vinculadas.
- Configure a extração de dados da empresa
1. Configuração do Raspador
- Conexão: Use a mesma conexão Scrapeless
- URL: {{ $json.link }}
- Profundidade de Rastreio: 2 (página inicial + um nível profundo)
- Páginas Máx: 5 (limite para processamento mais rápido)
- Incluir Padrões: sobre|contato|equipe|empresa|serviços
- Excluir Padrões: blog|notícias|carreiras|privacidade|termos
- Formato: markdown (mais fácil para processamento de IA)
2. Por que usar o Raspador em vez de Web Unlocker?
- O Raspador obtém várias páginas e dados estruturados
- Melhor para B2B onde informações de contato podem estar nas páginas /sobre ou /contato
- Informações de empresa mais abrangentes
- Segue a estrutura do site de forma inteligente
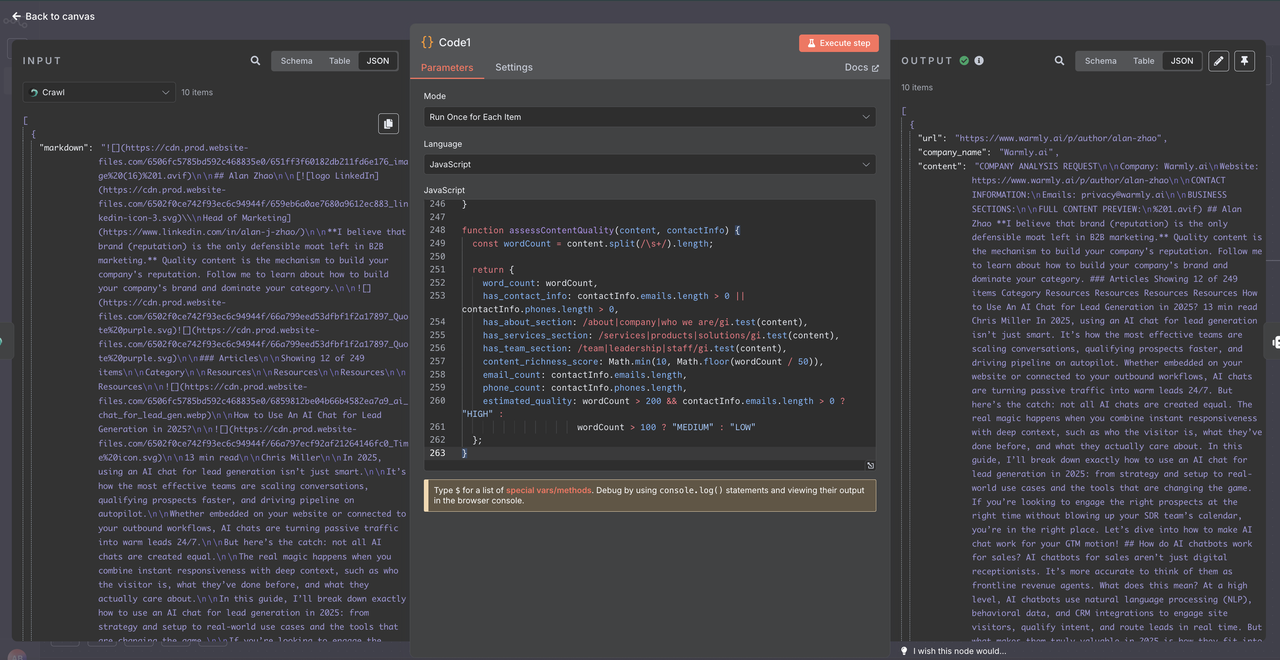
Etapa 5: Processamento de Dados com Nó de Código
Antes de enviar os dados raspados para a IA Claude, precisamos limpá-los e estruturá-los corretamente. O Raspador Scrapeless retorna dados em um formato específico que requer uma análise cuidadosa.
- Adicione um nó de Código após o Raspador Scrapeless
- Use JavaScript para analisar e limpar os dados brutos do rastreamento
- Isso garante qualidade de dados consistente para análise de IA
1. Entendendo a Estrutura de Dados do Raspador Scrapeless
O Raspador Scrapeless retorna dados como um array de objetos, não como um único objeto:
[
{
"markdown": "# Página Inicial da Empresa\n\nBem-vindo à nossa empresa...",
"metadata": {
"title": "Nome da Empresa - Página Inicial",
"description": "Descrição da empresa",
"sourceURL": "https://empresa.com"
}
}
]2. Configuração do Nó de Código
console.log("=== PROCESSANDO DADOS DO RASPADOR SCRAPELESS ===");
try {
// Os dados chegam como um array
const crawlerDataArray = $json;
console.log("Tipo de dado:", typeof crawlerDataArray);
console.log("É array:", Array.isArray(crawlerDataArray));
console.log("Comprimento do array:", crawlerDataArray?.length || 0);
// Verificar se o array está vazio
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ Dados do raspador vazios ou inválidos");
return {
url: "desconhecido",
company_name: "Sem Dados",
content: "",
error: "Resposta do raspador vazia",
processing_failed: true,
skip_reason: "Nenhum dado retornado do raspador"
};
}
// Pegue o primeiro elemento do array
const crawlerResponse = crawlerDataArray[0];
// Extração do conteúdo markdown
const markdownContent = crawlerResponse?.markdown || "";
// Extração de metadados (se disponível)
const metadata = crawlerResponse?.metadata || {};
// Informações básicas
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`Processando: ${companyName}`);
console.log(`URL: ${sourceURL}`);
console.log(`Comprimento do conteúdo: ${markdownContent.length} caracteres`);
// Verificação da qualidade do conteúdose (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "Conteúdo insuficiente do crawler",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "Conteúdo muito curto ou vazio"
};
}
// Limpeza e estruturação do conteúdo markdown
let cleanedContent = cleanMarkdownContent(markdownContent);
// Extração de informações de contato
const contactInfo = extractContactInformation(cleanedContent);
// Extração de seções importantes de negócios
const businessSections = extractBusinessSections(cleanedContent);
// Construindo conteúdo para Claude AI
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// Métricas de qualidade do conteúdo
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "SUCESSO"
};
console.log(✅ Processamento bem-sucedido de ${companyName});
return result;
} catch (error) {
console.error("❌ Erro ao processar dados do crawler:", error);
return {
url: "desconhecido",
company_name: "Erro de Processamento",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== FUNÇÕES ÚTEIS ==========
function extractURLFromContent(content) {
// Tentar extrair URL do conteúdo markdown
const urlMatch = content.match(/https?://[^\s)]+/);
return urlMatch ? urlMatch[0] : "desconhecido";
}
function extractCompanyFromContent(content) {
// Tentar extrair o nome da empresa do conteúdo
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// Buscar e-mails para extrair o domínio
const emailMatch = content.match(/@([a-zA-Z0-9.-]+.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "Empresa Desconhecida";
}
function cleanMarkdownContent(markdown) {
return markdown
// Remover elementos de navegação
.replace(/^[Pular para o conteúdo].$/gmi, '')
.replace(/^[.](#.)$/gmi, '')
// Remover links markdown, mas manter texto
.replace(/[([]]+)]([)]+)/g, '$1')
// Remover imagens e base64
.replace(/![([]]*)]([)])/g, '')
.replace(/<Base64-Image-Removed>/g, '')
// Remover menções de cookies/privacidade
.replace(/.?(cookie|política de privacidade|termos de serviço).?\n/gi, '')
// Limpar espaços múltiplos
.replace(/\s+/g, ' ')
// Remover múltiplas linhas em branco
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// Regex para e-mails
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/g;
// Regex para telefones (com suporte internacional)
const phoneRegex = /(?:+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|(\d{3})\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// Buscar seções importantes
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// Detecção de cabeçalho
if (line.startsWith('#')) {
// Salvar seção anterior
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// Nova seção
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('sobre') || title.includes('serviço') ||
title.includes('contato') || title.includes('empresa')) {
currentSection = title.includes('sobre') ? 'sobre' :
title.includes('serviço') ? 'serviços' :
title.includes('contato') ? 'contato' : 'empresa';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}
pt
}
// Salvar a última seção
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `SOLICITAÇÃO DE ANÁLISE DA EMPRESA\n\n`;
aiContent += `Empresa: ${companyName}\n`;
aiContent += `Website: ${sourceURL}\n`;
if (description) {
aiContent += `Descrição: ${description}\n`;
}
aiContent += `\nINFORMAÇÕES DE CONTATO:\n`;
if (contactInfo.emails.length > 0) {
aiContent += `Emails: ${contactInfo.emails.join(', ')}\n`;
}
if (contactInfo.phones.length > 0) {
aiContent += `Telefones: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\nSEÇÕES DE NEGÓCIOS:\n`;
for (const [section, content] of Object.entries(businessSections)) {
if (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// Adicionar conteúdo principal (limitado)
aiContent += `\nVISUALIZAÇÃO DO CONTEÚDO COMPLETO:\n`;
aiContent += cleanedContent.substring(0, 2000);
// Limitação final para a API do Claude
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /sobre|empresa|quem somos/gi.test(content),
has_services_section: /serviços|produtos|soluções/gi.test(content),
has_team_section: /equipe|liderança|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "ALTA" :
wordCount > 100 ? "MÉDIA" : "BAIXA"
};
}3. Por que adicionar uma etapa de processamento de código?
- Adaptação da Estrutura de Dados: Converte o formato de array do Scrapeless para uma estrutura amigável ao Claude
- Otimização de Conteúdo: Extrai e prioriza seções relevantes para os negócios
- Descoberta de Contatos: Identifica automaticamente emails e números de telefone
- Avaliação de Qualidade: Avalia a riqueza e a completude do conteúdo
- Eficiência de Tokens: Reduz o tamanho do conteúdo enquanto preserva informações importantes
- Tratamento de Erros: Gerencia falhas de rastreamento e conteúdo insuficiente de forma elegante
- Suporte à Depuração: Registro abrangente para resolução de problemas
4. Estrutura de Saída Esperada
Após o processamento, cada lead terá este formato estruturado:
{
"url": "https://empresa.com",
"company_name": "Nome da Empresa",
"content": "SOLICITAÇÃO DE ANÁLISE DA EMPRESA\n\nEmpresa: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contato@empresa.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "ALTA",
"content_richness_score": 10
},
"processing_status": "SUCESSO"
}
Isso ajuda a verificar o formato dos dados e solucionar quaisquer problemas de processamento.
5. Benefícios do Nó de Código
- Economia de Custos: Conteúdo menor e mais limpo = menos tokens da API do Claude
- Melhores Resultados: Conteúdo focado melhora a precisão da análise da IA
- Recuperação de Erros: Lida com respostas vazias e falhas de rastreamento
- Flexibilidade: Fácil de ajustar a lógica de parsing com base nos resultados
- Métricas de Qualidade: Avaliação incorporada da completude dos dados do lead
Etapa 6: Qualificação de Leads com Inteligência Artificial com Claude
Use a IA do Claude para extrair e qualificar informações de leads a partir de conteúdo rastreado que foi processado e estruturado pelo nosso Nó de Código.
- Adicione um nó de Agente de IA após o nó de Código
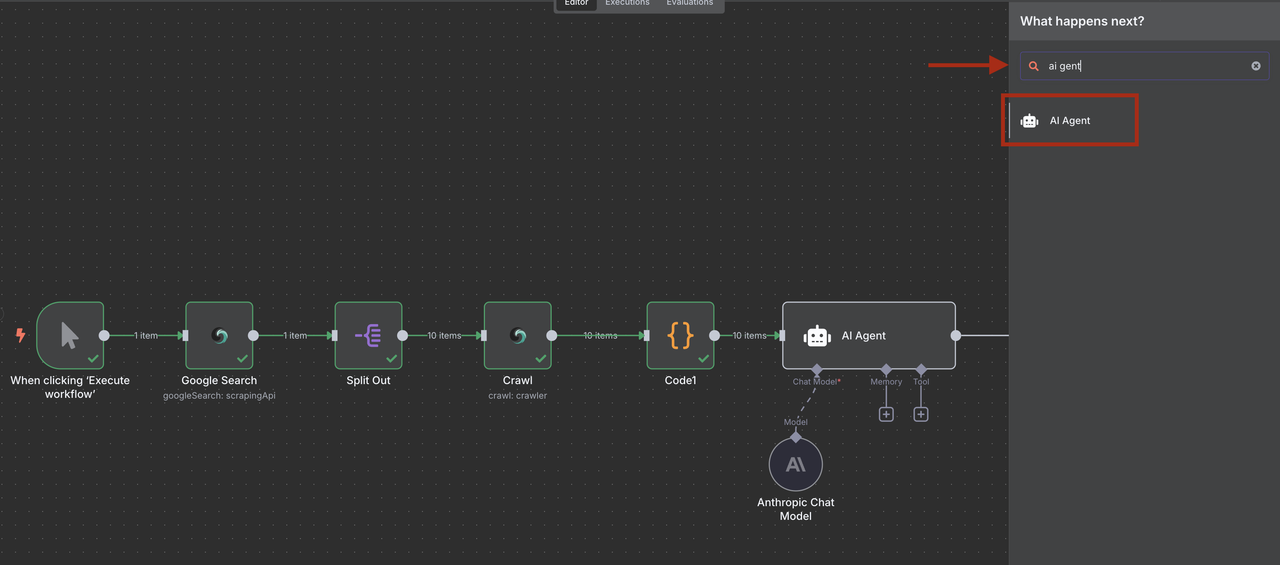
- Adicione um nó do Anthropic Claude e configure para análise de leads
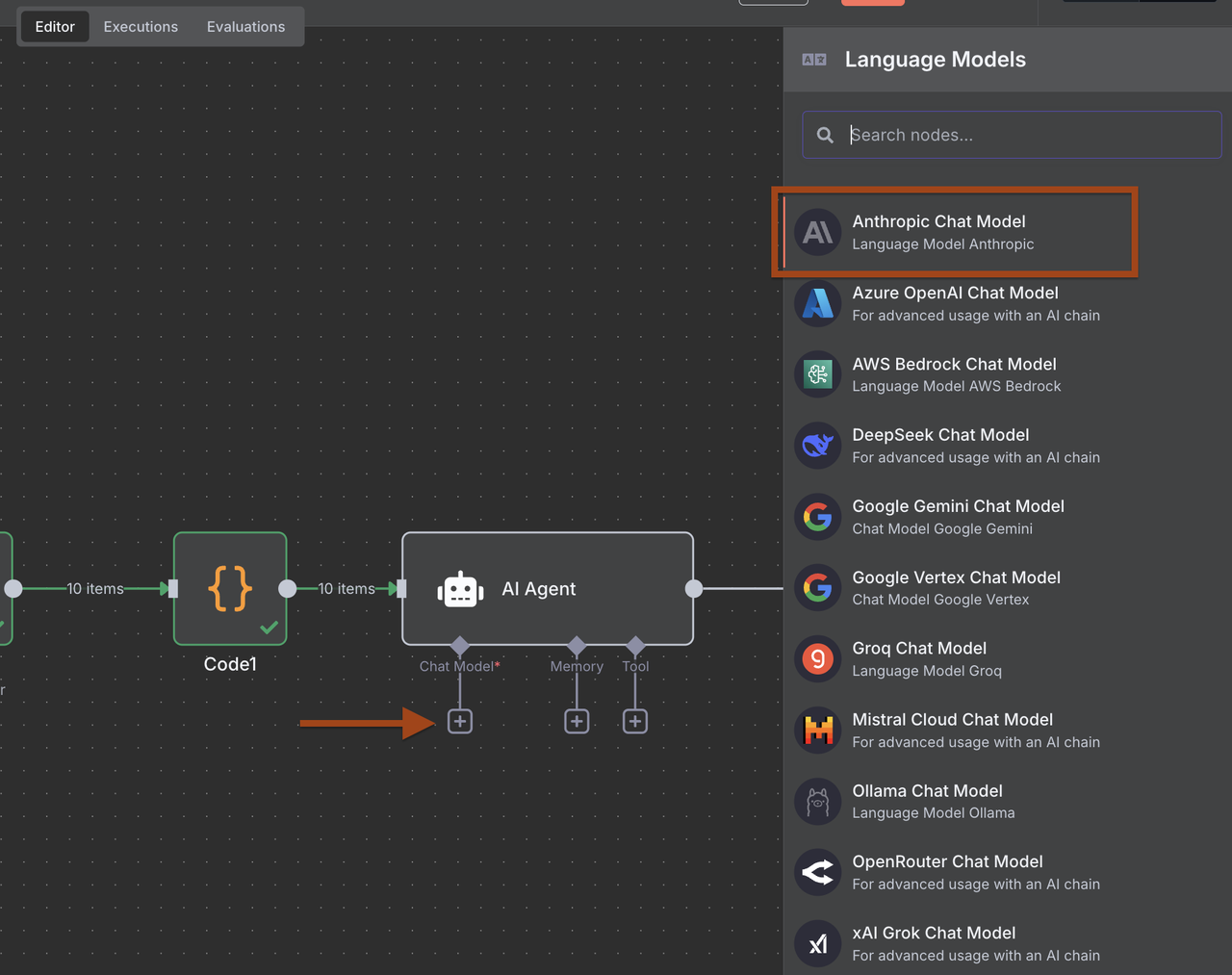
- Configure os prompts para extrair dados estruturados de leads B2B
Clique no agente de IA -> Adicione opção -> Mensagem do Sistema e cole a mensagem abaixo
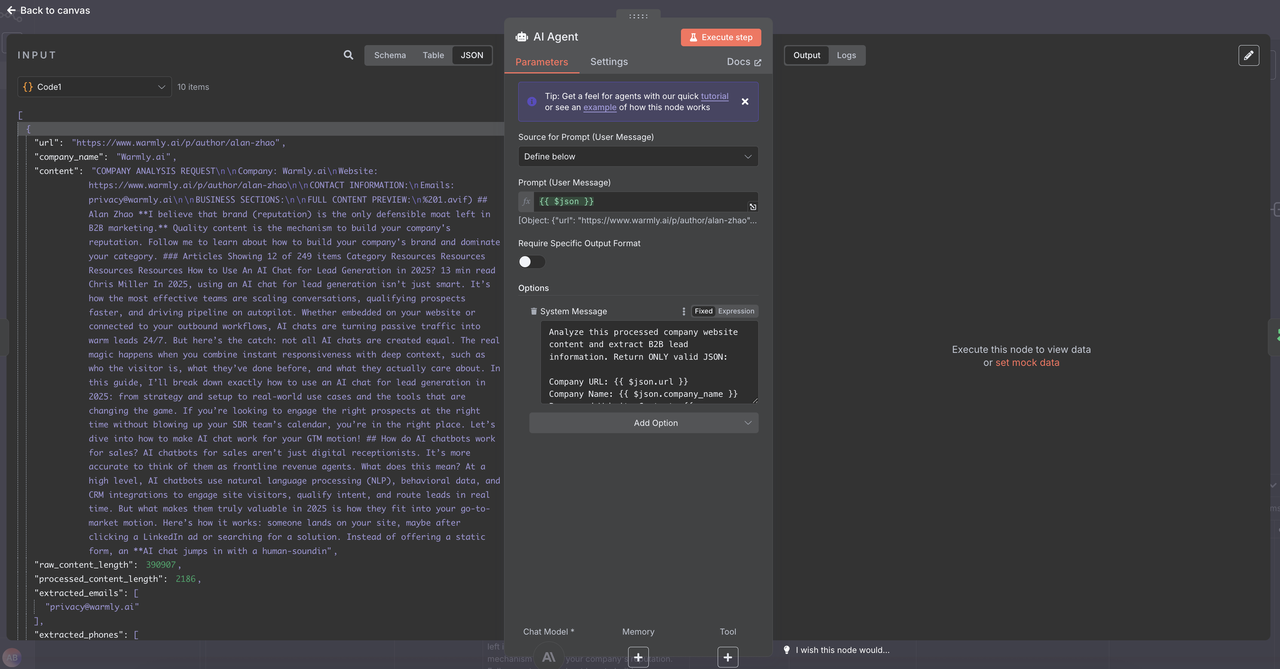
Prompt de Extração de Leads do Sistema:
Analise este conteúdo processado do site da empresa e extraia informações de leads B2B. Retorne APENAS JSON válido:
URL da Empresa: {{ $json.url }}
Nome da Empresa: {{ $json.company_name }}
Conteúdo do Site Processado: {{ $json.content }}
Avaliação da Qualidade do Conteúdo: {{ $json.content_quality }}
Informações de Contato Pré-extracionadas:
Emails: {{ $json.extracted_emails }}
Telefones: {{ $json.extracted_phones }}
Informações de Metadados: {{ $json.metadata_info }}Detalhes do Processamento:
Comprimento do conteúdo bruto: {{ $json.raw_content_length }} caracteres
Comprimento do conteúdo processado: {{ $json.processed_content_length }} caracteres
Status do processamento: {{ $json.processing_status }}
Com base nesses dados estruturados, extraia e qualifique este lead B2B. Retorne SOMENTE JSON válido:
{
"company_name": "Nome oficial da empresa contido no conteúdo",
"industry": "Indústria/setor primário identificado",
"company_size": "Número de funcionários ou categoria de tamanho (startup/PME/mercado médio/empresa)",
"location": "Localização da sede ou mercado primário",
"contact_email": "Melhor e-mail geral ou de vendas extraído dos e-mails",
"phone": "Número de telefone principal extraído dos telefones",
"key_services": ["Principais serviços/produtos oferecidos com base no conteúdo"],
"target_market": "Quem eles atendem (B2B/B2C, PME/Empresa, indústrias específicas)",
"technologies": ["Tecnologia, plataformas ou ferramentas mencionadas"],
"funding_stage": "Estágio de financiamento se mencionado (seed/serie A/B/C/público/privado)",
"business_model": "Modelo de receita (SaaS/consultoria/produto/marketplace)",
"social_presence": {
"linkedin": "URL da empresa no LinkedIn se encontrado no conteúdo",
"twitter": "Identificador do Twitter se encontrado"
},
"lead_score": 8.5,
"qualification_reasons": ["Razões específicas pelas quais este lead é qualificado ou não"],
"decision_makers": ["Nomes e cargos dos contatos chave encontrados"],
"next_actions": ["Estratégias de acompanhamento recomendadas com base no perfil da empresa"],
"content_insights": {
"website_quality": "Profissional/Básico/Pobre com base na riqueza do conteúdo",
"recent_activity": "Qualquer notícia recente, financiamento ou atualizações mencionadas",
"competitive_positioning": "Como se posicionam em relação aos concorrentes"
}
}
Critérios de Pontuação Aprimorados (1-10):
9-10: Perfeito ajuste ICP + informações de contato completas + sinais de alto crescimento + conteúdo profissional
7-8: Bom ajuste ICP + algumas informações de contato + empresa estável + conteúdo de qualidade
5-6: Ajuste moderado + informações de contato limitadas + conteúdo básico + precisa de pesquisa
3-4: Mau ajuste + informações mínimas + conteúdo de baixa qualidade + mercado-alvo errado
1-2: Não qualificado + sem informações de contato + falha no processamento + irrelevante
Fatores de Pontuação a Considerar:
Pontuação de Qualidade do Conteúdo: {{ $json.content_quality.content_richness_score }}/10
Informações de Contato: {{ $json.content_quality.email_count }} emails, {{ $json.content_quality.phone_count }} telefones
Completude do Conteúdo: {{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
Sucesso do Processamento: {{ $json.processing_status }}
Volume de Conteúdo: {{ $json.content_quality.word_count }} palavras
Instruções:
Use SOMENTE as informações de contato pré-extraídas de extracted_emails e extracted_phones
Baseie o company_name no campo processed company_name, não no conteúdo bruto
Leve em consideração as métricas de qualidade do conteúdo ao determinar o lead_score
Se o processing_status não for "SUCESSO", reduza significativamente a pontuação
Use null para qualquer informação ausente - não crie dados
Seja conservador com a pontuação - melhor subestimar do que superestimar
Foque na relevância B2B e no ajuste ICP com base no conteúdo estruturado fornecido
A estrutura do prompt torna o filtro mais confiável, uma vez que Claude recebe uma entrada consistente e estruturada. Isso leva a pontuações de lead mais precisas e melhores decisões de qualificação na próxima etapa do seu fluxo de trabalho.
## Etapa 7: Analisando a Resposta da AI Claude
Antes de filtrar leads, precisamos analisar corretamente a resposta JSON de Claude, que pode vir formatada em markdown.
1. Adicione um nó de Código após o Agente AI (Claude)
2. Configure para analisar e limpar a resposta JSON de Claude
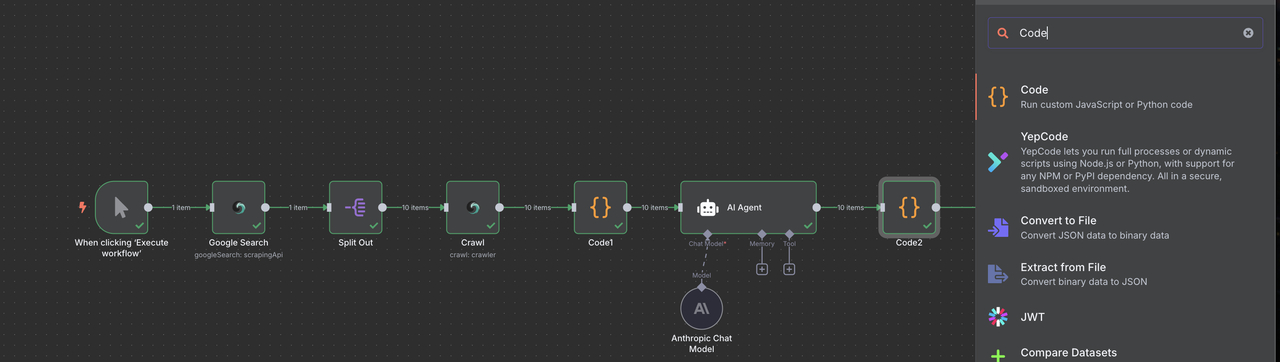
### 1. Configuração do Nó de Código// Código para analisar a resposta JSON da AI Claude
console.log("=== ANALISANDO A RESPOSTA DA AI CLAUDE ===");
try {
// A resposta de Claude chega no campo "output"
const claudeOutput = $json.output || "";
console.log("Comprimento da saída de Claude:", claudeOutput.length);
console.log("Pré-vista da saída de Claude:", claudeOutput.substring(0, 200));
// Extrair JSON da resposta markdown de Claude
let jsonString = claudeOutput;
// Remover backticks de markdown se presente
if (jsonString.includes('json')) {
const jsonMatch = jsonString.match(/json\s*([\s\S]?)\s/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
} else if (jsonString.includes('')) {
// Fallback para casos com apenas
const jsonMatch = jsonString.match(/\s*([\s\S]?)\s```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// Limpeza adicional
jsonString = jsonString.trim();
console.log("String JSON extraída:", jsonString.substring(0, 300));
// Analisar o JSON
const leadData = JSON.parse(jsonString);
console.log("Dados do lead analisados com sucesso para:", leadData.company_name);
console.log("Pontuação do lead:", leadData.lead_score);
```javascript
console.log("Email de contato:", leadData.contact_email);
// Validação e limpeza de dados
const cleanedLead = {
company_name: leadData.company_name || "Desconhecido",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// Meta-informações para filtragem
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "SUCESSO"
};
console.log(`✅ Lead processado: ${cleanedLead.company_name} (Pontuação: ${cleanedLead.lead_score}, Qualificado: ${cleanedLead.is_qualified})`);
return cleanedLead;
} catch (error) {
console.error("❌ Erro ao processar resposta do Claude:", error);
console.error("Saída bruta:", $json.output);
// Resposta de erro estruturada
return {
company_name: "Erro de Análise do Claude",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [`Falha na análise do Claude: ${error.message}`],
decision_makers: [],
next_actions: ["Corrigir análise da resposta do Claude", "Verificar formato JSON"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "FALHOU",
parsing_error: error.message,
raw_claude_output: $json.output || "Nenhuma saída recebida"
};
}2. Por que adicionar análise da resposta do Claude?
- Manipulação de Markdown: Remove a formatação JSON das respostas do Claude
- Validação de Dados: Garante que todos os campos tenham tipos e padrões corretos
- Recuperação de Erros: Trata falhas de análise JSON de forma elegante
- Preparação para Filtragem: Adiciona campos computados para filtragem mais fácil
- Suporte para Depuração: Registro abrangente para resolução de problemas
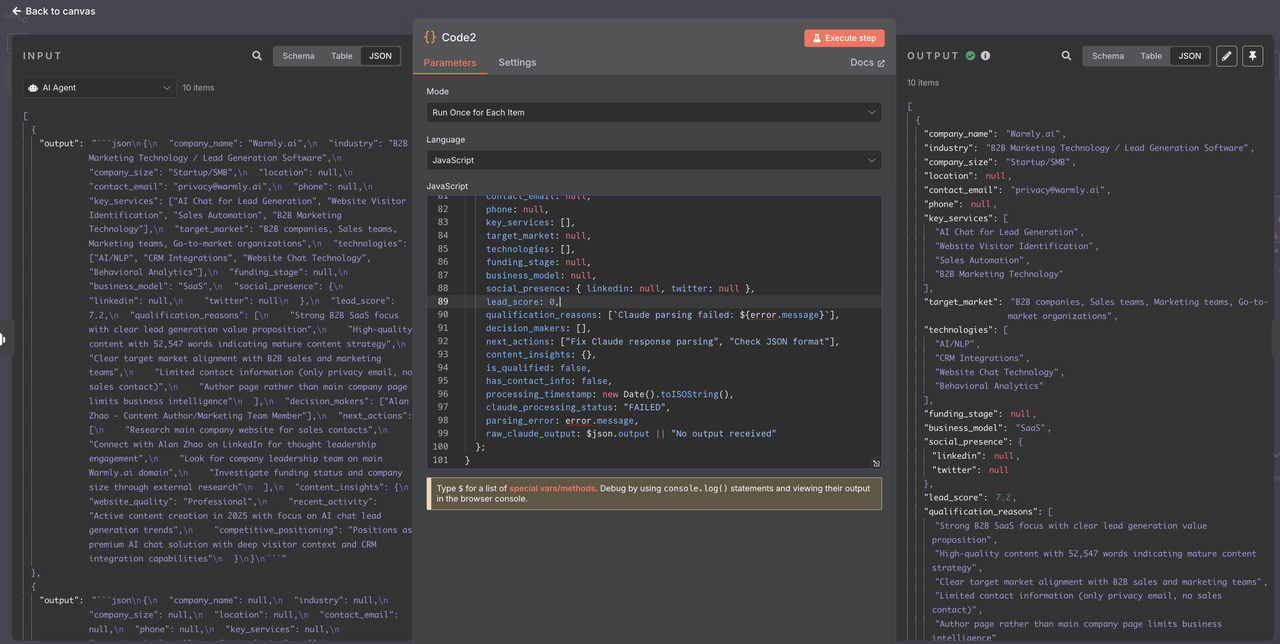
Etapa 8: Filtragem de Leads e Controle de Qualidade
Filtrar leads com base em pontuações de qualificação e completude de dados usando os dados analisados e validados.
- Adicione um nó IF após o Analisador de Resposta do Claude
- Configure critérios de qualificação aprimorados
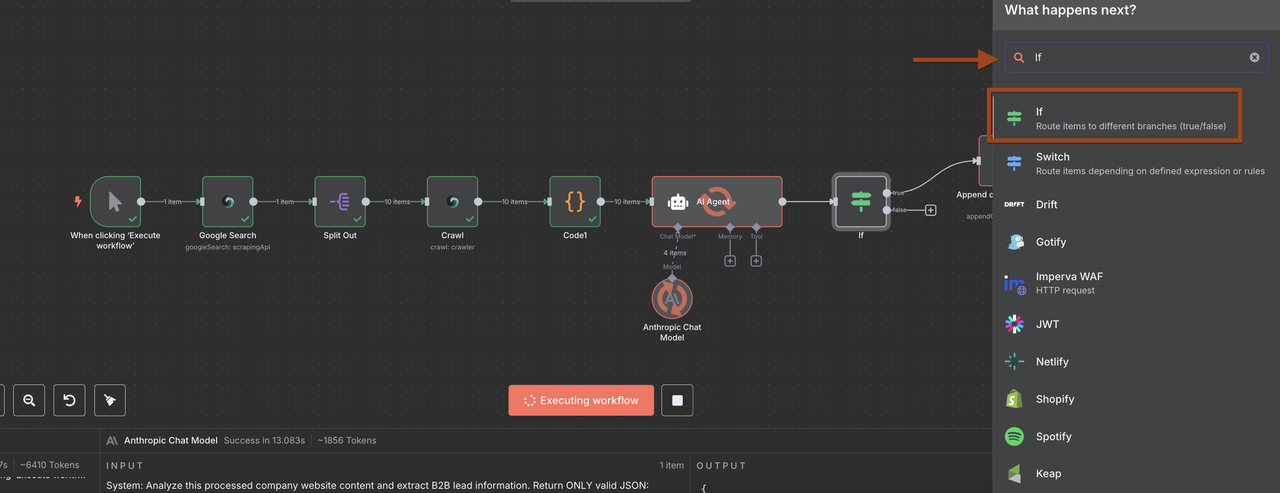
1. Nova Configuração do Nó IF
Agora que os dados estão corretamente analisados, use estas condições no nó IF:
1: Adicionar Múltiplas Condições
Condição 1:
- Campo: {{ $json.lead_score }}
- Operador: é igual ou maior que
- Valor: 6
Condição 2:
- Campo: {{ $json.claude_processing_status }}
- Operador: é igual a
- Valor: SUCESSO
Opção: Converter tipos onde necessário
- VERDADEIRO
2. Benefícios da Filtragem
- Garantia de Qualidade: Apenas leads qualificados prosseguem para armazenamento
- Otimização de Custos: Evita o processamento de leads de baixa qualidade
- Integridade de Dados: Garante que os dados analisados sejam válidos antes do armazenamento
- Capacidade de Depuração: Falhas na análise são capturadas e registradas
Etapa 9: Armazenamento de Leads no Google Sheets
Armazenar leads qualificados em um banco de dados do Google Sheets para fácil acesso e gerenciamento.
- Adicione um nó do Google Sheets após o filtro
- Configure para adicionar novos leads
No entanto, você pode optar por gerenciar os dados como desejar.
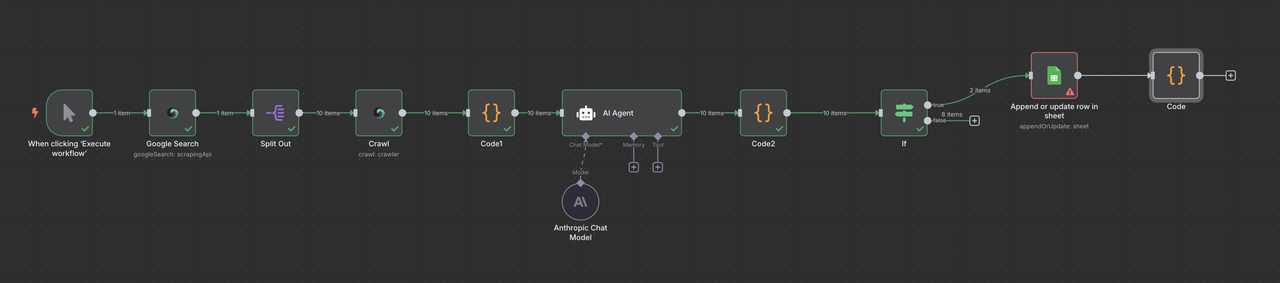
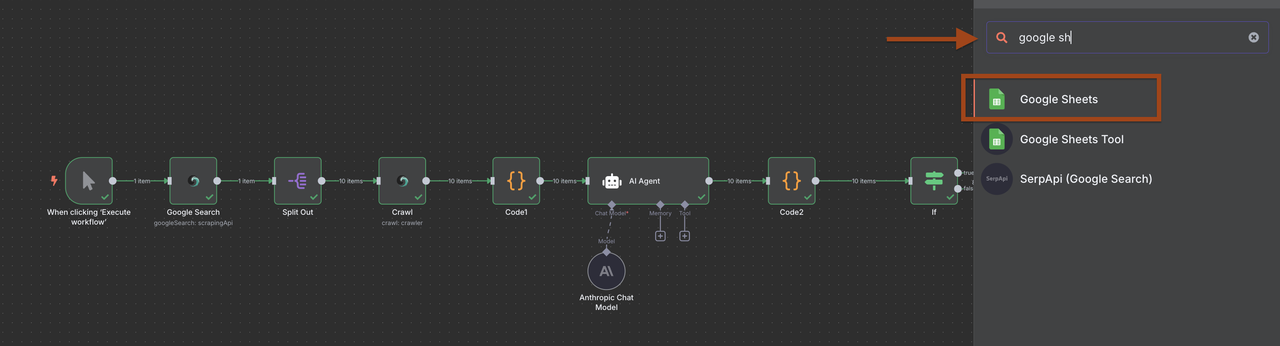
Configuração do Google Sheets:
- Crie uma planilha chamada "Banco de Dados de Leads B2B"
- Configure as colunas:
- Nome da Empresa
- Indústria
- Tamanho da Empresa
- Localização
- E-mail de Contato
- Telefone
- Site
- Pontuação do Lead
- Data Adicionada
- Notas de Qualificação
- Próximas Ações
Por minha parte, escolho usar diretamente um webhook do Discord
Passo 9-2: Notificações no Discord (Adaptável a Outros Serviços)
Envie notificações em tempo real para novos leads qualificados.
- Adicione um nó de Solicitação HTTP para o webhook do Discord
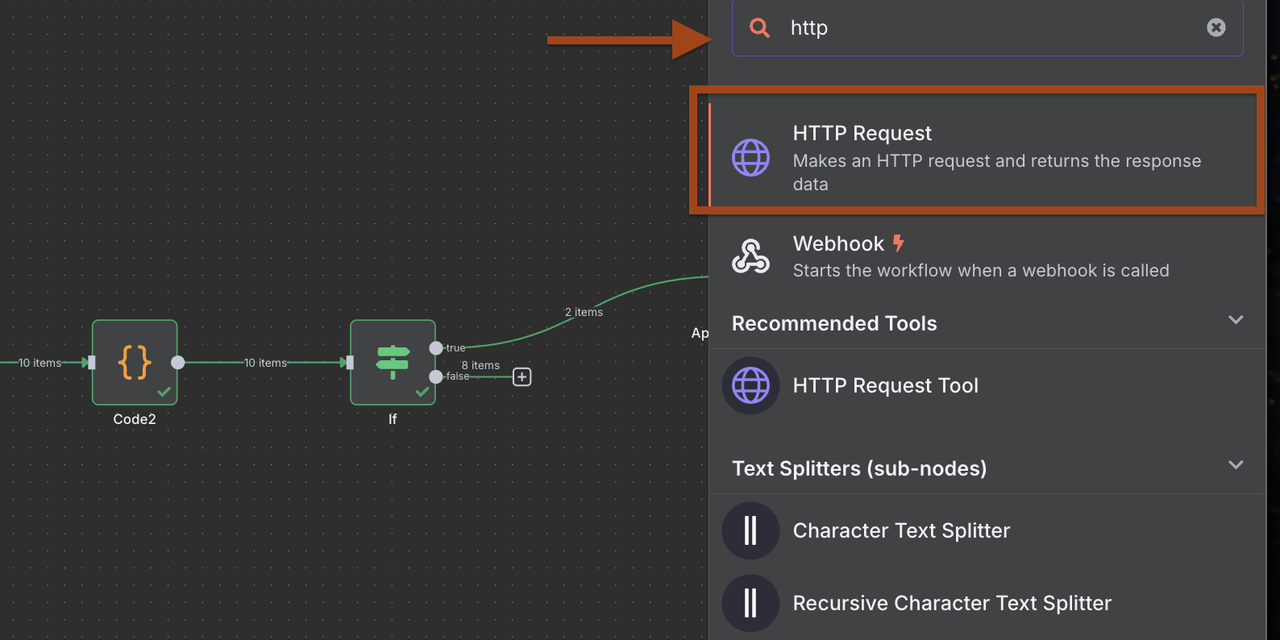
- Configure o formato de carga útil específico do Discord
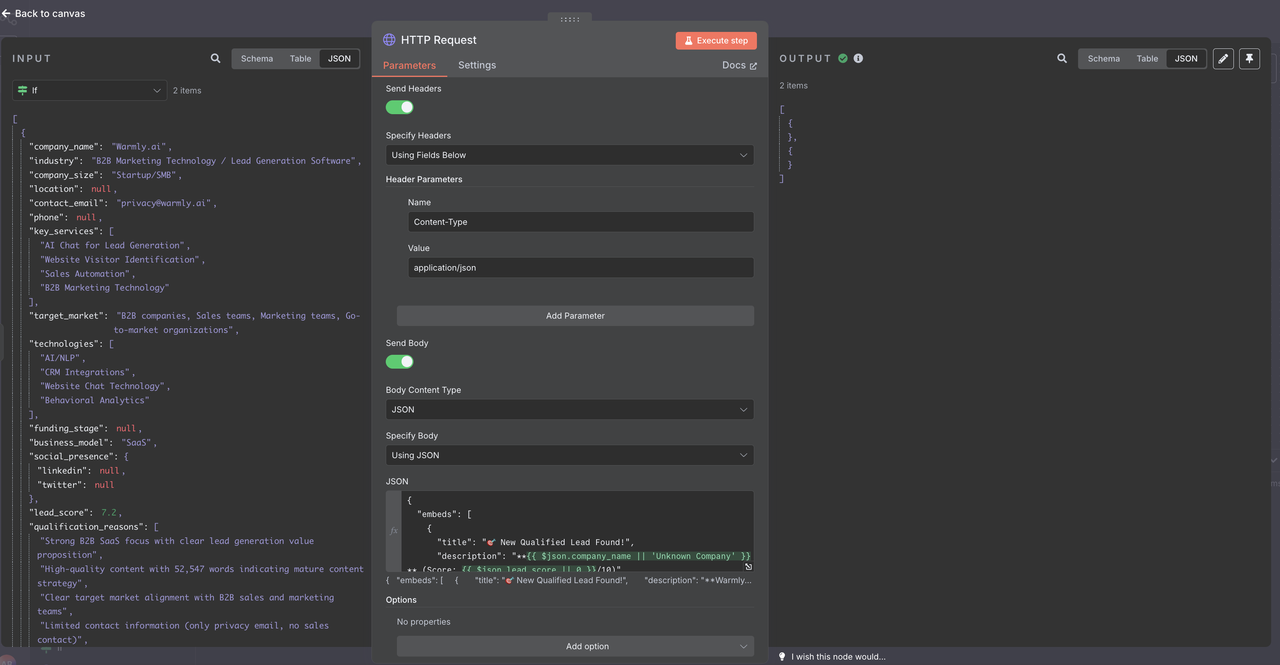
Configuração do Webhook do Discord:
- Método: POST
- URL: Sua URL do webhook do Discord
- Cabeçalhos: Content-Type: application/json
Carga Útil da Mensagem do Discord:
{
"embeds": [
{
"title": "🎯 Novo Lead Qualificado Encontrado!",
"description": "**{{ $json.company_name || 'Empresa Desconhecida' }}** (Pontuação: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "Indústria",
"value": "{{ $json.industry || 'Não especificado' }}",
"inline": true
},
{
"name": "Tamanho",
"value": "{{ $json.company_size || 'Não especificado' }}",
"inline": true
},
{
"name": "Localização",
"value": "{{ $json.location || 'Não especificado' }}",
"inline": true
},
{
"name": "Contato",
"value": "{{ $json.contact_email || 'Nenhum e-mail encontrado' }}",
"inline": false
},
{
"name": "Telefone",
"value": "{{ $json.phone || 'Nenhum telefone encontrado' }}",
"inline": false
},
{
"name": "Serviços",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : 'Não especificado' }}",
"inline": false
},
{
"name": "Site",
"value": "[Visitar Site]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "Por que Qualificado",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : 'Critérios de qualificação padrão atendidos' }}",
"inline": false
}
],
"footer": {
"text": "Gerado pelo Fluxo de Trabalho de Geração de Leads n8n"
},
"timestamp": ""
}
]
}Resultados
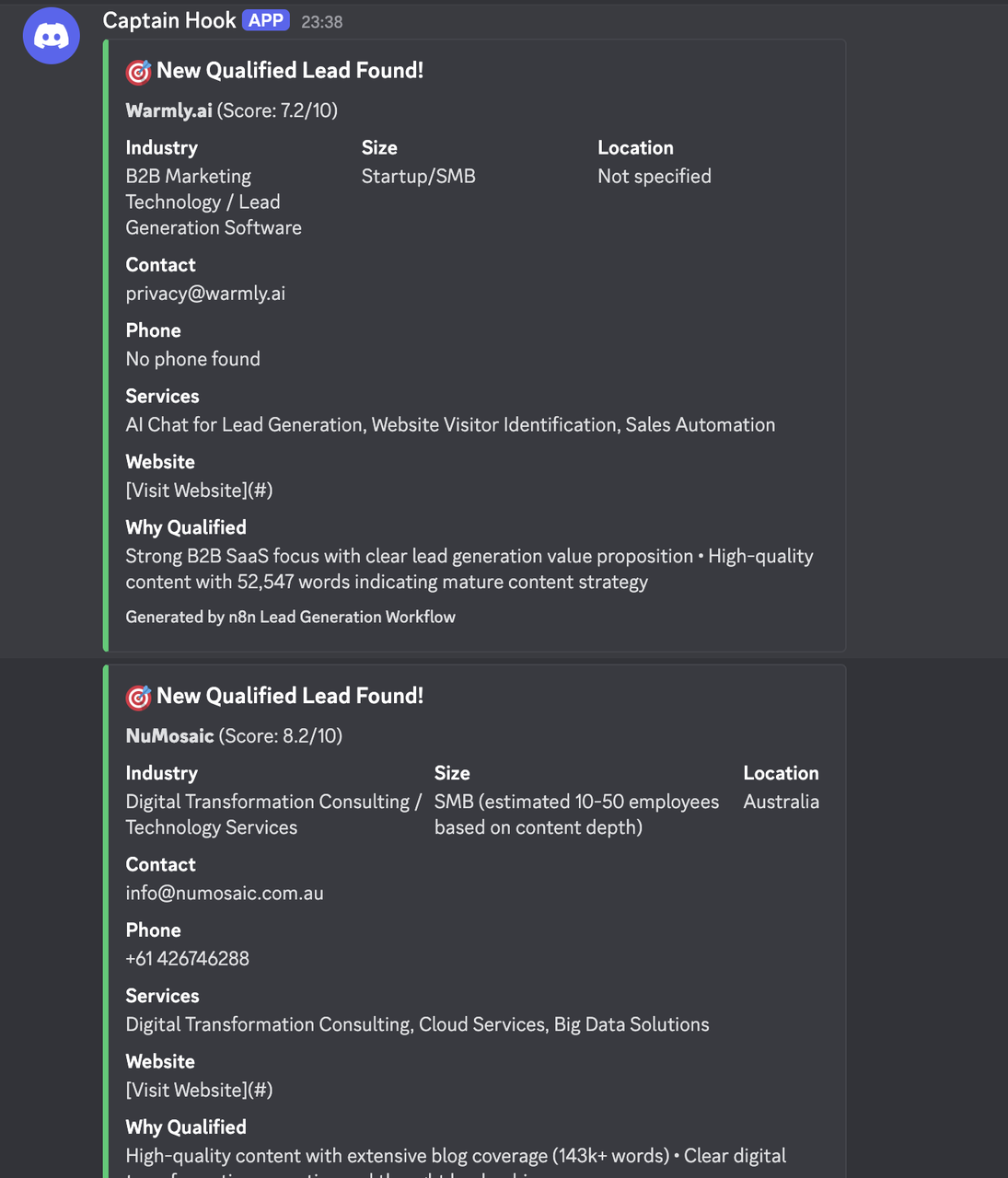
Configurações Específicas por Indústria
Empresas de SaaS/Software
Consultas de Pesquisa:
"empresas de SaaS" "software B2B" "software empresarial"
"software em nuvem" "API" "desenvolvedores" "modelo de assinatura"
"software como serviço" "plataforma" "integração"Critérios de Qualificação:
- Contagem de funcionários: 20-500
- Usa pilha de tecnologia moderna
- Possui documentação de API
- Ativo no GitHub/conteúdo técnico
Agências de Marketing
Consultas de Pesquisa:
"agência de marketing digital" "marketing B2B" "clientes empresariais"
"automação de marketing" "geração de demanda" "geração de leads"
"agência de marketing de conteúdo" "marketing de crescimento" "marketing de desempenho"Critérios de Qualificação:
- Estudos de caso de clientes disponíveis
- Tamanho da equipe: 10-100
- Especializa-se em B2B
- Marketing de conteúdo ativo
E-commerce/Varejo
Consultas de Pesquisa:
"empresas de ecommerce" "varejo online" "marcas D2C"
"lojas Shopify" "WooCommerce" "plataforma de ecommerce"
"marketplace online" "comércio digital" "tecnologia de varejo"Critérios de Qualificação:
- Indicadores de receita
- Presença multicanal
- Plataforma de tecnologia mencionada
- Sinais de trajetória de crescimento
Gestão e Análise de Dados
Esquema do Banco de Dados de Leads
Estruture suas planilhas do Google para máxima utilidade:
Informações Principais do Lead:
- Nome da Empresa, Indústria, Tamanho, Localização
- E-mail de Contato, Telefone, Site
- Pontuação do Lead, Data Adicionada, Consulta de Origem
Dados de Qualificação:
- Razões de Qualificação, Tomadores de Decisão
- Próximas Ações, Data de Acompanhamento
- Representante de Vendas Atribuído, Status do Lead
Campos de Enriquecimento:
- URL do LinkedIn, Presença nas Redes Sociais
- Tecnologias Usadas, Estágio de Financiamento
- Concorrentes, Notícias Recentes
Análise e Relatórios
Acompanhe o desempenho do fluxo de trabalho com planilhas adicionais:
Planilha de Resumo Diário:
- Leads Gerados por Dia
- Pontuação Média do Lead
- Principais Indústrias Encontradas
- Taxas de Conversão
Desempenho de Pesquisa:
- Consultas com Melhor Desempenho
- Distribuição Geográfica
- Distribuição por Tamanho da Empresa
- Taxa de Sucesso por Indústria
Acompanhamento do ROI:
- Custo por Lead (custos da API)
- Tempo para Contato
- Conversão para Oportunidade
- Atribuição de Receita
Conclusão
Este fluxo de trabalho inteligente de geração de leads B2B transforma sua prospecção de vendas ao automatizar a descoberta, qualificação e organização de potenciais clientes. Ao combinar a Pesquisa do Google com rastreamento inteligente e análise de IA, você cria uma abordagem sistemática para construir seu pipeline de vendas.
O fluxo de trabalho se adapta ao seu setor específico, metas de tamanho da empresa e critérios de qualificação, mantendo alta qualidade de dados por meio da análise impulsionada por IA. Com a configuração e monitoramento adequados, este sistema se torna uma fonte consistente de leads qualificados para sua equipe de vendas.
A integração com o Google Sheets fornece um banco de dados acessível para as equipes de vendas, enquanto as notificações no Discord garantem consciência imediata sobre prospects de alto valor. O design modular permite fácil adaptação a diferentes serviços de notificação, sistemas de CRM e soluções de armazenamento de dados.
O Scrapeless cumpre rigorosamente as leis e regulamentos aplicáveis, acessando apenas dados publicamente disponíveis de acordo com os termos de serviço e políticas de privacidade dos sites. Esta solução é projetada para fins legítimos de inteligência de negócios e otimização de marketing.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


