
Construa um Assistente de Pesquisa Potenciado por IA com Linear + Scrapeless + Claude
Advanced Data Extraction Specialist
Equipes modernas precisam de acesso instantâneo a dados confiáveis para tomada de decisões informadas. Seja pesquisando concorrentes, analisando tendências ou reunindo inteligência de mercado, a coleta manual de dados desacelera seu fluxo de trabalho e quebra seu ímpeto de desenvolvimento.
Ao combinar a plataforma de gerenciamento de projetos Linear com as poderosas APIs de extração de dados da Scrapeless e as capacidades analíticas da Claude AI, você pode criar um assistente de pesquisa inteligente que responde a comandos simples diretamente em suas questões do Linear.
Essa integração transforma seu espaço de trabalho do Linear em um centro de comando inteligente, onde digitar /search análise de concorrente ou /trends AI mercado aciona automaticamente uma coleta abrangente de dados e análise impulsionada por IA — tudo entregue de volta como comentários estruturados em suas questões do Linear.
Por Que Escolher Linear + Scrapeless + Claude?
Linear: O Espaço de Trabalho Moderno para Desenvolvimento
O Linear oferece a interface perfeita para colaboração em equipe e gerenciamento de tarefas:
- Fluxo de Trabalho Baseado em Questões: Integração natural com processos de desenvolvimento
- Atualizações em Tempo Real: Notificações instantâneas e comunicação sincronizada da equipe
- Webhooks e API: Poderosas capacidades de automação com ferramentas externas
- Rastreamento de Projetos: Análises internas e monitoramento de progresso
- Colaboração em Equipe: Recursos de comentários e discussão sem interrupções
Scrapeless: Extração de Dados de Nível Empresarial
A Scrapeless oferece extração de dados confiável e escalável de múltiplas fontes:
- Pesquisa Google: Permite a extração abrangente de dados SERP do Google em todos os tipos de resultados.
- Tendências Google: Recupera dados de tendências de palavras-chave do Google, incluindo popularidade ao longo do tempo, interesse regional e pesquisas relacionadas.
- API de Scraping Universal: Acesse e extraia dados de sites com renderização JS que normalmente bloqueiam bots.
- Crawl: Rasteie um site e suas páginas vinculadas para extrair dados abrangentes.
- Scrape: Extraia informações de uma única página da web.
Claude AI: Análise de Dados Inteligente
A Claude AI transforma dados brutos em insights acionáveis:
- Raciocínio Avançado: Análise sofisticada e reconhecimento de padrões
- Saída Estruturada: Respostas limpas e formatadas, perfeitas para comentários no Linear
- Consciência de Contexto: Entende o contexto de negócios e a intenção do usuário
- Insights Acionáveis: Fornece recomendações e próximos passos
- Síntese de Dados: Combina múltiplas fontes de dados em uma análise coerente
Casos de Uso
Centro de Comando de Inteligência Competitiva
Pesquisa Instantânea de Concorrentes
- Análise da Posição de Mercado: Rastreamento automatizado de sites de concorrentes e análise
- Monitoramento de Tendências: Acompanhe menções de concorrentes e mudanças na percepção da marca
- Detecção de Lançamentos de Produtos: Identifique quando concorrentes introduzem novos recursos
- Insights Estratégicos: Análise com base em IA da posição competitiva
Exemplos de Comandos:
/search "lançamento de produto concorrente" 2024
/trends nome-da-marca-concorrente
/crawl https://concorrente.com/produtosAutomação de Pesquisa de Mercado
Inteligência de Mercado em Tempo Real
- Análise de Tendências da Indústria: Monitoramento automatizado de Tendências Google para segmentos de mercado
- Sentimento do Consumidor: Análise de tendências de pesquisa para categorias de produtos
- Identificação de Oportunidades de Mercado: Análise de lacunas de mercado impulsionada por IA
- Pesquisa de Investimento: Análise de tendências de financiamento de startups e indústrias
Exemplos de Comandos:
/trends "mercado de inteligência artificial"
/search "financiamento de startup SaaS 2024"
/crawl https://techcrunch.com/category/startupsPesquisa de Desenvolvimento de Produtos
Pesquisa e Validação de Recursos
- Análise de Necessidades do Usuário: Análise de tendências de pesquisa para recursos de produtos
- Pesquisa de Tecnologia: Documentação e pesquisa de API automatizadas
- Descoberta de Melhores Práticas: Rasteie líderes de mercado em busca de padrões de implementação
- Validação de Mercado: Análise de tendências para avaliação do ajuste entre produto e mercado
Exemplos de Comandos:
/search "melhores práticas de autenticação do usuário"
/trends "recursos de aplicativos móveis"
/crawl https://docs.stripe.com/apiGuia de Implementação
Etapa 1: Configuração do Espaço de Trabalho Linear
Prepare seu Ambiente Linear
-
Acesse seu Espaço de Trabalho Linear
- Navegue até linear.app e faça login no seu espaço de trabalho
- Certifique-se de ter permissões de administrador para configuração de webhook
- Crie ou selecione um projeto para automação de pesquisa
-
Gere o Token da API Linear
- Vá para Configurações do Linear > API > Tokens de API Pessoais
- Clique em "Criar token" com as permissões apropriadas
- Copie o token para uso na configuração do n8n
Etapa 2: Configuração do Fluxo de Trabalho n8n
Crie Seu Ambiente de Automação n8n
- Configure a Instância n8n
- Use n8n cloud ou auto-hospede (observação: a auto-hospedagem requer configuração do ngrok; para este guia, usaremos o n8n cloud)
- Crie um novo fluxo de trabalho para a integração Linear
- Importe o JSON do fluxo de trabalho fornecido
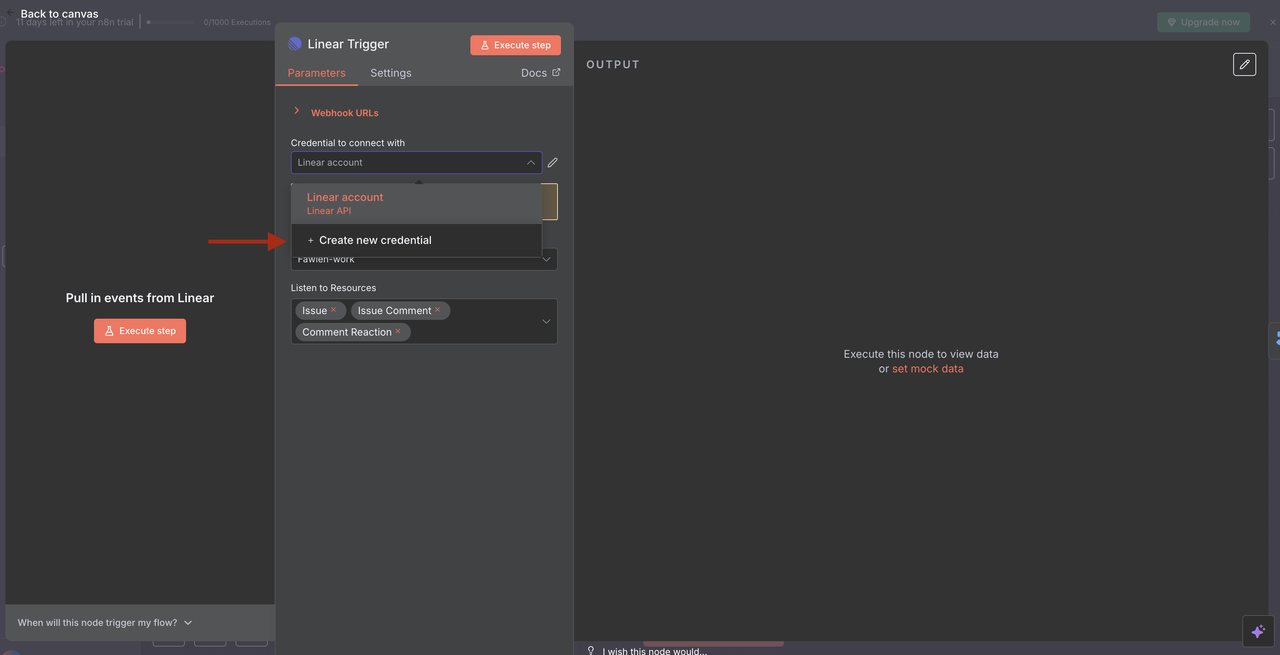
- Configurar o Gatilho Linear
- Adicione credenciais Linear usando seu token da API
- Configure um webhook para escutar eventos de issues
- Configure o ID da equipe e aplique filtros de recursos conforme necessário
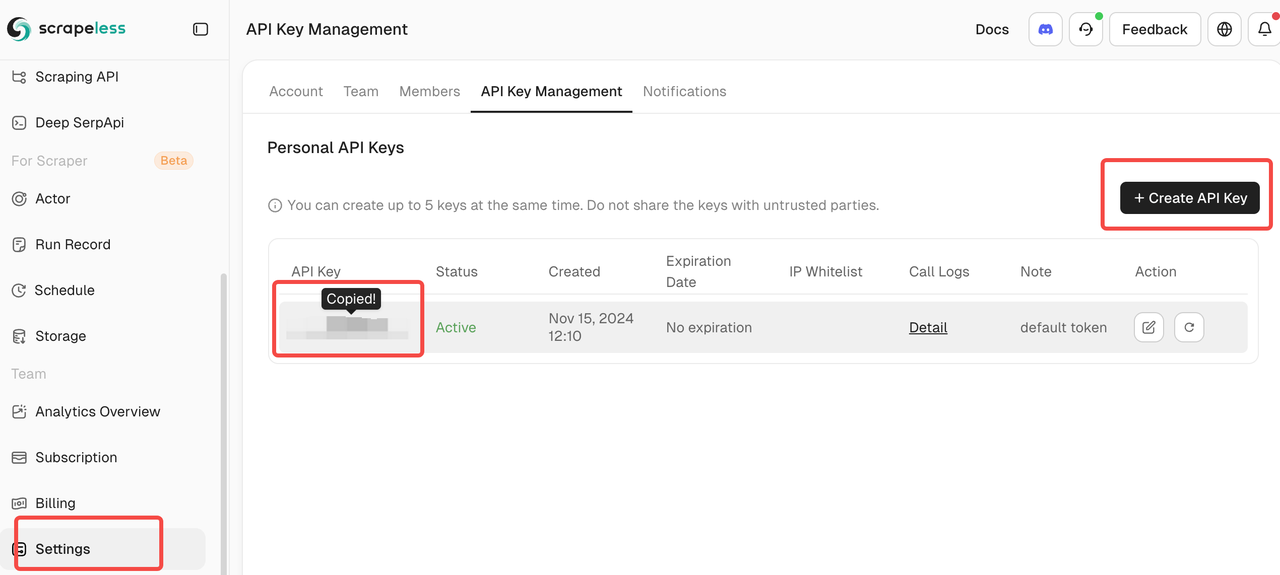
Passo 3: Configuração da Integração Scrapeless
Conecte Sua Conta Scrapeless
- Obtenha Credenciais Scrapeless
- Inscreva-se em scrapeless.com
- Navegue até Painel > Chaves de API
- Copie seu token API para a configuração do n8n
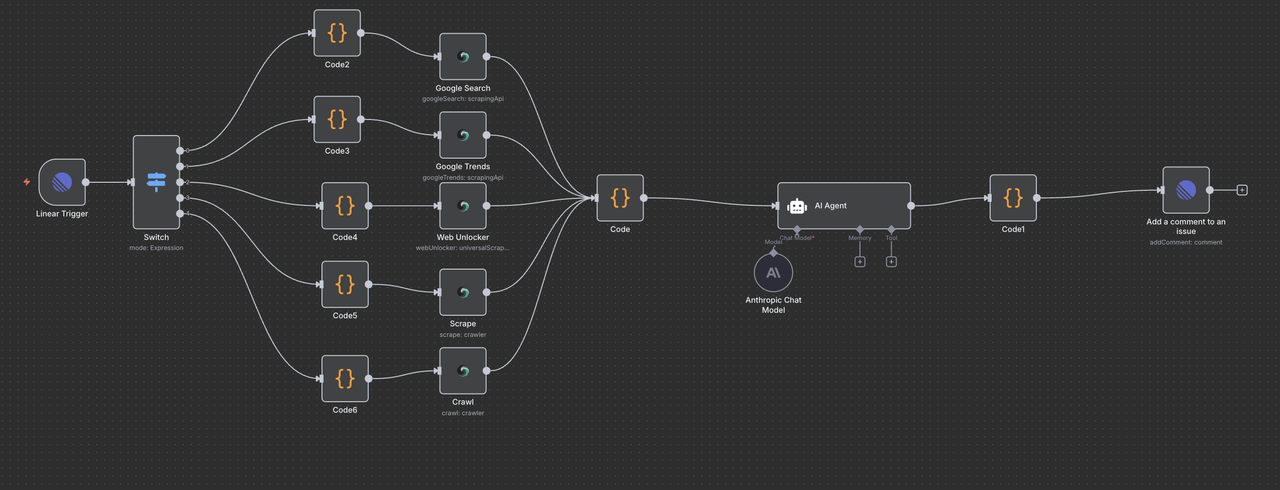
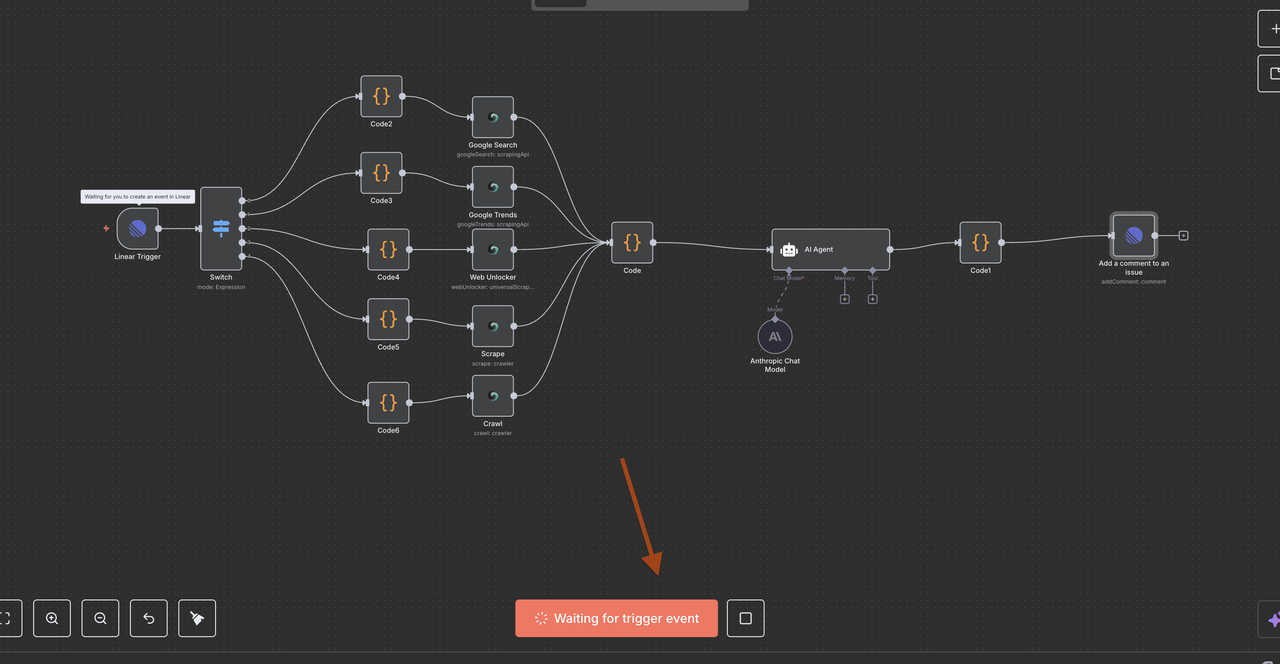
Compreendendo a Arquitetura do Fluxo de Trabalho
Vamos passar por cada componente do fluxo de trabalho passo a passo, explicando o que cada nó faz e como eles funcionam juntos.
Passo 4: Nó de Gatilho Linear (Ponto de Entrada)
O Ponto de Partida: Gatilho Linear
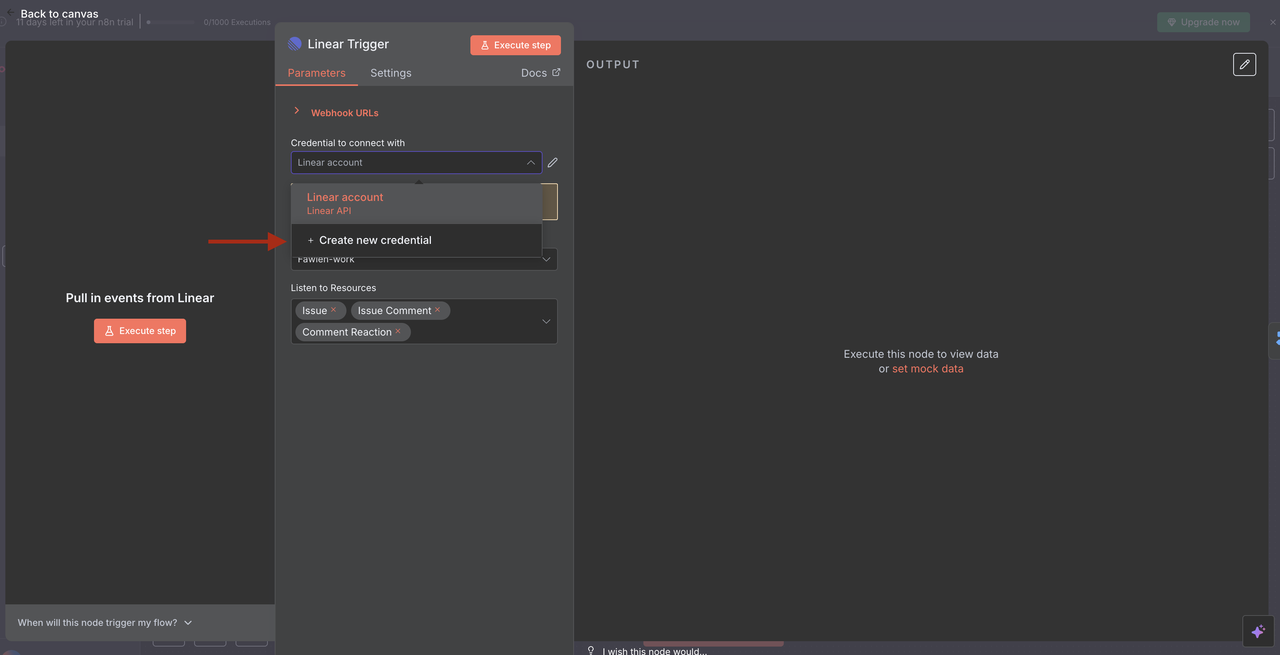
O Gatilho Linear é o ponto de entrada do nosso fluxo de trabalho. Este nó:
O que faz:
- Escuta eventos de webhook do Linear sempre que issues são criadas ou atualizadas
- Captura todos os dados da issue, incluindo título, descrição, ID da equipe e outros metadados
- Só é acionado quando eventos específicos ocorrem (ex: Issue criada, Issue atualizada, Comentário criado)
Detalhes da Configuração:
- ID da Equipe: Vincula à equipe do seu espaço de trabalho Linear específico
- Recursos: Definido para monitorar eventos de
issue,commentereaction - URL do Webhook: Gerada automaticamente pelo n8n e deve ser adicionada às configurações de webhook do Linear
Por que é essencial:
Este nó transforma suas issues Linear em gatilhos de automação.
Por exemplo, quando alguém digita /search análise de concorrentes no título de uma issue, o webhook envia esses dados ao n8n em tempo real.
Passo 5: Nó Switch (Roteador de Comandos)
Detecção e Roteamento Inteligente de Comandos
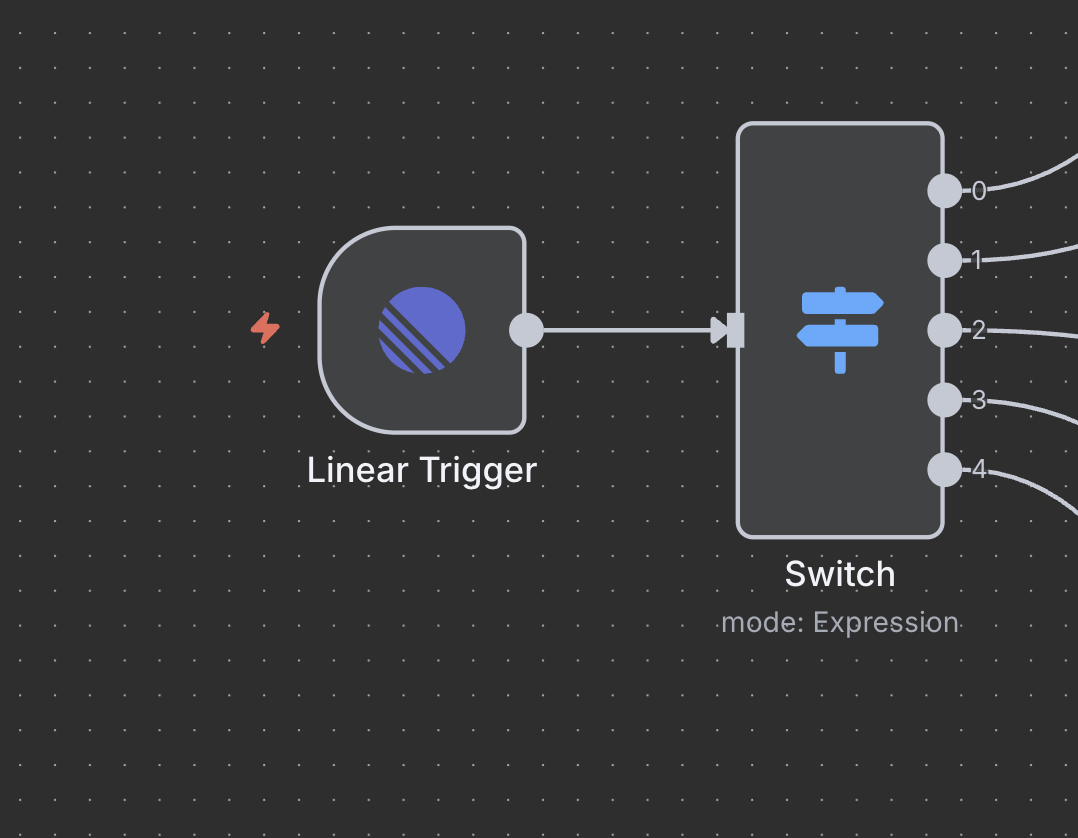
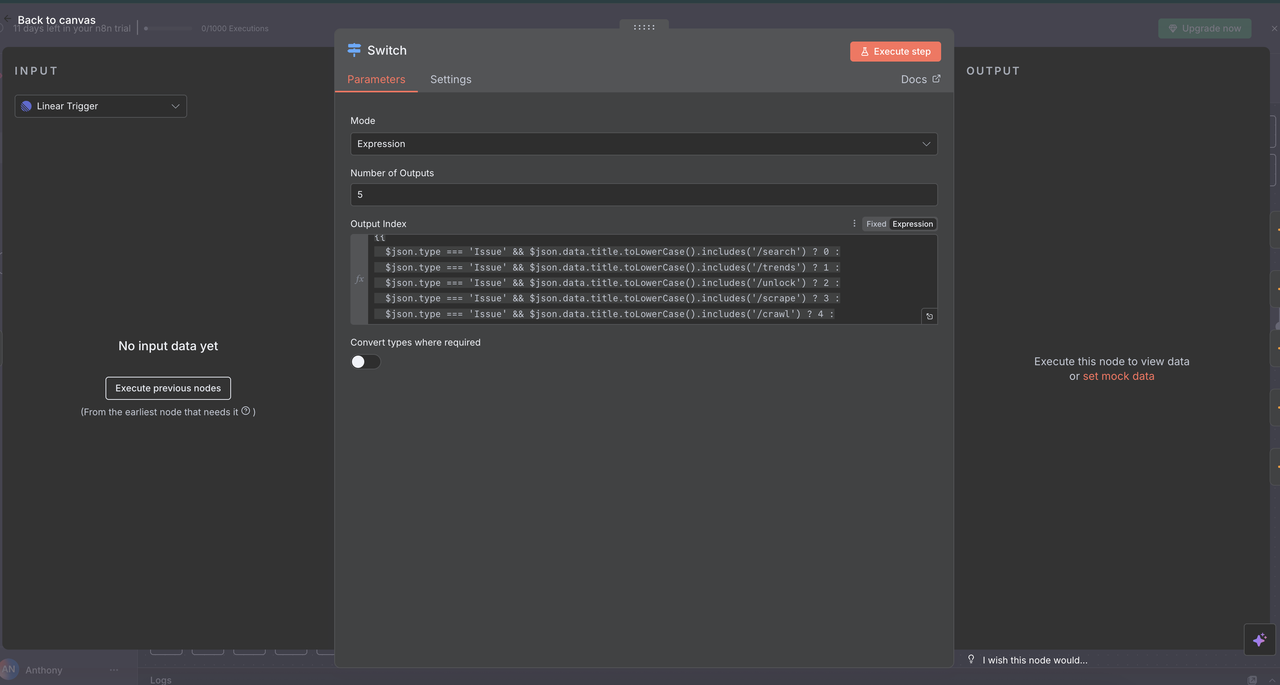
O nó Switch atua como o “cérebro” que determina que tipo de pesquisa realizar com base no comando no título da issue.
Como funciona:
// Lógica de detecção e roteamento de comandos
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}Explicações das Rotas
- Saída 0 (
/search): Roteia para a API de Pesquisa do Google para resultados de pesquisa na web - Saída 1 (
/trends): Roteia para a API de Tendências do Google para análise de tendências - Saída 2 (
/unlock): Roteia para o Desbloqueador da Web para acesso a conteúdo protegido - Saída 3 (
/scrape): Roteia para o Raspador para extração de conteúdo de uma única página - Saída 4 (
/crawl): Roteia para o Crawler para rastreamento de sites de várias páginas - Saída -1: Nenhum comando detectado, fluxo de trabalho termina automaticamente
Configuração do Nó Switch
- Modo: Definido como
"Expressão"para roteamento dinâmico - Número de Saídas:
5(uma para cada tipo de comando) - Expressão: O código JavaScript determina a lógica de roteamento
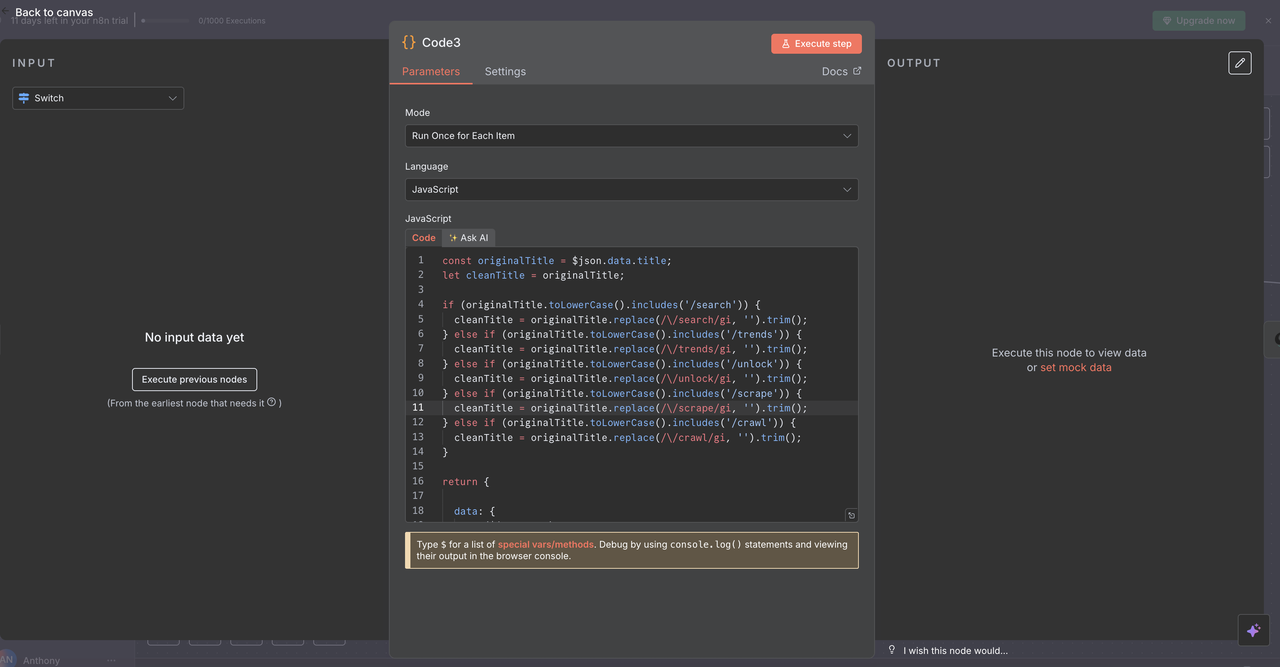
Passo 6: Limpeza do Título Nós de Código
Preparação de Comandos para Processamento da API
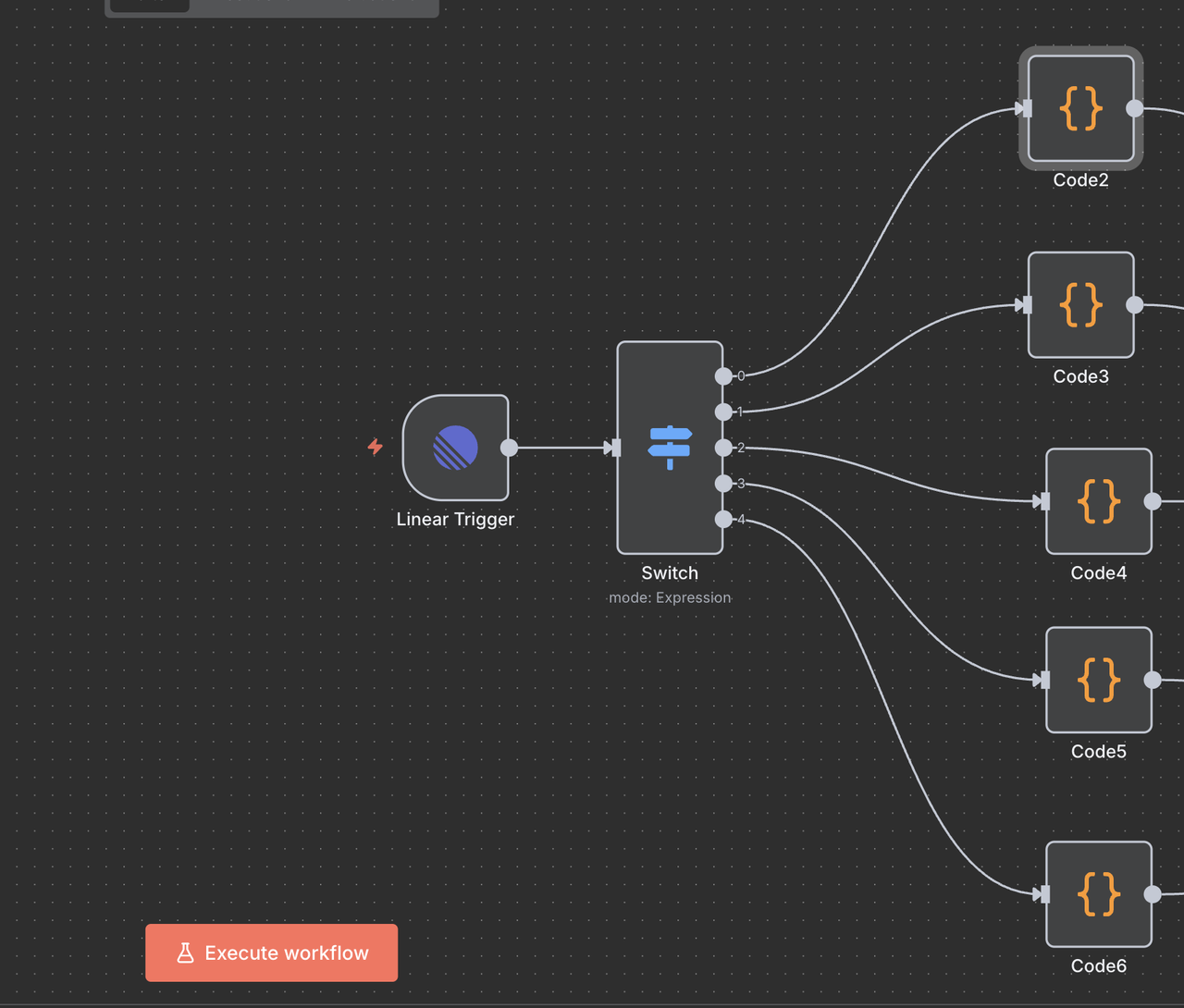
Cada rota inclui um Nó de Código que limpa o comando do título da questão antes de chamar as APIs do Scrapeless.
O que cada Nó de Código faz:
js
// Limpar comando do título para processamento da API
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// Remover prefixos de comando com base no comando detectado
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};
Exemplos de Transformações
/search análise de concorrentes→análise de concorrentes/trends crescimento do mercado de IA→crescimento do mercado de IA/unlock https://exemplo.com→https://exemplo.com
Por que esta etapa é importante
As APIs do Scrapeless precisam de consultas limpas, sem prefixos de comando, para funcionar corretamente.
Isso garante que os dados enviados para as APIs sejam precisos e interpretáveis, melhorando a confiabilidade da automação.
Etapa 7: Nós de Operação do Scrapeless
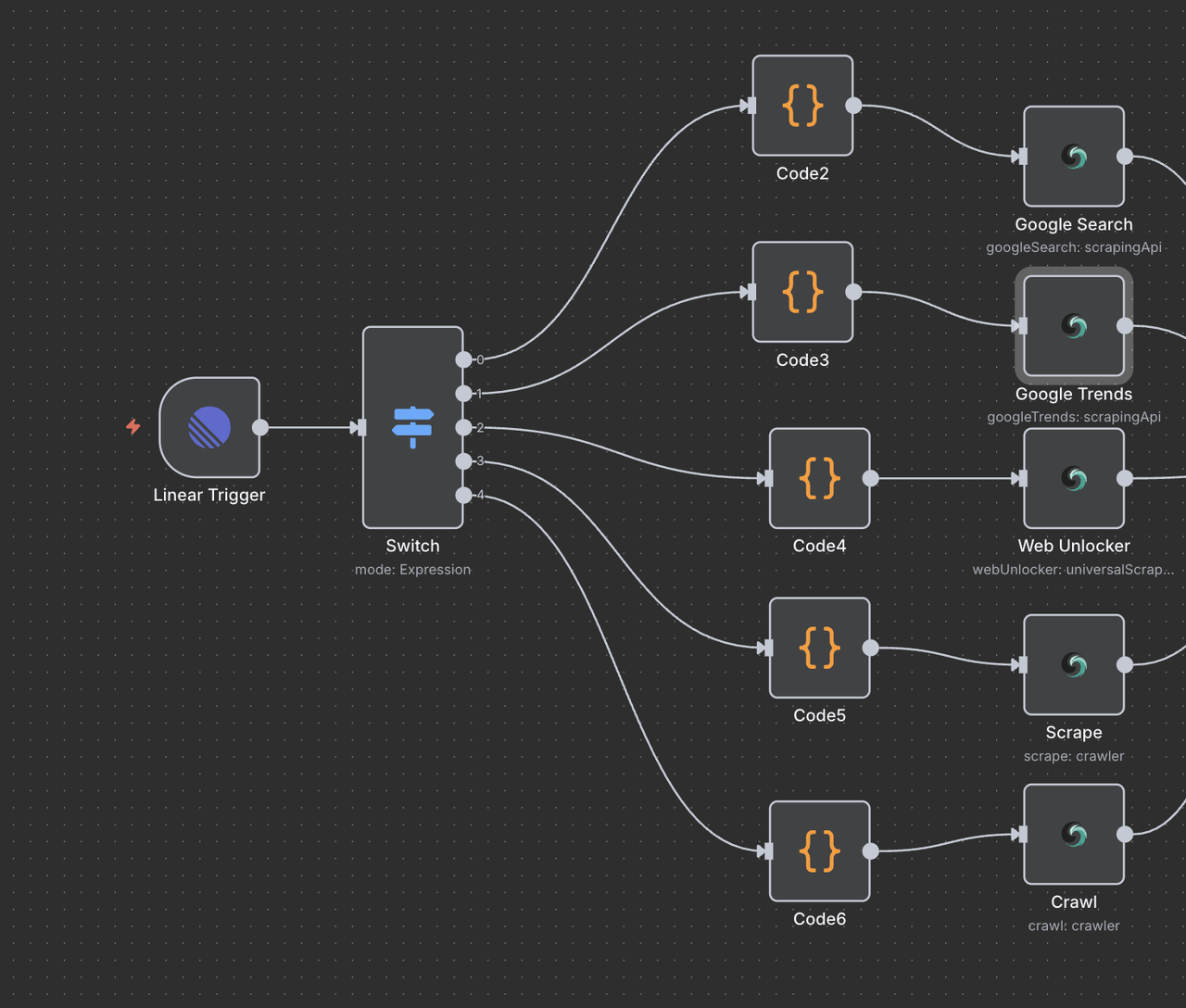
Esta seção apresenta cada nó de operação do Scrapeless e explica sua função.
7.1 Nó de Pesquisa do Google (/search comando)
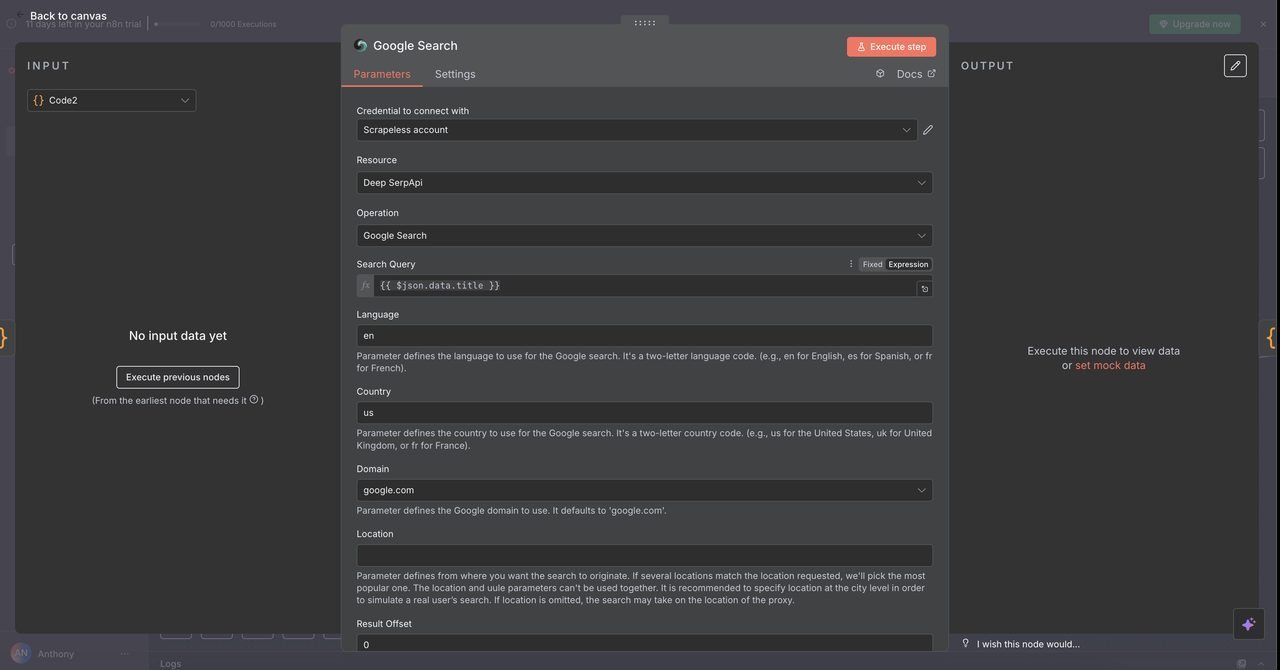
Propósito:
Realiza pesquisas na web do Google e retorna resultados de busca orgânica.
Configuração:
- Operação:
Pesquisar no Google(padrão) - Consulta:
{{ $json.data.title }}(título limpo da etapa anterior) - País:
"US"(pode ser personalizado por localidade) - Idioma:
"pt"(Português)
O que ele retorna:
- Resultados de busca orgânica: Títulos, URLs e trechos
- Perguntas relacionadas na seção "As pessoas também perguntam"
- Metadados: Contagem estimada de resultados, duração da pesquisa
Casos de Uso:
- Pesquisar produtos de concorrentes
/search estratégia de preços de concorrentes
- Encontrar relatórios de indústria
/search relatório do mercado de SaaS 2024
- Descobrir melhores práticas
/search melhores práticas de segurança de API
7.2 Nó de Tendências do Google (/trends comando)
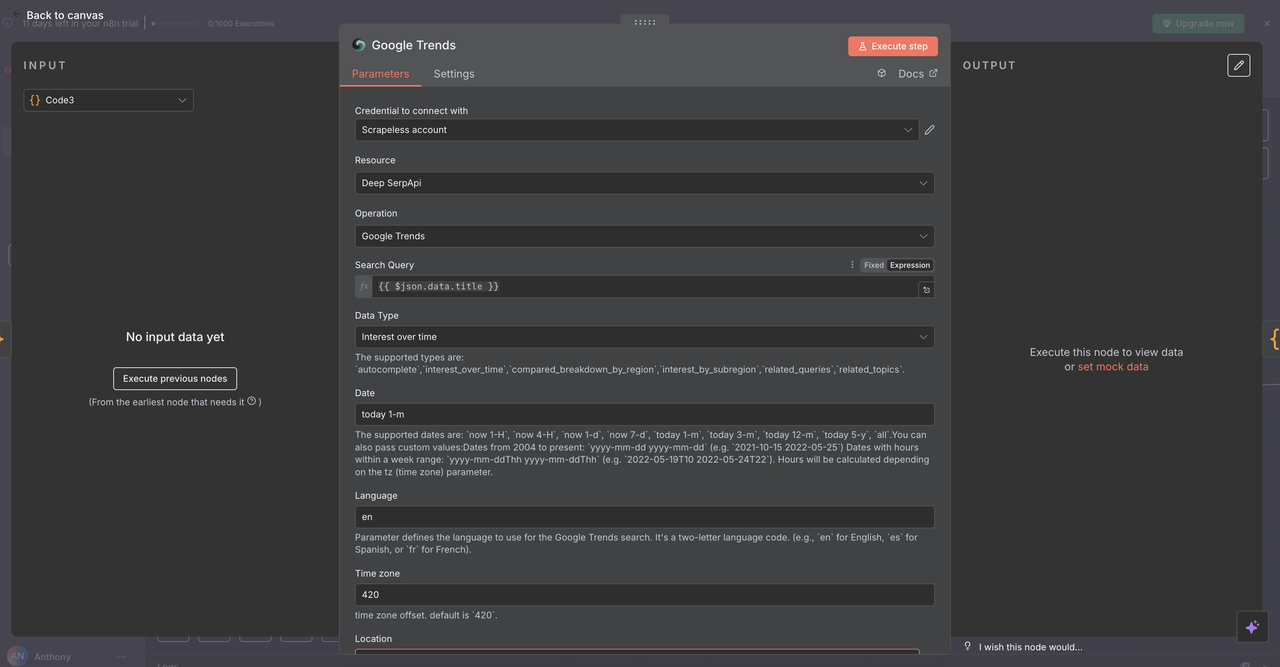
Propósito:
Analisa dados de tendências de busca e interesse ao longo do tempo para palavras-chave específicas.
Configuração:
- Operação:
Tendências do Google - Consulta:
{{ $json.data.title }}(palavra ou frase limpa) - Intervalo de Tempo: Escolher entre opções como 1 mês, 3 meses, 1 ano
- Geográfico: Definir como
Globalou especificar uma região
O que ele retorna:
- Gráfico de interesse ao longo do tempo (escala de 0 a 100)
- Consultas relacionadas e tópicos em tendência
- Distribuição geográfica do interesse
- Divisões de categorias para contexto de tendência
Casos de Uso:
- Validação de mercado
/trends adoção de veículos elétricos - Análise sazonal
/trends tendências de compras de fim de ano - Monitoramento de marca
/trends menções de nome-da-empresa
7.3 Nó Desbloqueador de Web (/unlock comando)
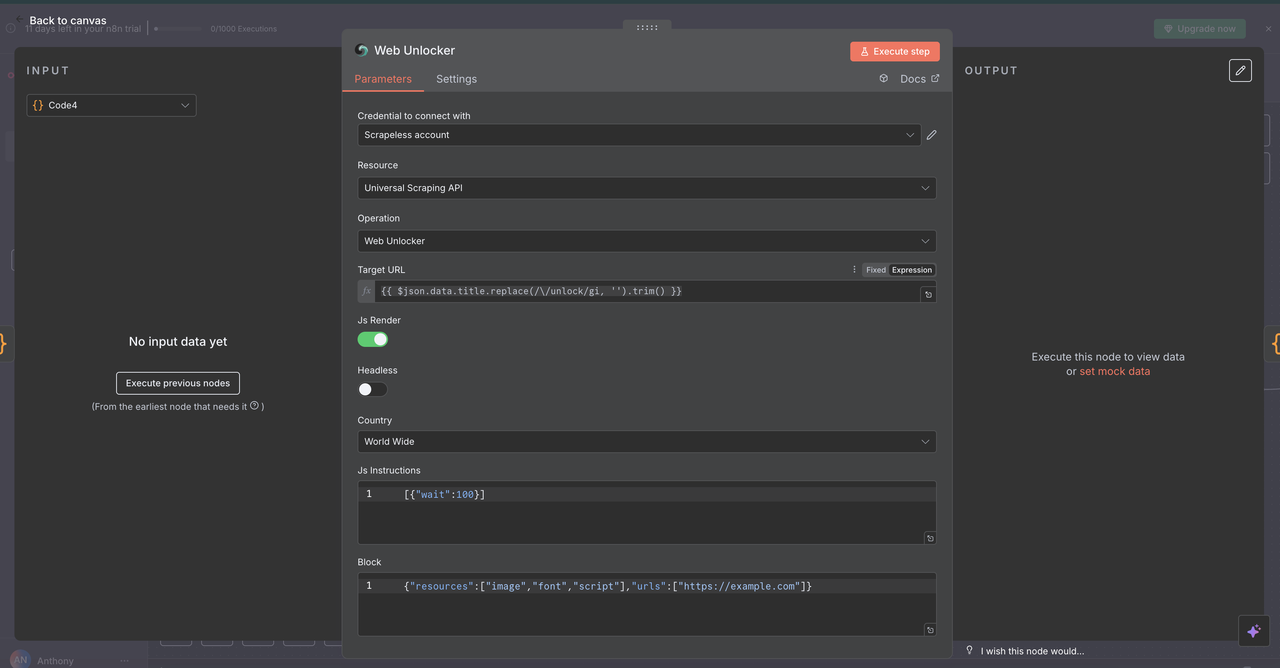
Propósito:
Acessar conteúdo de sites protegidos por mecanismos anti-bots ou paywalls.
Configuração:
- Recurso:
API de Raspagem Universal - URL:
{{ $json.data.title }}(deve conter uma URL válida) - Headless:
false(para melhor compatibilidade com anti-bots) - Renderização de JavaScript:
habilitada(para carregamento completo de conteúdo dinâmico)
O que ele retorna:
- Conteúdo HTML completo da página
- Conteúdo final renderizado em JavaScript
- Capacidade de contornar proteções anti-bots comuns
Casos de Uso:
- Análise de preços de concorrentes
/unlock https://concorrente.com/precos - Acesso a pesquisas restritas
/unlock https://site-de-pesquisa.com/relatorio - Raspagem de aplicativos dinâmicos
/unlock https://aplicativo-spa.com/dados
7.4 Nó de Raspagem (/scrape comando)
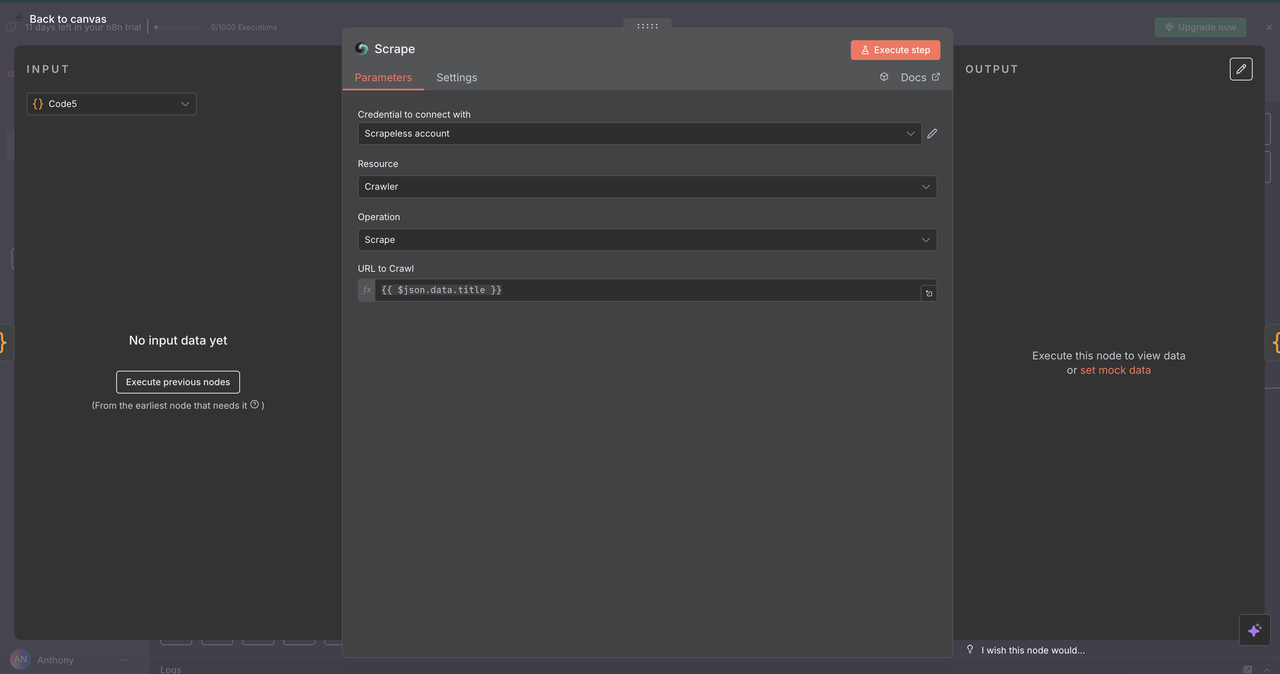
Propósito:
Extrair conteúdo estruturado de uma única página da web usando seletores ou análise padrão.
Configuração:
- Recurso:
Crawler(usado aqui para scraping de uma única página) - URL:
{{ $json.data.title }}(página da web alvo) - Formato: Escolher saída como
HTML,TextoouMarkdown - Seletores: Seletores CSS opcionais para direcionar conteúdo específico
O Que Retorna:
- Texto estruturado e limpo da página
- Metadados da página (título, descrição, etc.)
- Exclui navegação/anúncios por padrão
Casos de Uso:
- Extração de artigos de notícias
/scrape https://news-site.com/article - Análise de documentos da API
/scrape https://api-docs.com/endpoint - Captura de informações de produtos
/scrape https://product-page.com/item
7.5 Nó do Crawler (/crawl comando)
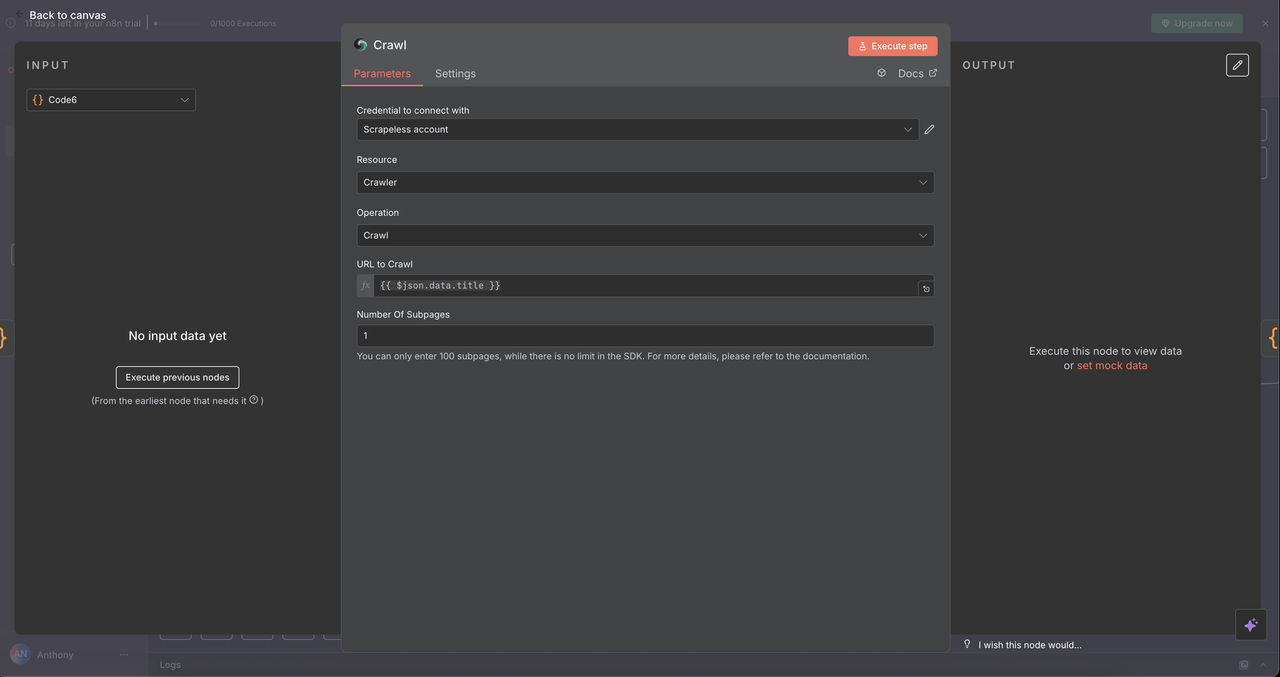
Propósito:
Rastear sistematicamente várias páginas de um site para extração abrangente de dados.
Configuração:
- Recurso:
Crawler - Operação:
Crawl - URL:
{{ $json.data.title }}(URL ponto de partida) - Limitar Páginas de Rasteio: Limite opcional, por exemplo, 5–10 páginas para evitar sobrecarga
- Incluir/Excluir Padrões: Filtros de regex ou string para refinar o escopo do rastreamento
O Que Retorna:
- Conteúdo de várias páginas relacionadas
- Estrutura de navegação do site
- Conjunto de dados rico em todo o domínio/subseções alvo
Casos de Uso:
-
Pesquisa de Concorrentes
/crawl https://competitor.com
(ex: preços, recursos, páginas sobre) -
Mapeamento de Documentação
/crawl https://docs.api.com
(rasteia toda a documentação da API ou do desenvolvedor) -
Auditorias de Conteúdo
/crawl https://blog.company.com
(mapeia artigos, categorias, tags para revisão de SEO)
Passo 8: Convergência e Processamento de Dados
Unindo Todos os Resultados Scrapeless
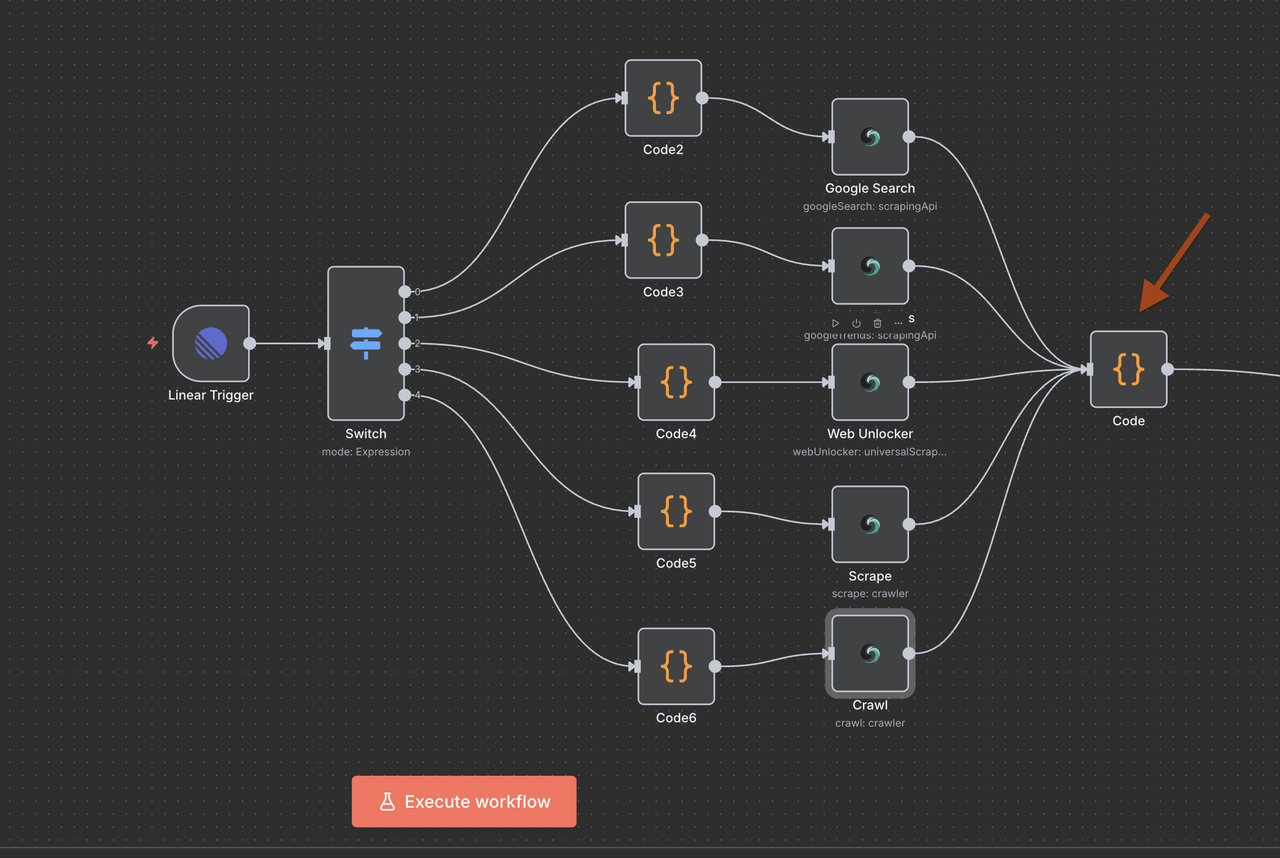
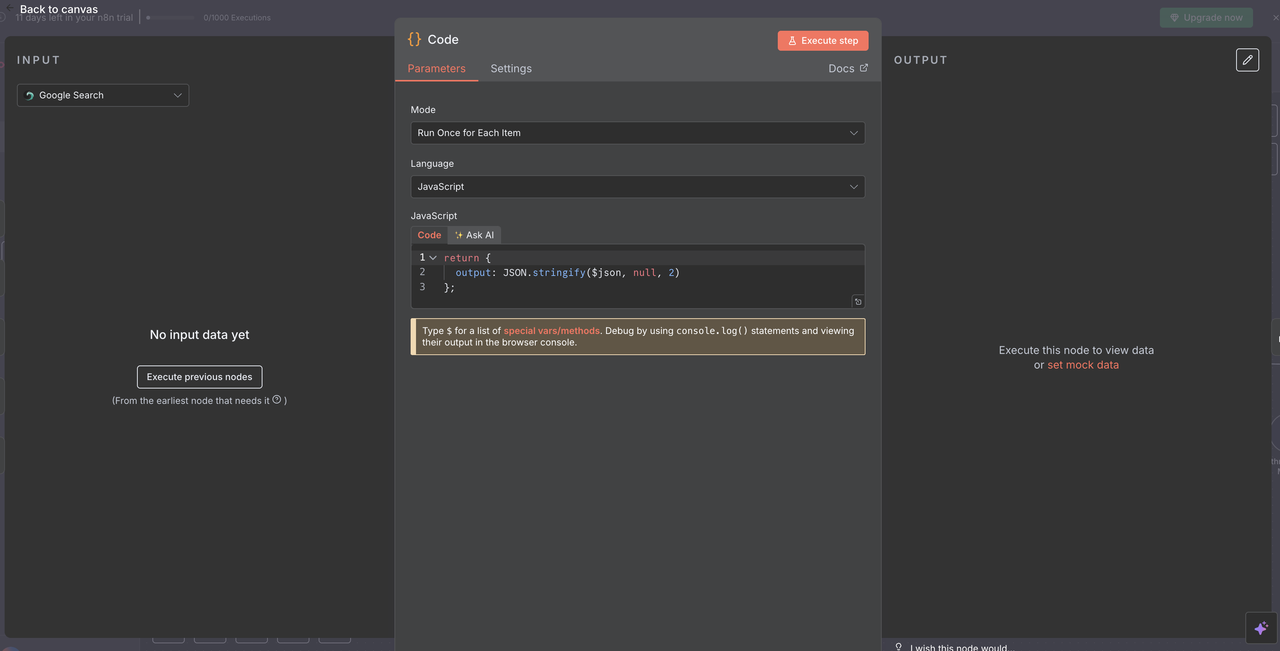
Após executar um dos 5 ramos de operação Scrapeless, um único Nó de Código é usado para normalizar a resposta para processamento de IA.
Propósito do Nó de Código de Convergência:
- Agrega a saída de qualquer um dos nós Scrapeless
- Normaliza o formato dos dados em todos os comandos
- Prepara a carga final para entrada no Claude ou outro modelo de IA
Configuração do Código:
javascript
// Converte a resposta Scrapeless para um formato legível pela IA
return {
output: JSON.stringify($json, null, 2)
};
Passo 9: Motor de Análise AI Claude
Análise de Dados Inteligente e Geração de Insights
9.1 Configuração do Nó do Agente AI
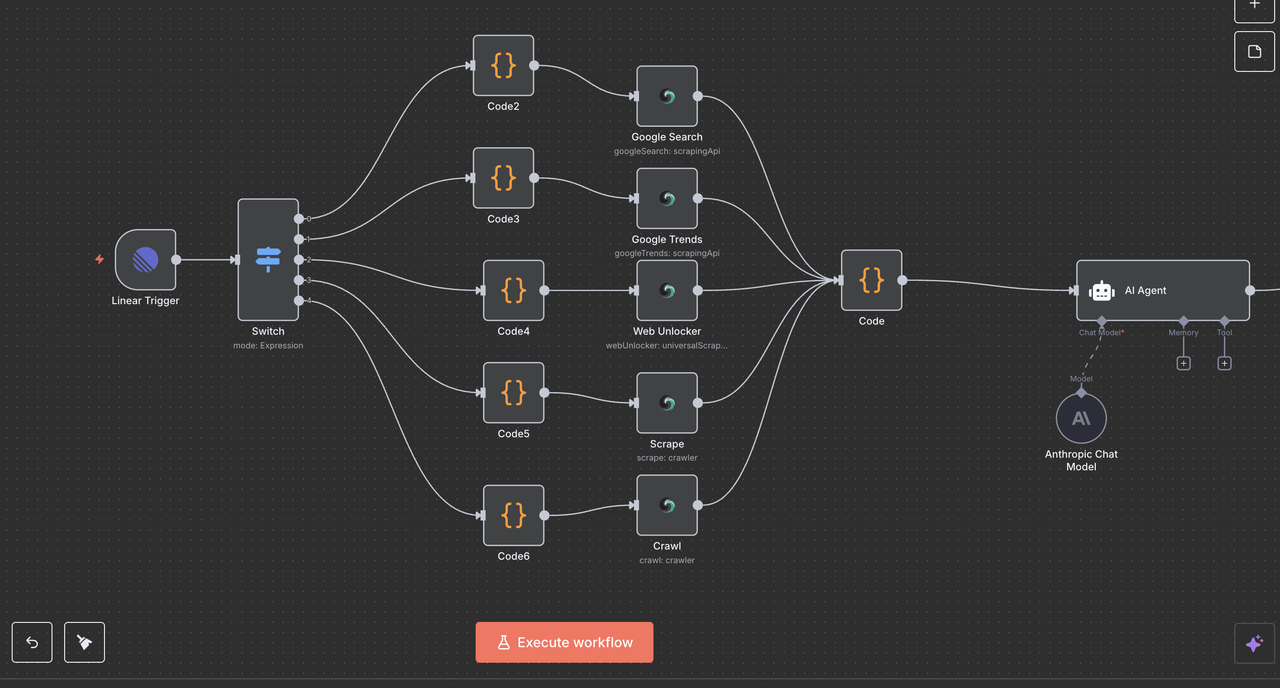
⚠️ Não se esqueça de configurar sua chave API para Claude.
O Nó do Agente AI é onde a mágica acontece — ele pega a saída normalizada do Scrapeless e a transforma em insights claros e acionáveis, adequados para uso em comentários do Linear ou outras ferramentas de relatório.
Detalhes da Configuração:
- Tipo de Prompt:
Definir - Entrada de Texto:
{{ $json.output }}(string JSON processada do nó de convergência) - Mensagem do Sistema: Define o tom, papel e tarefa para o Claude
Prompt do Sistema de Análise AI:
Você é um analista de dados. Resuma os resultados da busca/raspagem de forma concisa. Seja factual e breve. Formate para comentários Linear.
Analise os dados fornecidos e crie um resumo estruturado que inclua:
- Principais descobertas e insights
- Fonte de dados e avaliação de confiabilidade
- Recomendações acionáveis
- Métricas e tendências relevantes
- Próximos passos para pesquisa adicional
Formate sua resposta com cabeçalhos claros e marcadores para fácil leitura no Linear.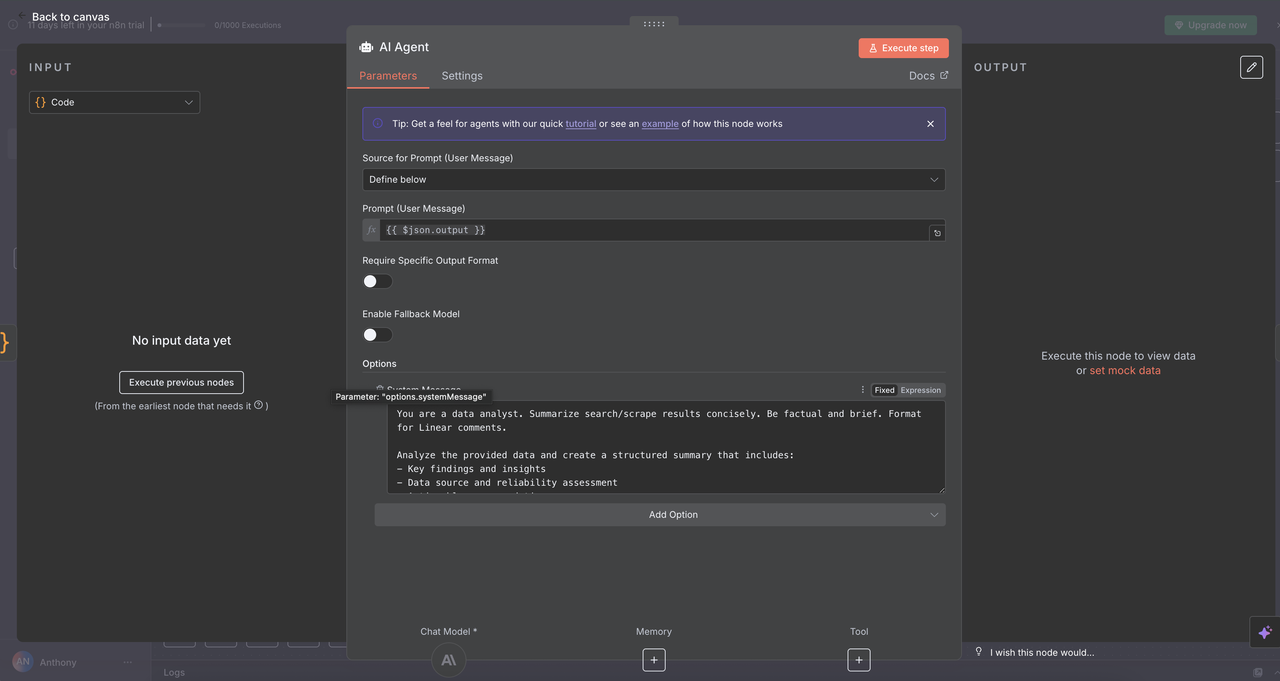
Por Que Este Prompt Funciona
- Especificidade: Diz ao Claude exatamente que tipo de análise realizar
- Estrutura: Solicita uma saída organizada com seções claras
- Contexto: Otimizado para formatação de comentários Linear
- Ação: Foca em insights que as equipes podem agir
9.2 Configuração do Modelo Claude
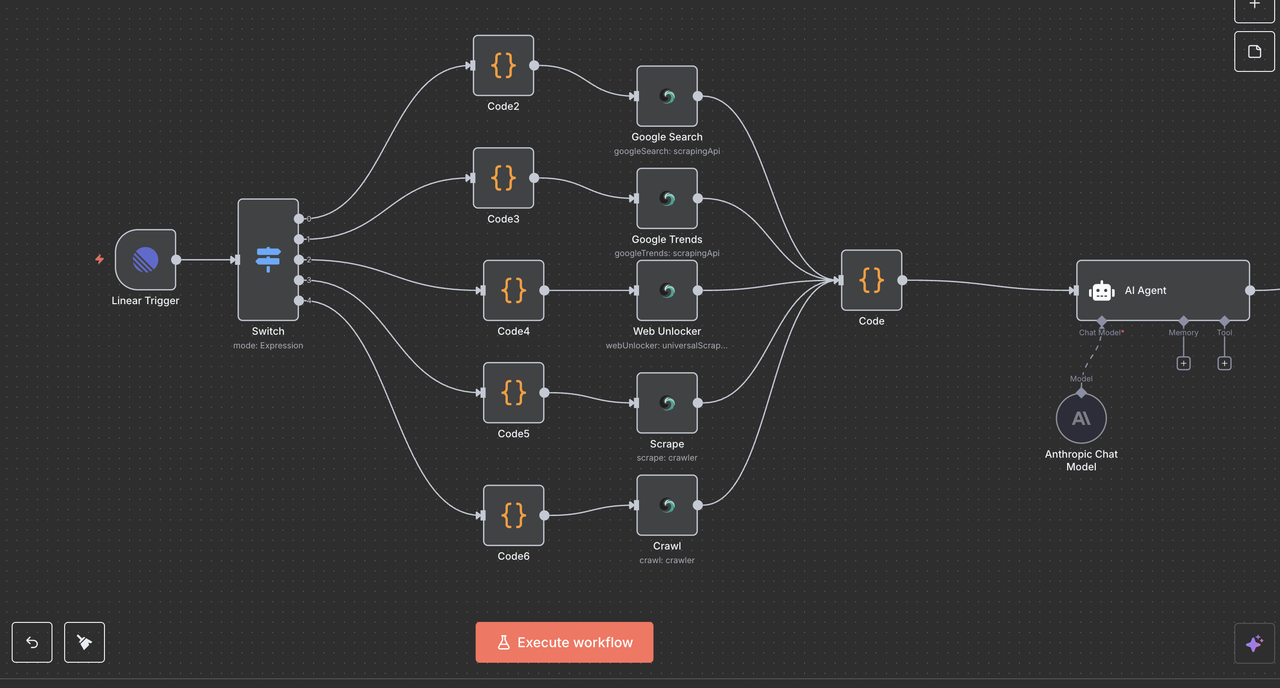
O Nó do Modelo de Chat da Anthropic conecta o Agente AI ao poderoso processamento de linguagem do Claude.
Seleção e Parâmetros do Modelo
- Modelo:
claude-3-7-sonnet-20250219(Claude Sonnet 3.7) - Temperatura:
0.3(equilibrado entre criatividade e consistência) - Máximos Tokens:
4000(suficiente para respostas abrangentes)
Por Que Estas Configurações
- Claude Sonnet 3.7: Um forte equilíbrio entre inteligência, desempenho e custo-eficiência
- Baixa Temperatura (0.3): Garante respostas factuais e repetíveis
- 4000 Tokens: Suficiente para geração de insights profundos sem custo excessivo
Passo 10: Processamento e Limpeza da Resposta
Preparando a Saída do Claude para Comentários Lineares
10.1 Código de Limpeza de Resposta
O Nó de Código após o Claude limpa a resposta da IA para exibição adequada nos comentários Lineares.
Código de Limpeza de Resposta:
// Limpa a resposta da IA do Claude para comentários Lineares
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};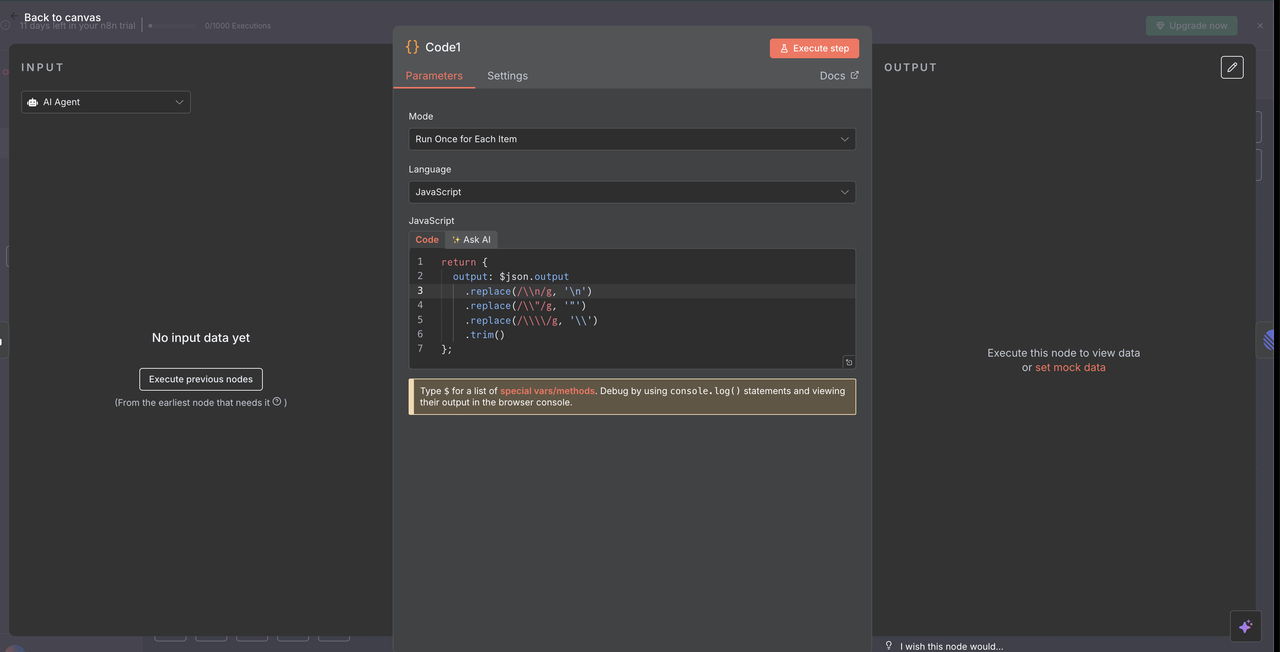
O Que Esta Limpeza Realiza
- Remoção de Caracteres de Escape: Remove caracteres de escape JSON que, de outra forma, seriam exibidos incorretamente
- Correção de Quebras de Linha: Converte strings literais
\nem quebras de linha reais - Normalização de Aspas: Garante que as aspas sejam exibidas corretamente em comentários Lineares
- Remoção de Espaços Desnecessários: Remove espaços em branco iniciais e finais desnecessários
Por Que a Limpeza É Necessária
- A saída do Claude é entregue como JSON, que escapa caracteres especiais
- O renderizador de markdown do Linear requer texto simples formatado corretamente
- Sem este passo de limpeza, a resposta exibiria caracteres de escape brutos, prejudicando a legibilidade
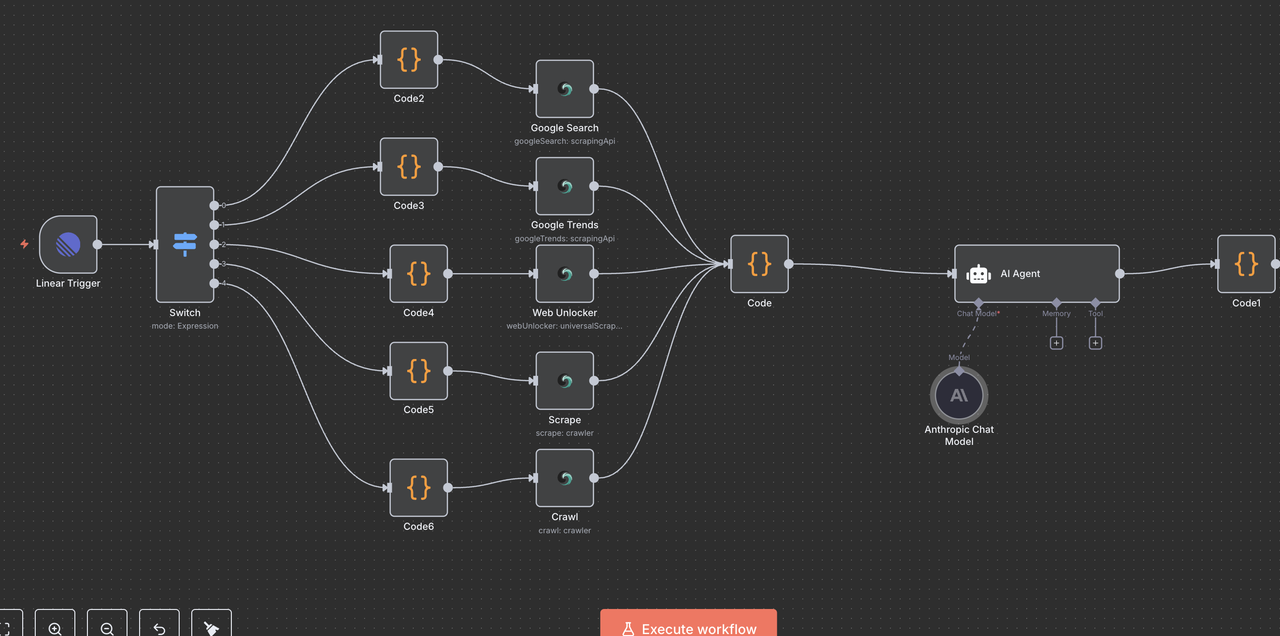
10.2 Entrega do Comentário Linear
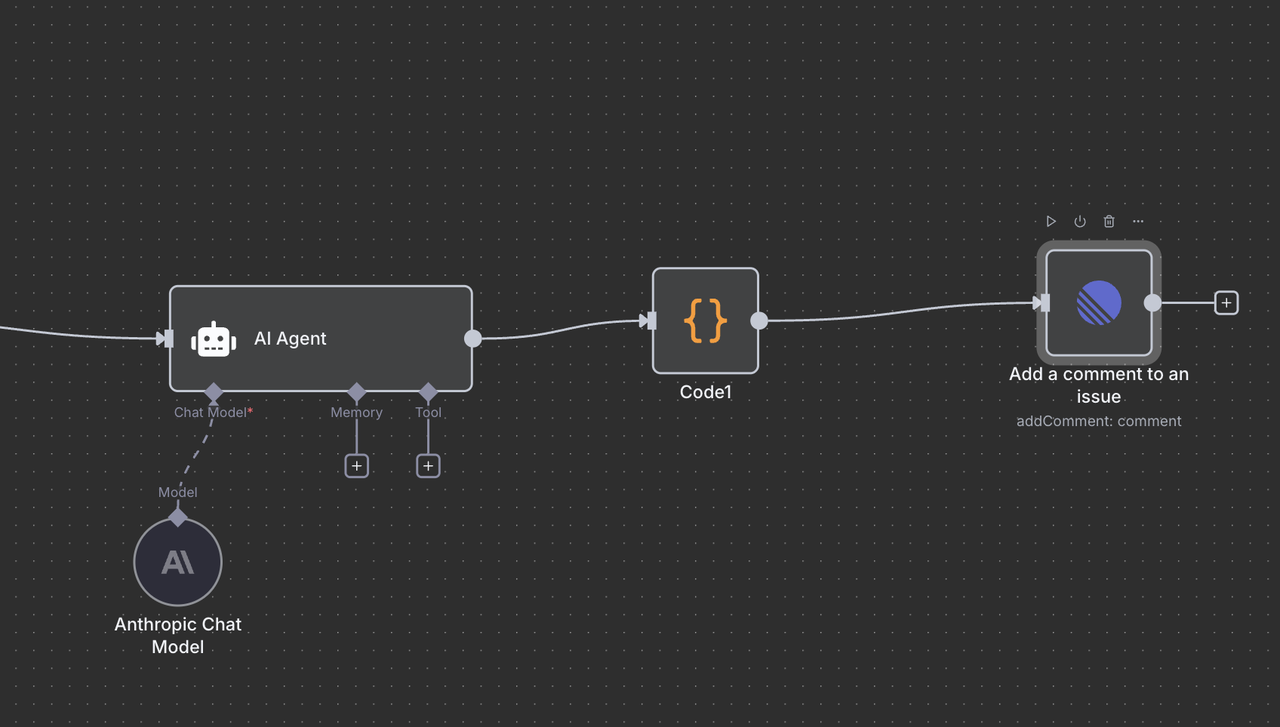
O Nó Linear final publica a análise gerada pela IA como um comentário de volta ao problema original.
Detalhes da Configuração:
- Recurso: Configurado para a operação
"Comentário" - ID do Problema:
{{ $('Linear Trigger').item.json.data.id }} - Comentário:
{{ $json.output }} - Campos Adicionais: Inclua opcionalmente metadados ou opções de formatação
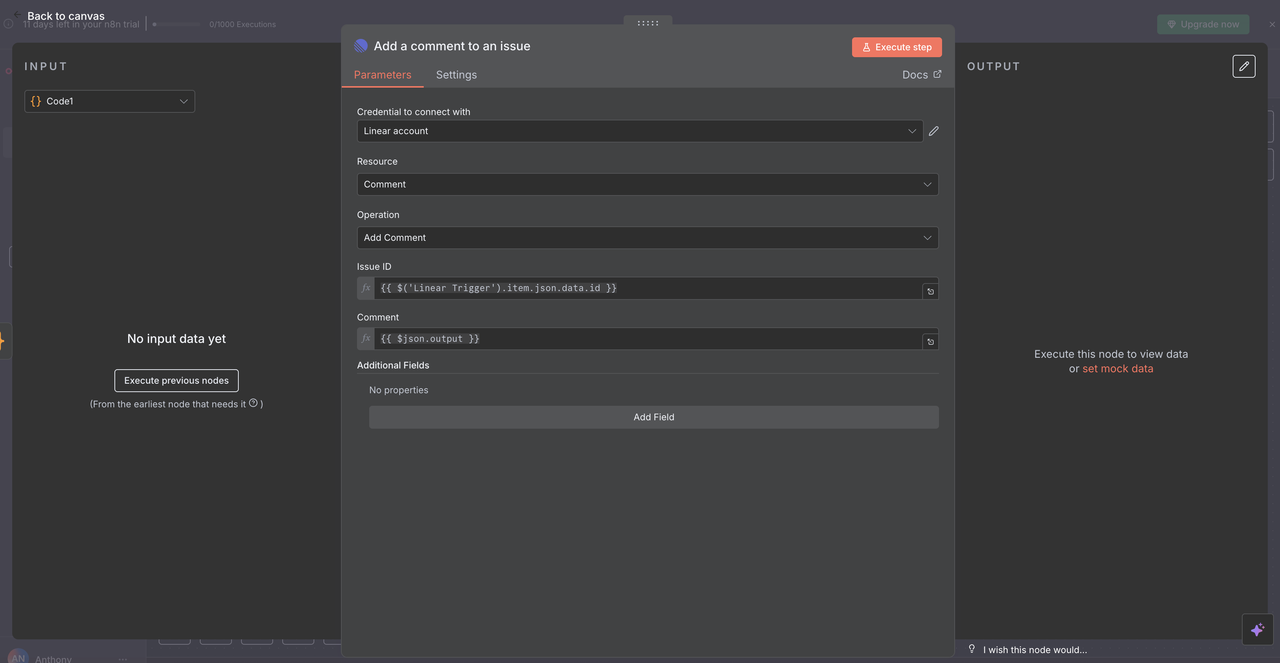
Como o ID do Problema Funciona
- Faz referência ao nó Linear Trigger original
- Usa o exato ID do problema do webhook que iniciou o fluxo de trabalho
- Garante que a resposta da IA apareça no problema Linear correto
O Ciclo Completo
- O usuário cria um problema com
/search competitive analysis - O fluxo de trabalho processa o comando e coleta dados
- Claude analisa os resultados coletados
- A análise é postada de volta como um comentário no mesmo problema
- A equipe vê os insights de pesquisa diretamente em contexto
Passo 11: Testando Seu Assistente de Pesquisa
Valide o Fluxo de Trabalho Completo
Agora que todos os nós estão configurados, teste cada tipo de comando para garantir o funcionamento adequado.
11.1 Teste Cada Tipo de Comando
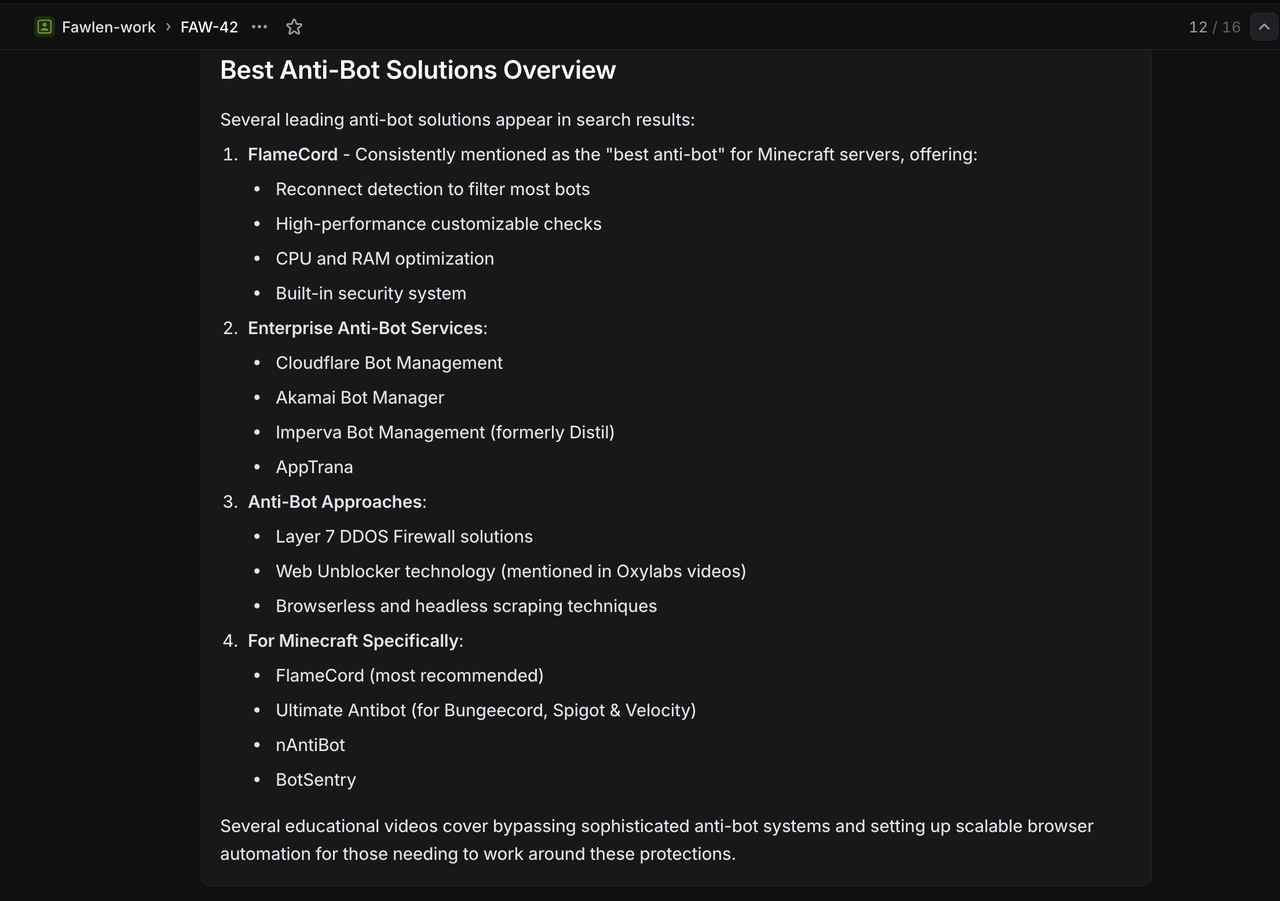
Crie Problemas de Teste no Linear com Estes Títulos Específicos:
Teste de Pesquisa no Google:
`/search competitive analysis for SaaS platforms` Resultado Esperado: Retorna resultados de busca no Google sobre análise competitiva de SaaS
Teste de Tendências do Google:
`/trends artificial intelligence adoption` Resultado Esperado: Retorna dados de tendências mostrando o interesse na adoção de IA ao longo do tempo
Teste de Desbloqueador de Web:
`/unlock https://competitor.com/pricing` Resultado Esperado: Retorna conteúdo de uma página de preços protegida ou pesada em JavaScript
Teste de Scraping:
`/scrape https://news.ycombinator.com` Resultado Esperado: Retorna conteúdo estruturado da página inicial do Hacker News
Teste de Crawling:
`/crawl https://docs.anthropic.com` Resultado Esperado: Retorna conteúdo de várias páginas da documentação da Anthropic
Guia de Resolução de Problemas
Problemas com Webhooks do Linear
- Problema: Webhook não disparando
- Solução: Verifique a URL do webhook e as permissões do Linear
- Verifique: Status do endpoint do webhook n8n
Erros da API do Scrapeless
- Problema: Falhas de autenticação
- Solução: Verifique as chaves da API e os limites da conta
- Verifique: Dashboard do Scrapeless para métricas de uso
Problemas de Resposta do Claude AI
- Problema: Análise pobre ou incompleta
- Solução: Refinar os prompts e o contexto do sistema
- Verificação: Qualidade e formatação dos dados de entrada
Formatação de Comentários Lineares
- Problema: Markdown ou formatação quebrada
- Solução: Atualizar o código de limpeza de respostas
- Verificação: Manipulação de caracteres especiais
Conclusão
A combinação do workspace colaborativo da Linear, da extração de dados confiável da Scrapeless e da análise inteligente do Claude AI cria um poderoso sistema de automação de pesquisa que transforma a maneira como as equipes coletam e processam informações.
Essa integração elimina a fricção entre identificar necessidades de pesquisa e obter insights acionáveis. Basta digitar comandos em questões da Linear, e sua equipe pode acionar fluxos de trabalho abrangentes de coleta e análise de dados que tradicionalmente requereriam horas de trabalho manual.
Principais Benefícios
- ⚡ Pesquisa Instantânea: Da pergunta ao insight em menos de 60 segundos
- 🎯 Preservação de Contexto: A pesquisa permanece conectada às discussões do projeto
- 🧠 Aprimoramento por IA: Dados brutos se tornam inteligência acionável automaticamente
- 👥 Eficiência da Equipe: Pesquisa compartilhada acessível a toda a equipe
- 📊 Cobertura Abrangente: Múltiplas fontes de dados em um fluxo de trabalho unificado
Transforme as capacidades de pesquisa da sua equipe de reativa para proativa. Com a Linear, Scrapeless e Claude trabalhando juntos, você não está apenas coletando dados—está construindo uma vantagem competitiva de inteligência que escala com seu negócio.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


