
O que é impressão digital de navegador e como ela identifica a impressão digital?
Senior Web Scraping Engineer
A impressão digital do navegador é a base para a construção de inteligência de dispositivos, permitindo que empresas identifiquem exclusivamente visitantes de sites em todo o mundo.
Assim como sua impressão digital física é uma combinação absolutamente única de loops, vórtices e arcos, o navegador da web que você usa para se conectar a sites também deixa uma impressão única. No entanto, em vez de loops duplos e arcos em forma de tenda, os navegadores possuem marcadores pessoais, como resolução de tela, WebGL armazenado e configuração de placa de vídeo.
O que é impressão digital de navegador e como ela detecta seu dispositivo e bloqueia a atividade de bots?
Leia este artigo e descubra agora.
O que é Impressão Digital de Navegador?
Impressão digital de navegador é um conjunto de ferramentas e tecnologias que podem capturar dados por meio das atividades de navegação dos usuários da web. Os sites coletam várias informações sobre você, como sistema operacional do usuário, tipo de navegador, resolução de tela, fuso horário, layout do teclado, etc., e esse processo geralmente é feito sem seu conhecimento. Ao processar esses detalhes, ele cria um identificador único ou "impressão digital digital" para cada usuário.
A impressão digital do navegador se parece um pouco com os cookies. Mas eles são diferentes, pois a impressão digital não requer consentimento do usuário e não há uma função de "opt-out", que você pode basicamente ver quando visita um site pela primeira vez com cookies.
Quais dados serão coletados?
As ferramentas de impressão digital do navegador coletam dados do usuário relacionados à configuração de software e hardware do usuário, incluindo:
| ✅ Fontes do sistema | ✅ Se os cookies estão habilitados |
| ✅ Sistema operacional | ✅ Idioma do SO |
| ✅ Sistema operacional | ✅ Idioma do SO |
| ✅ Plataforma | ✅ Atributos de cabeçalho HTTP |
| ✅ Layout do teclado | ✅ Extensões do navegador da web usadas |
| ✅ Navegador Tor ou não | ✅ Análise de contexto de áudio |
| ✅ Navegador seguro ou não | ✅ Classe de CPU |
| ✅ Agente do usuário | ✅ Impressão digital da tela HTML 5 (tamanho da tela) |
| ✅ Bancos de dados locais do navegador | ✅ Suporte de toque |
| ✅ Propriedades do navegador | ✅ Sensores como acelerômetro, proximidade e giroscópio |
Como fui descoberto?
Se você está sendo rastreado ou identificado, é provável que a configuração do seu navegador, plug-ins ou a falta de medidas adequadas de privacidade tenham feito sua impressão digital se destacar. As impressões digitais são especialmente eficazes para usuários:
- Confiam em configurações de navegador exclusivas.
- Usam navegadores altamente personalizados ou desatualizados.
- Deixam de bloquear a coleta de dados de JavaScript ou Canvas.
Para evitar a detecção, considere navegadores focados na privacidade, ferramentas como soluções de navegador anti-detecção, desative plug-ins desnecessários ou aproveite os recursos do navegador que ofuscam os dados de impressão digital.
Como funciona a Impressão Digital do Navegador?
1️⃣ Etapa 1. Coleta de dados
Os sites coletam informações do navegador e do dispositivo do usuário por meio de JavaScript ou outras tecnologias, incluindo tipo de navegador, sistema operacional, resolução de tela, configurações de idioma, fontes, informações de hardware (como GPU) e saída de renderização Canvas/WebGL.
2️⃣ Etapa 2. Atributos combinados
Os múltiplos atributos coletados são integrados a um conjunto de dados, que pode manter a singularidade suficiente mesmo que alguns atributos mudem (como atualizações do navegador).
3️⃣ Etapa 3. Gerar um identificador único
Ao processar esses conjuntos de dados (como cálculos de hash), uma impressão digital única é gerada para identificar o dispositivo e o navegador do usuário.
4️⃣ Etapa 4. Rastreamento entre sessões e sites
Os sites usam as impressões digitais geradas para rastrear os usuários e ainda podem identificar o mesmo usuário mesmo que o usuário limpe os cookies ou ative o modo de privacidade.
Como contornar a Impressão Digital do Navegador?
Scrapeless Scraping Browser é uma maneira eficaz de contornar a impressão digital do navegador. Ele fornece uma plataforma serverless de alto desempenho. Simplifica efetivamente o processo de extração de dados de sites dinâmicos. Os desenvolvedores podem executar, gerenciar e monitorar navegadores sem cabeça sem servidores dedicados, permitindo automação da web e coleta de dados eficientes.
Por que o Scrapeless é especial para web scraping?
O Scrapeless Scraping Browser possui uma rede global que abrange 195 países e mais de 70 milhões de IPs residenciais, um poderoso desbloqueador da web e um solucionador de captcha altamente estável. É ideal para usuários que precisam de uma solução de web scraping confiável e escalável.
Como usar o navegador de scraping Scrapeless?
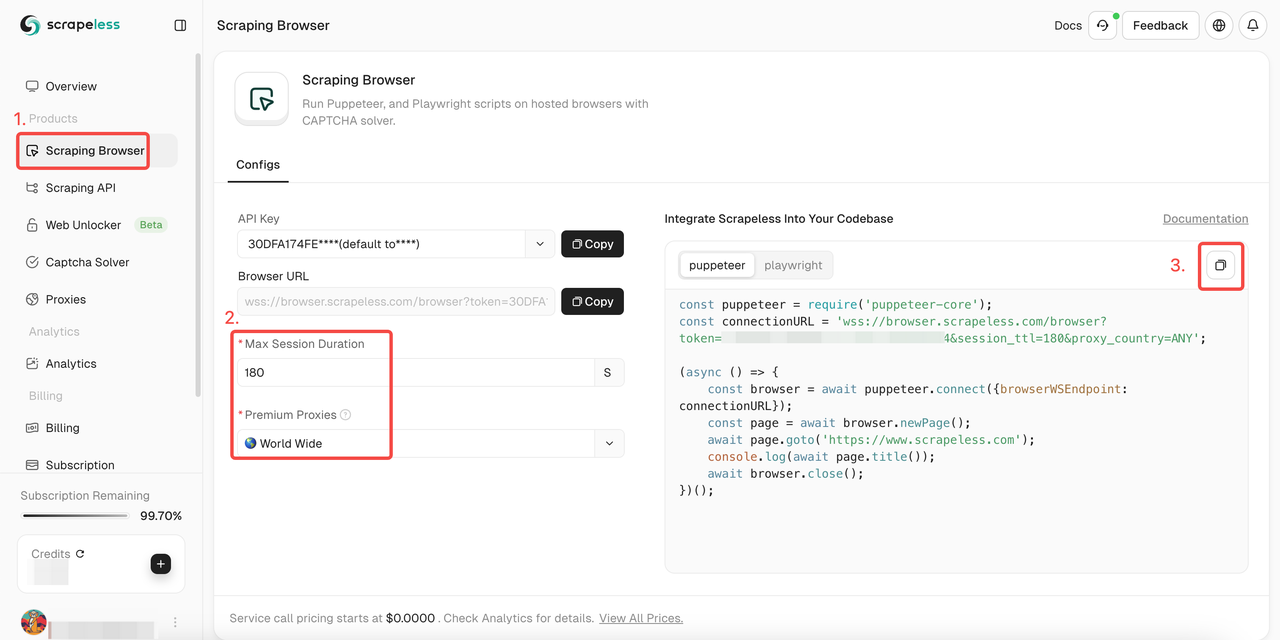
- Etapa 1. Faça login Scrapeless
- Etapa 2. Entre no "Scraping Browser"
- Etapa 3. Defina os parâmetros de acordo com suas necessidades
- Etapa 4. Copie os códigos de amostra para integrar ao seu projeto:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Quer obter mais detalhes? Nosso documento irá ajudá-lo muito!
- Puppeteer:
Instale as bibliotecas necessárias
Primeiro, instale puppeteer-core, uma versão leve do Puppeteer projetada para se conectar a uma instância de navegador existente:
Bash
npm install puppeteer-coreEscreva código para conectar ao navegador de scraping
Em seu código Puppeteer, conecte-se ao Scraping Browser usando o seguinte método:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Dessa forma, você pode aproveitar a infraestrutura do Scraping Browser, incluindo escalabilidade, rotação de IP e acesso global.
Exemplos:
Aqui estão algumas operações Puppeteer comuns após a integração com o Scraping Browser:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Captura de tela
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();- Playwright:
Instale as bibliotecas necessárias
Primeiro, instale playwright-core, uma versão leve do Playwright que se conecta a uma instância de navegador existente:
Bash
npm install playwright-coreEscreva código para conectar ao navegador de scraping
No código Playwright, conecte-se ao Scraping Browser usando o seguinte método:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Isso permite que você aproveite a infraestrutura do Scraping Browser, incluindo escalabilidade, rotação de IP e acesso global.
Exemplos:
Aqui estão algumas operações Playwright comuns após a integração com o Scraping Browser:
- Navegação e extração de conteúdo da página
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Captura de tela
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Executar scripts personalizados
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();7 Técnicas de Impressão Digital do Navegador
1. Impressão digital de Canvas
A impressão digital de Canvas analisa as diferenças na GPU e no driver de gráficos do dispositivo do usuário por meio do elemento Canvas HTML5. O script desenha uma imagem e captura os resultados de renderização do navegador. As diferenças no hardware do dispositivo resultam em renderizações ligeiramente diferentes, e essas características são convertidas em uma "impressão digital de canvas" única.
2. Impressão digital de WebGL
Essa tecnologia usa WebGL para gerar gráficos 3D no navegador do usuário e gera um identificador único para o dispositivo analisando diferenças sutis nos gráficos gerados (causadas pela GPU e pelo driver). Ela depende de uma combinação de hardware e drivers de dispositivo para distinguir com precisão os usuários.
3. Impressão digital de dispositivo de mídia
A impressão digital de dispositivo de mídia gera impressões digitais identificando o hardware de mídia e os dispositivos conectados ao dispositivo do usuário. Embora os usuários sejam obrigados a autorizar o acesso à câmera ou ao microfone, é muito útil para serviços que dependem de dispositivos de mídia (como chamadas de vídeo).
4. Impressão digital TLS
A impressão digital TLS identifica dispositivos analisando a combinação de algoritmos de criptografia usados por dispositivos e servidores ao estabelecer comunicações seguras. Este método usa detalhes na troca de TLS para gerar uma impressão digital de dispositivo única.
5. Impressão digital de fonte
Essa tecnologia usa o conjunto único de fontes instaladas no dispositivo do usuário para gerar uma impressão digital. Ao detectar diferenças de fonte no sistema do usuário, o site pode distinguir entre dispositivos de usuário. Este método é particularmente eficaz para entrega de conteúdo personalizado e identificação do usuário.
6. Impressão digital de dispositivo móvel
A impressão digital de dispositivo móvel usa dados como sistema operacional e resolução de tela para criar um perfil único do dispositivo. Ajuda as plataformas a identificar usuários que retornam e detectar comportamentos anormais do dispositivo e é uma ferramenta importante para otimizar a experiência do usuário e prevenir fraudes.
7. Impressão digital de áudio
A impressão digital de áudio identifica os usuários capturando pequenas diferenças de hardware e software em como os dispositivos geram e processam áudio. Essa tecnologia é amplamente utilizada na gestão de direitos digitais e na entrega de conteúdo de áudio personalizado.
Por que minhas impressões digitais foram coletadas?
- Detecção de fraude. A impressão digital fornece indicadores de alerta precoce para sites que podem estar sujeitos a altos níveis de fraude.
- Criação e recuperação de contas. A impressão digital impede que o mesmo usuário gere/crie muitas contas. Isso evita spam em seu site e oferece maior proteção. Além disso, a correspondência de impressões digitais é uma ferramenta muito útil para verificar a existência de usuários que precisam recuperar suas contas após esquecerem suas informações de login.
- Personalização de conteúdo. A personalização de conteúdo está intimamente relacionada à impressão digital. Anúncios e personalização de páginas da web podem ser construídos com base em seu histórico de uso, guiando você a encontrar coisas que você pensa que quer ver, ouvir ou até mesmo comprar.
Cookies e Impressão Digital do Navegador: diferenças específicas
Os cookies são pequenos pedaços de dados que os sites armazenam em seu dispositivo para lembrar informações sobre sua visita. Eles são transparentes e fáceis de gerenciar, permitindo que os usuários vejam, excluam ou bloqueiem por meio das configurações do navegador. No entanto, as impressões digitais são completamente passivas. Eles coletam dados silenciosamente sem serem armazenados em seu dispositivo ou ter qualquer interação direta com você.
O conteúdo a seguir pode ajudá-lo a ver claramente suas diferenças:
| Recurso | Cookies | Impressão digital |
|---|---|---|
| Persistência | Temporário; pode expirar ou ser excluído manualmente. | Longo prazo: baseado em dados de hardware, software e comportamentais que raramente mudam. |
| Transparência | Requer consentimento do usuário; os usuários podem visualizar, excluir ou bloquear cookies. | Opera silenciosamente, muitas vezes sem o conhecimento do usuário ou opções de opt-out. |
| Rastreamento | Armazenado no dispositivo do usuário, geralmente requer consentimento explícito. | Coleta passiva de dados sem consentimento do usuário. |
| Escopo | Limitado a sites específicos, a menos que explicitamente compartilhado. | Rastreia usuários em sites, sessões, dispositivos e até mesmo redes diferentes. |
| Dificuldade de evasão | Facilmente bloqueado ou gerenciado usando as configurações ou extensões do navegador. | Requer medidas avançadas, como navegadores anti-detecção ou ferramentas especializadas. |
| Divulgação | Divulgado por meio de banners e políticas de privacidade. | Raramente divulgado, tornando difícil para os usuários saberem quando a impressão digital ocorre. |
Considerações Finais
A impressão digital do navegador tornou-se uma ferramenta poderosa, mas controversa, no rastreamento online, combinando tecnologia complexa com problemas profundos de privacidade. Ao contrário do uso de cookies, a impressão digital coleta passivamente dados e resiste às defesas tradicionais de privacidade, como "invisibilidade", tornando-se um método de rastreamento frequente e um tanto invasivo.
Como contornar efetivamente a detecção de impressão digital para alcançar uma coleta e rastreio de dados sem problemas? O Scrapeless Scraping Browser fornece impressão digital de navegador real e rotação inteligente de IP, garantindo resposta rápida e desbloqueio eficiente do site.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


