
Scraping Browser CLI: Web Scraping Primeiro no Terminal para Agentes de IA e Desenvolvedores
Senior Web Scraping Engineer
Principais Conclusões:
- O Scraping Browser CLI revoluciona a extração de dados da web ao oferecer automação de navegador nativa em nuvem diretamente do seu terminal.
- Ele fornece recursos robustos de anti-deteção, proxies residenciais globais e sessões persistentes, superando desafios comuns de scraping na web.
- Integre-se perfeitamente com agentes de IA, capacitando-os a realizar interações complexas na web e coleta de dados com precisão semelhante à humana.
- Descubra técnicas avançadas para manipulação de conteúdo dinâmico, automação de formulários e construção de pipelines de dados sofisticados.
Introdução: A Evolução da Extração de Dados da Web
No mundo orientado a dados de hoje, acessar e interagir com dados da web é primordial para desenvolvedores, cientistas de dados e o crescente campo dos agentes de IA. No entanto, o cenário do web scraping tornou-se cada vez mais complexo. Sites empregam medidas sofisticadas de anti-bot, o carregamento dinâmico de conteúdo requer renderização avançada e gerenciar configurações de automação de navegador local pode ser intensivo em recursos e propenso a falhas. Esses desafios muitas vezes transformam o que deveria ser uma tarefa simples de aquisição de dados em um obstáculo significativo de engenharia.
O Scraping Browser CLI, impulsionado pelo Scrapeless, surge como uma poderosa solução para esses dilemas modernos de web scraping. É uma ferramenta de automação de navegador em nuvem de ponta que permite que você scrape, busque e interaja facilmente com páginas da web usando comandos intuitivos no terminal. Ao descarregar a execução do navegador para uma infraestrutura robusta em nuvem, ela oferece uma experiência contínua e de alto desempenho tanto para desenvolvedores humanos quanto para agentes de IA, garantindo extração de dados confiável e eficiente, sem o ônus da manutenção local ou sobrecarga de infraestrutura.
O que é o Scraping Browser CLI?
O Scraping Browser CLI é uma ferramenta avançada de interface de linha de comando meticulosamente elaborada para automação de navegador em nuvem e integração profunda de agentes de IA. Ao contrário de frameworks convencionais de automação de navegador local, como Puppeteer ou Playwright, que exigem instalações locais do Chrome ou Chromium, este CLI opera inteiramente dentro da infraestrutura em nuvem do Scrapeless. Essa diferença fundamental oferece vantagens incomparáveis em escalabilidade, confiabilidade e gerenciamento de recursos.
Essa abordagem nativa em nuvem significa que você pode executar interações poderosas na web, realizar scraping de dados em larga escala e conduzir testes automatizados sem consumir os recursos computacionais do seu sistema local. Além disso, as habilidades especializadas construídas sobre o Scraping Browser CLI podem conceder aos seus agentes de IA capacidades completas de navegador em nuvem. Isso os capacita a navegar em sites, preencher formulários, clicar em botões e extrair dados exatamente como um usuário humano, completando de maneira contínua várias tarefas de automação na web.
Vantagens Principais: Por que Nativo em Nuvem Importa
O Scraping Browser CLI traz vários benefícios distintos e transformadores para o seu fluxo de trabalho de scraping na web:
- Execução em Nuvem: Todas as operações do navegador são realizadas na nuvem, eliminando completamente a necessidade de configurações de navegador local, gerenciamento de drivers e o consumo de recursos associado.
- Anti-Deteção Inteligente: Possui mecanismos sofisticados de impressão digital de navegador e anti-bot integrados. Isso permite que você navegue suavemente por restrições de sites e CAPTCHAs, imitando o comportamento humano.
- Proxies Globais: Suporte integrado para proxies residenciais globais permite simular acesso de várias localidades geográficas, essencial para extração de dados localizada e contorno de bloqueios geográficos.
- Persistência de Sessão: O gerenciamento avançado de sessão garante a retenção de estado em várias interações, crucial para processos multietapas como logins e submissões complexas de formulários.
- Design Amigável para IA: O CLI utiliza um sistema intuitivo de referência de elementos (como @e1, @e2) para facilitar interações fáceis e robustas para agentes de IA, abstraindo seletores complexos do DOM.
Para obter informações mais detalhadas, você pode explorar a documentação oficial ou visitar o repositório do GitHub.
Recursos e Capacidades: Uma Análise Profunda
O Scraping Browser CLI está repleto de recursos projetados para lidar com os desafios mais exigentes do moderno web scraping. Abaixo, segue uma análise abrangente de suas funcionalidades principais:
| Categoria de Recurso | Descrição |
|---|---|
| Automação de Navegador em Nuvem | Executa todas as operações na nuvem, não exigindo instalação de navegador local, garantindo alto desempenho e escalabilidade. |
| Suporte a Proxies Residenciais | Proxies residenciais globais integrados com direcionamento de geolocalização precisa para acesso localizado a dados. |
| Impressão Digital Inteligente | Impressão digital automatizada de navegador e mecanismos de anti-deteção para contornar sistemas sofisticados de anti-bot. |
| Gerenciamento de Sessões | Suporte abrangente para criar, gerenciar e persistir sessões através de fluxos de trabalho complexos. |
| Interação Amigável com IA | Sistema de referência de elementos (@e1, @e2) projetado especificamente para compatibilidade perfeita com agentes de IA. |
| Capturas de Tela & Extração | Capacidades robustas para capturar capturas de tela de página inteira e extrair conteúdo específico e estruturado. |
| Gravação de Sessão | Suporta gravação de sessões para fins de depuração, auditoria e reprodução. |
Essas funcionalidades fazem dele uma ferramenta altamente versátil, comparável a outras soluções líderes de mercado, mas com uma ênfase pronunciada na integração com agentes de IA e execução nativa na nuvem.
Visão Geral dos Principais Comandos: Seu Kit de Ferramentas de Automação
O CLI fornece uma sintaxe simples e intuitiva para gerenciar sessões e interagir com páginas da web. Aqui estão alguns dos principais comandos que você usará para orquestrar sua automação:
bash
# Gerenciamento de Sessão
scrapeless-scraping-browser new-session # Criar uma nova sessão
scrapeless-scraping-browser sessions # Listar todas as sessões ativas
scrapeless-scraping-browser stop <id> # Parar uma sessão específica
# Navegação de Página
scrapeless-scraping-browser open <url> # Abrir uma página da web
scrapeless-scraping-browser close # Fechar a sessão atual
# Interação com Página
scrapeless-scraping-browser snapshot -i # Obter elementos interativos
scrapeless-scraping-browser click @e1 # Clicar em um elemento específico
scrapeless-scraping-browser fill @e2 "texto" # Preencher um campo de formulário
# Extração de Dados
scrapeless-scraping-browser get text @e1 # Extrair texto de um elemento
scrapeless-scraping-browser screenshot # Capturar uma captura de tela da páginaComeçando: Um Guia Passo a Passo
Configurar o CLI do Scraping Browser é um processo rápido e simples, projetado para que você comece a extrair dados em minutos.
Instalação
O método recomendado é instalar o CLI globalmente usando npm, garantindo que esteja disponível em todo o seu sistema:
bash
npm install -g scrapeless-scraping-browserAlternativamente, você pode executá-lo diretamente sem instalação usando npx para tarefas rápidas e pontuais:
bash
npx scrapeless-scraping-browser open https://example.comObtenha Sua Chave de API
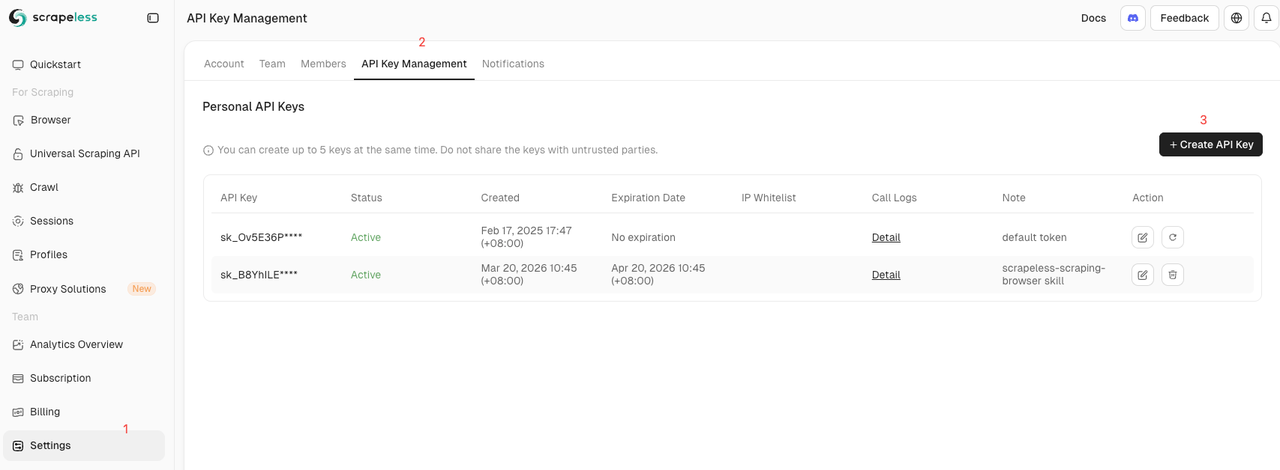
Para autenticar suas solicitações e acessar a infraestrutura em nuvem, você precisa de uma chave de API do Scrapeless:
- Visite o Painel do Scrapeless.
- Faça login ou registre-se para uma nova conta.
- Navegue até a página de configurações da API para gerar e copiar com segurança sua chave de API.
Configurando Autenticação
Você pode configurar suas credenciais de autenticação usando um arquivo de configuração ou variáveis de ambiente, oferecendo flexibilidade para diferentes ambientes de implantação.
Método 1: Arquivo de Configuração (Recomendado para persistência)
bash
scrapeless-scraping-browser config set apiKey sua_chave_api_aquiMétodo 2: Variáveis de Ambiente (Ideal para pipelines de CI/CD)
bash
export SCRAPELESS_API_KEY=sua_chave_api_aquiVocê pode verificar sua configuração executando:
bash
scrapeless-scraping-browser config get apiKey
scrapeless-scraping-browser sessionsExemplo de Fluxo de Trabalho Básico: Orquestrando uma Sessão
Aqui está um fluxo de trabalho simples e fundamental que demonstra como criar uma sessão, interagir com uma página e fechar a sessão de forma limpa:
bash
# Passo 1: Criar uma sessão e salvar o ID da Sessão
SESSION_ID=$(scrapeless-scraping-browser new-session --name "meu-fluxo-de-trabalho" --ttl 3600 --json | jq -r '.taskId')
# Passo 2: Realizar operações no navegador usando o ID da Sessão
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.com
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
scrapeless-scraping-browser --session-id $SESSION_ID click @e1
# Passo 3: Fechar a sessão quando terminar para liberar recursos
scrapeless-scraping-browser --session-id $SESSION_ID close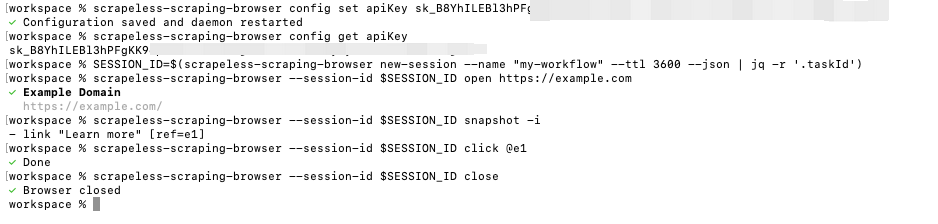
Casos de Uso do Mundo Real: Desde Extração Simples até Automação Complexa
O CLI do Scraping Browser se destaca em vários cenários práticos, escalando desde a extração de dados simples até a orquestração de fluxos de trabalho automatizados complexos.
Extraindo de Qualquer Site: Superando o Básico
Você pode facilmente extrair conteúdo específico de qualquer site-alvo, mesmo aqueles com conteúdo dinâmico:
bash
# Criar sessão
SESSION_ID=$(scrapeless-scraping-browser new-session --name "extração" --ttl 3600 --json | jq -r '.taskId')
# Visitar site-alvo
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# Obter título da página
scrapeless-scraping-browser --session-id $SESSION_ID get title
# Obter conteúdo de um elemento específico
scrapeless-scraping-browser --session-id $SESSION_ID get text "h1"
# Fechar sessão
scrapeless-scraping-browser --session-id $SESSION_ID close
Solicitações Baseadas em Geolocalização: Acesso a Dados Localizados
Se você precisar acessar dados conforme aparecem em um país específico (por exemplo, os Estados Unidos) para pesquisa de mercado ou preços localizados, pode configurar a sessão de acordo:
bash
# Criar uma sessão com direcionamento de geolocalização
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "geo-us" \
--proxy-country US \
--ttl 3600 \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://api.iplook.io
scrapeless-scraping-browser --session-id $SESSION_ID get text "pre"
scrapeless-scraping-browser --session-id $SESSION_ID close
Preenchimento Automático de Formulários: Otimizando Interações
Automatizar processos de login, registro ou formulários de busca complexos é simples com os robustos comandos de interação da CLI:
bash
# Criar sessão
SESSION_ID=$(scrapeless-scraping-browser new-session --name "form-fill" --ttl 3600 --json | jq -r '.taskId')
# Abrir página de login
scrapeless-scraping-browser --session-id $SESSION_ID open https://app.scrapeless.com/passport/login
# Obter elementos interativos
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
# Preencher campos do formulário e enviar
scrapeless-scraping-browser --session-id $SESSION_ID fill @e2 "this_is_email"
scrapeless-scraping-browser --session-id $SESSION_ID fill @e3 "this_is_pwd"
scrapeless-scraping-browser --session-id $SESSION_ID click @e5
Controlando Sessões de Navegador e Gravando: Depuração Facilitada
Para depurar scripts complexos ou monitorar tarefas automatizadas, você pode habilitar a gravação de sessão e interagir com a página em tempo real:
bash
# Criar sessão e habilitar gravação
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "browser-control" \
--recording true \
--ttl 7200 \
--json | jq -r '.taskId')
# Abrir página
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# Obter link de pré-visualização ao vivo
scrapeless-scraping-browser --session-id $SESSION_ID live
# Realizar operações na página
scrapeless-scraping-browser --session-id $SESSION_ID scroll down 500
scrapeless-scraping-browser --session-id $SESSION_ID screenshot page.pngEncadeando Comandos com Pipes Unix: Construindo Pipelines de Dados
A CLI se integra perfeitamente com ferramentas Unix padrão, permitindo que você construa pipelines de dados sofisticados e otimizados diretamente no seu terminal:
bash
# Operações encadeadas para execução eficiente
scrapeless-scraping-browser open https://example.com \
&& scrapeless-scraping-browser wait --load networkidle \
&& scrapeless-scraping-browser snapshot -i
# Salvar captura de tela
scrapeless-scraping-browser screenshot screenshot.pngCustomizando Impressões Digitais de Navegador: Evasão Avançada
Você pode definir agentes de usuário personalizados e outros parâmetros de impressão digital para corresponder a requisitos específicos de scraping e evitar detecções:
bash
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "customer-ua" \
--user-agent "custom_user_agent_string" \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.comCapacitando Agentes de IA: O Futuro da Interação na Web
Uma das características transformadoras do Scraping Browser CLI é sua capacidade de integrar-se perfeitamente aos clientes de Agentes de IA, concedendo-lhes capacidades autênticas e robustas de interação na web. Esta é uma vantagem significativa sobre ferramentas tradicionais, alinhando-se à mudança da indústria em direção a fluxos de trabalho agentes.
Exemplo de Integração: Linguagem Natural para Ação na Web
Você pode instruir seu Agente de IA usando prompts em linguagem natural, e a CLI traduz isso em ações web confiáveis:
bash
USER_PROMPT="Use a habilidade scrapeless-scraping-browser para buscar as informações de preços dos 20 principais fones de ouvido sem fio na Amazon e me diga qual marca tem o menor preço médio."
Agentes de IA Suportados
A CLI é projetada para ampla compatibilidade com vários agentes de IA que suportam extensões de habilidades, incluindo:
- Claude Code
- Cursor
- CodeLlama
- OpenClaw
- E muitos outros frameworks de IA extensíveis que utilizam protocolos como MCP (Protocolo de Contexto do Modelo).
Para saber mais sobre como integrar agentes de IA com Scrapeless e desbloquear essas capacidades, consulte nosso guia abrangente sobre O Melhor Navegador de Scraping em 2026: Scrapeless Lançou o Navegador de Scraping Habilidade OpenClaw.
Opções Avançadas de Configuração: Adaptando Seu Ambiente
Para tarefas complexas de scraping em nível empresarial, a CLI oferece extensos parâmetros de configuração para ajustar seu ambiente.
Opções de Sessão
Você pode configurar meticulosamente o ambiente da sua sessão com várias flags para simular perfis de usuário específicos:
bash
scrapeless-scraping-browser new-session \
--name "sessão-avançada" \
--ttl 7200 \
--recording true \
--proxy-country US \
--proxy-state CA \
--platform macOS \
--screen-width 1440 \
--screen-height 900 \
--timezone "America/Los_Angeles" \
--languages "en,es"Gerenciamento de Configuração
Gerencie suas configurações padrão facilmente para otimizar seu fluxo de trabalho:
bash
# Definir configurações
scrapeless-scraping-browser config set proxyCountry US
scrapeless-scraping-browser config set sessionTtl 3600
# Visualizar todas as configurações
scrapeless-scraping-browser config list
# Obter uma configuração específica
scrapeless-scraping-browser config get apiKeyPor que Escolher Scrapeless? A Vantagem Competitiva
Ao comparar ferramentas CLI de web scraping, a Scrapeless se destaca por oferecer uma solução abrangente e nativa na nuvem que prioriza a integração de IA, uma robusta proteção contra detecção e a experiência do desenvolvedor. Seja construindo um Scraper do Google Maps especializado, monitorando a visibilidade da marca com um Scraper Gemini ou implantando um Servidor MCP, o Scraping Browser CLI oferece a infraestrutura escalável e confiável necessária para o sucesso em 2026 e além.
Conclusão: Eleve Sua Automação Web
O Scraping Browser CLI é uma poderosa ferramenta de automação de navegador em nuvem que transforma paradigmas, equipando desenvolvedores e Agentes de IA com capacidades de interação na web diretas, mas potentes. Desde a extração simples de dados e testes automatizados até o monitoramento complexo da web e fluxos de trabalho autônomos, ele lida com tarefas exigentes com uma facilidade e confiabilidade sem precedentes.
Pronto para Construir Seu Pipeline de Dados Alimentado por IA?
Junte-se à nossa comunidade vibrante para reivindicar um plano gratuito e conectar-se com outros inovadores:
Discord
Telegram
Perguntas Frequentes
P: Preciso instalar um navegador local?
R: Não. O Scraping Browser CLI roda completamente na nuvem, executando todas as operações do navegador na infraestrutura segura e de alto desempenho da Scrapeless.
P: Como ele lida com mecanismos anti-scraping de sites?
R: A CLI possui mecanismos avançados de impressão digital do navegador e proteção contra detecção integrados. Combinados com nossa extensa rede de proxies residenciais, ele efetivamente contorna a maioria das restrições anti-scraping e CAPTCHAs.
P: Quanto tempo dura uma sessão?
R: O tempo limite da sessão padrão é de 180 segundos (3 minutos). Você pode facilmente personalizar essa duração usando o parâmetro --ttl para se adequar a fluxos de trabalho mais longos.
P: Como posso salvar capturas de tela?
R: Use o comando de captura de tela para salvar imagens. Ele suporta tanto capturas de tela de página completa quanto capturas de áreas específicas, perfeito para verificação visual.
P: Quais operações do navegador são suportadas?
R: Ele suporta uma ampla gama de operações comuns, como navegação em páginas, cliques em elementos, preenchimento de formulários, rolagem, espera e captura de telas, cobrindo quase todas as necessidades de interação.
P: Existe uma API programática disponível?
R: Sim, além dos comandos da CLI, a Scrapeless fornece um robusto cliente API TypeScript/Node.js para integração perfeita no código da sua aplicação.
Para mais insights sobre web scraping, automação de IA e técnicas avançadas, explore o Blog da Scrapeless.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


