
5 Melhores Web Crawlers em 2025: Guia Completo para Raspagem de Dados Eficiente
Advanced Data Extraction Specialist
Existem muitos rastreadores web que podem ajudar você a extrair dados, indexar páginas da web ou realizar web scraping automatizado de forma eficiente. No entanto, você pode descobrir que nem todos os rastreadores são igualmente eficazes — alguns têm funcionalidades limitadas, enquanto outros podem ser difíceis de configurar ou consumir muitos recursos. Às vezes, escolher a ferramenta errada pode retardar seu fluxo de trabalho ou até mesmo resultar em bloqueios de IP. Então, como você encontra a certa?
Para resolver esse problema, tudo o que você precisa é do melhor rastreador web que equilibre desempenho, facilidade de uso e escalabilidade. Dito isso, selecionamos e revisamos os 5 melhores rastreadores web que oferecem recursos poderosos para diversas necessidades de scraping. Continue lendo para encontrar aquele que melhor atende às suas necessidades.
| Produto | Facilidade de Uso | Recursos | Ideal para | Tipo | Preço |
|---|---|---|---|---|---|
| Scrapeless | Muito fácil, interface amigável com automação avançada | Tecnologia avançada anti-bloqueio, pool de proxies, extração rápida de dados, suporte a renderização dinâmica, desbloqueio de CAPTCHA, navegador real para anti-detecção | Profissionais e empresas que precisam de scraping de dados de alto desempenho | Baseado em nuvem, scraping em larga escala | A partir de US$ 49/mês, descontos de assinatura disponíveis |
| WebHarvy | Fácil de usar, interface de apontar e clicar | Interface de scraping visual, suporta scraping de imagens, links, texto, agendador para rastreamento automatizado | Pequenas e médias empresas que fazem scraping de dados estruturados | Baseado em desktop, interface gráfica | A partir de US$ 129 |
| OutWit Hub | Facilidade de uso moderada, alguns conhecimentos técnicos necessários | Detecta automaticamente padrões, extrai imagens, links, texto e outros tipos de dados | Usuários que precisam de scraping flexível e personalizável | Baseado em desktop, extensão do navegador | A partir de € 95 |
| ParseHub | Fácil de usar, configuração mínima necessária | Faz scraping de sites dinâmicos, suporta vários formatos de dados, funciona com estruturas web complexas | Usuários que fazem scraping de sites complexos ou dinâmicos | Baseado em desktop, com opções em nuvem | A partir de US$ 189/mês |
| Content Grabber | Moderado, mas recursos poderosos exigem aprendizado | Automação completa, suporta scraping de grandes conjuntos de dados, opções avançadas de exportação de dados | Agências e desenvolvedores que fazem scraping de grandes volumes de dados | Baseado em desktop, suporte a scripts poderosos | De US$ 449 a US$ 2495 |
Agora vamos entrar nos detalhes e discutir essas ferramentas juntamente com alguns conceitos básicos de rastreamento web.
O que é Rastreamento Web?
Rastreamento web é o processo de usar software automatizado para navegar e extrair dados de sites. O software, conhecido como rastreador web ou spider, segue links em um site para coletar dados como texto, imagens e outros conteúdos para uso posterior.
Por que o Rastreamento Web é Importante?
O rastreamento web é essencial para:
- Indexação de mecanismos de busca: Os rastreadores ajudam mecanismos de busca como o Google a indexar páginas da web para melhores resultados de pesquisa.
- Pesquisa de mercado: As empresas usam rastreadores para monitorar preços da concorrência, detalhes de produtos e tendências.
- Coleta de dados: Ajuda a coletar grandes conjuntos de dados para análise, aprendizado de máquina e insights.
- Eficiência: Automatiza a coleta de dados, economizando tempo e recursos.
Como Rastrear Dados?
Para rastrear dados, siga estas etapas:
Selecione sites alvo: Identifique os sites dos quais você deseja coletar dados.
Configure um rastreador: Use ferramentas ou scripts personalizados para automatizar o processo.
Extraia dados: Defina quais dados você precisa e configure o rastreador.
Armazene dados: Salve as informações extraídas em um formato estruturado para análise.
Tecnologia de Rastreamento Web
Os rastreadores web usam várias tecnologias como:
- Análise HTML: Extrai dados do HTML de uma página da web.
- Rastreamento de API: Usa APIs para recuperação de dados estruturados.
- Navegadores sem cabeça: Ferramentas como o Puppeteer ajudam a extrair dados de sites com muito JavaScript.
- Proxies e solução de CAPTCHA: Impede bloqueios girando IPs e contornando medidas de segurança.
O que é um Rastreador Web?
Um rastreador web é um programa automatizado projetado para coletar e replicar dados da web. Em quase todos os setores, empresas e organizações acabam precisando extrair dados para vários casos de uso.
No entanto, os rastreadores web não são apenas programas simples para copiar informações em massa. Eles devem ser poderosos o suficiente para extrair dados de várias fontes e imitar inteligentemente o comportamento humano para garantir a extração de dados sem serem bloqueados.
Por que usar um Rastreador Web?
Quando se trata de extração de dados em larga escala, o scraping online manual é impraticável. Além disso, a automação ajuda a definir algoritmos rígidos e evita ambiguidades. Usar um rastreador web oferece as seguintes vantagens em relação aos métodos manuais:
- Maior precisão: Os rastreadores automatizados garantem que os dados sejam coletados de forma consistente, sem erros humanos.
- Rentabilidade: Reduz os custos associados à entrada manual de dados.
- Controle sobre os dados: Você pode definir especificamente quais dados precisam ser extraídos.
- Eficiência de tempo: Os rastreadores web podem economizar uma quantidade significativa de tempo no processo de extração, tornando viável a coleta de dados em larga escala.
Para garantir que recomendamos apenas os rastreadores web mais eficazes, realizamos os seguintes testes:
| Critério | Detalhes |
|---|---|
| 🎉 Número testado | 10+ rastreadores web, incluindo ferramentas de código aberto e comerciais |
| 👀 O que rastreadores | Sites de comércio eletrônico, portais de notícias, plataformas de mídia social e bancos de dados estruturados |
| 😎 O que valorizamos | Preço, velocidade de rastreamento, recursos anti-detecção, simulação de navegador real, suporte a proxy e facilidade de uso |
1. Scrapeless ★★★
Preço: A partir de US$ 49/mês
Ideal para: Empresas e desenvolvedores que precisam de uma solução avançada e eficiente para scraping da web em larga escala
O Scrapeless é um dos melhores rastreadores web disponíveis no mercado atualmente, oferecendo uma solução completa para lidar com medidas anti-bloqueio enquanto extrai dados de sites de forma eficiente.
Com o Scrapeless, você pode extrair dados de uma ampla variedade de sites, incluindo plataformas de comércio eletrônico, pesquisa de mercado e mídia social. Ele se destaca ao contornar desafios de CAPTCHA, usando simulações de navegador real para anti-detecção e gerenciando conteúdo dinâmico com o qual outros rastreadores costumam ter dificuldades.
A tecnologia anti-bloqueio da ferramenta inclui recursos como um rico pool de IPs proxy, desbloqueio rápido de CAPTCHA e falsificação de impressão digital TLS, garantindo que suas atividades de scraping sejam indetectáveis e seguras contra bloqueios de IP. O Scrapeless também é conhecido por sua capacidade de extrair dados de páginas com muito JavaScript, tornando-o ideal para sites modernos e complexos. É uma solução poderosa para empresas que precisam de extração de dados em larga escala sem o risco de detecção.
Mais vantagens:
- Scrapeless: A partir de US$ 49/mês para acesso total às suas APIs de scraping da web.
- API do Google SERP : O preço da API do Google SERP é tão baixo quanto US$ 0,3 por 1.000 consultas, o que é muito acessível para pesquisas frequentes. Ele também cobre mais de 30 tipos de resultados de pesquisa, como resultados de IA, gráficos de conhecimento, notícias locais, resultados de anúncios, resultados do Twitter, etc.
- API de scraping do Google Trends: Entrega dados em apenas 2 segundos, oferecendo acesso rápido a dados de tendências.
Como usar a API de scraping do Scrapeless para extrair dados
Extrair dados com o Scrapeless é fácil e eficiente. Você pode começar seguindo estas etapas:
-
Cadastre-se para uma conta: Visite o site do Scrapeless e cadastre-se para uma conta.
-
Selecione a API de scraping para seu cenário: Você pode selecionar a API de scraping de que precisa à esquerda
Ou você pode configurar uma integração de API para integrar nossa ferramenta ao seu fluxo de trabalho, seja você usando Python, Node.js ou outras linguagens de programação. Você pode consultar a documentação da API do Scrapeless.
- Defina o destino de rastreamento: Selecione o site a ser rastreado e configure as configurações de rastreamento necessárias. Aqui, usamos o Google Flights como exemplo.
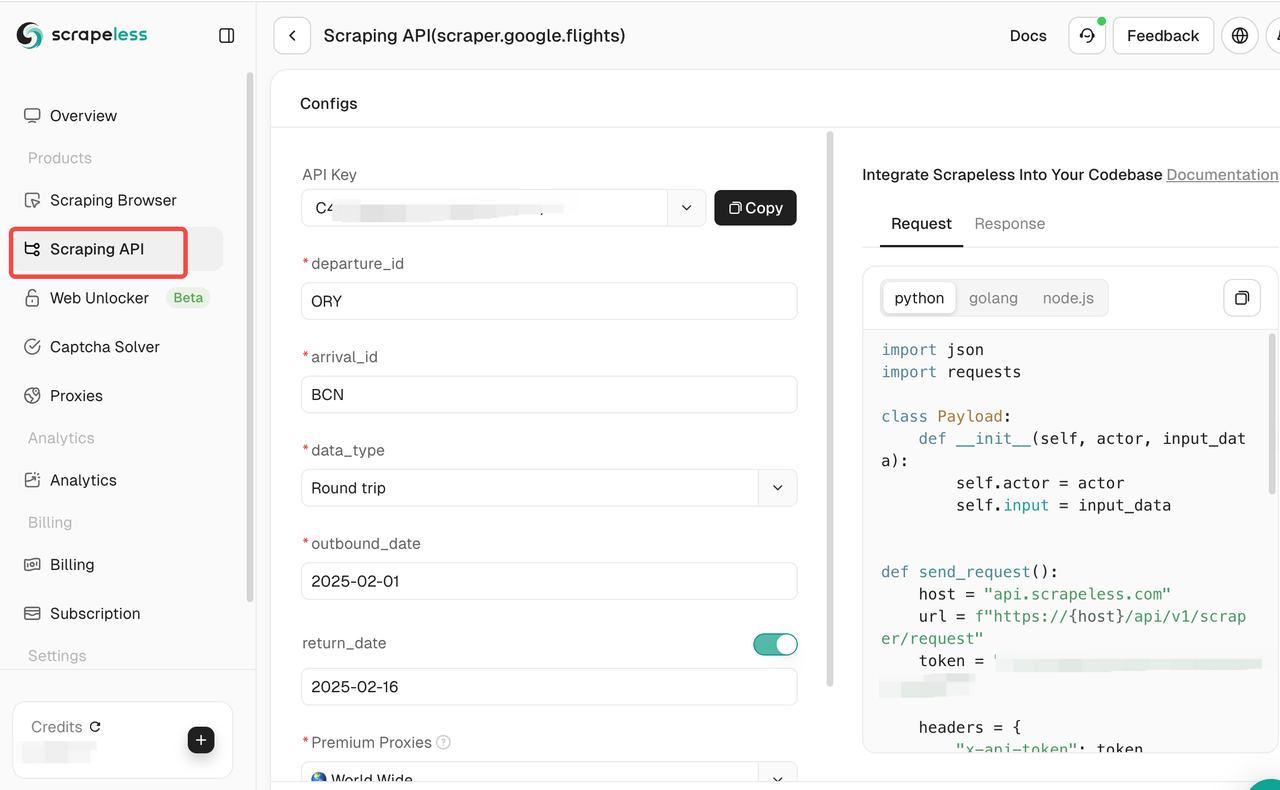
Clique em API de scraping, selecione Google Flight e defina os requisitos de scraping correspondentes.
- Comece a extrair dados: Clique em Iniciar scraping para iniciar a extração de dados e os resultados da extração aparecerão à direita.
2. WebHarvy
Preço: A partir de US$ 129
Ideal para: Usuários que procuram uma solução de scraping simples de apontar e clicar
O WebHarvy é um rastreador web fácil de usar, perfeito para iniciantes. Sua interface visual de apontar e clicar torna o scraping direto, sem precisar escrever uma única linha de código. Embora não tenha os mesmos recursos avançados anti-bloqueio do Scrapeless, é excelente para extrair dados de produtos de sites de comércio eletrônico e blogs.
Prós:
- Facilidade de uso: Interface amigável que não requer conhecimento de codificação
- Scraping visual de apontar e clicar: Extrai dados sem ter que aprender configurações complexas
- Bom para sites de comércio eletrônico: Ótimo para extrair listagens de produtos, imagens e preços
Contras:
- Recursos anti-bloqueio limitados: Vulnerável a restrições de scraping em sites com tráfego intenso
- Escalabilidade limitada: Não funciona bem para projetos de scraping em larga escala e alta frequência
3. OutWit Hub
Preço: A partir de € 95
Ideal para: Iniciantes que precisam de um scraper simples baseado em navegador
O OutWit Hub é um rastreador web baseado em extensão de navegador que permite extrair links, emails, imagens e muito mais. É excelente para iniciantes e tarefas pequenas de scraping, mas pode não ser a melhor escolha para casos de uso avançados que exigem scraping complexo ou tratamento de páginas com muito JavaScript.
Se você também encontrou o desafio do JS, pode clicar para verificar este tutorial: Como contornar o desafio do Cloudflare
Prós:
- Integração do navegador: Simples de instalar e usar diretamente no seu navegador
- Interface fácil de usar: Ideal para iniciantes sem experiência em codificação
- Flexibilidade: Permite extrair vários tipos de dados, como links, imagens e texto
Contras:
- Falta recursos avançados: Falta suporte para lidar com conteúdo dinâmico ou scraping de alto volume
- Escalabilidade limitada: Mais adequado para scraping leve do que para projetos grandes ou complexos
4. ParseHub
Preço: A partir de US$ 189 por mês
Ideal para: Usuários avançados que precisam extrair conteúdo dinâmico
O ParseHub é um rastreador web avançado que se destaca ao extrair sites com muito JavaScript. Ele fornece um conjunto mais robusto de recursos para lidar com sites complexos, mas o alto preço e a complexidade podem desencorajar usuários menos experientes. Ele oferece uma interface visual, mas é mais complexo que o WebHarvy.
Prós:
- Suporta sites dinâmicos: Excelente para extrair sites com muito JavaScript
- Interface visual: Permite criar projetos de scraping sem codificação
- Recursos avançados: Fornece opções para agendamento e automação de tarefas de scraping
Contras:
- Preço: Caro para usuários casuais ou em pequena escala
- Curva de aprendizado íngreme: Recursos mais avançados podem ser demais para iniciantes
- Desempenho mais lento: Não tão rápido quanto o Scrapeless para tarefas de scraping grandes
5. Content Grabber
Preço: De US$ 449 a US$ 2495
Ideal para: Soluções de scraping em nível empresarial
O Content Grabber é um rastreador web repleto de recursos, projetado para tarefas de web scraping em larga escala, especialmente para usuários em nível empresarial. É ótimo para scraping de dados estruturados em vários sites, mas o preço alto e a configuração avançada podem ser demais para usuários casuais.
Prós:
- Altamente personalizável: Adequado para extrair grandes conjuntos de dados e lidar com fluxos de trabalho complexos
- Recursos avançados: Suporta APIs, rotação de proxy e solução de CAPTCHA
- Ótimo para uso empresarial: Ideal para extração de dados de alto volume
Contras:
- Alto custo: O preço pode ser proibitivo para pequenas empresas ou indivíduos
- Complexidade: Requer tempo e esforço para aprender e configurar de forma eficaz
- Excesso para projetos pequenos: Mais adequado para operações em larga escala
FAQ sobre rastreadores web
1. Qual a diferença entre web scraping e rastreamento web?
Resposta: Embora tanto o web scraping quanto o rastreamento web envolvam a extração de informações da web, eles servem a propósitos diferentes. O rastreamento web concentra-se principalmente em descobrir e indexar conteúdo em vários sites. É usado por mecanismos de busca para mapear a estrutura da web. Por outro lado, o web scraping refere-se ao ato de extrair dados específicos de um site — como detalhes do produto, preços ou informações de contato — usando uma ferramenta de scraping. O scraping geralmente é mais direcionado e projetado para coletar dados acionáveis, enquanto o rastreamento trata de coletar e indexar conjuntos maiores de dados na web.
2. Como funciona o web scraping?
Resposta: O web scraping funciona usando software ou scripts automatizados (rastreadores web) para extrair dados de sites. O processo envolve enviar solicitações a um site, recuperar o conteúdo HTML e analisá-lo para extrair informações úteis, como texto, imagens, links e muito mais. Rastreadores avançados como o Scrapeless podem lidar com sites dinâmicos, contornar medidas anti-scraping e exportar dados em vários formatos para análise posterior.
3. Posso usar um rastreador web para extrair sites dinâmicos?
Resposta: Sim, muitos rastreadores web modernos, incluindo Scrapeless e ParseHub, são projetados para lidar com sites dinâmicos. Esses rastreadores podem renderizar JavaScript e interagir com sites como um navegador real faria, tornando possível extrair dados de páginas que carregam conteúdo dinamicamente. O Scrapeless, em particular, fornece recursos como tecnologia anti-detecção e extração rápida de dados, garantindo que o conteúdo dinâmico seja extraído com precisão e eficiência.
Considerações finais
No geral, escolher o melhor rastreador web para scraping de dados em 2025 é essencial para maximizar sua eficiência. Embora ferramentas como WebHarvy, OutWit Hub e ParseHub sejam boas opções, o Scrapeless assume a liderança com sua interface amigável, recursos avançados e preços competitivos (apenas US$ 49 por mês). Além disso, você pode experimentar o Scrapeless gratuitamente para explorar seus recursos.
Não perca a oportunidade de entrar na comunidade Scrapeless Discord, entre no Discord do Scrapeless e entre em contato com as vendas para solicitar sua avaliação gratuita!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


