
5 Melhores Scrapers da Amazon em 2026: A Ferramenta Definitiva para Ampliar a Inteligência em E-commerce
Expert in Web Scraping Technologies
Principais Pontos
- As defesas contra bots da Amazon evoluíram para incluir impressão digital TLS e análise comportamental, tornando APIs especializadas essenciais.
- A escolha do scraper certo depende de sua pilha técnica: Scrapeless e ScraperAPI são melhores para desenvolvedores, enquanto Octoparse atende usuários não técnicos.
- A extração de dados da Amazon é crucial para precificação dinâmica, monitoramento de concorrentes e análise de sentimentos no cenário de varejo de 2026.
- Scrapeless lidera o mercado em 2026 com uma taxa de sucesso >95%, oferecendo suporte exclusivo para Anúncios Patrocinados da Amazon e extração de dados Rufus AI.
Introdução
No dinâmico mundo do e-commerce, a Amazon se destaca como um titã indiscutível, um vasto oceano de produtos, preços e valiosas percepções do consumidor. Para empresas, pesquisadores e desenvolvedores, a capacidade de navegar e extrair dados de maneira eficaz deste colossal marketplace não é apenas uma vantagem—é uma necessidade. Desde o monitoramento das estratégias de precificação dos concorrentes até a análise de tendências de produtos e compreensão do sentimento dos clientes, os dados da Amazon alimentam a tomada de decisões informadas e o crescimento estratégico. No entanto, a escala imensa e os sofisticados mecanismos anti-scraping empregados pela Amazon tornam a coleta manual de dados uma tarefa árdua, senão impossível. É aqui que os scrapers da Amazon se tornam ferramentas indispensáveis, automatizando o processo de extração e transformando dados brutos da web em inteligência acionável.
Este guia abrangente explora os 5 melhores scrapers da Amazon em 2026, oferecendo uma comparação detalhada para ajudá-lo a escolher a ferramenta perfeita para suas necessidades específicas. Vamos explorar suas principais características, avaliar seus pontos fortes e fracos e fornecer insights sobre seus modelos de precificação. Se você é um profissional de dados experiente ou está apenas começando sua jornada na coleta de dados da web, este artigo irá equipá-lo com o conhecimento para aproveitar efetivamente o poder dos dados da Amazon. Também destacaremos como Scrapeless, com suas capacidades avançadas, como o Web Unlocker e extração de dados especializada para Anúncios Patrocinados e dados Rufus, se destaca neste cenário competitivo.
Por Que Raspar Dados da Amazon?
As motivações para raspar dados da Amazon são tão diversas quanto os produtos listados em sua plataforma. Para as empresas, os insights obtidos podem ser transformadores. Aqui estão algumas razões principais pelas quais a extração de dados da Amazon é crucial em 2026:
- Pesquisa de Mercado e Análise de Tendências: Ao coletar dados sobre popularidade de produtos, categorias e nichos emergentes, as empresas podem identificar lacunas no mercado e capitalizar novas oportunidades. Compreender o que está em alta permite uma gestão proativa de inventário e desenvolvimento de produtos.
- Monitoramento de Concorrentes: Ficar de olho nas listagens de produtos, preços, promoções e avaliações de clientes dos concorrentes é vital. Os scrapers da Amazon permitem que as empresas monitorem esses métricas em tempo real, permitindo ajustes ágeis em suas próprias estratégias. Isso inclui monitorar como os concorrentes utilizam Anúncios Patrocinados para ganhar visibilidade.
- Inteligência de Preços e Otimização: As flutuações de preços na Amazon são constantes. A raspagem permite um acompanhamento contínuo de preços, possibilitando estratégias dinâmicas de precificação que maximizam a competitividade e lucratividade. Isso é particularmente importante para varejistas que buscam manter uma vantagem competitiva.
- Desenvolvimento e Melhoria de Produtos: Analisar avaliações e classificações de clientes fornece feedback inestimável sobre o desempenho do produto, recursos desejados e pontos problemáticos comuns. Esses insights diretos do consumidor podem orientar melhorias de produtos e informar a criação de novas ofertas.
- Gestão da Cadeia de Suprimentos e Inventário: Ao monitorar os níveis de estoque de produtos populares, as empresas podem antecipar a demanda, otimizar sua cadeia de suprimentos e prevenir faltas de estoque ou excessos. Essa abordagem proativa garante eficiência operacional.
- Gestão da Reputação da Marca: Monitorar menções e avaliações da sua marca e produtos na Amazon ajuda a identificar e abordar rapidamente feedback negativo, protegendo a imagem da sua marca. Isso também se estende ao entendimento do impacto dos dados Rufus na visibilidade e vendas de produtos.
Principais Características a Procurar em um Scraper da Amazon
Escolher o scraper certo da Amazon envolve mais do que apenas encontrar uma ferramenta que possa extrair dados. A eficácia e eficiência das suas operações de scraping dependem fortemente de várias características chave. Ao avaliar soluções potenciais, considere o seguinte:
- Alta Taxa de Sucesso: A Amazon emprega medidas sofisticadas anti-bot. Um scraper confiável deve ter uma alta taxa de sucesso em contornar essas defesas, garantindo a entrega consistente de dados sem bloqueios frequentes ou CAPTCHAs. Isso geralmente envolve um gerenciamento avançado de proxies e rotação de IPs.
- Gerenciamento e Rotação de Proxies: Para evitar banimentos de IP e garantir um scraping contínuo, o scraper deve oferecer um gerenciamento robusto de proxies, incluindo uma grande quantidade de endereços IP diversos e rotação automática. Isso é crucial para manter a anonimidade e contornar geo-restrições.
- Tratamento de CAPTCHA: CAPTCHAs são um obstáculo comum no web scraping. Um scraper eficaz da Amazon deve ter capacidades integradas para resolver ou contornar automaticamente vários tipos de CAPTCHA, minimizando interrupções no seu fluxo de dados. O Web Unlocker da Scrapeless foi projetado precisamente para este fim.
- Renderização de JavaScript: Muitos sites modernos, incluindo a Amazon, dependem fortemente do JavaScript para carregar conteúdo dinamicamente. Um scraper capaz deve conseguir renderizar JavaScript para acessar todos os dados relevantes, não apenas o HTML inicial. Ferramentas como o Scraping Browser são essenciais para isso.
- Parse e Estruturação de Dados: HTML bruto raramente é útil. Os melhores scrapers podem parsear os dados extraídos em formatos estruturados como JSON, CSV ou Excel, facilitando a análise e integração em seus sistemas. Procure ferramentas que ofereçam parsers pré-construídos para pontos de dados comuns da Amazon.
- Facilidade de Uso e Integração: Seja você preferindo uma solução sem código ou uma API altamente personalizável, o scraper deve ser amigável ao usuário e oferecer integração simples com seus fluxos de trabalho existentes. A documentação e o suporte também são considerações importantes.
- Escalabilidade: Suas necessidades de dados podem crescer. O scraper escolhido deve ser capaz de escalar com seus requisitos, lidando com volumes crescentes de solicitações e dados sem comprometer o desempenho ou a confiabilidade.
- Modelo de Preços: Entenda a estrutura de preços—se é baseada em solicitações, volume de dados ou assinatura. Compare custos entre diferentes fornecedores para encontrar uma solução que se alinhe ao seu orçamento e padrões de uso.
Tabela de Comparação: 5 Melhores Scrapers da Amazon em 2026
| Nome do Scraper | Recursos Principais | Prós | Contras | Modelo de Preço | Melhor Para |
|---|---|---|---|---|---|
| Scrapeless | Alta velocidade e maior taxa de sucesso, campos de dados amplos - Dados de Anúncios Patrocinados e Dados de Rufus disponíveis, bypass anti-bot com inteligência artificial, rede de proxy global | Alta taxa de sucesso, lida com medidas complexas anti-bot, extração especializada de dados da Amazon, API flexível | Requer alguma configuração técnica para recursos avançados | Pagamento conforme o uso/Assinatura (opcional; apenas cobrança por solicitações bem-sucedidas) | Empresas que precisam de extração de dados da Amazon altamente confiável, escalável e especializada |
| ScraperAPI | Endpoint de Dados Estruturados, DataPipeline, 40M+ IPs, Geotargeting, tratamento de CAPTCHA | Fácil de usar, alta taxa de sucesso, bom para dados estruturados | Exportação CSV limitada, alguns parâmetros ainda em desenvolvimento | Baseado em assinatura (créditos da API) | Desenvolvedores e empresas que buscam uma API robusta e fácil de usar para dados estruturados da Amazon |
| Bright Data | Extensa rede de proxies (residenciais, de datacenter, ISP), IDE de Web Scraper, coletores de dados pré-construídos, desbloqueador | Maior rede de proxies, altamente personalizável, IDE poderosa, bom para projetos de grande escala | Pode ser complexo para iniciantes, custo mais alto para uso extensivo | Baseado em uso (tráfego, solicitações, dados) | Empresas e usuários avançados com necessidades complexas de scraping em grande escala |
| ScrapingBee | Renderização de JavaScript, rotação de proxies, geo-targeting, integra-se com várias linguagens | API simples, boa para scraping geral da web, preços razoáveis | Pode exigir mais parseamento personalizado para dados complexos da Amazon | Baseado em solicitações | Desenvolvedores e pequenas a médias empresas precisando de uma API simples para scraping geral da web, incluindo Amazon |
| Octoparse | Construtor visual de scraper da web, modelos prontos para uso, rotação de IP, serviço em nuvem | Solução sem código, fácil para iniciantes, interface visual | Pode ser intensivo em recursos para execuções locais, cobranças extras para recursos avançados | Baseado em assinatura (tarefas, dados em nuvem) | Iniciantes e usuários não técnicos que preferem um enfoque visual e sem código para scraping da Amazon |
Avaliação Detalhada de Cada Scraper
1. Scrapeless: A Escolha Inteligente para Dados da Amazon
Scrapeless surge como uma solução líder para extração de dados da Amazon em 2026, especialmente para aqueles que exigem alta confiabilidade, capacidades avançadas de contorno de bot e pontos de dados especializados. Nossa plataforma é projetada para enfrentar as defesas mais formidáveis da Amazon, garantindo que você receba dados consistentes e precisos.
Principais Recursos e Vantagens do Scrapeless:
- Rede Global de Proxies: Apoiado por uma rede de proxies residenciais robusta e diversificada, o Scrapeless garante que suas solicitações de scraping pareçam legítimas, minimizando o risco de proibições de IP e restrições geográficas. Nossos proxies são otimizados para desempenho e confiabilidade, essenciais para operações de scraping sustentadas na Amazon.
- API Flexível: O Scrapeless oferece uma API poderosa e flexível que se integra perfeitamente à sua infraestrutura existente, permitindo fluxos de trabalho personalizados de extração de dados e entrega de dados em tempo real.
- Detecção Avançada: Contorna automaticamente Cloudflare, reCAPTCHA e DataDome enquanto imita o comportamento humano para evitar bloqueios.
- Extração de Dados de Anúncios Patrocinados: Uma vantagem única do Scrapeless é sua capacidade de direcionar e extrair dados especificamente dos Anúncios Patrocinados da Amazon. Isso fornece insights incomparáveis sobre estratégias de publicidade de concorrentes, lances de palavras-chave e visibilidade de produtos, oferecendo uma vantagem significativa na análise de mercado.
- Integração de Dados do Rufus: Com o crescimento dos assistentes de compra impulsionados por IA, como o Rufus da Amazon, entender os dados que influenciam esses sistemas é crucial. O Scrapeless está na vanguarda da extração e análise de dados do Rufus, oferecendo insights sobre como os produtos estão sendo apresentados e recomendados pela IA, o que pode ser um divisor de águas para otimização de produtos e marketing.
- Teste gratuito disponível: Novos usuários podem se juntar à comunidade oficial do Scrapeless para reivindicar créditos de teste (até 3.000 solicitações):
Discord
Telegram
Prós:
- Taxa de sucesso excepcional contra as medidas anti-bot da Amazon.
- Extração especializada de dados de Anúncios Patrocinados e Rufus, oferecendo insights de mercado exclusivos.
- Manuseio automatizado de CAPTCHA e tentativas de nova tentativa com Web Unlocker.
- Capacidades completas de renderização JavaScript com Scraping Browser.
- Escalável e confiável para extração de dados em grande volume.
- Documentação abrangente e suporte.
Contras:
- Pode exigir alguma configuração técnica inicial para otimização.
- Não é uma solução sem código, requer conhecimento básico de programação para integração de API.
Preços: O Scrapeless opera com um modelo baseado em uso, onde você paga apenas por solicitações bem-sucedidas e pelo volume de dados extraídos. Isso garante eficiência de custos e está alinhado ao valor recebido.
2. ScraperAPI: Extração Simplificada de Dados da Amazon
ScraperAPI é uma escolha popular para desenvolvedores em busca de uma solução direta, mas poderosa, para extração de dados da Amazon. Ele simplifica as complexidades do scraping da web lidando com proxies, CAPTCHAs e tentativas de nova tentativa por trás de um único ponto de extremidade da API.
Principais Recursos:
- Ponto de Extremidade de Dados Estruturados: ScraperAPI oferece pontos de extremidade especializados para a Amazon, permitindo que os usuários recuperem dados JSON estruturados para produtos, resultados de busca, avaliações e ofertas com o mínimo de esforço.
- Pool de Proxies Extenso: Com mais de 40 milhões de endereços IP e capacidades de geolocalização em mais de 50 países, oferece um gerenciamento robusto de proxies para garantir altas taxas de sucesso.
- Gerenciamento de CAPTCHA e Renderização JavaScript: Ele gerencia automaticamente CAPTCHAs e pode renderizar JavaScript, tornando-o adequado para páginas dinâmicas da Amazon.
- DataPipeline: Uma solução de baixo código para coletar grandes quantidades de dados da Amazon usando templates pré-construídos, ideal para usuários que preferem uma abordagem mais visual sem extensa codificação.
Prós:
- Muito fácil de usar, especialmente com pontos de extremidade de dados estruturados.
- Alta taxa de sucesso e desempenho confiável.
- Bom para extrair pontos de dados específicos e estruturados da Amazon.
- Oferece soluções tanto para API quanto para baixo código.
Contras:
- Opções limitadas de exportação CSV atualmente.
- Alguns parâmetros avançados ainda estão em desenvolvimento.
Preços: O ScraperAPI utiliza um modelo baseado em assinatura com diferentes níveis de acordo com o número de créditos da API. Os planos começam em $49/mês para 100.000 créditos da API.
3. Bright Data: A Solução de Grau Empresarial
Bright Data é renomado por seu conjunto abrangente de ferramentas de web scraping e pela maior rede de proxies do mundo. É uma solução de nível empresarial preferida por grandes organizações e usuários com necessidades de extração de dados altamente complexas e exigentes da Amazon.
Principais Recursos:
- Rede de Proxies Ampla: Oferece proxies residenciais, de datacenter, ISP e móveis, proporcionando flexibilidade e anonimato inigualáveis para scraping em grande escala da Amazon.
- IDE para Web Scraper: Um poderoso ambiente de desenvolvimento integrado para construir, executar e gerenciar web scrapers, oferecendo extensas opções de personalização.
- Coletores de Dados Pré-construídos: Fornece coletores de dados prontos para uso para sites populares, incluindo Amazon, simplificando o processo de configuração para tarefas comuns de scraping.
- Desbloqueador: Uma solução avançada projetada para contornar sistemas sofisticados de anti-bot, garantindo acesso até mesmo às páginas da Amazon mais protegidas.
Prós:
- Tamanho e diversidade da rede de proxies inigualáveis.
- Altamente personalizável e poderoso para cenários de scraping complexos.
- Excelente para extração de dados em grande escala e alto volume.
- Tecnologia de desbloqueio robusta.
Contras:
- Pode ser caro, especialmente para uso alto.
- Curva de aprendizado íngreme para iniciantes devido às suas extensas funcionalidades e opções de personalização.
Preços: A precificação da Bright Data é baseada no uso, geralmente calculada com base no tráfego, solicitações e volume de dados. Oferece vários planos, incluindo pagamento conforme o uso e soluções empresariais personalizadas.
4. ScrapingBee: API de Web Scraping Amigável para Desenvolvedores
ScrapingBee oferece uma API simples, mas eficaz, para web scraping geral, incluindo Amazon. Foca em proporcionar uma experiência amigável para desenvolvedores ao lidar com navegadores headless, proxies e tentativas de nova conexão, permitindo que os usuários se concentrem na lógica de extração de dados.
Principais Recursos:
- Renderização de JavaScript: Renderiza automaticamente JavaScript, tornando-o adequado para scraping de conteúdo dinâmico nas páginas de produtos da Amazon.
- Rotação de Proxies e Geo-targeting: Gerencia a rotação de proxies e permite geo-targeting, ajudando a contornar restrições geográficas e manter o anonimato.
- API Simples: Fornece uma API limpa e fácil de usar que se integra bem com várias linguagens de programação.
- Captura de Tela e Bloqueio de Anúncios: Oferece funcionalidades adicionais, como tirar capturas de tela e bloquear anúncios, que podem ser úteis para tarefas específicas de scraping.
Prós:
- Amigável para desenvolvedores e fácil de integrar.
- Lida com desafios comuns de scraping, como navegadores headless e proxies.
- Bom para tarefas gerais de web scraping.
- Preços transparentes e previsíveis.
Contras:
- Pode exigir mais lógica de parsing personalizada para pontos de dados altamente específicos da Amazon em comparação a scrapers especializados da Amazon.
- O pool de proxies pode não ser tão extenso quanto o de provedores de proxies dedicados.
Preços: O ScrapingBee utiliza um modelo de preços baseado em solicitações, com diferentes níveis oferecendo várias quantidades de chamadas de API por mês. Os planos geralmente começam a partir de um nível gratuito para um número limitado de solicitações, subindo para assinaturas pagas.
5. Octoparse: O Scraper Visual Sem Código
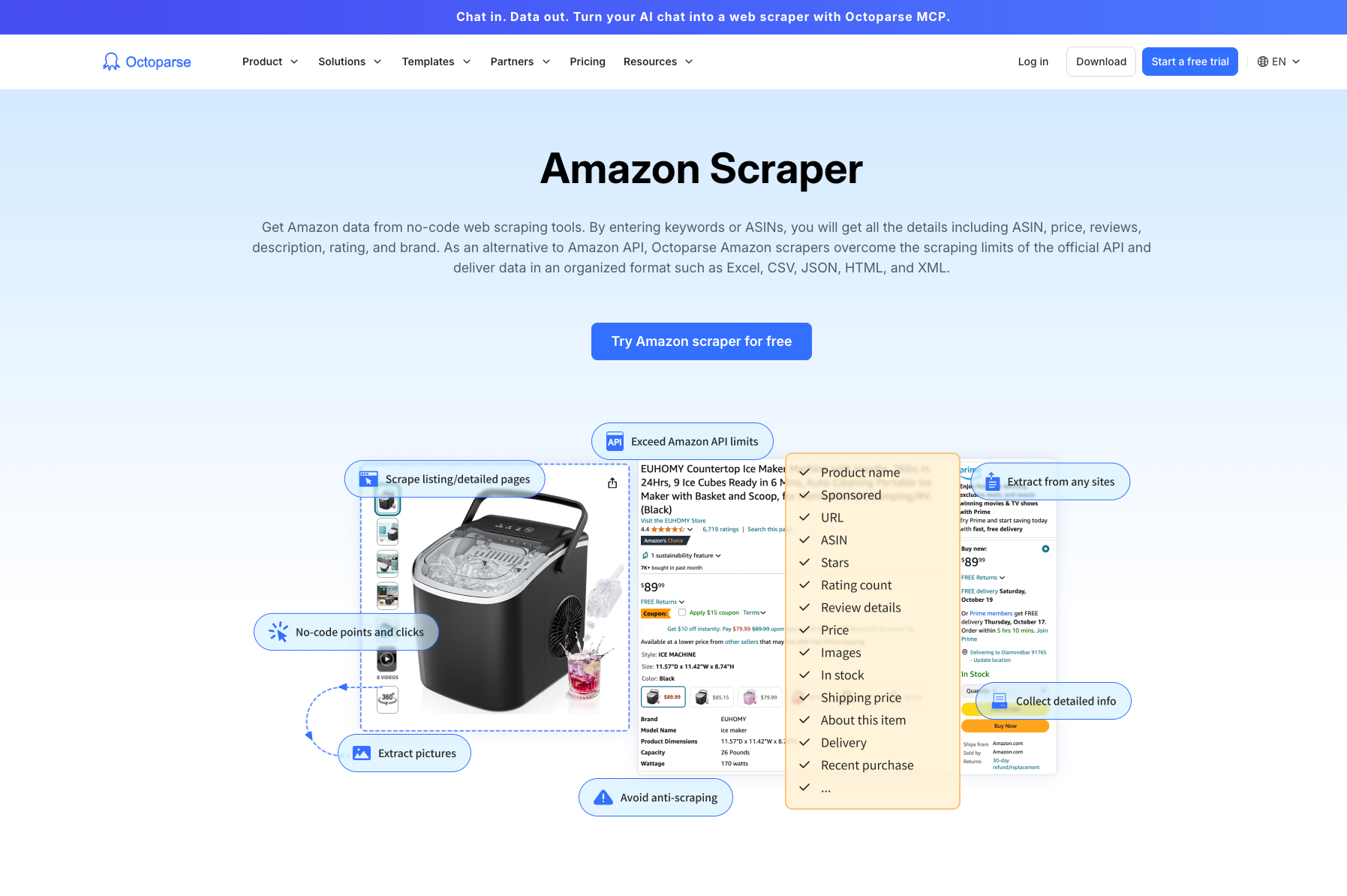
Octoparse é uma ferramenta popular de web scraping sem código que capacita usuários sem conhecimento em programação a extrair dados de sites, incluindo Amazon. Sua interface visual permite que os usuários construam scrapers simplesmente clicando em elementos que desejam extrair.
Principais Recursos:
- Construtor de Fluxo de Trabalho Visual: Os usuários podem criar fluxos de trabalho de scraping apontando e clicando em elementos da web, tornando-o altamente acessível para iniciantes.
- Modelos Prontos para Uso: Oferece modelos pré-construídos para sites populares como Amazon, simplificando o processo de extração de pontos de dados comuns, como detalhes de produtos e avaliações.
- Rotação de IP e Serviço em Nuvem: Fornece rotação de IP para evitar bloqueios e oferece uma plataforma em nuvem para executar scrapers, reduzindo a dependência de recursos locais do computador.
- Opções de Exportação de Dados: Suporta a exportação de dados extraídos em vários formatos, incluindo CSV, Excel e JSON.
Prós:
- Excelente para iniciantes e usuários não técnicos.
- Não é necessário programação para construir e executar scrapers.
- A interface visual torna a criação de fluxos de trabalho intuitiva.
- A execução baseada na nuvem reduz o consumo de recursos locais.
Contras:
- Pode ser menos flexível para cenários de scraping altamente complexos ou personalizados em comparação com soluções baseadas em API.
- Recursos avançados como tratamento de CAPTCHA ou proxies premium podem incorrer em custos adicionais.
- O desempenho pode ser limitado em projetos de escala muito grande.
Preços: O Octoparse oferece um plano gratuito com recursos limitados e planos de assinatura pagos que variam com base no número de tarefas, dados em nuvem e recursos avançados. Os planos geralmente começam em torno de $89/mês.
Como Escolher o Scraper da Amazon Certo para Suas Necessidades
Selecionar o raspador ideal da Amazon depende de uma confluência de fatores únicos para seu projeto e capacidades organizacionais. Considere o seguinte para tomar uma decisão informada:
- Escala e Frequência do Projeto: Para pequenas tarefas de extração de dados, infrequentes, uma solução mais simples e acessível como Octoparse ou um plano básico do ScrapingBee pode ser suficiente. No entanto, para monitoramento em grande escala, contínuo ou necessidades de dados de alto volume, soluções de nível empresarial como Scrapeless ou Bright Data, com sua infraestrutura robusta e capacidades avançadas de anti-detecção, são essenciais.
- Experiência Técnica: Se sua equipe tem habilidades de programação fortes, soluções baseadas em API como Scrapeless, ScraperAPI ou ScrapingBee oferecem máxima flexibilidade e personalização. Para usuários não técnicos ou aqueles que preferem uma abordagem visual, o Octoparse fornece uma excelente alternativa sem código.
- Requisitos Específicos de Dados: Você precisa de informações gerais sobre produtos ou está visando dados nichados como desempenho de Anúncios Patrocinados ou insights de dados do Rufus? Scrapeless, com suas capacidades de extração especializadas, se destaca nessas áreas. Certifique-se de que o raspador escolhido possa fornecer de forma confiável os dados precisos que você precisa.
- Restrições Orçamentárias: Os modelos de preços variam significativamente. Avalie se um modelo baseado em assinatura, preços baseados em uso ou uma combinação se adequa melhor ao seu orçamento e volume de dados esperado. Lembre-se de considerar custos adicionais potenciais para proxies ou recursos avançados.
- Integração com Sistemas Existentes: Considere quão facilmente o raspador pode se integrar com seus pipelines de dados atuais, ferramentas de análise ou sistemas internos. Soluções baseadas em API geralmente oferecem opções de integração mais suaves.
- Suporte e Documentação: Um suporte ao cliente confiável e documentação abrangente podem ser inestimáveis, especialmente ao encontrar desafios inesperados de raspagem. Procure por provedores que ofereçam assistência responsiva e guias claros.
Conclusão
A capacidade de raspar dados da Amazon de forma eficaz é um ativo poderoso no cenário de e-commerce orientado por dados de hoje. O raspador da Amazon certo pode desbloquear uma riqueza de insights, capacitando as empresas a tomar decisões mais inteligentes, otimizar estratégias e ganhar uma vantagem competitiva. Da simplicidade sem código do Octoparse ao poder de nível empresarial do Bright Data, e as APIs amigáveis para desenvolvedores do ScraperAPI e ScrapingBee, há uma solução para cada necessidade.
No entanto, para aqueles que buscam uma abordagem verdadeiramente inteligente, escalável e especializada para a extração de dados da Amazon—especialmente quando se trata de navegar por medidas complexas de anti-bot e acessar pontos de dados exclusivos como Anúncios Patrocinados e dados do Rufus—Scrapeless se destaca. Nosso avançado Desbloqueador da Web e Navegador de Raspagem garantem taxas de sucesso incomparáveis, permitindo que você se concentre no que realmente importa: alavancar dados para crescimento.
Não deixe que as defesas da Amazon impeçam suas ambições de dados. Explore o poder do Scrapeless hoje e transforme sua estratégia de e-commerce com dados da Amazon confiáveis e de alta qualidade. Experimente o Scrapeless agora!
Perguntas Frequentes
1. Raspagem da Amazon é legal em 2026?
Raspar dados disponíveis publicamente geralmente é legal, mas você deve cumprir as leis de privacidade de dados (como o GDPR) e evitar interromper os serviços da Amazon. Usar um serviço profissional como Scrapeless garante que sua raspagem seja feita de forma ética e responsável.
2. Como evito ser bloqueado pela Amazon?
A forma mais eficaz é usar uma API que trate da impressão digital TLS e da rotação de IP automaticamente. Scrapeless usa IA avançada para imitar o comportamento humano, mantendo sua taxa de sucesso acima de 95%.
3. Posso raspar Anúncios Patrocinados da Amazon?
A maioria dos raspadores enfrenta dificuldades com anúncios porque são carregados dinamicamente e altamente protegidos. No entanto, Scrapeless oferece um endpoint dedicado especificamente para Anúncios Patrocinados, fornecendo insights profundos sobre o marketing dos concorrentes.
4. O que são dados do Rufus e por que devo raspá-los?
Rufus é o assistente de compras por IA da Amazon. Raspar dados do Rufus permite que você veja como a IA recomenda produtos, o que é essencial para SEO moderno e posicionamento de produtos. Scrapeless é atualmente um líder em fornecer esses dados.
5. Preciso de um proxy para a raspagem da Amazon?
Sim, mas gerenciar seus próprios proxies é difícil e caro. É melhor usar uma ferramenta como Scrapeless que inclui uma rede de proxy residencial de alta qualidade como parte do serviço.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


