
Como construir um pipeline alimentado por IA usando o Scrapeless no n8n?
Advanced Data Extraction Specialist
Introdução
No cenário orientado por dados de hoje, as organizações precisam de maneiras eficientes para extrair, processar e analisar conteúdo da web. A raspagem de dados tradicional enfrenta inúmeros desafios: proteções contra bots, renderização complexa em JavaScript e a necessidade de manutenção constante. Além disso, fazer sentido de dados da web não estruturados requer processamento sofisticado.
Este guia demonstra como construir um pipeline completo de dados da web usando a automação de fluxos de trabalho n8n, raspagem da web Scrapeless, Claude AI para extração inteligente e banco de dados vetorial Qdrant para armazenamento semântico. Seja para construir uma base de conhecimento, realizar pesquisas de mercado ou desenvolver um assistente de IA, este fluxo de trabalho fornece uma base poderosa.
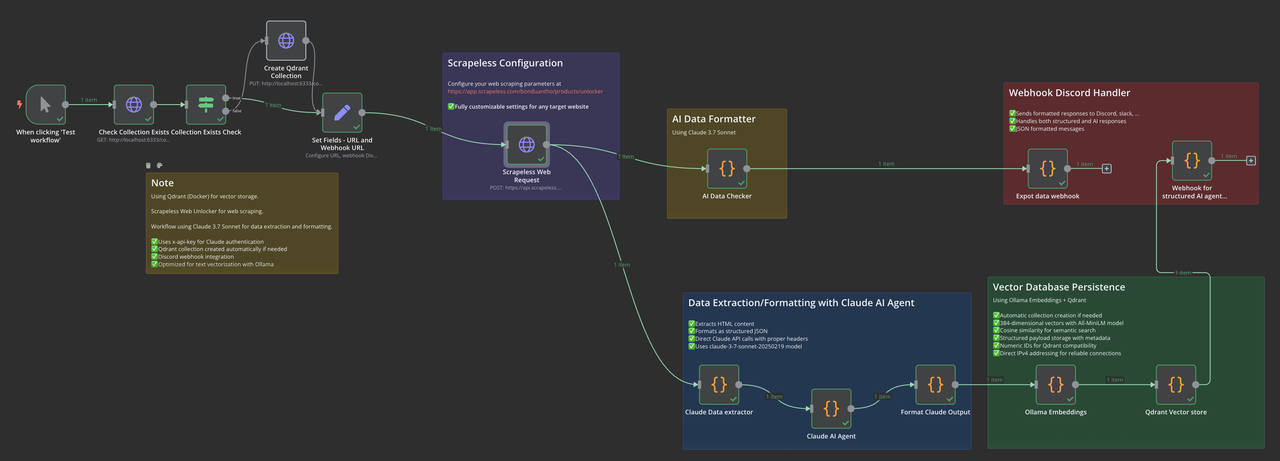
O que você irá construir
Nosso fluxo de trabalho n8n combina várias tecnologias de ponta:
- Scrapeless Web Unlocker: Raspagem avançada da web com renderização JavaScript
- Claude 3.7 Sonnet: Extração e estruturação de dados impulsionadas por IA
- Embeddings Ollama: Geração de embeddings vetoriais locais
- Banco de Dados Vetorial Qdrant: Armazenamento e recuperação semânticos
- Sistema de Notificação: Monitoramento em tempo real via webhooks
Este pipeline de ponta a ponta transforma dados da web desordenados em informações estruturadas e vetorizadas, prontas para busca semântica e aplicações de IA.
Instalação e Configuração
Instalando o n8n
O n8n requer Node.js v18, v20 ou v22. Se você encontrar problemas de compatibilidade de versão:
# Verifique sua versão do Node.js
node -v
# Se você tem uma versão mais nova não suportada (por exemplo, v23+), instale o nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
# Ou para Windows, use o instalador NVM para Windows
# Instale uma versão compatível do Node.js
nvm install 20
# Use a versão instalada
nvm use 20
# Instale o n8n globalmente
npm install n8n -g
# Execute o n8n
n8nSua instância do n8n agora deve estar disponível em http://localhost:5678.
Configurando a API do Claude
- Visite o Console da Anthropic e crie uma conta
- Navegue até a seção de Chaves da API
- Clique em "Criar Chave" e defina as permissões apropriadas
- Copie sua chave da API para uso no fluxo de trabalho n8n (No AI Data Checker, extrator de dados Claude e agente AI Claude)
Configurando o Scrapeless
- Visite Scrapeless e crie uma conta
- Navegue até a seção de API de Raspagem Universal em seu painel https://app.scrapeless.com/exemple/overview
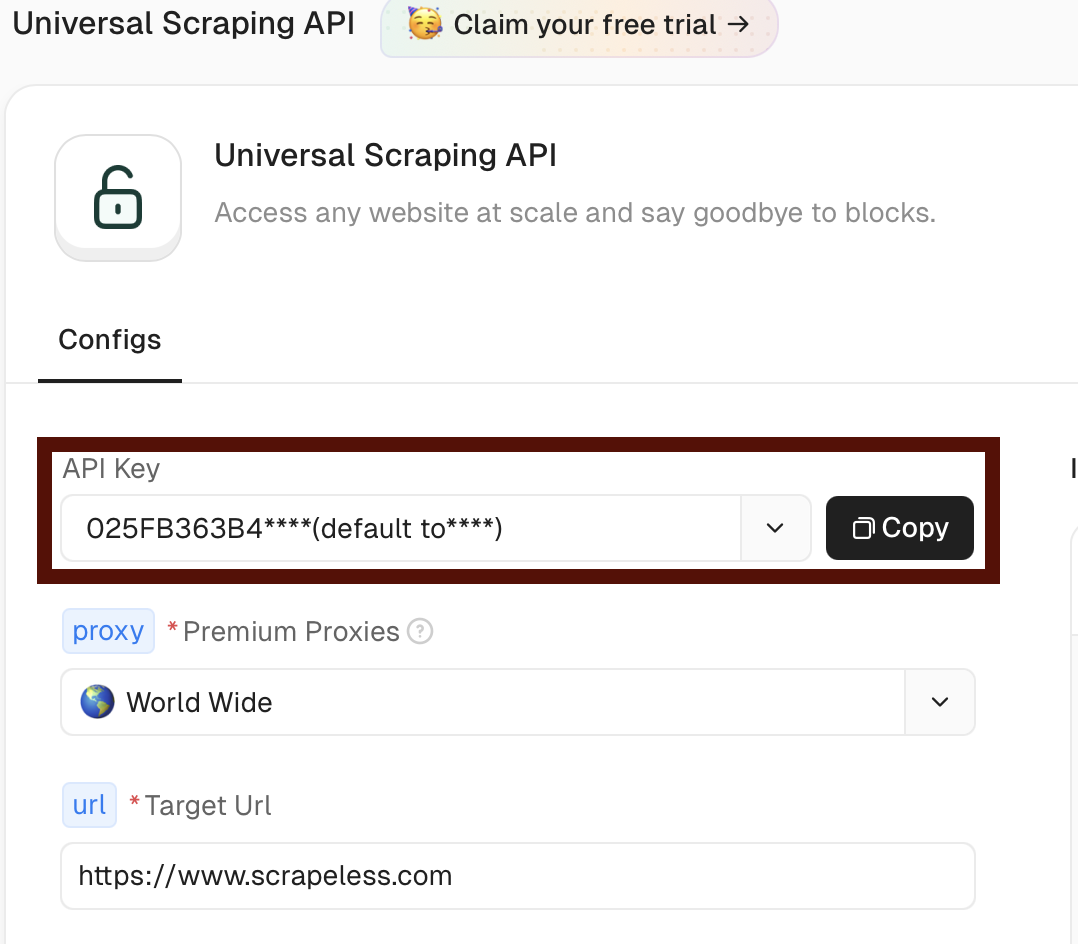
- Copie seu token para uso no fluxo de trabalho n8n
Você pode personalizar sua solicitação de raspagem web Scrapeless usando este comando curl e importá-lo diretamente para o nó de Solicitação HTTP no n8n:
curl -X POST "https://api.scrapeless.com/api/v1/unlocker/request" \
-H "Content-Type: application/json" \
-H "x-api-token: scrapeless_api_key" \
-d '{
"actor": "unlocker.webunlocker",
"proxy": {
"country": "ANY"
},
"input": {
"url": "https://www.scrapeless.com",
"method": "GET",
"redirect": true,
"js_render": true,
"js_instructions": [{"wait":100}],
"block": {
"resources": ["image","font","script"],
"urls": ["https://example.com"]
}
}
}'
Instalando o Qdrant com Docker
# Baixar imagem do Qdrant
docker pull qdrant/qdrant
# Executar contêiner Qdrant com persistência de dados
docker run -d \
--name qdrant-server \
-p 6333:6333 \
-p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrantVerifique se o Qdrant está em execução:
curl http://localhost:6333/healthzInstalando o Ollama
macOS:
brew install ollamaLinux:
curl -fsSL https://ollama.com/install.sh | shWindows: Baixe e instale do site do Ollama.
Inicie o servidor Ollama:
ollama serveInstale o modelo de embedding necessário:
ollama pull all-minilmVerifique a instalação do modelo:
ollama listConfigurando o Fluxo de Trabalho do n8n
Visão Geral do Fluxo de Trabalho
Nosso fluxo de trabalho consiste nestes componentes principais:
- Gatilho Manual/Agendado: Inicia o fluxo de trabalho
- Verificação de Coleta: Verifica se a coleção do Qdrant existe
- Configuração de URL: Define a URL e os parâmetros de destino
- Solicitação Web Scrapeless: Extrai conteúdo HTML
- Extração de Dados do Claude: Processa e estrutura os dados
- Embeddings Ollama: Gera embeddings vetoriais
- Armazenamento Qdrant: Salva vetores e metadados
- Notificação: Envia atualizações de status via webhook
Etapa 1: Configurar Gatilho de Fluxo de Trabalho e Verificação de Coleta
Comece adicionando um nó de Gatilho Manual, depois adicione um nó de Requisição HTTP para verificar se sua coleção Qdrant existe. Você pode personalizar o nome da coleção nesta etapa inicial - o fluxo de trabalho criará automaticamente a coleção se ela não existir.
Nota Importante: Se você quiser usar um nome de coleção diferente do padrão "hacker-news", certifique-se de alterá-lo consistentemente em TODOS os nós que fazem referência ao Qdrant.
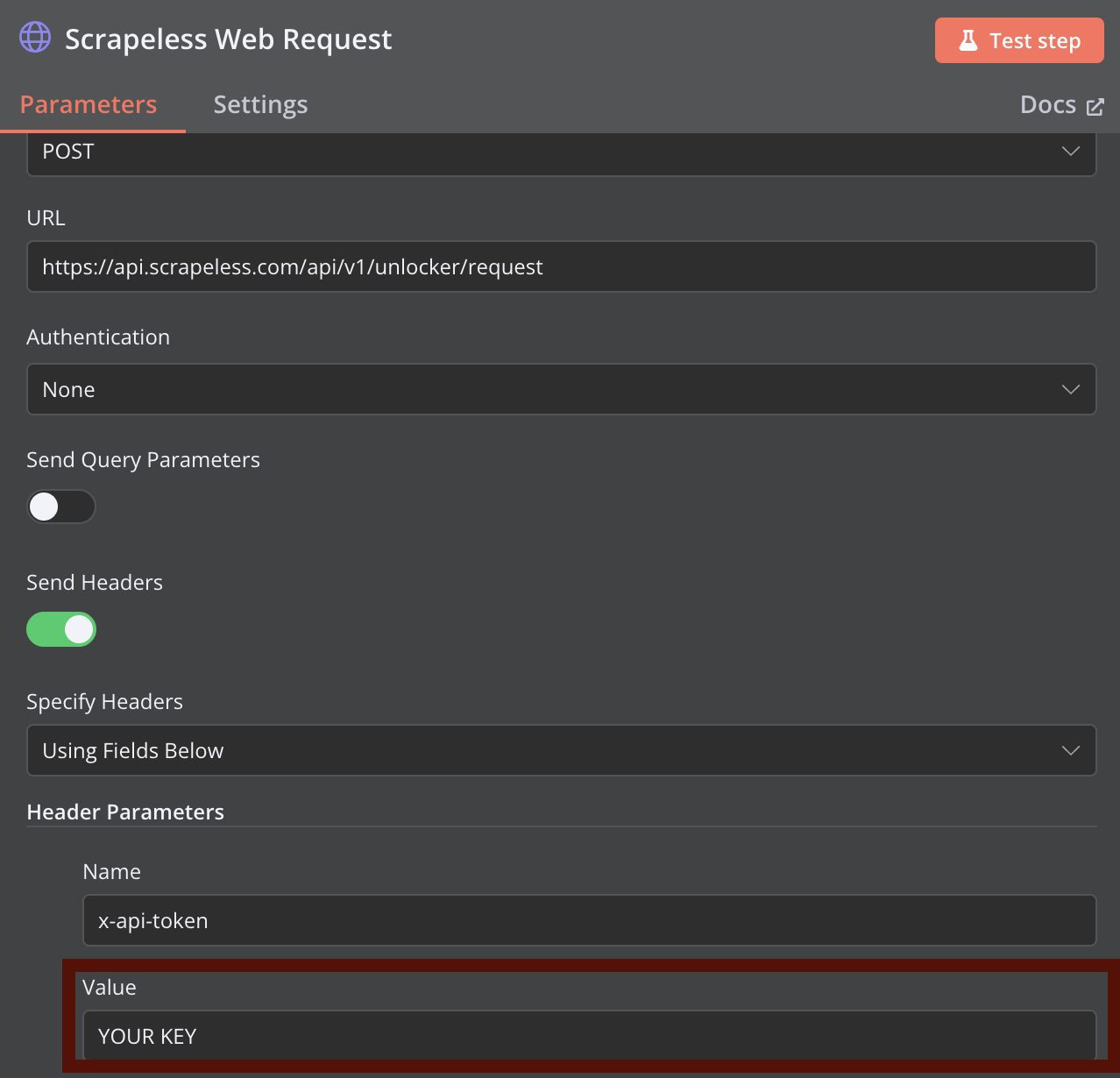
Etapa 2: Configurar Requisição Web Scrapeless
Adicione um nó de Requisição HTTP para web scraping Scrapeless. Configure o nó utilizando o comando curl fornecido anteriormente como referência, substituindo YOUR_API_TOKEN pelo seu token de API Scrapeless real.
Você pode configurar parâmetros de scraping mais avançados no Scrapeless Web Unlocker.
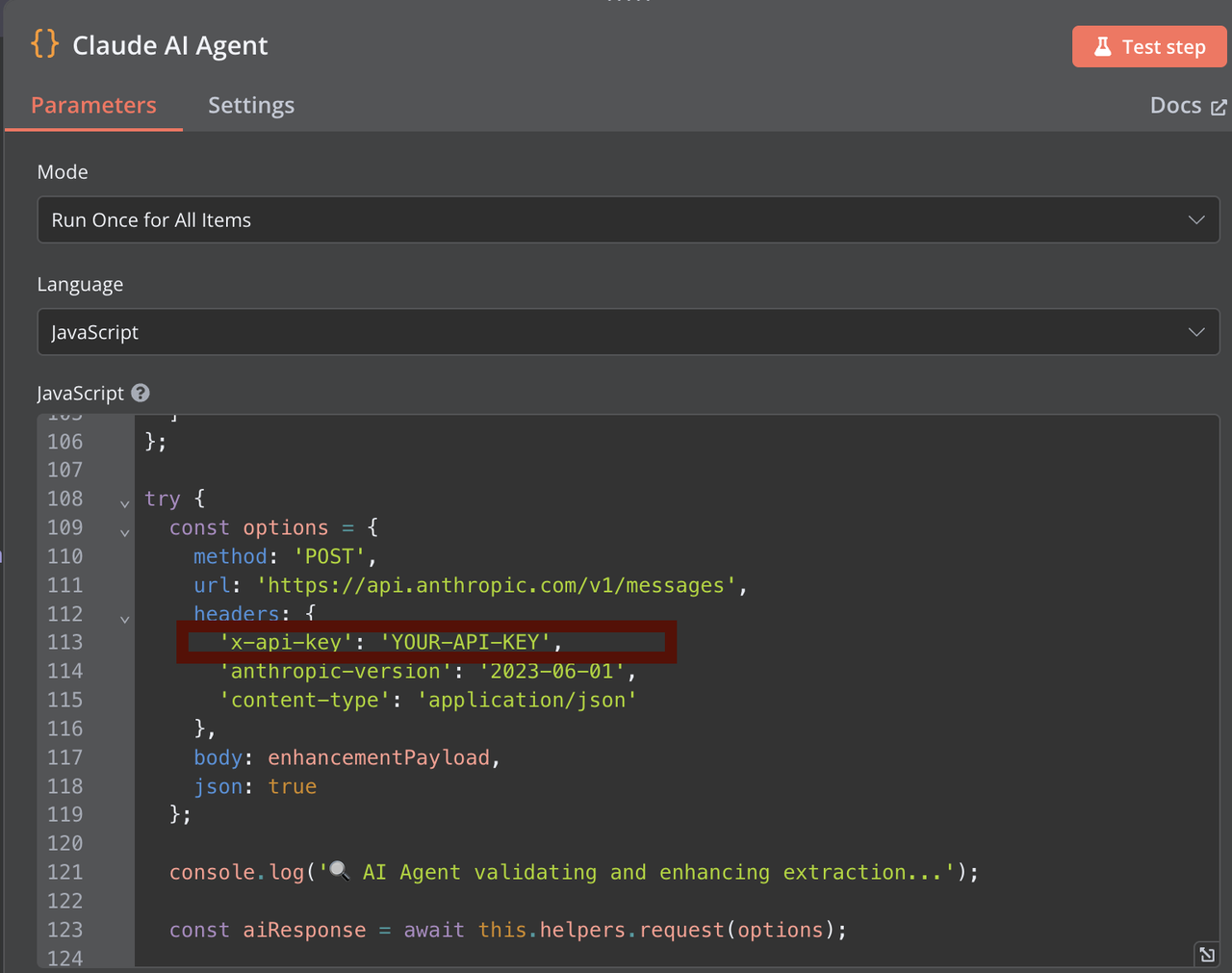
Etapa 3: Extração de Dados com Claude
Adicione um nó para processar o conteúdo HTML usando Claude. Você precisará fornecer sua chave de API Claude para autenticação. O extrator Claude analisa o conteúdo HTML e retorna dados estruturados em formato JSON.
Etapa 4: Formatar Saída do Claude
Este nó pega a resposta do Claude e a prepara para vetorização, extraindo as informações relevantes e formatando-as adequadamente.
Etapa 5: Geração de Embeddings Ollama
Este nó envia o texto estruturado para o Ollama para geração de embeddings. Certifique-se de que seu servidor Ollama está em funcionamento e que o modelo all-minilm está instalado.
Etapa 6: Armazenamento de Vetores Qdrant
Este nó pega os embeddings gerados e os armazena em sua coleção Qdrant, juntamente com metadados relevantes.
Etapa 7: Sistema de Notificação
O nó final envia uma notificação com o status da execução do fluxo de trabalho via seu webhook configurado.
Solução de Problemas Comuns
Problemas de Versão do Node.js do n8n
Se você ver um erro como:
Sua versão do Node.js X não é atualmente suportada pelo n8n.
Por favor, use Node.js v18.17.0 (recomendado), v20 ou v22 ao invés! Corrija instalando o nvm e usando uma versão compatível do Node.js conforme descrito na seção de configuração.
Problemas de Conexão com a API Scrapeless
- Verifique se seu token de API está correto
- Verifique se você está atingindo os limites de taxa da API
- Garanta a formatação adequada da URL
Erros de Embedding Ollama
Erro comum: connect ECONNREFUSED ::1:11434
Correção:
- Certifique-se de que o Ollama está em funcionamento: ollama serve
- Verifique se o modelo está instalado: ollama pull all-minilm
- Use o IP direto (127.0.0.1) em vez de localhost
- Verifique se outro processo está usando a porta 11434
Cenários de Uso Avançado
Processamento em Lote de Múltiplas URLs
Para processar várias URLs em uma execução de fluxo de trabalho:
- Use um nó Split In Batches para processar URLs em paralelo
- Configure o tratamento de erros adequado para cada lote
- Use o nó Merge para combinar os resultados
Atualizações de Dados Programadas
Mantenha seu banco de dados vetorial atualizado com atualizações programadas:
- Substitua o gatilho manual pelo nó Schedule
- Configure a frequência de atualização (diária, semanal, etc.)
- Use o nó If para processar apenas conteúdo novo ou alterado
Modelos de Extração Personalizados
Adapte a extração do Claude para diferentes tipos de conteúdo:
- Crie prompts específicos para artigos de notícias, páginas de produtos, documentação, etc.
- Use o nó Switch para selecionar o prompt apropriado
- Armazene os modelos de extração como variáveis de ambiente
Conclusão
Este fluxo de trabalho n8n cria um poderoso pipeline de dados combinando as forças do web scraping Scrapeless, extração de IA Claude, embeddings vetoriais e armazenamento Qdrant. Ao automatizar esses processos complexos, você pode se concentrar em usar os dados extraídos em vez dos desafios técnicos de obtê-los.
A natureza modular do n8n permite que você estenda este fluxo de trabalho com etapas de processamento adicionais, integração com outros sistemas ou lógica personalizada para atender às suas necessidades específicas. Seja construindo uma base de conhecimento em IA, realizando análise competitiva ou monitorando conteúdo da web, este fluxo de trabalho fornece uma base sólida.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


