
Escritor de Blog Movido por IA usando Scrapeless e Banco de Dados Pinecone
Senior Web Scraping Engineer
Você deve ser um criador de conteúdo experiente. Como uma equipe de startup, o conteúdo atualizado diariamente do produto é muito rico. Não só é necessário criar uma grande quantidade de blogs de drenagem para aumentar rapidamente o tráfego do site, mas também é preciso preparar de 2 a 3 blogs por semana que promovam a atualização do produto.
Comparado a gastar muito dinheiro para aumentar o orçamento de lances de anúncios pagos em troca de posições de exibição mais altas e mais exposição, o marketing de conteúdo ainda possui vantagens insubstituíveis: ampla gama de conteúdos, baixo custo de teste de aquisição de clientes, alta eficiência de produção, investimento de energia relativamente baixo, base de conhecimento rica em experiência de campo, etc.
No entanto, quais são os resultados de uma grande quantidade de marketing de conteúdo?
Infelizmente, muitos artigos ficam profundamente enterrados na 10ª página da busca do Google.
Há alguma boa maneira de evitar o forte impacto de artigos de "baixo tráfego" tanto quanto possível?
Você já quis criar um escritor de SEO autossustentável que clone o conhecimento de blogs de alto desempenho e gere conteúdo fresco em larga escala?
Neste guia, vamos guiá-lo na construção de um fluxo de trabalho de geração de conteúdo de SEO totalmente automatizado usando n8n, Scrapeless, Gemini (você pode escolher outros como Claude/OpenRouter se desejar) e Pinecone.
Esse fluxo de trabalho usa um sistema de Geração Aumentada por Recuperação (RAG) para coletar, armazenar e gerar conteúdo com base em blogs de alto tráfego existentes.
Tutorial no YouTube: https://www.youtube.com/watch?v=MmitAOjyrT4
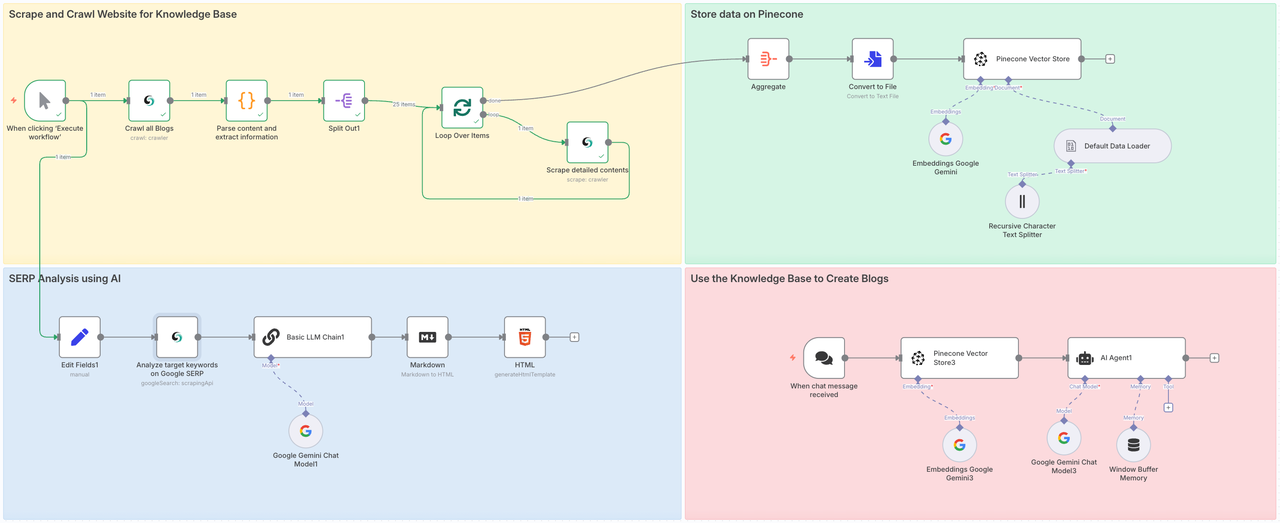
O que este fluxo de trabalho faz?
Esse fluxo de trabalho envolverá quatro etapas:
- Parte 1: Chame o Crawl do Scrapeless para rastrear todas as subpáginas do site-alvo e use o Scrape para analisar profundamente todo o conteúdo de cada página.
- Parte 2: Armazene os dados rastreados no Pinecone Vector Store.
- Parte 3: Use o nó Google Search do Scrapeless para analisar completamente o valor do tópico ou palavras-chave-alvo.
- Parte 4: Transmita instruções ao Gemini, integre conteúdo contextual do banco de dados preparado através do RAG e produza blogs-alvo ou responda perguntas.
Se você ainda não ouviu falar do Scrapeless, é uma empresa de infraestrutura líder focada em oferecer suporte a agentes de IA, fluxos de trabalho de automação e rastreamento da web. O Scrapeless fornece os elementos essenciais que permitem que desenvolvedores e empresas criem sistemas autônomos e inteligentes de forma eficiente.
Em seu núcleo, o Scrapeless oferece ferramentas em nível de navegador e APIs baseadas em protocolos—como navegador em nuvem sem interface, Deep SERP API e APIs de Rastreamento Universal—que servem como uma fundação modular e unificada para agentes de IA e plataformas de automação.
Ele é realmente construído para aplicações de IA porque os modelos de IA nem sempre estão atualizados com muitas coisas, seja em relação a eventos atuais ou novas tecnologias.
Além do n8n, ele também pode ser chamado através da API, e há nós nas principais plataformas como Make:
Você também pode usá-lo diretamente no site oficial.
Para usar o Scrapeless no n8n:
- Vá para Configurações > Nós da Comunidade
- Pesquise por n8n-nodes-scrapeless e instale-o
Precisamos instalar o nó da comunidade Scrapeless no n8n primeiro:
Conexão de Credenciais
Chave de API do Scrapeless
Neste tutorial, usaremos o serviço Scrapeless. Certifique-se de que você se registrou e obteve a chave de API.
- Inscreva-se no site do Scrapeless para obter sua chave de API e reivindique a versão de teste gratuita.
- Depois, você pode abrir o nó Scrapeless, colar sua chave de API na seção de credenciais e conectar.
Índice e Chave de API do Pinecone
Após rastrear os dados, iremos integrar e processar e coletar todos os dados no banco de dados Pinecone. Precisamos preparar a chave de API e o índice do Pinecone com antecedência.
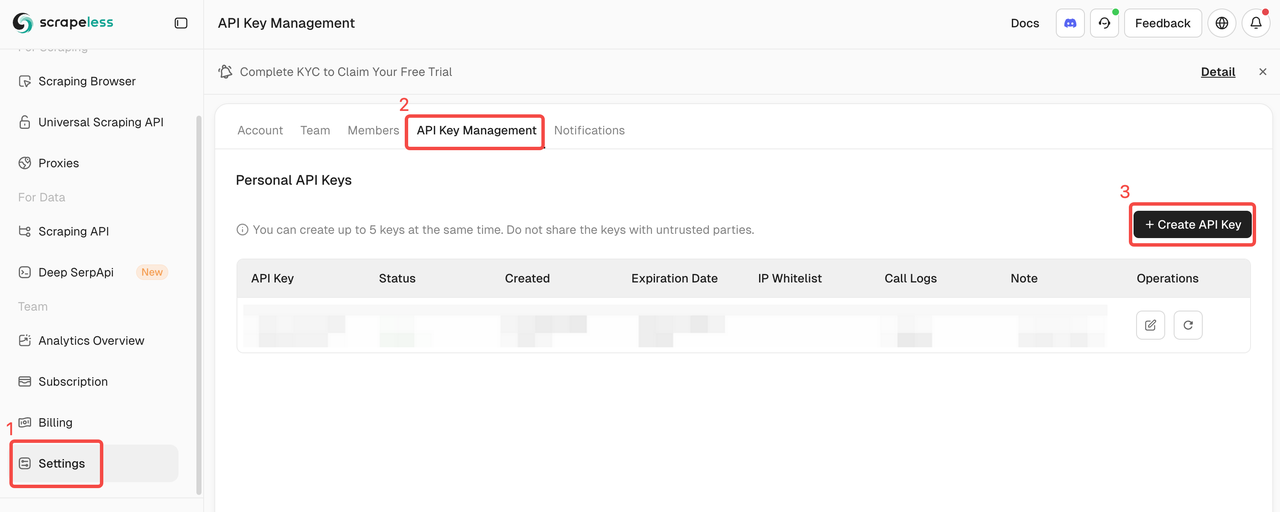
Criar Chave de API
Depois de fazer login, clique em Chaves de API → Clique em Criar chave de API → Complete o nome da sua chave de API → Criar chave. Agora, você pode configurá-lo nas credenciais do n8n.
⚠️ Após a criação, copie e salve sua chave de API. Para a segurança dos dados, o Pinecone não exibirá mais a chave de API criada.
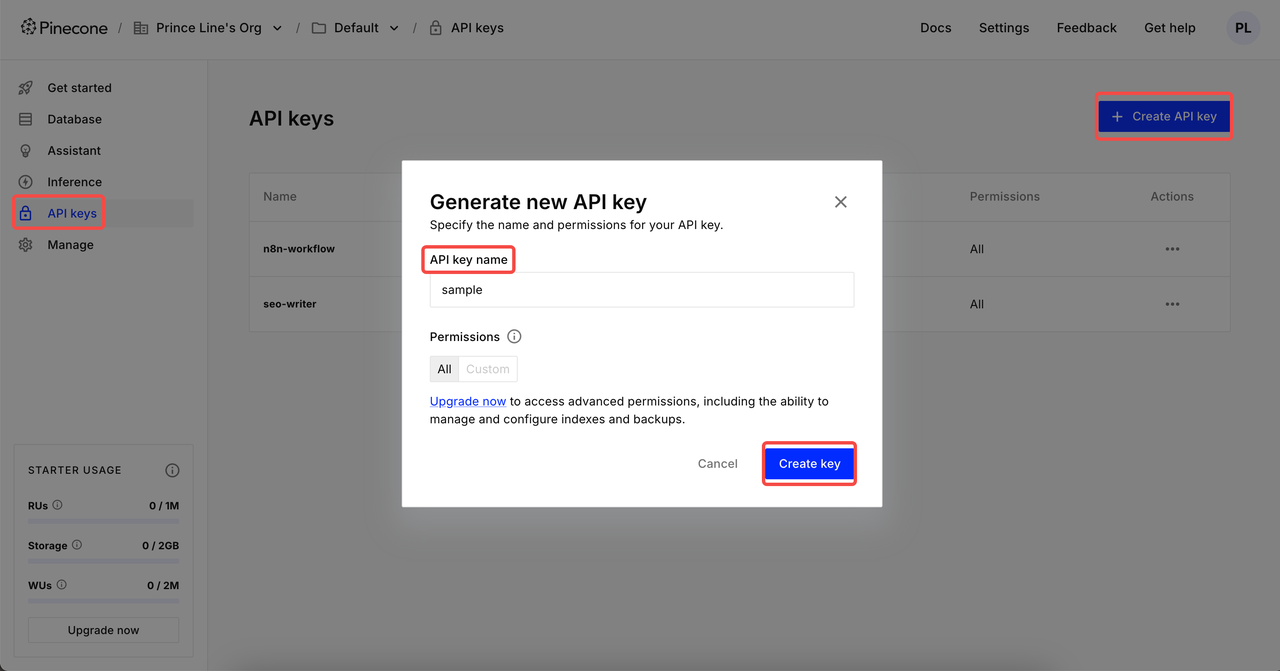
Criar Índice
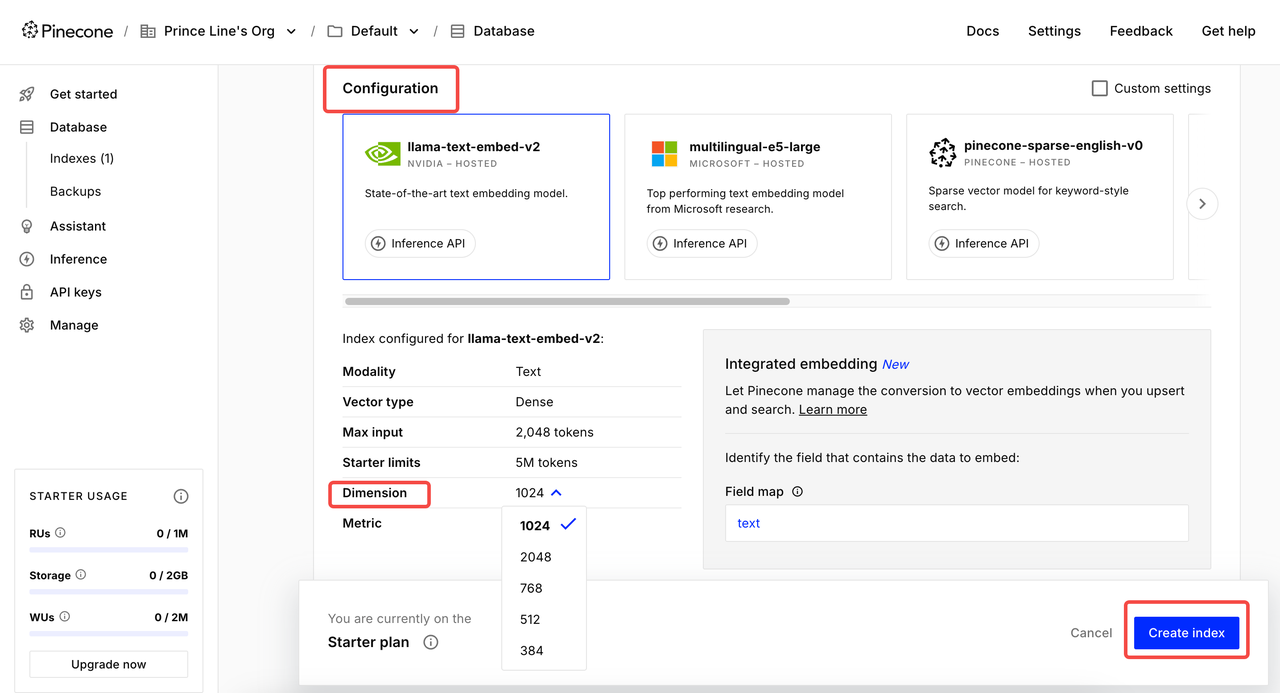
Clique em Índice e entre na página de criação. Defina o Nome do Índice → Selecione modelo para Configuração → Defina a Dimensão apropriada → Criar índice.
2 configurações comuns de dimensão:
- Google Gemini Embedding-001 → 768 dimensões
- OpenAI's text-embedding-3-small → 1536 dimensões
Fase 1: Raspar e Rastrear Websites para a Base de Conhecimento
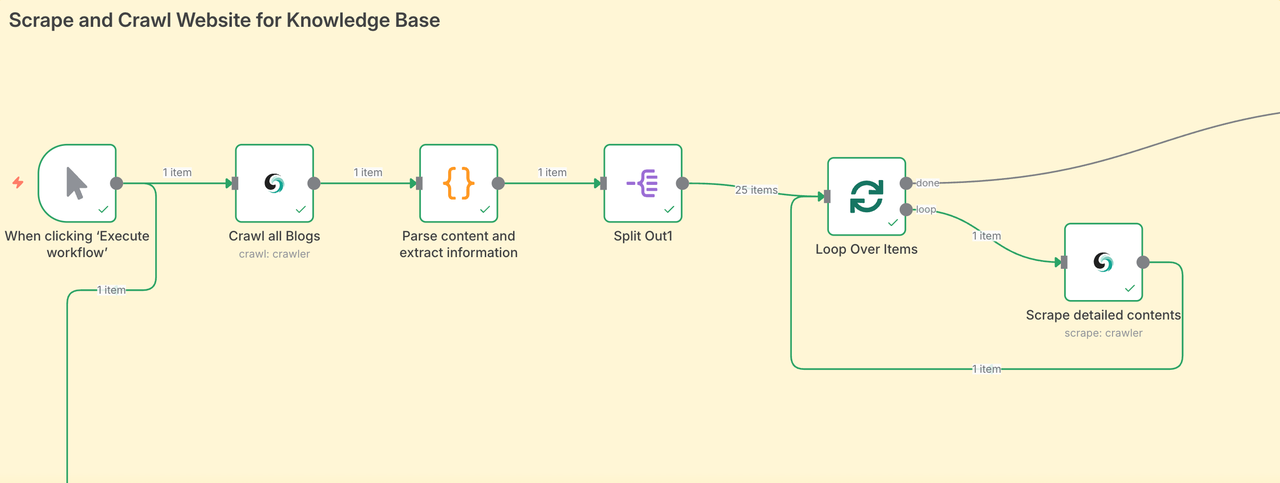
A primeira etapa é agregar diretamente todo o conteúdo do blog. Rastrear conteúdo de uma grande área permite que nosso Agente de IA obtenha fontes de dados de todos os campos, garantindo assim a qualidade dos artigos finais.
- O nó Scrapeless rastreia a página do artigo e coleta todos os URLs das postagens do blog.
- Em seguida, ele percorre cada URL, raspa o conteúdo do blog e organiza os dados.
- Cada postagem do blog é incorporada usando seu modelo de IA e armazenada no Pinecone.
- No nosso caso, raspamos 25 postagens do blog em apenas alguns minutos — sem mover um dedo.
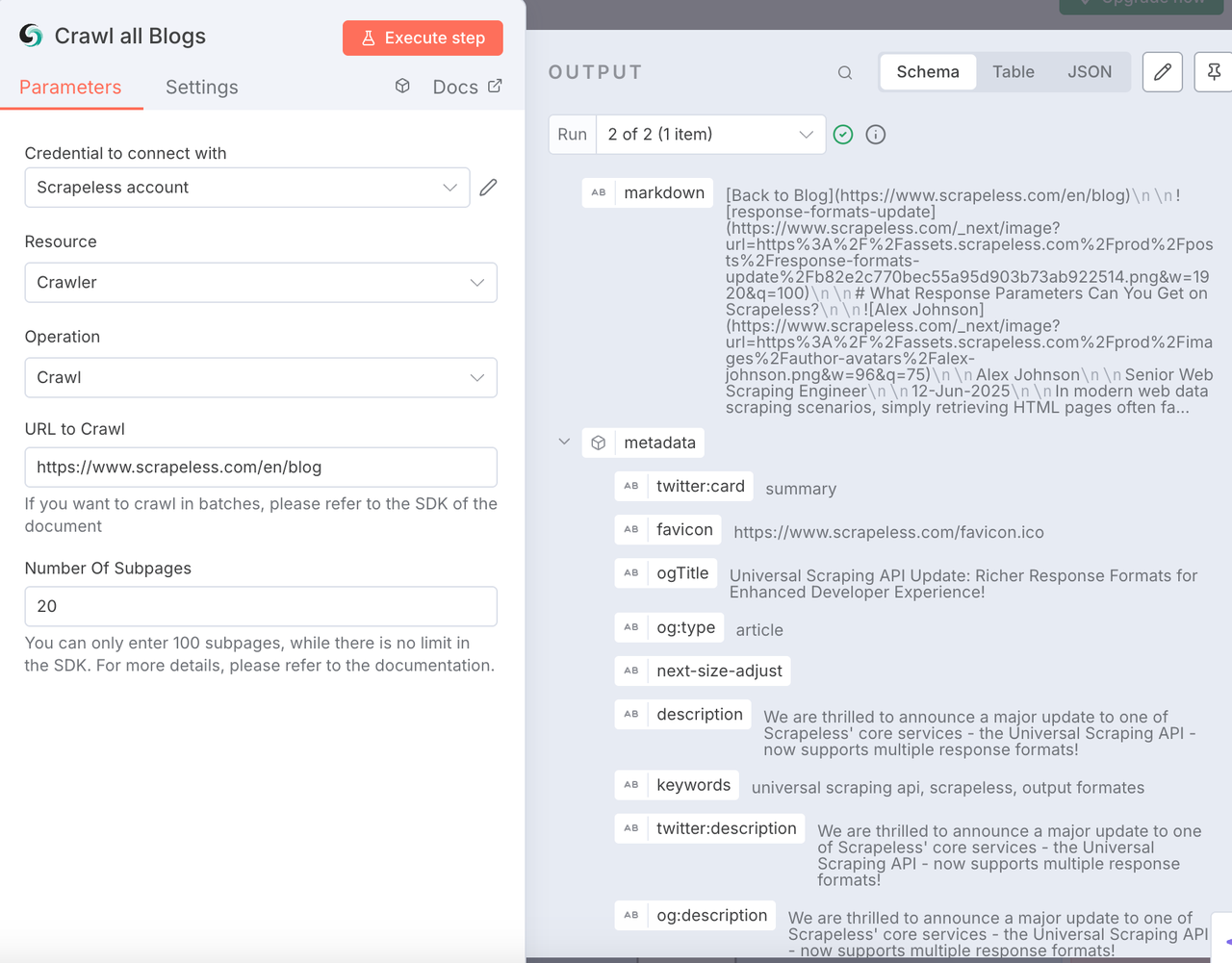
Nó de Rastreio do Scrapeless
Esse nó é usado para rastrear todo o conteúdo do site do blog-alvo, incluindo metadados, conteúdo de subpáginas e exportá-lo em formato Markdown. Este é um rastreamento de conteúdo em grande escala que não conseguimos realizar rapidamente por meio de codificação manual.
Configuração:
- Conecte sua chave API do Scrapeless
- Recurso:
Crawler - Operação:
Crawl - Insira o site de raspagem alvo. Aqui usamos https://www.scrapeless.com/pt/blog como referência.
Nó de Código
Depois de obter os dados do blog, precisamos analisar os dados e extrair as informações estruturadas de que precisamos.
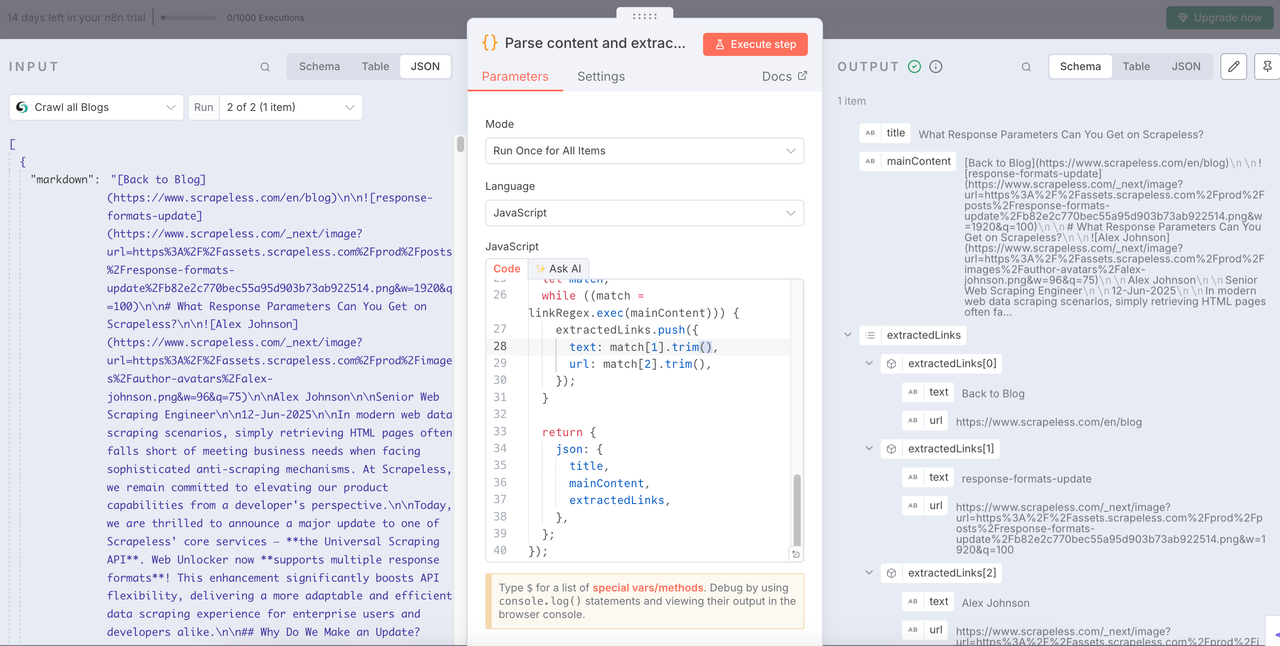
O seguinte é o código que eu usei. Você pode consultar diretamente:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('O conteúdo Markdown não é uma string:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'O conteúdo Markdown não é uma string'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : 'Título Não Encontrado';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});Nó: Separar
O nó Separar pode nos ajudar a integrar os dados limpos e extrair os URLs e o conteúdo de texto de que precisamos.
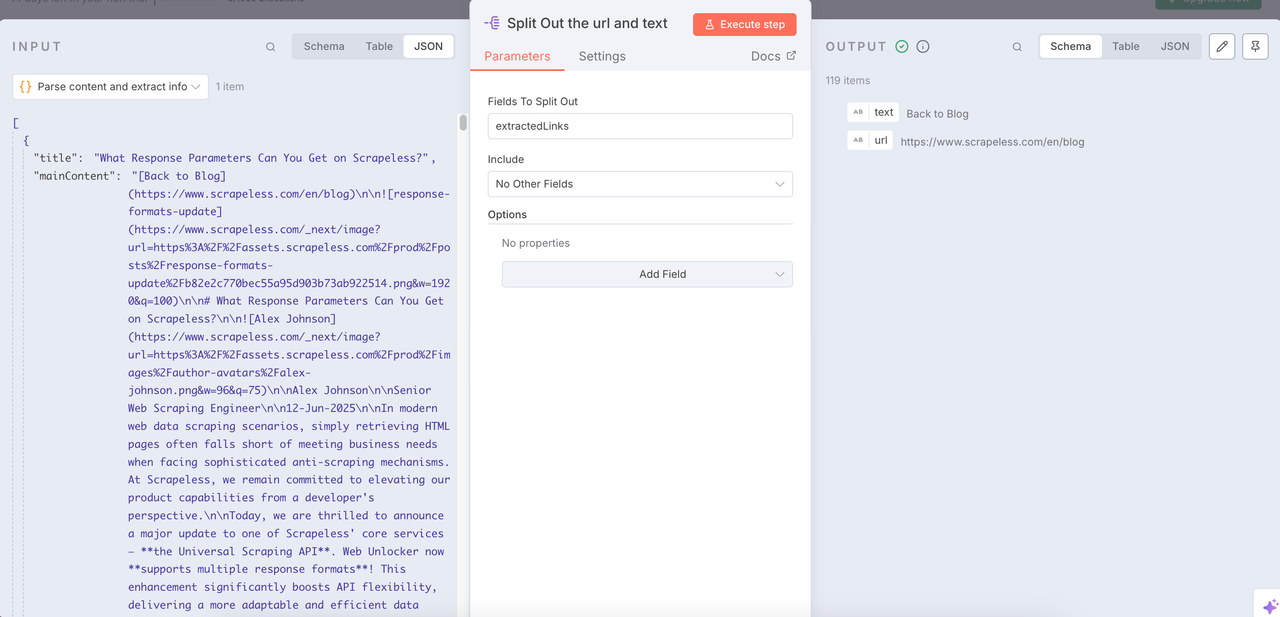
Loop Sobre Itens + Raspagem Scrapeless
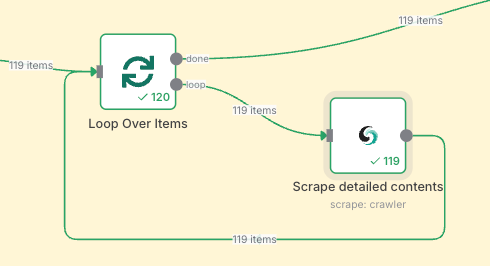
Loop Sobre Itens
Use o nó Loop Sobre Tempo com a Raspagem do Scrapeless para realizar repetidamente tarefas de rastreamento e analisar profundamente todos os itens obtidos anteriormente.
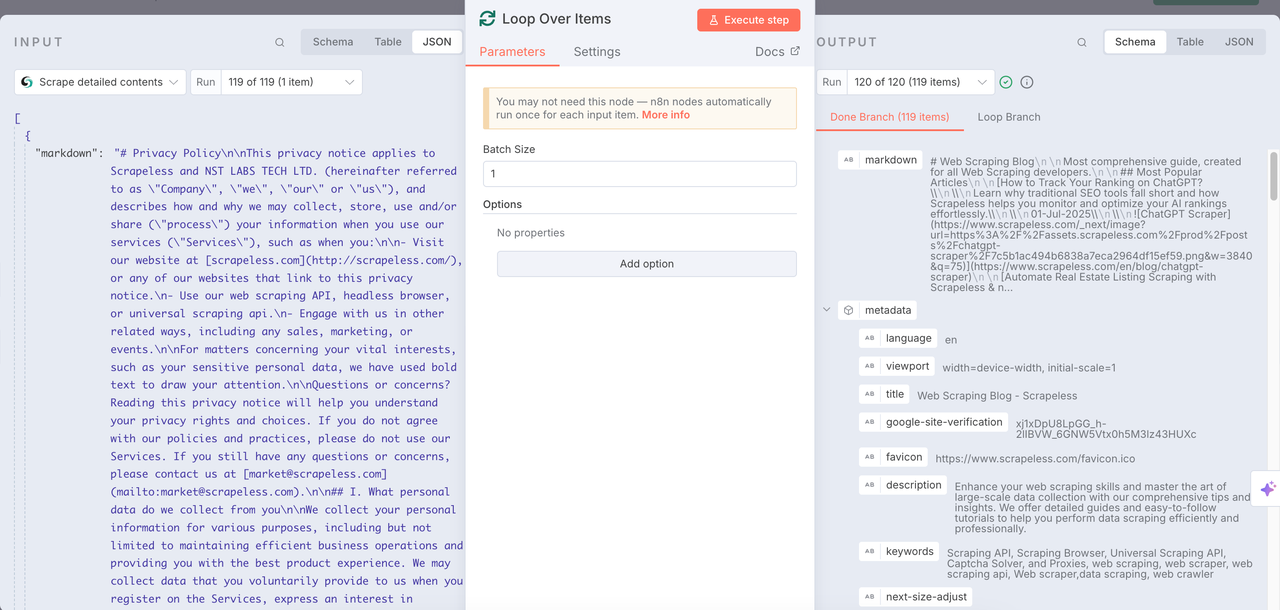
Raspagem Scrapeless
O nó de Raspagem é usado para rastrear todo o conteúdo contido na URL obtida anteriormente. Dessa forma, cada URL pode ser profundamente analisada. O formato markdown é retornado e metadados e outras informações são integrados.

Fase 2. Armazenar dados no Pinecone
Extraímos com sucesso todo o conteúdo da página do blog Scrapeless. Agora precisamos acessar o Armazenamento de Vetores do Pinecone para armazenar essas informações para que possamos usá-las posteriormente.
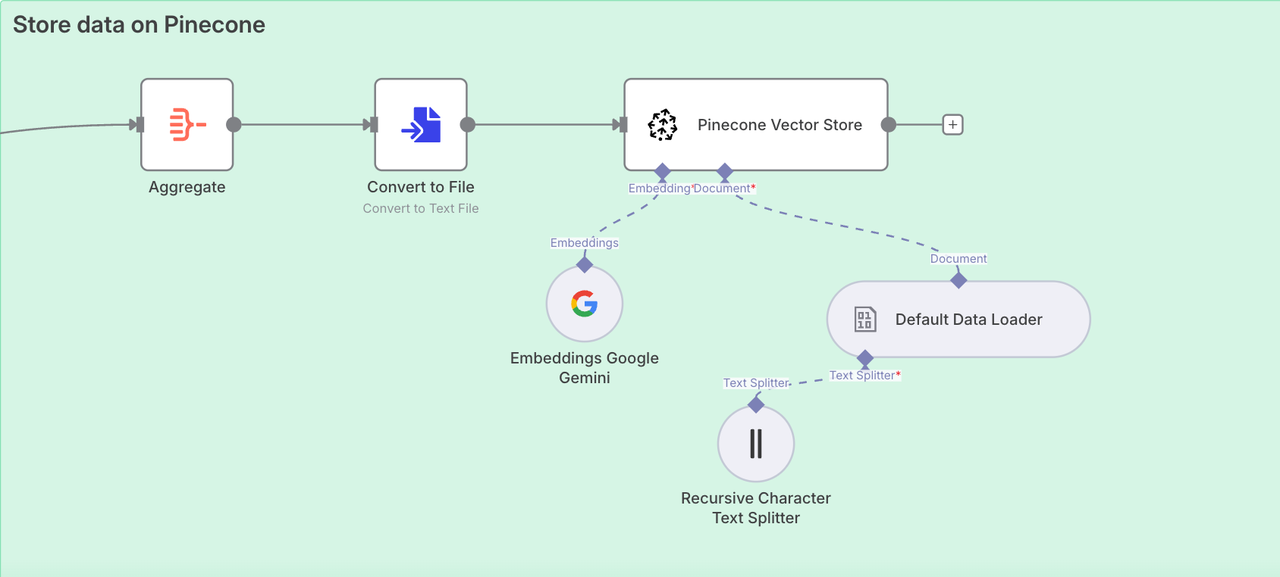
Nó: Agregar
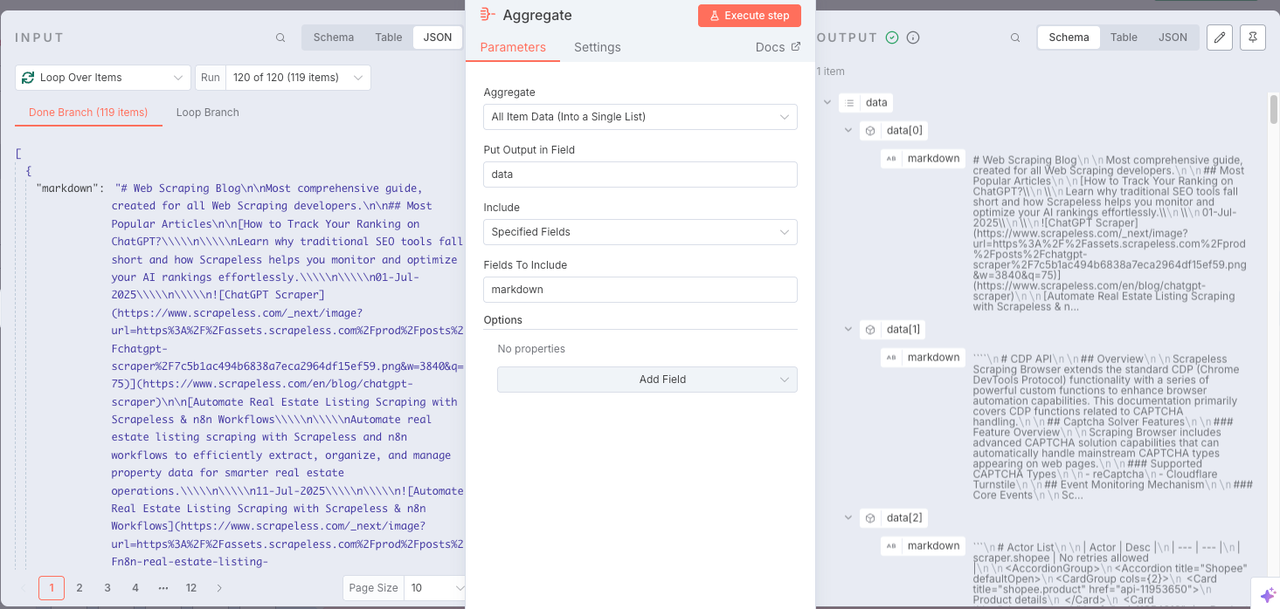
Para armazenar dados na base de conhecimento de forma conveniente, precisamos usar o nó Agregar para integrar todo o conteúdo.
- Agregar:
Todos os Dados dos Itens (Em uma Única Lista) - Colocar Saída no Campo:
data - Incluir:
Todos os Campos
Nó: Converter em Arquivo
Ótimo! Todos os dados foram integrados com sucesso. Agora precisamos converter os dados adquiridos em um formato de texto que pode ser lido diretamente pelo Pinecone. Para isso, basta adicionar um Converter para Arquivo.
Nó: Armazenamento de Vectores Pinecone
Agora precisamos configurar a base de conhecimento. Os nós utilizados são:
Armazenamento de Vetores PineconeGoogle GeminiCarregador de Dados PadrãoDivisória de Texto Recursiva de Caracteres
Os quatro nós acima irão integrar e rastrear os dados que obtivemos de forma recursiva. Então todos serão integrados à base de conhecimento do Pinecone.
Fase 3. Análise SERP usando IA
Para garantir que você esteja escrevendo conteúdo que classifique bem, realizamos uma análise SERP ao vivo:
- Use o Scrapeless Deep SerpApi para buscar resultados de pesquisa para a sua palavra-chave escolhida
- Insira tanto a palavra-chave quanto a intenção de busca (ex: Scraping, tendências do Google, API)
- Os resultados são analisados por um LLM e resumidos em um relatório HTML
Nó: Editar Campos
A base de conhecimento está pronta! Agora é hora de determinar nossas palavras-chave-alvo. Preencha as palavras-chave-alvo na caixa de conteúdo e adicione a intenção.
Nó: Pesquisa Google
O nó de Pesquisa Google chama o Deep SerpApi do Scrapeless para recuperar palavras-chave-alvo.
Nó: Cadeia LLM
Construir uma Cadeia LLM com Gemini pode nos ajudar a analisar os dados obtidos nas etapas anteriores e explicar ao LLM a entrada de referência e a intenção que precisamos usar para que o LLM possa gerar feedback que atenda melhor às necessidades.
Nó: Markdown
Uma vez que o LLM geralmente exporta em formato Markdown, como usuários não conseguimos obter diretamente os dados que precisamos de forma mais clara, então, por favor, adicione um nó Markdown para converter os resultados retornados pelo LLM em HTML.
Nó: HTML
Agora precisamos usar o nó HTML para padronizar os resultados - usar o formato Blog/Relatório para exibir intuitivamente o conteúdo relevante.
- Operação:
Gerar Modelo HTML
O seguinte código é necessário:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Resumo do Relatório</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>Relatório de Dados</h1>
<h2>Processado via Automação</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("Olá Mundo!");
</script>
</body>
</html>Este relatório inclui:
- Palavras-chave de alto ranqueamento e frases longas
- Tendências de intenção de busca do usuário
- Títulos e ângulos de blog sugeridos
- Agrupamento de palavras-chave
Fase 4. Gerando o Blog com IA + RAG
Agora que você coletou e armazenou o conhecimento e pesquisou suas palavras-chave, é hora de gerar seu blog.
- Construa um prompt usando insights do relatório SERP
- Chame um agente de IA (ex: Claude, Gemini ou OpenRouter)
- O modelo recupera o contexto relevante do Pinecone e escreve um post completo para o blog
Ao contrário da produção genérica de IA, o resultado aqui inclui ideias, frases e tom específicos do conteúdo original do Scrapeless — possibilitado pelo RAG.
Considerações Finais
Este motor de conteúdo SEO de ponta a ponta demonstra o poder de n8n + Scrapeless + Banco de Dados Vetorial + LLMs.
Você pode:
- Substituir a Página do Blog Scrapeless por qualquer outro blog
- Trocar Pinecone por outras lojas vetoriais
- Usar OpenAI, Claude ou Gemini como seu motor de escrita
- Construir pipelines de publicação personalizados (por exemplo, postar automaticamente no CMS ou Notion)
👉 Comece hoje instalando o nó da comunidade Scrapeless e comece a gerar blogs em escala — sem necessidade de codificação.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


