
Scrapelessで検出されないChromeDriverを設定する方法は?
Advanced Data Extraction Specialist
Undetected ChromeDriverがウェブスクレイピングのためのアンチボットシステムを回避する方法や、ステップバイステップのガイダンス、高度な手法、主要な制限事項を明らかにします。また、プロフェッショナルなスクレイピングニーズのためのより堅牢な代替手段であるScrapelessについても学びましょう。
このガイドでは、次のことを学びます:
- Undetected ChromeDriverとは何か、どのように役立つか
- ボット検出を最小限に抑える方法
- Pythonを使ったウェブスクレイピングの方法
- 高度な使用法と手法
- 主要な制限事項と欠点
- 推奨代替手段:Scrapeless
- アンチボット検出メカニズムの技術分析
さあ、始めましょう!
Undetected ChromeDriverとは?
Undetected ChromeDriverは、SeleniumのChromeDriverの最適化されたバージョンを提供するPythonライブラリです。これは、次のようなアンチボットサービスによる検出を制限するようにパッチされています:
- Imperva
- DataDome
- Distil Networks
- その他…
また、特定のCloudflare保護を回避するのにも役立ちますが、より難しい場合があります。
ブラウザ自動化ツール(Seleniumなど)を使用したことがあるなら、プログラム的にブラウザを制御できることを知っているでしょう。それを可能にするために、通常のユーザーセットアップとは異なる方法でブラウザを構成します。
アンチボットシステムは、これらの違いや「リーク」を見つけて自動化されたブラウザボットを特定します。Undetected ChromeDriverは、これらの証拠を最小限に抑えるためにChromeドライバをパッチし、ボット検出を減少させます。これにより、アンチスクレイピング対策で保護されたウェブサイトのウェブスクレイピングに最適です!
Undetected ChromeDriverはどのように機能するのか?
Undetected ChromeDriverは、以下のテクニックを使用してCloudflare、Imperva、DataDomeなどからの検出を減少させます:
- Selenium変数の名前を実際のブラウザで使用されるものに似せる
- 検出を避けるために正当な実世界のUser-Agent文字列を使用する
- ユーザーが自然な人間のインタラクションをシミュレートできるようにする
- ウェブサイトをナビゲートしながらクッキーやセッションを適切に管理する
- IPブロックを回避するためにプロキシを使用できるようにし、レート制限を防ぐ
これらの手法は、ライブラリが制御するブラウザが様々なアンチスクレイピング防御を効果的に回避するのに役立ちます。
Undetected ChromeDriverを使ったウェブスクレイピング:ステップバイステップガイド
ステップ1:前提条件とプロジェクトセットアップ
Undetected ChromeDriverには、以下の前提条件があります:
- 最新のChromeバージョン
- Python 3.6以上:Python 3.6以降がマシンにインストールされていない場合は、公式サイトからダウンロードし、インストール手順に従ってください。
注: このライブラリは自動的にドライバのバイナリをダウンロードしてパッチを適用するため、手動でChromeDriverをダウンロードする必要はありません。
プロジェクト用のディレクトリを作成します:
language
mkdir undetected-chromedriver-scraper
cd undetected-chromedriver-scraper
python -m venv env仮想環境をアクティブにします:
language
# LinuxまたはmacOSの場合
source env/bin/activate
# Windowsの場合
env\Scripts\activateステップ2:Undetected ChromeDriverのインストール
pipパッケージを介してUndetected ChromeDriverをインストールします:
language
pip install undetected_chromedriverこのライブラリは、自身の依存関係の一つであるSeleniumを自動的にインストールします。
ステップ3:初期セットアップ
scraper.pyファイルを作成し、undetected_chromedriverをインポートします:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Chromeインスタンスを初期化
driver = uc.Chrome()
# ターゲットページに接続
driver.get("https://scrapeless.com")
# スクレイピングロジック…
# ブラウザを閉じる
driver.quit()ステップ4:スクレイピングロジックの実装
次に、Appleページからデータを抽出するロジックを追加しましょう:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
import time
# Chromeウェブドライバーインスタンスを作成
driver = uc.Chrome()
# Appleのウェブサイトに接続
driver.get("https://www.apple.com/fr/")
# ページが完全に読み込まれるまで待機
time.sleep(3)
# 製品情報を格納する辞書
apple_products = {}
try:
# 製品セクションを見つける(提供されたHTMLのクラスを使用)
product_sections = driver.find_elements(By.CSS_SELECTOR, ".homepage-section.collection-module .unit-wrapper")
for i, section in enumerate(product_sections):
try:
# 製品名(見出し)を抽出
headline = section.find_element(By.CSS_SELECTOR, ".headline, .logo-image").get_attribute("textContent").strip()
# 説明(サブヘッド)を抽出
ja
subhead_element = section.find_element(By.CSS_SELECTOR, ".subhead")
subhead = subhead_element.text
# 利用可能なリンクを取得
link = ""
try:
link_element = section.find_element(By.CSS_SELECTOR, ".unit-link")
link = link_element.get_attribute("href")
except:
pass
apple_products[f"product_{i+1}"] = {
"name": headline,
"description": subhead,
"link": link
}
except Exception as e:
print(f"セクション {i+1} の処理中にエラーが発生しました: {e}")
# 収集したデータをJSON形式でエクスポート
with open("apple_products.json", "w", encoding="utf-8") as json_file:
json.dump(apple_products, json_file, indent=4, ensure_ascii=False)
print(f"{len(apple_products)} 件のApple製品を正常にスクレイピングしました")
except Exception as e:
print(f"スクレイピング中にエラーが発生しました: {e}")
finally:
# ブラウザを閉じてリソースを解放
driver.quit()実行方法:
language
python scraper.pyUndetected ChromeDriver: 高度な使用法
ライブラリの使い方がわかったので、もう少し高度なシナリオを探る準備が整いました。
特定のChromeバージョンを選択
ライブラリが使用する特定のChromeバージョンを指定するには、version_main引数を設定します:
language
import undetected_chromedriver as uc
# 対象のChromeバージョンを指定
driver = uc.Chrome(version_main=105)with構文
ドライバーが必要なくなったときにquit()メソッドを手動で呼び出すのを避けるために、with構文を使用できます:
language
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("https://example.com")
# 残りのコード...Undetected ChromeDriverの制限
undetected_chromedriverは強力なPythonライブラリですが、いくつかの既知の制限があります。
IPブロック
このライブラリは、IPアドレスを隠しません。データセンターからスクリプトを実行している場合、検出される可能性が高いです。同様に、自宅のIPの評判が悪い場合でもブロックされる可能性があります。
IPを隠すには、前述のように、制御されたブラウザをプロキシサーバーと統合する必要があります。
GUIナビゲーションのサポートがない
モジュールの内部動作のため、get()メソッドを使用してプログラム的にブラウジングする必要があります。手動ナビゲーションのためにブラウザGUIを使用することは避けてください。キーボードやマウスでページと対話すると、検出のリスクが高まります。
ヘッドレスモードのサポートが限られている
公式には、undetected_chromedriverライブラリではヘッドレスモードが完全にはサポートされていません。ただし、以下のように試してみることができます:
language
driver = uc.Chrome(headless=True)安定性の問題
結果はさまざまな要因によって異なる場合があります。検出アルゴリズムを理解して対抗するために継続的な努力を行っている限り、保証はありません。今日、ボット対策システムを回避できたスクリプトも、保護方法の更新により明日失敗する可能性があります。
おすすめの代替: Scrapeless
Undetected ChromeDriverの制限を考慮すると、Scrapelessはブロックされることなくウェブスクレイピングを行うためのより堅牢で信頼性の高い代替手段を提供します。
私たちはウェブサイトのプライバシーを厳重に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモンストレーションとしてのみ使用されます。情報やデータは保存しません。
なぜScrapelessが優れているのか
Scrapelessは、Undetected ChromeDriverアプローチの固有の問題に対処するリモートブラウザサービスです:
-
定期的なアップデート: Undetected ChromeDriverがボット対策システムのアップデート後に機能しなくなる可能性があるのに対し、Scrapelessはチームによって継続的に更新されます。
-
組み込みのIPローテーション: Scrapelessは自動IPローテーションを提供し、Undetected ChromeDriverのIPブロックの問題を解消します。
-
最適化された構成: Scrapelessブラウザは検出を避けるように最適化されており、プロセスが大幅に簡素化されます。
-
自動CAPTCHA解決: Scrapelessは遭遇する可能性のあるCAPTCHAを自動的に解決できます。
-
複数のフレームワークと互換性: Playwright、Puppeteer、その他の自動化ツールと連携して動作します。
Scrapelessにサインインして無料トライアルをお試しください。
おすすめの読み物: PuppeteerでCloudflareをバイパスする方法
ブロックされることなくScrapelessを使用してウェブをスクレイピングする方法
Scrapelessを使用してPlaywrightで同様のソリューションを実装する方法は次のとおりです:
ステップ1: Scrapelessに登録してログインする。
ステップ2: Scrapeless API KEYを取得する
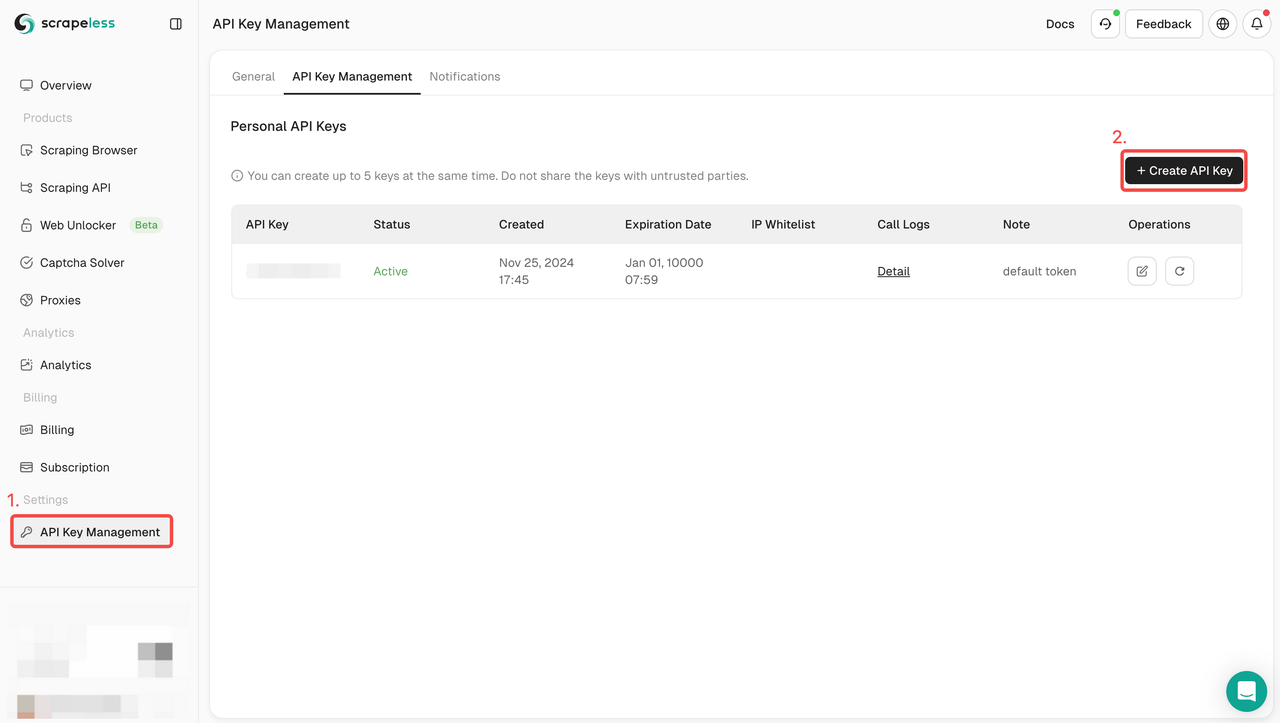
ステップ3: 次のコードをプロジェクトに統合できます
```language
const {chromium} = require('playwright-core');
// Scrapeless接続URLとあなたのトークン
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
// リモートScrapelessブラウザに接続する
const browser = await chromium.connectOverCDP(connectionURL);
try {
// 新しいページを作成
const page = await browser.newPage();
// Appleのウェブサイトに移動
console.log('Appleのウェブサイトに移動中...');
await page.goto('https://www.apple.com/fr/', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
console.log('ページが正常に読み込まれました');
// 商品セクションが利用可能になるのを待つ
await page.waitForSelector('.homepage-section.collection-module', { timeout: 10000 });
// ホームページから特集商品を取得
const products = await page.evaluate(() => {
const results = [];
// すべての商品セクションを取得
const productSections = document.querySelectorAll('.homepage-section.collection-module .unit-wrapper');
productSections.forEach((section, index) => {
try {
// 商品名を取得 - .headlineまたは.logo-imageの中にある可能性があります
const headlineEl = section.querySelector('.headline') || section.querySelector('.logo-image');
const headline = headlineEl ? headlineEl.textContent.trim() : '不明な商品';
// 商品の説明を取得
const subheadEl = section.querySelector('.subhead');
const subhead = subheadEl ? subheadEl.textContent.trim() : '';
// 商品のリンクを取得
const linkEl = section.querySelector('.unit-link');
const link = linkEl ? linkEl.getAttribute('href') : '';
results.push({
name: headline,
description: subhead,
link: link
});
} catch (err) {
console.error(`セクション${index}の処理中にエラーが発生しました: ${err.message}`);
}
});
return results;
});
// 結果を表示
console.log('見つかったApple製品:');
console.log(JSON.stringify(products, null, 2));
console.log(`見つかった商品総数: ${products.length}`);
} catch (error) {
console.error('エラーが発生しました:', error);
} finally {
// ブラウザを閉じる
await browser.close();
console.log('ブラウザが閉じました');
}
})();また、ScrapelessのDiscordに参加して、開発者サポートプログラムに参加し、最大500k SERP API使用クレジットを無料で受け取ることができます。
強化された技術分析
ボット検出: その仕組み
アンチボットシステムは、いくつかの技術を使用して自動化を検出します:
-
ブラウザフィンガープリンティング: 設定された数十のブラウザプロパティ(フォント、キャンバス、WebGLなど)を収集して、一意の署名を作成します。
-
WebDriver検出: WebDriver APIまたはそのアーティファクトの存在を検出します。
-
行動分析: マウスの動き、クリック、タイプ速度を分析して、ヒトとボットの違いを検出します。
-
ナビゲーション異常検出: あまりにも速いリクエストや画像/CSSの読み込みがないなどの疑わしいパターンを特定します。
推奨読書: アンチボットを回避する方法
Undetected ChromeDriverが検出を回避する方法
Undetected ChromeDriverは、以下の方法でこれらの検出を回避します:
-
WebDriverインジケーターの削除:
navigator.webdriverプロパティやその他のWebDriverの痕跡を排除します。 -
Cdc_のパッチ処理: ChromeDriverの既知の署名であるChrome Driver Controller変数を変更します。
-
現実的なユーザーエージェントの使用: デフォルトのユーザーエージェントを最新の文字列に置き換えます。
-
設定の変更を最小限に抑える: Chromeブラウザのデフォルトの動作への変更を減らします。
Undetected ChromeDriverがドライバーをパッチ処理する方法を示す技術コード:
language
Undetected ChromeDriverソースコードからの簡略化された抜粋
def _patch_driver_executable():
"""
自動化の兆候を取り除くためにChromeDriverバイナリをパッチ処理します。
"""
linect = 0
replacement = os.urandom(32).hex()
with io.open(self.executable_path, "r+b") as fh:
for line in iter(lambda: fh.readline(), b""):
if b"cdc_" in line.lower():
fh.seek(-len(line), 1)
newline = re.sub(
b"cdc_.{22}", b"cdc_" + replacement.encode(), line
)
fh.write(newline)
linect += 1
return linectなぜScrapelessがより効果的なのか
Scrapelessは次のような異なるアプローチを取ります。
-
事前設定された環境:人間のユーザーを模倣するために最適化されたブラウザを使用します。
-
クラウドベースのインフラストラクチャ:適切なフィンガープリンティングでクラウド上でブラウザを実行します。
-
インテリジェントなプロキシローテーション:ターゲットサイトに基づいてIPを自動的にローテーションします。
-
高度なフィンガープリンティング管理:セッション全体で一貫したブラウザのフィンガープリンティングを維持します。
-
WebRTC、Canvas、およびプラグインの抑制:一般的なフィンガープリンティング手法をブロックします。
Scrapelessにサインインして無料トライアルをお試しください。
結論
この記事では、Undetected ChromeDriverを使用してSeleniumにおけるボット検出への対処方法を学びました。このライブラリはブロックされることなくウェブスクレイピングを行うためのパッチ適用版のChromeDriverを提供します。
課題は、Cloudflareなどの高度なアンチボット技術があなたのスクリプトを検出し、ブロックすることができることです。undetected_chromedriverのようなライブラリは不安定であり、今日うまくいっても明日はうまくいかないかもしれません。
プロフェッショナルなスクレイピングニーズには、Scrapelessのようなクラウドベースのソリューションがより堅牢な代替手段を提供します。彼らはアンチボット対策を回避するために特別に設計された事前設定されたリモートブラウザを提供し、IPローテーションやCAPTCHA解決などの追加機能を備えています。
Undetected ChromeDriverとScrapelessの選択は、あなたの具体的なニーズに依存します:
- Undetected ChromeDriver:小規模なプロジェクトに適しており、無料かつオープンソースですが、より多くの維持管理が必要で、信頼性が低い場合があります。
- Scrapeless:プロフェッショナルなスクレイピングニーズにより適しており、信頼性が高く、常に更新されますが、サブスクリプションコストがかかります。
これらのアンチボット回避技術がどのように機能するかを理解することで、ウェブスクレイピングプロジェクトに適したツールを選び、自動データ収集の一般的な落とし穴を避けることができます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


