
Scrapelessを使ってAmazonのデータをスクレイプする方法は?
Advanced Data Extraction Specialist
アマゾンで競争優位性を得たいですか?価格を追跡したり、製品トレンドを分析したり、市場調査を行ったりする際、先に進むための鍵は、アマゾンデータを効果的にスクレイピングすることです。しかし、アマゾンから有用な情報を抽出することは難しい場合があります。特に、サイト構造の頻繁な変更、ボット対策、IPブロッキングがあるためです。そこで、Amazon Scraping API が登場します。このガイドでは、Pythonを使ってアマゾンの製品データをスクレイピングする方法を紹介し、世界最大のeコマースプラットフォームから価値あるデータや情報を収集するのをさらに簡単にします。
アマゾンスクレイピングAPIとは?
アマゾンウェブスクレイピングAPI は、アマゾンデータを収集するのに役立つリモートサーバーのようなものです。操作は簡単で、ターゲットURLやジオロケーションなどの他のパラメーターを含むリクエストをAPIエンドポイントに送信します。APIはその後、あなたのためにウェブサイトを訪れます。
アマゾンがクローリングをサポートするデータタイプ:
1. 製品:
-
製品情報: クローリング可能なコンテンツには、製品名、説明、価格、画像URL、ASIN(Amazon標準識別番号)、ブランドなどの基本情報が含まれます。
-
売上データ: 製品のランキング、販売量、コメントなど。
2. セラー:
- セラー情報: セラーの名前、商人ID、販売している製品に関する関連情報を取得できます。
- セラーランキング: 異なるセラーから製品をクローリングすることで、各セラーの市場パフォーマンスと特定のカテゴリにおける競争力を分析できます。
3. キーワード:
- キーワード検索結果: 特定のキーワード(「ラップトップ」や「アニメフィギュア」など)に基づいて関連する製品リストとその詳細情報をクローリングできます。
アマゾンスクレイピングの一般的な使用ケース
アマゾンスクレイピングは、ビジネスやマーケターにさまざまな目的で役立ちます:
1. 価格モニタリング: 製品価格をスクレイピングすることで、競合の価格を追跡し、自社の戦略を調整できます。
2. 製品研究: レビュー、評価、製品詳細をスクレイピングすることで、トレンド商品を特定し、顧客の好みを理解します。
3. 売上最適化: マーケターは、製品説明やプロモーションをスクレイピングしてコンテンツを改善し、効果的なキャンペーンを作成します。
4. 在庫レベルの追跡: リアルタイムの製品在庫データをスクレイピングすることで、ビジネスは在庫レベルや需要を監視できます。
5. 顧客の感情分析: アマゾンからスクレイピングしたレビューは、顧客満足度や改善すべき領域についての洞察を提供します。
要するに、アマゾンスクレイピングは競争分析、製品研究、マーケティング戦略を効率化します。
アマゾンスクレイピングの主な課題(例:CAPTCHA、レート制限)
- CAPTCHAチャレンジ
アマゾンは自動クローリングを防ぐためにCAPTCHA認証を使用しています。特に、大量の短時間リクエストが検出された場合。このような認証は、ユーザーに人間であることを確認させる必要があり、自動ツールがデータを取得するのを妨げます。
アマゾンにはリクエスト頻度の制限があります。あまりに頻繁にアクセスすると、システムが自動的に応答を遅らせたり、一時的にさらなるリクエストをブロックしたりします。これにより、クローリングプロセスが遅く、不安定になります。
ヒント: 一般のユーザーには、アマゾンは通常、1分あたり数十から数百のリクエストを許可しています。この頻度を超えると、遅延や一時的なブロックが発生する可能性があります。アマゾンは、頻繁なクローリングリクエストに対してより厳しい制限を設定する場合があります。
- IPブロッキング
非常に頻繁なクローリングは、アマゾンがIPアドレスを一時的にブロックする原因となることがあります。IPアドレスが異常なソースとしてマークされると、クローリング操作は完全にブロックされ、IPを変更するか、プロキシプールを使用してこの制限を回避する必要があります。一般的に言えば、1秒あたり5〜10のリクエストはリスクを引き起こす可能性があります。
- 動的コンテンツの読み込み
アマゾンページのコンテンツは通常、JavaScriptを通じて動的に読み込まれます。つまり、クローリング時にページレンダリングプロセスの追加処理が必要です。従来のHTMLクローリング方法では、動的に読み込まれたデータを直接取得できない場合がよくあります。
- 頻繁なレイアウト変更
アマゾンウェブサイトのページレイアウトは頻繁に変更されるため、クローリングスクリプトに挑戦がもたらされます。クローリングツールは、データ抽出の正確性と安定性を確保するために、ページの更新や変更に適応するように常に更新する必要があります。
Python環境の設定
Pythonでコードを書く前に、まず開発環境を設定する必要があります。このステップでは、Pythonコードを記述して実行するために必要なすべてのツールとライブラリを揃えることができます。このセクションでは、Pythonのインストール、仮想環境の設定、および作業フローを効率化するための統合開発環境(IDE)の構成手順をご案内します。
Pythonを使用するために、以下の構成をダウンロードする必要があります
1. Python: https://www.python.org/downloads/ これはPythonを実行するためのコアソフトウェアです。必要なバージョンを公式ウェブサイトからダウンロードできますが、最新バージョンをダウンロードすることはお勧めしません。最新のバージョンの最初の1〜2バージョンをダウンロードすることをお勧めします。
2. Python IDE: Pythonをサポートする任意のIDEで構いませんが、特にPython用に設計されたIDE開発ツールソフトウェアであるPyCharmの使用をお勧めします。PyCharmのバージョンとしては、無料のPyCharm Community Editionを使用することをお勧めします。
3. pip: Python Package Index(PyPi)を使用して、一つのコマンドでライブラリをインストールできます。
注意: Windowsユーザーの場合、インストールウィザードで「Add python.exe to PATH」オプションにチェックを入れるのを忘れないでください。こうすることで、WindowsはターミナルでPythonとコマンドを使用できるようになります。ちなみに、Python 3.4以降はデフォルトで含まれているため、手動でインストールする必要はありません。
Pythonプロジェクトの初期化
PyCharmを起動し、メニューバーの「ファイル」>「新しいプロジェクト...」オプションを選択します。

次にポップアップウィンドウが開きます。左側のメニューから「Pure Python」を選択し、次のようにプロジェクトを設定します:
注意: 下の赤いボックスでは、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択してください。
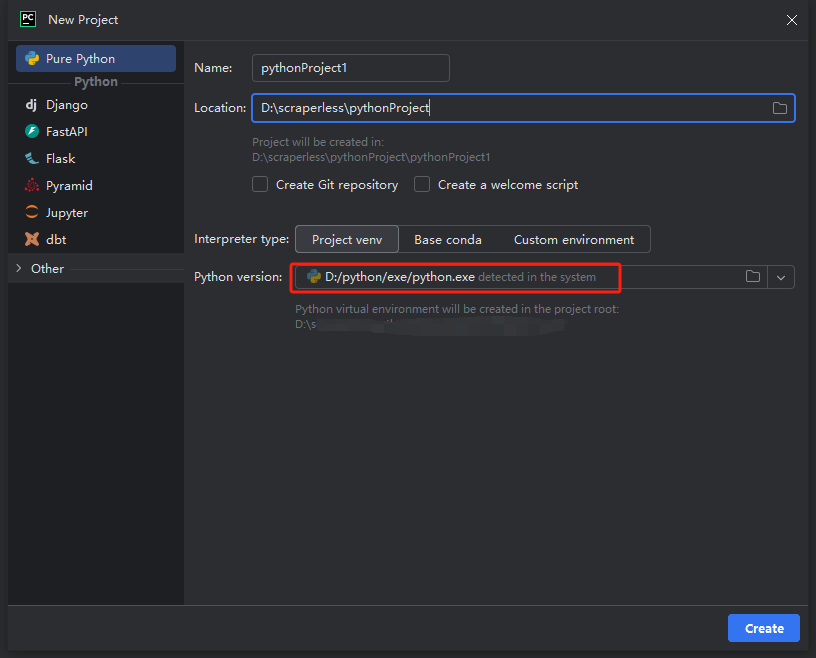
「python-scraper」という名前のプロジェクトを作成し、フォルダ内の「メイン.pyウェルカムスクリプトオプションを作成」にチェックを入れ、作成ボタンを押します。
PyCharmがプロジェクトを設定するのを待っていると、以下のような画面が表示されるはずです。
次に、右クリックして新しいPythonファイルを作成します。
すべてが正常に機能しているか確認するために、画面の下部にあるターミナルタブを開き、python main.pyと入力します。このコマンドを実行すると、「Hi, PyCharm」というメッセージが表示されるはずです。
scraperlessにあるコードを直接PyCharmにコピーして実行することで、Amazon商品データのJSON形式を取得できます。
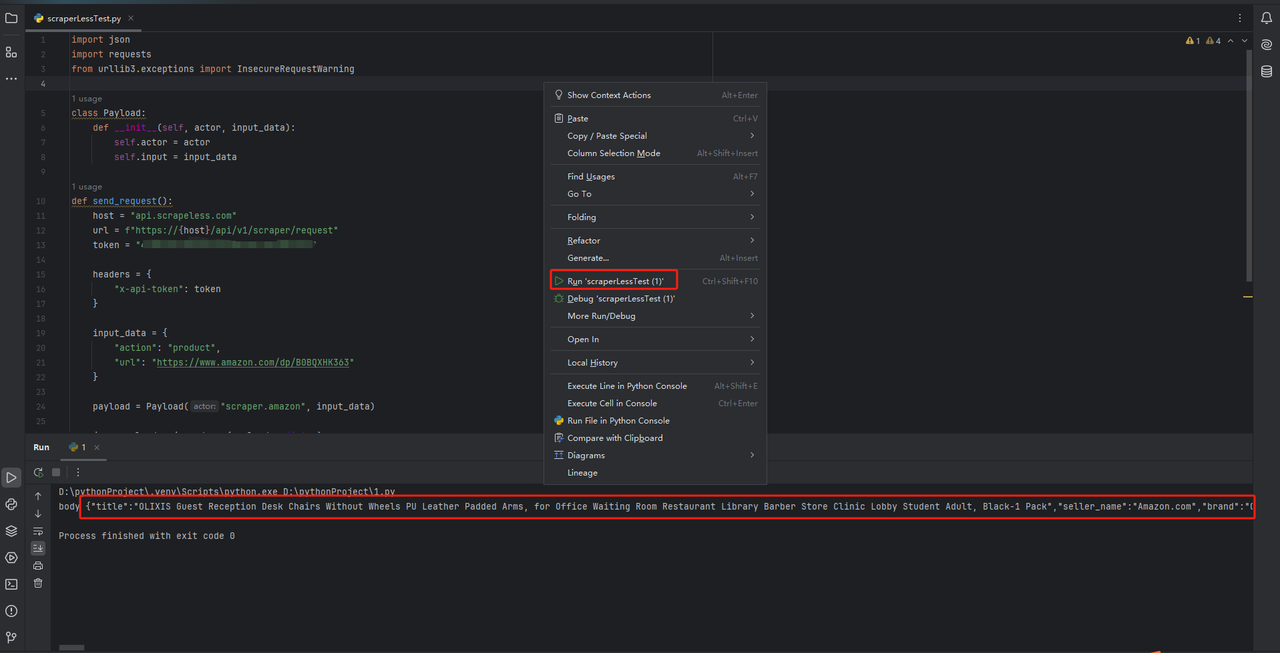
ステップバイステップガイド:Amazon商品データのスクレイピング
上記の通り、Amazonのウェブスクレイピングに必要な環境を設定した後は、ScrapelessのPythonコードを統合できます。
Amazon商品データをスクレイピングする方法
Scrapeless APIドキュメンテーションを直接訪れて、より完全なAPIコード情報を取得し、その後ScrapelessのPythonコードをプロジェクトに統合できます。
リクエストサンプル - 商品
python
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Amazonの販売者情報をスクレイピングする方法
同様に、Scrapeless APIのコードをスクレイピングセットアップに統合することで、Amazonのスクレイピングの障壁を回避し、Amazonの販売者情報をスクレイピングできます。
リクエストサンプル - 販売者
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
json
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
## Amazonキーワード検索結果をスクレイピングする方法
上記の手順に従って、リクエストサンプル - キーワードをプロジェクトに統合し、Amazonキーワード検索結果を取得します。
**リクエストサンプル - キーワード**
```import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))簡単な統合と構成を通じて、Scrapelessは、より効率的な方法でAmazonデータを取得するのを助けます。製品、販売者、キーワード情報など、Amazonプラットフォーム上の重要なデータを簡単にクロールできるため、データ分析の精度とリアルタイム性を向上させることができます。
Amazonデータをスクレイピングすることに関するよくある質問
1. Amazonデータをスクレイピングすることは合法ですか?
公開されている製品情報(タイトル、説明、価格、評価など)をスクレイピングすることは合法ですが、プライベートアカウントデータをスクレイピングすることはプライバシーの問題を引き起こす可能性があります。また、スクレイピングデータを市場調査や競合分析に使用することは一般的に「フェアユース」と見なされます。
2. Amazonからどのようなデータをスクレイピングできますか?
AmazonスクレイピングAPIを使用することで、製品、販売者、レビューなどに関連するデータを抽出できます。これには、商品名、価格、ASIN(Amazon標準識別番号)、ブランド、説明、仕様、カテゴリ、ユーザーレビューとその評価が含まれます。
3. Amazonデータを効果的にクロールする方法は?
Amazonデータを効果的にクロールする方法には、自動化されたスクリプトまたはAPIを使用し、Amazonの利用規約に従うことが含まれます。ブロックされないようにするためには、リクエストの頻度を減らし、負荷を適切にコントロールすることをお勧めします。また、キャプチャソリューションを使用することで、クロールの成功率を高めることができます。
結論:ベストなAmazonスクレイピングAPIプロバイダー
この記事の紹介を通じて、Pythonを使用してAmazon上の製品データを効率的にクロールする方法を習得しました。製品詳細、価格情報、レビューデータを取得するかに関わらず、Pythonの力と柔軟性は自動クロールをより簡単かつ効率的にします。しかし、大規模なデータをクロールする際には、対クローラー機構との課題に直面するかもしれません。その際、Scrapelessは、インテリジェントなウェブクロールソリューションとして、これらの障害を回避し、よりスムーズで効率的なクロールプロセスを確保するのに役立ちます。データクロールの速度と安定性を向上させたい場合は、ぜひScrapelessの使用を試してみて、クロールのワークフローをさらに最適化してください。
Scrapeless Discordコミュニティに参加しよう!🚀 データ愛好家とつながり、より迅速かつスマートにスクレイピングするための独占的なヒントを入手し、最新の機能について最新情報を受け取ろう。初心者でもプロでも、ここにはあなたの場所があります。リンクをクリックして、今すぐ参加を始めましょう!👾 今すぐ参加
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


