
Scrapelessのスクレイピングブラウザを使ったウェブページのスクレイピング方法
Advanced Data Extraction Specialist
Scrapelessのスクレイピングブラウザを選んでWebスクレイピングを行う理由とは?
Webスクレイピングは、競合他社の価格から市場トレンドまで、リアルタイムデータ収集のために企業にとって不可欠なツールとなっています。最近のStatistaの調査によると、70%以上の企業が貴重なデータ抽出にWebスクレイピングに依存しており、データに基づいた意思決定において重要な役割を果たしています。
Webスクレイピング市場は成長を続け、2025年までに54億ドルに達すると予測されています(MarketsandMarkets)。企業は、その効率性とスケーラビリティのために、スクレイピングツールをますます採用しています。しかし、IPブロック、CAPTCHA、動的コンテンツなどの課題がスクレイピングプロセスを妨げる可能性があります。
Scrapelessは、AI駆動型のソリューションでこれらの問題を解決し、一般的なアンチスクレイピング対策があってもシームレスなデータ抽出を保証します。
Scrapelessのスクレイピングブラウザで、今日からよりスマートなスクレイピングを始めましょう!ユーザーフレンドリーなツールで、複雑なWebページからも簡単にデータを抽出できます。今すぐお試しになり、かつてないシームレスなデータ抽出を体験してください!
Scrapelessは、企業がこれらの一般的な障害を克服するのに役立つように設計された、高度なAI駆動型のWebスクレイピングソリューションを提供します。Scrapelessツールキットは、Webから高品質で信頼性の高い高速なデータ抽出を求めるユーザー向けに調整されています。eコマースサイト、ソーシャルメディアプラットフォーム、ニュースアグリゲーターからスクレイピングする必要がある場合でも、Scrapelessは作業を完了するための適切なツールを提供します。
Scrapelessの主な利点:
- シームレスなプロキシ管理:IPローテーションとグローバルカバレッジでスクレイピングセッションを保護します。
- AI駆動型CAPTCHAソリューション:CAPTCHAの課題を自動的に解決して、データ収集の中断を回避します。
- 高度なブラウザテクノロジー:複雑で動的なWebページをエラーなくナビゲートします。
- スケーラブルなソリューション:小規模なデータ抽出タスクから大規模なスクレイピング操作まで、Scrapelessはニーズに合わせてスケーリングできます。
Scrapelessは、単なるスクレイピングツールではありません。Webスクレイピングに関連する主要な課題を解決し、データ収集を高速、効率的、かつ信頼性の高いものにする包括的なプラットフォームです。スタートアップ企業でも大企業でも、Scrapelessの柔軟性により、スクレイピングタスクを特定のニーズに合わせてカスタマイズできます。プロキシ管理から、動的コンテンツを含む複雑なWebサイトの処理まで、ScrapelessはWebスクレイピング操作を簡素化し、貴重な時間を節約するために必要なすべてのツールを提供します。
Scrapelessスクレイピングブラウザ:
Scrapeless Webスクレイピングソリューションの中核は、スクレイピングブラウザです。Scrapelessのスクレイピングブラウザは、最も困難なスクレイピングシナリオを処理するために最適化されており、Scrapelessツールキットとシームレスに統合して、優れたスクレイピングエクスペリエンスを提供します。
Scrapelessスクレイピングブラウザの主な機能:
- 🌐 動的コンテンツ処理:他のツールでは苦労するような、JavaScriptと動的コンテンツを多く使用するWebサイトを簡単にスクレイピングできます。
- 🖥️ ヘッドレスモード:フルブラウザウィンドウを起動せずにスクレイピングタスクを実行し、パフォーマンスを向上させ、リソースの使用を削減します。
- 🛡️ アンチ検知テクノロジー:ブラウザフィンガープリントやステルスモードなどの高度な技術で検知を防ぎます。
- ⚡ 優れた効率性:従来のブラウザモードよりも10倍高速で、サーバー側で実行されるため、応答時間が短縮され、大規模な同時アクセスがサポートされます。
- ⏱️ 99.99%のアップタイム:信頼性の高い24時間365日の可用性により、スクレイピングタスクは常に予定どおりに実行されます。
Scrapelessのスクレイピングブラウザを使用すると、データ抽出プロセスがより高速で、より信頼性が高く、より簡単になり、スクレイピングの技術的な課題に対処するのではなく、貴重な洞察の抽出に集中できます。
Scrapelessのスクレイピングブラウザの始め方
APIキー(アプリケーションプログラミングインターフェースキー)は、IDを確認し、APIへのアクセスを承認するために使用されるツールです。通常は、文字、数字、記号の一意の文字列です。APIキーは、APIにアクセスする際の認証「パス」として機能し、要求が正当なユーザーまたはアプリケーションによって行われたことを保証します。
✅ 以下の手順に従ってAPIキーを取得できます。
- **Scrapelessにログイン**をクリックすると、対応するAPIキーを自動的に取得できます。
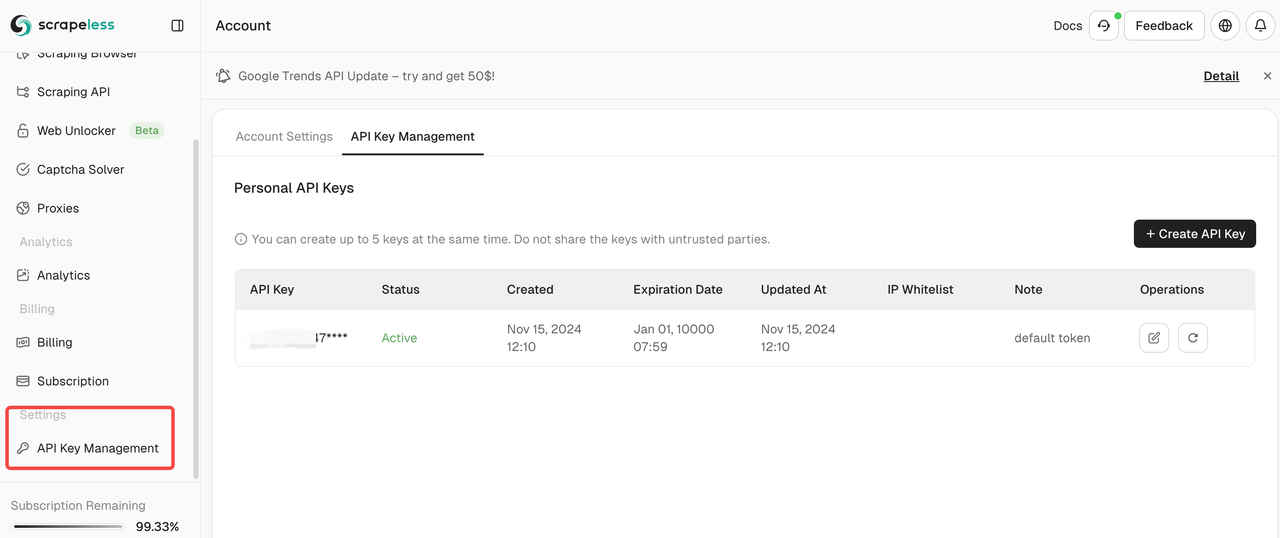
- APIキー管理でAPIキーを確認できます。
Scrapelessを使用したWebページスクレイピングの手順ガイド
このセクションでは、scrapeless + puppeteerを使用して、Amazonで製品コンテンツをクロールする方法を示します。
Puppeteerは、Googleによって開発されたNode.jsライブラリで、ChromiumまたはChromeブラウザを通じて自動操作を実行するための高レベルAPIを提供します。人間のユーザーのようにブラウザを操作し、クリック、入力、ナビゲーションなどを実行でき、ページコンテンツのクロール、スクリーンショットやPDFの生成、Webページのテストなども実行できます。
まず、APIキーscrapelessを取得する必要があります。APIキーの取得と表示方法については、前のセクションを参照してください。
Scrapelessを使用したWebページスクレイピングの手順ガイド:
- npmコマンドを使用してpuppeteerをインストールします。
npm i puppeteer-core- scrapelessの接続パラメーターを準備します。セッション時間とプロキシ国の設定を行うことができます。
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- Amazonでの製品データのクロール準備を始めます。
- ブラウザの開発者ツール(F12)を使用して入力ボックスと検索要素を取得し、要素のセレクターを取得します。
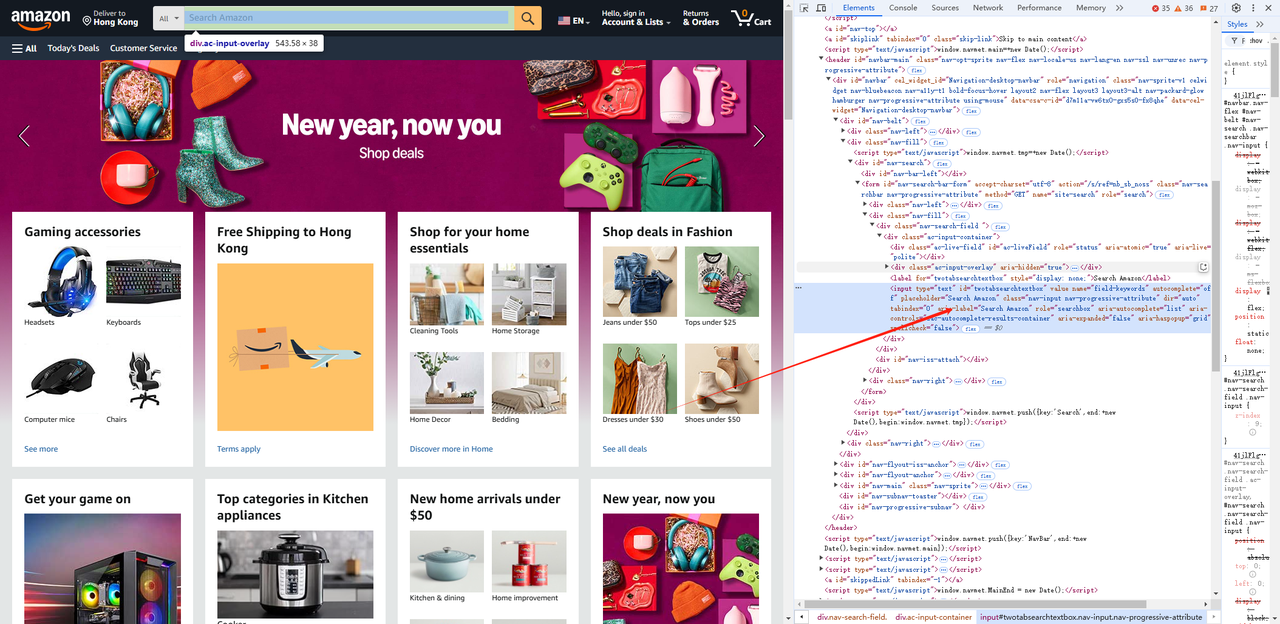
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')iphone 15はクロールしたいコンテンツに置き換えることができます。
- 次に製品一覧ページにアクセスし、role属性がlistitemであるすべてのdiv要素を取得します。
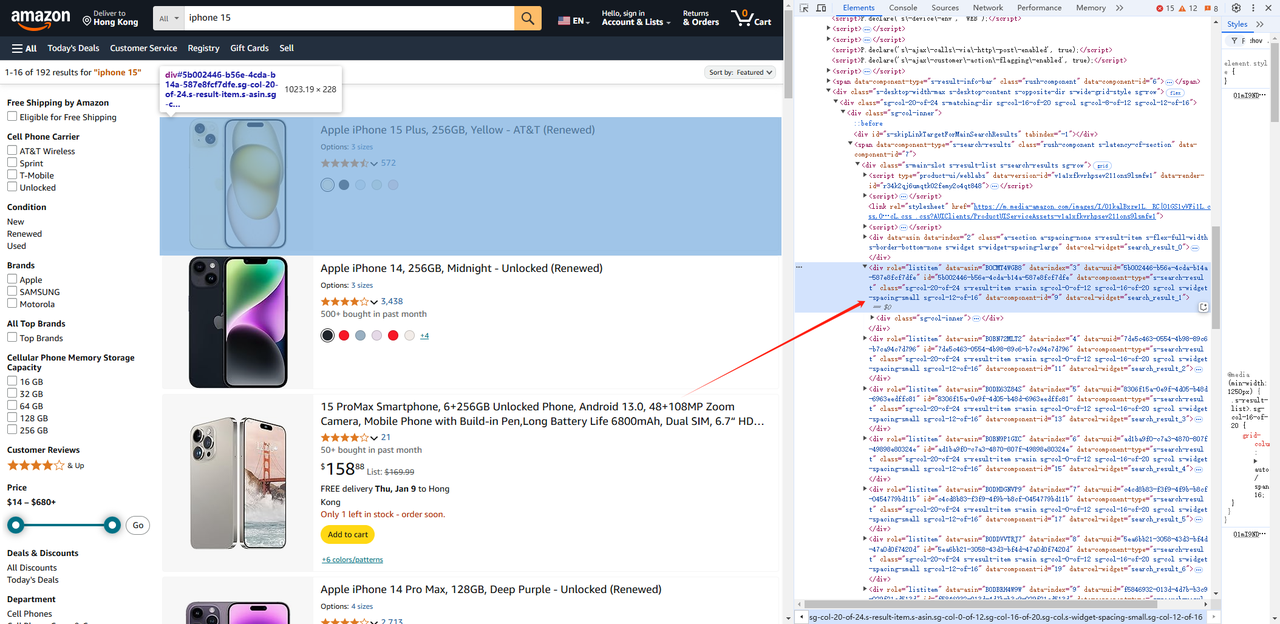
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // 要素がレンダリングされるのを待つ必要があります
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- 同様にして、各要素について画像、タイトル、リンクなどの製品情報を取得できます。
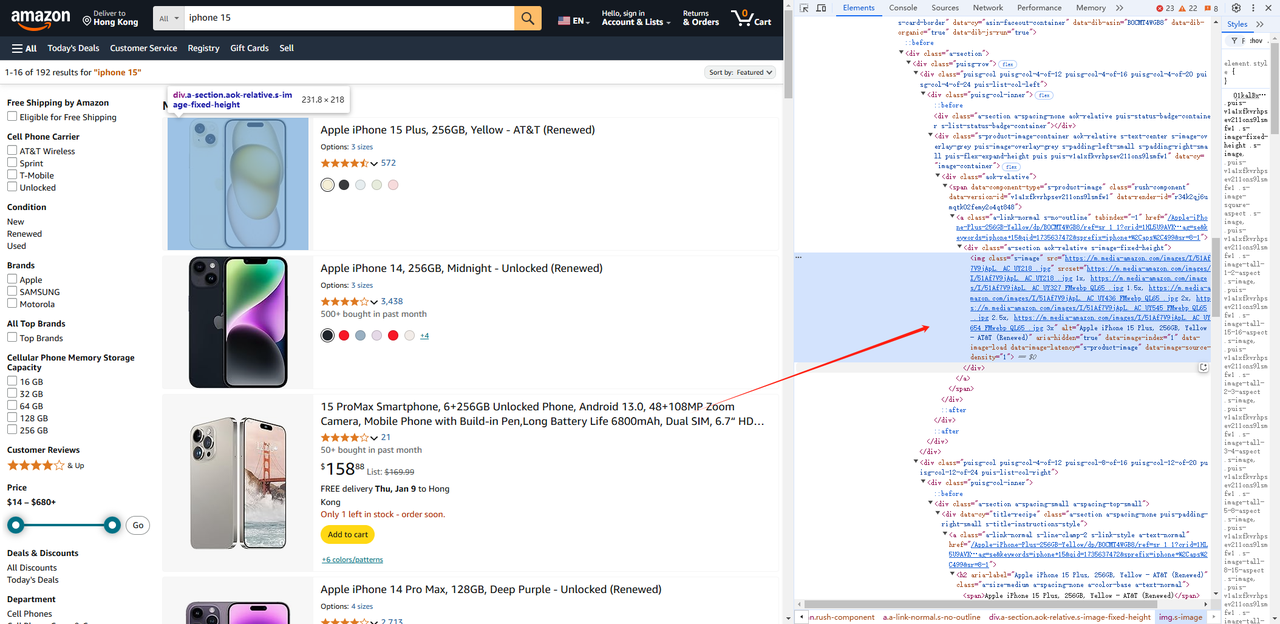
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
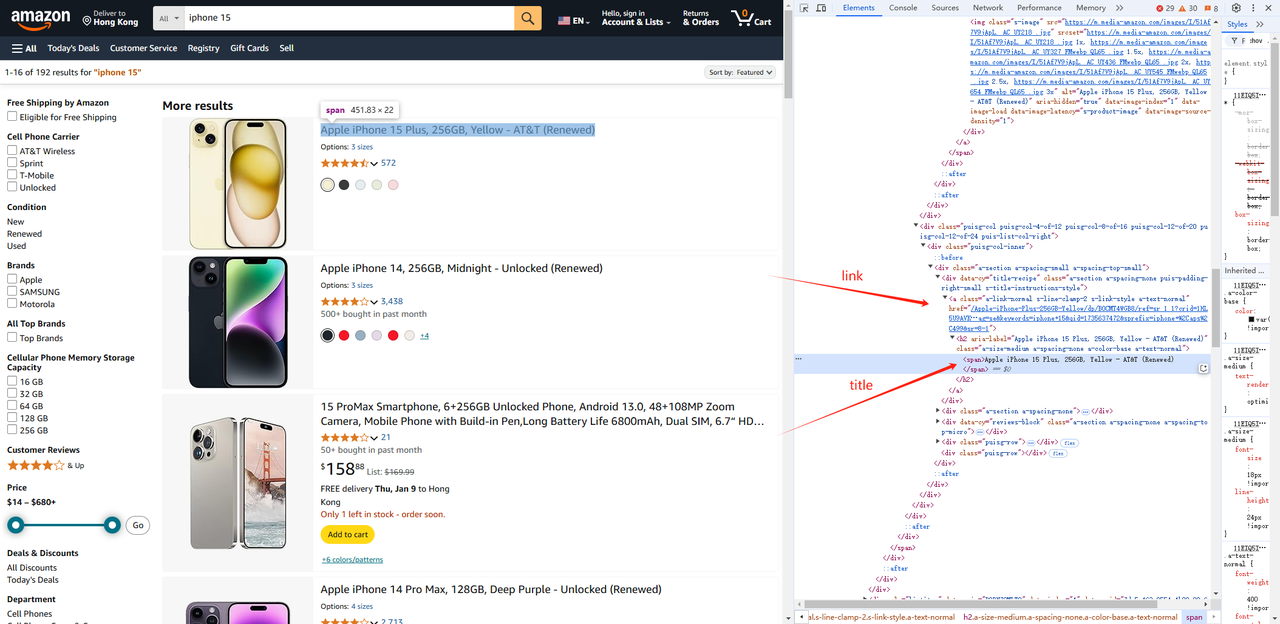
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}以下の完全なコードを実行して、クロールされたコンテンツを取得します。
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]パワーツーザー向け高度な機能
大規模または複雑なWebスクレイピング操作を行う場合、効率を維持し、障害を克服し、スクレイピングタスクをスケーリングするには、高度な機能が不可欠です。Scrapelessスクレイピングブラウザは、基本的なスクレイピング機能以上のものが必要なプロフェッショナルユーザーのニーズを満たすための強力な機能の範囲を提供し、いくつかの高度な機能も提供しています。
- 特定のユースケースに合わせてスクレイピングパラメーターをカスタマイズする
Webスクレイピングの主な課題の1つは、不要なデータの生成や機会の損失を招くことなく、必要なものを正確に抽出するようにツールを調整することです。Scrapelessは、ユーザーが特定のスクレイピングパラメーターを設定して、正確なユースケースに適合させることができる高度なカスタマイズオプションを提供します。
- CAPTCHAとアンチスクレイピング保護に対処する
Webサイトは、自動化されたロボットをブロックするために、CAPTCHAの課題と複雑なアンチスクレイピングメカニズムを展開することがよくあります。Scrapelessスクレイピングブラウザは、CAPTCHAのブロック解除機能を備えたクラウドベースのフィンガープリンティングブラウザです。これらの高度なソリューションは、データ収集の速度を向上させるだけでなく、強力なアンチボット対策を備えたWebサイトによって検出またはブロックされる可能性を低減します。
- スケーラビリティのためにプロキシとローテーションを使用し、IP禁止を回避する
スクレイピング操作を拡大すると、WebサイトがIPを禁止し、レートを制限することが多く、データ収集が中断されます。この問題を軽減するために、Scrapelessは強力なプロキシネットワークを提供しており、IPローテーションとプロキシプールが含まれており、中断することなく、継続的な大規模クロールを維持するのに役立ちます。Scrapelessは、200カ国以上から8,000万を超えるIPアドレスの膨大なプロキシネットワークへのアクセスを提供し、ユーザーがリクエストを分散してIP禁止を回避できるようにします。
効果的なWebスクレイピングのベストプラクティス
Webスクレイピングは、Webから貴重なデータを取得しようとしている企業にとって強力なツールです。ただし、データを効率的に抽出し、一般的な落とし穴を回避するには、ベストプラクティスに従うことが重要です。ScrapelessなどのAI駆動型ソリューションを活用することで、企業はスクレイピング戦略を強化し、正確性、コンプライアンス、およびスケーラビリティを確保できます。Scrapelessがこれらのプロセスを最適化する方法を含め、Webスクレイピングのベストプラクティスの概要を以下に示します。
データの正確性と完全性を確保する
Webスクレイピングの主な課題の1つは、収集されたデータの正確性を確保することです。さまざまなソースから大規模なデータセットを抽出する場合、データの欠落や不整合などの問題が発生しやすくなります。これに対処するために、ScrapelessのAIアルゴリズムは、Webページの構造を自動的に分析し、コンテンツに適合するようにスクレイピング手法を調整できます。
法的および倫理的な基準を遵守する
Webスクレイピングに対する監視が厳しくなるにつれて、法的および倫理的な範囲内で運用することが不可欠です。スクレイパーは、プライバシー法、Webサイトの利用規約、GDPRなどの規制を認識する必要があります。Scrapelessは、スクレイピングがWebサイトの所有者によって設定されたルールに準拠していることを保証するために、インテリジェントなrobots.txt検出を統合することにより、コンプライアンスを維持するのに役立ちます。
さらに、AIを使用してWebページのコンテンツを分析し、機密データまたは保護されたデータをフィルタリングすることで、企業が非倫理的な行為を回避することができます。ScrapelessのAIアルゴリズムは、ユーザーが法的要件を遵守するのに役立つように設計されており、知的財産権の侵害やプライバシー侵害などのリスクを回避するのに役立ちます。
Webサイトによってブロックされるのを回避する
Webサイトは、自動化されたスクレイパーを検出してブロックするために、アンチスクレイピング対策を展開することがよくあります。ScrapelessのAIテクノロジーは、人間のブラウジング動作をシミュレートすることにより、スクレイピングリクエストをより自然に見せることで、検出を回避するのに役立ちます。AIアルゴリズムは、リクエストの頻度、タイミング、ヘッダーを調整して、実際のユーザーアクティビティを模倣し、ブロックされる可能性を大幅に低減します。さらに、Scrapelessは、リクエストを分散するために複数のIPアドレス間で自動的に切り替えるAI駆動型システムであるプロキシローテーションを使用します。これにより、レート制限を回避し、Webサイトが多数のリクエストを送信する単一のIPアドレスをブロックするのを防ぎます。AIベースのプロキシローテーションをインテリジェントに使用することで、Scrapelessはデータ抽出の中断を回避します。
大規模データ収集のためのScrapelessテクノロジーの最適化
大規模データ収集に従事している企業にとって、スクレイピングの効率性とスケーラビリティは不可欠です。ScrapelessのAI機能は、複雑なWebサイトや大規模なWebサイトからデータを引き出す場合でも、最適なパフォーマンスを確保するためにスクレイピング戦略を自動的に調整します。たとえば、ScrapelessのAI駆動型クロールは、JavaScriptを多用するWebサイトなどの動的コンテンツを処理できるため、企業は従来のツールでは処理が困難な幅広いコンテンツをクロールできます。
さらに、AIアルゴリズムは最も重要なデータの優先順位を決定することにより、大量の情報を処理する場合のリソースの効率的な割り当てを保証します。これにより、速度とパフォーマンスを維持しながら、ビジネスニーズを満たすシームレスな大量クロールが可能になります。
Webスクレイピングのベストプラクティスに従うことは、収集されたデータの価値を最大限に引き出すための鍵となります。ScrapelessのAI駆動型クロールテクノロジーを活用することで、企業はデータの正確性を向上させ、法令遵守を確保し、Webサイトによってブロックされるのを回避し、大規模データ収集のためのクロール操作を最適化できます。Scrapelessを使用することで、企業は必要とするデータを迅速、効率的、かつ倫理的にアクセスでき、競争が激しいデータ主導の分野で優位に立つことができます。
Webスクレイピングの一般的な問題のトラブルシューティング
- Webサイト構造の変更
- 問題:WebサイトはレイアウトまたはHTML構造を頻繁に更新するため、特定のタグに依存するスクレイパーが壊れる可能性があります。
- 解決策:動的なテクニックを使用して柔軟なスクレイパーを作成するか、小さな変更に適応できるエラー処理を実装します。Scrapelessは、変更を検出してそれに応じて調整するスマートなAI搭載スクレイパーを提供します。
- IPブロック
- 問題:Webサイトは、単一のIPアドレスからのリクエスト数を制限し、多くの試行の後、スクレイパーをブロックします。
- 解決策:IPローテーションを使用してScrapelessプロキシを使用し、複数のIPにリクエストを分散することで、Webサイトがスクレイピングパターンを検出してアクセスをブロックすることを難しくします。
- CAPTCHAとアンチスクレイピングメカニズム
- 問題:CAPTCHAやその他のアンチボット対策(JavaScriptチャレンジなど)がスクレイパーを停止する可能性があります。
- 解決策:Scrapeless CAPTCHAソルバーを活用してCAPTCHAの解決を自動化します。JavaScriptを多用するページには、動的コンテンツを効率的に処理するScrapelessスクレイピングブラウザを使用します。
- レート制限
- 問題:Webサイトは、サーバーの過負荷を防ぐために特定の時間枠内のリクエスト数を制限し、スクレイパーが失敗する原因となります。
- 解決策:プロキシとローテーション、レート制限コントロールを使用してスクレイパーを設定し、人間の行動を模倣してレート制限に達するのを防ぎます。
- データの不正確さまたは情報不足
- 問題:スクレイピングロジックのエラーやデータパースの不備により、スクレイピングの結果、不完全または不正確なデータが発生します。
- 解決策:スクレイピングされたデータの検証を行い、スクレイパーが正しく構成されていることを確認するチェックを実装します。ScrapelessはAI駆動型アルゴリズムを使用して、データの整合性と一貫性を確保します。
- 法的および倫理的問題
- 問題:特定のWebサイトをスクレイピングすると、利用規約または現地の法律に違反し、法的結果につながる可能性があります。
- 解決策:常に法的および倫理的な基準を遵守してください。Scrapelessは、スクレイピングアクティビティが法的な範囲内にとどまるようにする組み込みのフレームワークを提供します。
Webスクレイピングにおけるより一般的な課題とその解決策については、Webスクレイピングの課題を解決する方法-完全ガイド2025をお読みください。
Webページのスクレイピングに関するよくある質問
1. Webページをスクレイピングするにはどうすればよいですか?
最も簡単な方法は、必要なデータをWebページから直接手動でコピーして、ドキュメントに貼り付けることです。
ブラウザの開発者ツール(Chromeの「検証」機能など)を使用して、WebページのHTML構造を表示し、そこからデータを取り出すこともできます。最も簡単なのは、ユーザーがコードを書かずにグラフィカルインターフェースを介してスクレイピングタスクを簡単に設定できるScrapelessなどのノーコードツールを使用することです。
これらの方法を使用すると、Webページを効果的にスクレイピングし、必要なデータを取り出すことができます。
2. Webサイトからデータをスクレイピングしても問題ありませんか?
サイトの利用規約、データ使用ポリシー、および現地の法律に従う限り、Webスクレイピングは合法です。スクレイピングする前に、必ずサイトのrobots.txtファイルと利用規約を確認してください。レート制限に従い、個人データや著作権のあるデータのスクレイピングを避けるのが最善です。
3. Webサイトのすべてのページを抽出するにはどうすればよいですか?
Webサイトのすべてのページをスクレイピングするには、Webクローラーを使用できます。これには、ホームページまたはその他の主要ページからすべてのリンクを再帰的に参照することが含まれます。ScrapelessスクレイピングブラウザまたはScrapeless APIなどのツールは、Webサイトの構造に基づいてすべてのページからデータを取り出すこのプロセスを自動化できます。
4. Webスクレイピングにはどのようなツールが使用されますか?
一般的なWebスクレイピングツールには、Scrapeless、BeautifulSoup、Selenium、Octoparse、Scrapyなどがあります。これらのツールを使用すると、リクエストを送信し、HTMLコンテンツを解析し、CSV、JSON、Excelなどの構造化された形式でデータを提供することで、Webサイトからデータを取り出すプロセスを自動化できます。
5. Webスクレイピングでお金を稼ぐことはできますか?
はい、企業にデータ抽出サービスを提供したり、市場調査を行ったり、クライアントのために公開されているデータをスクレイピングしたりすることで、Webスクレイピングでお金を稼ぐことができます。Webスクレイピングは、競合分析、リードジェネレーション、またはeコマース、不動産、金融などの業界にとって貴重な専門的なデータベースの構築のためのデータ収集にも使用できます。
まとめ:ScrapelessがWebスクレイピングの未来である理由
Scrapelessは、Webスクレイピングタスクを簡素化する強力なAI駆動型ソリューションを提供し、開発者と企業に大きなメリットをもたらします。最先端の機能を備えたScrapelessは、データ収集が効率的で、正確で、スケーラブルであることを保証します。
- AIスクレイピング:AIを活用してスクレイピングの効率性を向上させ、複雑で動的なコンテンツを処理します。
- 10倍高速:最適化されたブラウザ操作により、従来のスクレイピング方法よりも10倍高速です。
- CAPTCHAとアンチスクレイピングのバイパス:CAPTCHAやその他のアンチボット保護を自動的にバイパスします。
- カスタマイズ可能なスクレイピング:特定のニーズとユースケースに合わせてスクレイピングパラメーターをカスタマイズします。
- 自動化されたワークフロー:AI駆動型の自動化により、手動による介入が削減され、データ収集が簡素化されます。
スクレイピング効率を向上させようとしている開発者でも、大規模に構造化されたデータを取得しようとしている企業でも、Scrapelessは、ニーズを満たす包括的なソリューションを提供します。Webスクレイピングの複雑さに遅れを取らないでください。今日からScrapelessを使用し、シームレスでAI駆動型のWebデータ抽出の可能性を解き放ちましょう。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


