
PythonによるWebクローラー:2025年ステップバイステップガイド
Advanced Data Extraction Specialist
データ量の劇的な増加に伴い、Webクローラーはデータサイエンス、市場調査、競合分析などの分野で重要なツールとなっています。多くのプログラミング言語の中でも、Pythonは簡潔な構文と強力なライブラリサポートにより、Webクローラー開発(Python Webクローラー)の好ましい言語となっています。ECサイトからデータ抽出するのも、ニュースサイトから最新のニュース記事を収集するのも、Python Webクローラーは効率的にタスクを完了できます。この記事では、2025年版のステップバイステップガイドを提供し、基本的な知識から高度なテクニックまで、Pythonを使用して強力なWebクローラーを構築する方法を習得し、Webクローリング能力を包括的に向上させるお手伝いをします。
PythonにおけるWebクローラーとそのデータ抽出における重要性
Webクローラーは、特定のルールに従ってインターネットから情報を取得するように設計された自動化プログラムです。ブラウザをシミュレートしてWebページにアクセスし、必要なデータを抽出してローカルに保存します。このプロセスには通常、初期URLの選択、Webページコンテンツのダウンロード、HTMLの解析、リンクの追跡、およびこのプロセスの繰り返しによるデータ取得が含まれます。データ抽出におけるWebクローラーの役割は非常に重要です。これは、多数のWebページから情報を効率的に収集し、検索エンジンのインデックス構築やデータ分析タスクをサポートできるためです。
PythonによるWebクローラーの利点
PythonでWebクローラーを作成するメリットは多く、特に柔軟性と使いやすさにおいて顕著です。まず、Pythonの構文は簡潔で学習が容易なため、開発者は迅速に開始し、複雑なクローリングロジックを実装できます。次に、PythonにはScrapyやBeautifulSoupなどの豊富なライブラリとフレームワークがあり、Webページの解析とデータ抽出のプロセスが大幅に簡素化されます。さらに、Pythonのクロスプラットフォームの性質により、異なるオペレーティングシステムでクローラーを実行できるため、開発とデプロイの柔軟性が向上します。
💡 関連情報:2025年のPythonを使ったWebスクレイピング
PythonにおけるWebクローリングの高度なテクニック
PythonによるWebクローラー開発においては、特に動的なコンテンツや反スクレイピング対策に対処する場合、Webスクレイピング能力を向上させることができるいくつかの高度なテクニックがあります。これらの戦略は、Python Webクローラーの構築において頻繁に遭遇する、JavaScriptレンダリング、CAPTCHA解決、IPブロックなどの課題を克服するために不可欠です。いくつかの重要な戦略を以下に示します。
- 動的なWebページの処理:
- Seleniumを使用する:このライブラリを使用すると、ブラウザの操作を自動化でき、データ抽出の前にJavaScriptコンテンツの読み込みを待つことができます。
- Ajaxリクエストを実行する:ブラウザの開発者ツールでネットワークリクエストを分析してAPIエンドポイントを特定します。Pythonのrequestsライブラリを使用して、これらのエンドポイントに直接リクエストを送信し、より効率的なデータ取得を行います。
- 反スクレイピング対策の回避:
- プロキシを使用する:ローテーションするプロキシIPを実装して、複数のIPアドレスにリクエストを分散することにより、Webサイトがスクレイピング活動を検出してブロックするのを困難にします。
- ユーザーエージェントを偽装する:リクエストヘッダーのユーザーエージェント文字列を変更して、一般的なブラウザを模倣します。これにより、ボットとしてフラグ付けされる可能性が低くなります。
- 効率の向上:
- 非同期プログラミングを実装する:asyncioやaiohttpなどのライブラリを使用して同時リクエストを行い、データ抽出プロセスを大幅に高速化します。
- XPathまたはCSSセレクターを活用する:これらのツールを使用すると、HTML要素を正確にターゲット指定できるため、データ抽出の精度と効率が向上します。
WebクローリングのためのPython環境のセットアップ
Webクローリング環境のセットアップを開始する前に、いくつかの基本的な環境を準備する必要があります。
- Python 3+:インストーラーをダウンロードし、ダブルクリックしてインストールウィザードに従います。
- Python IDE:Python拡張機能を備えたVisual Studio CodeまたはPyCharm。
次に、ターミナルで次のコマンドを入力して、python-crawlerというプロジェクトを初期化します。
mkdir python-crawler
cd python-crawler
python -m venv envWebクローリングを行う際は、HTTPリクエストとHTML解析のために2つのライブラリを使用する必要があります。Pythonで最も人気のある2つのライブラリは次のとおりです。
- requests:HTTPリクエストを送信し、レスポンスを処理できる強力なHTTPクライアントライブラリ。
- beautifulsoup4:フル機能のHTMLおよびXMLパーサー。
次のコマンドをターミナルに入力してインストールします。
pip install beautifulsoup4 requestsプロジェクトフォルダーでcrawler.pyを作成し、プロジェクトの依存関係をインポートします。
import requests
from bs4 import BeautifulSoupプロジェクトが構築されました。Webクローリングを開始しましょう。
Pythonを使用したAmazonデータのスクレイピング方法
Amazonからデータをスクレイピングすると、製品情報、レビュー、トレンドに関するコンテンツを取得できます。ただし、CAPTCHAやIPレート制限などのAmazonの反スクレイピング対策により、プロセスが困難になります。このガイドでは、Pythonを使用してAmazonデータをスクレイピングする方法を説明します。
PythonでシンプルなWebクローラーを構築する方法
上記のステップに従ってWebクローリング環境をセットアップした後、次のステップに従ってPythonでシンプルなWebクローラーを作成する必要があります。
**ステップ1:**RequestsとBeautifulSoupを使用した基本的なWebクローラー
コード例
import requests
from bs4 import BeautifulSoup
class SimpleWebCrawler:
def __init__(self, start_url):
self.start_url = start_url
self.visited_urls = set()
self.urls_to_visit = [start_url]
def crawl(self):
while self.urls_to_visit:
current_url = self.urls_to_visit.pop(0)
if current_url in self.visited_urls:
continue
print(f"Crawling: {current_url}")
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
self.visited_urls.add(current_url)
self.extract_links(soup)
def extract_links(self, soup):
for link in soup.find_all('a', href=True):
absolute_link = link['href']
if absolute_link not in self.visited_urls and absolute_link not in self.urls_to_visit:
self.urls_to_visit.append(absolute_link)
if __name__ == "__main__":
crawler = SimpleWebCrawler("https://example.com")
crawler.crawl()説明
- 初期化:SimpleWebCrawlerクラスは、開始URLと、アクセス済みURLとアクセスするURLを追跡するためのセットで初期化されます。
- クローリングロジック:crawlメソッドは、urls_to_visitリスト内のURLを処理し、各ページのコンテンツを取得します。
- リンクの抽出:extract_linksメソッドは、ページ上のすべてのハイパーリンクを見つけ、まだアクセスされていない場合は、アクセスするURLのリストに追加します。
**ステップ2:**より複雑なクローリングのためのScrapyの使用
プロジェクトで、複数のリクエストを同時に処理したり、大規模なWebサイトを効率的にスクレイピングしたりするなどの高度な機能が必要な場合は、Scrapyを使用することを検討してください。
基本的なScrapyの例
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ['https://example.com']
def parse(self, response):
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)Scrapyの実行
コマンドラインを使用してScrapyスパイダーを実行できます。
scrapy crawl my_spiderPythonを使用したAmazonデータのスクレイピング方法
次に、このセクションでは、Pythonを使用してAmazonデータをクローリングする方法について詳しく説明します。
ステップ1. まず、製品ページを取得し、getメソッドを使用してリクエストを行います。
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)response.contentには、サーバーによって生成されたHTMLドキュメントが含まれています。これはBeautifulSoupに供給され、html.parserオプションを使用すると、ライブラリが使用するパーサーを指定できます。
soup = BeautifulSoup(response.content, "html.parser")ステップ2. 次に、取得したいデータを取得する必要があります。CSSセレクターを使用して、対応する要素を取得できます。
BeautifulSoupは、selectとselect_oneの2つのメソッドを提供しており、どちらもCSSセレクター戦略をサポートしています。コードを記述する前に、devtoolsツールを開いて要素のCSSを確認できます。
- 製品タイトルの取得:
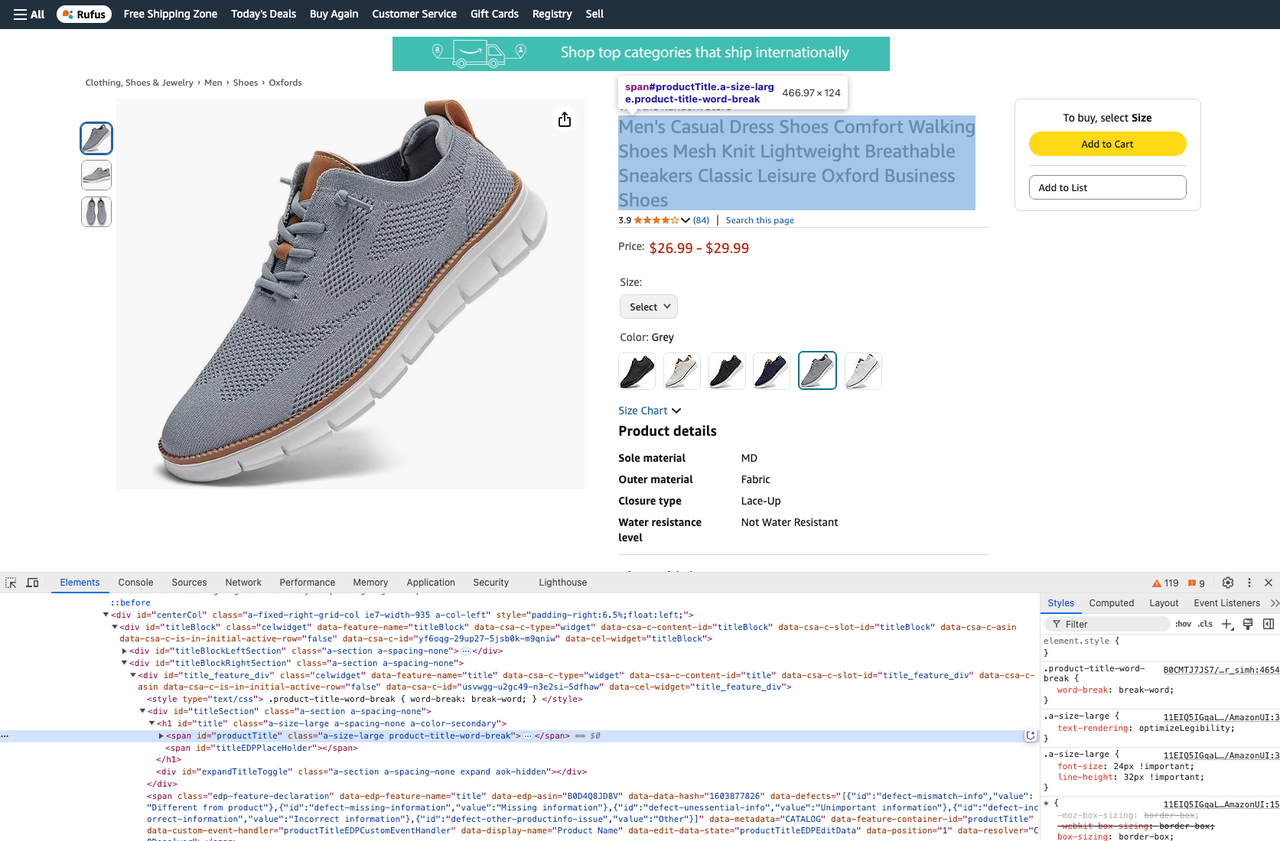
product_title = soup.select_one("#productTitle").text- 製品説明の取得:
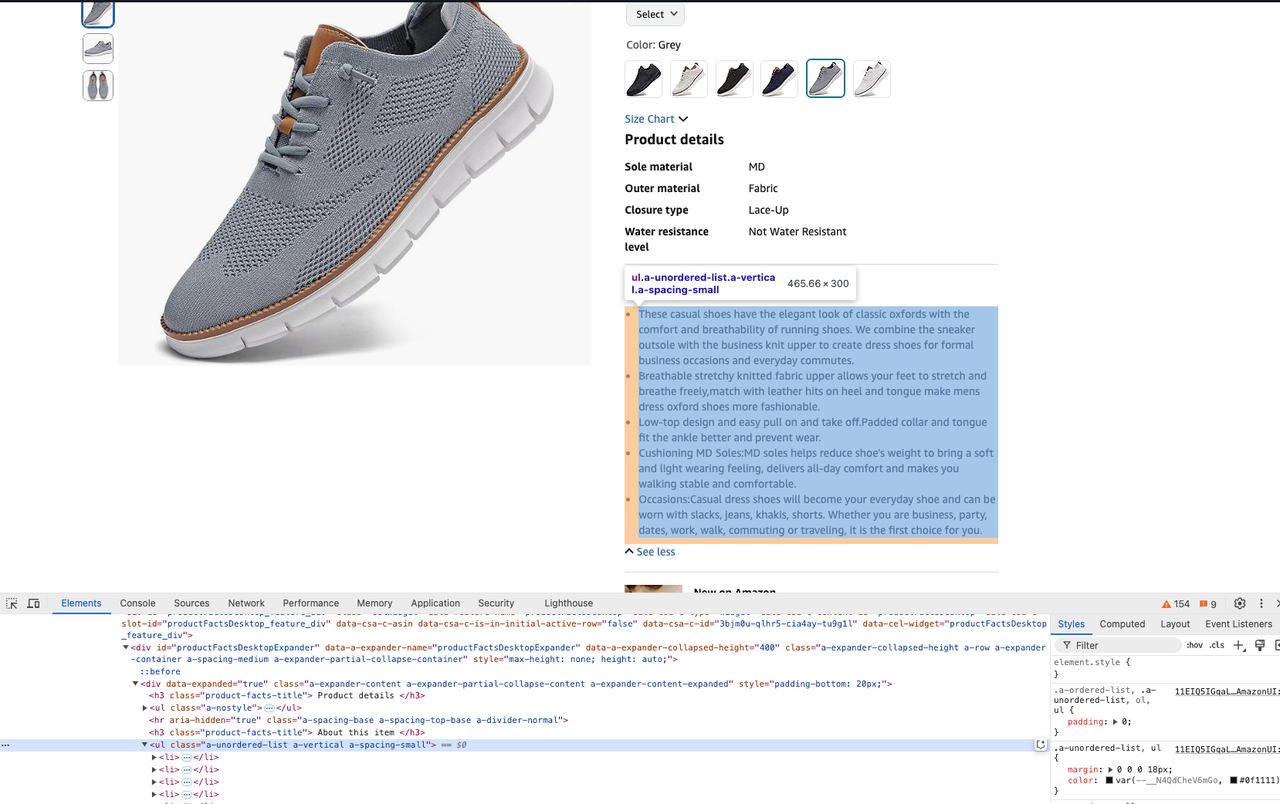
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text- 製品価格の取得:
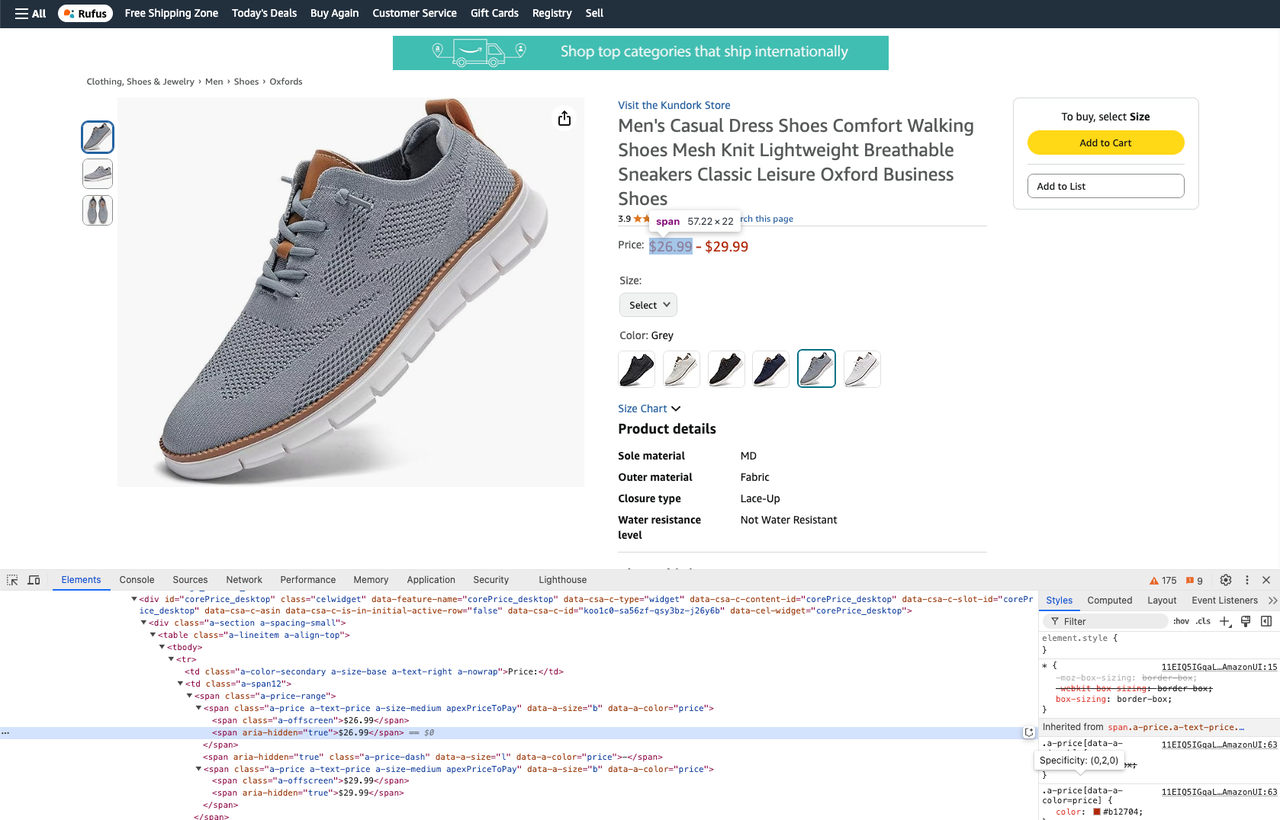
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text- 製品レビューの取得:
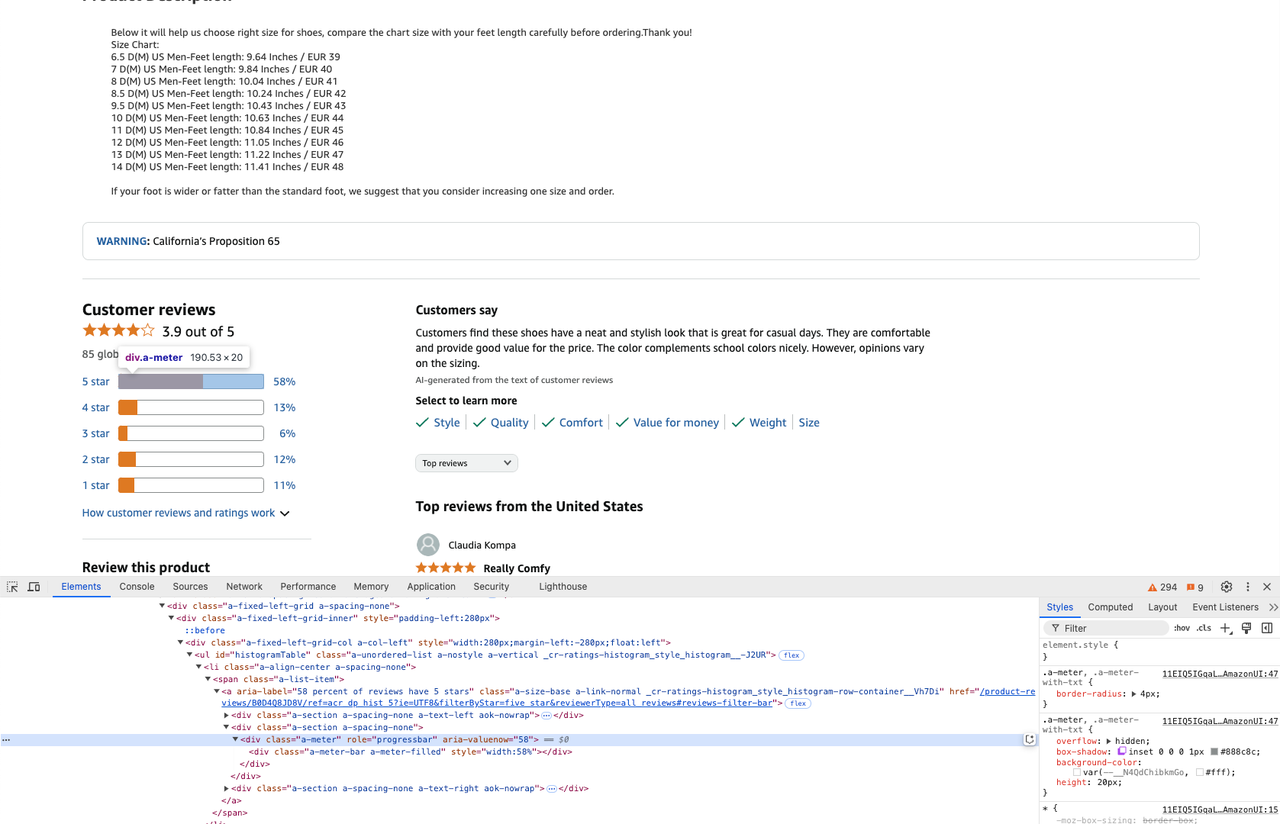
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'ステップ3. Webサイトをクローリングして必要なデータを取得したので、クローリングされた情報をcsvファイルに抽出できます。
これを行うには、ファイルの先頭に次の行を追加します。
import csvクローリングされたデータをcsvファイルに書き込みます。
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])ターミナルで次のコマンドを実行して、クローリングコマンドを実行します。
python crawler.pyステップ4. 実行が完了すると、フォルダーにproduct.csvファイルが表示されます。このファイルを開くと、クローリングしたデータの結果を確認できます。

完全なコードは次のとおりです。
import csv
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
product_title = soup.select_one("#productTitle").text
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])ScrapelessのAmazonスクレイピングAPIがWebクローリングタスクを簡素化する理由
ScrapelessのAmazonスクレイピングAPIは、Amazonからのデータ抽出プロセスを自動化および簡素化するために設計されており、開発者や企業にとって貴重なツールとなっています。IPローテーションやCAPTCHAバイパスなどのさまざまな課題に対処するために、多くの場合、広範な手動コーディングが必要となるPythonによるWebクローラーの使用とは異なり、Scrapeless APIはプロセスを合理化します。効率を向上させるさまざまな機能を提供し、ユーザーは複雑なPythonスクリプトを必要とせずに、製品価格、レビュー、説明などのデータを簡単に収集できます。
AmazonスクレイピングAPIに加えて、ScrapelessにはShopeeスクレイピングAPI、LazadaスクレイピングAPI、Google TrendsスクレイピングAPI、Google FlightsスクレイピングAPI、Google検索スクレイピングAPI、AirbnbスクレイピングAPIなどが含まれており、Webデータ抽出のための包括的なソリューションを提供しています。
簡単にスクレイピングを始めませんか?
すぐにScrapelessにサインアップして、無料トライアルでAPIの力を体験してください。Amazon、Shopeeなど、主要なECプラットフォームからのシームレスなデータ抽出を有効化します。今すぐ始めましょう!
手動のPython Webクローラーに対する利点
1. 自動化と効率性
AmazonスクレイピングAPIはデータ抽出プロセス全体を自動化するため、ユーザーは大量のデータを迅速かつ正確に収集できます。これにより、動的なコンテンツや反スクレイピング対策などのさまざまな課題に対処する必要がある、手動のPython Webクローラーで通常必要となる複雑なコーディングが不要になります。
2. 組み込みインフラストラクチャ
ScrapelessのAPIを使用すると、ユーザーは、プロキシ管理、IPローテーション、CAPTCHA解決を自動的に処理する堅牢なインフラストラクチャを利用できます。対照的に、手動のPython Webクローラーでは、開発者がこれらの機能を自分で実装する必要があり、これは時間と労力を要し、エラーが発生しやすい可能性があります。
3. コード不要のインターフェース
APIは、ユーザーが簡単なAPI呼び出しでスクレイピングタスクを開始できるコード不要のインターフェースを提供します。これは、Python Webクローラーのコードを記述およびデバッグするよりもはるかに簡単であるため、さまざまなスキルレベルのユーザーが使用できます。
APIを通じて効率的にAmazonデータを抽出する
ScrapelessのAmazonスクレイピングAPIを使用すると、次の手順に従って構造化されたデータを簡単に抽出できます。
-
APIキーの生成:Scrapelessにサインアップして、独自のAPIキーを生成します。
-
スクラピングAPIをクリックし、Amazonを選択します。
-
要件を定義する:スクレイピングするデータの種類(例:製品の詳細、レビュー)を指定します。
-
スクラピングの開始をクリックする:簡単なAPI呼び出しを使用してAmazonからデータを取得します。
-
構造化されたデータを受信する:Scrapeless APIは、収集されたデータをさまざまな形式(例:JSON)で提供し、分析したり、システムに統合したりできます。
ScrapelessのAmazonスクレイピングAPIを活用することで、ユーザーはWebスクレイピングタスクを大幅に簡素化し、Webスクレイピングの複雑さを管理するのではなく、洞察の分析に集中できます。この強力なツールは、生産性を向上させるだけでなく、データ保護規制への準拠も確保するため、市場調査の取り組みで競争優位性を獲得しようとする企業にとって理想的です。
Scrapelessを独自のプロジェクトに統合する必要がある場合は、サンプルコードを参照できます。こちらをクリックして完全なドキュメントを表示することもできます。
リクエストサンプル - 製品
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)リクエストサンプル - 販売者
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))リクエストサンプル - キーワード
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Scrapeless Discordコミュニティに参加しましょう!
毎週のニュース、限定アップデートの最新情報を入手し、エキサイティングなイベントに参加してクレジットを獲得するチャンスがあります。今すぐ参加しましょう!
PythonによるWebクローラーに関するFAQ
FAQ #1:PythonにおけるWebクローラーとWebスクレイパーの違いは何ですか?
WebクローラーとWebスクレイパーは、データ抽出の分野で異なる用途があります。Webクローラーは主に発見に焦点を当てており、Webサイトを閲覧してURLを見つけてインデックスを作成し、本質的にインターネットまたは特定のWebサイトのマップを作成します。Webクローラーの出力は通常、URLのリストです。対照的に、WebスクレイパーはこれらのURLから、製品の詳細や価格情報などの特定のデータを抽出します。両方のプロセスでHTMLコンテンツのダウンロードが含まれますが、クローラーの目標はリンクを収集することであるのに対し、スクレイパーの目標はこれらのページから関連するデータポイントをフィルタリングして抽出することです。
FAQ #2:PythonでWebクローラーを構築する際にCAPTCHAを処理するにはどうすればよいですか?
CAPTCHAの処理は、自動アクセスを防ぐために特別に設計されているため、PythonでWebクローラーを構築する際の最も困難な側面の1つです。CAPTCHAを処理するための効果的な戦略を次に示します。
- ヘッドレスブラウザを使用する:ヘッドレスブラウザとPuppeteerやPlaywrightなどのツールを組み合わせると、実際のブラウザの動作を模倣することでCAPTCHAをバイパスできます。
- CAPTCHAをトリガーしないようにする:
2.1 プロキシサービスを使用してIPアドレスをローテーションし、検出を防ぎます。
2.2 リクエストヘッダー(例:ユーザーエージェント)をランダム化し、リクエスト間の遅延を導入して、人間の活動を模倣します。
これらの方法ではCAPTCHAをバイパスできますが、常に、あなたの行動がWebサイトの利用規約および法的要件に準拠していることを確認してください。
FAQ #3:Pythonを使用してAmazonなどのWebサイトからデータをスクレイピングすることは合法ですか?
Webスクレイピングの合法性は、特にAmazonのようなECプラットフォームをターゲットとする場合は、さまざまな要因によって異なります。いくつかの重要な考慮事項を以下に示します。
- robots.txtへの準拠:Webサイトには、サイトのどの部分をスクレイピングできるかを概説したファイルが含まれていることがよくあります。これを無視することはそれ自体が違法ではありませんが、倫理に反したり、ベストプラクティスに反したりする可能性があります。
- 公正使用と公開データ:データが公開されており、非商業目的(学術研究など)で使用される場合、一部の司法管轄区域では「公正使用」に該当する可能性があります。ただし、これは必ずしも当てはまるとは限りません。
法的問題を回避するには:
- データをスクレイピングする前に、必ずWebサイトの利用規約を確認してください。
- 可能であれば、許可を求めてください。
- Scrapelessなどの合法的なWebサイトスクレイピングAPIを使用してください。
まとめ
この記事では、PythonにおけるWebクローラーの重要性、特にECサイトデータクローリングにおける広範な用途について説明しました。柔軟性と強力さを備えたプログラミング言語であるPythonは、開発者がECプラットフォームから効率的にデータをクローリングし、製品情報、価格、コメントなどの重要なデータを取得するのに役立つ豊富なライブラリとツールを提供します。ただし、手動でWebクローラーを記述および保守するには、特に複雑な反クローラーメカニズムに直面した場合は、多くの時間と労力が必要になります。
この文脈において、ScrapelessのAmazonスクレイピングAPIは効率的な代替手段を提供します。大規模なECデータをクローリングする必要があるユーザーにとって、Scrapeless APIはクローリングプロセスを簡素化するだけでなく、さまざまな複雑な問題を自動的に処理するため、ユーザーは時間と労力を節約し、必要なAmazonデータを簡単に取得できます。小規模企業から大規模なデータ需要まで、Scrapelessは理想的な選択肢です。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


