
Playwright を使用して Cloudflare をバイパスする方法 (2024年)
Advanced Data Extraction Specialist
ヘッドレスブラウザを使用している際に、Webスクレーパーがブロックされていますか?このガイドでは、Playwrightのマスクを改善することで、Cloudflareを回避する方法を紹介します。
Cloudflareとは?
セキュリティとパフォーマンスの最適化を提供するCloudflareが提供するサービスであるBot Managementは、多くのスクレーパーにとって悪夢です。ウェブサイトの約5分の1が、Webアプリケーションファイアウォール(WAF)を利用しており、スクレーパーを定期的に識別して停止させています。PlaywrightやSeleniumなどのヘッドレスブラウザはこのカテゴリに分類されます。
Cloudflareの仕組み
Cloudflareは、次のようなさまざまな手法を使用して、ボットによって生成されたトラフィックと実際のユーザーによって生成されたトラフィックを比較して分離します。
行動分析: クリック、マウスの動き、ページの読み込み時間など、ユーザーのウェブサイトとのやり取りのさまざまな側面を監視します。
IPレピュテーション分析: すべてのリクエストのIPアドレスをデータベースと照合して、スクレーピングに使用されたかどうかを確認します。
ユーザーエージェント分析: 文字列は、ウェブサイトのリクエストを行うブラウザまたはデバイスを識別するための手段として機能します。Cloudflareは、スクレーパーによって使用される、一般的なまたはすぐに識別できるユーザーエージェント文字列を識別できます。
CAPTCHAテスト: システムは、ウェブサイトにリクエストを送信しているユーザーがロボットか人間かを判断することを選択できます。ユーザーが合格すれば、リクエストは承認されます。そうでなければ、禁止されます。
リクエストレート分析: この手法を使用すると、ウェブサイトに送信されるクエリの量を追跡し、自動化されたボットの特徴的な傾向を見つけることができます。たとえば、ボットは短い時間内に多くのリクエストを頻繁に送信します。
Playwrightの基本的な使用方法ではCloudflareを回避できない理由
Playwrightを使用しても、Cloudflareのボット対策を回避できない場合があります。その理由は?このブラウザ自動化ツールやその他のブラウザ自動化ツールを使用すると、人間の行動に似たブラウジング動作をシミュレートすることで、いくつかの問題を克服できますが、プロキシやカスタムユーザーエージェントの使用などのより高度な方法は、克服するために追加の努力が必要となる可能性があります。
これを示すために、NodeJS Playwrightプロジェクトを起動して、Cloudflareを介してどのように機能しないかを見てみましょう。
ステップ1: コンピュータにnpmとNode.jsがインストールされていることを確認します。
ステップ2: 必要なディレクトリに移動した後、このコマンドを使用して新しいプロジェクトを起動します。
language
npm initステップ3: 次に、このコマンドを使用してPlaywrightを依存関係としてインストールします。
language
npm install playwrightステップ4: 素晴らしい仕事!これでPlaywrightを使用できます。scraper.jsなどの.js拡張子の新しいファイルを作成し、プロジェクトディレクトリに配置します。その中で、https://crozdesk.comにアクセスしてスクリーンショットを取得するスクリプトを構築します。
language
const playwright = require("playwright");
async function scraper() {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://crozdesk.com");
await page.waitForTimeout(1000);
await page.screenshot({ path: "screenshot.png", fullPage: true });
await browser.close();
}
scraper();スクレーパーは、4行目でわかるように、Chromiumをブラウザとして使用していますが、他のブラウザを使用することもできます。
ステップ5: このコマンドを使用して、コード全体を実行します。
language
node scraper.jsこれが結果です。
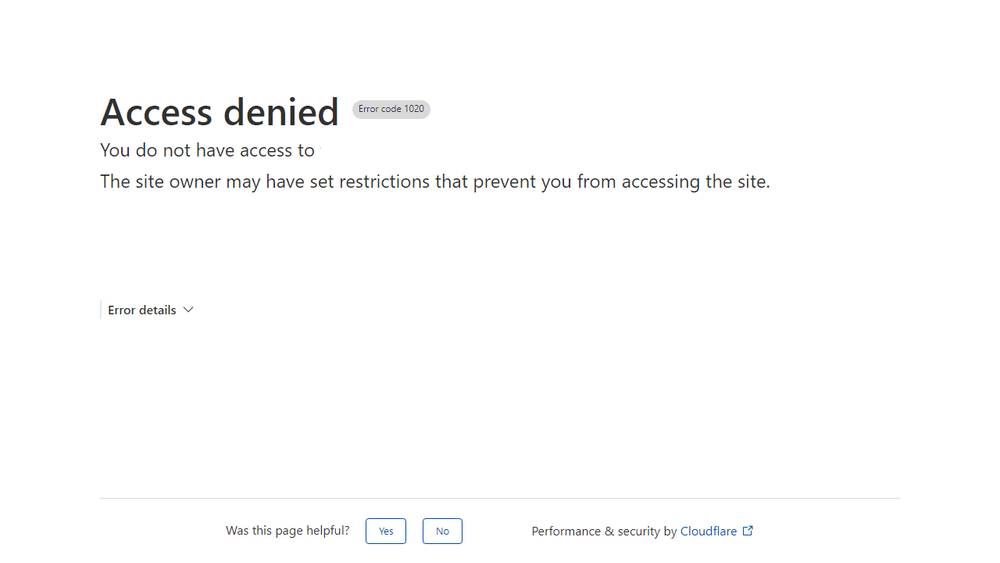
残念ながら、Playwrightの単純なバージョンはボットとしてフラグ付けされ、ウェブサイトへのアクセスがブロックされます。
次のセクションでは、Cloudflareを回避するのに役立ついくつかの戦略について説明します。読み続けてください!
PlaywrightをマスクしてCloudflareを回避する方法
Cloudflareの検出テクニックを処理するためのいくつかの戦略を見てみましょう。通常、スクリプトを機能させるには、これらの戦略を組み合わせる必要があります。
方法1: 人間の行動を複製する
自動化されたブラウザをより人間らしく見せるために、以前のPlaywrightスクレーパーコードにランダムな一時停止、スクロール、その他のウェブサイトとのやり取りを追加できます。
方法2: プロキシを使用する
短い時間内に多くのクエリを送信すると、ウェブサイトのスクレーピングから簡単に禁止されてしまいます。回転するプロキシを使用することで、さまざまなユーザーのように見えるようにし、これを防ぐことができます。
方法3: 一意のユーザーエージェントを選択する
ユーザーエージェントは、オペレーティングシステムやブラウザなど、リクエストを行うクライアントに関する情報を保持しています。Playwrightのデフォルトのユーザーエージェントではなく、一般的なオンラインブラウザを模倣したカスタムユーザーエージェントを使用すると、検出されるのを防ぐことができます。
方法4: CAPTCHAソルバーを使用する
Playwrightでは、Scrapelessなどのさまざまなツールを使用して、CAPTCHAを解決できます。
絶え間ないWebスクレーピングのブロックとCAPTCHAにうんざりしていませんか?
Scrapelessを紹介します - オールインワンの究極のWebスクレーピングソリューション!
データ抽出の可能性を最大限に引き出すための強力なツールスイートをご紹介します。
Best Web Unlocker
高度なCAPTCHAを自動的に解決し、スクレイピングをシームレスかつ途切れなく行うことができます。
違いを実感してください - 無料でお試しください!
方法 5: Playwright-extra を追加する
Playwright-extra は Playwright プラグイン用の軽量なフレームワークで、追加の便利なアドオンを可能にします。Cloudflare を回避するために使用するものは Puppeteer-extra-plugin-stealth と呼ばれ、マウスイベントの生成やユーザーエージェントの変更など、さまざまな戦略を用いてヘッドレスブラウザの使用を隠蔽します。
まとめ
ご覧のとおり、Playwright を使用して Cloudflare を回避することはできますが、毎回うまくいくとは限らない高度なトリックを使用する必要がある場合があります。一方、Scrapeless はすぐに成功するお手伝いをし、今すぐ無料の API キーを提供します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


