
人間とコンピュータの相互作用でタスクを追跡する方法は?
Expert Network Defense Engineer
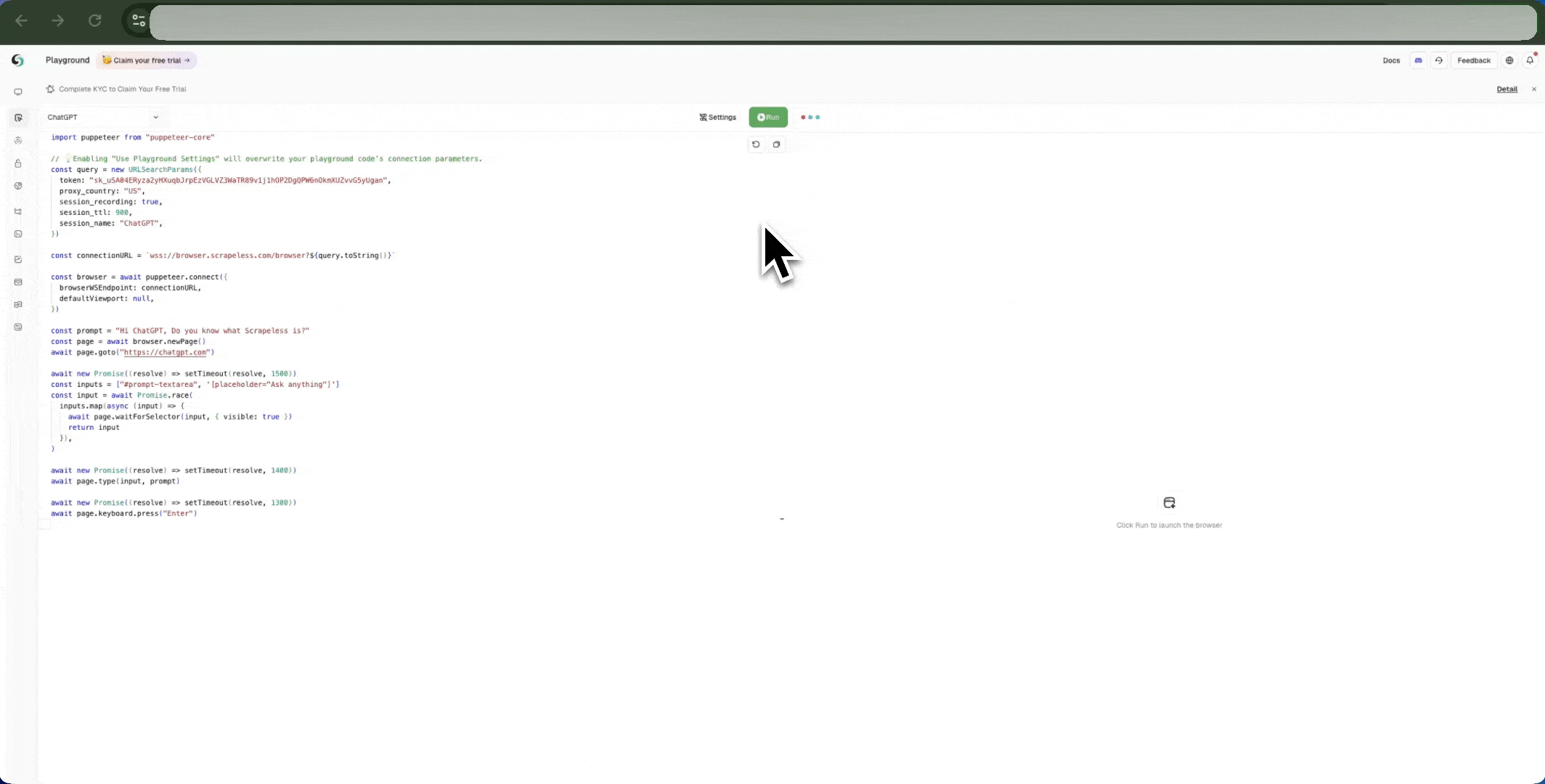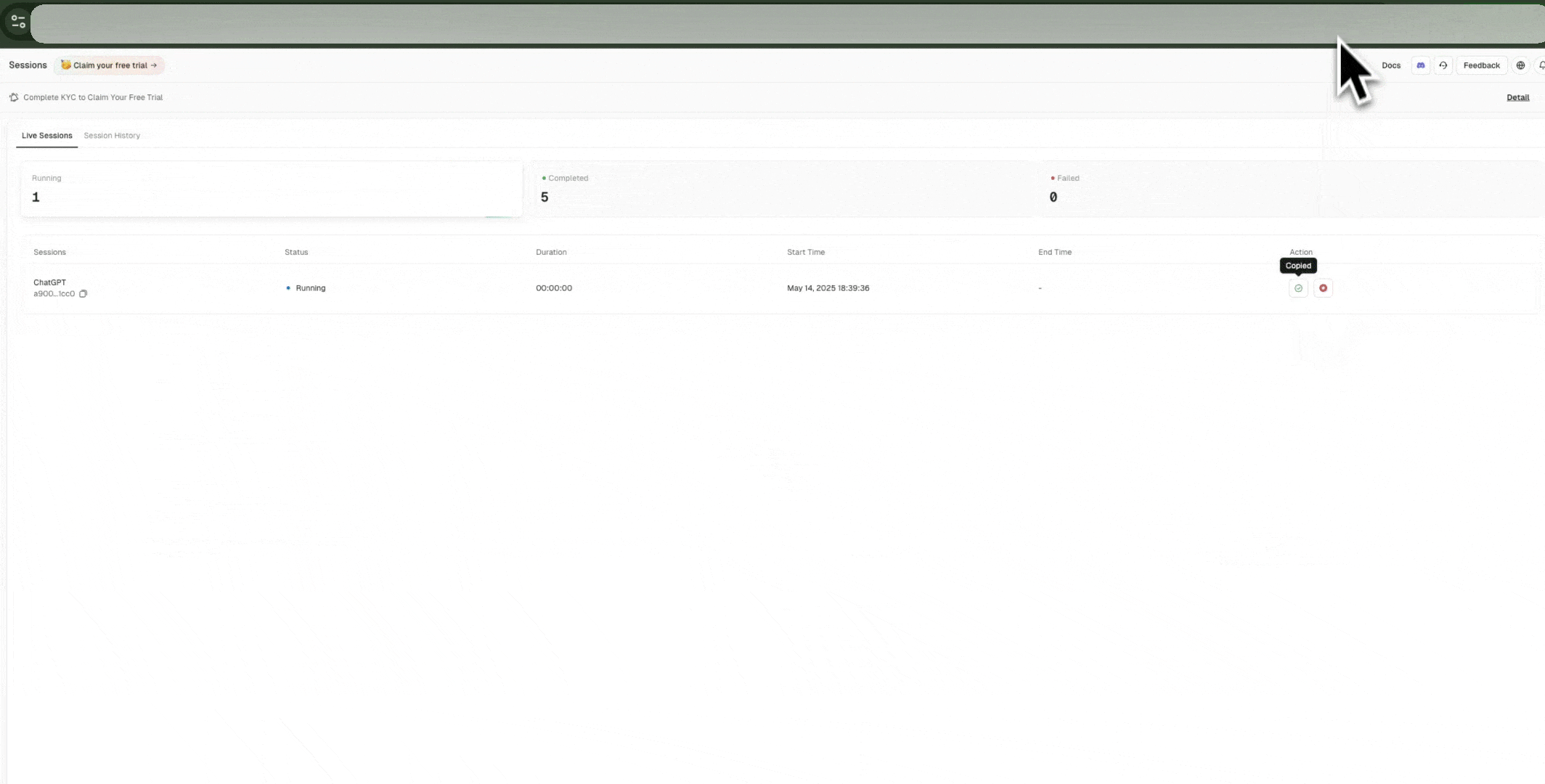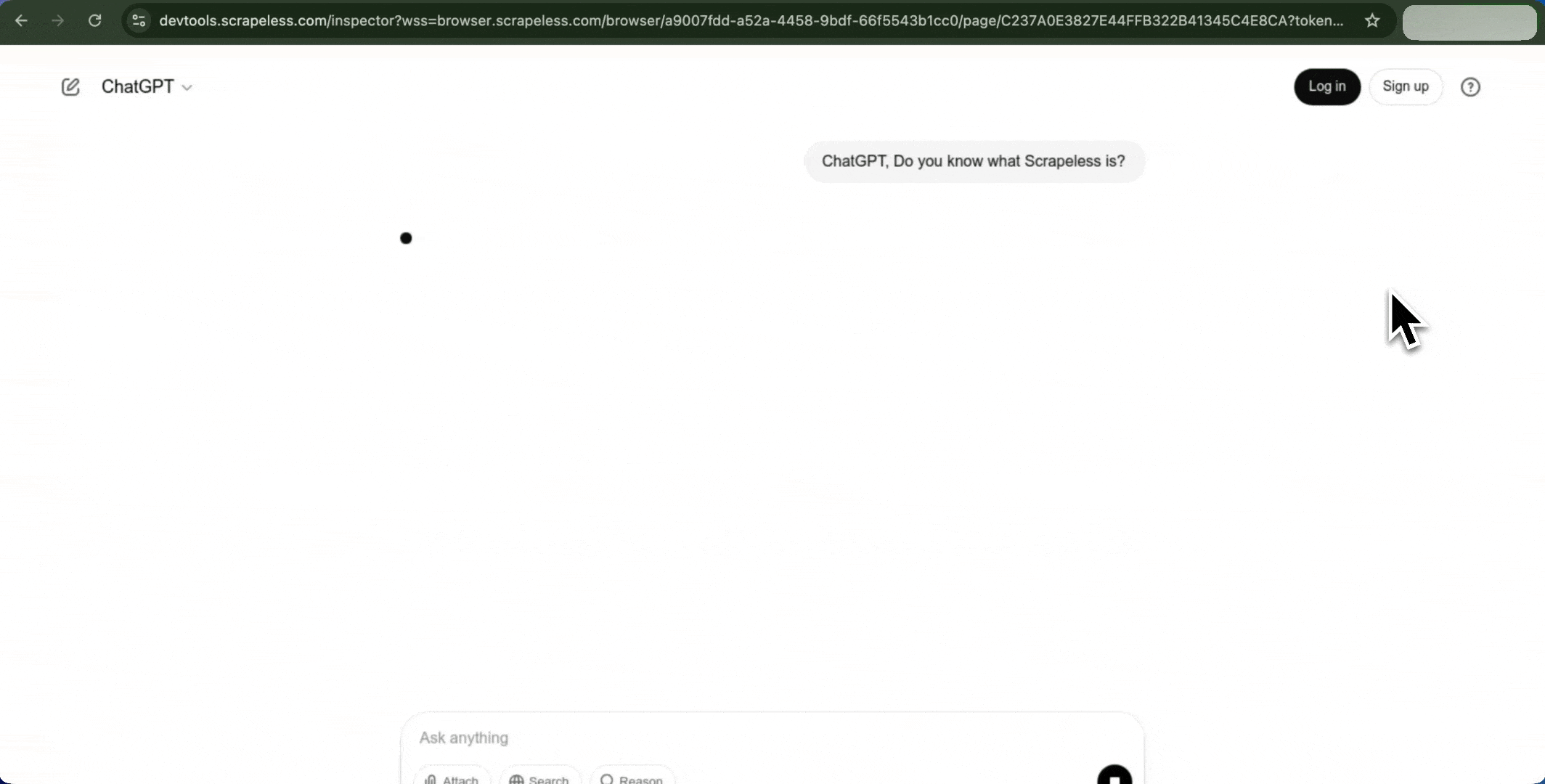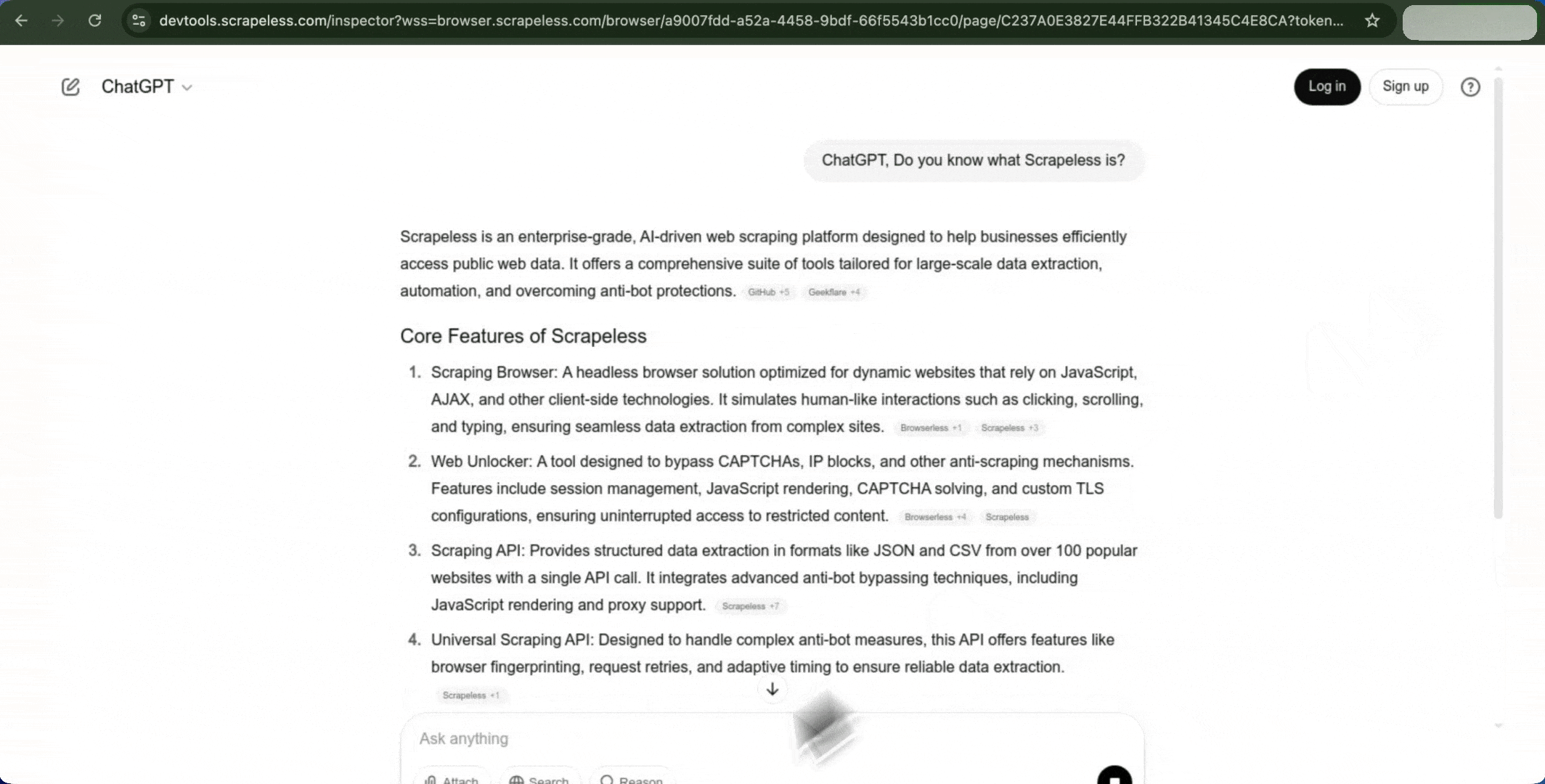
Scrapeless Scraping Browserは、セッションベースのワークフローを通じて自動化タスクを完全にサポートしています。PlaygroundまたはAPIを通じて開始された場合でも、すべてのプログラム実行をダッシュボードで同期的に追跡できます。
- ライブビューを開いて、実行時のステータスをリアルタイムで監視します。
- リモートユーザーインタラクションのためにライブURLを共有します。たとえば、ログインページやフォームの記入、支払いの完了など。
- セッションリプレイを使って、実行プロセス全体をレビューします。
しかし、次のことが気になるかもしれません:
これらのセッション機能とは具体的に何ですか?それは私にどのようにメリットがありますか?そして、どのように使用しますか?
このブログでは、Scrapeless Scraping Browserのセッションについて詳しく掘り下げます。以下をカバーします:
- ライブビューの概念と目的
- ライブURLとは何か
- ユーザーインタラクションのためのライブURLの使用方法
- なぜセッションリプレイが重要なのか
ライブビュー:リアルタイムプログラムモニタリング
Scrapeless Scraping Browserのライブビュー機能を使用すると、ブラウザのセッションをリアルタイムで追跡および制御できます。具体的には、クリック、入力、すべてのブラウザアクションを観察し、自動化ワークフローを監視し、手動でスクリプトをデバッグし、必要に応じてセッションを直接制御することが可能です。
ブラウザセッションの作成
まず、セッションを作成する必要があります。これには2つの方法があります。
方法1:Playground経由でセッションを作成
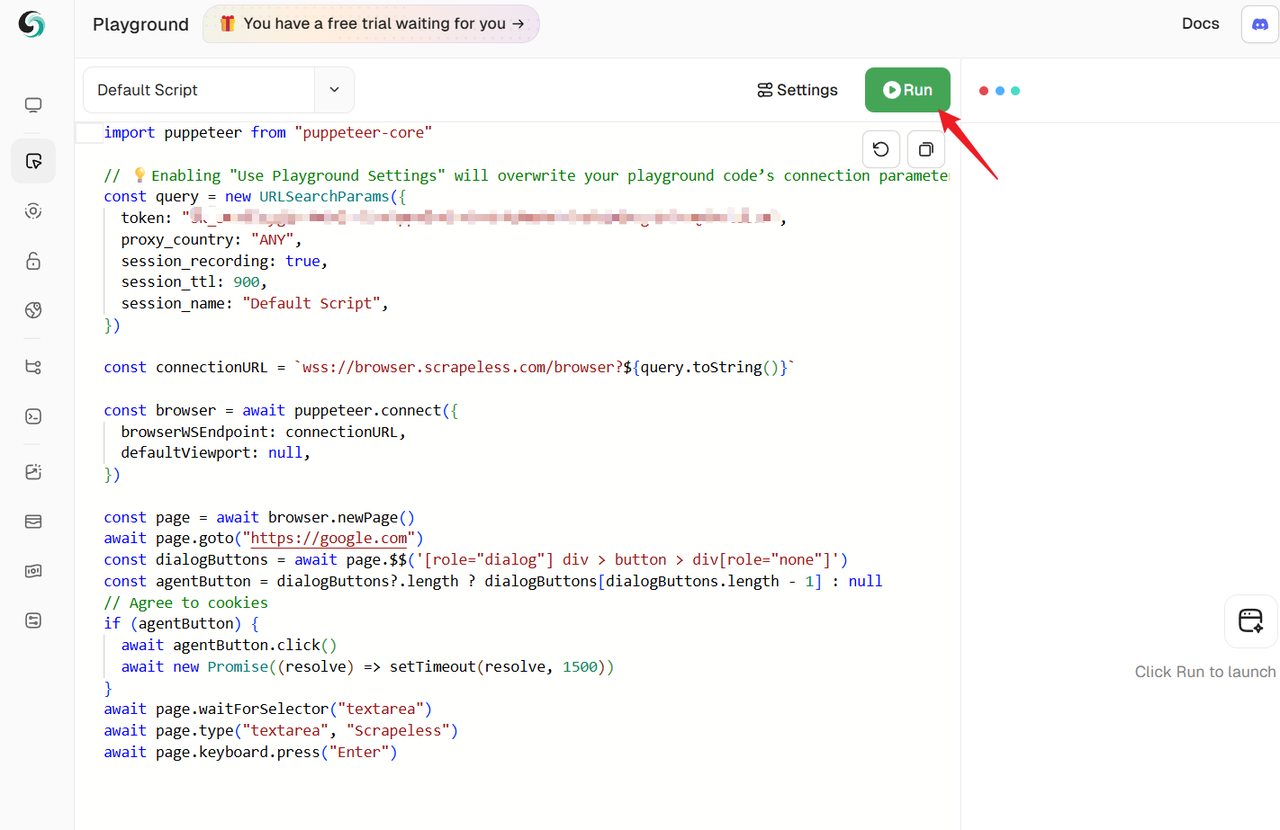
方法2:API経由でセッションを作成
APIを使用してセッションを作成することもできます。APIドキュメントを参照してください:Scraping Browser API Documentation。私たちのセッション機能は、リアルタイム表示機能を含むセッション管理を助けます。
JavaScript
const puppeteer =require('puppeteer-core');
const token = 'API Key'
// カスタムフィンガープリント
const fingerprint = {
platform: 'Windows',
}
const query = new URLSearchParams({
session_ttl: 180,
session_name: 'test_scraping', // セッション名
proxy_country: 'ANY',
token: token,
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
await new Promise(res => setTimeout(res, 3000));
await page.goto('https://www.google.com');
await new Promise(res => setTimeout(res, 3000));
await page.goto('https://www.youtube.com');
await new Promise(res => setTimeout(res, 3000));
await browser.close();
})();ライブセッションの表示
Scrapelessのセッション管理インターフェースでは、ライブセッションを簡単に表示できます。
方法1:ダッシュボードでライブセッションを直接表示
Playgroundでセッションを作成した後、右側にライブで実行中のセッションを見ることができます。
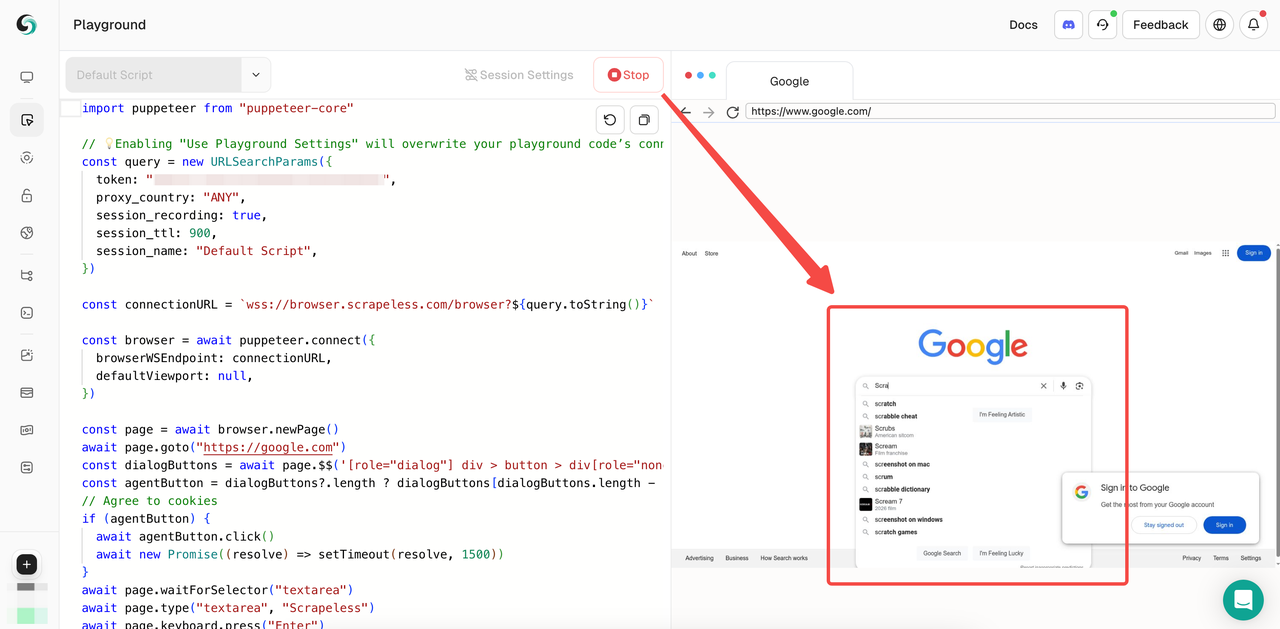
または、ライブセッションページでセッションの状態を確認できます:
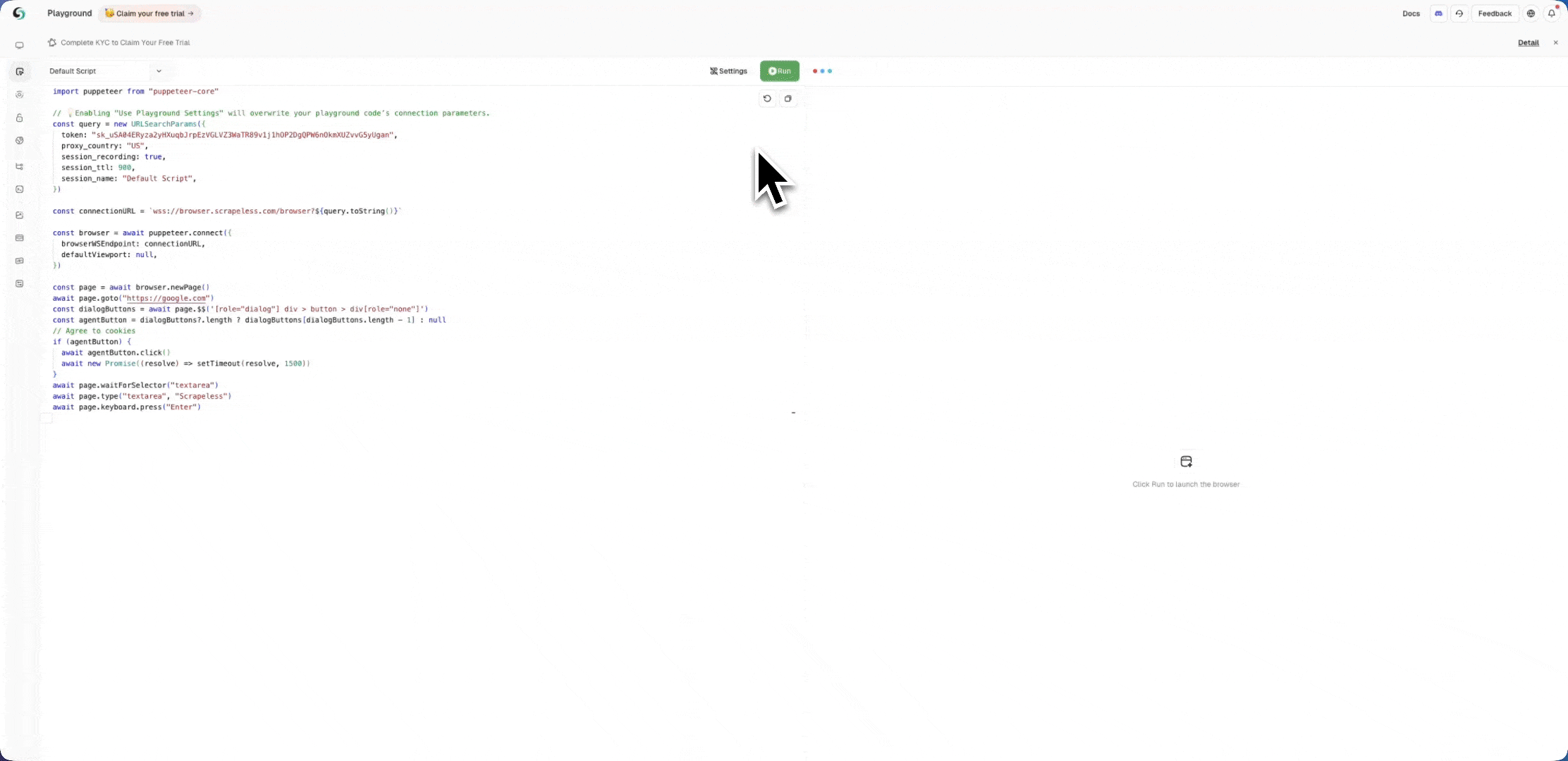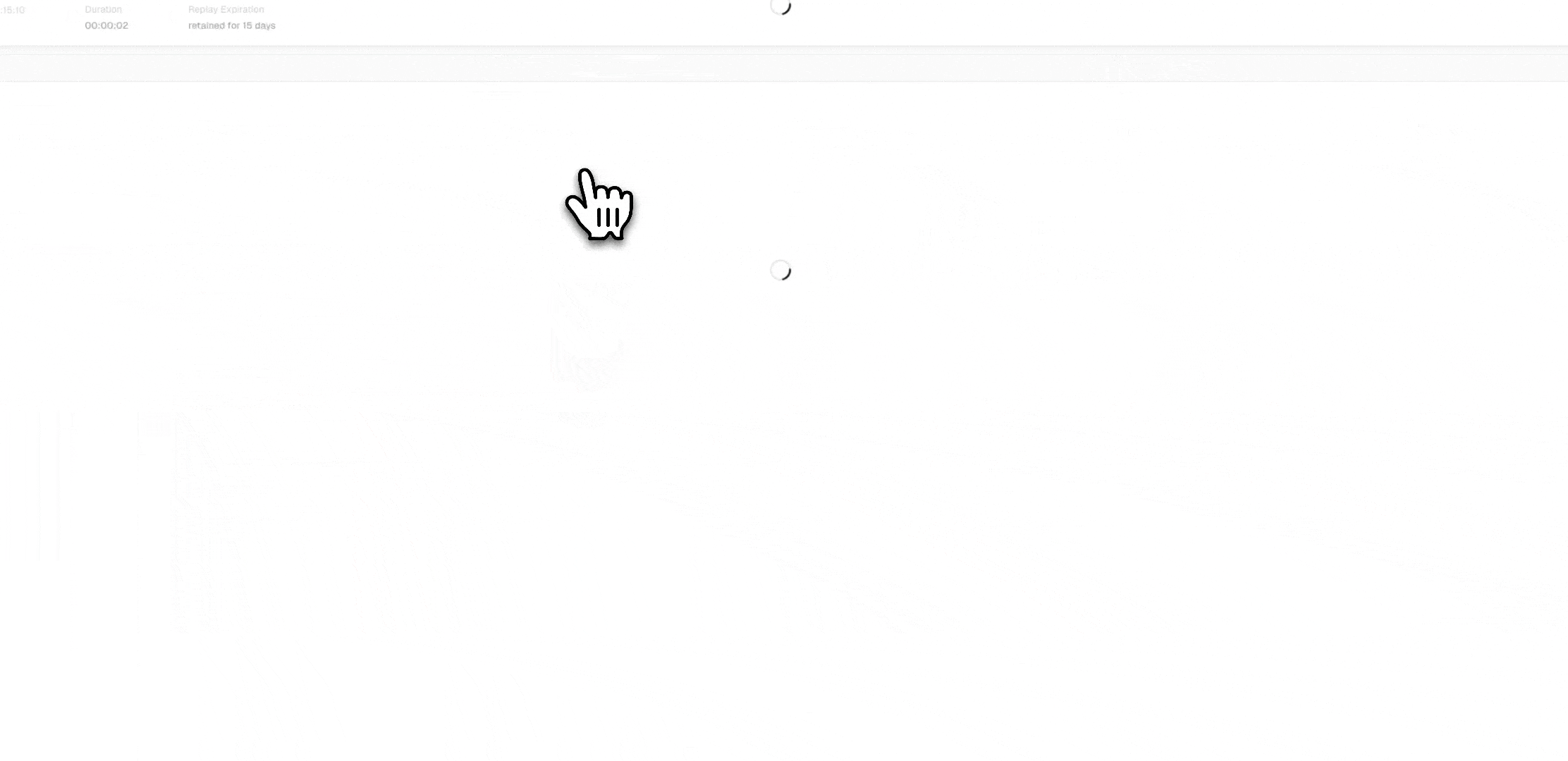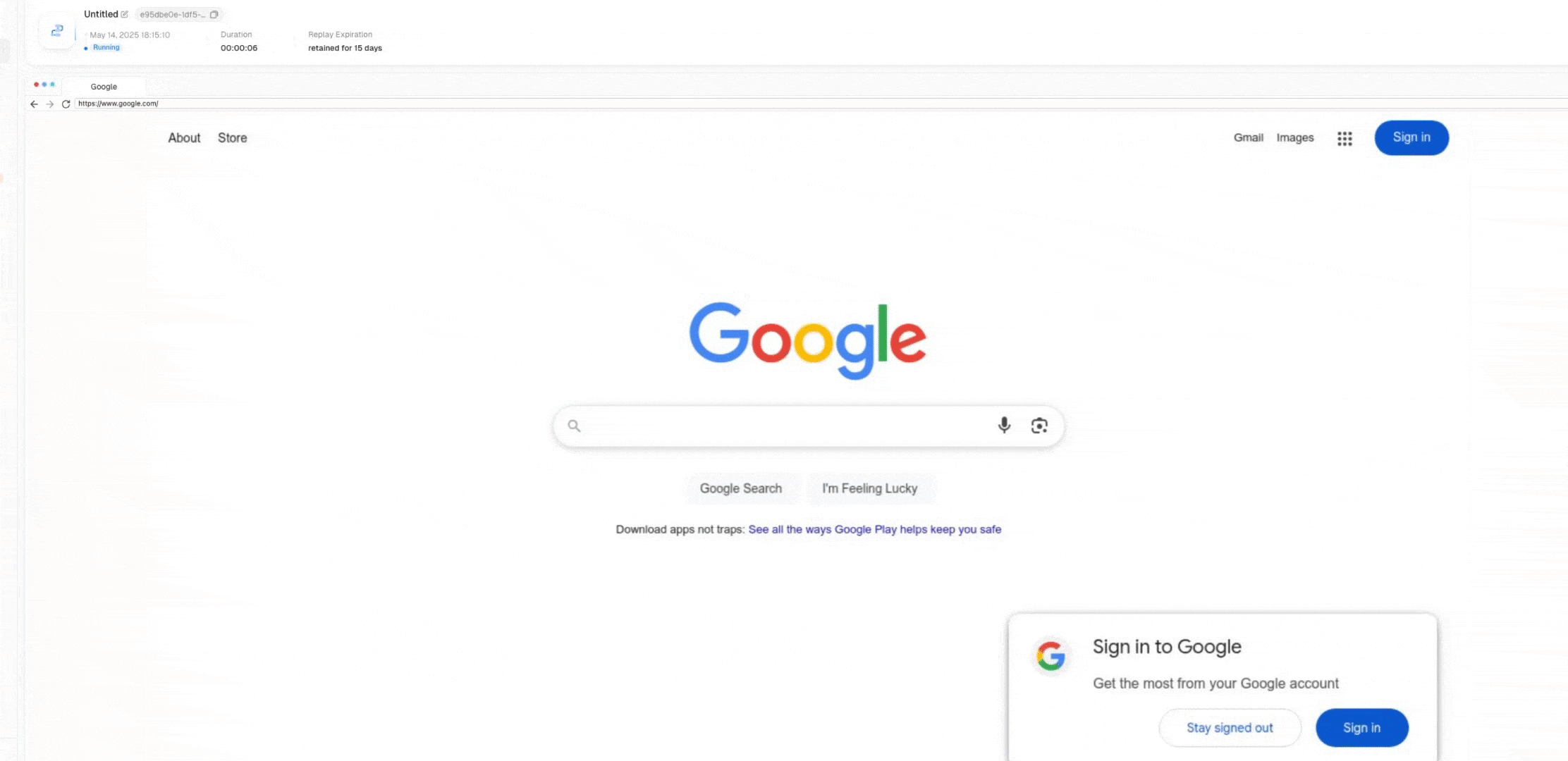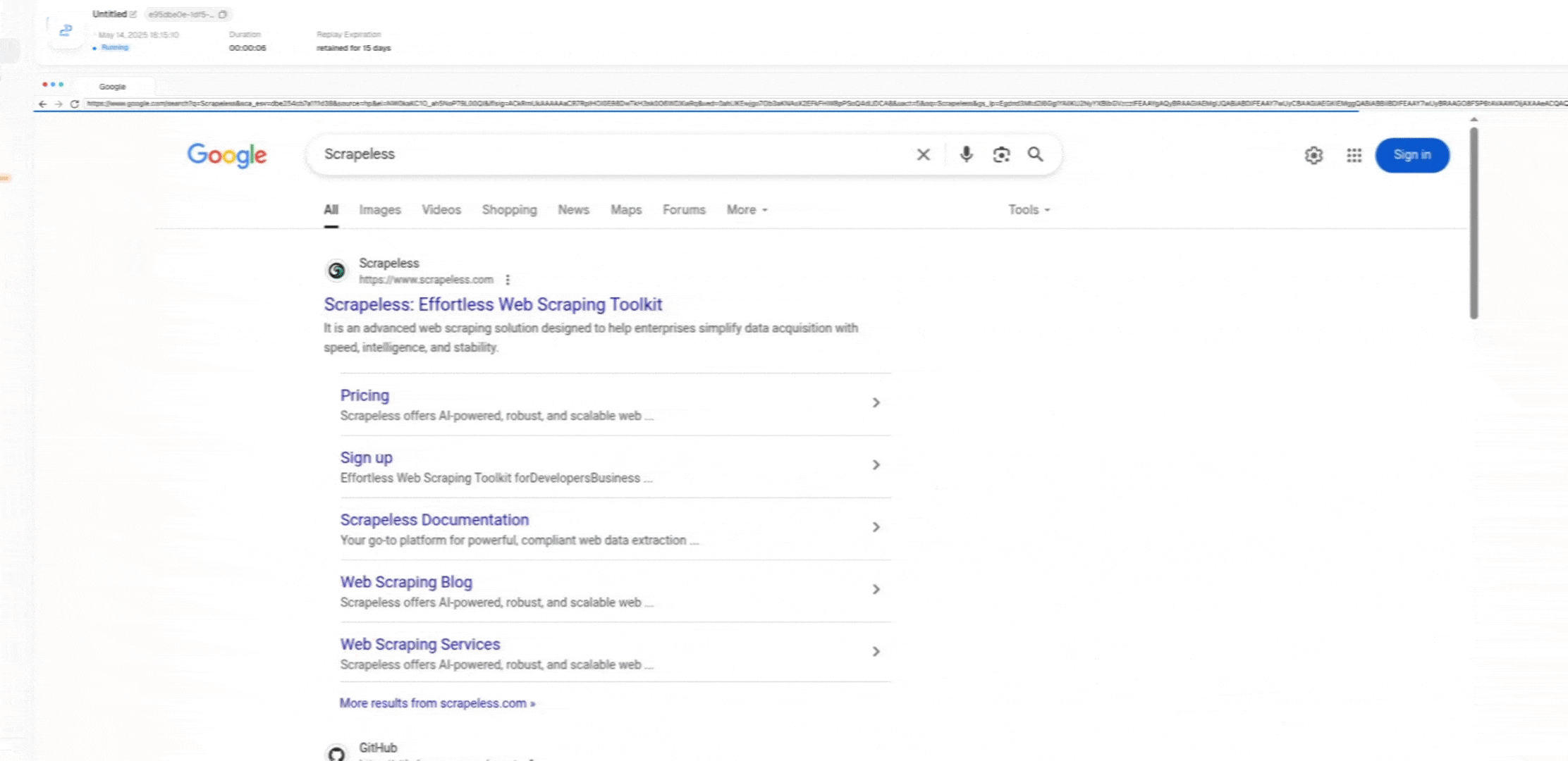
方法2:ライブURL経由でセッションを表示
ライブURLは、実行中のセッションのために生成され、ブラウザでプロセスをライブで見ることができます。
ライブURLは、以下の目的で便利です:
- デバッグと監視:すべてをリアルタイムで監視するか、チームメイトと共有。
- 人間のインタラクション:直接制御または入力—ユーザーがパスワードのような機密情報を安全に入力できるようにします。
ライブセッションページで「🔗」アイコンをクリックすることで、ライブURLをコピーできます。PlaygroundおよびAPI作成のセッションは、ライブURLをサポートしています。
- ダッシュボードからライブURLを取得
以下のチュートリアルをご覧ください:
- API経由でライブURLを取得
APIコールを介してライブURLを取得することもできます。以下のサンプルコードは、セッションAPIを介してすべての実行中のセッションを取得し、その後、ライブURL APIを使用して特定のセッションのライブビューを取得します:
Python
import requests
API_CONFIG = {
"host": "https://api.scrapeless.com",
"headers": {
"x-api-token": "API Key",
"Content-Type": "application/json"
}
}
async def fetch_live_url(task_id):
try:
live_response = requests.get(f"{API_CONFIG['host']}/browser/{task_id}/live", headers=API_CONFIG["headers"])
if not live_response.ok:
raise Exception(f"ライブURLの取得に失敗しました: {live_response.status_code} {live_response.reason}")
live_result = live_response.json()
if live_result and live_result.get("data"):
print(f"taskId: {task_id}")
print(f"liveUrl: {live_result['data']}")
else:print("このタスクに利用できるライブURLデータはありません")
except Exception as error:
print(f"タスク {task_id} のライブURLを取得中にエラーが発生しました: {str(error)}")
async def fetch_browser_sessions():
try:
session_response = requests.get(f"{API_CONFIG['host']}/browser/running", headers=API_CONFIG["headers"])
if not session_response.ok:
raise Exception(f"セッションの取得に失敗しました: {session_response.status_code} {session_response.reason}")
session_result = session_response.json()
sessions = session_result.get("data")
if not sessions or not isinstance(sessions, list) or len(sessions) == 0:
print("アクティブなブラウザセッションが見つかりません")
return
task_id = sessions[0].get("taskId")
if not task_id:
print("セッションデータにタスクIDが見つかりません")
return
await fetch_live_url(task_id)
except Exception as error:
print(f"ブラウザセッションの取得中にエラーが発生しました: {str(error)}")
import asyncio
asyncio.run(fetch_browser_sessions())- CDPコマンドを介してライブURLを取得する
コードが実行中にライブURLを取得するには、CDPコマンド Agent.liveURL を使用します:
Python
import asyncio
from pyppeteer import launcher
async def main():
try:
browser = await launcher.connect(
browserWSEndpoint="wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY"
)
page = await browser.newPage()
await page.goto('https://www.scrapeless.com')
client = await page.target.createCDPSession()
result = await client.send('Agent.liveURL')
print(result)
except Exception as e:
print(e)
asyncio.run(main())言及すべきハイライト:
ライブURLはリアルタイムの監視を可能にするだけでなく、人間と機械の相互作用も可能にします。
例えば: ユーザーにログインパスワードを入力してもらう必要があります。
「ああ、いや!私のプライベート情報を盗もうとしているの?絶対に無理!」
実際には、ユーザーは画面上で自分でデータを入力でき、すべてが100%プライベートに保たれます。この直接的でありながら安全な方法がライブURLによって可能になります — リモートインタラクションです。
ライブURL: どのようにコラボレーションとユーザーインタラクションを可能にするか
Scrapelessへの登録とログインを例に取り、ユーザーと直接対話する方法を説明します。
必要なコードは以下の通りです:
JavaScript
const puppeteer = require("puppeteer-core");
(async () => {
const fingerprint = {
// カスタム画面フィンガープリント
screen: {
width: 1920,
height: 1080,
},
args: {
// 画面フィンガープリントと同じ値でウィンドウサイズを設定
"--window-size": "1920,1080",
},
};
const query = new URLSearchParams({
token: "APIKey",
session_ttl: 600,
proxy_country: "ANY",
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const browserWsEndpoint = `wss://browser.scrapeless.com/browser?${query.toString()}`;
try {
const browser = await puppeteer.connect({
browserWSEndpoint: browserWsEndpoint,
});
const page = await browser.newPage();
await page.setViewport(null);
await page.goto(`https://app.scrapeless.com/passport/register`, {
timeout: 120000,
waitUntil: "domcontentloaded",
});
const client = await page.createCDPSession();
const result = await client.send("Agent.liveURL");
// ユーザーにライブURLを共有できます
console.log(`${result.liveURL}`);
// ユーザー登録のために5分待機
await page.waitForSelector("#none-existing-selector", {timeout: 300_000});
} catch (e) {
console.log(e);
}
})()上記を実行し、ユーザーとライブURLを共有します。例えば: Scrapeless登録URL。
これまでのステップでは:
- ウェブサイトにナビゲートする
- Scrapelessのホームページを訪れる
- ログインをクリックし、登録ページに入る
これらすべては、上記のコードを使用してセッションを作成することによって直接行うことができます。最も重要なステップは、ユーザーが登録を完了するために自分のメールとパスワードを入力する必要があるということです。
ユーザーとライブURLを共有した後、プログラムの実行プロセスをリモートで追跡できます。プログラムは自動的に実行され、ユーザーの操作を必要とするページにジャンプします。他の人によって入力されたパスワードは完全に隠され、ユーザーはパスワード漏洩を心配する必要はありません。
ユーザー操作プロセスをより直感的に反映するために、以下のインタラクションステップを参照してください:
以下のインタラクティブなプロセスは、ライブURL内で完全に実行されます
## セッションリプレイ:プログラムの実行を再生してすべてをデバッグ
セッションリプレイは、録画ライブラリを使用して構築されたユーザーセッションの動画のような再現です。リプレイは、ウェブアプリケーションのDOM状態のスナップショットに基づいて作成されます(ブラウザのメモリ内のHTML表現)。各スナップショットを再生すると、ウェブサイト訪問中に行われたすべてのページロード、リフレッシュ、ナビゲーションを含むセッション中に行われたアクションの記録を見ることができます。
セッションリプレイは、プログラムの動作のすべての側面をトラブルシュートするのに役立ちます。すべてのページ操作が記録され、ビデオとして保存されます。セッション中に問題を見つけた場合は、リプレイを通じてそれらをトラブルシュートし、調整することができます。
- セッションに移動
- **セッション履歴**をクリック
- セッションを探す
- セッションの詳細で、実行を視聴および確認するために再生ボタンをクリックします:
## 総括
Scrapeless Scraping Browserを使用すると、**リアルタイムで監視し、リモートでインタラクトし、すべてのステップを再生できます。**
- [**ライブビュー**](https://docs.scrapeless.com/en/scraping-browser/features/live-session/): ブラウザのアクティビティをライブストリームのように観察。すべてのクリックと入力が見えます!
- **ライブURL**: ユーザーが直接データを入力できる共有可能なリンクを生成します。完全にプライベートで、安全です。
- [**セッションリプレイ**](https://docs.scrapeless.com/en/scraping-browser/features/session-replay/): プログラムを再実行することなく、何が起こったのかを正確に再生してデバッグします。
開発者がデバッグする場合でも、PMがデモを行う場合でも、カスタマーサポートがユーザーを案内する場合でも、Scrapeless Sessionsがあなたをサポートします。
**自動化をスマートで人間に優しくする時間です。**
[**今すぐ無料トライアルを開始!**](https://app.scrapeless.com/passport/login?utm_source=official&utm_medium=blog&utm_campaign=session-url)Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


