
PowerShell で Selenium を使う方法 [チュートリアル 2025]
Advanced Data Extraction Specialist
Seleniumは、ブラウザの自動化によるWebスクレイピングとテストにおいて、依然として人気の選択肢です。これらのタスクは、PowerShellを含むスクリプト言語を使用して記述するのが一般的です。PowerShellでSeleniumの機能を活用するために、開発者コミュニティは、この統合を可能にする専用のバインディングを作成しました。
しかし、Cloudflareのような高度なアンチボットシステムにより、Webスクレイピングはますます困難になっています。この包括的なガイドでは、以下について説明します。
- SeleniumとPowerShellの始め方
- ブラウザでWebページを操作する方法
- アンチボットシステムからのブロックを回避する方法
- Scrapeless Scraping Browserを使用したCloudflareの課題の解決方法
始めましょう!
PowerShellでSeleniumを使用できますか?
Seleniumは、ITコミュニティで最も人気のあるヘッドレスブラウザライブラリです。その豊富で一貫性のあるAPIは、テストとWebスクレイピングのためのブラウザ自動化スクリプトを構築するのに最適です。
PowerShellは、Windowsクライアントとサーバーの両方の環境で使用できる強力なコマンドシェルです。ブラウザの自動化はスクリプトを完璧に補完するため、開発者コミュニティはPowerShell用のSelenium WebDriverの移植版であるselenium-powershellを作成しました。
このライブラリは現在メンテナンス担当者を募集していますが、PowerShellでのWeb自動化のための主要なモジュールであり続けています。
注: このSelenium PowerShellチュートリアルに進む前に基本事項を復習する必要がある場合は、ヘッドレスブラウザスクレイピングとPowerShellを使用したWebスクレイピングの基本事項を確認してください。
SeleniumとPowerShellを使用したWebスクレイピング:基本
注: この記事の例は、Selenium-PowerShellモジュールやCOMオブジェクトなどの機能がWindows固有であるため、Windowsオペレーティングシステム向けに設計されています。macOSまたはLinuxを使用している場合は、これらのスクリプトを適宜調整する必要があるかもしれません。
このセクションでは、PowerShellでSeleniumを使用する基本的な概念を紹介します。G2のような複雑なCloudflare保護サイトに進む前に、基本を理解しておくと役立ちます。
対象:G2レビュー
このチュートリアルでは、G2からのレビュー、特に次の場所にあるAirtableレビューのスクレイピングに焦点を当てます:https://www.g2.com/products/airtable/reviews。これは、従来のスクレイピング方法に課題を提示するCloudflare保護サイトの実例です。
G2を興味深いターゲットにする理由:
- ほとんどの基本的なスクレイピング試行をブロックするCloudflareによって保護されています。
- 市場調査に役立つ可能性のある貴重なビジネスソフトウェアレビューが含まれています。
- レビューは、データ抽出に最適な方法で構成されています。
- アンチボットシステムの背後に存在することが多い、高価値のビジネスデータのタイプを表しています。
まず、従来のPowerShellを使用したSeleniumのアプローチがこのサイトでどのように苦労するか、そしてScrapelessがどのように問題を解決できるかを見てみましょう。
適切なChromeDriverの取得(2025年2月)
PowerShellでSeleniumを設定する際の重要なステップは、Chromeブラウザと一致する正しいChromeDriverバージョンを確保することです。2025年2月28日現在、最新のChromeバージョンとその対応するWebDriverは次のとおりです。
Chrome Stable(133.0.6943.141):
- Windows 64ビット用ChromeDriver:chromedriver-win64.zip
- Windows 32ビット用ChromeDriver:chromedriver-win32.zip
- Mac(Intel)用ChromeDriver:chromedriver-mac-x64.zip
- Mac(M1/M2)用ChromeDriver:chromedriver-mac-arm64.zip
- Linux用ChromeDriver:chromedriver-linux64.zip
異なるChromeバージョン(ベータ版、開発版、カナリア版)を使用している場合は、Chrome for Testingダウンロードページの対応するセクションから一致するChromeDriverをダウンロードしてください。
システムに適切なChromeDriverをダウンロードし、ZIPファイルを解凍して、実行ファイルをプロジェクトフォルダに配置します。次に、PowerShellスクリプトでこの場所を参照します。
$Driver = Start-SeChrome -WebDriverDirectory '/path/to/chromedriver/folder' -Headless正しいChromeDriverバージョンを使用することが不可欠です。バージョンが一致しない場合、Seleniumはエラーをスローし、Chromeを適切に制御できなくなります。
基本的なSeleniumを使用したG2のスクレイピングの試行
次に、基本的なSelenium設定を使用してG2レビューにアクセスしてみましょう。
Import-Module -Name Selenium
# Selenium WebDriverを初期化します
$Driver = Start-SeChrome -WebDriverDirectory './chromedriver-win64' -Headless
# G2レビューページにアクセスします
Enter-SeUrl 'https://www.g2.com/products/airtable/reviews' -Driver $Driver
# ページの読み込みを待ちます
Start-Sleep -Seconds 5
# ページタイトルを取得します
$Title = $Driver.Title
Write-Host "ページタイトル:$Title"
# ページソースを出力します
$Html = $Driver.PageSource
$Html | Out-File -FilePath "g2_response.html"
# ブラウザを閉じます
Stop-SeDriver -Driver $Driverこのスクリプトを実行すると、実際のG2レビューページを取得する代わりに、おそらく次のようになります。
- Cloudflareチャレンジページ
- 「しばらくお待ちください…」または「ブラウザを確認しています…」などのタイトル
- CloudflareのJavaScriptチャレンジを含むHTML
これは、CloudflareがSeleniumのような自動化されたブラウザを検出し、基本的なSelenium設定では自動的に解決できないチャレンジを表示するためです。
G2スクレイピングチャレンジ:レビュー構造の理解
データの抽出を試みる前に、スクレイピングしようとしているものを理解しましょう。G2レビューには、次のものが含まれる構造化された形式があります。
- レビュータイトル:通常、レビューの要約を引用したものです。
- 評価:星(5つ星満点)で表示されます。
- 日付:レビューが公開された日時。
- レビュー本文:「最も気に入っている点」や「気に入らない点」などのセクションに分割されています。
- ユーザー情報:レビューを書いた人の詳細。
HTML構造における一般的なG2レビューの例:
<div class="paper__bd">
<div class="d-f mb-1">
<div class="f-1 d-f ai-c mb-half-small-only">
<div class="stars large xlarge--medium-down stars-10"></div>
<div class="time-stamp pl-4th ws-nw">
<span><span class="x-current-review-date" data-poison-date="">
<meta content="2025-02-11" itemprop="datePublished">
<time datetime="2025-02-11">Feb 11, 2025</time>
</span></span>
</div>
</div>
</div>
<div class="d-f">
<div class="f-1">
<div data-poison="">
<a class="pjax" href="https://www.g2.com/products/airtable/reviews/airtable-review-10822745">
<div class="m-0 l2" itemprop="name">"Helped us get a handle on our complicated team-based scheduling and management."</div>
</a>
</div>
<div data-poison-text="">
<div itemprop="reviewBody">
<div>
<div class="l5 mt-2">What do you like best about Airtable?</div>
<div>
<p class="formatted-text">The best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do...</p>
</div>
</div>
<!-- More review sections... -->
</div>
</div>
</div>
</div>
</div>解決策:Cloudflareの回避のためのScrapeless Scraping Browser
高度なSelenium設定を使用しても、多くのスクレイピングプロジェクトはCloudflareのセキュリティシステムによってブロックされます。ここで、Scrapeless Scraping Browserが画期的なソリューションとして登場します。
Scrapeless Scraping Browserとは?
Scrapeless Scraping Browserは、独自のインフラストラクチャを維持することなくJavaScriptの課題を回避できるヘッドレスブラウザ環境を提供する高性能ソリューションです。PuppeteerおよびPlaywrightとシームレスに統合され、次のような機能を提供します。
- 99.9%の成功率Cloudflareチャレンジの回避
- Puppeteer/Playwrightとのシームレスな互換性
- AI駆動型で、最新のセキュリティポリシーに自動的に適応します。
- 地理的に制限されたコンテンツにアクセスするためのグローバルカバレッジ
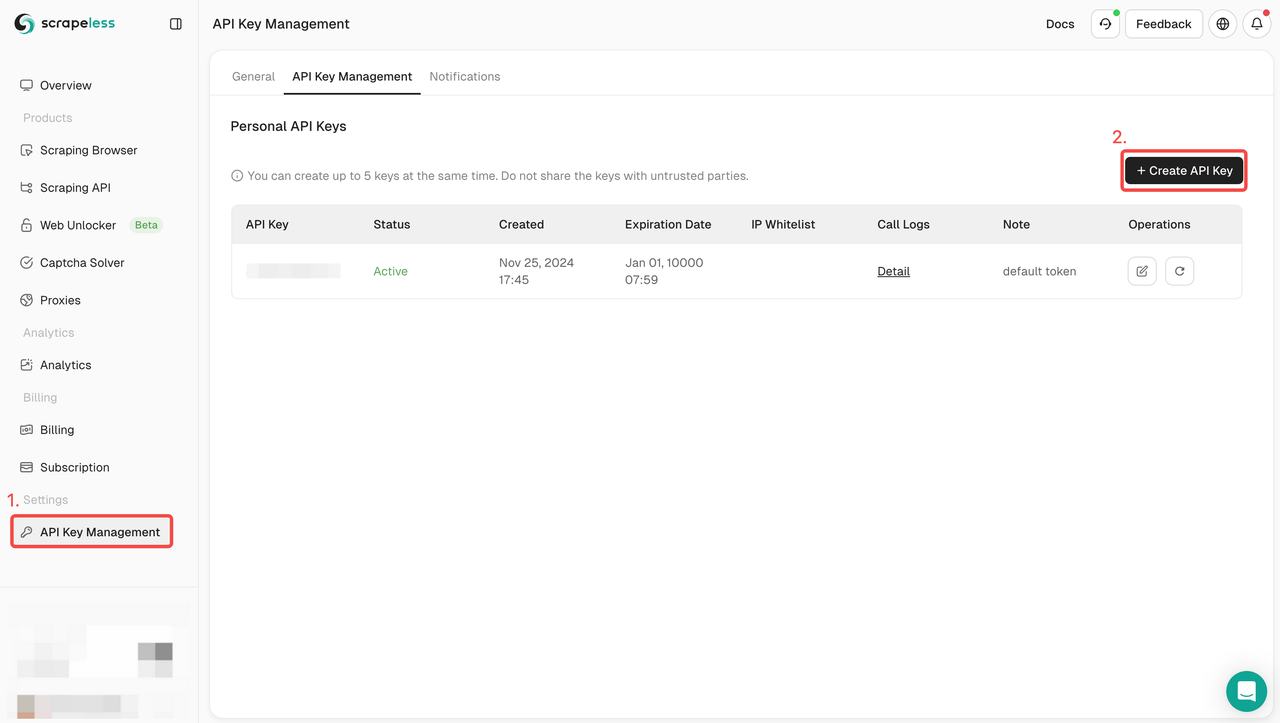
Scrapelessダッシュボードにログインして、APIキー管理でAPIキーを作成してください。
Scrapeless Scraping Browserを使用したG2レビューの抽出
PowerShellを使用した標準のSeleniumがG2などのCloudflare保護サイトで苦労する理由を理解したので、Scrapeless Scraping Browserを使用したソリューションを実装しましょう。
Puppeteerを使用したScrapeless Scraping Browserの設定
Scrapeless Scraping Browserを使用する最も効果的な方法は、Puppeteerを使用したNode.jsです。設定方法は次のとおりです。
- Node.jsのインストール
- nodejs.orgからNode.jsをダウンロードしてインストールします。
- コマンドプロンプトを開き、「node --version」と「npm --version」と入力してインストールを確認します。
- プロジェクトフォルダの作成
- スクリプトプロジェクト用の新しいフォルダを作成します。
- このフォルダでコマンドプロンプトを開きます。
- 必要なパッケージのインストール
- npmを使用してpuppeteer-coreをインストールします。
npm install puppeteer-core- スクリプティングスクリプトの作成
- 次のコードを含むscrape.jsというファイルを作成します。
// scrape.js
const puppeteer = require('puppeteer-core');
async function scrapeG2Reviews() {
// 実際のScrapeless APIトークンに置き換えます
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// Scrapeless Scraping Browserへの接続を設定します
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=180&proxy_country=ANY`;
console.log('Scrapeless Scraping Browserに接続しています...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('接続しました!');
const page = await browser.newPage();
// ナビゲーションのタイムアウトを長く設定します
page.setDefaultNavigationTimeout(120000);
// すべてのレビューを保持する配列
const allReviews = [];
// スクラップするページ数
const pagesToScrape = 3;
for (let currentPage = 1; currentPage <= pagesToScrape; currentPage++) {
console.log(`ページ${currentPage}に移動しています...`);
// 特定のページ番号に直接移動します
const pageUrl = currentPage === 1
? 'https://www.g2.com/products/airtable/reviews'
: `https://www.g2.com/products/airtable/reviews?page=${currentPage}`;
await page.goto(pageUrl, {
waitUntil: 'networkidle2',
timeout: 60000
});
console.log(`ページ${currentPage}が読み込まれました。スクリーンショットを撮っています...`);
// ページが正しく読み込まれたことを確認するためにスクリーンショットを撮ります
await page.screenshot({ path: `g2_page_${currentPage}.png` });
// ページコンテンツの読み込みを待ちます
// 構造が変更されている可能性があるため、さまざまなセレクターを試してみてください
try {
console.log('コンテンツの読み込みを待機しています...');
// 最初に元のセレクターを試します
await page.waitForSelector('.paper__bd', { timeout: 10000 })
.then(() => console.log('セレクターが見つかりました:.paper__bd'))
.catch(() => console.log('セレクター.paper__bdが見つかりません。代替案を試しています...'));
// まだここにある場合は、別の方法でページ構造を確認しましょう
console.log('ページ構造を分析しています...');
// 正しいページにいることを確認するためにページタイトルを取得します
const pageTitle = await page.title();
console.log('ページタイトル:', pageTitle);
// より一般的なアプローチでレビューを抽出します
console.log('レビューを抽出しています...');
// より堅牢なアプローチでレビューを抽出してみてください
const pageReviews = await page.evaluate(() => {
// 複数のセレクターを使用してレビューコンテナを探します
const reviewElements = Array.from(
document.querySelectorAll('.paper__bd, .review-item, .reviews-section article, [data-testid="review-card"]')
);
console.log(`見つかった可能性のあるレビュー要素の数:${reviewElements.length}`);
if (reviewElements.length === 0) {
// 特定のセレクターでレビューが見つからない場合は、ページ構造をダンプします
const html = document.documentElement.outerHTML;
return { error: 'レビューが見つかりません', html: html.substring(0, 5000) }; // デバッグのため最初の5000文字
}
return reviewElements.map(review => {
// 複数の可能性のあるセレクターを使用してタイトルを取得してみてください
const titleElement =
review.querySelector('[itemprop="name"], .review-title, h3, h4') ||
review.querySelector('a.pjax div');
const title = titleElement ? titleElement.innerText.trim() : 'タイトルなし';
// 複数の可能性のあるセレクターを使用して日付を取得してみてください
const dateElement =
review.querySelector('time, .review-date, [data-testid="review-date"]') ||
review.querySelector('.time-stamp');
const date = dateElement ? dateElement.innerText.trim() : '日付なし';
// 複数の方法で評価を取得してみてください
let rating = 0;
const starsElement = review.querySelector('.stars, .rating, [data-testid="star-rating"]');
if (starsElement) {
// stars-Xクラスを確認します
const starsClass = starsElement.className;
const starsMatch = starsClass.match(/stars-(\d+)/);
if (starsMatch) {
rating = parseInt(starsMatch[1]) / 2;
} else {
// そうでない場合は、評価が含まれている可能性のあるaria-labelを確認します
const ariaLabel = starsElement.getAttribute('aria-label');
if (ariaLabel) {
const ratingMatch = ariaLabel.match(/(\d+(\.\d+)?)/);
if (ratingMatch) {
rating = parseFloat(ratingMatch[1]);
}
}
}
}
// 複数の可能性のあるセレクターを使用してレビューテキストを取得してみてください
const textElements = review.querySelectorAll('.formatted-text, .review-content, p, [data-testid="review-content"]');
let content = '';
textElements.forEach(el => {
const text = el.innerText.trim();
if (text && !text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim() || 'コンテンツが見つかりません'
};
});
});
if (pageReviews.error) {
console.log('レビューの抽出エラー:', pageReviews.error);
console.log('ページHTMLスニペット:', pageReviews.html);
} else {
console.log(`ページ${currentPage}から${pageReviews.length}件のレビューを抽出しました`);
// コレクションに追加します
allReviews.push(...pageReviews);
}
} catch (error) {
console.error('ページのエラー:', error);
// デバッグのためにエラー発生時に別のスクリーンショットを撮ります
await page.screenshot({ path: `error_page_${currentPage}.png` });
// デバッグのためにページHTMLをダンプします
const html = await page.content();
require('fs').writeFileSync(`error_page_${currentPage}.html`, html);
console.log(`error_page_${currentPage}.htmlにエラーページHTMLを保存しました`);
}
// サーバーに優しくするためにページ間の短い一時停止
await new Promise(r => setTimeout(r, 2000));
}
console.log(`合計で${allReviews.length}件のレビューを抽出しました`);
// すべてのレビューをファイルに保存します
require('fs').writeFileSync('g2_reviews.json', JSON.stringify(allReviews, null, 2));
console.log('レビューをg2_reviews.jsonに保存しました');
await browser.close();
console.log('完了しました!');
}
scrapeG2Reviews().catch(console.error);- スクリプトの実行
- 次のようにスクリプトを実行します。
node scrape.jsJSON出力形式
スクリプトを実行した後、次のようなコンテンツを含むg2_reviews.jsonファイルが作成されます。
[
{
"title": "\"Helped us get a handle on our complicated team-based scheduling and management.\"",
"date": "Feb 11, 2025",
"rating": 5,
"content": "What do you like best about Airtable?\nThe best part about airtable is it's customiizable nature. We worked with a tech specialist to configure Airtable to meet our unique needs and it has so far been adaptable to everything we needed it to do. It has a huge capacity in terms of features and we were able to get it up and running in a fairly short period of time.\n\nWhat do you dislike about Airtable?\nThere are no real downsides except the intial learning curve. I believe we could have built Airtable out as we needed but it would have been a bigger intial time investment. Working with a tech specialist who knew Airtable well really helped us get up and running fast. It was worth the cost."
},
{
"title": "\"Great for organization, has changed our workflow\"",
"date": "Feb 8, 2025",
"rating": 4.5,
"content": "What do you like best about Airtable?\nWhat I like best about Airtable is its flexibility and customizability. It allows us to create databases that perfectly fit our needs, with custom fields, views, and formulas. The ability to link records between tables is incredibly powerful.\n\nWhat do you dislike about Airtable?\nSometimes the learning curve can be steep for new users, especially when dealing with more complex formulas and automations. The pricing can also become quite expensive as your needs grow and you require more records or features."
},
{
"title": "\"Powerful database tool with a spreadsheet interface\"",
"date": "Jan 29, 2025",
"rating": 4,
"content": "What do you like best about Airtable?\nAirtable combines the familiarity of spreadsheets with the power of a database. I appreciate how it allows for different views of the same data - grid, kanban, calendar, etc. It's intuitive enough for non-technical users but powerful enough for complex data management.\n\nWhat do you dislike about Airtable?\nThe free tier is quite limited, and pricing jumps significantly for premium features. Sometimes performance can slow down with large datasets, and there are occasional sync issues when multiple team members are editing simultaneously."
}
]PowerShell統合:PowerShellからのScrapeless Scraping Browserの使用
PowerShellでの作業を好む場合は、Node.jsスクリプトを呼び出して結果を処理するラッパースクリプトを作成できます。
- PowerShellラッパースクリプトの作成
- 次のコードを含むrun-scraper.ps1というファイルを作成します。
# ファイル:run-scraper.ps1
Write-Host "Scrapeless Scraping Browserを使用したG2.comのスクレイピングを開始します..."
# 出力フォルダを作成します
$outputFolder = "G2_Reviews_" + (Get-Date -Format "yyyyMMdd_HHmmss")
New-Item -ItemType Directory -Path $outputFolder -Force | Out-Null
# Node.jsスクリプトを実行し、出力を取得します
$jsonFile = Join-Path $outputFolder "reviews.json"
node scrape.js > $jsonFile
Write-Host "Node.jsスクレイピングが完了しました。結果を処理しています..."
# ファイルに有効なJSONデータが含まれているかどうかを確認します
try {
# ファイルの内容を読み取ります
$content = Get-Content -Path $jsonFile -Raw
# JSON部分を抽出します(すべてのconsole.logメッセージの後の出力であると仮定します)
if ($content -match '\[.*\]') {
$jsonContent = $Matches[0]
Set-Content -Path $jsonFile -Value $jsonContent
# JSONをPowerShellオブジェクトに解析します
$reviews = $jsonContent | ConvertFrom-Json
# CSVにエクスポートします
$csvPath = Join-Path $outputFolder "g2_reviews.csv"
$reviews | Export-Csv -Path $csvPath -NoTypeInformation -Encoding UTF8
Write-Host "レビューを$($reviews.Count)件正常に抽出しました"
Write-Host "結果を次の場所に保存しました:$csvPath"
# 基本的な分析
$averageRating = ($reviews | Measure-Object -Property rating -Average).Average
Write-Host "平均評価:5つ星満点中$averageRating"
$ratingDistribution = $reviews | Group-Object -Property rating | Sort-Object -Property Name
foreach ($ratingGroup in $ratingDistribution) {
Write-Host "$($ratingGroup.Name)つ星:$($ratingGroup.Count)件のレビュー"
}
} else {
Write-Error "出力にJSONデータが見つかりません"
}
} catch {
Write-Error "JSONデータの処理エラー:$_"
}- PowerShellラッパースクリプトの実行
- PowerShellを開きます。
- プロジェクトフォルダに移動します。
- スクリプトを実行します。
.\run-scraper.ps1- 結果の確認
- スクリプトは、日付付きのフォルダにJSONとCSVの結果を作成します。
- 基本的な統計がコンソールに表示されます。
- CSVファイルは、Excelなどのアプリケーションで開いて、さらに分析できます。
詳細な例:Scrapeless Scraping Browserを使用した複数ページのスクレイピング
より高度なユースケースとして、複数のページからレビューをスクレイピングする方法を示す例を次に示します。
// ファイル:scrape-g2-multipage.js
const puppeteer = require('puppeteer-core');
async function scrapeG2ReviewsMultiPage() {
// 実際のScrapeless APIトークンに置き換えます
const API_TOKEN = 'YOUR_API_TOKEN_HERE';
// Scrapeless Scraping Browserへの接続を設定します
const connectionURL = `wss://browser.scrapeless.com/browser?token=${API_TOKEN}&session_ttl=300&proxy_country=ANY`;
console.log('Scrapeless Scraping Browserに接続しています...');
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('接続しました!G2.comを開いています...');
const page = await browser.newPage();
// 適切なナビゲーションタイムアウトを設定します
page.setDefaultNavigationTimeout(60000);
// すべてのレビューを保持する配列
const allReviews = [];
// 現在のページからレビューを抽出する関数
const extractReviews = async () => {
return page.evaluate(() => {
return Array.from(document.querySelectorAll('.paper__bd')).map(review => {
// タイトル
const titleElement = review.querySelector('a.pjax div[itemprop="name"]');
const title = titleElement ? titleElement.innerText : 'タイトルなし';
// 日付
const dateElement = review.querySelector('time');
const date = dateElement ? dateElement.innerText : '日付なし';
// 評価
const starsElement = review.querySelector('.stars');
let rating = 0;
if (starsElement) {
const starsClass = starsElement.className;
const match = starsClass.match(/stars-(\d+)/);
if (match) {
rating = parseInt(match[1])/2;
}
}
// レビューコンテンツ
const contentElements = review.querySelectorAll('.formatted-text');
let content = '';
contentElements.forEach(el => {
const text = el.innerText;
if (!text.includes('Review collected by and hosted on G2.com')) {
content += text + '\n\n';
}
});
return {
title,
date,
rating,
content: content.trim()
};
});
});
};
// 最初のページに移動します
await page.goto('https://www.g2.com/products/airtable/reviews', {
waitUntil: 'networkidle2'
});
// レビューの読み込みを待ちます
await page.waitForSelector('.paper__bd', {timeout: 30000});
// 最初のページのスクリーンショットを撮ります
await page.screenshot({ path: 'page1.png' });
// スクラップするページ数(デモ用制限)
const pagesToScrape = 3;
let currentPage = 1;
while (currentPage <= pagesToScrape) {
console.log(`ページ${currentPage}をスクレイピングしています...`);
// 現在のページからレビューを抽出します
const pageReviews = await extractReviews();
console.log(`ページ${currentPage}で${pageReviews.length}件のレビューが見つかりました`);
// コレクションに追加します
allReviews.push(...pageReviews);
// 次のページボタンがあるかどうかを確認します
javascript
const hasNextPage = await page.evaluate(() => {
const nextButton = document.querySelector('a.next_page');
return nextButton && !nextButton.classList.contains('disabled');
});
if (hasNextPage && currentPage < pagesToScrape) {
// 次のページURLに直接移動
currentPage++;
await page.goto(`https://www.g2.com/products/airtable/reviews?page=${currentPage}`, {
waitUntil: 'networkidle2'
});
// 新しいページのレビューの読み込みを待ちます
await page.waitForSelector('.paper__bd', {timeout: 30000});
// 新しいページのスクリーンショットを撮ります
await page.screenshot({ path: `page${currentPage}.png` });
} else {
break;
}
}
console.log(`合計で${allReviews.length}件のレビューを抽出しました。`);
// すべてのレビューをJSONとして出力します
console.log(JSON.stringify(allReviews, null, 2));
await browser.close();
console.log('完了しました!');
}
scrapeG2ReviewsMultiPage().catch(console.error);Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


