
Scrapeless SDKが公式に launchされました: ウェブスクレイピングとブラウザのためのオールインワンソリューション
Expert Network Defense Engineer
私たちは、公式のScrapeless SDKが現在ライブであることを発表できることを大変嬉しく思います!🎉
これは、あなたと強力なScrapelessプラットフォームの間の究極の架け橋です。ウェブデータ抽出とブラウザ自動化をこれまで以上にシンプルにします。
わずか数行のコードで、大規模なウェブスクレイピングとSERPデータ抽出を実行でき、Agentic AIシステムに安定したサポートを提供します。
Scrapeless SDKは、すべてのコアサービスの公式ラッパーを開発者に提供します。これには以下が含まれます:
- スクレイピングブラウザ:Puppeteer&Playwrightベースの自動化レイヤーで、リアルなクリック、フォームの入力、その他の高度な機能をサポートします。
- ブラウザAPI:ブラウザセッションの作成および管理、特に高度な自動化ニーズに最適です。
- スクレイピングAPI:ウェブページを取得し、複数のフォーマットでコンテンツを抽出します。
- ディープSERP API:Googleなどの検索結果を簡単にスクレイピングできます。
- ユニバーサルスクレイピングAPI:JSレンダリング、スクリーンショット、およびメタデータ抽出を伴う汎用ウェブスクレイピング。
- プロキシAPI:IPアドレスや地理的位置を含むプロキシを瞬時に設定できます。
データエンジニア、クローラ開発者、またはデータ駆動型製品を構築しているスタートアップの一部であれば、Scrapeless SDKはあなたが必要なデータをより迅速かつ信頼性高く取得する手助けをします。
ブラウザ自動化から検索エンジン結果の解析、ウェブデータの抽出から自動プロキシ管理まで、Scrapeless SDKはあなたのデータ取得ワークフロー全体を効率化します。
Scrapeless SDK 使用参考
前提条件
ログインしてScrapelessダッシュボードからAPIキーを取得してください
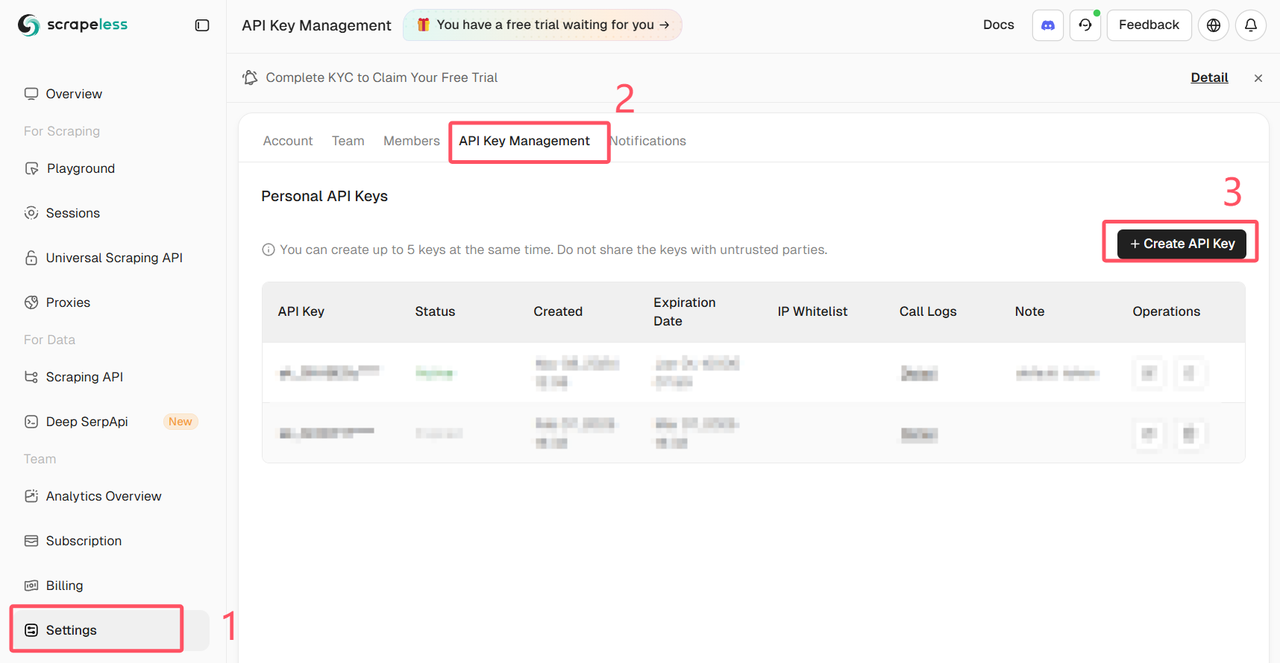
インストール
- npm:
Bash
npm install @scrapeless-ai/sdk- yarn:
Bash
yarn add @scrapeless-ai/sdk- pnpm:
Bash
pnpm add @scrapeless-ai/sdk基本セットアップ
JavaScript
import { Scrapeless } from '@scrapeless-ai/sdk';
// クライアントの初期化
const client = new Scrapeless({
apiKey: 'your-api-key' // https://scrapeless.com からAPIキーを取得
});環境変数
SDKは環境変数を使用して設定することもできます:
Bash
# 必須
SCRAPELESS_API_KEY=your-api-key
# オプション - カスタムAPIエンドポイント
SCRAPELESS_BASE_API_URL=https://api.scrapeless.com
SCRAPELESS_ACTOR_API_URL=https://actor.scrapeless.com
SCRAPELESS_STORAGE_API_URL=https://storage.scrapeless.com
SCRAPELESS_BROWSER_API_URL=https://browser.scrapeless.com
SCRAPELESS_CRAWL_API_URL=https://crawl.scrapeless.comスクレイピングブラウザ(ブラウザ自動化ラッパー)
スクレイピングブラウザモジュールは、ScrapelessブラウザAPIの上に構築された高レベルで統一されたブラウザ自動化用APIを提供します。これはPuppeteerとPlaywrightの両方をサポートし、標準のページオブジェクトにrealClick、realFill、liveURLなどの高度なメソッドを拡張し、より人間らしい自動化を実現します。
Puppeteerの例:
Python
import { PuppeteerBrowser } from '@scrapeless-ai/sdk';
const browser = await PuppeteerBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('現在のページURL:', urlInfo.liveURL);
await browser.close();Playwrightの例:
Python
import { PlaywrightBrowser } from '@scrapeless-ai/sdk';
const browser = await PlaywrightBrowser.connect({
session_name: 'my-session',
session_ttl: 180,
proxy_country: 'US'
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.realClick('#login-btn');
await page.realFill('#username', 'myuser');
const urlInfo = await page.liveURL();
console.log('現在のページURL:', urlInfo.liveURL);
await browser.close();👉 ドキュメントを訪問して、さらに多くの使用例を確認してください
👉 GitHub経由でのワンクリック統合
実践例:Nike.comで「エアマックス」検索結果をスクレイピング
靴の比較プラットフォームのバックエンドシステムを構築していて、Nikeの公式サイトから「エアマックス」の検索結果をリアルタイムで取得する必要があるとします。従来であれば、Puppeteerをデプロイし、プロキシを扱い、ブロックを回避し、ページ構造を解析する必要があり…時間がかかり、エラーが発生しやすいです。
しかし、Scrapeless SDKを使用すれば、全プロセスはわずか数行のコードで済みます:
ステップ1. SDKをインストール
お好きなパッケージマネージャーを利用してください:
Python
npm install @scrapeless-ai/sdkステップ2. クライアントを初期化
TypeScript
import { Scrapeless } from '@scrapeless-ai/sdk';
const client = new Scrapeless({
apiKey: 'your-api-key' // 在 https://scrapeless.com 获取
});ステップ3. ワンクリックSERPスクレイピング
TypeScript
const results = await client.deepserp.scrape({
actor: 'scraper.google.search',
input: {
q: 'Air Max site:www.nike.com'
}
});
console.log(results);プロキシ、アンチボットメカニズム、ブラウザエミュレーション、またはIPローテーションについて心配する必要はありません — Scrapelessがすべての処理を裏で行います。
出力例
JSON
{
inline_images: [
{
position: 1,
thumbnail: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtHPNOwXmvXfYfaT_4UqM1IvNBqZDZe7rScA&s',
related_content_id: 'N2x0F2OpsGqRuM,xzJA7z__Ip2bvM',
related_content_link: 'https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_wEXAOj_ChUIx-WA-v7nv5GdARC32NG7sayq2GoyjCpjFwAAAA%3D%3D&q=https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2&ctx=iv&hl=en-US',
source: 'Nike',
source_logo: '',
title: "ナイキ エア マックス 1 メンズ シューズ",
link: 'https://www.nike.com/t/air-max-1-mens-shoes-2C5sX2',
original: 'https://static.nike.com/a/images/t_PDP_936_v1/f_auto,q_auto:eco/c5ff2a6b-579f-4271-85ea-0cd5131691fa/NIKE+AIR+MAX+1.png',
original_width: 936,
original_height: 1170,
in_stock: false,
is_product: false
},
....
}これらの結果をデータベースに保存するか、直接表示およびランキング分析に使用できます。
今すぐScrapeless SDKをインストール
Scrapeless Node.js SDKは、ウェブスクレイピングとブラウザ自動化をこれまで以上に簡単にします。価格監視ツール、SERP分析システムの構築、または実際のユーザー行動のシミュレーションなど、1行のコードでScrapelessの強力なインフラストラクチャに接続できます。
Scrapeless SDKはMITライセンスの下でオープンソースです。開発者はコードの貢献、問題の提出、またはアイデアをもっと得るために私たちのDiscordコミュニティに参加することを歓迎します!
✅ 無料トライアル利用可能
🔗 ドキュメントを読む
💬 質問がありますか?Discordコミュニティに参加する
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


