
ウェブスクレイピングのベストプラクティスは何ですか?
Advanced Data Extraction Specialist
はじめに:AI時代のブラウザ自動化とデータ収集の新しいパラダイム
生成AI、AIエージェント、データ集中型アプリケーションの急速な発展に伴い、ブラウザは従来の「ユーザーインタラクションツール」から「インテリジェントシステムのためのデータ実行エンジン」へと進化しています。この新しいパラダイムでは、多くのタスクが単一のAPIエンドポイントに依存するのではなく、自動化されたブラウザ制御を利用して複雑なページインタラクション、コンテンツスクレイピング、タスクオーケストレーション、コンテキスト取得を処理しています。
eコマースサイトでの価格比較、地図のスクリーンショット、検索エンジンの結果パース、ソーシャルメディアのコンテンツ抽出など、ブラウザはAIが現実世界のデータにアクセスするための重要なインターフェースとなりつつあります。しかし、現代のウェブ構造の複雑さ、強固なボット対策、高い同時アクセス要求は、ローカルのPuppeteer/Playwrightインスタンスやプロキシローテーション戦略などの従来の解決策にとって大きな技術的および運用上の課題を引き起こしています。
そこで登場するのがScrapeless Scraping Browser—大規模な自動化のために特別に構築された先進的なクラウドベースのブラウザプラットフォームです。これは、ボット対策メカニズム、フィンガープリンティング検出、プロキシ管理といった主要な技術的障壁を克服します。さらに、クラウドネイティブな同時実行スケジューリング、人間のような振る舞いのシミュレーション、構造化データの抽出を提供し、次世代の自動化システムやデータパイプラインにおける重要なインフラストラクチャコンポーネントとしての地位を確立しています。
この記事では、Scrapelessのコア機能とブラウザ自動化およびウェブスクレイピングにおける実用的な応用について探ります。現在の業界のトレンドと将来の方向性を分析することで、開発者、プロダクトビルダー、データチームに対して包括的かつ体系的なガイドを提供することを目的としています。
I. 背景:なぜScrapeless Scraping Browserが必要なのか?
1.1 ブラウザ自動化の進化
AI駆動の自動化時代において、ブラウザはもはや人間のインタラクションのためのツールではなく、構造化データおよび非構造化データを取得するための重要な実行エンドポイントとなっています。多くの現実のシナリオでは、APIが利用できないか制限されており、データ収集、タスク実行、情報抽出のためにブラウザを介して人間の振る舞いをシミュレーションする必要があります。
一般的な使用例には以下が含まれます:
- eコマースサイトでの価格比較:価格や在庫データは、しばしばブラウザで非同期にロードされます。
- 検索エンジンの結果ページのパース:コンテンツはページ要素をスクロールしたりクリックしたりして完全に読み込まれる必要があります。
- 多言語サイト、レガシーシステム、イントラネットプラットフォーム:APIを介してのデータアクセスは不可能です。
従来のスクレイピングソリューション(例:ローカルで実行されるPuppeteer/Playwrightやプロキシローテーションのセットアップ)は、高い同時実行性の下で安定性が低く、頻繁にボットによるブロックに遭遇し、維持コストが高くなることがしばしばあります。Scrapeless Scraping Browserは、そのクラウドネイティブなデプロイメントと実際のブラウザによる振る舞いのシミュレーションにより、開発者にとって高可用性で信頼性の高いブラウザ自動化プラットフォームを提供します—AI自動化システムとデータワークフローのための重要なインフラストラクチャとして機能します。
1.2 ボット対策メカニズムの課題
同時に、ボット対策技術が進化する中で、従来のクローラー工具はターゲットとなるウェブサイトによってボットトラフィックとしてフラグが立てられることが増えており、IP禁止やアクセス制限を引き起こしています。一般的なボット対策メカニズムには以下が含まれます:
- ブラウザフィンガープリンティング:User-Agent、キャンバスレンダリング、TLSハンドシェイクなどを介して異常なアクセスパターンを検出します。
- CAPTCHA検証:ユーザーに人間であることを証明させる必要があります。
- IPのブラックリスト化:頻繁にアクセスするIPをブロックします。
- 行動分析アルゴリズム:異常なマウスの動き、スクロール速度、インタラクションロジックを検出します。
Scrapeless Scraping Browserは、正確なブラウザフィンガープリントのカスタマイズ、内蔵されたCAPTCHA解決、柔軟なプロキシサポートを通じて、これらの課題を効果的に克服し、次世代の自動化ツールのためのコアインフラストラクチャとなります。
II. Scrapelessのコア機能
Scrapeless Scraping Browserは強力なコア機能を提供し、ユーザーに安定した、効率的な、スケーラブルなデータインタラクション機能を提供します。以下はその主な機能モジュールと技術的詳細です。
2.1 実際のブラウザ環境
ScrapelessはChromiumエンジンに基づいて構築されており、実際のユーザーの振る舞いをシミュレートできる完全なブラウザ環境を提供します。主な機能には以下が含まれます:
- TLSフィンガープリントの偽装:従来のボット対策メカニズムを回避するためにTLSハンドシェイクパラメータを偽装します。
- ダイナミックフィンガープリンティングの難読化:User-Agent、画面解像度、タイムゾーンなどを調整し、各セッションが非常に人間らしく見えるようにします。
- ローカリゼーションサポート:ターゲットウェブサイトとのインタラクションをより自然にするために、言語、地域、タイムゾーンの設定をカスタマイズします。
ブラウザフィンガープリントの深いカスタマイズ
Scrapelessはブラウザフィンガープリントの包括的なカスタマイズを提供し、ユーザーがより「本物」なブラウジング環境を作成できるようにします:
- ユーザーエージェント制御: ブラウザのHTTPリクエストにおけるユーザーエージェント文字列を定義し、ブラウザエンジン、バージョン、OSを含めます。
- 画面解像度マッピング: 一般的な表示サイズをシミュレートするために、
screen.widthとscreen.heightの戻り値を設定します。 - プラットフォームプロパティロック: オペレーティングシステムの種類をシミュレートするために、JavaScriptにおける
navigator.platformの戻り値を指定します。 - ローカライズされた環境エミュレーション: コンテンツのレンダリング、時間形式、およびウェブサイト上の言語の優先検出に影響を与えるカスタムローカライズ設定を完全にサポートします。
2.2 クラウドベースの展開とスケーラビリティ
Scrapelessは完全にクラウドに展開されており、以下の利点があります。
- ローカルリソース不要: ハードウェアコストを削減し、展開の柔軟性を向上させます。
- グローバルに分散したノード: 大規模な同時タスクをサポートし、地理的制約を克服します。
- 高同時実行サポート: 50から無制限の同時セッションまで—小さなタスクから複雑な自動化ワークフローまで理想的です。
パフォーマンス比較
伝統的なツール(SeleniumやPlaywrightなど)と比較すると、Scrapelessは高同時実行シナリオにおいて優れています。以下は簡単な比較表です。
| 機能 | Scrapeless | Selenium | Playwright |
|---|---|---|---|
| 同時実行サポート | 無制限(エンタープライズグレードのカスタマイズ) | 限定的 | 中程度 |
| フィンガープリンツカスタマイズ | 高度 | 基本 | 中程度 |
| CAPTCHA解決 | 組込(成功率98%) reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDomeなどをサポート |
外部依存 | 外部依存 |
同時に、Scrapelessは高同時実行シナリオにおいて他の競合製品よりも優れたパフォーマンスを発揮します。以下はさまざまな観点からの機能概要です。
| 機能 / プラットフォーム | Scrapeless | Browserless | Browserbase | HyperBrowser | Bright Data | ZenRows | Steel.dev |
|---|---|---|---|---|---|---|---|
| 展開方法 | クラウドベース | クラウドベースのPuppeteerコンテナ | マルチブラウザクラウドクラスター | クラウドベースのヘッドレスブラウザプラットフォーム | クラウド展開 | ブラウザAPIインターフェース | ブラウザクラウドクラスター + ブラウザAPI |
| 同時実行サポート | 50から無制限 | 3〜50 | 3〜50 | 1〜250 | プランに応じて無制限 | 最大100(ビジネスプラン) | 公式データなし |
| アンチ検出機能 | 無料のCAPTCHA認識とバイパス、reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDomeなどをサポート | CAPTCHAバイパス | CAPTCHAバイパス + インコグニートモード | CAPTCHAバイパス + インコグニート + セッション管理 | CAPTCHAバイパス + フィンガープリンツ偽装 + プロキシ | カスタムブラウザフィンガープリンツ | プロキシ + フィンガープリンツ認識 |
| ブラウザランタイムコスト | $0.063 – $0.090/時間(無料のCAPTCHAバイパスを含む) | $0.084 – $0.15/時間(単位ベース) | $0.10 – $0.198/時間(2〜5GBの無料プロキシを含む) | $30〜$100/月 | ~$0.10/時間 | ~$0.09/時間 | $0.05 – $0.08/時間 |
| プロキシコスト | $1.26 – $1.80/GB | $4.3/GB | $10/GB(無料クォータを超える場合) | 公式データなし | $9.5/GB(標準);$12.5/GB(プレミアムドメイン) | $2.8 – $5.42/GB | $3 – $8.25/GB |
2.3 CAPTCHA自動解決およびイベント監視メカニズム
Scrapelessは高度なCAPTCHAソリューションを提供し、ブラウザ自動化の信頼性を向上させるためにChrome DevTools Protocol(CDP)を通じて一連のカスタム機能を拡張します。
CAPTCHA解決能力
Scrapelessは、reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDomeなどを含む主流のCAPTCHAタイプを自動的に処理できます。
イベント監視メカニズム
Scrapelessは、CAPTCHA解決プロセスを監視するための3つのコアイベントを提供します:
| イベント名 | 説明 |
|---|---|
| Captcha.detected | CAPTCHAが検出されました |
| Captcha.solveFinished | CAPTCHAが解決されました |
| Captcha.solveFailed | CAPTCHA解決に失敗しました |
イベント応答データ構造
| フィールド | タイプ | 説明 |
|---|---|---|
| type | string | CAPTCHAタイプ(例:recaptcha、turnstile) |
| success | boolean | 解決の結果 |
| message | string | ステータスメッセージ(例:"NOT_DETECTED"、"SOLVE_FINISHED") |
| token? | string | 成功時に返されるトークン(任意) |
2.4 強力なプロキシサポート
Scrapelessは、複数のプロキシモードをサポートする柔軟で制御可能なプロキシ統合システムを提供します:
- 内蔵の住宅プロキシ:195か国/地域の地理的プロキシをアウト・オブ・ザ・ボックスでサポート。
- カスタムプロキシ(プレミアムサブスクリプション):ユーザーが自分のプロキシサービスに接続できるようにし、Scrapelessのプロキシの請求には含まれません。
2.5 セッションリプレイ
セッションリプレイは、Scrapelessスクレイピングブラウザの最も強力な機能の1つです。ページごとにセッションをリプレイして、実行された操作とネットワークリクエストを確認することができます。
3. コード例:Scrapelessの統合と使用
3.1 Scrapelessスクレイピングブラウザの使用
Puppeteerの例
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwrightの例
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=your-scrapeless-api-key&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();3.2 Scrapelessスクレイピングブラウザのフィンガープリンターパラメータの例コード
以下は、PuppeteerおよびPlaywrightを通じてScrapelessのブラウザフィンガープリンタのカスタマイズ機能を統合する方法を示すシンプルな例コードです:
Puppeteerの例
const puppeteer = require('puppeteer-core');
// カスタムブラウザフィンガープリント
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // 必須
session_ttl: 180,
proxy_country: 'ANY',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();Playwrightの例
const { chromium } = require('playwright-core');
// カスタムブラウザフィンガープリント
const fingerprint = {
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36',
platform: 'Windows',
screen: {
width: 1280, height: 1024
},
localization: {
languages: ['zh-HK', 'en-US', 'en'], timezone: 'Asia/Hong_Kong',
}
}
const query = new URLSearchParams({
token: 'APIKey', // 必須
session_ttl: 180,
proxy_country: 'ANY',
fingerprint: encodeURIComponent(JSON.stringify(fingerprint)),
});
const connectionURL = `wss://browser.scrapeless.com/browser?${query.toString()}`;
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
const info = await page.evaluate(() => {
return {
screen: {
width: screen.width,
height: screen.height,
},
userAgent: navigator.userAgent,
timeZone: Intl.DateTimeFormat().resolvedOptions().timeZone,
languages: navigator.languages
};
});
console.log(info);
await browser.close();
})();
3.3 CAPTCHAイベント監視の例
以下は、Scrapelessを使用してCAPTCHAイベントを監視するための完全なコード例であり、CAPTCHAの解決状況をリアルタイムで監視する方法を示しています。
// CAPTCHA解決イベントをリッスンする
const client = await page.createCDPSession();
client.on('Captcha.detected', (result) => {
console.log('Captchaが検出されました:', result);
});
await new Promise((resolve, reject) => {
client.on('Captcha.solveFinished', (result) => {
if (result.success) resolve();
});
client.on('Captcha.solveFailed', () =>
reject(new Error('Captchaの解決に失敗しました'))
);
setTimeout(() =>
reject(new Error('Captcha解決のタイムアウト')),
5 * 60 * 1000
);
});Scrapelessスクレイピングブラウザーのコア機能と利点を習得した後、現代のウェブスクレイピングにおけるその価値をよりよく理解するだけでなく、そのパフォーマンスの利点をより効果的に活用できるようになります。開発者がウェブサイトをより効率的かつ安全に自動化およびスクレイピングするのを助けるために、一般的なシナリオに基づいてScrapelessスクレイピングブラウザーを特定のユースケースで適用する方法を探ります。
4. Scrapelessスクレイピングブラウザーを使用した自動化およびウェブスクレイピングのベストプラクティス
法的免責事項と予防策
このチュートリアルでは、教育のための一般的なウェブスクレイピング技術を扱います。公共のサーバーとの相互作用には、注意と敬意が必要であり、何をすべきでないかの良い要約は次のとおりです。
- ウェブサイトに損害を与える可能性のある速度でスクレイピングしないでください。
- 公開されていないデータをスクレイピングしないでください。
- GDPRによって保護されているEU市民の個人情報を保存しないでください。
- 一部の国で違法となる可能性がある、全体の公開データセットを再利用しないでください。
Cloudflare保護の理解
- Cloudflareとは何ですか?
Cloudflareは、コンテンツ配信ネットワーク(CDN)、DNSアクセラレーション、およびセキュリティ保護を統合したクラウドプラットフォームです。ウェブサイトは、分散型サービス拒否(DDoS)攻撃(つまり、複数のアクセス要求によるウェブサイトのオフライン化)を軽減し、その使用を確実にするためにCloudflareを使用します。
Cloudflareがどのように機能するかを理解するためのシンプルな例は以下の通りです。
Cloudflareが有効になっているウェブサイト(例:example.com)を訪れると、あなたのリクエストは最初にオリジンサーバーではなくCloudflareのエッジサーバーに届きます。Cloudflareは次に、以下のような複数のルールに基づいて、リクエストを続行するかどうかを判断します。
- キャッシュされたページを直接返すことができるかどうか;
- CAPTCHAテストに合格する必要があるかどうか;
- リクエストがブロックされるかどうか;
- リクエストが実際のウェブサイトサーバー(オリジン)に転送されるかどうか。
あなたが正当なユーザーとして特定されると、Cloudflareはリクエストをオリジンサーバーに転送し、そのコンテンツを返します。このメカニズムは、ウェブサイトのセキュリティを大幅に向上させますが、自動アクセスには大きな課題をもたらします。
Cloudflareの回避は、多くのデータ収集タスクにおける最も厳しい技術的課題の1つです。以下では、Cloudflareを回避することがなぜ難しいのかをさらに深く掘り下げます。
- Cloudflare保護回避の課題
Cloudflareを回避するのは簡単ではなく、特に高度なボット対策機能(Bot Management、Managed Challenge、Turnstile Verification、JS課題など)が有効になっている場合は特にそうです。多くの従来のスクレイピングツール(SeleniumやPuppeteerなど)は、明らかなフィンガープリンティング機能や不自然な振る舞いのシミュレーションによって、リクエストが行われる前にしばしば検出され、ブロックされます。
Cloudflareを回避するために特に設計されたオープンソースツール(FlareSolverr、undetected-chromedriverなど)もありますが、これらのツールは通常、寿命が短いです。広く使用されると、Cloudflareはすぐに検出ルールを更新してそれらをブロックします。したがって、持続的かつ安定的にCloudflareの保護メカニズムを回避するには、チームが社内開発能力を必要とし、メンテナンスと更新のために継続的なリソース投資が必要です。
Cloudflare保護回避の主な課題は次のとおりです。
- 厳格なブラウザフィンガープリンティング認識: Cloudflareは、User-Agent、言語設定、画面解像度、タイムゾーン、Canvas/WebGLレンダリングなどのリクエスト内のフィンガープリンティング機能を検出します。異常なブラウザや自動化動作が検出されると、リクエストがブロックされます。
- 複雑なJSチャレンジメカニズム: Cloudflareは動的にJavaScriptチャレンジ(CAPTCHA、遅延リダイレクト、論理計算など)を生成し、自動化スクリプトはこれらの複雑な論理を正しくパースまたは実行するのに苦労します。
- 行動分析システム: Cloudflareは、静的なフィンガープリントに加えて、マウスの動き、ページ上での滞在時間、スクロールアクションなどのユーザー行動の軌跡を分析します。これには、人間の行動をシミュレートするための高い精度が要求されます。
- レートと同時実行制御: 高頻度のアクセスは容易にCloudflareのレート制限およびIPブロック戦略をトリガーします。プロキシプールと分散スケジューリングは高度に最適化されなければなりません。
- 見えないサーバーサイドの検証: Cloudflareはエッジインターセプターであるため、多くの実リクエストはオリジンサーバーに到達する前にブロックされ、従来のパケットキャプチャ分析手法は効果がありません。
したがって、Cloudflareを成功裏にバイパスするには、実際のブラウザの振る舞いをシミュレートし、JavaScriptを動的に実行し、フィンガープリントを柔軟に構成し、高品質のプロキシおよび動的スケジューリング機構を使用する必要があります。
Scrapeless Scraping Browserを用いたIdealistaのCloudflareバイパスによる不動産データの収集
この章では、Scrapeless Scraping Browserを利用して、欧州の主要な不動産プラットフォームであるIdealistaから不動産データを効率的で安定した自動化システムでスクレイピングする方法を示します。IdealistaはCloudflare、動的読み込み、IPレート制限、およびユーザー行動認識など、複数の保護メカニズムを採用しており、非常に挑戦的なターゲットプラットフォームとなっています。
以下の技術的側面に焦点を当てます:
- Cloudflareの検証ページをバイパス
- カスタムフィンガープリンティングと実際のユーザー行動のシミュレーション
- セッションリプレイの利用
- 複数のプロキシプールを使用した高同時実行のスクレイピング
- コスト最適化
課題の理解:IdealistaのCloudflare保護
Idealistaは南ヨーロッパの主要なオンライン不動産プラットフォームであり、住宅、アパート、シェアルームなど、さまざまな物件の数百万件のリスティングを提供しています。その不動産データの商業的価値が非常に高いため、このプラットフォームは厳格な対スクレイピング対策を実施しています。
自動化されたスクレイピングに対抗するために、IdealistaはCloudflareを導入しており、これは悪意のあるボット、DDoS攻撃、およびデータ濫用から守るために設計された広く使用されているアンチボットおよびセキュリティ保護システムです。Cloudflareの対スクレイピングメカニズムは主に以下の要素から構成されています:
- アクセス検証メカニズム: JSチャレンジ、ブラウザの整合性チェック、CAPTCHA確認を含み、訪問者が実際のユーザーであるかどうかを判断します。
- 行動分析: マウスの動き、クリックパターン、スクロール速度などのアクションを通じて実際のユーザーを検出します。
- HTTPヘッダー分析: ブラウザのタイプ、言語設定、リファラーデータを検査して不一致を確認します。疑わしいヘッダーは、自動ボットを隠そうとする試みを晒す可能性があります。
- フィンガープリンタ検出とブロック: ブラウザのフィンガープリント、TLSフィンガープリント、ヘッダー情報を通じて自動化ツール(SeleniumやPuppeteerなど)によって生成されたトラフィックを特定します。
- エッジノードフィルタリング: リクエストはまずCloudflareのグローバルエッジネットワークに入り、そのリスクが評価されます。リスクが低いと見なされるリクエストのみがIdealistaのオリジンサーバーに転送されます。
次に、Scrapeless Scraping Browserを使用してIdealistaのCloudflare保護をバイパスし、不動産データを成功裏に収集する方法について詳しく説明します。
Scrapeless Scraping Browserを用いたIdealistaのCloudflareバイパス
前提条件
始める前に、必要なツールを揃えておきましょう:
-
Python: まだPythonをインストールしていない場合は、最新バージョンをダウンロードし、システムにインストールしてください。
-
必要なライブラリ: 複数のPythonライブラリをインストールする必要があります。ターミナルまたはコマンドプロンプトを開き、以下のコマンドを実行してください:
pip install requests beautifulsoup4 lxml selenium selenium-wire undetected-chromedriver -
ChromeDriver: ChromeDriverをダウンロードしてください。インストールしたChromeのバージョンに合ったものを選択してください。
-
Scrapelessアカウント: Idealistaのボット保護をバイパスするためには、Scrapeless Scraping Browserのアカウントが必要です。こちらでサインアップして、$2の無料トライアルを受け取ることができます。
データの場所を特定する
私たちの目標は、Idealista上の各物件リスティングについての詳細情報を抽出することです。ブラウザの開発者ツールを使って、サイトの構造を理解し、ターゲットとする必要があるHTML要素を特定することができます。
ページ上の任意の場所を右クリックして検査を選択し、ページソースを表示します。
この記事では、以下のURLを使用してマドリードのアルカラ・デ・エナーレスから物件リストをスクレイピングすることに焦点を当てます:
https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/
各リストから抽出したいデータポイントは次のとおりです:
- タイトル
- 価格
- エリア情報
- 物件説明
- 画像URL
以下には、各物件の情報がどこにあるかを示す注釈付きの物件リストページが表示されています。
HTMLソースコードを調べることで、各データポイントのCSSセレクターを特定できます。CSSセレクターは、HTMLドキュメント内の要素を選択するために使用されるパターンです。
HTMLソースコードを検査した結果、各物件リストはitemクラスを持つ<article>タグ内に含まれていることがわかりました。それぞれのアイテム内では:
- タイトルは
item-linkクラスを持つ<a>タグにあります。 - 価格は
item-priceクラスを持つ<span>タグにあります。 - 他のデータポイントに関しても同様です。
ステップ1: ChromeDriverを使用してSeleniumをセットアップ
まず、SeleniumをChromeDriverを使うように設定する必要があります。chrome_optionsを設定し、ChromeDriverを初期化します。
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("ChromeDriverへのパスを指定")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)このコードは、ブラウザとの高度な相互作用のためにseleniumwireを含む必要なモジュールをインポートし、HTML解析のためにBeautifulSoupをインポートします。
listings(url)という関数を定義し、chrome_optionsに--headless引数を追加することで、Chromeをヘッドレスモードで実行するように設定します。その後、指定されたサービスパスを使用してChromeDriverを初期化します。
ステップ2: ターゲットURLを読み込む
次に、ターゲットURLを読み込み、ページが完全に読み込まれるのを待ちます。
driver.get(url)
time.sleep(8) # ウェブサイトの読み込み時間に基づいて調整ここでは、driver.get(url)コマンドはブラウザに指定されたURLに移動するよう指示します。
time.sleep(8)を使用してスクリプトを8秒間一時停止し、ウェブページが完全に読み込まれるのに十分な時間を確保します。この待機時間は、ウェブサイトの読み込み速度に応じて調整できます。
ステップ3: ページコンテンツを解析する
ページが読み込まれたら、BeautifulSoupを使用してその内容を解析します:
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()ここでは、driver.page_sourceを使用して読み込まれたページのHTMLコンテンツを取得し、lxmlパーサーを使ってBeautifulSoupで解析します。最後に、driver.quit()を呼び出してブラウザインスタンスを閉じ、リソースをクリーンアップします。
ステップ4: 解析されたHTMLからデータを抽出する
次に、解析されたHTMLから関連するデータを抽出します。
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"タイトル": listing.find("a", class_="item-link").get("title", "nil"),
"価格": listing.find("span", class_="item-price").get_text(strip=True),
"ベッドルーム": bedrooms,
"エリア": area,
"説明": description_text,
"画像URL": first_image_url,
}
extracted_data.append(listing_info)ここでは、itemというクラス名を持つarticleタグに一致するすべての要素を探しており、これが個々の物件リストを表します。各リストについて、そのタイトル、詳細(ベッドルームの数やエリアなど)、画像URLを抽出します。これらの詳細を辞書に保存し、各辞書をextracted_dataというリストに追加します。
ステップ5: 抽出したデータを保存する
最後に、抽出したデータをJSONファイルに保存します。
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"抽出したデータは {json_filename} に保存されました")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)ここに完全なコードがあります:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
from datetime import datetime
import json
def listings(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
s = Service("ChromeDriverのパスを置き換えてください")
driver = webdriver.Chrome(service=s, chrome_options=chrome_options)
driver.get(url)
time.sleep(8) # ウェブサイトの読み込み時間に応じて調整
soup = BeautifulSoup(driver.page_source, "lxml")
driver.quit()
house_listings = soup.find_all("article", class_="item")
extracted_data = []
for listing in house_listings:
description_elem = listing.find("div", class_="item-description")
description_text = description_elem.get_text(strip=True) if description_elem else "nil"
item_details = listing.find_all("span", class_="item-detail")
bedrooms = item_details[0].get_text(strip=True) if len(item_details) > 0 else "nil"
area = item_details[1].get_text(strip=True) if len(item_details) > 1 else "nil"
image_urls = [img["src"] for img in listing.find_all("img") if img.get("src")]
first_image_url = image_urls[0] if image_urls else "nil"
listing_info = {
"タイトル": listing.find("a", class_="item-link").get("title", "nil"),
"価格": listing.find("span", class_="item-price").get_text(strip=True),
"ベッドルーム": bedrooms,
"面積": area,
"説明": description_text,
"画像URL": first_image_url,
}
extracted_data.append(listing_info)
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"new_revised_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"抽出したデータは {json_filename} に保存されました")
url = "https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/"
idealista_listings = listings(url)ボット検出を回避する
このチュートリアル中にスクリプトを少なくとも2回実行した場合、CAPTCHAページが表示されることに気付いたかもしれません。
Cloudflareのチャレンジページは最初にcf-chl-bypassスクリプトを読み込み、JavaScript計算を行います。通常この処理には約5秒かかります。
Scrapelessは、独自のスクレイピングインフラを構築・維持することなく、Idealistaのようなサイトからデータにアクセスするためのシンプルで信頼性の高い方法を提供します。Scrapeless Scraping Browserは、AI向けに構築された高同時実行性の自動化ソリューションです。これは、大規模なデータスクレイピング用に設計された高性能でコスト効率の良い、ブロック回避ブラウザプラットフォームであり、人間に非常に似た振る舞いをシミュレートします。リアルタイムで再CAPTCHA、Cloudflareターンスタイル/チャレンジ、AWS WAF、DataDomeなどを処理でき、効率的なウェブスクレイピングソリューションとなっています。
以下は、Scrapelessを使ってCloudflareの保護を回避する手順です:
ステップ1:準備
1.1 プロジェクトフォルダを作成
- プロジェクト用の新しいフォルダを作成します。例えば、
scrapeless-bypass。 - ターミナルでフォルダに移動します:
cd path/to/scrapeless-bypass1.2 Node.jsプロジェクトを初期化
次のコマンドを実行してpackage.jsonファイルを作成します:
npm init -y1.3 必要な依存関係をインストール
ブラウザインスタンスへのリモート接続を許可するPuppeteer-coreをインストールします:
npm install puppeteer-coreシステムにPuppeteerがまだインストールされていない場合、完全版をインストールします:
npm install puppeteer puppeteer-coreステップ2:Scrapeless APIキーを取得
2.1 Scrapelessにサインアップ
- Scrapelessにアクセスしてアカウントを作成します。
- APIキー管理セクションに移動します。
- 新しいAPIキーを生成してコピーします。
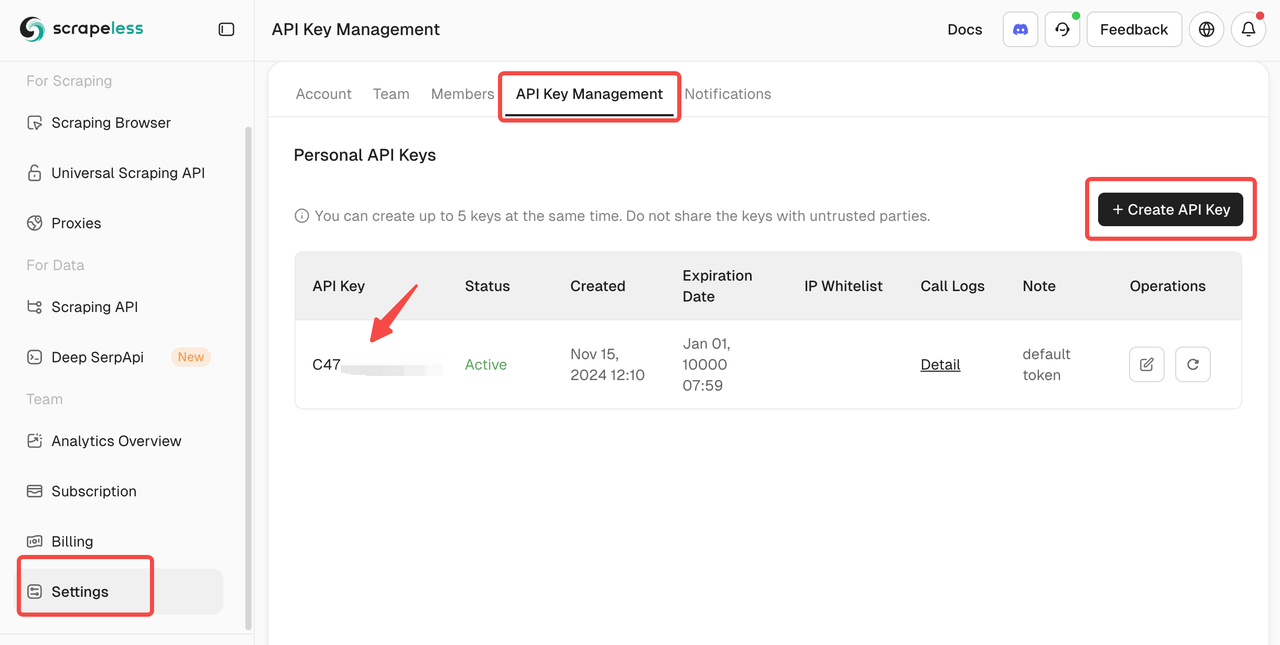
ステップ3:Scrapeless Browserlessに接続
3.1 WebSocket接続URLを取得
Scrapelessは、クラウドベースのブラウザと対話するためにPuppeteerにWebSocket接続URLを提供します。
形式は次のとおりです:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYAPIKeyを実際のScrapeless APIキーに置き換えてください。
3.2 接続パラメータを設定
token: あなたのScrapeless APIキーsession_ttl: ブラウザセッションの持続時間(秒)、例えば180proxy_country: プロキシサーバーの国コード(例:イギリスならGB、アメリカならUS)
---
#### ステップ4: Puppeteerスクリプトを書く
##### 4.1 スクリプトファイルの作成
プロジェクトフォルダ内に `bypass-cloudflare.js` という名前の新しいJavaScriptファイルを作成します。
##### 4.2 Scrapelessに接続し、Puppeteerを起動する
`bypass-cloudflare.js` に次のコードを追加します:import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 実際のAPIキーに置き換えてください
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({token: API_KEY, session_ttl: '180', // ブラウザセッションの継続時間(秒)proxy_country: 'GB', // プロキシ国コードproxy_session_id: 'test_session', // プロキシセッションID(同じIPを維持)proxy_session_duration: '5' // プロキシセッションの継続時間(分)
}).toString();
const connectionURL = ${host}/browser?${query};
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL, defaultViewport: null,
});
console.log('Scrapelessに接続しました');
##### 4.3 ウェブページを開き、Cloudflareをバイパスする
スクリプトを拡張して、新しいページを開き、Cloudflareで保護されたウェブサイトに移動します:const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
##### 4.4 ページ要素の読み込みを待つ
先に進む前にCloudflareの保護がバイパスされていることを確認します:await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // 必要に応じてセレクターを調整
##### 4.5 スクリーンショットを撮る
Cloudflareの保護が正常にバイパスされたかどうかを確認するために、ページのスクリーンショットを撮ります:await page.screenshot({ path: 'challenge-bypass.png' });
console.log('スクリーンショットがchallenge-bypass.pngとして保存されました');
##### 4.6 完全なスクリプト
以下が完全なスクリプトです:import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 実際のAPIキーに置き換えてください
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = ${host}/browser?${query};
(async () => {
try {
// Scrapelessに接続
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Scrapelessに接続しました');
// 新しいページを開いてターゲットウェブサイトに移動
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// ページが完全に読み込まれるのを待つ
await page.waitForTimeout(5000); // 必要に応じて遅延を調整
await page.waitForSelector('main.page-content', { timeout: 30000 });
// スクリーンショットをキャプチャ
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('スクリーンショットがchallenge-bypass.pngとして保存されました');
// ブラウザを閉じる
await browser.close();
console.log('ブラウザが閉じられました');} catch (error) {
console.error('エラー:', error);
}
})();
#### ステップ5: スクリプトを実行
##### 5.1 スクリプトを保存
スクリプトがbypass-cloudflare.jsとして保存されていることを確認してください。
##### 5.2 スクリプトを実行
Node.jsを使ってスクリプトを実行します:node bypass-cloudflare.js
##### 5.3 期待される出力
すべてが正しく設定されている場合、ターミナルに次のように表示されます:Scrapelessに接続しました
スクリーンショットがchallenge-bypass.pngとして保存されました
ブラウザが閉じられました
challenge-bypass.pngファイルがプロジェクトフォルダに表示され、Cloudflareの保護が正常にバイパスされたことを確認できます。
Scrapeless Scraping Browserを直接スクレイピングコードに統合することもできます:const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=C4778985476352D77C08ECB031AF0857&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();
### フィンガープリンティングのカスタマイズ
特に**Idealista**のような大規模な不動産プラットフォームからデータをスクレイピングする際には、**Scrapeless**を使って**Cloudflare**チャレンジを正常にバイパスしたとしても、繰り返しの高ボリュームアクセスによりボットとしてフラグされる可能性があります。
ウェブサイトは、**ブラウザフィンガープリンティング**を使用して自動化された振る舞いを検出し、アクセスを制限することがよくあります。
---
#### ⚠️ よくある問題点
- **複数回のスクレイピング後の遅延応答**
サイトはIPや行動パターンに基づいてリクエストを制限することがあります。
- **ページレイアウトがレンダリングされない**
動的コンテンツはリアルなブラウザ環境に依存することがあり、スクレイピング中にデータが欠けたり壊れたりすることがあります。
- **特定の地域でのリスティングが欠けている**
サイトは疑わしいトラフィックパターンに基づいてコンテンツをブロックまたは非表示にすることがあります。
---
これらの問題は、各リクエストに対して同一のブラウザ設定が原因で発生することが多いです。ブラウザのフィンガープリントが変わらない場合、ボット対策システムは自動化を検出しやすくなります。
---
#### 解決策:Scrapelessによるカスタムフィンガープリンティング
**Scrapeless Scraping Browser** は、リアルユーザーの行動を模倣し、検出を避けるためのフィンガープリンティングカスタマイズを備えています。
以下のフィンガープリント要素を**ランダム化またはカスタマイズ**できます:
| フィンガープリント要素 | 説明 |
|---------------------|-------------|
| **User-Agent** | 様々なOS/ブラウザの組み合わせを模倣します(例:Windows/MacのChrome)。 |
| **プラットフォーム** | 異なるオペレーティングシステムをシミュレートします(Windows、macOSなど)。 |
| **画面サイズ** | モバイル/デスクトップの不一致を避けるため、様々なデバイスの解像度をエミュレートします。 |
| **ローカリゼーション** | 一貫性のために、地理位置に合わせて言語とタイムゾーンを調整します。 |
---
これらの値を回転させたりカスタマイズすることで、各リクエストがより自然に見え、検出のリスクを減らし、データ抽出の信頼性を向上させます。
**コード例:**const puppeteer = require('puppeteer-core');
const query = new URLSearchParams({
token: 'your-scrapeless-api-key', // 必須
session_ttl: 180,
proxy_country: 'ANY',
// フィンガープリンティングパラメータを設定
userAgent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.6998.45 Safari/537.36',
platform: 'Windows',
screen: JSON.stringify({ width: 1280, height: 1024 }),
localization: JSON.stringify({
locale: 'zh-HK',
languages: ['zh-HK', 'en-US', 'en'],
timezone: 'Asia/Hong_Kong',
})
});
const connectionURL = wss://browser.Scrapeless.com/browser?${query.toString()};
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.Scrapeless.com');
console.log(await page.title());
await browser.close();
})();
### セッションリプレイ
ブラウザフィンガープリントをカスタマイズすると、ページの安定性が大幅に向上し、コンテンツの抽出がより信頼できるようになります。
ただし、大規模なスクレイピング操作中に予期しない問題が発生し、抽出に失敗することがあります。この問題に対処するために、**Scrapeless**は強力な**セッションリプレイ**機能を提供しています。
---
#### セッションリプレイとは?
セッションリプレイは、ブラウザセッション全体を詳細に記録し、以下の全てのインタラクションをキャプチャします:
- ページロードプロセス
- ネットワークリクエストとレスポンスデータ
- JavaScript実行の動作
- 動的に読み込まれたが未解析のコンテンツ
---
#### なぜセッションリプレイを使用するのか?
**Idealista**のような複雑なウェブサイトをスクレイピングする際に、セッションリプレイはデバッグの効率を大幅に向上させることができます。
| 利点 | 説明 |
|----------------------------|-----------------------------------------------------------------------------|
| **正確な問題追跡** | 推測なしで失敗したリクエストを迅速に特定 |
| **コードの再実行が不要** | スクレイパーを再実行することなく、リプレイから問題を直接分析 |
| **協力の改善** | チームメンバーとリプレイログを共有し、トラブルシューティングを容易にする |
| **動的コンテンツ分析** | スクレイピング中に動的に読み込まれたデータがどのように動作するかを理解する |
---
#### 使用のヒント
**セッションリプレイ**が有効になったら、スクレイプが失敗したり、データが不完全に見えるときは、まずリプレイログを確認してください。これにより、問題を迅速に診断し、デバッグ時間を短縮できます。
### プロキシ設定
Idealistaをスクレイピングする際には、このプラットフォームが特定の都市からの非ローカルIPアドレスに非常に敏感であることに注意が必要です。もしIPが国外から発信されると、Idealistaは:
- リクエストを完全にブロックする
- ページの簡略版または削減版を返す
- CAPTCHAをトリガーすることなく、空または不完全なデータを提供することがある
---
#### Scrapelessによるプロキシサポート
Scrapelessは**組み込みプロキシ設定**を提供しており、地理的なソースを直接指定できます。
以下のいずれかを使用して設定できます:
- `proxy_country`: 2文字の国コード(例:スペインの場合は `'ES'`)
- `proxy_url`: 自分のプロキシサーバーのURL
使用例:proxy_country: 'ES',
### 高い同時実行性
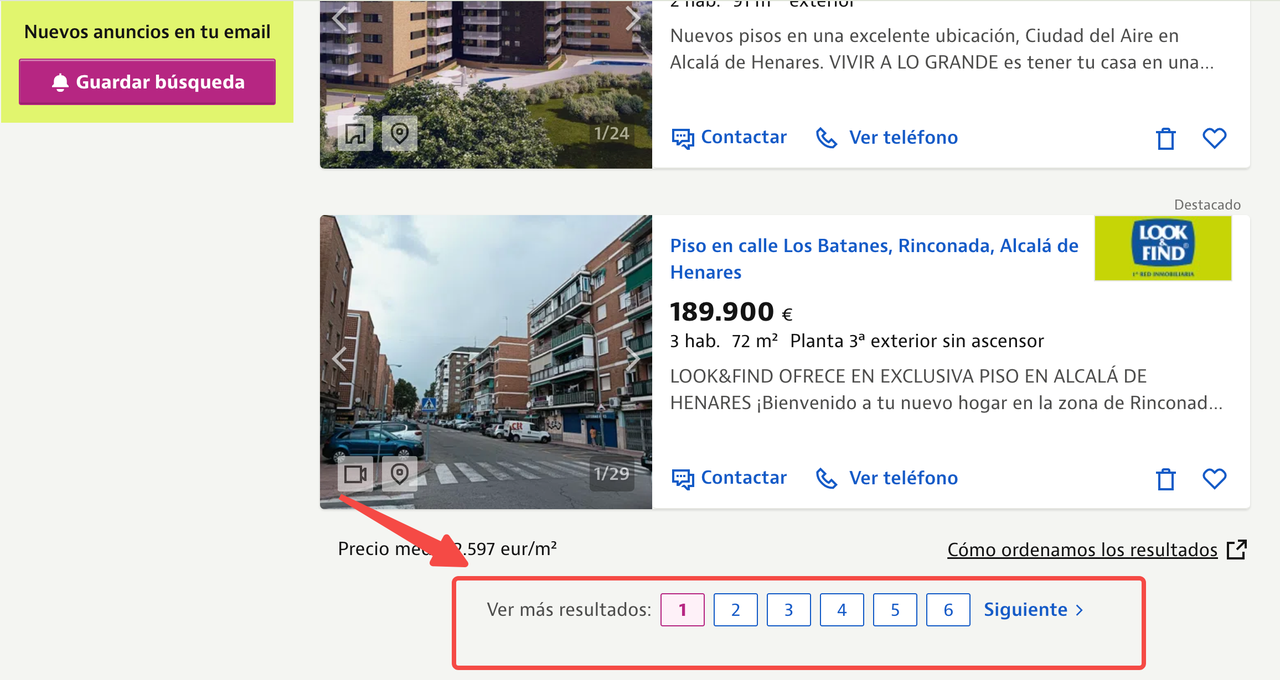
私たちがIdealistaからスクレイピングしたページは、[アルカラ・デ・エナレスの不動産リスト](https://www.idealista.com/venta-viviendas/alcala-de-henares-madrid/)で、最大6ページのリストがあります。
業界のトレンドを研究したり、競争力のあるマーケティング戦略を収集する際に、**20以上の都市から日々**不動産データをスクレイピングする必要があるかもしれません。場合によっては、毎時間このデータを更新する必要があるかもしれません。
---
#### 高同時接続要件
このボリュームを効率的に処理するために、以下の要件を考慮してください。
- **複数の同時接続**: 長時間の待機時間なしで、数百のページからデータをスクレイピングするため。
- **自動化ツール**: 同時リクエストを大規模に処理できるScrapeless Scraping Browserや類似のツールを使用。
- **セッション管理**: CAPTCHASやIPブロックを避けるために持続的なセッションを維持。
---
#### Scrapelessのスケーラビリティ
Scrapelessは高同時接続のスクレイピングのために特別に設計されています。以下の機能を提供します。
- **並列ブラウザセッション**: 複数のリクエストを同時に処理し、多くの都市にわたって大量のデータをスクレイピングできるようにします。
- **低コストで高効率のスクレイピング**: 並列でのスクレイピングは、1ページあたりのコストを削減し、スループットを最適化します。
- **高ボリュームのボット対策を回避**: 高負荷のスクレイピング中でも、自動的にCAPTCHAやその他の認証システムを処理します。
---
> **ヒント**: リクエストは十分に間隔を空けて、人間のようなブラウジング行動を模倣し、Idealistaからのレート制限や禁止を防ぐようにしてください。
#### スケーラビリティとコスト効率
通常のPuppeteerはセッションを効率的にスケールするのに苦労し、キューシステムと統合できません。しかし、Scrapeless Scraping Browserは**数十**の同時セッションから**無制限**の同時セッションまでスムーズにスケーリングをサポートし、ピークタスク負荷時にも**ゼロキュー時間とゼロタイムアウト**を保証します。
以下は高同時接続のスクレイピングに対するさまざまなツールの比較です。Scrapelessの高同時接続ブラウザを使用する場合、コストについて心配する必要はありません。実際、手数料が**50%近く**節約できるかもしれません。
---
#### ツール比較
| **ツール名** | **時間当たり料金 (USD/時)** | **プロキシ料金 (USD/GB)** | **同時サポート** |
| ------------- | --------------------------- | ------------------------- | ------------------ |
| **Scrapeless** | $0.063 – $0.090/時 (同時接続と使用状況による) | $1.26 – $1.80/GB | 50 / 100 / 200 / 400 / 600 / 1000 / 無制限 |
| **Browserbase** | $0.10 – $0.198/時 (2-5GBの無料プロキシに含まれる) | $10/GB (無料配布後) | 3 (基本) / 50 (上級) |
| **Brightdata** | $0.10/時 | $9.5/GB (標準); $12.5/GB (上級ドメイン) | 無制限 |
| **Zenrows** | $0.09/時 | $2.8 – $5.42/GB | 最大100 |
| **Browserless** | $0.084 – $0.15/時 (ユニットベースの請求) | $4.3/GB | 3 / 10 / 50 |
> **ヒント**: **大規模スクレイピング**と**高同時接続サポート**が必要な場合、**Scrapeless**が最良のコスト対パフォーマンス比を提供します。
### ウェブスクレイピングのコスト管理戦略
注意深いユーザーは、私たちがスクレイピングするIdealistaのページには、高解像度の物件画像、インタラクティブな地図、ビデオプレゼンテーション、広告スクリプトが大量に含まれていることに気づいたかもしれません。これらの要素はエンドユーザーには使いやすいですが、データ抽出には不要で、帯域幅の消費とコストを大幅に増加させます。
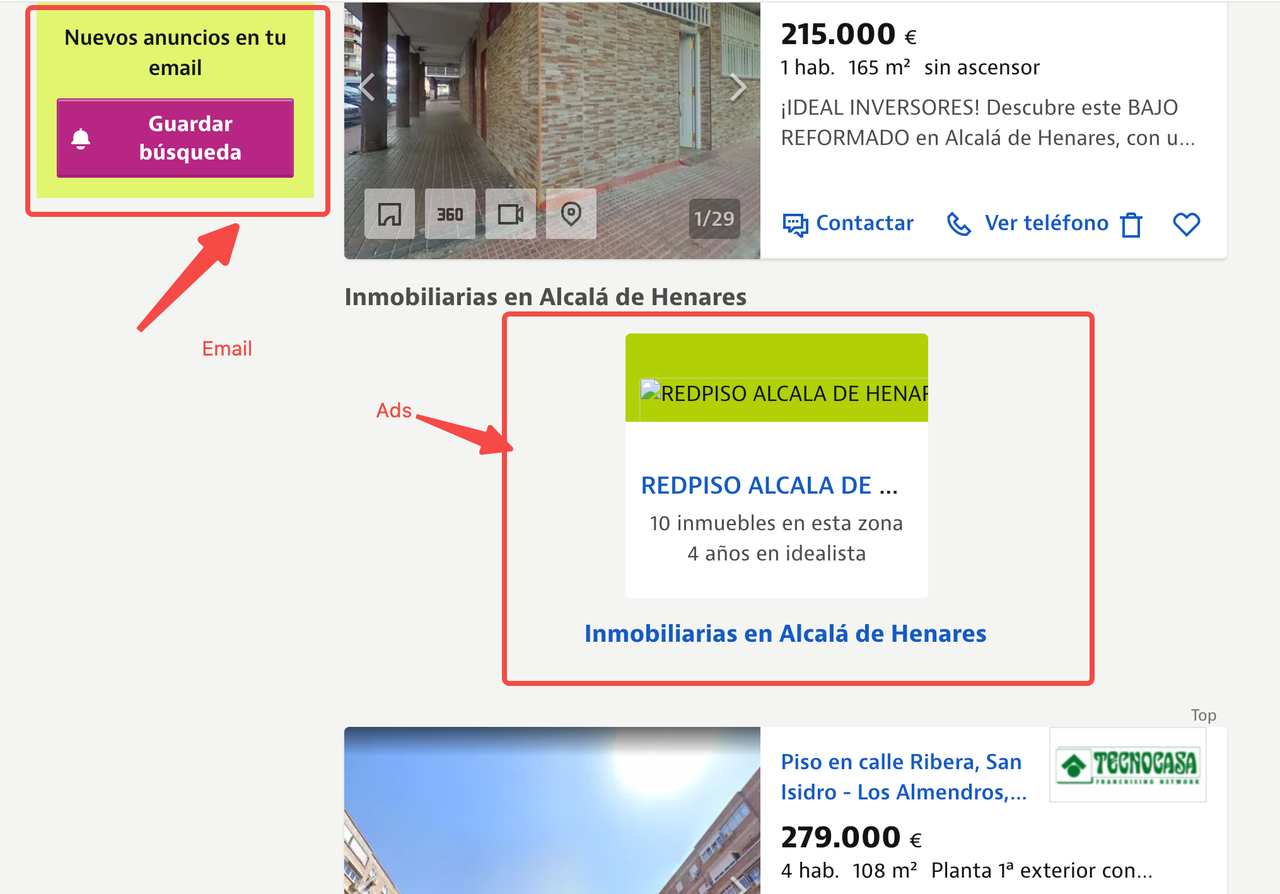
トラフィックの使用を最適化するために、次の戦略を採用することをお勧めします。
1. **リソースのインターセプト**: 不要なリソースリクエストをインターセプトしてトラフィック消費を削減します。
2. **リクエストURLのインターセプト**: URLの特性に基づいて特定のリクエストをインターセプトし、さらにトラフィックを最小化します。
3. **モバイルデバイスのシミュレーション**: モバイルデバイスの設定を使用して、軽量なページバージョンを取得します。
---
#### 詳細な戦略
##### 1. **リソースのインターセプト**
リソースのインターセプトを有効にすると、スクレイピング効率が大幅に向上します。Puppeteerの`setRequestInterception`関数を設定することで、画像、メディア、フォント、スタイルシートなどのリソースをブロックし、大きなコンテンツのダウンロードを避けます。
##### 2. **リクエストURLのフィルタリング**
リクエストURLを検査することで、データ抽出に関連しない広告サービスやサードパーティの分析スクリプトなどの無関係なリクエストをフィルタリングできます。これにより、不要なネットワークトラフィックが減少します。
##### 3. **モバイルデバイスのシミュレーション**
モバイルデバイス(例:ユーザーエージェントをiPhoneに設定)をシミュレーションすることで、軽量でモバイル最適化されたバージョンのページを取得できます。これにより、読み込まれるリソースが少なくなり、スクレイピングプロセスが迅速化します。
> 詳細については、[Scrapelessの公式ドキュメント](https://docs.scrapeless.com/en/scraping-browser/guides/optimizing-cost/)を参照してください。
---
#### コード例
以下は、リソーススクレイピングを最適化するために、Scrapeless Cloud Browser + Puppeteerを使用してこれらの3つの戦略を組み合わせる例です:import puppeteer from 'puppeteer-core';
const scrapelessUrl = 'wss://browser.scrapeless.com/browser?token=your_api_key&session_ttl=180&proxy_country=ANY';
async function scrapeWithResourceBlocking(url) {
const browser = await puppeteer.connect({
browserWSEndpoint: scrapelessUrl,
defaultViewport: null
});
const page = await browser.newPage();
// リクエストインターセプションを有効にする```ja
await page.setRequestInterception(true);
// ブロックするリソースタイプを定義
const BLOCKED_TYPES = new Set([
'image',
'font',
'media',
'stylesheet',
]);
// リクエストをインターセプト
page.on('request', (request) => {
if (BLOCKED_TYPES.has(request.resourceType())) {
request.abort();
console.log(`ブロックされました: ${request.resourceType()} - ${request.url().substring(0, 50)}...`);
} else {
request.continue();
}
});
await page.goto(url, {waitUntil: 'domcontentloaded'});
// データを抽出
const data = await page.evaluate(() => {
return {
title: document.title,
content: document.body.innerText.substring(0, 1000)
};
});
await browser.close();
return data;
}
// 使用方法
scrapeWithResourceBlocking('https://www.scrapeless.com')
.then(data => console.log('スクレイピング結果:', data))
.catch(error => console.error('スクレイピング失敗:', error));このようにして、高いトラフィックコストを節約できるだけでなく、データ品質を確保しながらクローリング速度を向上させることができ、システムの全体的な安定性と効率を改善します。
5. セキュリティとコンプライアンスに関する推奨事項
Scrapelessをデータスクレイピングに使用する際、開発者は以下に注意する必要があります:
- ターゲットウェブサイトの
robots.txtファイルおよび関連する法律や規則を遵守する: スクレイピング活動が合法であり、サイトのガイドラインを尊重していることを確認してください。 - ウェブサイトのダウンタイムにつながる過剰なリクエストを避ける: サーバーの過負荷を防ぐため、スクレイピングの頻度に注意してください。
- 機密情報をスクレイピングしない: ユーザープライバシーデータ、支払い情報、その他の機密コンテンツを収集しないでください。
6. 結論
ビッグデータの時代において、データ収集は業界全体におけるデジタルトランスフォーメーションの重要な基盤となっています。特にマーケットインテリジェンス、eコマースの価格比較、競争分析、金融リスク管理、不動産分析などの分野では、データに基づいた意思決定の需要がますます急増しています。しかし、ウェブ技術の進化が続く中、特に動的に読み込まれるコンテンツの広範な使用により、従来のウェブスクレイパーは徐々に限界を露呈しています。これらの制限は、スクレイピングをより困難にするだけでなく、アンチスクレイピングメカニズムの激化をもたらし、ウェブスクレイピングのハードルを引き上げています。
ウェブ技術の進展により、従来のスクレイパーは複雑なスクレイピングニーズを満たすことができなくなりました。以下は、いくつかの主要な課題とそれに対する対応策です:
- 動的コンテンツの読み込み: ブラウザベースのスクレイパーは、JavaScriptコンテンツの実際のブラウザレンダリングをシミュレートすることにより、動的に読み込まれるウェブデータをスクレイピングできることを保証します。
- アンチスクレイピングメカニズム: プロキシプール、フィンガープリンティング認識、行動シミュレーションなどの技術を使用することで、従来のスクレイパーによって一般的にトリガーされるアンチスクレイピングメカニズムを回避できます。
- 高同時接続のスクレイピング: ヘッドレスブラウザは高同時接続タスクの展開をサポートし、プロキシスケジューリングと組み合わせることで、大規模データスクレイピングのニーズを満たします。
- コンプライアンス問題: 法的なAPIやプロキシサービスを使用することで、スクレイピング活動がターゲットウェブサイトの利用規約に準拠することを保証できます。
その結果、ブラウザベースのスクレイパーは業界の新しいトレンドとなっています。この技術は、実際のブラウザを通じてユーザーの行動をシミュレートするだけでなく、現代のウェブサイトの複雑な構造やアンチスクレイピングメカニズムに柔軟に対応し、開発者により安定した効率的なスクレイピングソリューションを提供します。
Scrapeless Scraping Browserは、この技術トレンドを取り入れ、ブラウザレンダリング、プロキシ管理、アンチ検出技術、高同時接続タスクスケジューリングを組み合わせることで、開発者が複雑なオンライン環境でデータスクレイピングタスクを効率的かつ安定に完了できるよう支援しています。いくつかのコアの利点を通じて、スクレイピングの効率と安定性を向上させます:
- 高同時接続ブラウザソリューション: Scrapelessは大規模な高同時接続タスクをサポートし、数千のスクレイピングタスクの迅速な展開を可能にし、長期的なスクレイピングニーズに応えます。
- アンチ検出のサービス: 内蔵のCAPTCHA解決ソリューションやカスタマイズ可能なフィンガープリンツが開発者のフィンガープリントや行動認識メカニズムを回避するのを助け、ブロックされるリスクを大幅に減少させます。
- 視覚デバッグツール - セッションリプレイ: スクレイピングプロセス中の各ブラウザインタラクションをリプレイすることで、開発者はスクレイピングプロセス内の問題を簡単にデバッグおよび診断でき、特に複雑なページや動的に読み込まれるコンテンツの処理を行う上で便利です。
- コンプライアンスおよび透明性の保証: Scrapelessはコンプライアントなデータスクレイピングを重視し、ウェブサイトの
robots.txtルールの遵守をサポートし、ターゲットウェブサイトのポリシーに準拠したユーザーのデータスクレイピング活動を保証するために詳細なスクレイピングログを提供します。
- **柔軟なスケーラビリティ**: ScrapelessはPuppeteerとシームレスに統合されており、ユーザーはスクレイピング戦略をカスタマイズし、他のツールやプラットフォームと接続してワンストップのデータスクレイピングおよび分析ワークフローを実現できます。
eコマースプラットフォームでの価格比較のためのスクレイピング、不動産ウェブサイトデータの抽出、または金融リスク監視やマーケットインテリジェンス分析の適用において、Scrapelessはさまざまな業界に高効率でインテリジェント、かつ信頼性のあるソリューションを提供します。
この記事で取り上げられた技術的な詳細とベストプラクティスを通じて、あなたは大規模データスクレイピングのためにScrapelessを活用する方法を理解しました。動的ページの処理、複雑なインタラクティブデータの抽出、トラフィックの最適化、またはアンチスクレイピング機構の克服において、Scrapelessはあなたのスクレイピング目標を迅速かつ効率的に達成する手助けをします。Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


