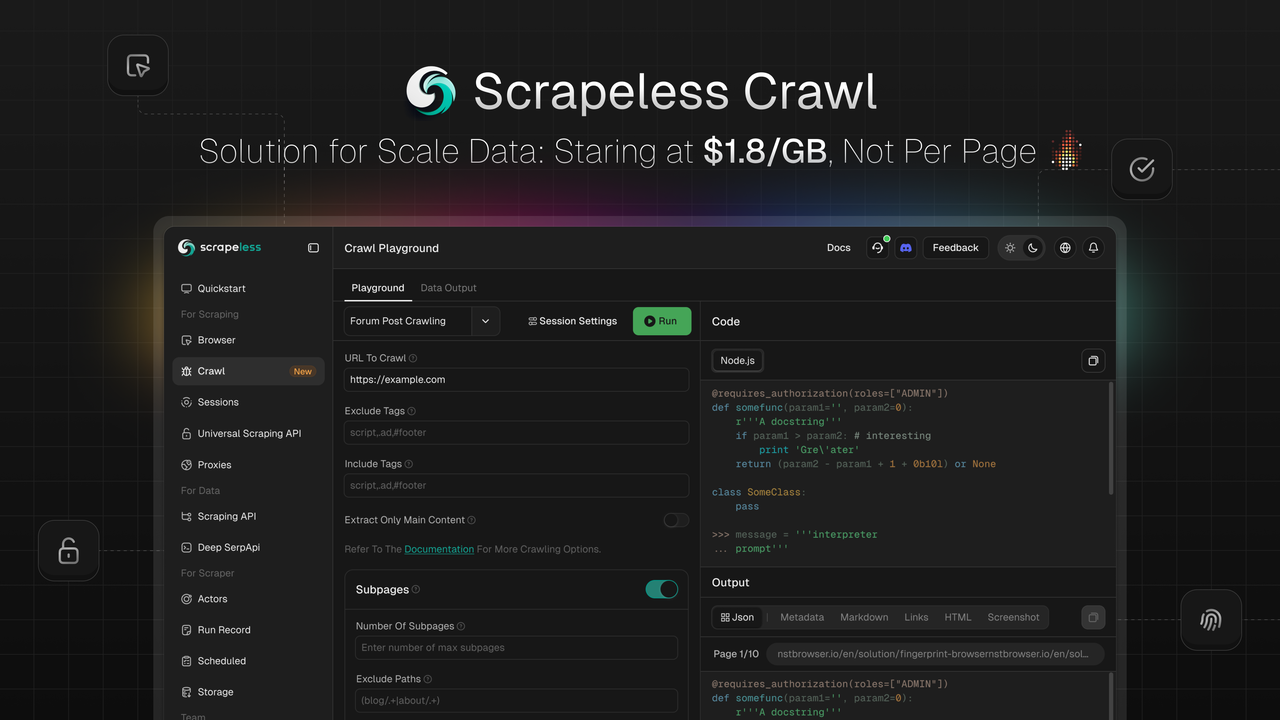
スクレイプレスクロールとは何ですか?そして、それはどのように機能しますか?
Senior Web Scraping Engineer
Scrapelessは、大規模なデータスクレイピングと処理のために特別に設計された機能である**Crawlを発表できることを嬉しく思います。Crawlは、インテリジェントな再帰スクレイピング、バルクデータ処理機能、および柔軟なマルチフォーマット出力**というコアの利点により際立っており、企業や開発者が巨額なウェブデータを迅速に取得して処理できるようにします。これは、AIトレーニング、市場分析、ビジネス意思決定などのアプリケーションを推進します。
💡近日公開予定:AI LLM Gatewayを通じたデータ抽出と要約。オープンソースのフレームワークや視覚的ワークフロー統合とのシームレスな統合を実現し、AI開発者のためのウェブコンテンツの課題を解決します。
Crawlとは
**Crawl**は、単なるデータスクレイピングツールではなく、スクレイピングとクロール機能を統合した総合的なプラットフォームです。
-
バルククロール:大規模な単一ページクロールや再帰的クロールをサポート。
-
マルチフォーマット配信:JSON、Markdown、メタデータ、HTML、リンク、およびスクリーンショット形式に対応。
-
検出防止スクレイピング:高いカスタマイズ性、セッション管理、検出防止機能を可能にする独自開発のChromiumカーネルを提供。フィンガープリント構成、CAPTCHA解決、ステルスモード、およびプロキシローテーションにより、ウェブサイトのブロックを回避します。
-
自社開発のChromium駆動:当社のChromiumカーネルにより、高いカスタマイズ性、セッション管理、および自動CAPTCHA解決を可能にします。
1. 自動CAPTCHAソルバー:reCAPTCHA v2やCloudflare Turnstile/Challengeなどの一般的なCAPTCHAタイプに自動的に対応します。
2. セッション録画と再生:セッション再生により、録画再生を通じてアクションやリクエストを簡単に確認でき、問題解決やプロセス改善のためにステップバイステップでレビューできます。
3. 同時実行の利点:厳しい同時実行制限のある他のクロールツールとは異なり、Crawlの基本プランは50の同時実行をサポートし、プレミアムプランでは無制限の同時実行が可能です。
4. コスト削減:対抗策のあるウェブサイトで競合を上回り、無料のCAPTCHA解決の大きな利点を提供 — 予想される70%のコスト削減。
高度なデータスクレイピングと処理機能を駆使して、Crawlは構造化されたリアルタイム検索データを提供します。これにより、企業や開発者は常に市場動向の先を行き、データ駆動の自動化ワークフローを最適化し、市場戦略を迅速に調整できます。
Crawlを使用して複雑なデータの課題を解決する:より速く、よりスマートに、より効率的に
信頼性のあるウェブデータを大規模に必要とする開発者及び企業に対して、Crawlは次のことを提供します:
✔ 高速データスクレイプ – 数秒で複数のウェブページからデータを取得
✔ シームレスな統合– 近日中にLangchain、N8n、Clay、Pipedream、Makeなどのオープンソースフレームワークやビジュアルワークフロー統合に統合予定です。
✔ 地理的ターゲティングプロキシ – 195か国に対応した内蔵プロキシサポート
✔ セッション管理 – インテリジェントにセッションを管理し、リアルタイムでLiveURLセッションを表示
Crawlの使用方法
Crawl APIは、特定のコンテンツをウェブページから単一の呼び出しで取得したり、サイト全体とそのリンクを再帰的にクロールしてすべての利用可能なデータを収集したりすることで、データスクレイプを簡素化します。
Scrapelessは、スクレイプリクエストを開始し、そのステータス/結果を確認するためのエンドポイントを提供します。デフォルトでは、スクレイピングは非同期です:最初にジョブを開始し、完了するまでそのステータスを監視します。ただし、当社のSDKには、プロセス全体を処理し、ジョブが完了するとデータを返す簡単な機能が含まれています。
インストール
NPMを使用してScrapeless SDKをインストールします:
Bash
npm install @scrapeless-ai/sdkPNPMを使用してScrapeless SDKをインストールします:
Bash
pnpm add @scrapeless-ai/sdk単一ページをクロールする
特定のデータ(例:製品詳細、レビュー)をウェブページから一度の呼び出しでクロールします。
使用法
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// クライアントを初期化
const client = new Scrapeless({
apiKey: "your-api-key", // https://scrapeless.com からAPIキーを取得
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();ブラウザの設定
プロキシを使用するなど、スクレイピング用のセッション設定をカスタマイズできます。新しいブラウザセッションを作成するのと同様です。
Scrapelessは、reCAPTCHA v2やCloudflare Turnstile/Challengeなどの一般的なCAPTCHAを自動的に処理します。追加の設定は不要です。詳細については、キャプチャ解決を参照してください。
すべてのブラウザパラメーターを調べるには、APIリファレンスまたはブラウザパラメーターを確認してください。
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// クライアントの初期化
const client = new Scrapeless({
apiKey: "your-api-key", // APIキーは https://scrapeless.com から取得してください
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();スクレイプ設定
スクレイプジョブのオプションパラメーターには、出力形式、メインページコンテンツのみを返すフィルタリング、ページナビゲーションの最大タイムアウト設定が含まれます。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// クライアントの初期化
const client = new ScrapingCrawl({
apiKey: "your-api-key", // APIキーは https://scrapeless.com から取得してください
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();スクレイプエンドポイントの完全なリファレンスについては、APIリファレンスを確認してください。
バッチスクレイプ
バッチスクレイプは通常のスクレイプと同じように動作しますが、単一のURLの代わりに、同時にスクレイプするURLのリストを提供できます。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// クライアントの初期化
const client = new ScrapingCrawl({
apiKey: "your-api-key", // APIキーは https://scrapeless.com から取得してください
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();サブページをクローリング
クローリングAPIは、ウェブサイトとそのリンクを再帰的にクローリングして、利用可能なすべてのデータを抽出します。
詳細な使用法については、クローリングのAPIリファレンスを確認してください。
使用法
再帰的クローリングを使用して、ドメイン全体とそのリンクを探索し、アクセス可能なすべてのデータを抽出します。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// クライアントの初期化
const client = new ScrapingCrawl({
apiKey: "your-api-key", // APIキーは https://scrapeless.com から取得してください
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();レスポンス
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "Example Page",
"description": "A sample webpage"
},
"markdown": "# Example Page\nThis is content...",
...
},
...
]
}クローリングした各ページには、completedまたはfailedのステータスがあり、独自のエラーフィールドが存在する場合もあるため、注意が必要です。完全なスキーマについては、APIリファレンスを確認してください。
ブラウザ設定
スクレイプジョブのセッション設定をカスタマイズするプロセスは、新しいブラウザセッションを作成するのと同じです。利用可能なオプションには、プロキシ設定が含まれます。サポートされているすべてのセッションパラメーターを表示するには、APIリファレンスまたはブラウザパラメーターを参照してください。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// クライアントの初期化
const client = new ScrapingCrawl({
apiKey: "your-api-key", // APIキーは https://scrapeless.com から取得してください
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();スクレイピング設定
パラメータには出力フォーマット、メインページコンテンツのみを返すフィルター、およびページナビゲーションの最大タイムアウト設定が含まれる場合があります。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// クライアントを初期化
const client = new ScrapingCrawl({
apiKey: "your-api-key", // https://scrapeless.com からAPIキーを取得
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();クロールエンドポイントの完全なリファレンスについては、APIリファレンスを参照してください。
クロールの多様な利用ケースを探る
開発者がコードをテストおよびデバッグできるビルトインのプレイグラウンドがあり、Crawlをあらゆるスクレイピングニーズに利用できます。例えば:
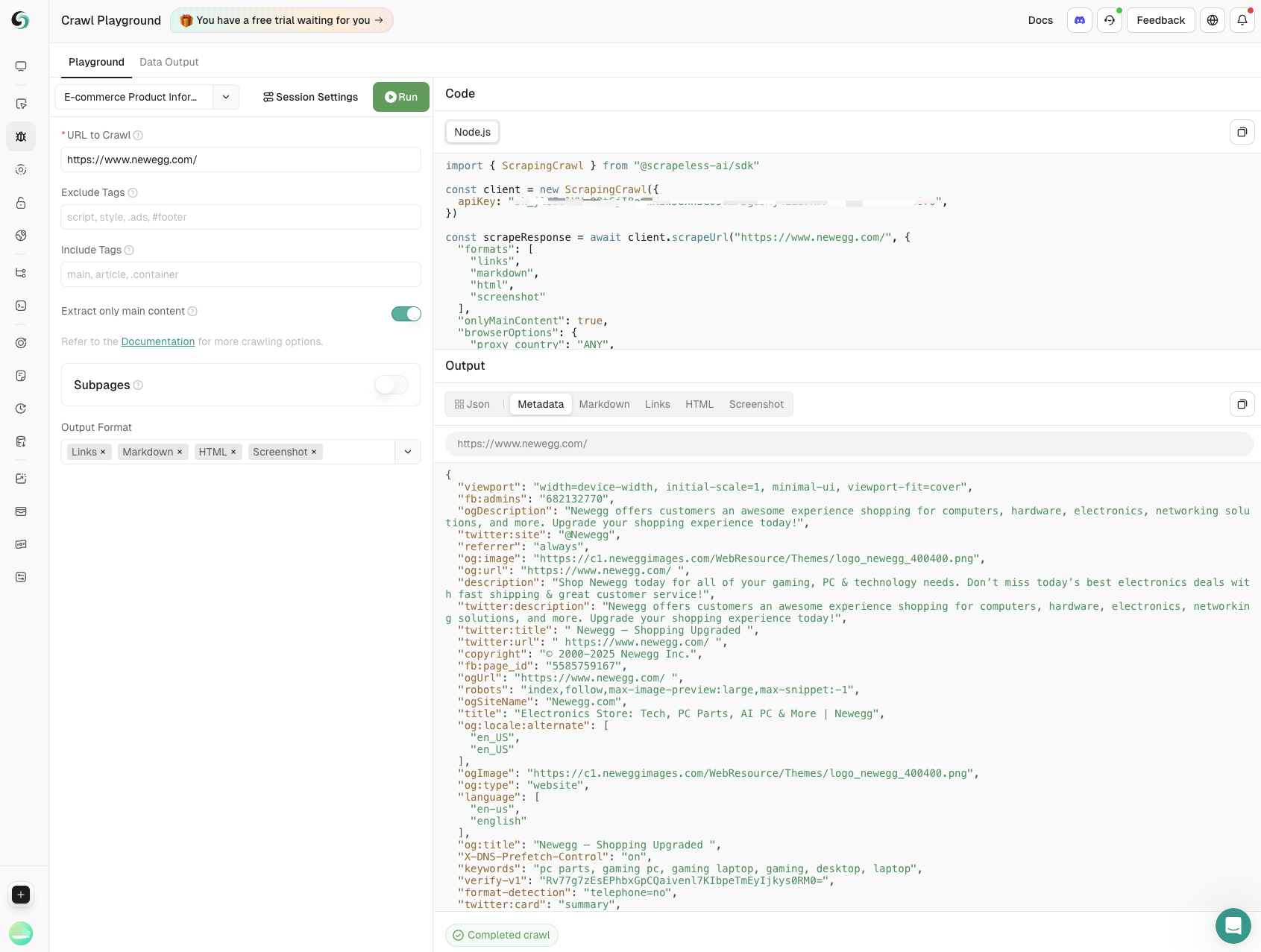
- 製品情報のスクレイピング
Eコマースウェブサイトでスクレイピングを行うことで、製品名、価格、ユーザー評価、レビュー数などの重要なデータを抽出します。製品モニタリングを完全にサポートし、ビジネスが情報に基づいた意思決定を行えるよう支援します。
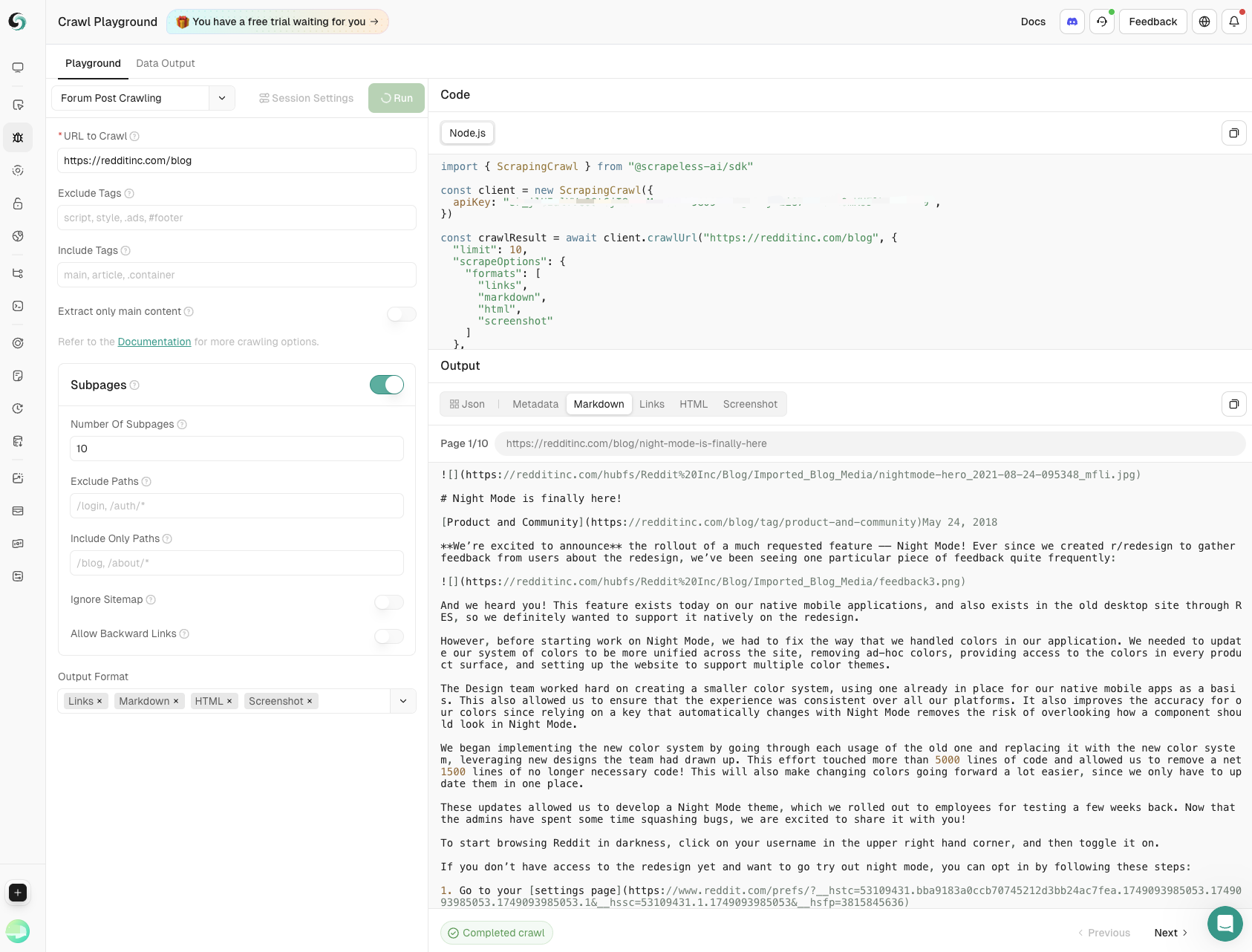
- フォーラムポストのクロール
メイン投稿の内容とサブページのコメントを深さと幅を正確に制御しながらキャプチャし、コミュニティディスカッションから包括的な洞察を得ることを保証します。
今すぐCrawlとScrapeを楽しもう!
コスト効率が高く、あらゆるニーズに対応:$1.8/GBから、ページごとではありません
競合他社を上回るクロミウムベースのスクレイパーを提供しており、プロキシボリュームと時間料金を組み合わせた料金モデルを特徴とし、ページ数モデルと比較して大規模データプロジェクトで最大70%のコスト削減を実現します。
今すぐトライアルに登録し、強力なウェブツールキットを手に入れましょう。
💡高ボリュームのユーザー向けに、カスタマイズされた料金についてお問い合わせください。ニーズに応じた競争力のある料金を提供します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


