スクレイプレスクラウドブラウザの動作:オートメーション、フィンガープリンティング、およびCAPTCHA処理のためのPuppeteerの適応
Expert Network Defense Engineer
ウェブ自動化とデータスクレイピングのシナリオでは、開発者はしばしば三つの核心的な技術的課題に直面します。
- 環境の隔離:
数十または数百の独立したブラウザセッションを同時に実行する場合、従来のローカルデプロイメントソリューションは高いリソース消費、複雑な管理、面倒な設定に悩まされます。
- フィンガープリント検出リスク:
同じブラウザフィンガープリントを使用して繰り返し訪問すると、対象ウェブサイトでアンチボットおよびフィンガープリント検出メカニズムが簡単にトリガーされます。
- CAPTCHAによる中断:
トリガーされると、reCAPTCHAやCloudflare Turnstileなどの検証が自動化スクリプトを中断させます。サードパーティ製のCAPTCHA解決サービスを統合すると、開発コストと複雑性が増し、実行効率が低下します。
これらの問題は、開発者がローカル環境を設定したり外部サービスを統合するために多くの時間を費やさざるを得なくなり、時間と運用コストが増大します。
本質的に、必要なのは以下の機能を持つツールです。
- 大規模に隔離された環境:
各プロファイルが完全に隔離されたブラウザインスタンスを表すように、API経由で独立したブラウザプロファイルを生成します。
- 自動フィンガープリントのランダム化:
User-Agent、タイムゾーン、言語、画面解像度などの重要なパラメータをランダム化しつつ、実際のブラウザ環境との完全な一貫性を維持します。
- 組み込みのCAPTCHA処理:
人間の介入やサードパーティの統合なしに、一般的なCAPTCHAの課題を自動的に認識し、解決します。
では、フィンガーブラウザについてはどうでしょうか?
国内の企業自動化では、ローカルにデプロイされたフィンガーブラウザが広く使用されています。しかし、これらは大きなシステムリソースを消費し、インスタンス全体で一貫して維持することが難しく、検証処理にはサードパーティのCAPTCHAサービスを必要とします。
対照的に、現代のクラウドベースのヘッドレスブラウザ(例:Scrapeless.com)は、よりスケーラブルで効率的な代替手段を提供します。これにより、開発者は以下を行えます:
- APIを介して隔離されたブラウザプロファイルを作成すること、
- ネイティブにフィンガープリントをランダム化すること、
- CAPTCHAの課題を自動的に処理すること、
すべてクラウド内で実行でき、開発および保守コストを大幅に削減し、高い同時実行作業負荷をサポートします。
次のセクションでは、クラウドベースのヘッドレスブラウザがフィンガープリントの隔離、同時実行性、およびCAPTCHA処理の観点からどのように機能するかを評価するために、いくつかのベンチマークシナリオを探ります。
⚠️ 免責事項:
いかなるブラウザ自動化ソリューションを使用する際にも、対象ウェブサイトの利用規約、robots.txtルール、および関連する法律と規制を常に遵守してください。
無許可または違法な目的でのデータスクレイピングや他者の権利を侵害する行為は厳しく禁止されています。
当社は、誤用に起因する法的結果や損失に対して一切の責任を負いません。
環境設定
まず、Scrapeless Node SDKをインストールします。Nodeがインストールされていない場合は、事前にインストールしてください。
bash
npm install @scrapeless-ai/sdk puppeteer-core基本的な接続テスト
js
// APIキーを設定
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer } from "@scrapeless-ai/sdk";
const browser = await Puppeteer.connect({
sessionName: "sdk_test",
sessionTTL: 180,
proxyCountry: "ANY",
sessionRecording: true,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://www.scrapeless.com");
console.log(await page.title());
await browser.close();ページタイトルが表示されれば、環境は正常に設定されています。
ウェブ自動化を強化する準備はできましたか? Scrapeless クラウドブラウザを今すぐ試して、シームレスなプロファイル管理、独立したフィンガープリント、自動化されたCAPTCHA処理をすべてクラウド内で体験してください!
ケース1:ランダムブラウザフィンガープリント検証
目標: 各プロファイルによって生成されるブラウザフィンガープリントが真に独立していることを確認します。
この例では:
- 複数の独立したプロファイルを作成する
- フィンガープリントテストサイトに訪問する: https://xfreetool.com/zh/fingerprint-checker
- 各プロファイルのブラウザフィンガープリントIDを抽出して比較する
- フィンガープリントの独立性とランダム性を検証する
サイト https://xfreetool.com/zh/fingerprint-checker は、ブラウザフィンガープリントをチェックし、訪問するブラウザからフィンガープリント情報を自動的にキャプチャするウェブサイトです。
例コード:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from "@scrapeless-ai/sdk";
// 設定定数
const MAX_PROFILES = 3; // 必要なプロファイルの最大数
// クライアントを初期化
const client = new ScrapelessClient();- CreepJSページからブラウザフィンガープリンターIDを取得する
- @param {Object} page - Puppeteerページオブジェクト
- @returns {Promise<string>} ブラウザフィンガープリンターID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
-
単一タスクを実行する
-
@param {string} profileId - プロファイルID
-
@param {number} taskId - タスクID
-
@returns {Promise<string>} ブラウザフィンガープリンターID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 45000,
profileId: profileId,
});const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});try {
const page = await browser.newPage();
page.setDefaultTimeout(45000);await page.goto('https://xfreetool.com/zh/fingerprint-checker', { waitUntil: 'networkidle0' }); // クッキー情報を取得して出力する const cookies = await page.cookies(); console.log(`[${taskId}] Cookies:`); cookies.forEach(cookie => { // console.log(` Name: ${cookie.name}, Value: ${cookie.value}, Domain: ${cookie.domain}`); }); const fpId = await getFPId(page); console.log(`[${taskId}] ✓ ブラウザフィンガープリンターID = ${fpId}`); return fpId;} finally {
await browser.close();
}
};
/**
- 新しいプロファイルを作成する
- @returns {Promise<string>} 新しく作成されたプロファイルID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('プロファイルが作成されました:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('プロファイルの作成に失敗しました:', error);
throw error;
}
};
/**
-
必要なプロファイルのリストを取得または作成する
-
@param {number} count - 必要なプロファイルの数
-
@returns {Promise<string[]>} プロファイルIDのリスト
*/
const getProfiles = async (count) => {
try {
// 既存のプロファイルを取得する
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];// 既存のプロファイルが不足している場合、新しいプロファイルを作成する if (profiles.length < count) { const profilesToCreate = count - profiles.length; const creationPromises = Array(profilesToCreate) .fill(0) .map(() => createProfile()); const newProfiles = await Promise.all(creationPromises); return [ ...profiles.map(p => p.profileId), ...newProfiles ]; } // 十分なプロファイルが存在する場合、最初の`count`プロファイルを返す return profiles.slice(0, count).map(p => p.profileId);} catch (error) {
console.error('プロファイルの取得に失敗しました:', error);
throw error;
}
};
/**
-
タスクを同時に実行する
*/
const runTasks = async () => {
try {
// 必要なプロファイルを取得または作成する
const profileIds = await getProfiles(MAX_PROFILES);// 各プロファイルのタスクを作成する const tasks = profileIds.map((profileId, index) => { const taskId = index + 1; return runTask(profileId, taskId); }); await Promise.all(tasks); console.log('すべてのタスクが正常に完了しました');} catch (error) {
console.error('タスクの実行中にエラーが発生しました:', error);
}
};
// タスクを実行する
await runTasks();
/**
- テスト結果:
-
- 3つのプロファイルが同時に実行され、各環境は完全に独立しています。
-
- 各プロファイルのブラウザフィンガープリンターIDは完全に異なります。
*/
- 各プロファイルのブラウザフィンガープリンターIDは完全に異なります。
/**
- 結果の説明:
-
- フィンガープリントのユニーク性
-
3つのプロファイルが異なるフィンガープリンターIDを返します。プロファイルが作成されるたびに、ブラウザフィンガープリンターがランダムに生成され、重複フィンガープリンターによる検出を回避しています。 -
- 環境の隔離の検証
-
各プロファイルのクッキーは完全に独立しています: -
* プロファイル1のクッキーはプロファイル2や3には現れません -
* 複数のプロファイルが異なるアカウントに同時にログインすることができ、互いに影響を与えません
*/
/** ケース2:高い同時実行性と環境隔離テスト
- 目標:高い同時実行性シナリオにおけるプロファイルの環境隔離を検証し、プロファイルの一括作成と管理の能力をテストする。
*/
多くの場合、データスクレイピングを迅速化したり、複数のアカウントにログインしたりするためには、ツールが高い同時実行性と環境の分離をサポートする必要があります。これは、数十または数百の独立したブラウザインスタンスを同時に持つことに相当します。Scrapelessは、プロファイルを手動で追加したり、APIを介してプロファイルを操作したりすることをサポートしています。
この例では:
- APIを介して10の独立したプロファイルを作成します
- 各プロファイルが最初にhttps://abrahamjuliot.github.io/creepjs/を訪れて、ブラウザフィンガープリントIDを取得します
- 次にhttps://minecraftpocket-servers.com/login/を訪れて、スクリーンショットを撮ります
- フィンガープリントの独立性と環境の分離を検証します
例コード:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
// 設定定数
const MAX_PROFILES = 5; // 必要なプロファイルの最大数
// クライアントの初期化
const client = new ScrapelessClient({});
/**
* CreepJSページからブラウザフィンガープリントIDを取得
* @param {Object} page - Puppeteerページオブジェクト
* @returns {Promise<string>} ブラウザフィンガープリントID
*/
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector(
'#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div'
);
return fpContainer.textContent;
});
};
/**
* 単一タスクを実行
* @param {string} profileId - プロファイルID
* @param {number} taskId - タスクID
* @returns {Promise<string>} ブラウザフィンガープリントID
*/
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: 'My Browser',
sessionTTL: 30000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
// ステップ1: ブラウザフィンガープリントを取得
let page = await browser.newPage();
page.setDefaultTimeout(30000);
await page.goto('https://abrahamjuliot.github.io/creepjs/', {
waitUntil: 'networkidle0'
});
const fpId = await getFPId(page);
await page.close(); // 最初のページを閉じる
// ステップ2: スクリーンショット用の新しいページを使用
page = await browser.newPage();
const screenshotPath = `fp_${taskId}_${fpId}.png`;
await page.goto('https://minecraftpocket-servers.com/login/', {
waitUntil: 'networkidle0'
});
await page.screenshot({
fullPage: true,
path: screenshotPath
});
console.log(`[${taskId}] ✓ フィンガープリントID: ${fpId}, スクリーンショットが保存されました: ${screenshotPath}`);
return fpId;
} finally {
await browser.close();
}
};
/**
* 新しいプロファイルを作成
* @returns {Promise<string>} 新しく作成されたプロファイルID
*/
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('My Profile' + randomString());
console.log('プロファイルが作成されました:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('プロファイルの作成に失敗しました:', error);
throw error;
}
};
/**
* 必要なプロファイルのリストを取得または作成
* @param {number} count - 必要なプロファイルの数
* @returns {Promise<string[]>} プロファイルIDのリスト
*/
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({
page: 1,
pageSize: count
});
const profiles = response?.docs || [];
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate)
.fill(0)
.map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [
...profiles.map(p => p.profileId),
...newProfiles
];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('プロファイルの取得に失敗しました:', error);
throw error;
}
};
/**
* タスクを同時に実行
*/
const runTasks = async () => {
try {
console.log(`タスクを開始します。${MAX_PROFILES} 個のプロファイルが必要です`);
const profileIds = await getProfiles(MAX_PROFILES);
console.log(`取得したプロファイル数: ${profileIds.length}`);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
const results = await Promise.all(tasks);
console.log('すべてのタスクが正常に完了しました!');
console.log('フィンガープリントIDのリスト:', results);
} catch (error) {
```javascript
console.error('タスクの実行中にエラーが発生しました:', error);
}
};
// タスクを実行
await runTasks();テスト結果:
- フィンガープリントの独立性: フィンガープリントと環境パラメータはランダムに生成され、相互に異なります。
- 環境の隔離: 各タスクは独立したプロファイルで実行されるため、ブラウザデータ(Cookie、LocalStorage、Sessionなど)は共有されません。
- 同時実行の安定性: 10のプロファイルが同時に正常に作成および実行されました。
例結果の説明:
- プロファイル作成と接続プロセス
出力はプロファイル作成とブラウザ接続プロセスの全容を示しています。
プロファイルが作成されました: a27cd6f9-7937-4af0-a0fc-51b2d5c70308
プロファイルが作成されました: d92b0cb1-5608-4753-92b0-b7125fb18775
...
info Puppeteer: Scrapelessブラウザに正常に接続されました {}
...
すべてのタスクが正常に完了しました10のプロファイルはほぼ同時に作成され、Scrapeless Cloud Browserに接続され、 高同時実行下での安定性を示しています。
- フィンガープリントの独立性の確認
各プロファイルはまったく異なるフィンガープリントIDを返します。
10のユニークなフィンガープリントは、各プロファイルのブラウザフィンガープリントが独立してランダムに生成されており、重複がないことを証明しています。
-
高い同時実行処理の安定性
すべての10タスクが同時に実行され、エラーや競合なく正常に完了しました。 -
プロファイル作成の複数の方法
Scrapelessはプロファイルを作成および管理するための複数の方法を提供します。
- ダッシュボードからの手動作成: ダッシュボードから直接プロファイルを作成し、すぐに開始し、個別の操作を行うことができます。
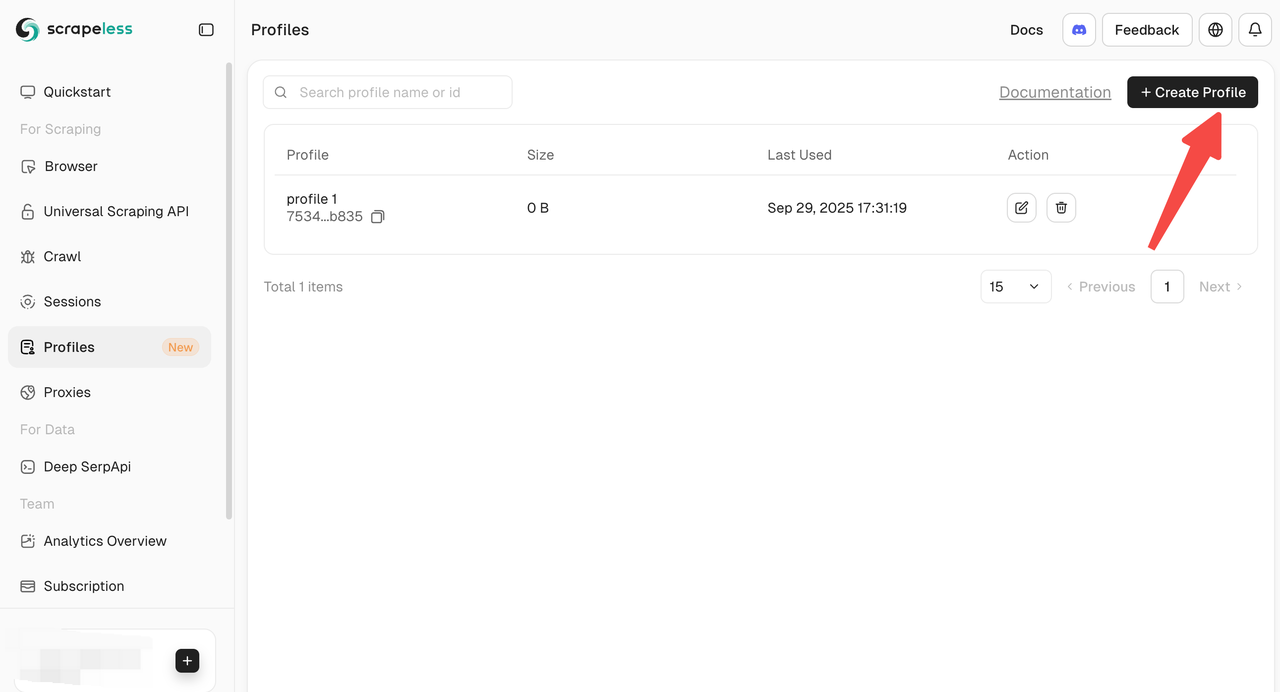
- APIによる作成: バッチ操作のためにプロファイル作成APIを介してプログラムでプロファイルを作成します。
- SDKによる作成: 公式SDKを使用してプロファイルを作成します。これは高い同時実行やカスタム自動化ワークフローに最適です。
ケース3: Cloudflareチャレンジ + Google再キャプチャ – 手動介入なしで完全自動CAPTCHAバイパス
目的: Scrapeless Cloud Browserがサイト訪問時に自動的にreCAPTCHAまたはCloudflareチャレンジを検出してパスできるかどうかをテストし、再現可能な検証プロセスと結果を記録します。
この例では:
- Amazonの検索ページhttps://www.amazon.com/s?k=toyに訪問(reCAPTCHAをトリガーする高い確率があります)
- CAPTCHAを自動的に処理し、製品データを抽出します。
- 自動化されたCAPTCHA処理能力を検証します。
例のコード:
process.env.SCRAPELESS_API_KEY = 'sk_xxx';
import { Puppeteer, randomString, ScrapelessClient } from '@scrapeless-ai/sdk';
const client = new ScrapelessClient();
const MAX_PROFILES = 1; // 必要なプロファイルの最大数
// CreepJSページからブラウザフィンガープリントIDを取得
const getFPId = async (page) => {
await page.waitForSelector('.n-menu-item-content-header', { timeout: 15000 });
return await page.evaluate(() => {
const fpContainer = document.querySelector('#app > div > div > div > div > div > div.tool-content > div > div:nth-child(4) > div');
return fpContainer.textContent;
});
};
const runTask = async (profileId, taskId) => {
const browserEndpoint = client.browser.create({
sessionName: '私のブラウザ',
sessionTTL: 45000,
profileId: profileId,
});
const browser = await Puppeteer.connect({
browserWSEndpoint: browserEndpoint,
defaultViewport: null,
timeout: 15000
});
try {
let page = await browser.newPage();
page.setDefaultTimeout(45000);
await page.goto('https://www.amazon.com/s?k=toy&crid=37T7KZIWF16VC&sprefix=to%2Caps%2C351&ref=nb_sb_noss_2');
await page.waitForSelector('[role="listitem"]', { timeout: 15000 });
console.log('ページが正常に読み込まれました...');
const products = await page.evaluate(() => {
const items = [];
const productElements = document.querySelectorAll('[role="listitem"]');
productElements.forEach((product) => {
const titleElement = product.querySelector('[data-cy="title-recipe"] a h2 span');
const title = titleElement ? titleElement.textContent.trim() : 'N/A';
console.log(title);
const priceWhole = product.querySelector('.a-price-whole');
const priceFraction = product.querySelector('.a-price-fraction');
const price = priceWhole && priceFraction
? `$${priceWhole.textContent}${priceFraction.textContent}`
: 'N/A';
const ratingElement = product.querySelector('.a-icon-alt');
const rating = ratingElement ? ratingElement.textContent.split(' ')[0] : 'N/A';
const imageElement = product.querySelector('.s-image');
ja
const imageUrl = imageElement ? imageElement.src : 'N/A';
const asin = product.getAttribute('data-asin') || 'N/A';
items.push({
title,
price,
rating,
imageUrl,
asin
});
});
return items;
});
console.log(JSON.stringify(products, null, 2));
return products;
} finally {
await browser.close();
}
};
// 新しいプロフィールを作成する
const createProfile = async () => {
try {
const createResponse = await client.profiles.create('マイプロフィール' + randomString());
console.log('プロフィールが作成されました:', createResponse);
return createResponse.profileId;
} catch (error) {
console.error('プロフィールの作成に失敗しました:', error);
throw error;
}
};
// 必要なプロフィールを取得または作成する
const getProfiles = async (count) => {
try {
const response = await client.profiles.list({ page: 1, pageSize: count });
const profiles = response?.docs;
if (profiles.length < count) {
const profilesToCreate = count - profiles.length;
const creationPromises = Array(profilesToCreate).fill(0).map(() => createProfile());
const newProfiles = await Promise.all(creationPromises);
return [...profiles.map(p => p.profileId), ...newProfiles];
}
return profiles.slice(0, count).map(p => p.profileId);
} catch (error) {
console.error('プロフィールの取得に失敗しました:', error);
throw error;
}
};
// タスクを同時に実行する
const runTasks = async () => {
try {
const profileIds = await getProfiles(MAX_PROFILES);
const tasks = profileIds.map((profileId, index) => {
const taskId = index + 1;
return runTask(profileId, taskId);
});
await Promise.all(tasks);
console.log('すべてのタスクが正常に完了しました');
} catch (error) {
console.error('タスクの実行中にエラーが発生しました:', error);
}
};
// タスクを実行する
await runTasks();テスト結果:
- Amazonの検索ページは、トリガーされたreCAPTCHAを自動的に処理しました
- 商品のタイトル、価格、評価、画像、ASIN、その他のデータを正常に抽出しました
- プロセス全体に人間の介入は不要で、CAPTCHAは自動的に検出されて通過しました
結果説明の例:
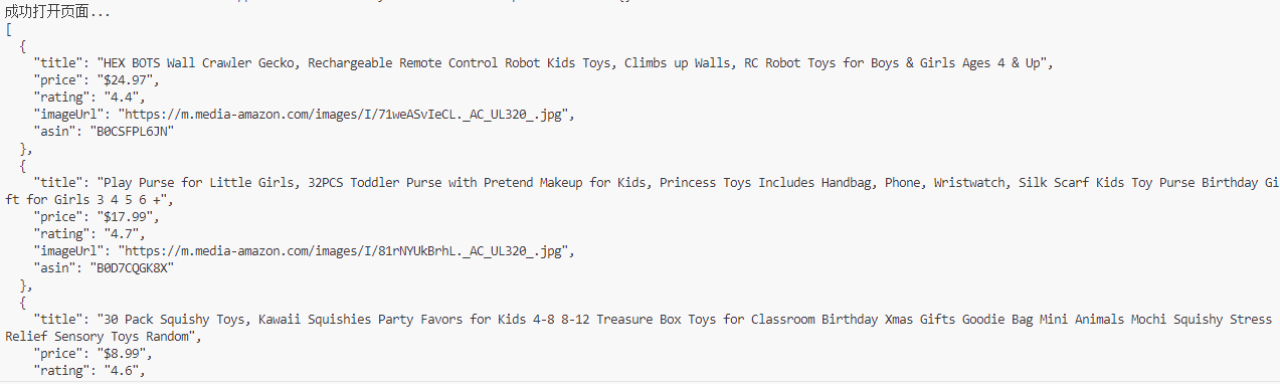
- 成功したCAPTCHAの回避とデータ抽出:
ページが正常に読み込まれ、商品データが抽出されました:
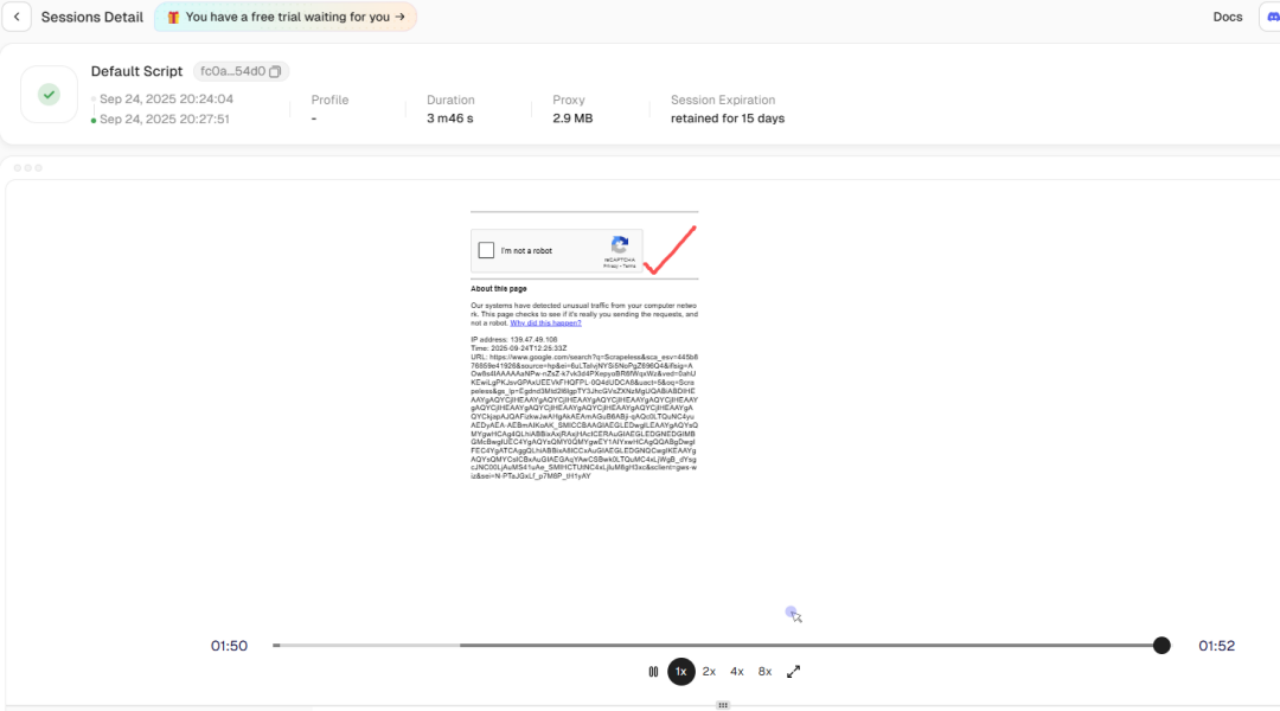
- 自動化されたCAPTCHA処理:
セッション履歴の再生機能を使用すると、データスクレイピング中にリスク確認がトリガーされたことが確認できますが、Scrapelessは内部でreCAPTCHAを自動的に回避しました。これにより、バックグラウンドでのデータスクレイピングがブロックされる障害が解決されます。
通常、Amazonの検索ページを訪れると、手動の操作を必要とするreCAPTCHAがトリガーされる可能性があります。Scrapeless Cloud Browserを使用すると:
- reCAPTCHAが自動的に検出されます
- 内蔵APIが検証フローを自動的に完了します
- スクリプトが実行を続け、商品データを抽出します
- クラウド可観測性:
Scrapelessパネルは提供します:
- ライブセッション: ブラウザインスタンスのリアルタイム監視によるスクリプト実行の観察
- セッション履歴: 過去のセッションを再生してデバッグおよびCAPTCHA処理のレビュー
ブラウザがクラウドで実行されているにもかかわらず、ローカルデバッグに近い体験を提供し、クラウドブラウザのデバッグの難易度を大幅に削減します。
まとめ
3つの実用的なシナリオから、Scrapeless Cloud Browserの主要な次元におけるパフォーマンスを要約できます:
- 同時実行性と環境の分離
- プロフィールのバッチ作成と管理をサポート
- 各プロフィールのフィンガープリント、クッキー、キャッシュ、ブラウザデータは完全に分離されます
- 競合やリソースの争奪なしに10以上の同時タスクをサポートしており、数千の同時タスクにスケール可能
- 数百または数千の独立したブラウザインスタンスを同時に持つのと同等
- ランダムなブラウザフィンガープリント
- 各プロフィールの作成時に、ユーザーエージェント、タイムゾーン、言語、画面解像度などのコアパラメータがランダムに生成されます
- フィンガープリントは実際のブラウザ環境を密接に模倣
- 自動アクセスとして検出される可能性を減少させる
- 内蔵CAPTCHAの自動化
- reCAPTCHA、Cloudflare Turnstile / Challenge、その他のCAPTCHAタイプの自動認識をサポート
- 人間の介入なしに自動的に検証を完了
- クラウドブラウザの可視性
* **ライブセッション:** ブラウザの実行をリアルタイムで監視
* **セッション履歴:** 過去のセッションを再生してデバッグと検証
マルチ環境の隔離、高い同時実行性、およびCAPTCHAバイパスを必要とする自動化シナリオには、Scrapeless Cloud Browserが強力な選択肢です。
> ウェブ自動化を強化する準備はできていますか? [Scrapeless](https://app.scrapeless.com/passport/login?utm_source=wechat&utm_medium=official_account&utm_campaign=bee) Cloud Browserを今すぐお試しください。シームレスなプロファイル管理、独立したフィンガープリント、そして自動化されたCAPTCHA処理をすべてクラウドで体験できます!
---
**免責事項:** 自動化ツールの使用は、対象サイトの利用規約および関連法令に従う必要があります。この記事は技術的な研究および検証目的のみです。Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


