
Instagramプロフィールデータを迅速にスクレイピングする方法
Specialist in Anti-Bot Strategies
Instagramは、世界中で数百万人のユーザーを抱える、最も人気のあるソーシャルメディアプラットフォームの1つです。Instagramプロフィールのスクレイピングは、マーケティング分析、競合調査、または個人データ管理のために、企業、開発者、データ分析の専門家に役立ちます。
この記事では、Instagramプロフィールのスクレイピングのプロセスを詳しく説明します。Instagramプロフィールや投稿ページからデータを取得するためのInstagramスクレイパーの作成方法を説明します。
便利なスクレイピングAPIを使用して、Insデータを迅速にスクレイピングする方法を学ぶ時です。
- #方法1. Python Instagramプロフィールスクレイパーを構築する
- #方法2. スクレイピングAPIを使用して簡単にデータ収集する
なぜInstagramプロフィールをスクレイピングするのか?
Instagramのパブリックデータは膨大であり、あらゆる種類のインサイトを提供できます。プロフィールデータのスクレイピングは、世界中の人気のユーザーに関する貴重な情報を提供し、トレンドの予測、ブランド認知度の追跡、Instagramのパフォーマンス向上方法の理解、または同様の興味を持つ人気のあるInstagramプロフィールに接続することにより、企業が新たな顧客を獲得し、リーチするのに役立ちます。
さらに、スクレイピングされたInstagramデータは、感情分析研究にとって貴重なリソースです。このデータは投稿やコメントに見られ、特定のトレンドやニュースに対する世論を収集するために使用できます。
方法1. Python Instagramプロフィールスクレイパー
Instagramのユーザープロフィールのスクレイピングから始めましょう!次に、Instagramユーザーladygagaのプロフィール情報をスクレイピングする方法を詳しく説明します。以下の手順に従って実行できます。
ウェブサイトのプライバシーを厳格に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモとしてのみ使用されます。情報は一切保存しません。
ステップ1. ターゲットページの分析
- ターゲットURLにアクセスします:https://www.instagram.com/ladygaga/。
- ページのソースコードを検査して、埋め込まれたJSONデータを見つけます。
- Instagramは、
window._sharedDataという形式のscriptタグにユーザー情報を埋め込んでいます。 - HTMLを解析することで、このデータを取得できます。
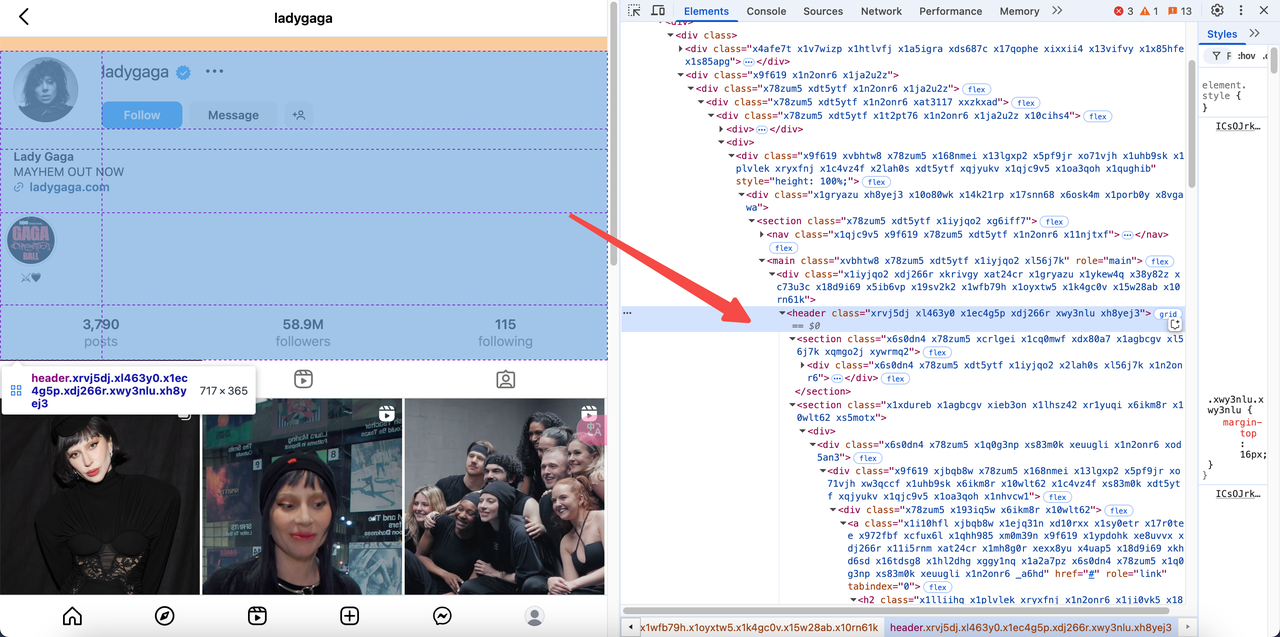
ステップ2. 必要なライブラリのインストール
次のPythonライブラリがインストールされていることを確認します。
pip install requests beautifulsoup4
ステップ3. リクエストヘッダーの設定
ブラウザアクセスをシミュレートするには、User-AgentヘッダーとRefererヘッダーを設定して、アンチスクレイピングメカニズムによってブロックされないようにします。
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}ステップ4. JSONデータの解析
HTMLのscriptタグからwindow._sharedDataの内容を抽出し、Pythonの辞書に変換する必要があります。
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSONデータがページに見つかりません。")
return None
# JSONデータの解析
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: JSONデータの解析に失敗しました。")
return Noneステップ5. 必要なフィールドの抽出
解析されたJSONデータから、ユーザー名、バイオ、フォロワー数、投稿数、その他の関連情報を取得します。
完全なコード
以下は、Lady Gagaのプロフィール情報をスクレイピングするために直接使用できる完全なPythonコードです。
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: {username}のデータを取得できませんでした。ステータスコード:{response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSONデータがページに見つかりません。")
return None
# JSONデータの解析
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: JSONデータの解析に失敗しました。")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# 使用例
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Instagramプロフィールデータ:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))スクレイピング結果
コードを実行した後、profile_dataの出力には次のフィールドが含まれます。
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}方法2. ScrapelessスクレイピングAPI(推奨)
Instagramのスクレイピングは非常に簡単です。しかし、Instagramは公開データへのアクセスに関して非常に制限的です。ログインしていないユーザーに対しては、1日に許可されるリクエスト数が非常に少なく、それを超えるとログインページにリダイレクトされます。
Instagramスクレイパーのブロックを回避するにはどうすればよいでしょうか?Scrapelessが理想的なスクレイピングツールです!
Scrapelessは、大規模なデータ収集のためのウェブスクレイピング、ウェブブロック解除、データ抽出APIを提供します。
- ボット対策の回避: ウェブのスクレイピング中にブロックされるのを回避!
- ローテーション住宅プロキシ: IPブロックとジオブロッキングを防ぎます。
- JavaScriptレンダリング: クラウドブラウザを介して動的なウェブページをスクレイピングします。
- PythonとTypescript SDK、そしてScrapyの統合。
このInstagramスクレイピングAPIは無料ですか?
はい。Scrapelessは2ドルの無料クレジットを提供します。無料クレジットを請求するには直接サインアップできます。Instagramプロフィールスクレイパーを使用すると、ユーザー情報を無料で簡単に収集できます!
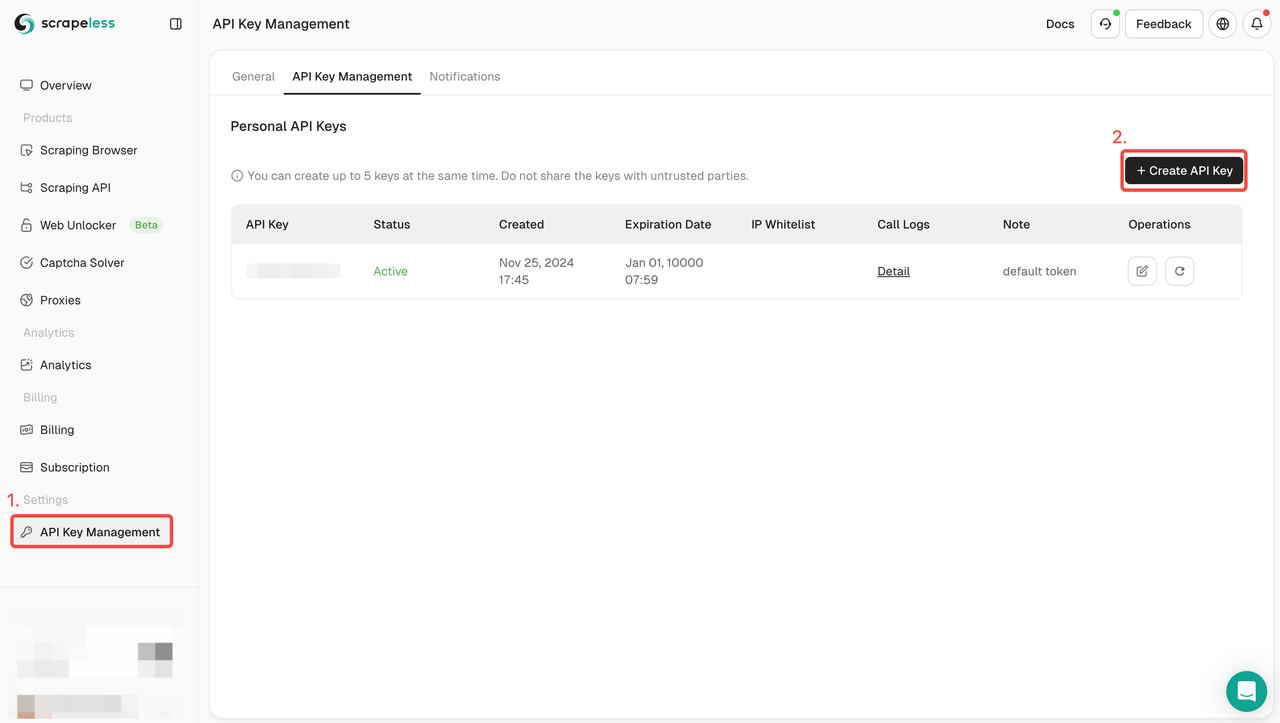
ステップ1. APIトークンの作成
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 作成したら、APIキーをクリックしてコピーします。
まとめ
このチュートリアルでは、Instagramプロフィールデータを取得する2つの効率的な方法を紹介しました。認証方法、リクエスト方法、レスポンスの処理方法、およびプロキシIPを統合して安定性とセキュリティを向上させる方法を示しました。
このガイドに従って、プライバシーを維持し、レート制限などの問題を回避しながら、個人用または商用でInstagramプロフィールデータの抽出を簡単に開始できます。
データ収集の効率を向上させるために、高度なスクレイピングAPIを使用することをお勧めします。これにより、単純な設定パラメーターだけでデータ抽出を完了できます!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


