
PythonでGoogleの商品オンライン販売業者をスクレイピングする方法
Advanced Data Extraction Specialist
はじめに
今日の競争の激しいeコマース環境において、Googleなどのプラットフォーム上での商品リスティングの監視とオンラインセラーのパフォーマンス分析は、貴重な洞察を提供します。Googleの商品リスティングをスクレイピングすることで、企業はリアルタイムのデータを収集し、価格を比較したり、トレンドを追跡したり、競合他社を分析したりすることができます。この記事では、さまざまな方法を用いて、PythonでGoogleの商品オンラインセラーをスクレイピングする方法を紹介します。また、信頼性が高く、スケーラブルで、合法的なソリューションを求める企業にとって、Scrapelessが最適な選択肢である理由についても説明します。
Googleの商品オンラインセラーのスクレイピングにおける課題の理解
Googleの商品オンラインセラーをスクレイピングしようとすると、いくつかの重要な課題が発生する可能性があります。
- 反スクレイピング対策: ウェブサイトは、自動化されたスクレイピングを防ぐためにCAPTCHAやIPブロックを実装しており、データ抽出を困難にしています。
- 動的コンテンツ: Googleの商品ページは、多くの場合、JavaScriptを使用してデータをロードするため、Requests & BeautifulSoupやSeleniumなどの従来のスクレイピング方法では見逃される可能性があります。
- レート制限: 短時間に過剰なリクエストを行うと、アクセスが絞り込まれ、スクレイピングプロセスが遅延したり中断したりする可能性があります。
プライバシーに関する通知: 当社はウェブサイトのプライバシーを厳格に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモンストレーションのみに使用されます。いかなる情報やデータも保存しません。
方法1:Scrapeless APIを使用したGoogleの商品オンラインセラーのスクレイピング(推奨ソリューション)
Scrapelessが優れたツールである理由:
- 効率的なデータ抽出: Scrapelessは、CAPTCHAや反ボット対策を回避できるため、スムーズで中断のないデータスクレイピングを実現します。
- 手頃な価格: クエリ1,000件あたりわずか0.1ドルで、ScrapelessはGoogleのスクレイピングのための最も手頃な価格のソリューションの1つを提供しています。
- 複数ソースのスクレイピング: Googleの商品オンラインセラーのスクレイピングに加えて、Scrapelessでは、Googleマップ、Googleホテル、Googleフライト、Googleニュースなどからデータ収集できます。
- 速度とスケーラビリティ: 大規模なスクレイピングタスクを迅速に処理できるため、小規模プロジェクトからエンタープライズレベルのプロジェクトまで、あらゆる規模のプロジェクトに最適です。
- 構造化データ: このツールは、分析、レポート、またはシステムへの統合にすぐに使用できる、構造化されたクリーンなデータを提供します。
- 使いやすさ: 複雑な設定は不要で、APIキーを統合するだけで数分以内にデータのスクレイピングを開始できます。
Scrapeless APIの使い方:
- サインアップ: Scrapelessに登録してAPIキーを取得します。同時に、ダッシュボードの上部で無料トライアルも入手できます。
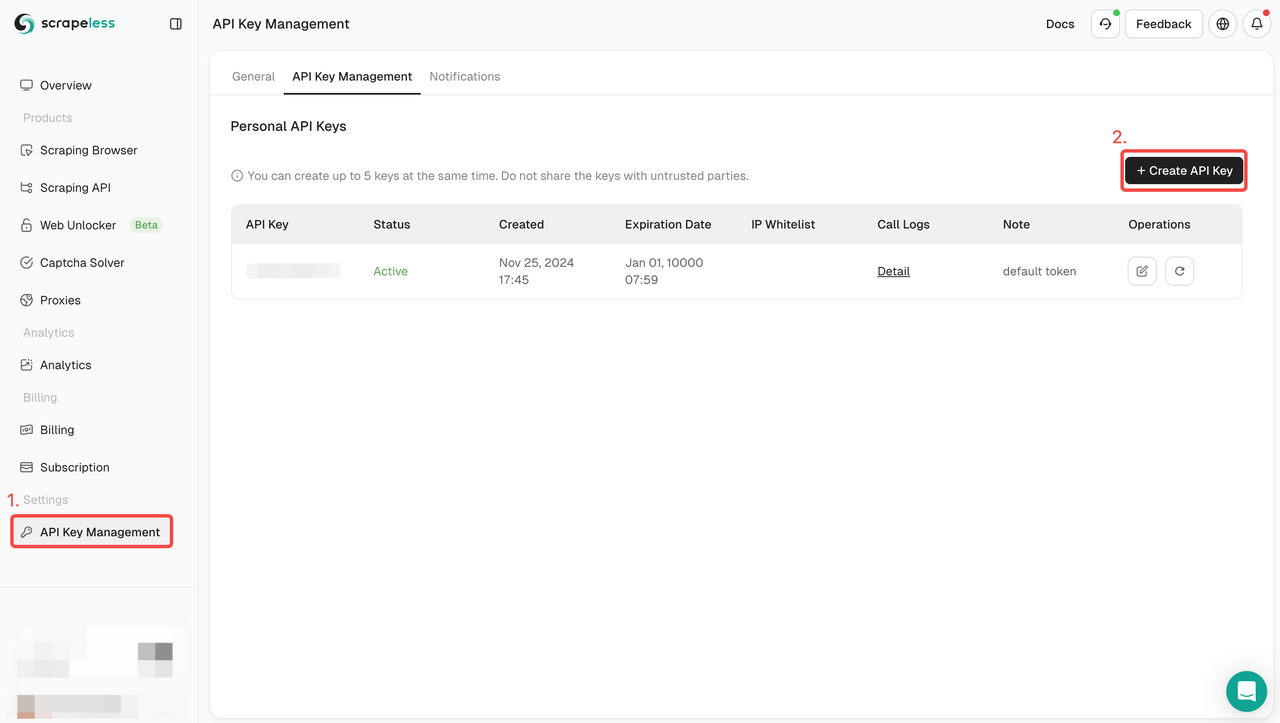
- APIの統合: サービスへのリクエストを開始するために、コードにAPIキーを含めます。
- スクレイピング開始: 商品のURLまたは検索クエリを使用してGETリクエストを送信すると、Scrapelessは商品名、価格、レビューなどを含む構造化されたデータが返されます。
- データの使用: 取得したデータを、競合分析、トレンド追跡、またはGoogleデータの洞察を必要とするその他のプロジェクトに活用します。
完全なコード例:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Scrapelessを無料で試すと、当社のAPIがGoogleの商品オンラインセラーのスクレイピングプロセスをどのように簡素化できるかを体験してください。無料トライアルはこちらで開始してください。
Discordコミュニティに参加して、サポートを受けたり、洞察を共有したり、最新の機能に関する最新情報を入手したりしてください。こちらをクリックして参加してください!
方法2:Requests & BeautifulSoupを使用したGoogleの商品リスティングのスクレイピング
この方法では、強力な2つのPythonライブラリであるRequestsとBeautifulSoupを使用して、Googleの商品リスティングをスクレイピングする方法を詳しく説明します。これらのライブラリを使用すると、Googleの商品ページにHTTPリクエストを行い、HTML構造を解析して貴重な情報を抽出できます。
ステップ1. 環境の設定
まず、システムにPythonがインストールされていることを確認します。そして、このプロジェクトのコードを保存するための新しいディレクトリを作成します。次に、beautifulsoup4とrequestsをインストールする必要があります。これはPIPを使用して行うことができます。
language
$ pip install requests beautifulsoup4ステップ2. requestsを使用して単純なリクエストを行う
次に、Google商品のデータをクロールする必要があります。product_id 4172129135583325756の商品を例に、OnlineSellerのいくつかのデータをクロールしてみましょう。
まず、requestsを使用してGETリクエストを送信してみます。
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)予想通り、リクエストは完全なHTMLページを返します。次に、以下のページからいくつかのデータを取り出す必要があります。
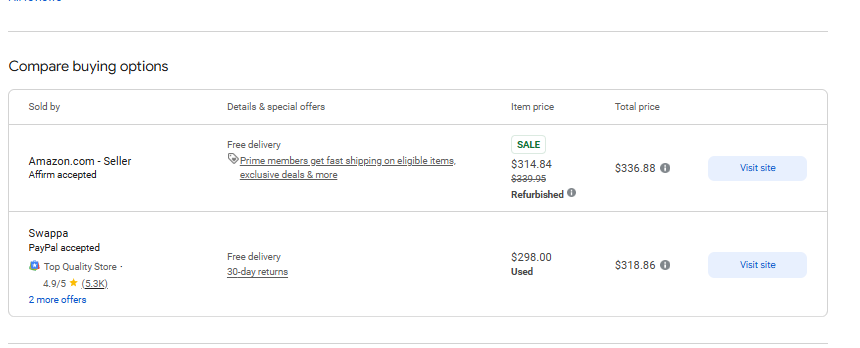
ステップ3. 特定のデータを取得する
図に示すように、必要なデータはtr[jscontroller='d5bMlb']の下にあります。
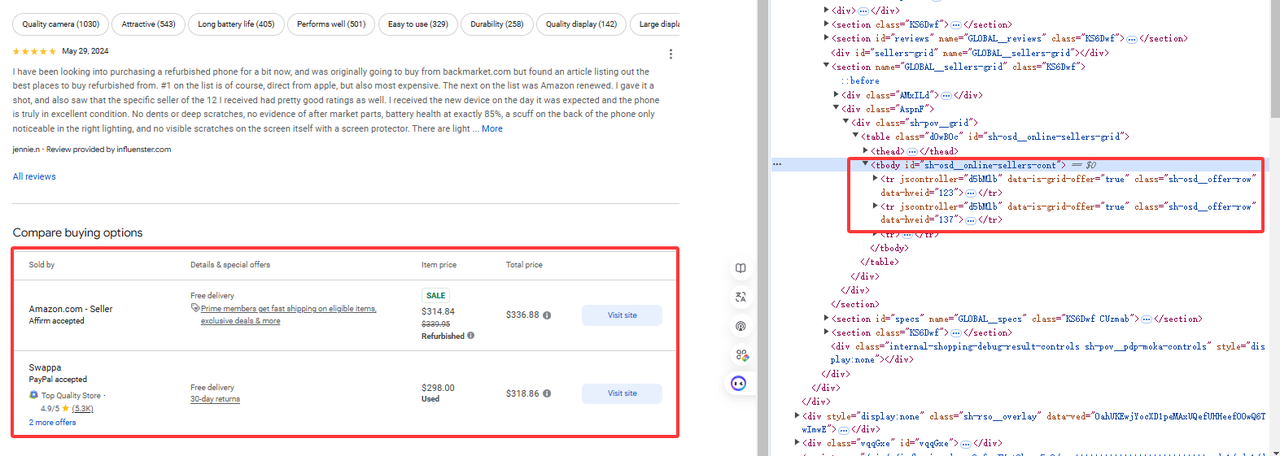
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})次に、BeautifulSoupを使用してHTMLページを解析し、関連する要素を取得します。
完全なコード
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)コンソール出力結果は以下の通りです。

制限事項
もちろん、部分的なデータを取得する上記の例を使用してデータを戻すことができますが、IPブロックのリスクがあります。大量のリクエストを行うことはできず、Googleの商品リスク管理がトリガーされます。
方法3:Seleniumを使用したGoogleの商品オンラインセラーのスクレイピング
この方法では、強力なWeb自動化ツールであるSeleniumを使用して、オンラインセラーからGoogleの商品リスティングをスクレイピングする方法について説明します。RequestsとBeautifulSoupとは異なり、Seleniumを使用すると、実行にJavaScriptが必要な動的なページと対話できるため、動的にコンテンツを読み込むGoogleの商品リスティングのスクレイピングに最適です。
ステップ1:環境の設定
まず、システムにPythonがインストールされていることを確認します。そして、このプロジェクトのコードを保存するための新しいディレクトリを作成します。次に、seleniumとwebdriver_managerをインストールする必要があります。これはPIPを使用して行うことができます。
pip install selenium
pip install webdriver_managerステップ2:Selenium環境の初期化
次に、Seleniumのいくつかの構成項目を追加し、環境を初期化する必要があります。
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)ステップ3:特定のデータを取得する
Seleniumを使用して、product_id 4172129135583325756の商品を取得し、OnlineSellerのいくつかのデータを取得します。
driver.get(url)
time.sleep(5) #ページを待つ
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""完全なコード
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)コンソール出力結果は以下の通りです。

制限事項
SeleniumはWebブラウザ操作を自動化するための強力なツールであり、自動テストやWebデータクロールで広く使用されています。ただし、ページの読み込みを待つ必要があるため、データクロールプロセスは比較的遅くなります。
FAQ
Googleの商品リスティングを大規模にスクレイピングするための最良の方法は何ですか?
大規模なGoogleの商品スクレイピングに最も効果的な方法は、Scrapelessを使用することです。高速でスケーラブルなAPIを提供し、動的コンテンツ、IPブロック、CAPTCHAを効率的に処理するため、企業に最適です。
商品リスティングをスクレイピングするときに、Googleの反スクレイピング対策をどのように回避しますか?
Googleは、CAPTCHAやIPブロックなど、いくつかの反スクレイピング対策を講じています。Scrapelessは、これらの対策を回避し、スムーズで中断のないデータ抽出を保証するAPIを提供します。
BeautifulSoupやSeleniumなどのPythonライブラリを使用して、Googleの商品リスティングをスクレイピングできますか?
BeautifulSoupとSeleniumはGoogleの商品リスティングのスクレイピングに使用できますが、パフォーマンスの低下、検出リスク、スケーリングできないなどの制限があります。Scrapelessは、これらの問題をすべて解決する、より効率的なソリューションを提供します。
まとめ
この記事では、Googleの商品オンラインセラーをスクレイピングする3つの方法、Requests & BeautifulSoup、Selenium、およびScrapelessについて説明しました。それぞれの方法には独自の利点がありますが、大規模なスクレイピングを扱う場合は、Scrapelessが企業にとって間違いなく最良の選択肢です。
- Requests & BeautifulSoupは小規模なスクレイピングタスクに適していますが、動的コンテンツを扱う場合やスケールアップする際には制限があります。これらのツールは、反スクレイピング対策によってブロックされるリスクもあります。
- SeleniumはJavaScriptでレンダリングされたページに効果的ですが、リソースを大量に消費し、他のオプションよりも遅いため、Googleの商品リスティングの大規模なスクレイピングにはあまり適していません。
一方、Scrapelessは、従来のスクレイピング方法に関連するすべての課題に対処します。高速で信頼性が高く、合法的なため、ブロックされる心配やその他の障害に遭遇することなく、効率的にGoogleの商品オンラインセラーを大規模にスクレイピングできます。
効率的でスケーラブルなソリューションを求める企業にとって、Scrapelessは最適なツールです。従来の方法のすべての障害を回避し、Googleの商品データの収集をスムーズかつ簡単にします。
無料トライアルでScrapelessを今日試してみて、Googleの商品スクレイピングタスクを簡単にスケーリングする方法を発見してください。今すぐ無料トライアルを開始。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


