
PythonでGoogleの商品レビュー結果をスクレイピングする方法
Advanced Data Extraction Specialist
デジタルの波が世界を席巻する中、世界最大の検索エンジンの1つであるGoogleは、その検索結果ページ(SERP)に膨大な量の貴重なデータを隠しています。このデータは、単なる情報のリストではなく、市場のダイナミクスへの洞察、競合他社の分析、消費者行動の理解への鍵でもあります。
しかし、Googleの検索結果を効率的かつ効果的にクロールすることは容易ではありません。Google Productのページ構造は複雑で変化しやすく、強力な反クローラーメカニズムを備えているため、従来のデータクロール方法は多くの場合機能しません。これらの課題に対処するために、Googleの構造変化に適応できる強力で、スケーラブルで、柔軟なデータパイプラインが特に重要になります。独自の大規模言語モデル(LLM)を構築する計画がある場合でも、市場から第一線の消費者インサイトを得たい場合でも、信頼できるGoogle検索クローラーは不可欠です。
この記事では、PythonとBeautifulSoupライブラリを使用して、Google製品レビュー結果クローラーをゼロから構築する方法に焦点を当てます。このツールを使用すると、貴重なデータを自動的に抽出し、検索エンジンのデータの海から意思決定に直接使用できる洞察を掘り出すことができます。
Google製品結果スクレイピングのユースケース
Google製品結果のスクレイピングは、企業や研究者が市場の洞察を得るための重要な手段となっています。このデータを分析することにより、企業は市場トレンド、消費者嗜好、競合他社のダイナミクスを理解し、より効果的なビジネス戦略を開発することができます。以下は、一般的な使用例です。
- 市場調査とトレンド分析
- 競合他社分析
- 製品開発と最適化
- 消費者行動の洞察
- 価格監視と調整
- ブランド保護と評判管理
- eコマースとオンライン小売の最適化
- 学術研究とデータ分析
- 公共政策の策定と監督
Google製品レビュークロールにおける困難
Google製品レビューの抽出には、以下の課題があります。
反スクレイピング対策
- GoogleはCAPTCHAとIPブロックを使用してボットを防止しています。
- バイパスするにはプロキシとユーザーエージェントのローテーションが必要です。
動的コンテンツとJavaScriptレンダリングコンテンツ
- レビューはJavaScriptを介して動的に読み込まれます。
- PuppeteerやSeleniumなどのツールが必要です。
頻繁なDOM構造の変更
- GoogleはHTML構造を定期的に更新します。
- スクレイパーは継続的なメンテナンスが必要です。
方法1:Scrapelessを使用したGoogle製品レビュー結果のスクレイピング
PythonでGoogle製品レビューをスクレイピングするには、動的コンテンツの読み込みや反スクレイピングメカニズムなどの課題に対処する必要があります。このセクションでは、レビューデータを効率的に抽出するための効果的な方法とツールについて説明します。
ステップ1:Google製品データクロール環境の構築
まず、データクロール環境を構築し、以下のツールを用意する必要があります。
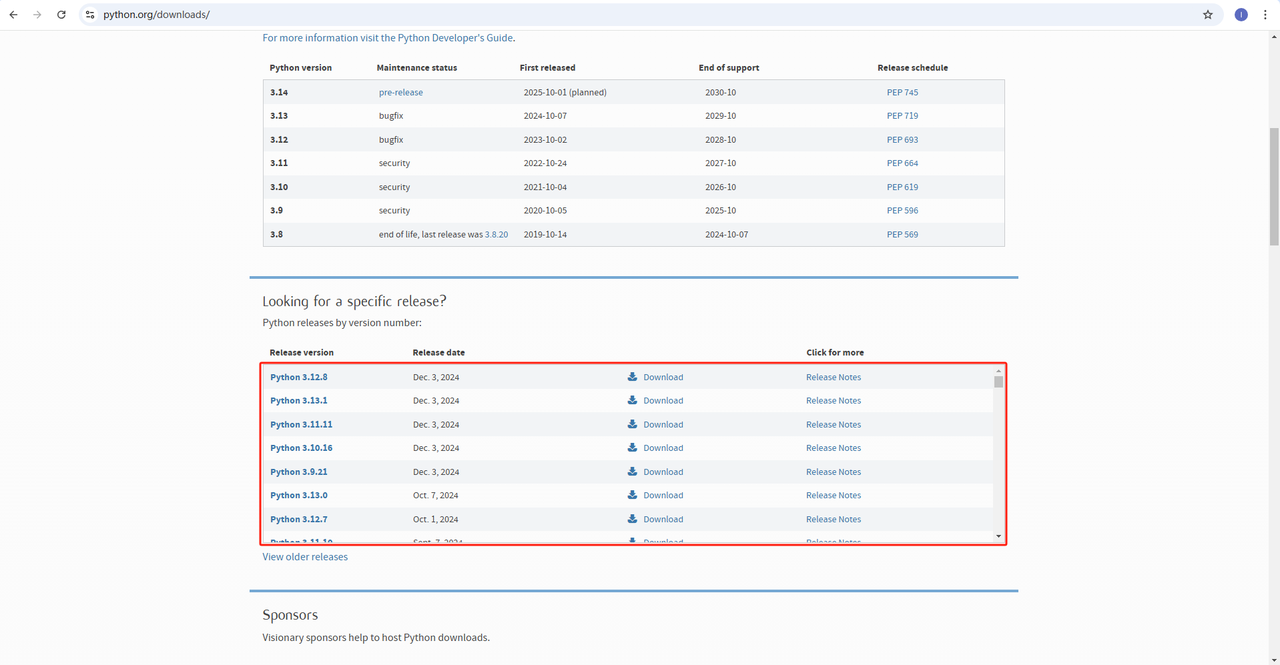
1. Python: これはPythonを実行するためのコアソフトウェアです。以下の図に示す公式ウェブサイトのリンクから必要なバージョンをダウンロードできますが、最新バージョンをダウンロードしないことをお勧めします。最新バージョンより1~2つ前のバージョンをダウンロードできます。
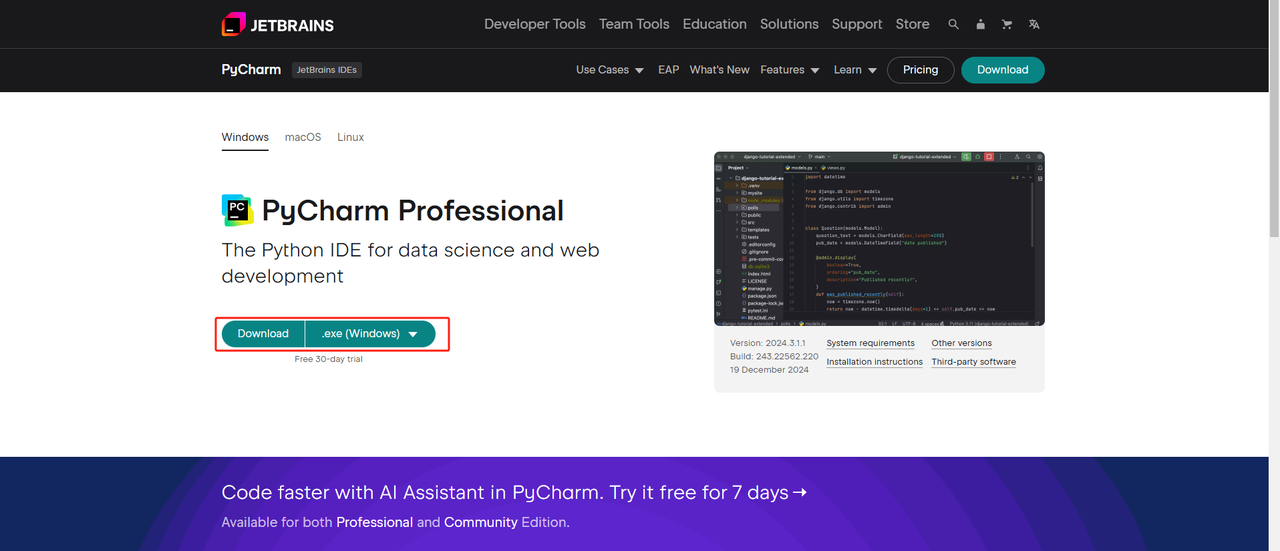
2. Python IDE: PythonをサポートするIDEであればどれでも構いませんが、Python用に特別に設計されたIDE開発ツールソフトウェアであるPyCharmをお勧めします。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
3. Pip: Python Package Indexを使用して、単一のコマンドでプログラムを実行するために必要なライブラリをインストールできます。
注記: Windowsユーザーの場合は、インストールウィザードで「Add python.exe to PATH」オプションを必ず選択してください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
上記の手順により、Google Productデータクロールのための環境が設定されます。次に、ダウンロードしたPyCharmとScraperlessを組み合わせてGoogle Productデータをクロールできます。
ステップ2:PyCharmとScrapelessを使用したGoogle Productデータのスクレイピング
-
PyCharmを起動し、メニューバーから[ファイル]>[新規プロジェクト]を選択します。
-
次に、表示されるウィンドウの左側のメニューから[Pure Python]を選択し、プロジェクトを次のように設定します。
注記: 下の赤いボックスで、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択します。
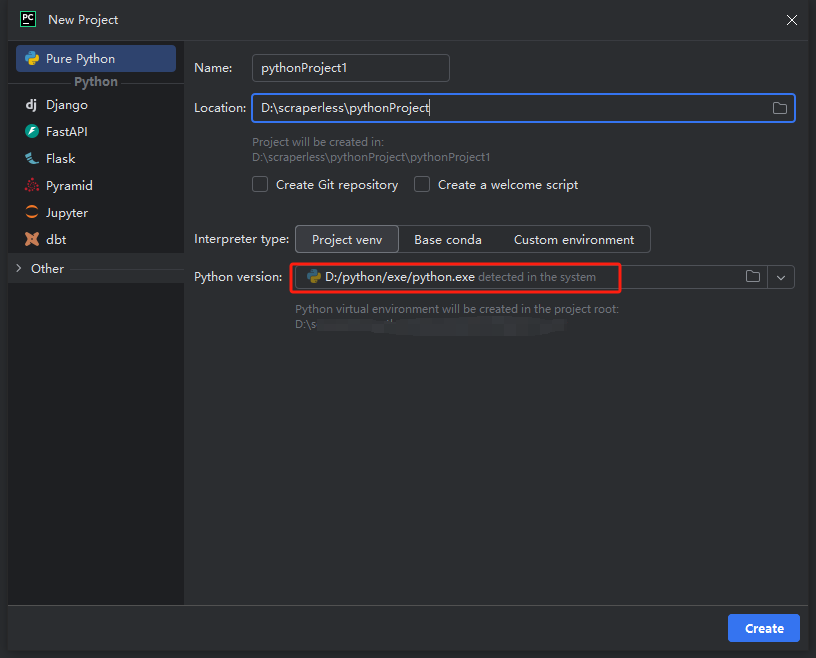
python-scraperという名前のプロジェクトを作成し、「フォルダー内の "Create main.py welcome script" オプション」を選択して「作成」ボタンをクリックします。PyCharmがしばらくプロジェクトを設定した後、次のようになります。
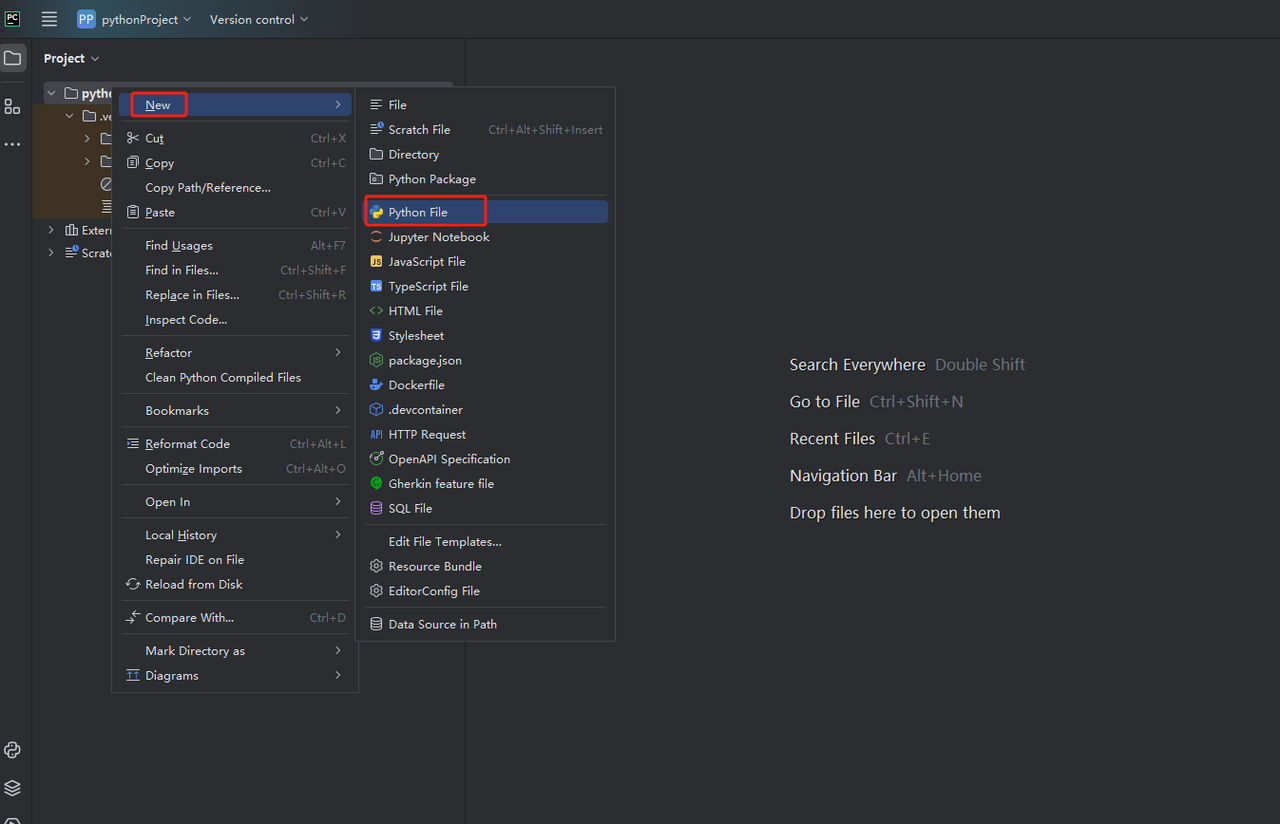
-
次に、右クリックして新しいPythonファイルを作成します。
-
すべてが正しく機能していることを確認するために、画面下部の[ターミナル]タブを開き、「python main.py」と入力します。このコマンドを実行すると、「Hi, PyCharm.」が表示されます。
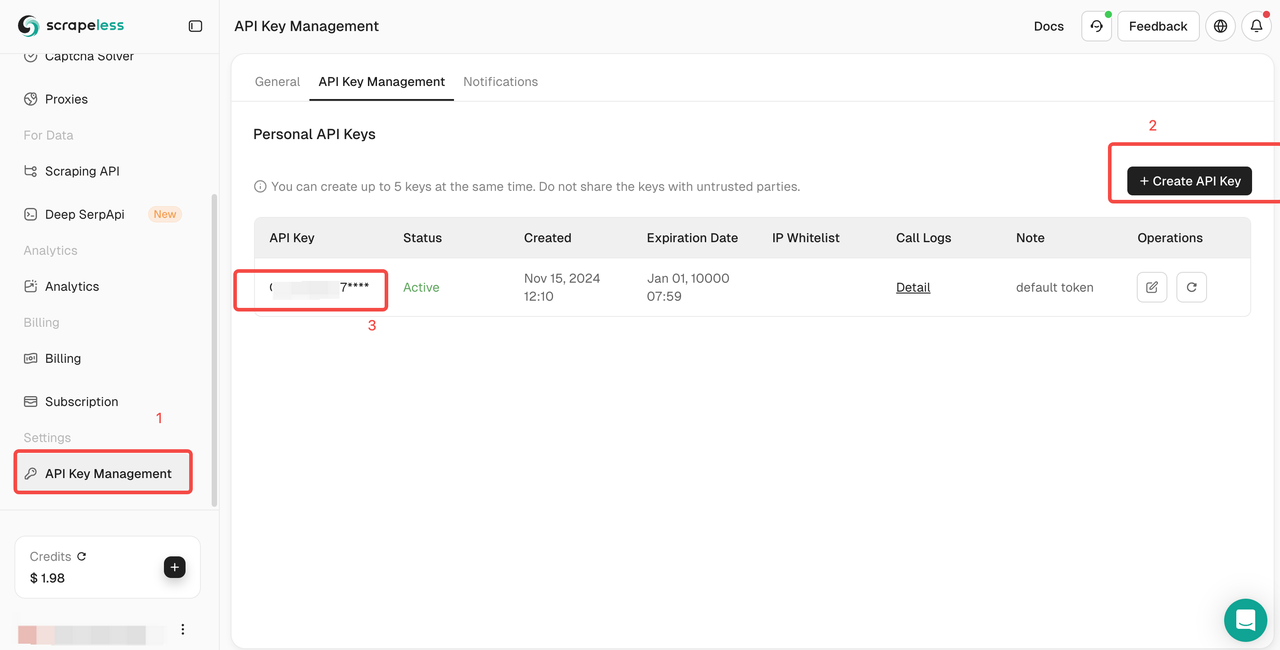
ステップ3:Scrapeless APIキーの取得
これで、ScrapelessのコードをPyCharmに直接コピーして実行できるため、Google JobのJSON形式のデータを取得できます。ただし、最初にScrapeless APIキーを取得する必要があります。手順は以下のとおりです。
- まだアカウントをお持ちでない場合は、Scrapelessにサインアップしてください。サインアップ後、ダッシュボードにログインします。
- Scrapelessダッシュボードで、[APIキー管理]に移動し、[APIキーの作成]をクリックします。APIキーを取得します。マウスをキーの上に置いてクリックしてコピーします。このキーは、Scrapeless APIを呼び出す際の要求の認証に使用されます。
当サイトではウェブサイトのプライバシーを厳守しています。このブログのすべてのデータは公開されており、クロールプロセスのデモンストレーションのみに使用されています。情報は一切保存しません。
Scrapelessに参加して、20,000件のクエリを無料で入手しましょう!
Scrapelessにサインアップして、無料で20,000件のクエリをお楽しみください!Google製品レビューのクロールを開始し、簡単に貴重な洞察を解き放ちましょう。見逃さないでください—今すぐ登録して、Scrapelessのパワーを無料で体験しましょう!
ステップ4:スクレイピングツールにScrapeless APIを統合する方法
APIキーを取得したら、独自のスクレイピングツールにScrapeless APIを統合し始めることができます。次に、Scrapeless APIを呼び出してPythonとrequestsを使用してデータを取得する方法の例を示します。
Scrapeless APIを使用してGoogle Product情報をクロールするためのサンプルコード:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()このコードの出力に基づいて、Google製品レビューに関するすべての情報を見つけることができます。
Scrapeless APIパラメーターの公式ドキュメントドキュメントも参照できます。
以下は、ユーザーコメント情報を含む結果の一部です。
json
body {"product_results":{"product_id":"4172129135583325756","title":"Apple iPhone 12 Pro - 128 GB - Silver - AT\u0026T","price":["$314.84","$298.00","$325.33"],"reviews":14303,"rating":4.4,"extensions":["Smartphone","Dual SIM","5G","With Wireless Charging","With Fast Charging","AT\u0026T","Dual Lens","iOS","GSM","CDMA"],"description":"5G goes Pro. A14 Bionic rockets past every other smartphone chip. The iPhone 12 Pro features a 6.1” Super Retina XDR display, LiDAR scanner for ultrafast and accurate depth maps of whatever space you're in and MagSafe wireless charging. The Pro camera system takes low-light ...More5G goes Pro. A14 Bionic rockets past every other smartphone chip. The iPhone 12 Pro features a 6.1” Super Retina XDR display, LiDAR scanner for ultrafast and accurate depth maps of whatever space you're in and MagSafe wireless charging. The Pro camera system takes low-light photography to the next level with Night mode available in both the Wide and Ultra Wide cameras, so it’s better than ever at capturing incredible low-light shots. And Ceramic Shield delivers four times better drop performance.Less","media":[{"type":"image","link":"https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcStw-jdTZtGmdXcVKCqweq6wxzU5tpRTTbl6stPV97GpGVR6XY\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn1.gstatic.com/shopping?q=tbn:ANd9GcR0wJ1fsUOPAGDMtjdtx1zsd5ZWUXwnNe70fmZszERkEihkYCKnZoGJ3Y4lqSQTyR4soiTVWFVzllzYTHJBTRXegTR7Pj83RA\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn1.gstatic.com/shopping?q=tbn:ANd9GcR4L66Gss9O5HSL00NLxaHu0pl5huMUojbC9tO9FKCRpCQObUqdHWsSPYZJ4lU8eETn-MlJx4Hni_oc_l5mxIs_l-Z2htBiaA\u0026usqp=CAY"},{"type":"image","link":"https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcQLv5xOi-9b-Mka7jfFnQzlXkTrEAsjPAzumbUB2D6Ddgl3FHGZOQXAUGQAv6WkUeZsbsdvKA2NRF1-h8EOBSQPLmuPMLPQ2Q\u0026usqp=CAY"}],"sizes":{"128 GB":{"link":"https://www.google.com/shopping/product/4172129135583325756?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8","product_id":"4172129135583325756"},"256 GB":{"link":"https://www.google.com/shopping/product/1700752269234454309?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8\u0026prds=opd:11579479524734831751,rsk:PC_14243855303706753583\u0026sa=X\u0026ved=0ahUKEwjxhNXT2ZeMAxVcK7kGHUh1ErMQlIUHCEQoAQ","product_id":"1700752269234454309"},"512 GB":{"link":"https://www.google.com/shopping/product/14752474427020499512?gl=us\u0026hl=en\u0026sourceid=chrome\u0026ie=UTF-8\u0026prds=opd:11579479524734831751,rsk:PC_14243855303706753583\u0026sa=X\u0026ved=0ahUKEwjxhNXT2ZeMAxVcK7kGHUh1ErMQlIUHCEUoAg","product_id":"14752474427020499512"}},"highlight":["5G transforms iPhone with accelerated wireless speeds and better performance on congested networks","A14 Bionic: generations ahead of any other smartphone chip","Night mode comes to both the Wide and Ultra Wide cameras, and it's better than ever at capturing incredible low-light shots",Scrapelessを使用してGoogle製品レビューをクロールする理由
- 手頃な価格: クエリ1,000件あたりわずか0.1ドルで、Scrapelessは予算を圧迫することなくデータ収集を拡大する必要がある企業にとって非常に費用対効果の高いソリューションを提供します。
- 高速で信頼性が高い: 3秒未満の応答時間で、Scrapelessはリアルタイムの結果を提供するため、必要なデータに迅速かつ効率的にアクセスできます。これは、ペースの速いビジネス環境にとって不可欠です。
- 使いやすい: Scrapelessは直感的なインターフェースを備えており、技術的な専門知識が限られているチームでも最小限の設定で開始できるため、広範なトレーニングの必要性が軽減されます。
- スケーラブルなデータ収集: 小規模プロジェクトのデータ収集であっても、エンタープライズレベルの分析であっても、Scrapelessはビジネスニーズに合わせてスケールするため、問題なく大量のクエリを処理できます。
- カスタマイズ可能なスクレイピング: Scrapelessを使用すると、特定の製品、地域、またはレビューの種類をターゲットとする場合でも、データ抽出を特定のニーズに合わせて調整できるため、最も関連性の高いインサイトを収集できます。
- 意思決定の強化: Scrapelessは、企業がGoogle製品レビューから貴重なインサイトを得るのに役立ち、顧客感情分析と製品改善の意思決定を支援します。これは、競争力を維持しようとする企業にとって特に重要です。
- シームレスな統合: Scrapelessを他のビジネスツールと統合するオプションがあるため、チームは既存のシステム内で収集したデータを直接分析して、迅速にインサイトに基づいて行動することができます。
Discordコミュニティに参加して、TOBのお客様とつながりましょう!
Discordコミュニティに参加して、他のTOBのお客様とネットワークを構築し、インサイトを共有し、戦略について議論しましょう。さらに、パーソナライズされたサポートのために、当社のチームに直接アクセスできます—カスタムソリューション、データテスト、またはガイダンスが必要な場合でも。Scrapelessエクスペリエンスを向上させるこの機会をお見逃しなく!
方法2:PythonとSeleniumを使用したGoogle製品レビューのスクレイピング
前提条件
始める前に、次のものがあることを確認してください。
- Pythonがインストールされている(3.xを推奨)
- Google ChromeとChromeDriver
- 必要なPythonライブラリ:
bash
pip install selenium beautifulsoup4 pandasステップ1:Selenium WebDriverの設定
Seleniumを使用すると、Webの操作を自動化できます。まず、Chrome WebDriverを初期化する必要があります。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
service = Service('path/to/chromedriver') # 正しいパスに更新してください
options = webdriver.ChromeOptions()
options.add_argument('--headless') # ヘッドレスモードで実行
driver = webdriver.Chrome(service=service, options=options)
driver.get('https://www.google.com/shopping/product/1234567890/reviews') # 例のURLステップ2:レビューデータの抽出
BeautifulSoupを使用してページソースを解析し、レビューの詳細を抽出します。
python
from bs4 import BeautifulSoup
def extract_reviews(driver):
soup = BeautifulSoup(driver.page_source, 'html.parser')
reviews = []
for review in soup.find_all('div', class_='sh-dgr__content'):
rating = review.find('div', class_='sh-dgr__rating')
text = review.find('div', class_='sh-dgr__review-text')
if rating and text:
reviews.append({
'rating': rating.text.strip(),
'review': text.text.strip()
})
return reviews
data = extract_reviews(driver)
print(data)ステップ3:ページネーションの自動化
複数のページのレビューがある場合は、ページネーションを自動化する必要があります。
python
def scrape_multiple_pages(driver):
all_reviews = []
while True:
all_reviews.extend(extract_reviews(driver))
try:
next_button = driver.find_element(By.XPATH, '//a[@aria-label="Next page"]')
next_button.click()
time.sleep(2) # 新しいページの読み込みを待機
except:
break
return all_reviews
data = scrape_multiple_pages(driver)
print(f'Total Reviews Scraped: {len(data)}')ステップ4:CSVへのデータの保存
データを収集したら、保存してさらに分析できます。
python
import pandas as pd
df = pd.DataFrame(data)
df.to_csv('google_reviews.csv', index=False)
print('Reviews saved to google_reviews.csv')比較:Google製品レビューのスクレイピングにおけるScrapelessとSelenium + BeautifulSoup
ScrapelessがGoogle製品レビューのスクレイピングに最適な選択肢である理由を示す比較表を以下に示します。
| 項目 | Scrapeless 🚀(推奨) | Selenium + BeautifulSoup ⚙️(従来の方法) |
|---|---|---|
| 使いやすさ | コーディング不要、API呼び出しのみ | Pythonコードの記述とメンテナンスが必要 |
| 反スクレイピング対策 | 組み込みのバイパスメカニズム | Googleによって簡単に検出され、ブロックされる可能性がある |
| 速度 | クラウドベース、高速スクレイピング | ローカルで実行、ページの読み込みが原因で遅い |
| メンテナンスコスト | メンテナンス不要、Scrapelessがサイトの更新を処理 | ページの変更のために頻繁なコード更新が必要 |
| データ品質 | 構造化データ、JSON/CSV出力 | 手動のHTML解析が必要、不整合が発生する可能性がある |
| 複数ページのスクレイピング | ページネーションを自動的に処理 | ページネーションの手動コーディングが必要 |
| 環境設定 | 追加ソフトウェア不要、APIベース | ChromeDriverと複雑な設定が必要 |
まとめ
Scrapeless、Selenium、Scrapyはすべて、Google製品レビューデータのスクレイピングに有効なソリューションですが、それぞれ長所と短所があります。
- Scrapelessは、特に構造化データを迅速に取得する必要があるシナリオでは、最もシンプルで効率的なオプションです。反クロールメカニズムと動的コンテンツの読み込みを自動的に処理できます。
- Seleniumは強力な動的コンテンツ処理機能を提供しますが、パフォーマンスが低く、メンテナンスコストが高く、検出されやすいという欠点があります。
- Scrapyは大規模データクロールに適した効率的なクローラーフレームワークですが、動的コンテンツの処理が困難であり、学習曲線が急峻です。
全体的に、迅速、効率的、かつ安定してGoogle製品レビューデータを取得したい場合は、Scrapelessが最適な選択肢です。スクレイピングプロセスを簡素化するだけでなく、複雑な開発とメンテナンス作業を回避できます。どのツールを使用する場合でも、Googleの利用規約を遵守して、不必要な法的リスクを回避してください。
データスクレイピングを次のレベルに引き上げましょうか?
ビジネスが遅れを取らないようにしましょう!Scrapelessに今日登録し、Google製品レビューを簡単にスクレイピングを始めましょう。簡単なAPI呼び出しだけで、製品開発と顧客エンゲージメントを改善するための貴重なインサイトにアクセスできます。さらに、Scrapelessはレビューに限定されません—さまざまなプラットフォーム全体のデータ収集、競合他社の分析、トレンドの追跡などにも使用できます!
今すぐ参加して20,000件の無料クエリを取得し、Scrapelessが提供するすべての強力な機能を探索しましょう。eコマース、マーケティング、研究のいずれに従事していても、Scrapelessは効率的で、スケーラブルで、カスタマイズ可能なデータ抽出のための最適なツールです。
今すぐサインアップして、ビジネスにもたらす違いを確認しましょう!
さらに詳しい情報
データキャプチャにも関心があるかもしれません。ぜひご相談ください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


