
PythonでGoogle Playストアアプリをスクレイピングする方法
Advanced Data Extraction Specialist
Google Playストアには、アプリ名、開発者情報、評価、ダウンロード数、ユーザーレビューなど、膨大な量のアプリデータが含まれています。このデータは、市場分析、競合調査、アプリストア最適化(ASO)、自動データ監視に不可欠です。例えば、開発者はGoogle Playストアのデータをスクレイピングして、競合のアップデート頻度、トレンドキーワード、ユーザーフィードバックを分析し、製品戦略を最適化することができます。
さらに、市場調査担当者は、Playストアのデータを収集・分析することで、特定のアプリカテゴリの成長トレンドを追跡できます。
しかし、Google Playストアのスクレイピングは、いくつかの課題があるため簡単ではありません。
- 動的コンテンツの読み込み: ほとんどのアプリ情報はJavaScriptを使用してレンダリングされるため、従来のリクエスト+BeautifulSoupメソッドでは完全なデータを抽出することができません。
- 反スクレイピングメカニズム: Googleは異常なアクセスパターンを検出し、CAPTCHA、IP制限、その他の対策を使用してスクレイパーをブロックします。
- 複雑なHTML構造: Google Playストアのページの構造は頻繁に変更されるため、スクレイパーを継続的に更新する必要があります。
この記事では、Requests + BeautifulSoupを含む、いくつかの一般的なPythonベースのスクレイピング手法を分析し、その長所と短所を分析します。最後に、複雑なスクレイピングスクリプトを書かずに、簡単にGoogle Playストアのデータを抽出できる、より効率的で信頼性の高いソリューションであるScrapelessを紹介します。
Google Playストアのスクレイピングの課題を理解する
Google Playストアのスクレイピングは、自動化されたデータ抽出を防ぐいくつかの組み込み保護機能があるため、困難な場合があります。Google Playストアのスクレイピング方法を学ぶ前に、スクレイパーが直面する主な障害を理解することが不可欠です。
1. 動的コンテンツの読み込み
アプリの説明、レビュー、評価など、Google Playストアの多くのセクションは、JavaScriptを使用して動的に読み込まれます。つまり、単純なrequests + BeautifulSoupのアプローチでは機能しません。生のHTMLレスポンスには完全なアプリの詳細が含まれていないためです。代わりに、Google Playスクレイパーは、JavaScriptをレンダリングして完全なデータを抽出する必要があります。そのためには、SeleniumやPuppeteerなどのツールが必要になることがよくあります。
2. 反スクレイピングメカニズム
Google Playストアは、自動化されたリクエストを検出してブロックするいくつかの反スクレイピングメカニズムを実装しています。これらには以下が含まれます。
- CAPTCHA: 同じIPからのリクエストが多すぎると、Google PlayストアはCAPTCHA検証を求めるプロンプトを表示し、スクレイパーの継続を困難にします。
- IPレート制限: Googleは異常なトラフィックパターンを追跡し、リクエストが多すぎるIPアドレスを一時的または永続的にブロックすることがあります。
- ユーザーエージェント検出: ブラウザのユーザーエージェントのような適切なヘッダーなしでリクエストを送信すると、すぐにブロックされる可能性があります。
Google Playストアのスクレイパーは、これらの制限を回避するために、ローテーションプロキシ、CAPTCHA解決技術、現実的なブラウザヘッダーを使用する必要があります。
3. HTML構造の継続的な変更
Googleは、Playストアページのレイアウトと構造を頻繁に更新します。これは、今日構築されたGoogle Playスクレイパーは、定期的に更新されない限り、数ヶ月後に機能しなくなる可能性があることを意味します。これは、Webスクレイピングに依存するデータ抽出を行う開発者にとってよくある課題です。
4. APIの制限
Googleは、Google Playストアのデータをスクレイピングするための無料の公式APIを提供していません。サードパーティのAPIがいくつか存在しますが、多くの場合、レート制限があり、サブスクリプションが必要であるか、データ抽出の柔軟性に欠けています。
方法1: RequestsとBeautifulSoupを使用してGoogle Playストアをスクレイピングする
Google Playストアをスクレイピングする最も簡単な方法の1つは、Pythonのrequestsライブラリを使用してHTMLを取得し、BeautifulSoupを使用してページを解析することです。この方法は簡単ですが、以下で説明するいくつかの制限があります。
注: ウェブサイトのプライバシーを厳重に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモとしてのみ使用されます。いかなる情報やデータも保存しません。
RequestsとBeautifulSoupを使用してGoogle Playストアをスクレイピングする方法
requestsとBeautifulSoupを使用してGoogle Playストアからアプリの詳細を抽出する方法の簡単な例を以下に示します。
import requests
from bs4 import BeautifulSoup
# アプリページのURLを定義します
app_url = "https://play.google.com/store/apps/details?id=com.whatsapp"
# 実際のブラウザリクエストを模倣するヘッダーを設定します
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# リクエストを送信します
response = requests.get(app_url, headers=headers)
# リクエストが成功したかどうかを確認します
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# アプリ名を取得します
app_name = soup.find("h1", class_="Fd93Bb F5UCq").text if soup.find("h1", class_="Fd93Bb F5UCq") else "Not Found"
# アプリの説明を取得します
app_description = soup.find("div", class_="bARER").text if soup.find("div", class_="bARER") else "Not Found"
print(f"アプリ名: {app_name}")
print(f"説明: {app_description}")
else:
print(f"ページの取得に失敗しました、ステータスコード: {response.status_code}")いくつかのクロール結果を以下に示します。
説明: MetaのWhatsAppは、無料のメッセージングおよびビデオ通話アプリです。180カ国以上で20億人以上が使用しています。シンプルで信頼性があり、プライバシーも保護されているため、友人や家族と簡単に連絡を取り合うことができます。WhatsAppは、低速な接続でも、モバイルとデスクトップで動作し、サブスクリプション料金はかかりません*。世界中でのプライベートメッセージング友人や家族への個人メッセージと通話は、エンドツーエンドで暗号化されています。チャットの外にいる誰も、WhatsAppでさえ、それらを読み取ったり聞いたりすることはできません。シンプルで安全な接続をすぐにすべての必要なのは電話番号だけです。ユーザー名やログインは必要ありません。WhatsAppを使用している連絡先をすばやく表示し、メッセージングを開始できます。高品質の音声通話とビデオ通話最大8人まで無料*で安全なビデオ通話と音声通話を行うことができます。通話は、低速な接続でも、電話のインターネットサービスを使用してモバイルデバイス間で機能します。あなたを繋ぎ止めておくグループチャット
.....RequestsとBeautifulSoupを使用してGoogle Playストアをスクレイピングすることの制限
requestsとBeautifulSoupはGoogle Playストアをスクレイピングする簡単な方法を提供しますが、このアプローチにはいくつかの欠点があります。
❌ 動的コンテンツを処理できない
- Google Playストアは、レビューや評価など、多くの要素をJavaScriptを介して動的に読み込みます。requestsは生のHTMLのみを取得するため、動的に読み込まれたデータは欠落します。
- 多くのアプリの詳細(開発者情報やユーザーレビューなど)には、JavaScriptの実行が必要です。requestsはそれを処理できません。
❌ Googleによって簡単にブロックされる
- Google Playには、異常なトラフィックパターンを検出する厳格な反スクレイピングメカニズムがあります。同じIPから複数回リクエストを行うと、Googleはアクセスをブロックしたり、CAPTCHAを表示したりすることがあります。
- 静的なヘッダーを使用すると一時的に役立つ場合がありますが、最終的にはスクレイパーがフラグ付けされます。
❌ 使用事例が限られている
- このメソッドはJavaScriptをレンダリングできないため、JavaScriptの実行が必要ない静的コンテンツのスクレイピングにのみ役立ちます。
- ユーザーレビュー、更新履歴、アプリのスクリーンショットなどの詳細情報が必要な場合、このアプローチでは機能しません。
いつRequestsとBeautifulSoupをGoogle Playストアのスクレイピングに使用するか?
その制限にもかかわらず、この方法は、JavaScriptの実行が必要ない小規模なスクレイピングタスク(例:アプリ名と基本的な説明の抽出、アプリパッケージIDの取得、カテゴリ、ランキング、静的メタデータのスクレイピングなど)に役立ちます。
方法2: Scrapelessを使用してGoogle Playストアをスクレイピングする(B2Bニーズに最適なパフォーマンス)
市場情報、広告追跡、競合調査のためにGoogle Playストアのスクレイパーソリューションに依存する企業にとって、SeleniumやScrapyなどの従来のWebスクレイピング方法は、遅く、信頼性が低く、高いメンテナンスが必要になる可能性があります。一方、Scrapelessは、インフラストラクチャの管理やGoogleの反スクレイピング保護に対処することなく、効率的にGoogle PlayストアをスクレイピングするためのスケーラブルなAPIベースのソリューションを提供します。
ScrapelessがB2B Google Playスクレイピングに最適な理由
🚀 スクレイピングの課題を排除 – Scrapelessは、完全に管理されたGoogle Playスクレイパーを提供し、プロキシやブラウザの自動化を必要とせずにGoogleの反スクレイピングメカニズムをバイパスします。
💰 運用コストの削減 – 独自のGoogle Playストアスクレイパーを維持するには、継続的な更新、プロキシのローテーション、CAPTCHAの処理が必要です。Scrapelessはこれらのコストを削減し、1000リクエストあたり0.1ドルという低価格のAPI価格設定により、B2Bデータニーズにとって費用対効果の高い選択肢となります。
📊 実行可能な構造化データ – APIはクリーンで構造化されたJSONデータを提供するため、企業はデータの解析やクレンジングの手間をかけることなく、アプリのトレンドの監視、競合の追跡、機械学習モデルの構築を容易に行うことができます。
ScrapelessをGoogle Playストアスクレイパーとして使用する方法(Python API例)
大規模なGoogle Playスクレイピングを必要とするB2B企業の場合、ScrapelessをPythonで使用してアプリデータを取得する方法を以下に示します。
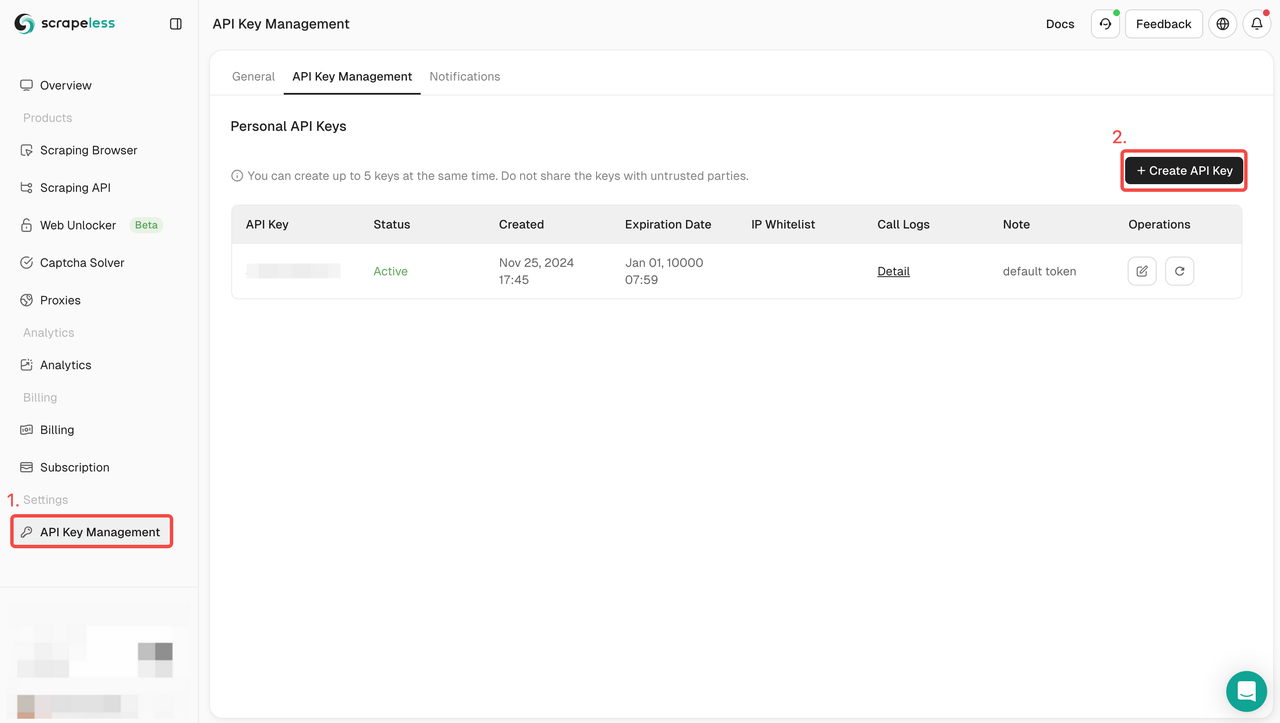
ステップ1: Google PlayストアAPIトークンを作成する
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 作成したら、APIキーをクリックしてコピーします。
Scrapelessの価格は、無料トライアルを利用して効率的なGoogle Playストアデータスクレイピングサービスを体験できる、リクエスト1000回あたりわずか0.1ドルです。
ステップ2: Scrapeless APIを統合するPythonスクリプトを作成する
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"apps_category": "BEAUTY",
}
payload = Payload("scraper.google.play", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("エラー:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()詳細なパラメータ情報については、Scrapelessの**公式APIドキュメント**を参照してください。
また、「your_token」をScrapeless APIキーに置き換えてください。
ScrapelessをGoogle Playストアスクレイパーとして使用する主なビジネスユースケース
-
競合インテリジェンス – 競合アプリの更新、価格変更、顧客感情分析を監視します。
-
市場調査とトレンド分析 – より深い業界の洞察を得るために、履歴データとリアルタイムのアプリデータを取得します。
-
広告インテリジェンスとASO最適化 – より効果的なマーケティング戦略のために、キーワードのトレンド、アプリのランキング、開発者の活動を追跡します。
-
エンタープライズシステムとのデータ統合 – Scrapeless APIを内部分析、CRM、または自動化プラットフォームに簡単に接続します。
なぜ従来のGoogle Playスクレイピング方法よりもScrapelessを選択するのか?
| 方法 | 速度 | 反スクレイピングをバイパス | JavaScriptを処理 | メンテナンスが必要 | 最適な用途 |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | ⚡⚡ | ❌ いいえ | ❌ いいえ | ✅ はい | 小規模なスクレイピング |
| Selenium | ⚡ | ❌ いいえ | ✅ はい | ✅ はい | JavaScriptを多用するページ |
| Scrapeless | ⚡⚡⚡⚡ | ✅ はい | ✅ はい | ❌ いいえ | 大規模なB2Bデータ抽出 |
従来のGoogle Playストアスクレイパー設定とは異なり、Scrapelessは完全に管理されたスケーラブルなソリューションを提供するため、信頼性が高く、構造化され、費用対効果の高いデータ抽出を必要とする企業にとって最適な選択肢です。
**Scrapelessを無料で試す**して、APIがGoogle Playストアのスクレイピングプロセスをどのように簡素化できるかを確認してください。こちらから無料トライアルを開始してください。
Discordコミュニティに参加して、サポートを受け、洞察を共有し、最新の機能を最新の状態に保ちましょう。こちらをクリックして参加してください!
Google Playストアのスクレイピングに関するFAQ
Q1: Google Playストアの反スクレイピングメカニズムを処理するにはどうすればよいですか?
Google Playストアには、CAPTCHAやIPブロックなどの厳格な反スクレイピング対策があります。ローテーションプロキシ、ヘッドレスブラウザ、またはScrapelessのような特殊なGoogle Playスクレイパーを使用すると、これらの制限を回避できます。
Q2: 大規模なスクレイピングにScrapyやSeleniumを使用できますか?
ScrapyとSeleniumはGoogle Playストアをスクレイピングできますが、IPブロックのリスクが高く、パフォーマンスが遅いことから、大規模なスクレイピングには適していません。ScrapelessのようなクラウドベースのGoogle Playストアスクレイパーは、より高い効率を提供します。
Q3: Google Playストアをスクレイピングするための最良のツールは何ですか?
最良の選択肢は、ニーズによって異なります。スケーラブルで手間のかからないソリューションが必要な場合は、Scrapelessは高速で信頼性の高いデータ抽出を行う強力なGoogle Playスクレイパーです。
まとめ
この記事では、Google Playストアをスクレイピングするいくつかの方法を調査しました。それぞれに長所と短所があります。Requests + BS4はシンプルで小規模なスクレイピングには適していますが、動的コンテンツを扱う際には制限があります。Scrapelessは大規模なエンタープライズレベルのデータ収集に最適なパフォーマンスを提供します。複雑なスクレイパーを維持する必要がなくなり、従来の方法よりも高速で、費用対効果の高い価格モデルを提供します。
時間と開発コストを節約し、高品質なデータを取得したい企業にとって、Scrapelessは最適なソリューションです。Scrapelessを無料で試すことをお勧めします。APIがGoogle Playストアのスクレイピングプロセスをどのように合理化できるかを体験してください。こちらをクリックして無料トライアルを開始してください!
その他のリソース
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


