
Scrapelessを使って、Google Jobsから簡単に求人リストを作成する
Advanced Data Extraction Specialist
適切な求人データを迅速に見つけることは困難な課題となる可能性がありますが、適切なツールを使用すれば、容易になります。Google求人から求人情報をスクレイピングすることで、企業、求人サイト、開発者は正確で最新の求人情報を収集できます。このプロセスを自動化することで、包括的な求人リストを簡単に作成し、場所や職種で絞り込み、このデータをプラットフォームに統合できます。この記事では、Google求人を効率的にスクレイピングし、関連性があり正確な求人リストを作成する方法を紹介します。
Google求人とは?
Google求人は、Googleが提供する専門的な求人検索エンジンであり、求人サイト、企業ウェブサイト、人材派遣会社など、さまざまなソースからの求人情報を集約しています。2017年に開始されたGoogle求人は、ユーザーがさまざまな業界や場所で求人機会を発見するためのワンストッププラットフォームを提供することにより、求人検索プロセスを簡素化することを目的としています。
なぜGoogle求人をスクレイピングするのか?
Google求人のスクレイピングは、企業、求職者、求人サイトのすべてにいくつかの利点を提供します。Google求人データのスクレイピングを検討すべき主な理由をいくつかご紹介します。
1. 包括的な求人情報
Google求人は、複数の信頼できるソースから求人情報を集約しているため、求人データのワンストップショップとなっています。
2. カスタマイズ可能な検索
場所、職種、給与範囲などの特定の基準に基づいて求人結果を絞り込むことができ、対象者にとって適切な結果を得ることができます。
3. 時間を節約する自動化
Google求人のスクレイピングを自動化することで、ウェブサイトやアプリに常に最新の求人情報が表示されるようにし、手動での更新の必要性を排除できます。
4. 競争優位性
求人サイトや採用ウェブサイトを運営している場合、Google求人データにアクセスすることで、求職者を惹きつける包括的な求人情報を提供し、競争優位性を確保できます。
Pythonを使用してGoogle求人をスクレイピングし、求人リストを簡単に作成する
適切な仕事を見つけることは大変な作業となる可能性がありますが、Scrapelessを使用すると、Google求人から求人情報を迅速かつ効率的に収集し、独自のツールに統合できます。この記事では、Scrapeless APIを使用して求人データをスクレイピングし、独自の求人リストを作成する方法を説明します。
Scrapelessは、強力で使いやすいウェブスクレイピングツールであり、自分でスクレイピングの複雑さを処理することなく、Google求人を含むさまざまなソースから構造化されたデータを収集できます。

Scrapelessの利点
-
**正確で包括的なデータ:**職種、企業名、勤務地、給与範囲、職務内容など、重要なコンテンツを含む正確な求人情報を提供します。
-
**複数のパラメーターのカスタマイズに対応:**職種(フルタイム、パートタイムなど)、経験要件、業界分野など、10個以上カスタマイズされたパラメーターを使用して、ターゲットの求人データを正確に絞り込むことができます。
-
**複数地域に対応:**グローバルなビジネス拡大のニーズを満たすために、さまざまな国と地域でGoogle求人検索結果を取得できます。
-
**フォーマットの指定:**標準化されたJSON形式で出力データを提供するため、開発者はさまざまなシステムやプログラムで簡単に統合および処理できます。
-
**統合が容易:**シンプルなAPIインターフェースを提供するため、開発者は一般的なプログラミング言語(Python、Javaなど)を使用して簡単に呼び出しと統合ができます。
-
**リアルタイム更新:**取得した求人データがリアルタイムであり、最新の採用情報をタイムリーに反映するようにします。
今すぐ登録して、2ドル分の無料クレジットを受け取り、すべての強力な機能を試してみてください。見逃さないでください
ステップ1:Google求人データクロール環境を構築する
まず、データクロール環境を構築し、次のツールを用意する必要があります。
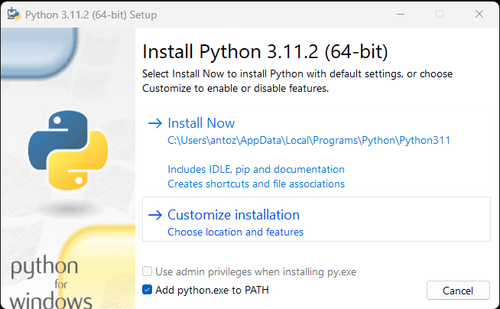
1. Python:こちらはPythonを実行するためのコアソフトウェアです。以下の図のように公式ウェブサイトのリンクから必要なバージョンをダウンロードできますが、最新バージョンをダウンロードしないことをお勧めします。最新バージョンより1〜2バージョン前のバージョンをダウンロードできます。
**2. Python IDE:**PythonをサポートするIDEであればどれでも構いませんが、Python用に特別に設計されたIDE開発ツールソフトウェアであるPyCharmをお勧めします。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
**3. Pip:**Python Package Indexを使用して、プログラムの実行に必要なライブラリを1つのコマンドでインストールできます。
**注記:**Windowsユーザーの場合は、インストールウィザードで「Add python.exe to PATH」オプションを選択することを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
上記のステップにより、Google求人データのクロール環境が設定されます。次に、ダウンロードしたPyCharmとScraperlessを組み合わせてGoogle求人データをクロールできます。
ステップ2:PyCharmとScrapelessを使用してGoogle求人データを取得する
- PyCharmを起動し、メニューバーから[ファイル]>[新規プロジェクト]を選択します。
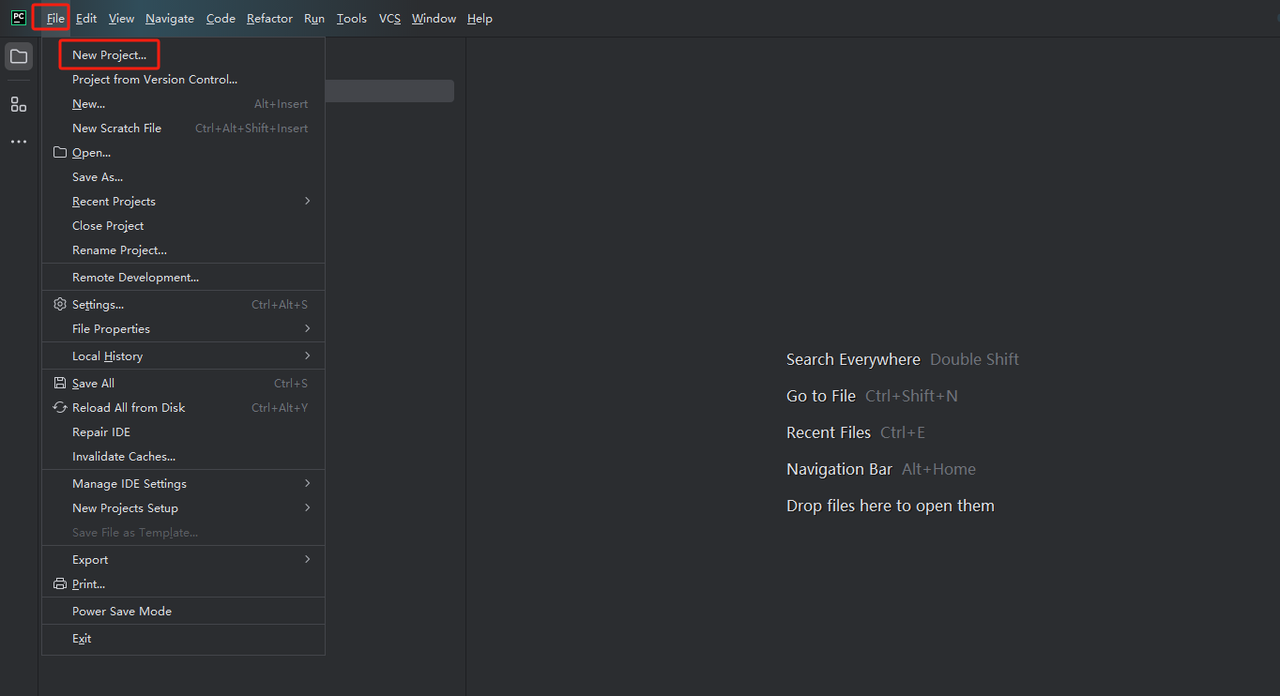
- 次に、表示されるウィンドウで、左側のメニューから[Pure Python]を選択し、プロジェクトを次のように設定します。
**注記:**下の赤いボックスで、環境設定の最初のステップでダウンロードしたPythonのインストールパスを選択します。
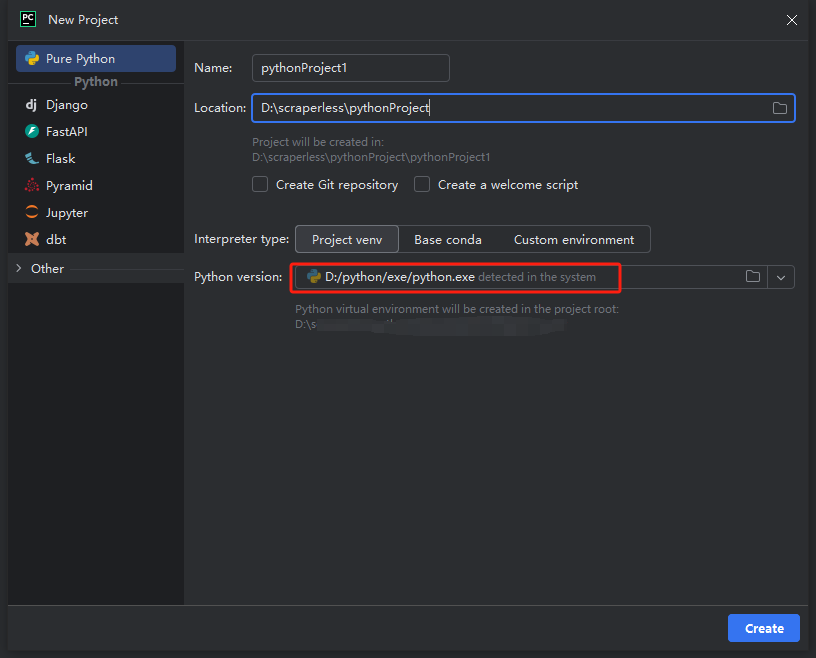
python-scraperというプロジェクトを作成し、「フォルダー内の「Create main.py welcome script」オプションを選択して「作成」ボタンをクリックします。PyCharmがしばらくプロジェクトを設定した後、次のようになります。
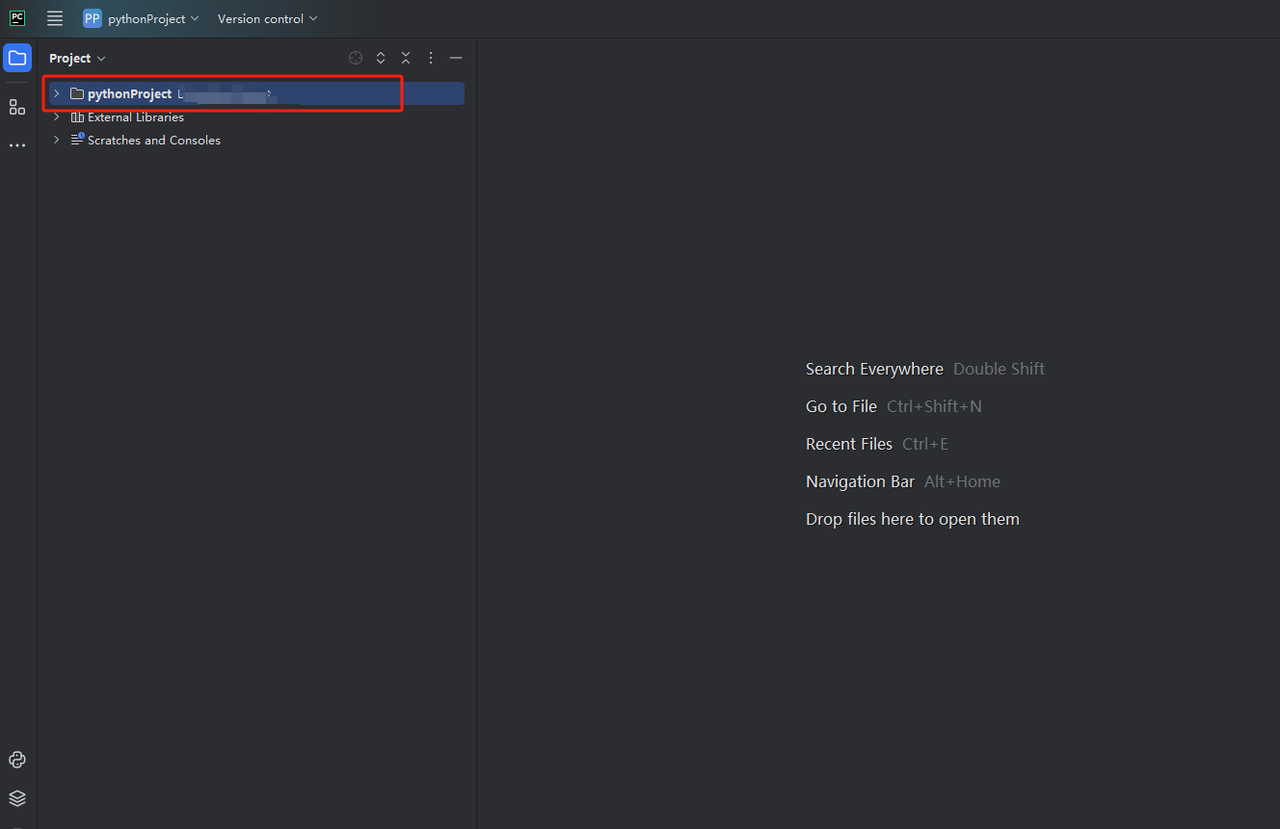
- 次に、右クリックして新しいPythonファイルを作成します。
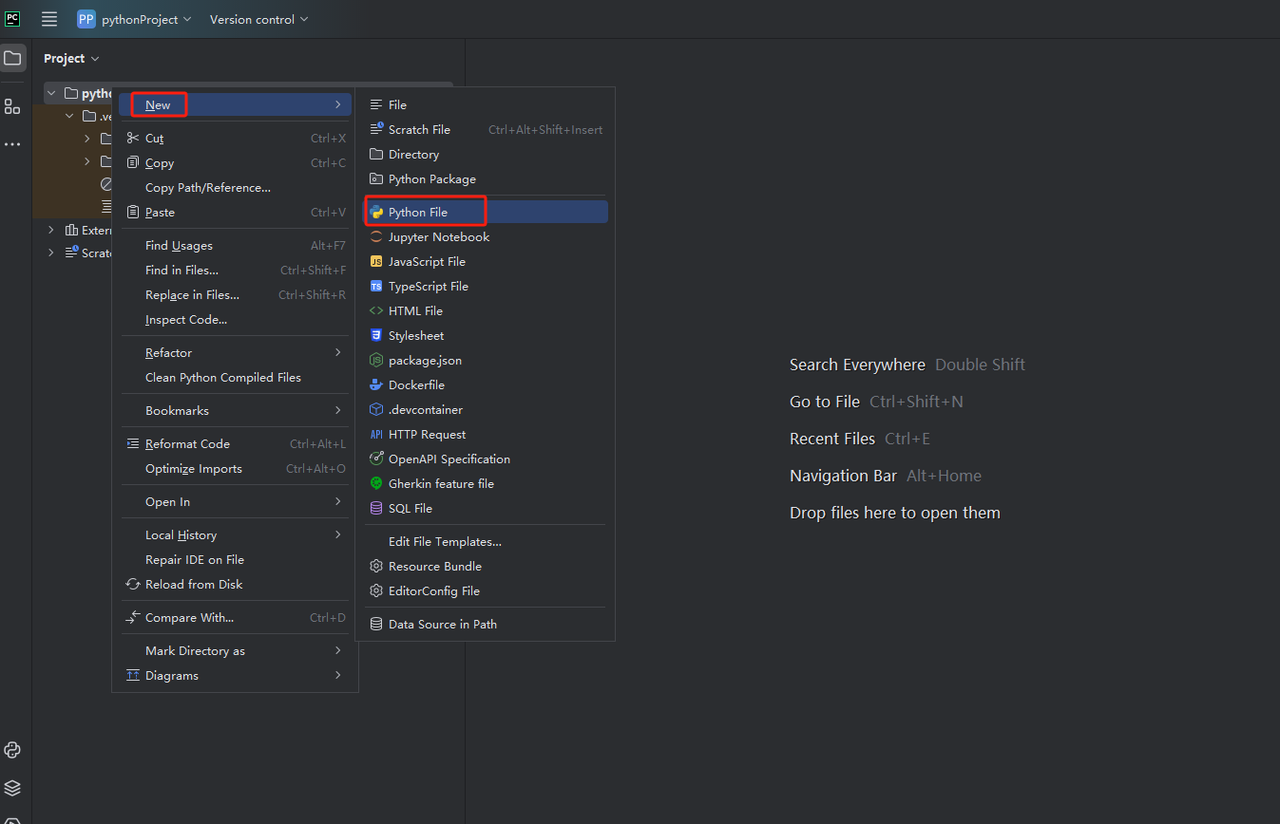
- すべてが正しく機能していることを確認するには、画面下部の[ターミナル]タブを開き、「python main.py」と入力します。このコマンドを実行すると、「Hi, PyCharm.」が表示されます。
ステップ3:Scrapeless APIキーを取得する
これで、ScrapelessのコードをPyCharmに直接コピーして実行できるようになり、Google求人のJSON形式のデータを取得できます。ただし、最初にScrapeless APIキーを取得する必要があります。手順は次のとおりです。
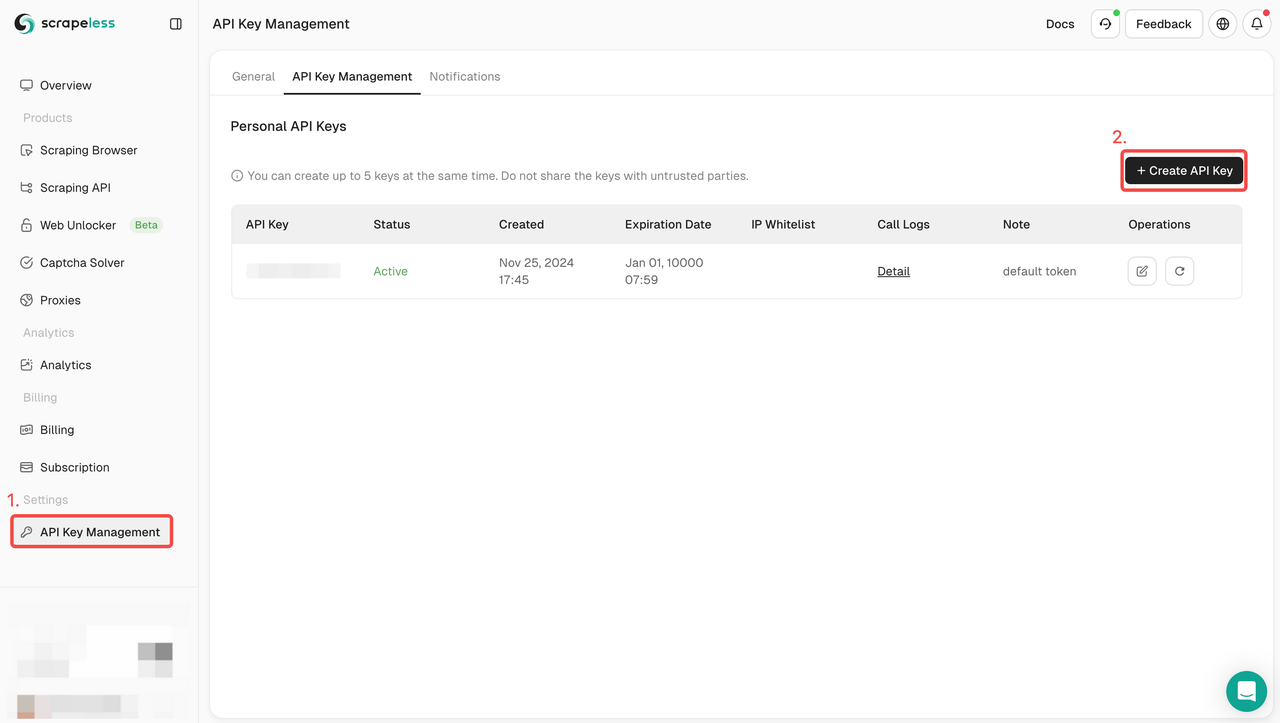
- まだアカウントを持っていない場合は、Scrapelessに登録してください。登録後、ダッシュボードにログインします。
- Scrapelessダッシュボードで、APIキー管理に移動し、APIキーの作成をクリックします。APIキーを取得します。マウスをキーの上に置き、クリックしてコピーします。このキーは、Scrapeless APIを呼び出すときの要求の認証に使用されます。
ステップ4:Scrapeless APIパラメーターを理解する
Scrapeless APIは、取得するデータをフィルタリングおよび絞り込むために使用できるさまざまなパラメーターを提供します。Google求人情報のスクレイピングのための主なAPIパラメーターを次に示します。
| パラメーター | 必須 | 説明 |
|---|---|---|
| engine | TRUE | Google求人APIエンジンを使用するには、パラメーターをgoogle_jobsに設定します。 |
| q | TRUE | パラメーターは、検索するクエリを定義します。 |
| uule | FALSE | パラメーターは、検索に使用するGoogleエンコードされた場所です。uuleパラメーターとlocationパラメーターを同時に使用することはできません。 |
| google_domain | FALSE | パラメーターは、使用するGoogleドメインを定義します。デフォルトはgoogle.comです。サポートされているGoogleドメインの完全なリストについては、Googleドメインページを参照してください。 |
| gl | FALSE | パラメーターは、Google検索に使用する国を定義します。2文字の国コードです(例:米国はus、英国はuk、フランスはfr)。サポートされているGoogle国の完全なリストについては、Google国ページを参照してください。 |
| hl | FALSE | パラメーターは、Google求人検索に使用する言語を定義します。2文字の言語コードです(例:英語はen、スペイン語はes、フランス語はfr)。サポートされているGoogle言語の完全なリストについては、Google言語ページを参照してください。 |
| next_page_token | FALSE | パラメーターは次のページトークンを定義します。結果の次のページを取得するために使用されます。ページごとに最大10件の結果が返されます。次のページトークンは、SerpApi JSONレスポンスのpagination -> next_page_tokenにあります。 |
| lrad | TRUE | キロメートル単位の検索半径を定義します。半径を厳密に制限するわけではありません。 |
| ltype | TRUE | パラメーターは、在宅勤務による結果を絞り込みます。 |
| uds | TRUE | パラメーターは検索の絞り込みを有効にします。Googleがフィルターとして提供する文字列です。uds値は、「udsを使用したフィルター」、「q」、各フィルターに提供される「link」値のセクションの下に提供されます。 |
ステップ5:スクレイピングツールにScrapeless APIを統合する方法
APIキーを取得したら、独自のスクレイピングツールにScrapeless APIを統合できます。Pythonとrequestsを使用してScrapeless APIを呼び出してデータを取得する方法の例を次に示します。
Scrapeless APIを使用してGoogle求人情報をクロールするためのサンプルコード:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_jobs",
"q": "barista new york",
}
payload = Payload("scraper.google.jobs", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()ステップ6:結果データを分析する
Scrapeless APIの結果データには、JSON形式で詳細な情報が含まれています。以下は、結果データの一部の例です。具体的な情報は、APIドキュメントで確認できます。
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 結果の主要なフィールド:
- title:職種。
- company:求人を提供している企業
- link:求人情報のリンク
- location:求人の場所
- date_posted:求人が投稿された日付
このデータを使用して、求人サイトを作成したり、通知を送信したり、既存のウェブサイトやアプリケーションに求人データを統合したりできます。
求人情報を簡単に収集する方法をお探しですか?
今日からScrapelessのGoogle求人APIを使用してください!正確でリアルタイムの求人データを簡単に取得し、求人検索プロセスを効率化します。今すぐお試しくださいそして違いを見てください!
採用と労働市場分析のためのその他の一般的なデータソースについて探る
Google求人の他に、多くのプラットフォームが貴重な採用データと業界トレンドを提供しており、より広範な採用データ分析に適しています。たとえば、Crunchbase、Indeed、LinkedInは、採用と人材市場分析のための重要なデータソースです。
- Crunchbaseは、スタートアップ、企業の資金調達、業界トレンドなどの詳細な情報を提供しており、企業の採用ニーズと市場トレンドを調査するのに非常に役立ちます。
- Indeedは、世界最大の採用プラットフォームの1つであり、豊富な求人情報、給与データ、業界トレンドを備えており、求人分析、給与予測、人材市場調査に適しています。
- LinkedInは、グローバルなプロフェッショナルソーシャルネットワークと採用データを提供しており、人材の流れ、スキル要件、仕事の開発トレンドを分析するのに役立ちます。
ビジネスがGoogle求人のクロールに限定されない場合は、Scrapelessなどのツールを使用してこれらのプラットフォームから採用データを取得し、採用分析と市場調査をさらに充実させることも検討できます。
同様のクロールニーズがある場合、またはScrapelessツールを使用してCrunchbase、Indeed、LinkedInなどのプラットフォームからデータをクロールする方法を学習したい場合は、お問い合わせください。データのクロールと分析を効率的に完了できるように、カスタマイズされたソリューションを提供します。
Scrapeless Deep SerpApi:強力なGoogle SERP APIツール
Deep SerpApiは、大規模言語モデル(LLM)とAIエージェント用に特別に設計された専門的な検索エンジンAPIです。リアルタイムで正確かつ公平な情報を提供し、AIアプリケーションがGoogleなどのデータを取得して処理する効率を高めます。
✅ 包括的なデータカバレッジインターフェース:20以上のGoogle SERPシナリオと主要な検索エンジンに対応しています。
✅ 費用対効果が高い:Deep SerpApiは、1000件のクエリあたり0.10ドルからの価格を提供し、応答時間は1〜2秒です。開発者と企業は、効率的かつ低コストでデータを取得できます。
✅ 高度なデータ統合機能:利用可能なすべてのオンラインチャネルと検索エンジンからの情報を統合できます。
✅ 過去24時間以内に更新されたデータでリアルタイムの更新を取得します。
今後のロードマップの一環として、動的なウェブ情報をAI駆動型のソリューションにシームレスに統合することで、AI開発者のニーズに応えることに全力を注いでいます。目標は、1回の呼び出しでシームレスな検索とデータ抽出を可能にするオールインワンAPIを提供することです。
🎺🎺お知らせ!
開発者サポートプログラム: Scrapeless Deep SerpApiをAIツール、アプリケーション、またはプロジェクトに統合します。[すでにDifyをサポートしており、Langchain、Langflow、FlowiseAIなどのフレームワークもまもなくサポートします]。その後、結果をGitHubまたはソーシャルメディアで共有すると、最大月額500ドルの1〜12か月間の無料開発者サポートを受けられます。
FAQ
Q1:ScrapelessのAPIキーを取得するにはどうすればよいですか?
scrapeless.comでサインアップし、ダッシュボードにログインして、APIキー管理セクションでAPIキーを生成します。
Q2:他のウェブサイトから求人をスクレイピングできますか?
はい、Scrapelessはさまざまな求人サイトやその他の多くの種類のデータのスクレイピングをサポートしています。Google求人APIはその一例です。
Q3:Google求人を無料でスクレイピングできますか?
Scrapelessは、限定的な無料トライアルを提供しています。続行するには、有料プランが必要です。有料プランでは、より高い制限と高度な機能にアクセスできます。
Q4:Scrapelessは他に何を提供していますか?
Google求人の他に、ScrapelessはGoogleマップ、Googleフライト、Googleトレンドなど、多くの種類のデータのスクレイピングができます。
まとめ
Scrapeless APIを使用したGoogle求人のスクレイピングは、独自のプロジェクトのために求人情報を収集する強力で簡単な方法です。わずか数行のコードで、Scrapelessをスクレイパーに統合し、求人データの抽出プロセスを自動化できます。
Scrapelessの機能を活用することで、Googleの求人検索エンジンから求人リストを迅速に作成し、時間を節約して、求人サイトまたはアプリケーションの構築に集中できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


