
Node.jsでGoogleホテルの価格をスクレイピングする方法
Advanced Data Extraction Specialist
季節の変化、需要の変動、プロモーション活動などにより、ホテルの価格は頻繁に変化します。これらの変化を手動で追跡することはほぼ不可能です。代わりに、旅行ウェブサイトやプラットフォームをスクレイピングすることでこのプロセスを自動化すると、時間と労力を節約できます。
この記事では、最大手の集約サイトの1つであるGoogleからホテルの価格をスクレイピングする方法をご紹介します。Googleのホテルデータをスクレイピングすることで、分析、価格比較、ダイナミックプライシング戦略のために、ホテルの価格、評価、アメニティに関する広範な情報を迅速に収集できます。
なぜGoogleホテルの価格をスクレイピングするのか?
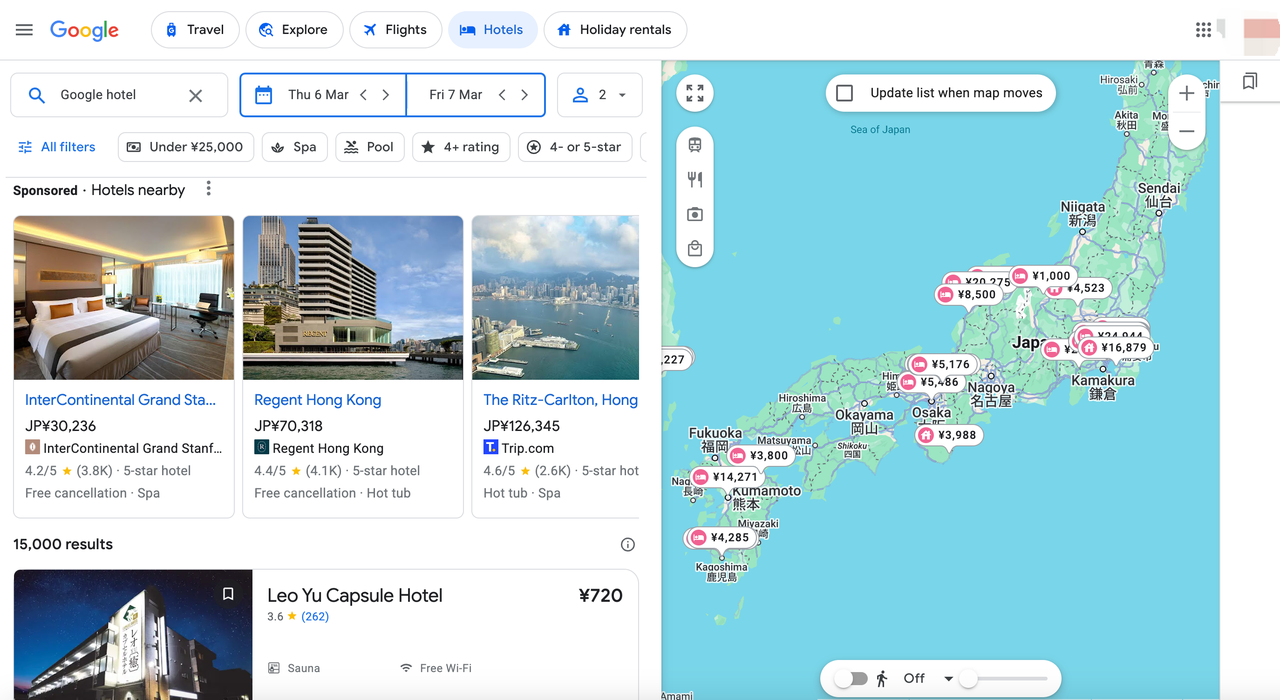
ホテル関連のキーワードを検索すると、Googleは、数千ものホテルの名前、画像、住所、評価、価格を含む専用のホテルセクションを生成します。これは、Googleが数百万もの旅行およびホテルのウェブサイトからの情報を1か所に集約しているためです。
旅行者、企業、アナリストは、さまざまな目的でこのデータを使用できます。
- 価格比較:さまざまな予約プラットフォームや旅行ウェブサイトで価格を比較し、最良の取引を見つけることができます。
- データ分析:アナリストはホテルの価格データを使用して、価格動向、季節変動、競争機会を明らかにすることができます。
- ダイナミックプライシング戦略:企業は、需要、空室状況、競合他社の価格に基づいて価格を調整することで、収益と稼働率を最適化できます。
- カスタムアラート:価格の低下を監視して、顧客に警告したり、個人的な使用のために使用したりできます。
- 旅行集約サービス:さまざまなソースからのホテルの価格と選択肢を統合したビューをユーザーに提供します。
- 予算と計画:旅行者は宿泊費を予測し、それに応じて計画を調整できます。
要するに、このデータの用途は広範ですが、洞察を得る前に、それを収集する必要があります。
Node.jsを使用したGoogleホテル価格のスクレイピング方法
このチュートリアルでは、ニューヨークのホテルに焦点を当て、ホテルの価格データを収集して、最も安いホテルから最も高いホテルまでホテルリストをソートするスクリプトを作成します。
1. 前提条件
このチュートリアルに従うには、コンピューターに次のツールがインストールされている必要があります。
- Node.js 18+とNPM
- JavaScriptとNode.js APIの基本的な知識
2. プロジェクトの設定
プロジェクトフォルダーを作成します。
mkdir google-hotel-scraper次に、次のコマンドを実行してNode.jsプロジェクトを初期化します。
cd google-hotel-scraper
npm init -yこのコマンドにより、フォルダーにpackage.jsonファイルが作成されます。index.jsファイルを作成し、単純なJavaScriptステートメントを追加します。
touch index.js
echo "console.log('Hello world!');" > index.jsNode.jsランタイムを使用してindex.jsファイルを実行します。
node index.jsターミナルに「Hello world!」と表示された場合、プロジェクトは正常に実行されています。
3. 必要な依存関係のインストール
スクレイパーを作成するには、2つのNode.jsパッケージが必要です。
- Puppeteer:Googleホテルページを読み込み、HTMLコンテンツをダウンロードします。
- Cheerio:PuppeteerによってダウンロードされたHTMLからホテル情報を抽出します。
次のコマンドを使用してこれらのパッケージをインストールします。
npm install puppeteer cheerio4. Googleホテルページからスクレイピングする情報の特定
ウェブページから情報を抽出するには、最初に目的のHTML要素をターゲットにするDOMセレクターを特定する必要があります。
関連データの各部分のDOMセレクターの表を次に示します。
| 情報 | DOMセレクター | 説明 |
|---|---|---|
| ホテルコンテナ | .uaTTDe |
結果リスト内の単一のホテルアイテム |
| ホテル名 | .QT7m7 > h2 |
ホテルの名前 |
| ホテル価格 | .kixHKb > span |
1泊あたりの部屋の価格 |
| ホテルの星の数 | .HlxIlc .UqrZme |
星の数 |
| ホテルの評価 | .oz2bpb > span |
ホテルの顧客レビュー |
| ホテルのオプション | .HlxIlc .XX3dkb |
提供される追加サービス |
| ホテルの写真 | .EyfHd .x7VXS |
ホテルの写真 |
5. Googleホテルページのスクレイピング
DOMセレクターを特定したので、Puppeteerを使用してページのHTMLをダウンロードしましょう。ターゲットとする最初のページは、https://www.google.com/travel/searchです。
一部の国(主にヨーロッパ)では、URLにリダイレクトする前に同意ページが表示されます。「すべて拒否」ボタンをクリックし、3秒待って、Googleホテルページが完全に読み込まれていることを確認するコードを追加します。
次のコードを使用してindex.jsファイルを更新します。
const puppeteer = require('puppeteer');
const PAGE_URL = 'https://www.google.com/travel/search';
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(PAGE_URL);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
const html = await page.content();
await browser.close();
console.log(html);
}
void main();node index.jsを使用してコードを実行します。ターミナルには、ページのHTMLコンテンツが出力されます。
6. HTMLからの情報の抽出
ページのHTMLを取得しましたが、生のHTMLから直接貴重なデータを取り出すことは困難です。これが、Cheerioの出番です。
次のコードはHTMLを読み込み、各ホテルの部屋の価格を抽出します。
const cheerio = require("cheerio");
const $ = cheerio.load(html);
$('.uaTTDe').each((i, el) => {
const priceElement = $(el).find('.kixHKb span').first();
console.log(priceElement.text());
});Cheerioを使用してコンテンツを抽出し、配列に格納し、価格が低い順にソートするようにindex.jsファイルを更新します。
const cheerio = require("cheerio");
const puppeteer = require("puppeteer");
const { sanitize } = require("./utils");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const GOOGLE_HOTEL_PRICE = 'https://www.google.com/travel/search';
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(GOOGLE_HOTEL_PRICE);
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(3000);
const html = await page.content();
await browser.close();
const hotelsList = [];
const $ = cheerio.load(html);
$('.uaTTDe').each((i, el) => {
const titleElement = $(el).find('.QT7m7 > h2');
const priceElement = $(el).find('.kixHKb span').first();
const reviewsElement = $(el).find('.oz2bpb > span');
const hotelStandingElement = $(el).find('.HlxIlc .UqrZme');
const options = [];
const pictureURLs = [];
$(el).find('.HlxIlc .XX3dkb').each((i, element) => {
options.push($(element).find('span').last().text());
});
$(el).find('.EyfHd .x7VXS').each((i, element) => {
pictureURLs.push($(element).attr('src'));
});
const hotelInfo = sanitize({
title: titleElement.text(),
price: priceElement.text(),
standing: hotelStandingElement.text(),
averageReview: reviewsElement.eq(0).text(),
reviewsCount: reviewsElement.eq(1).text(),
options,
pictures: pictureURLs,
});
hotelsList.push(hotelInfo);
});
const sortedHotelsList = hotelsList.slice().sort((hotelOne, hotelTwo) => {
if (!hotelTwo.price) {
return 1;
}
return hotelOne.price - hotelTwo.price;
});
console.log(sortedHotelsList);
}
void main();コードを実行して結果を確認してください。これで、すべてのホテルに関する情報を収集できました。
以前の内容では、Node.jsとPuppeteerを使用してGoogleホテル価格のクロールを実装しました。この方法は基本的なニーズを満たすことができますが、多くのコードを記述する必要があり、複雑な反クローラーメカニズムに対処する場合には多くの課題に遭遇する可能性があります。
タスクをより効率的に完了するために、より簡単な方法をお勧めします。Scrapeless Deep SerpAPIを使用します。
Scrapeless Deep SerpApiを使用してGoogleホテル情報をクロールする
Deep SerpApiは、大規模言語モデル(LLM)およびAIエージェント向けに設計された専用の検索エンジンであり、AIアプリケーションが効率的にデータを取得および処理できるように、リアルタイムで正確かつ公平な情報を提供することを目的としています。
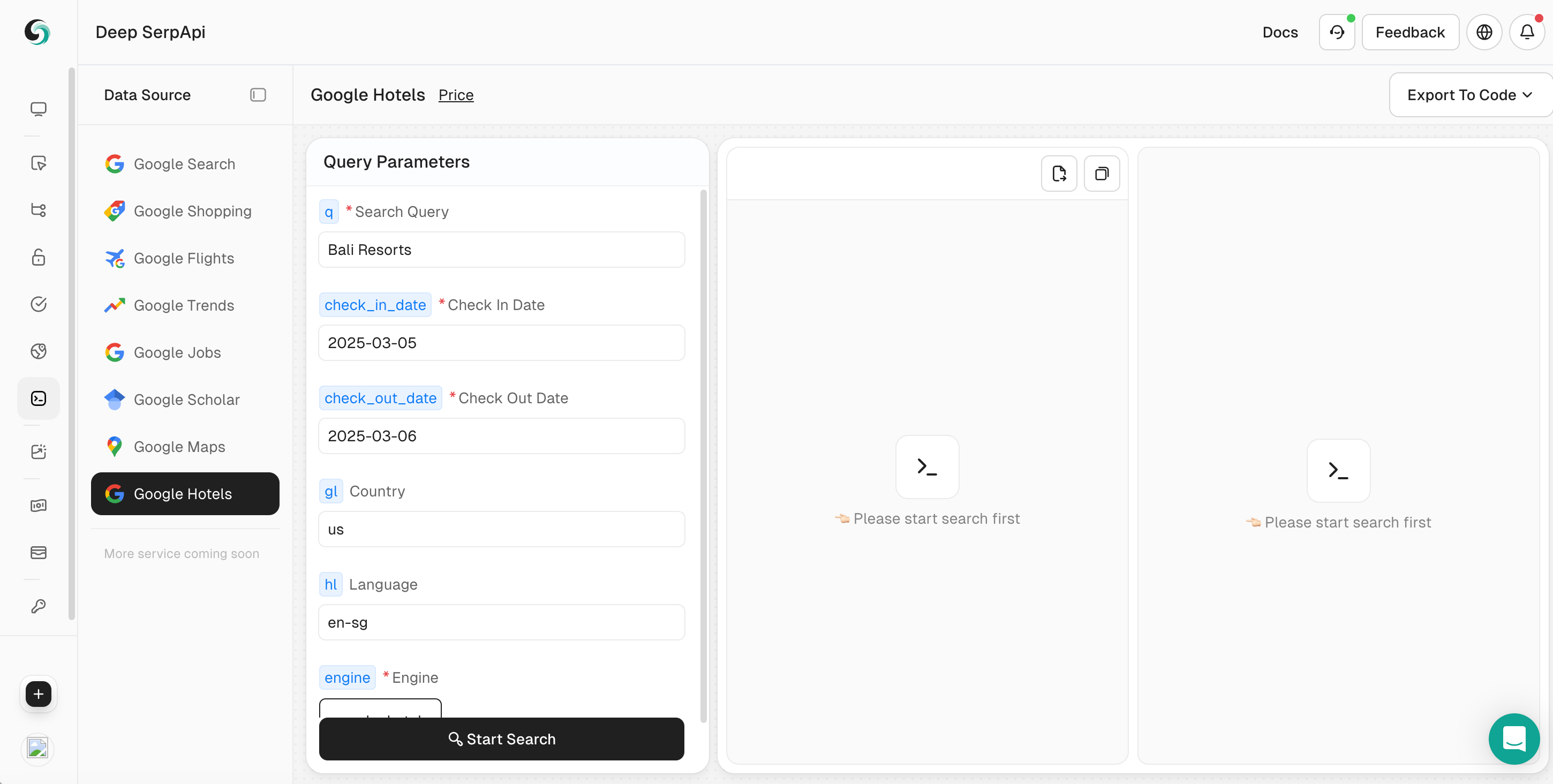
これにより、開発者はGoogle検索エンジンの20以上の異なるシナリオの結果を迅速に取得できます。複数のパラメーター設定をサポートし、地域、言語、デバイスの種類に基づいて検索をカスタマイズし、開発者が直接使用できる構造化されたJSONデータを提供します。

Deep SerpAPIの利点
-
**最低価格:Deep SerpAPIの価格はわずか0.1ドル/k**です。市場で最も低い価格です。
-
**使いやすさ:**複雑なコードを記述する必要はありません。API呼び出しを通じてデータを取得するだけです。
-
**リアルタイム:**各リクエストは、最新の検索結果を即座に返すことができ、データのタイムリーさを保証します。
-
**グローバルサポート:**グローバルIPアドレスとブラウザークラスタを通じて、検索結果が実際のユーザーのエクスペリエンスと一致することを保証します。
-
**豊富なデータ型:Google検索、Googleマップ、Googleショッピングなど、20以上**の検索タイプをサポートします。
-
**高い成功率:**最大99.995%のサービス可用性(SLA)を提供します。
Deep SerpAPI Playgroundを使用してGoogleホテル情報をスクレイピングする方法
**Deep SerpAPI**は、開発者がコードを記述せずにGoogleホテル情報を迅速にスクレイピングできる強力なオンラインツール、Playgroundを提供します。Playgroundは、簡単なパラメーター設定とクリック操作を通じて構造化された検索結果データを取得できるビジュアルインターフェースです。以下は、Deep SerpAPI Playgroundを使用してGoogleホテル情報をスクレイピングするための詳細な手順です。
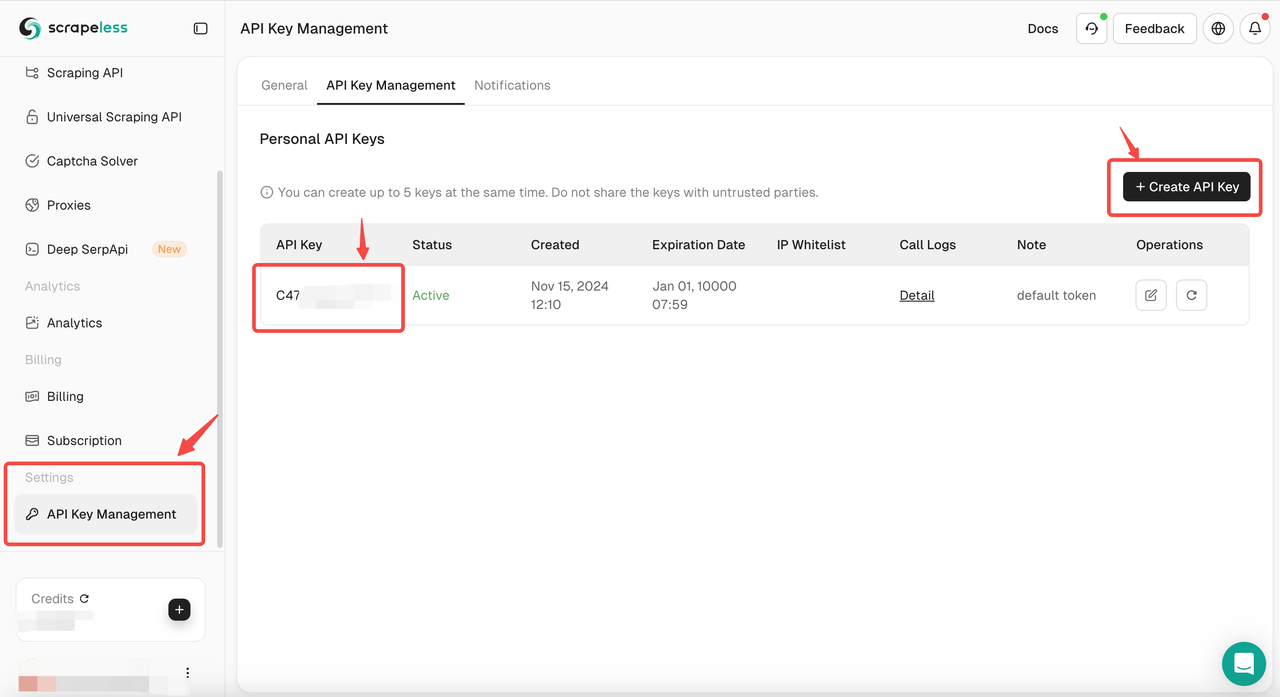
Deep SerpAPIのAPIキーの取得方法:
- Scrapelessで無料登録した後、20,000件の無料検索クエリが得られます。
- APIキー管理に移動します。「作成」をクリックして、一意のAPIキーを生成します。作成したら、APをクリックしてコピーするだけです。
1. サインアップしてPlaygroundにアクセスする
- アカウントを作成する:まだ作成していない場合は、Deep SerpAPIアカウントにサインアップします。
- Deep SerpApi Playgroundにアクセスする:ログインしたら、「Deep SerpApi」セクションに移動します。
2. 検索パラメーターを設定する
- Playgroundで、「ニューヨークのホテル」などの検索キーワードを入力します。
- チェックイン日、チェックアウト日、国、言語などの他のパラメーターを設定します。
公式APIドキュメント をクリックして表示し、Googleホテルのパラメーターについて学ぶこともできます。
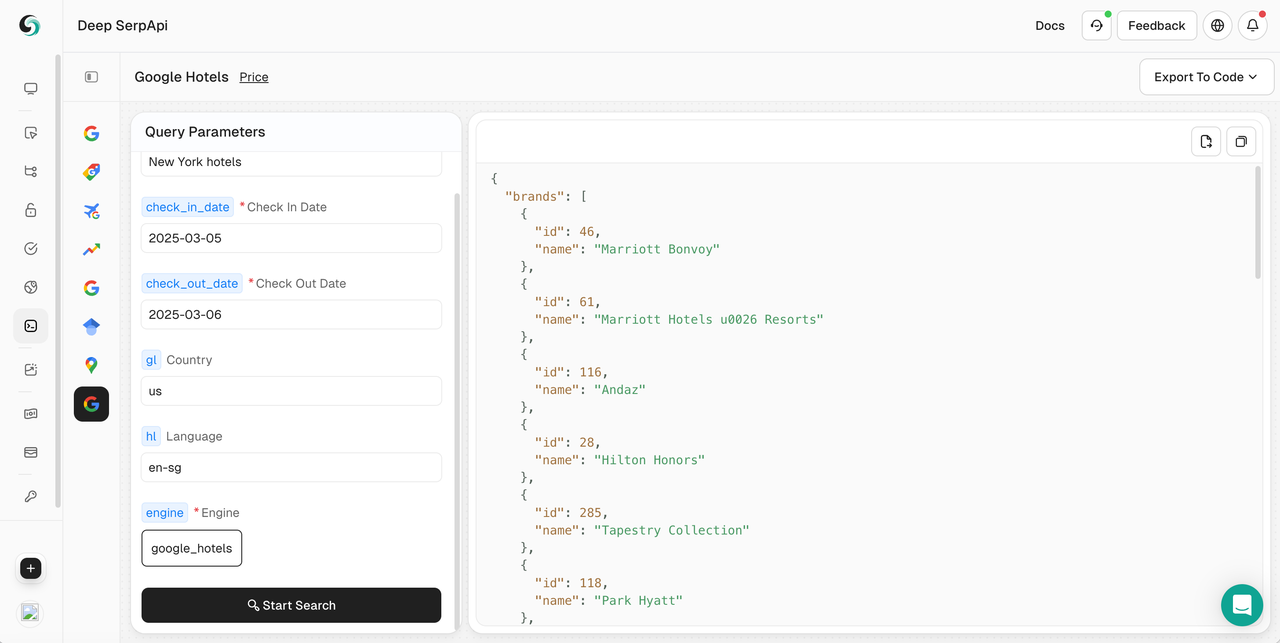
3. 検索を実行する
- 「検索開始」ボタンをクリックすると、PlaygroundはDeep Serp APIにリクエストを送信し、構造化されたJSONデータが返されます。
- 返されたデータには、ホテルの名前、ブランドの詳細、価格情報、説明、評価、施設、近くの場所、ホテルの評価などが含まれます。
4. データを表示してエクスポートする
- 返されたJSONデータを参照して、各ホテルの詳細情報を確認します。
- 必要に応じて、右上の「エクスポート」をクリックして、データをCSVまたはJSON形式でエクスポートし、さらに分析できます。
5. プロジェクトに統合する
- アプリケーションにデータを統合する必要がある場合、Deep SerpAPIはPython、JavaScript、Ruby、PHP、Java、C#、C ++、Swift、Go、Rustなど、複数のプログラミング言語のライブラリサポートを提供しています。
サンプルコード(Python)
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_hotel",
q: query,
engine: 'google',
gl: 'us',
hl: 'en'
}
payload = Payload("scraper.google.hotel", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Deep SerpAPI価格プラン:手頃な価格でパワフル
Deep SerpAPIは、開発者がGoogle検索結果ページ(SERP)データを迅速に取得するための費用対効果の高いソリューションを提供します。その価格プランは非常に競争力があり、価格はクエリ1,000件あたりわずか0.1ドルで、Googleの20以上の検索結果シナリオに適用できます。
無料の開発者サポートプログラム
Deep SerpAPIは現在、開発者がAPIをより適切に統合および使用できるようにする無料の開発者サポートプログラムも提供しています。プログラムの詳細を以下に示します。
- **統合サポート:**Deep SerpAPIをAIツール、アプリケーション、またはプロジェクトに統合します。すでにDifyをサポートしており、まもなくLangchain、Langflow、FlowiseAIなどのフレームワークをサポートする予定です。
- **無料サポート期間:**統合後、GitHubまたはソーシャルメディアで結果を共有することで、開発者は1〜12か月間の無料開発者サポートを受けることができます。
- 使用クォータ:最大月間500kの使用により、開発者はプロジェクトの初期段階でコストの問題を心配する必要がなくなります。

イベントへの参加について詳しくは、Discordに参加してLiamに連絡してください。
まとめ
要約すると、Node.jsを使用してGoogleホテルの価格をスクレイピングすることは、価格データを収集するための貴重な方法ですが、動的なコンテンツの処理や検出の回避などの課題があります。PuppeteerやPlaywrightなどのツールは役立ちますが、継続的なメンテナンスと技術的な専門知識が必要です。プロセスを合理化するために、Scrapelessの使用をお勧めします。これは、ホテル価格データを効率的かつ確実に抽出するための手間のかからないノーコードソリューションを提供します。Scrapelessを使用すると、Webスクレイピングの複雑さではなく、洞察に集中できます。今すぐ試して、データ収集を簡素化しましょう!
追加のリソース
Pythonを使用したGoogleニュースのスクレイピング方法
PowerShellでのSeleniumの使い方
Scrapelessを使用したGoogleショッピングからの製品詳細のスクレイピング
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


