
PythonでGoogle Financeのティッカー株価データを取得する方法
Advanced Data Extraction Specialist
金融の速いペースの世界では、最新かつ正確な株価データへのアクセスは、投資家、トレーダー、アナリストにとって不可欠です。Google Financeは、リアルタイムの株価、過去の財務データ、ニュース、通貨レートを提供する貴重なリソースです。Pythonを使用してこのデータをスクレイピングする方法を学ぶことは、データを収集し、センチメント分析を行い、市場予測を行い、またはリスクを効果的に管理しようとしている人にとって大きなメリットとなります。
なぜGoogle Financeをスクレイピングするのか?
Google Financeのスクレイピングは、次のような様々な理由で有益です。
- リアルタイム株価データ – 最新の株価、市場トレンド、過去の業績にアクセスできます。
- 自動化された市場分析 – トレンド分析、ポートフォリオ管理、またはアルゴリズム取引のために、大規模に財務データを収集できます。
- 企業に関する洞察 – 投資調査のために、財務概要、収益報告書、株価のパフォーマンスを収集できます。
- 競合他社と業界調査 – データに基づいた意思決定を行うために、競合他社の財務状況と業界トレンドを監視できます。
- ニュースとセンチメント分析 – 特定の株式や業界に関するニュース記事と最新情報を抽出し、センチメントを追跡できます。
スクレイピングする情報
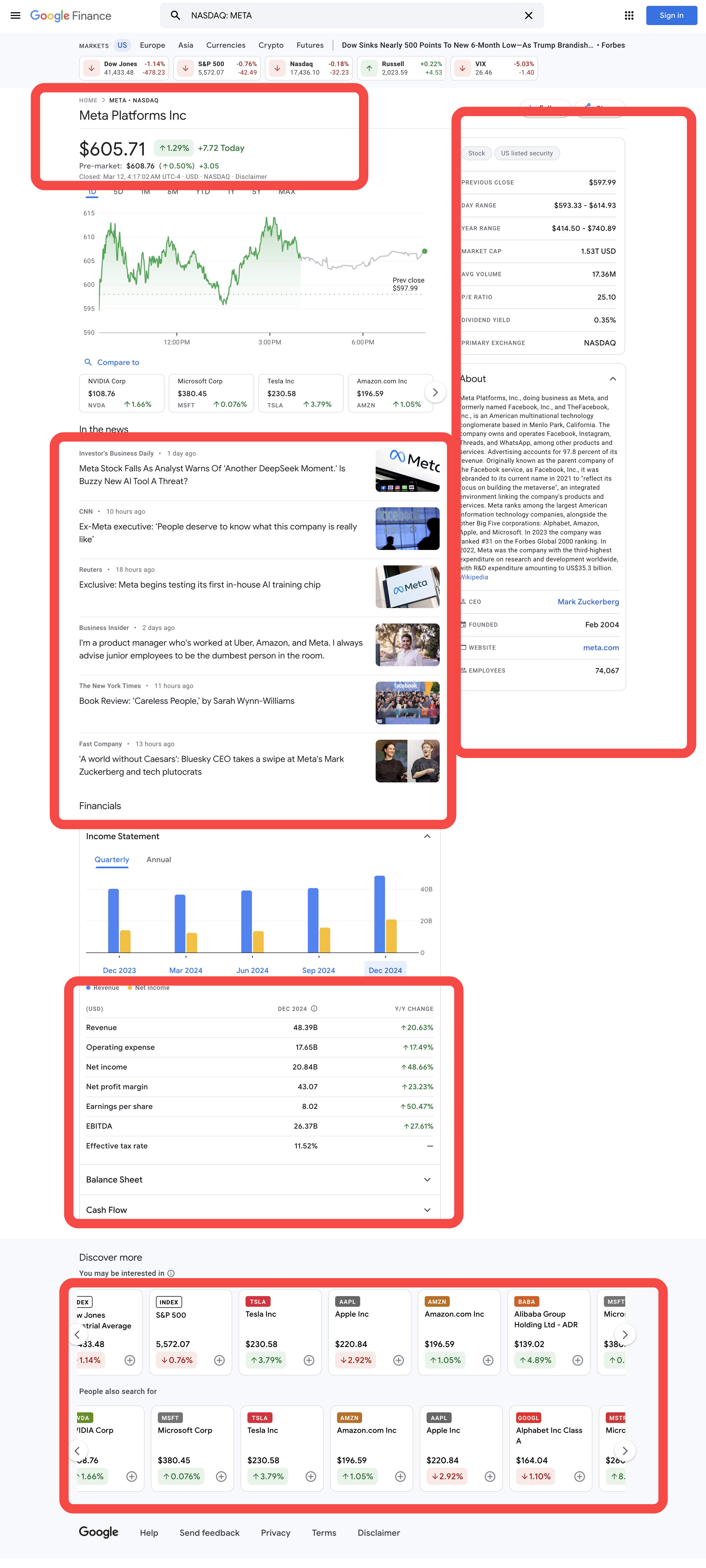
PythonでGoogle Financeのティッカークォートデータを取得する方法
ステップ1. 環境の設定
-
Python: ソフトウェア はPythonを実行するコアです。下記のように公式サイトから必要なバージョンをダウンロードできます。ただし、最新バージョンをダウンロードすることはお勧めしません。最新バージョンより1.2バージョン前のバージョンをダウンロードできます。
-
Python IDE: PythonをサポートするIDEであればどれでも機能しますが、PyCharmをお勧めします。これはPython用に特別に設計された開発ツールです。PyCharmのバージョンについては、無料のPyCharm Community Edition をお勧めします。
注:Windowsユーザーの場合は、インストールウィザード中に「Add python.exe to PATH」オプションにチェックを入れることを忘れないでください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
これで、ターミナルまたはコマンドプロンプトを開いて次のコマンドを入力することで、Pythonがインストールされているかどうかを確認できます。
python --versionステップ2. 依存関係のインストール
プロジェクトの依存関係を管理し、他のPythonプロジェクトとの競合を避けるために、仮想環境を作成することをお勧めします。ターミナルでプロジェクトディレクトリに移動し、次のコマンドを実行してgoogle_lensという名前の仮想環境を作成します。
python -m venv google_financeシステムに基づいて仮想環境をアクティブ化します。
- Windows:
language
google_finance_env\Scripts\activate- MacOS/Linux:
language
source google_finance_env/bin/activate仮想環境をアクティブ化したら、Webスクレイピングに必要なPythonライブラリをインストールします。Pythonでリクエストを送信するためのライブラリはrequestsで、データをスクレイピングするための主なライブラリはBeautifulSoup4です。次のコマンドを使用してインストールします。
language
pip install requests
pip install beautifulsoup4
pip install playwrightステップ3. データのスクレイピング
Google Financeから株価情報を抽出するには、最初にWebサイトのURLを使用して目的の株式をスクレイピングする方法を理解する必要があります。複数の株式が含まれているNasdaqインデックスを例に取ってみましょう。各株式のシンボルにアクセスするには、このリンクのNasdaq株式フィルターを使用できます。ここで、METAをターゲット株式として設定しましょう。インデックスと株式を手に入れたら、スクリプトの最初のスニペットを作成できます。
ウェブサイトのプライバシーを厳重に保護しています。このブログのすべてのデータは公開されており、クロールプロセスのデモンストレーションとしてのみ使用されます。いかなる情報やデータも保存しません。
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"これで、Requestsライブラリを使用してTARGET_URLにHTTPリクエストを行い、Beautiful Soupインスタンスを作成してHTMLコンテンツをスクレイピングできます。
language
HTTPリクエストを行う
page = requests.get(TARGET_URL)# "page"からコンテンツを取得するためにHTMLパーサーを使用する
soup = BeautifulSoup(page.content, "html.parser")クロールを開始する前に、まずWebページを検査することでHTML要素(TARGET_URL)を処理する必要があります。
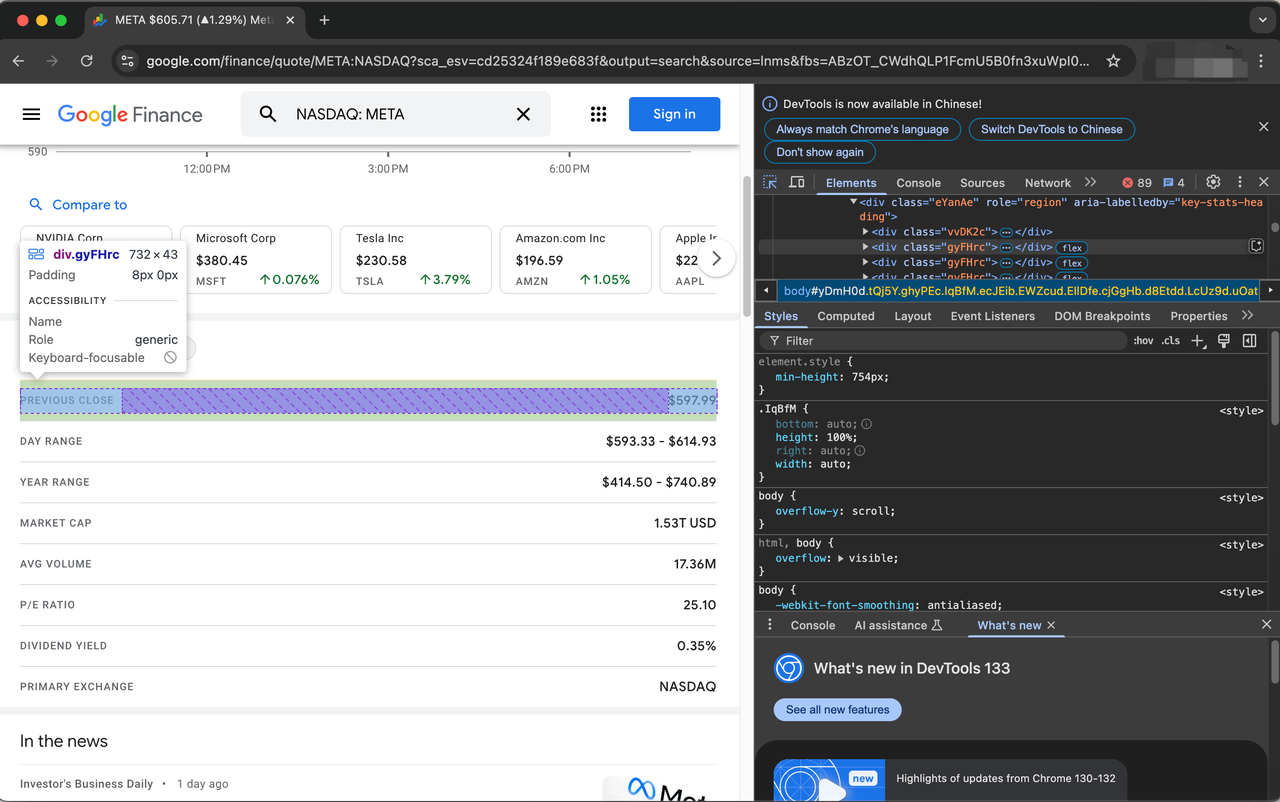
株式を説明する項目は、クラスgyFHrcで表されます。このような要素のそれぞれの中に、項目のタイトル(例:「終値」)と対応する値(例:$597.99)を表すクラスがあります。タイトルはmfs7Fcクラスから取得でき、値はP6K39cクラスから取得できます。
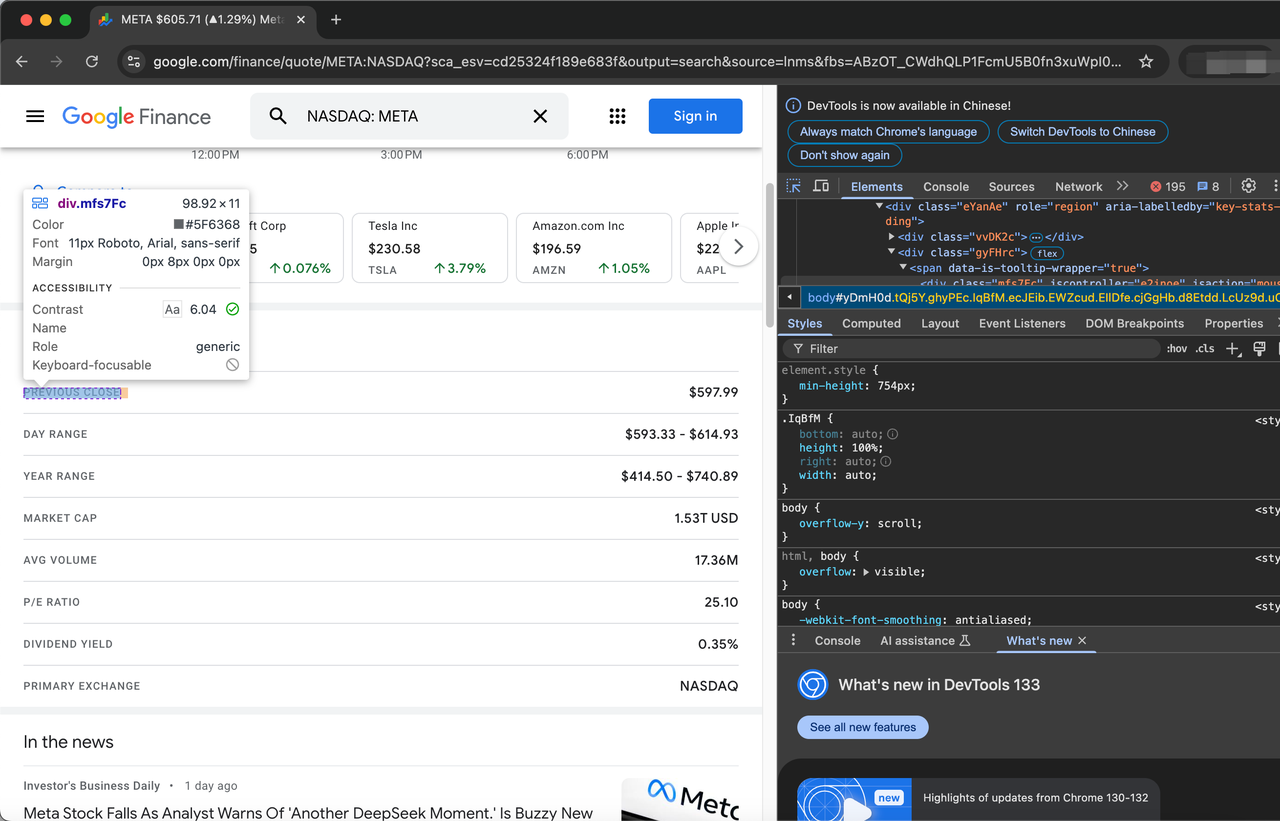
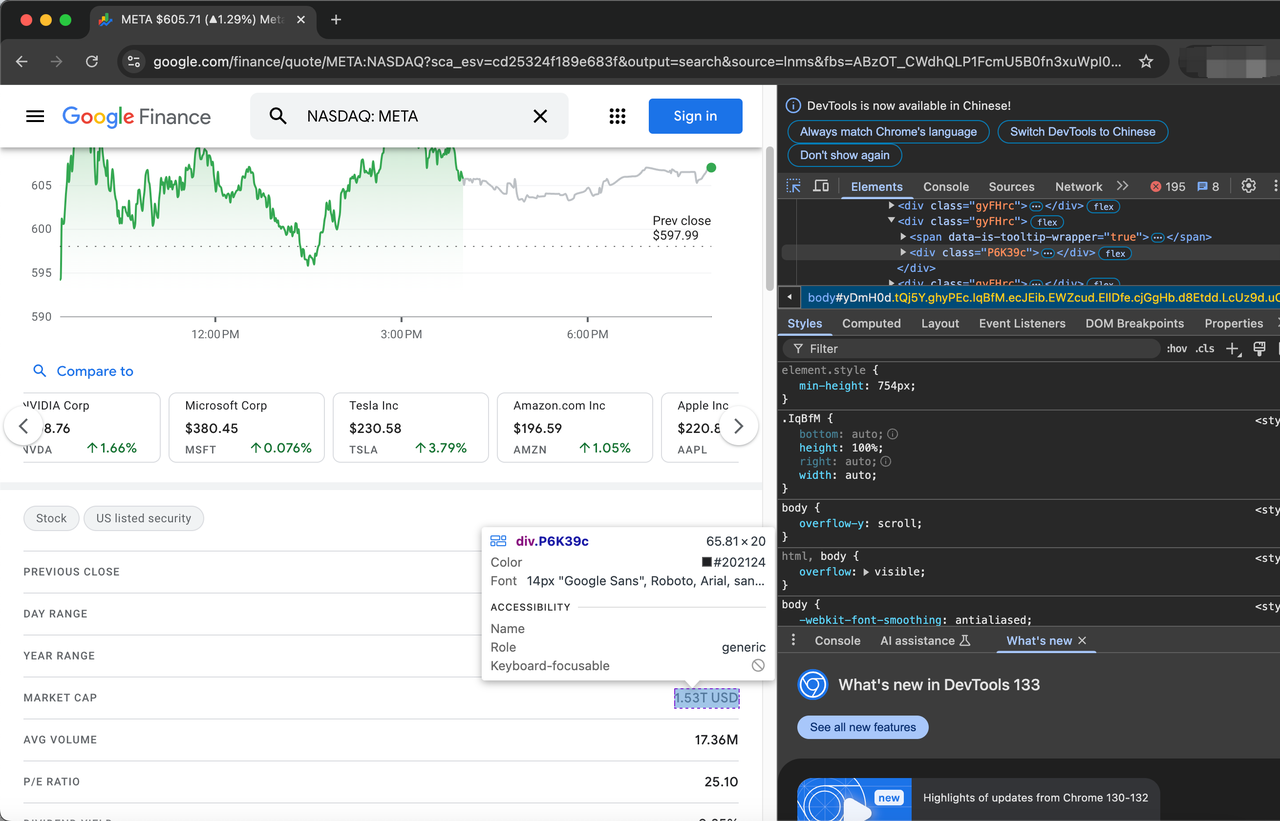
クロールする項目の完全なリストは以下のとおりです。
- 前日終値
- 日足レンジ
- 年足レンジ
- 時価総額
- 平均出来高
- PER
- 配当利回り
- 主要取引所
- CEO
- 創立
- ウェブサイト
- 従業員数
それでは、Pythonコードを使用してこれらの項目を取得する方法を見てみましょう。
# 株価を説明する項目を取得する
items = soup.find_all("div", {"class": "gyFHrc"})
# 株価の説明を格納するための辞書を作成する
stock_description = {}
# 項目を反復処理し、辞書に追加する
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)これは、お気に入りの株式を追跡するための取引ボット、アプリケーション、またはシンプルなダッシュボードに統合できるシンプルなスクリプトの例にすぎません。
完全なコード
ページから取得できるデータ属性は他にもたくさんありますが、今のところ、完全なコードは少しこんな感じになります。
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"# HTTPリクエストを行う
page = requests.get(TARGET_URL)# "page"からコンテンツを取得するためにHTMLパーサーを使用する
soup = BeautifulSoup(page.content, "html.parser")# 株価を説明する項目を取得する
items = soup.find_all("div", {"class": "gyFHrc"})# 株価の説明を格納するための辞書を作成する
stock_description = {}# 項目を反復処理し、辞書に追加する
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value結果は次のようになります。

Google Financeをスクレイピングする際の制限
上記の方法を使用すると、小さなスクレイパーを作成できますが、大規模なスクレイピングを行う場合、このスクレイパーはデータを提供し続けません。Googleはデータのスクレイピングに非常に敏感であり、最終的にIPをブロックします。
IPがブロックされると、何もスクレイピングできなくなり、データパイプラインが最終的に破損します。では、この問題をどのように克服すればよいでしょうか?非常に簡単な解決策があり、それはGoogle FinanceスクレイピングAPIを使用することです。
このAPIを使用して、Google Financeから無制限のデータを取得する方法を見てみましょう。
なぜScrapeless Google FinanceスクレイピングAPIを使用するのか?
データの品質と正確性
- 高精度データ: Scrapeless SerpApi は常に正確で信頼性が高く、最新のGoogle Financeデータを提供するため、ユーザーは最も正確で有用な市場情報を取得できます。
- リアルタイムの更新: リアルタイムの株価、市場トレンドなどを含む、Google Financeの最新データをリアルタイムで取得できることは、タイムリーな投資判断を行う必要があるユーザーにとって不可欠です。
多言語と場所のサポート
- 多言語サポート: 複数の言語をサポートしており、ユーザーは必要に応じて異なる言語で財務データを取得でき、世界中のさまざまな地域のユーザーのニーズを満たすことができます。
- 場所のカスタマイズ: 指定された地理的位置、デバイスの種類、その他の параметрに基づいてカスタマイズされた検索結果を取得でき、これはさまざまな地域における市場状況の分析や、地域に特化した市場調査を行うのに非常に役立ちます。
パフォーマンスとコストのメリット
- 超高速: 平均応答時間はわずか1~2秒で、Scrapeless SerpApiは市場で最も高速な検索クロールAPIの1つであり、ユーザーに必要なデータを迅速に提供できます。
- 費用対効果: Scrapeless SerpApiは、クエリ1,000件あたりわずか0.1ドルでGoogle Search APIを提供します。この価格モデルは大規模なデータスクレイピングプロジェクトにとって非常に費用対効果が高いです。
統合 - 容易な統合: Scrapeless SerpApiは、さまざまな一般的なプログラミング言語(Python、Node.js、Golangなど)との統合をサポートしており、ユーザーはそれを独自のアプリケーションや分析ツールに簡単に組み込むことができます。
安定性と信頼性 - 高可用性: Scrapeless SerpApiは高いサービス可用性と安定性を備えており、長期間および高頻度のデータスクレイピング中にユーザーへの中断のないサービスを保証できます。
- 専門的なサポート: Scrapeless SerpApiは、ユーザーが使用中に遭遇する問題を解決し、ユーザーがスムーズにデータを取得して使用できるようにするための専門的な技術サポートとカスタマーサービスを提供します。
Scrapelessを使用してGoogle Financeデータをスクレイピングする方法
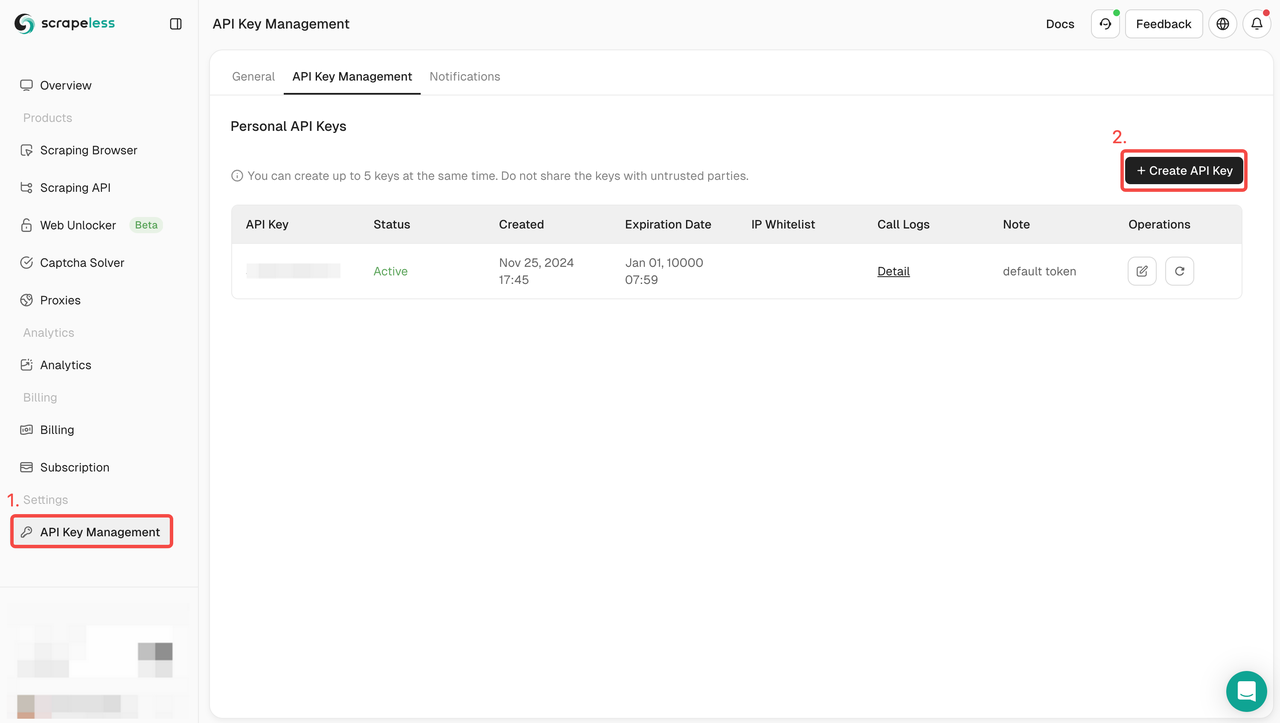
ステップ1. ScrapelessにサインアップしてAPIキーを取得する
- まだScrapelessアカウントを持っていない場合は、Scrapeless Webサイトにアクセスしてサインアップしてください。20,000件の無料検索クエリを取得できます。
- サインアップしたら、ダッシュボードにログインします。
- ダッシュボードで、「APIキー管理」に移動し、「APIキーの作成」をクリックします。生成されたAPIキーをコピーします。これは、Scrapeless APIを呼び出す際の認証資格情報になります。
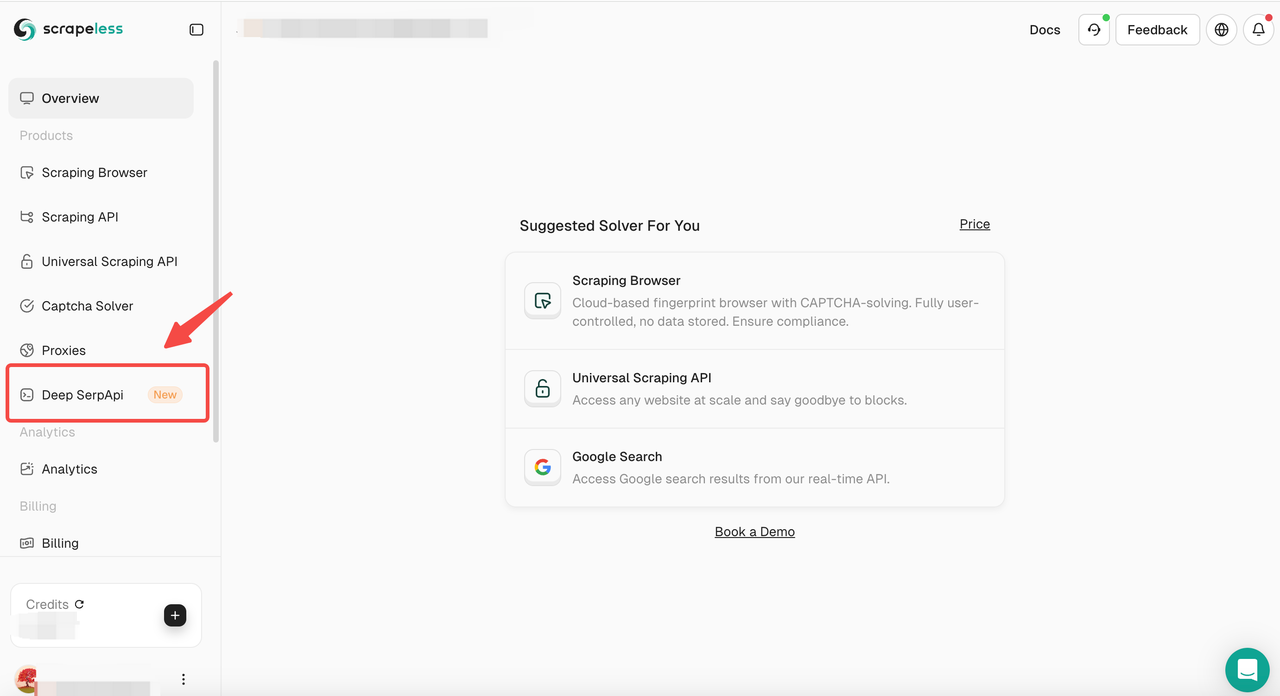
ステップ2. Deep SerpApi Playgroundにアクセスする
- 次に、「Deep SerpApi」セクションに移動します。
ステップ3. 検索パラメーターを設定する
- Playgroundで、「GOOGL:NASDAQ」などの検索キーワードを入力します。
- クエリ用語、言語、時間などの他のパラメーターを設定します。
ScrapelessのGoogle Financeのパラメーターについては、公式APIドキュメントをクリックして確認することもできます。
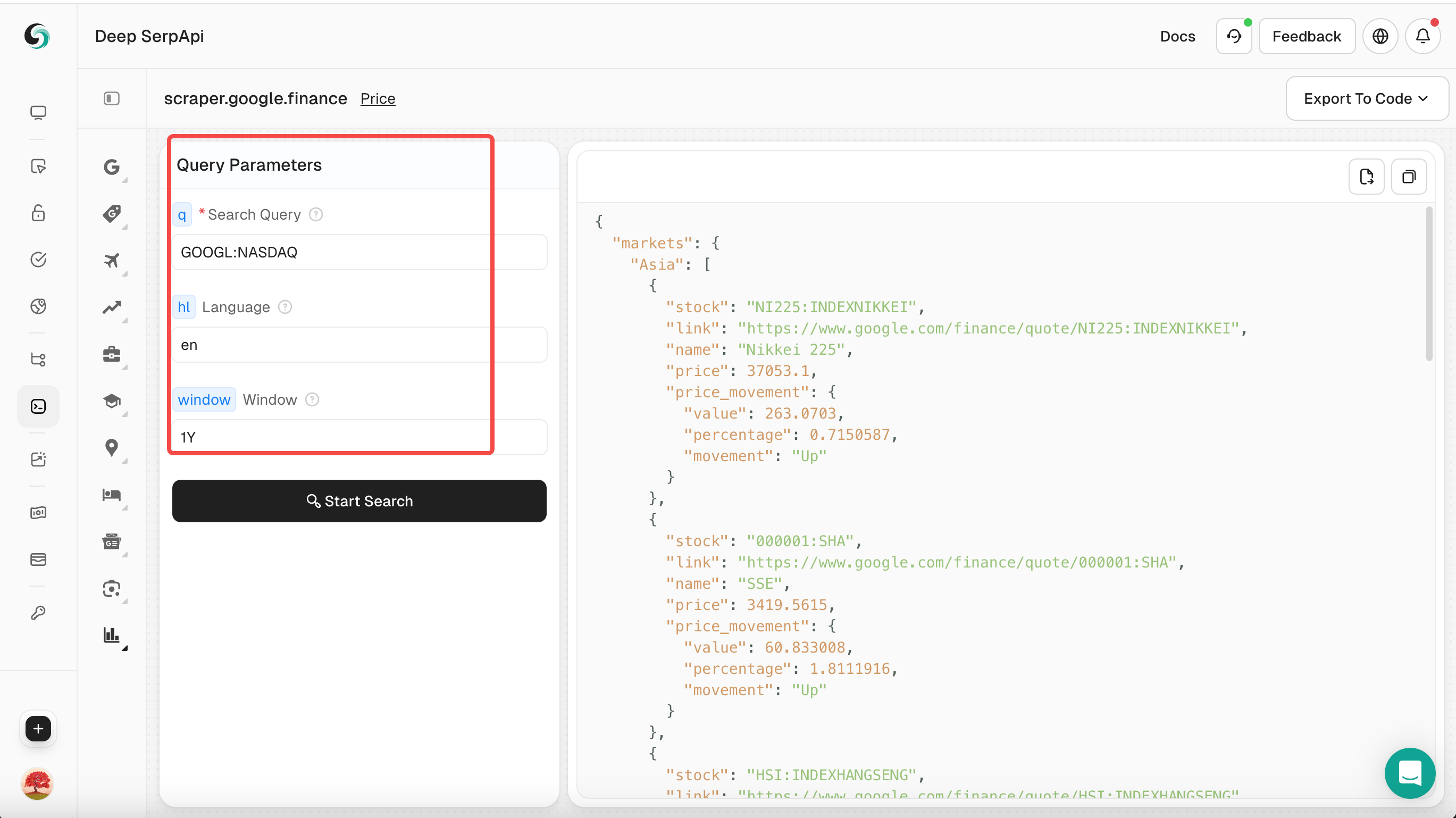
ステップ4. 検索を実行する
- 「検索開始」ボタンをクリックすると、PlaygroundはDeep Serp APIにリクエストを送信し、構造化されたJSONデータが返されます。
ステップ5. データを表示してエクスポートする
- 返されたJSONデータを参照して、詳細情報を表示します。
- 必要に応じて、右上の「コピー」をクリックして、データをCSVまたはJSON形式でエクスポートし、さらに分析できます。
無料の開発者サポート:
Scrapeless Deep SerpApiをAIツール、アプリケーション、またはプロジェクトに統合します(すでにDifyをサポートしており、Langchain、Langflow、FlowiseAIなどのフレームワークを今後サポートします)。
統合結果をソーシャルメディアで共有すると、月間最大500Kの使用量まで、1~12ヶ月間の無料開発者サポートが得られます。
この機会にプロジェクトを改善し、より多くの開発サポートをお楽しみください!詳細については、Discord経由でLiamに連絡することもできます。
Scrapeless APIを統合する方法
以下は、Scrapeless APIを使用してGoogle Financeの結果をスクレイピングするためのサンプルコードです。
language
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "あなたのAPIキー"
headers = {
"x-api-token": token
}
input_data = {
"q": "GOOG:NASDAQ",
"window": "MAX",
.....
}
payload = Payload("scraper.google.finance", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()より正確な結果を得るために、必要に応じてクエリパラメーターを調整してください。APIパラメーターの詳細については、Scrapelessの公式APIドキュメントを確認してください。
YOUR-API-KEYをコピーしたAPIキーに置き換える必要があります。
追加のリソース
PythonでGoogleニュースをスクレイピングする方法
PuppeteerでCloudflareをバイパスする方法
Scrapelessを使用してGoogle Lensの結果をスクレイピングする方法
まとめ
結論として、PythonでGoogle Financeのティッカークォートデータをスクレイピングすることは、リアルタイムの財務情報にアクセスするための強力なテクニックです。requestsやBeautifulSoupなどのライブラリ、またはSeleniumなどの高度なツールを利用することで、市場データを効率的に抽出して分析し、投資判断に役立てることができます。Webサイトの利用規約を尊重し、持続可能なデータアクセスのため、利用可能な場合は公式APIを使用することを検討してください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


