
PythonでExpediaのデータをスクレイピングする方法
Expert Network Defense Engineer
エクスペディアは旅行者にとって最適なウェブサイトです!ユーザーは、航空運賃からバケーションレンタル、レンタカーまで、包括的で正確な旅行情報を簡単に検索できます。情報検索に加えて、エクスペディアでは、フライト、宿泊施設、レンタカーをウェブサイト上で直接予約することもできるため、旅行関連データの貴重なリソースとなっています。
しかし、エクスペディアはスクレイピングAPIを提供していないため、大量のフライト情報を直接スクレイピングすることが困難です。ページ数が多いため、このデータを手動で収集することは現実的ではありません。
この記事では、エクスペディアの正確なフライト情報を簡単にスクレイピングする方法について詳しく説明します。
今すぐお読みください!
なぜエクスペディアのデータはそれほど重要なのか?
エクスペディアのデータをクロールすることで、豊富な市場情報を取得し、旅行業界の企業がよりスマートな意思決定を行うことができます。運用戦略の最適化から、顧客へのより費用対効果の高い選択肢の提供まで、これらのデータは重要な役割を果たします。
- 市場分析: 市場トレンドと競合価格を分析し、旅行代理店がより競争力のある戦略を策定するのに役立ちます。
- 価格比較: さまざまなプラットフォームの価格をリアルタイムで比較し、顧客にとって最適な選択肢を確保します。
- 在庫監視: フライト、ホテル、レンタカーの在庫を追跡し、需要を満たすためにタイムリーに供給を調整します。
- トレンド予測: 過去のデータに基づいて旅行トレンドを予測し、事前にリソースを計画します。
なぜエクスペディアからのデータスクレイピングが難しいのか?
ほとんどの最新のウェブサイトと同様に、エクスペディアはコンテンツのレンダリングとユーザーインタラクションの処理に多くのJavaScriptを使用する動的なウェブサイトです。そのため、Beautiful SoupやCheerioなどの従来のHTMLベースのウェブスクレイピングツールではJavaScriptを実行できないため、スクレイピングが困難です。
Pythonを使用したエクスペディアデータのスクレイピング方法2つ
方法1. ScrapelessスクレイピングAPI(最適な選択肢)
Scrapelessは、エクスペディアやその他の旅行関連ウェブサイトからデータ抽出を行うための強力で効率的なオールインワンのツールキットです。独自のスクレイパーを構築する際の技術的な課題なしに、貴重な情報をシームレスに収集する方法を提供します。
Scrapelessは、手頃な価格で安定した安全なエクスペディアスクレイピングAPIサービスを提供します。フライトとホテルの詳細を3秒以内で取得できます。パラメーターを構成し、APIトークンを入力するだけです。
- 包括的なデータ抽出: Scrapelessは、フライト、ホテル料金、レンタカーなど、必要なすべての情報を確保する旅行データをスクレイピングできます。
- カスタマイズ可能なソリューション: 市場分析、競合価格、在庫監視など、特定のビジネスニーズを満たすために、カスタマイズされたスクレイピングソリューションを提供します。
- 動的コンテンツの処理: JavaScriptを多用するウェブサイトを管理するための高度な技術により、完全で正確なデータ抽出を保証します。
- スケーラブルで信頼性が高い: 大規模なデータスクレイピングに対応し、プロジェクトを信頼性が高く効率的に実行し、タイムリーで一貫性のあるデータを提供します。
- データ転送: Scrapelessコードをデータベースに直接転送して、既存のシステムとのシームレスな統合を確保できます。ScrapelessはJSON形式の返却とエクスポートをサポートしています。
- コンプライアンスと倫理: Scrapelessは、ウェブサイトの利用規約とデータプライバシー規制を尊重し、法的および倫理的なガイドラインへの準拠を保証します。
方法2. 独自のエクスペディアPythonスクレイパーを構築する
欠点:
- 独自のGoogleマップスクレイピングツールの構築には時間がかかります。
- IPブロッキング、CAPTCHA検証、複数のプロキシの設定、リクエスト制限の管理などの課題に直面する可能性があります。
PythonとScrapelessを使用してエクスペディアデータのスクレイピングを行う
次に、PythonとScrapeless APIを組み合わせてエクスペディアのフライトデータをクロールする方法を詳しく説明します。
Scrapeless APIを使用せずに開発する場合、エクスペディアサイトのクロールには、リクエスト速度、プロキシ、リスク管理、データ送信などの問題を考慮する必要がありますが、Scrapeless APIを使用すると、必要なデータの構成と編集を行うだけで、プログラムを実行して必要なデータを取得できます。
注:関連するコードと構成は後で示します
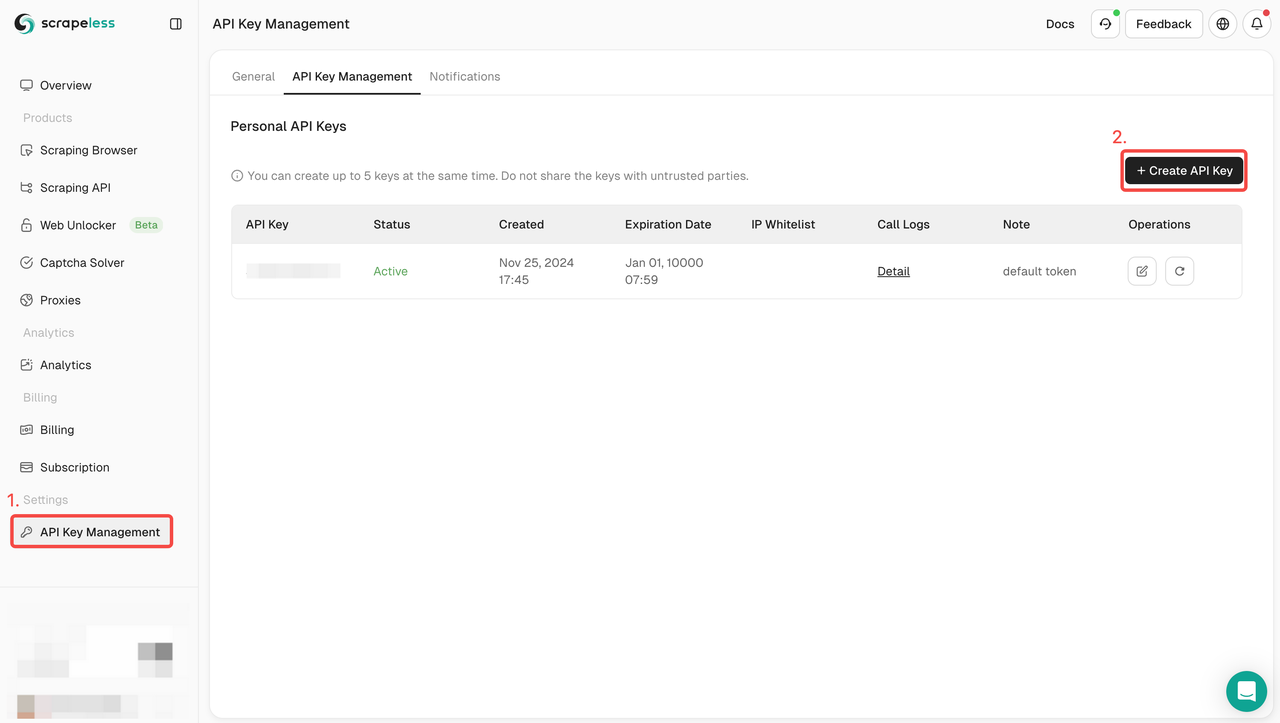
ステップ1. APIキーを取得する
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 作成したら、APIキーをクリックしてコピーします。
Scrapelessに登録を完了すると、2ドル分の無料検索残高を受け取ります。
ステップ2. Scrapeless APIリクエストコードを記述する
以下は私が記述した参照リクエストコードです。必要に応じて特定の値を調整できます。
Python
payload = {
"actor": "scraper.expedia", # 呼び出すサービス
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan", # 出発地
"destination": "New York, NY, United States of America (NYC-All Airports)", # 目的地
"date": {"year": 2025, "month": 3, "day": 5}, # 出発日
"cabin_class": "PREMIUM_ECONOMY", # キャビンクラス
"travelers": {
"adult": 1, # 大人人数
"children": [], # 2~17歳の子どもの年齢
"infants_on_lap": [], # 0~1歳の幼児の年齢
"infants_in_seat": [], # 0~1歳の幼児の年齢
},
"size": 20, # クエリごとに返されるデータの数、最大20
"page": 0, # クエリされたページ数
},
}ステップ3. Scrapeless APIに統合する
先ほど作成したAPIキーを覚えていますか?リクエストが記述された後、Scrapeless APIサービスに正式にアクセスする必要があります。以下のコードにAPIトークンを入力してください。
Python
url = "https://api.scrapeless.com/api/v1/scraper/request"
headers = {"x-api-token": api-key} # APIキーを入力
res = requests.post(url, json=payload, headers=headers)すべてのコーディング:
Python
import time
import requests
api_key = "..."
headers = {"x-api-token": api_key}
payload = {
"actor": "scraper.expedia",
"input": {
"page": 0,
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {"year": 2025, "month": 4, "day": 22},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": [],
},
"size": 20,
"page": 0,
},
}
url = "https://api.scrapeless.com/api/v1/scraper/request"
res = requests.post(url, json=payload, headers=headers)
print(data.text)
data = res.json()
# タイムアウトが発生した場合は、タスクIDを返します
if "taskId" in data:
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + data["taskId"]
resp = requests.get(url, headers=headers)
if resp.status_code != 200:
print("failed:", resp.text)
break
if "data" in resp.json():
print("succeed:", resp.text)
break
print(resp.text)スクラピング結果参照

さらに読む:
APIDocs経由でエクスペディアデータのスクレイピングを行う
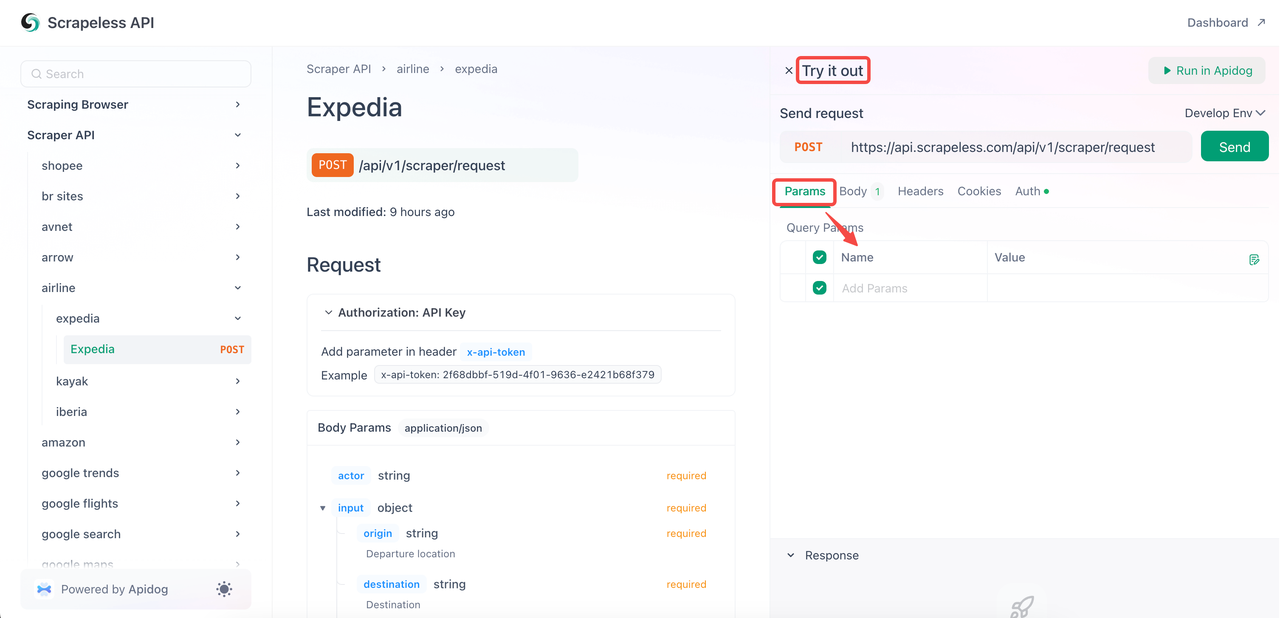
Scrapeless APIドキュメントで直接エクスペディアのフライトデータをスクレイピングすることもできます。次の手順を参照してください。
- ステップ1. APIトークンを作成します(既に説明済み)。
- ステップ2. エクスペディアページにアクセスし、「Try it out」をクリックします。
- ステップ3.
Paramsセクションに必要なパラメーターを構成します。全体的なコードコンテンツはBodyで確認できます。
参照用のリクエストコードを次に示します。
Python
{
"actor": "scraper.expedia",
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {
"year": 2025,
"month": 3,
"day": 5
},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": []
},
"size": 20,
"page": 0
}
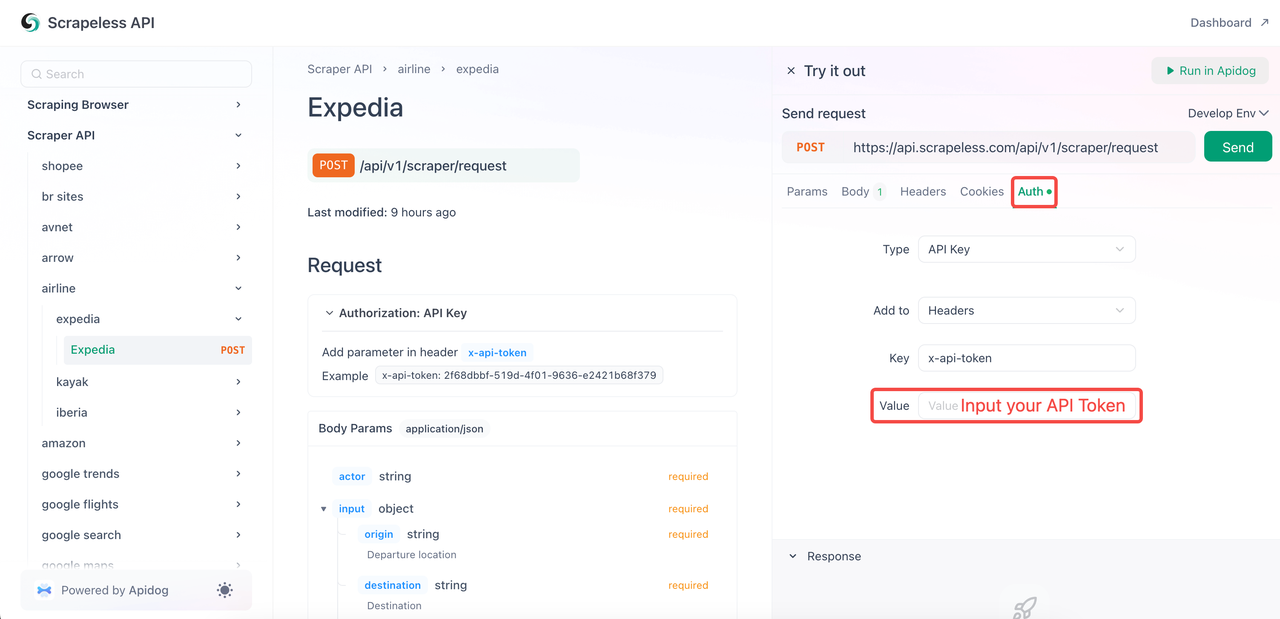
}- ステップ4. 最も重要なのは、「Auth」をクリックしてAPIトークンを貼り付けることです。最後に、「Send」をクリックしてデータをスクレイピングします!
- クロール結果の参照:
JSON
{
"data": {
"flightsSearch": {
"flightsSheets": null,
"clientMetadata": {
"pageName": "TYO to NYC flights",
"pageNameAnalytics": {
"__typename": "FlightsAnalytics",
"linkName": "Flight Search Page One Way",
"referrerId": "page.Flight-Search-Oneway"
},
"responseTags": [
"RESPONSE_SUMMARY_HYBRID",
"UNRECOGNIZED",
"UNRECOGNIZED",
"UNRECOGNIZED",
"RESPONSE_SUMMARY_REFINEMENTS_CACHE_LIVE"
],
"responseMetrics": [
{
"name": "LISTINGS_SUPPLY_RESPONSE_TIME",
"value": "1450"
}
],
"evaluatedExperiments": [
{
"bucket": 0,
"id": "FARES_ON_FSR_VARIANT"
},
{
"bucket": 1,
"id": "RECOMMENDED_SORT_V2_ENABLED"
},
{
"bucket": 0,
"id": "CACHE_HYDRATOR_FEATURE"
},
{
"bucket": 0,
"id": "TEST_SEARCH_STACK"
},
{
"bucket": 0,
"id": "NONSTOP_ENABLED"
},
{
"bucket": 1,
"id": "VERTICAL_SLICING_ENABLED"
},
{
"bucket": 0,
"id": "SHARED_UI_LISTINGS_ENABLED"
}
]
},Scrapeless Deep SerpApiが準備完了です!
Deep SerpAPiは、大規模言語モデル(LLM)とAIエージェント向けに設計された専用の検索エンジンです。リアルタイムで正確かつ公平な情報を提供し、AIアプリケーションがデータを効果的に取得および処理できるようにします。
✅ 20以上のGoogle検索APIシナリオインターフェースを内蔵しており、主流の検索エンジンのデータに接続されています。
✅ 検索結果、ニュース、ビデオ、画像など、20以上のデータタイプに対応しています。
✅ 過去24時間以内の履歴データの更新をサポートしています。
Deep SerpApiは、AI開発者のニーズを十分に考慮します!動的なウェブ情報をAI駆動型のソリューションに統合するプロセスを簡素化し、最終的にウェブデータのワンクリック検索と抽出を可能にするALL-in-One APIを実現します。さらに、この分野で長期間にわたって最低価格(1Kクエリあたり0.1〜0.3ドル)を維持します。
開発者スポンサーシッププログラムをお見逃しなく!
コミュニティに参加して、今すぐ50万クレジットを無料で入手しましょう。
結論
Pythonクローラーを手動で構築することでエクスペディアデータをクロールできますが、さまざまなウェブサイトのブロック障害に遭遇しやすいです。エクスペディアのフライトデータをより安全に、直接的に、迅速に、正確にクロールしたい場合は、ScrapelessスクレイピングAPIを試してみてください。シンプルなパラメーター構成とデータ入力だけで、結果のクロールをシームレスに完了できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


