
Scrapelessで取得できる応答パラメータは何ですか?
Senior Web Scraping Engineer
現代のウェブデータスクレイピングシナリオにおいて、単にHTMLページを取得することは、洗練されたアンチスクレイピング対策に直面した際にビジネスニーズを満たすには不十分なことが多いです。Scrapelessでは、開発者の視点から製品の能力を向上させることに取り組んでいます。
本日、Scrapelessのコアサービスの一つであるユニバーサルスクレイピングAPIの大規模なアップデートを発表できることを嬉しく思います。Web Unlockerは現在複数のレスポンス形式をサポートしています!この強化により、APIの柔軟性が大幅に向上し、エンタープライズユーザーや開発者にとっても、より適応性の高い効率的なデータスクレイピング体験を提供します。
なぜアップデートを行うのか?
以前、ユニバーサルスクレイピングAPIはデフォルトでHTMLページのコンテンツを返していましたが、これは暗号化されていないページやアンチスクレイピング対策が弱いウェブサイトに迅速にアクセスするにはうまく機能しました。しかし、ユーザーの自動化に対する要求が高まる中で、多くのユーザーがHTMLを取得した後にデータ構造を手動で処理し、コンテンツをクリーニングし、要素を抽出しなければならないことに気が付きました—これは不必要な開発負担を増加させていました。このプロセスを簡略化して、事前処理されたコンテンツを一度のステップで提供できるのでしょうか?
今や、あなたは可能です!
レスポンスロジックを刷新しました。response_typeパラメータを設定することで、開発者は希望するデータ形式を柔軟に指定できます。生HTML、プレーンテキスト、または構造化されたメタデータが必要な場合でも、単純なパラメータ設定だけで済みます。
今得られるレスポンス形式:
現在サポートされている形式には、以下が含まれますが、これに限りません:
- JSON出力フィルター:
outputsパラメータを使用してJSON形式のデータをフィルタリングします。許可されているフィルタータイプにはemail、phone_numbers、headings、および9つの他のものが含まれ、結果は構造化されたJSONで返されます。 - 複数の戻り形式: JSONフィルタリングを超えて、リクエストに
response_typeパラメータを追加することでレスポンス形式を直接指定できます(例:response_type=plaintext)。現在サポートされている形式は次の通りです:
HTML: ページコンテンツをHTML形式で抽出します(静的ページに最適)。Plaintext: HTMLタグやMarkdown形式が取り除かれたプレーンテキストとしてスクレイピングしたコンテンツを返します—テキスト処理や分析に最適です。Markdown: ページコンテンツをMarkdown形式で抽出します(静的なMarkdownベースのページに最適),読みやすく処理しやすくなります。PNG/JPEG:response_type=pngを設定すると、ターゲットページのスクリーンショットをキャプチャし、PNGまたはJPEG形式で返します(全ページのスクリーンショットのオプションあり)。
注意: デフォルトのresponse_typeはhtmlです。
例を考えてみましょう
1. JSON戻り値フィルタリング:
outputsパラメータを使用してJSON形式のデータをフィルタリングできます。このパラメータが設定されると、レスポンスタイプはJSONに固定されます。
このパラメータはカンマで区切ったフィルター名のリストを受け入れ、構造化されたJSON形式でデータを返します。サポートされているフィルタータイプには、phone_numbers、headings、images、audios、videos、links、menus、hashtags、emails、metadata、tables、faviconがあります。
以下のサンプルコードは、scrapelessサイトのホームページで画像情報をすべて取得する方法を示しています:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- 結果:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75","https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
Plain Text
# Scrapeless API
## ドキュメント
- スクレイピングブラウザ [CDP API](https://apidocs.scrapeless.com/doc-801748.md):
- スクレイピングAPI > shopee [アクターリスト](https://apidocs.scrapeless.com/doc-754333.md):
- スクレイピングAPI > amazon [APIパラメーター](https://apidocs.scrapeless.com/doc-857373.md):
- スクレイピングAPI > google検索 [APIパラメーター](https://apidocs.scrapeless.com/doc-800321.md):
- スクレイピングAPI > googleトレンド [APIパラメーター](https://apidocs.scrapeless.com/doc-796980.md):
- スクレイピングAPI > googleフライト [APIパラメーター](https://apidocs.scrapeless.com/doc-796979.md):
- スクレイピングAPI > googleフライトチャート [APIパラメーター](https://apidocs.scrapeless.com/doc-908741.md):
- スクレイピングAPI > googleマップ [APIパラメーター(Googleマップ)](https://apidocs.scrapeless.com/doc-834792.md):
- スクレイピングAPI > googleマップ [APIパラメーター(Googleマップオートコンプリート)](https://apidocs.scrapeless.com/doc-834799.md):
- スクレイピングAPI > googleマップ [APIパラメーター(Googleマップ寄稿者レビュー)](https://apidocs.scrapeless.com/doc-834806.md):
- スクレイピングAPI > googleマップ [APIパラメーター(Googleマップの指示)](https://apidocs.scrapeless.com/doc-834821.md):
- スクレイピングAPI > googleマップ [APIパラメーター(Googleマップレビュー)](https://apidocs.scrapeless.com/doc-834831.md):
- スクレイピングAPI > googleスカラー [APIパラメーター(Googleスカラー)](https://apidocs.scrapeless.com/doc-842638.md):
- スクレイピングAPI > googleスカラー [APIパラメーター(Googleスカラー著者)](https://apidocs.scrapeless.com/doc-842645.md):
- スクレイピングAPI > googleスカラー [APIパラメーター(Googleスカラー引用)](https://apidocs.scrapeless.com/doc-842647.md):
- スクレイピングAPI > googleスカラー [APIパラメーター(Googleスカラーのプロフィール)](https://apidocs.scrapeless.com/doc-842649.md):
- スクレイピングAPI > googleジョブ [APIパラメーター](https://apidocs.scrapeless.com/doc-850038.md):
- スクレイピングAPI > googleショッピング [APIパラメーター](https://apidocs.scrapeless.com/doc-853695.md):
- スクレイピングAPI > googleホテル [APIパラメーター](https://apidocs.scrapeless.com/doc-865231.md):
- スクレイピングAPI > googleホテル [サポートされているGoogleバケーションレンタル物件タイプ](https://apidocs.scrapeless.com/doc-890578.md):
- スクレイピングAPI > googleホテル [サポートされているGoogleホテル物件タイプ](https://apidocs.scrapeless.com/doc-890580.md):
- スクレイピングAPI > googleホテル [サポートされているGoogleバケーションレンタル設備](https://apidocs.scrapeless.com/doc-890623.md):
- スクレイピングAPI > googleホテル [サポートされているGoogleホテル設備](https://apidocs.scrapeless.com/doc-890631.md):
- スクレイピングAPI > googleニュース [APIパラメーター](https://apidocs.scrapeless.com/doc-866643.md):
- スクレイピングAPI > googleレンズ [APIパラメーター](https://apidocs.scrapeless.com/doc-866644.md):
- スクレイピングAPI > googleファイナンス [APIパラメーター](https://apidocs.scrapeless.com/doc-873763.md):
- スクレイピングAPI > googleプロダクト [APIパラメーター](https://apidocs.scrapeless.com/doc-880407.md):
- スクレイピングAPI [googleプレイストア](https://apidocs.scrapeless.com/folder-3277506.md):
- スクレイピングAPI > googleプレイストア [APIパラメーター](https://apidocs.scrapeless.com/doc-882690.md):
- スクレイピングAPI > googleプレイストア [サポートされているGoogleプレイカテゴリー](https://apidocs.scrapeless.com/doc-882822.md):
- スクレイピングAPI > google広告 [APIパラメーター](https://apidocs.scrapeless.com/doc-881439.md):
- ユニバーサルスクレイピングAPI [JSレンダードキュメント](https://apidocs.scrapeless.com/doc-801406.md):
## APIドキュメント
- ユーザー [ユーザー情報を取得](https://apidocs.scrapeless.com/api-11949851.md): 現在認証されているユーザーに関する基本情報を取得します。アカウント残高やサブスクリプションプランの詳細が含まれます。
- スクレイピングブラウザ [接続](https://apidocs.scrapeless.com/api-11949901.md):
- スクレイピングブラウザ [実行中のセッション](https://apidocs.scrapeless.com/api-16890953.md): すべての実行中のセッションを取得
- スクレイピングブラウザ [ライブURL](https://apidocs.scrapeless.com/api-16891208.md): セッショントask IDに基づいて実行中のセッションのライブURLを取得
- スクレイピングAPI > shopee [Shopee製品](https://apidocs.scrapeless.com/api-11953650.md):
- スクレイピングAPI > shopee [Shopee検索](https://apidocs.scrapeless.com/api-11954010.md):
- スクレイピングAPI > shopee [ShopeeRcmd](https://apidocs.scrapeless.com/api-11954111.md):
- スクレイピングAPI > ブラジルサイト [Solucoes cnpjreva](https://apidocs.scrapeless.com/api-11954435.md): 対象URL `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- スクレイピングAPI > ブラジルサイト [Solucoes certidaointernet](https://apidocs.scrapeless.com/api-12160439.md): 対象URL `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`- スクレイピングAPI > ブラジルサイト Servicos receita: ターゲットURL
https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp - スクレイピングAPI > ブラジルサイト Consopt: ターゲットURL
https://consopt.www8.receita.fazenda.gov.br/consultaoptantes - スクレイピングAPI > アマゾン 製品:
- スクレイピングAPI > アマゾン 売り手:
- スクレイピングAPI > アマゾン キーワード:
- スクレイピングAPI > グーグル検索 Google検索:
- スクレイピングAPI > グーグル検索 Google画像:
- スクレイピングAPI > グーグル検索 Googleローカル:
- スクレイピングAPI > グーグルトレンド オートコンプリート:
- スクレイピングAPI > グーグルトレンド 時間経過による関心:
- スクレイピングAPI > グーグルトレンド 地域別の比較内訳:
- スクレイピングAPI > グーグルトレンド サブリージョン別の関心:
- スクレイピングAPI > グーグルトレンド 関連クエリ:
- スクレイピングAPI > グーグルトレンド 関連トピック:
- スクレイピングAPI > グーグルトレンド 今トレンド中:
- スクレイピングAPI > グーグルフライト 往復:
- スクレイピングAPI > グーグルフライト 片道:
- スクレイピングAPI > グーグルフライト 複数都市:
- スクレイピングAPI > グーグルフライトチャート チャート:
- スクレイピングAPI > グーグルマップ Googleマップ:
- スクレイピングAPI > グーグルマップ Googleマップオートコンプリート:
- スクレイピングAPI > グーグルマップ Googleマップ寄稿者レビュー:
- スクレイピングAPI > グーグルマップ Googleマップの道順:
- スクレイピングAPI > グーグルマップ Googleマップレビュー:
- スクレイピングAPI > グーグルスカラー Googleスカラー:
- スクレイピングAPI > グーグルスカラー Googleスカラー著者:
- スクレイピングAPI > グーグルスカラー Googleスカラー引用:
- スクレイピングAPI > グーグルスカラー Googleスカラーのプロフィール:
- スクレイピングAPI > グーグルジョブ Googleジョブ:
- スクレイピングAPI > グーグルショッピング Googleショッピング:
- スクレイピングAPI > グーグルホテル Googleホテル:
- スクレイピングAPI > グーグルニュース Googleニュース:
- スクレイピングAPI > グーグルレンズ Googleレンズ:
- スクレイピングAPI > グーグルファイナンス Googleファイナンス:
- スクレイピングAPI > グーグルファイナンス Googleファイナンス市場:
- スクレイピングAPI > グーグルプロダクト Googleプロダクト:
- スクレイピングAPI > グーグルプレイストア Googleプレイゲーム:
- スクレイピングAPI > グーグルプレイストア Googleプレイブックス:
- スクレイピングAPI > グーグルプレイストア Googleプレイ映画:
- スクレイピングAPI > グーグルプレイストア Googleプレイプロダクト:
- スクレイピングAPI > グーグルプレイストア Googleプレイアプリ:
- スクレイピングAPI > グーグル広告 Google広告:
- スクレイピングAPI スクレイパーリクエスト:
- スクレイピングAPI スクレイパー結果取得:
- ユニバーサルスクレイピングAPI JSレンダー:
- ユニバーサルスクレイピングAPI ウェブアンロッカー:
- ユニバーサルスクレイピングAPI Akamaiwebクッキー:
- ユニバーサルスクレイピングAPI Akamaiwebセンサー:
- クローラー > スクレイプ 単一URLをスクレイプ:
- Crawler > Scrape 複数のURLをスクレイプ:
- Crawler > Scrape バッチスクレイプジョブをキャンセル:
- Crawler > Scrape スクレイプのステータスを取得:
- Crawler > Scrape バッチスクレイプジョブのステータスを取得:
- Crawler > Scrape バッチスクレイプジョブのエラーを取得:
- Crawler > Crawl オプションに基づいて複数のURLをクロール:
- Crawler > Crawl クロールジョブをキャンセル:
- Crawler > Crawl クロールジョブのステータスを取得:
- Crawler > Crawl クロールジョブのエラーを取得:
- Public アクターステータス:
- Public アクターステータス:
### 4. マークダウン
リクエストパラメータに`response_type=markdown`を追加することで、Scrapeless Universal Scraping APIは特定のページの内容をマークダウン形式で返します。
以下の例は、[スクレイピングブラウザクイックスタートページ](https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started)のマークダウン効果を示しています。まずページインスペクションを使用してテーブルのCSSセレクタを取得します。
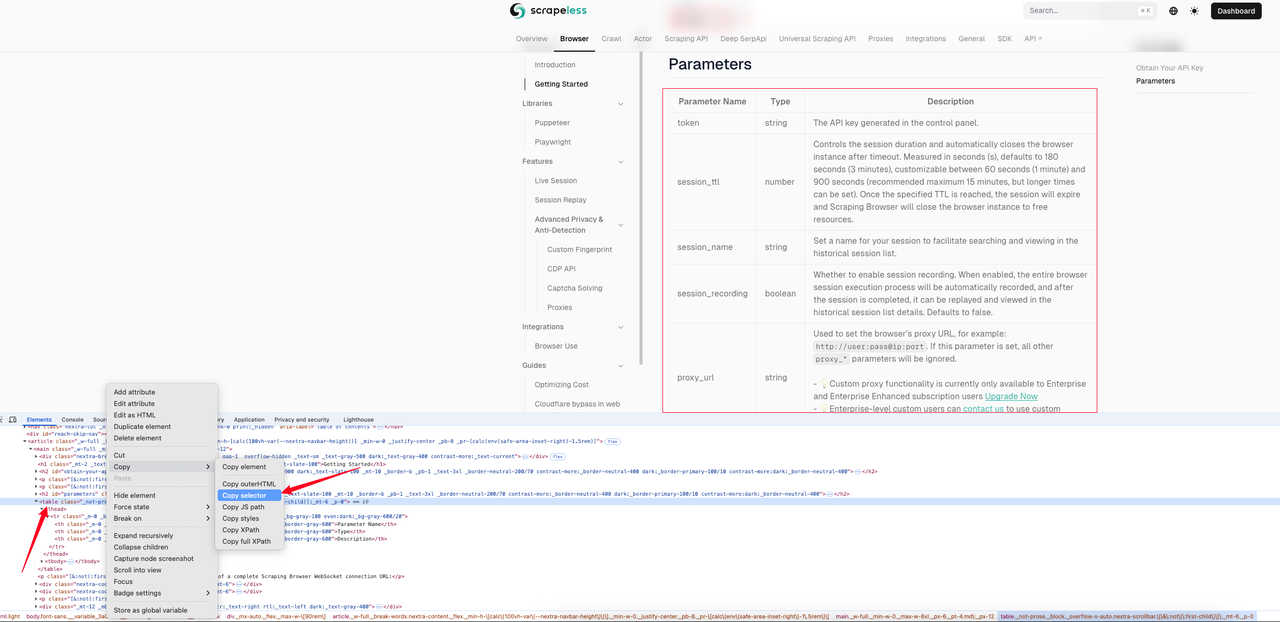
この例では、取得したCSSセレクタは次のとおりです:`#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table`。以下が完全なサンプルコードです。
> ジャバスクリプト
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // ページテーブル要素のCSSセレクタ
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "APIキー",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # ページテーブル要素のCSSセレクタ
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "APIキー",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])クロールされたテーブルのマークダウンテキストの表示:
Markdown
| パラメータ名 | 型 | 説明 |
| --- | --- | --- |
| token | string | コントロールパネルで生成されたAPIキー。 |
| session_ttl | number | セッションの持続時間を制御し、タイムアウト後にブラウザインスタンスを自動的に閉じる。秒(s)で測定され、デフォルトは180秒(3分)。60秒(1分)から900秒(最大推奨は15分)までカスタマイズ可能。指定されたTTLに達すると、セッションは期限切れとなり、スクレイピングブラウザはブラウザインスタンスを閉じてリソースを解放します。 |
| session_name | string | セッションに名前を付けて履歴セッションリストでの検索および表示を容易にします。 |
| session_recording | boolean | セッション記録を有効にするかどうか。これが有効になると、ブラウザセッションの実行プロセス全体が自動的に記録され、セッションが完了した後に履歴セッションリストの詳細で再生して表示できます。デフォルトはfalse。 |
| proxy_url | string | ブラウザのプロキシURLを設定するために使用されます。例えば: http://user:pass@ip:port。このパラメータが設定されている場合、他のすべてのproxy_*パラメータは無視されます。- 💡カスタムプロキシ機能は現在、エンタープライズおよびエンタープライズ強化サブスクリプションユーザーのみに利用可能。今すぐアップグレード- 💡エンタープライズレベルのカスタムユーザーは、カスタムプロキシの使用についてお問い合わせいただけます。 || proxy_country | 文字列 | プロキシの対象国/地域を設定し、その地域のIPアドレスを介してリクエストを送信します。国コード(例:アメリカ合衆国のUS、イギリスのGB、すべての国のANY)を指定できます。サポートされているすべてのオプションの国コードを参照してください。 |
| fingerprint | 文字列 | ブラウザフィンガープリントは、ブラウザとデバイスの構成情報を使用して作成されたほぼユニークな「デジタルフィンガープリント」で、クッキーがなくてもオンライン活動を追跡するために使用できます。幸いなことに、Scraping Browserでのフィンガープリンティングの設定はオプションです。ブラウザのユーザーエージェント、タイムゾーン、言語、画面解像度などのコアパラメータのようなブラウザフィンガープリントの深いカスタマイズを提供し、カスタムランチパラメータを通じて機能を拡張することをサポートします。複数アカウントの管理、データ収集、プライバシー保護のシナリオに適しており、Scrapelessの独自のChromiumブラウザを使用することで検出を完全に回避します。デフォルトでは、Scraping Browserサービスは各セッションに対してランダムなフィンガープリントを生成します。参照 |
### 5. PNG/JPEG
response_type=pngをリクエストに追加することで、ターゲットページのスクリーンショットをキャプチャし、pngまたはjpeg画像を返すことができます。レスポンス結果がpngまたはjpegに設定されている場合、返される結果がフルスクリーンであるかどうかは、`response_image_full_page=true`パラメータを使用して設定できます。このパラメータのデフォルト値はfalseです。
以下のコード例は、指定した領域のスクリーンショットを[Srapelessのホームページ](https://www.scrapeless.com/?utm_source=official&utm_medium=blog&utm_campaign=response-formats-update)から取得する方法を示しています。最初に、キャプチャしたい画像のためのCSSセレクタを見つけます。
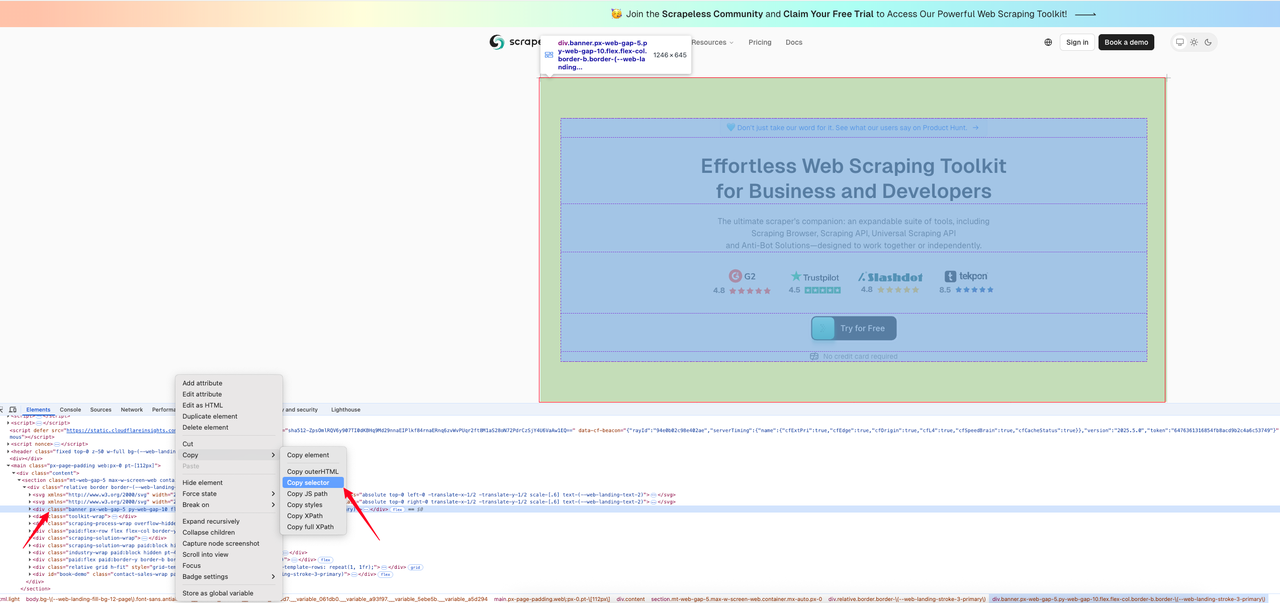
以下はインターセプションコードです:
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // ページテーブル要素のCSSセレクタ
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # ページテーブル要素のCSSセレクタ
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- PNGレスポンスの結果:

👉 詳細についてはScrapeless Docsを訪れてください
👉 APIドキュメントを今すぐチェックしてください:JS Render
使用シナリオが完全にカバーされています
このアップデートは特に次のように適しています:
- コンテンツ抽出アプリケーション(要約生成、情報収集など)
- SEOデータクローリング(メタ、構造化データ分析など)
- ニュース集約プラットフォーム(テキストと著者を素早く抽出)
- リンク分析および監視ツール(href、nofollow情報を抽出)
テキストを迅速にクロールしたい場合でも、構造化データを取得したい場合でも、このアップデートはより少ない労力でより多くの結果を得るのに役立ちます。
今すぐ体験してください
この機能はScrapelessで完全に立ち上げられました。 追加の認証やアップグレードプランは必要ありません。出力パラメータを制限するか、response_typeパラメータを渡すだけで新しいデータ返却形式を体験できます!
Scrapelessは常に、インテリジェントで安定した使いやすいウェブデータプラットフォームの構築に取り組んできました。 このアップデートはさらなる一歩です。皆様の体験やフィードバックをお待ちしています。共にウェブデータの取得を簡単にしていきましょう。
🔗 今すぐScrapeless Universal Scraping APIを試してみてください
📣 コミュニティに参加して 最初に最新情報や実用的なヒントをゲットしましょう!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


