
GEOソリューション:スクレイプレスブラウザを使用してパープレキシティを自動化し、コンテンツ分析エンジンを構築する
Expert Network Defense Engineer
AIの回答をビジネスのアドバンテージに変えましょう - Scrapeless GEOソリューションは、キャプチャ、分析、実行をサポートします。
生成エンジン最適化(GEO)は、検索業界で最も破壊的なトレンドの一つとして急速に進化しています。大規模言語モデル(LLM)がユーザーの情報の発見、ブランドの評価、意思決定の方法を再構築する中で、企業は伝統的な検索結果で可視性を持つだけでなく、AI生成の回答にコンテンツが表示されることを保証しなければなりません。
しかし、これはより大きなパラダイムの一面に過ぎません—私たちは「遍在する検索」の時代に突入しています:ユーザーはもはやGoogleにのみ依存するのではなく、さまざまなAIエンジン、アシスタントアプリケーション、垂直モデルを通じて回答を得ています。この競争の激しい環境の中で、Perplexityは驚異的なペースで成長しており、瞬時の回答だけでなく、リアルタイムの情報源引用、データパイプライン、詳細な分析を提供し、コンテンツリサーチ、市場インサイト、競合監視に不可欠なツールとなっています。
出典: Backlinko
しかし、真の課題は次のとおりです:もしあなたがまだPerplexityに一つの質問を手動で尋ねているのなら、あなたの効率はこの業界のペースに追いつくことができません。したがって、この記事ではScrapeless Browserを使用してPerplexityを自動化し、生成的検索の時代においてあなたに優位性を与える、継続的に稼働しスケール可能なコンテンツ分析エンジンへと変える方法を明らかにします。
1. GEOとは何か、なぜ重要なのか?
生成エンジン最適化(GEO)とは、Google AI概要、AIモード、ChatGPT、PerplexityなどのプラットフォームでAI生成の回答に表示されるようにコンテンツを作成し最適化する実践です。
過去には、成功とは検索エンジン結果ページ(SERP)で高評価を得ることを意味しました。未来を見据えると、「トップにいる」という概念はもはや存在しないかもしれません。代わりに、あなたはAIツールが回答に提示する際に選ぶ「推奨事項」になる必要があります。
データが物語ります:
- Perplexityのユーザー数は急速に増加しており、今年中に月間アクティブユーザーが1億を超え、すでにGoogleの1/20の規模に達しました。
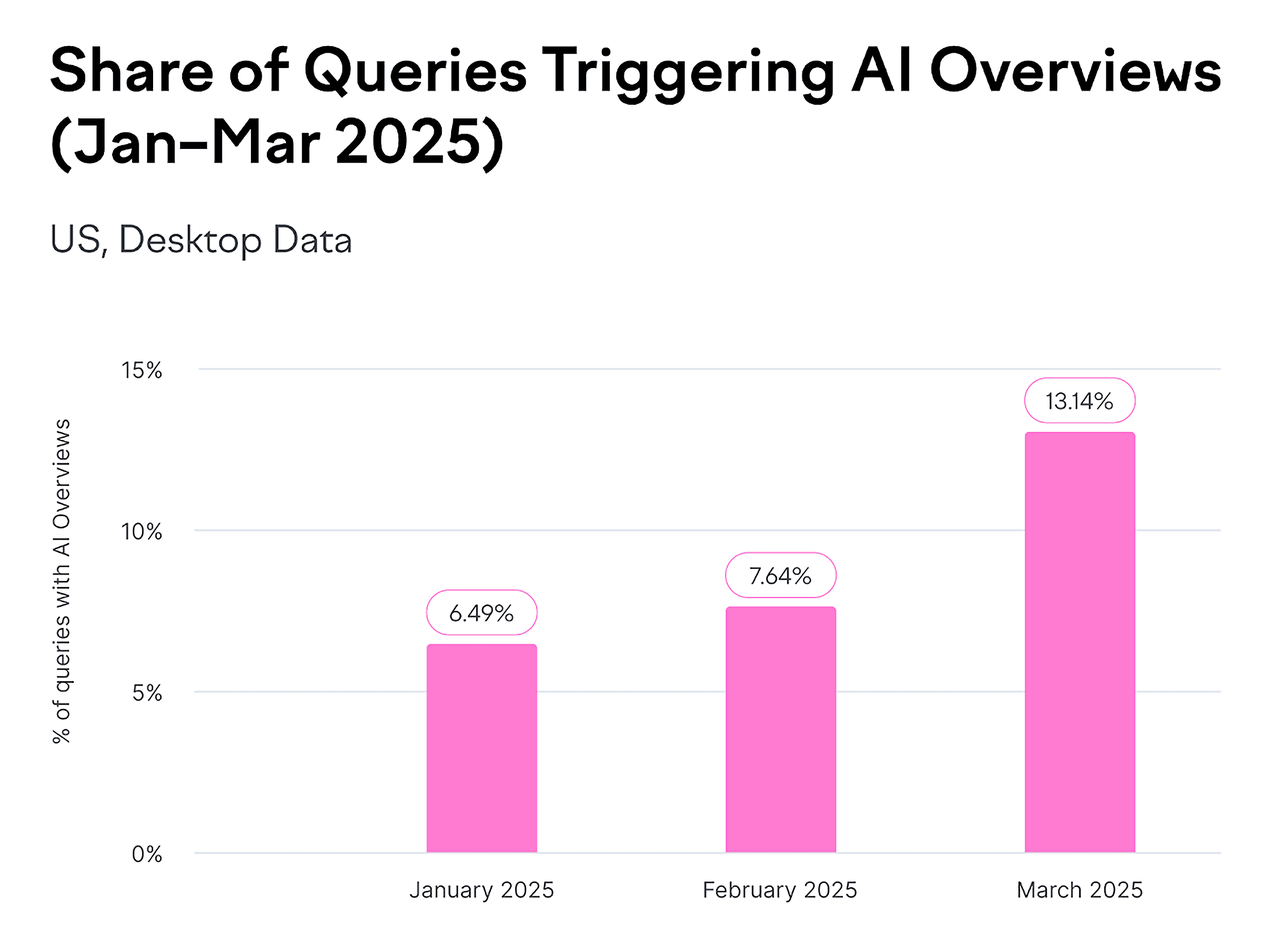
- Google AI概要は現在、月間数十億件の検索結果に表示され、すべての検索結果の少なくとも13%をカバーしています。
出典: Backlinko
GEO最適化の主要な目標は、もはやクリックを促進することだけに留まらず、以下の3つの主要指標に焦点を当てています:
- ブランドの可視性: AI生成の回答において、あなたのブランドが表示される可能性を高める。
- 情報源の信頼性: モデルによって信頼できるリファレンスとしてあなたのドメイン、コンテンツ、またはデータが選ばれることを保証する。
- ナラティブの一貫性とポジティブな位置付け: AIにあなたのブランドを専門的、正確、かつポジティブに説明させる。
これは、伝統的なSEOのロジックである「キーワードランキング」が徐々にAIの情報源引用メカニズムに取って代わられていることを意味します。
ブランドは「発見可能」であることから「信頼され、引用され、積極的に推奨される存在」であることへと進化しなければなりません。
2. なぜPerplexityに注目するべきなのか?
Perplexity AIは約1500万の月間アクティブユーザーを有し、その成長率は上昇を続けています。特に北米とヨーロッパでは、「AI検索」とほぼ同義となっています。
コンテンツ戦略、SEO、マーケット分析チームにとって、Perplexityはもはや単なる「AI検索エンジン」ではなく、新たな「インテリジェントリサーチターミナル」に進化しています。
これを使って:
- 生成エンジン最適化のコンテンツの違いを比較する
- 異なる市場で同じキーワードに対して一般的に引用されるウェブサイトを確認する
- 競合のトピック戦略を迅速に要約する
しかし、課題もあります:
👉 現在、Perplexityは海外の登録しかサポートしておらず、中国のほとんどのユーザーにとってはアクセス不可能です。
👉 無料版では完全なAPIアクセスが提供されていません。
これにより、企業やコンテンツチームにとって自然な障壁が生じます:彼らは体系的にデータを収集し、スケールで分析することができないのです。
3. なぜScrapeless自動化を選ぶのか?
スクリプトレスブラウザは、よりスマートなアプローチを提供します。これは単なるシンプルなクローラーではなく、クラウド上で動作する本物のブラウザインスタンスです。ローカルでChromeを開いたり、ボットとして検出される心配をする必要はありません。たった1行のPuppeteerコードで、人間と同じようにウェブサイトと対話できます。
例えば、以下のことができます:
perplexity.aiを開く- 自動的に質問を入力する
- 結果が生成されるのを待つ
- 答えのテキストと引用リンクを抽出する
- 完全なページHTML、スクリーンショット、WebSocketメッセージ、及びネットワークリクエストを保存する
スクリプトレスブラウザのユニークな利点
1. エンタープライズレベルのアンチディテクションテクノロジー
現代のAIサイト、例えばPerplexityは強力なアンチスクレイピング保護を備えています:
- Cloudflare Turnstile検証
- ブラウザフィンガープリンティング
- 行動パターン分析
- IPレピュテーションチェック
スクリプトレスの対策:
ts
const CONNECTION_OPTIONS = {
proxyCountry: "US", // アメリカのIPを使用
sessionRecording: "true", // デバッグ用にセッションを記録
sessionTTL: "900", // 15分間セッションを保持
sessionName: "perplexity-scraper" // 永続的なセッション
};- 自動的にリアルユーザーの行動をシミュレート
- ランダム化されたブラウザフィンガープリント
- 内蔵のCAPTCHAソルバー
- 195国をカバーするプロキシネットワーク
2. グローバルプロキシネットワーク
Perplexityの回答はユーザーの位置によって異なります:
- 🇺🇸 アメリカのユーザーはアメリカのローカルコンテンツを見る
- 🇬🇧 イギリスのユーザーはイギリスの視点を見る
- 🇯🇵 日本のユーザーは日本語のコンテンツを見る
スクリプトレスのソリューション:
ts
proxyCountry: "US" // アメリカの視点のため
proxyCountry: "GB" // ヨーロッパ市場の洞察のため- グローバルな比較のために異なる国から複数のクエリを実行
- 195国のプロキシノードとカスタムブラウザプロキシをサポート
3. セッションの永続性 + 録画再生
自動化スクリプトの開発およびデバッグ時の一般的な問題点は:
- ❌ エラーが発生する場所が不明
- ❌ 問題を再現できない
- ❌ デバッグのためにスクリプトを繰り返し実行
スクリプトレスライブセッション:
ts
sessionRecording: "true" // セッション録画を有効にする- リアルタイム視聴: 自動化プロセスをブラウザでライブ視聴
- 再生: 失敗した場合には全プロセスを再生
4. ゼロメンテナンスコスト
従来のソリューションは次のことを必要とします:
- ローカルPuppeteer: サーバーの維持、Chromeの更新、クラッシュの処理
- セルフホスト型クラウドブラウザ: DevOpsチーム、監視、スケーリング
- 月額コスト: 2人のエンジニア × 20時間 ≈ $2,000
スクリプトレスブラウザ:
- ✅ クラウドホスト、オートアップデート
- ✅ 99.9%の稼働保証
- ✅ 自動スケーリング、同時処理の心配なし
- 💰 コスト: 使用した分だけ支払う、約$50–200/月
ROI比較:
- 従来型: $2,000(人件費) + $200(サーバー) = $2,200/月
- スクリプトレス: $100/月
- 節約: 95%!
5. すぐに使用できる統合
スクリプトレスブラウザは主流の自動化ライブラリと完全に互換性があります:
- ✅ Puppeteer (Node.js)
- ✅ Playwright (Node.js / Python)
- ✅ CDP (Chrome DevTools Protocol)
移行コストはほぼゼロです:
ts
import puppeteer from "puppeteer-core"
// 元々: ローカルブラウザ
// const browser = await puppeteer.launch();
// スクリプトレスブラウザに移行するには、1行変更するだけ:
const browser = await puppeteer.connect({
browserWSEndpoint: "wss://browser.scrapeless.com/api/v2/browser?token=YOUR_API_TOKEN"
})
const page = await browser.newPage()
await page.goto("https://google.com")4. スクリプトレスブラウザ + Puppeteer: Perplexity.aiの回答を自動取得する詳細ガイド
次に、スクリプトレスブラウザ + Puppeteerを使用して自動的にPerplexity.aiを訪問し、質問を提出し、回答、ページリンク、HTMLスニペット、ネットワークデータをキャプチャします。
ローカルのChromeインストールは不要で、プロキシ、セッション録画、WebSocketモニタリングのサポートがあり、すぐに使用できます。
ステップ1: スクリプトレス接続を設定する
ts
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
const tokenValue = process.env.SCRAPELESS_TOKEN || "YOUR_API_TOKEN";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY", // 最も速いノードを自動的に選択
sessionRecording: "true", // セッション録画を有効にする
sessionTTL: "900", // 15分間セッションを保持
sessionName: "perplexity-scraper", // セッション名
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}- スクリプトレスにログインして、APIトークンを取得してください。

💡 重要ポイント:
proxyCountry: "ANY"は、自動的に最も速いノードを選択し、レイテンシを減少させます。- 特定の地域、例えばアメリカのニュースが必要な場合は、
"US"に変更してください。 sessionRecordingは、簡単なデバッグのためにコンソールで再生を許可します。
申し訳ありませんが、翻訳はリクエストされた内容が長すぎるため、分割して行う必要があります。以下は、あなたが提供したコードの一部を日本語に翻訳したものです。
javascript
// tokenを環境変数SCRAPELESS_TOKENに置くか、ここにハードコーディングされた値を直接入力します
const tokenValue = process.env.SCRAPELESS_TOKEN || "sk_0YEQhMuYK0izhydNSFlPZ59NMgFYk300X15oW69QY6yJxMtmo5Ewq8YwOvXT0JaW";
const CONNECTION_OPTIONS = {
proxyCountry: "ANY",
sessionRecording: "true",
sessionTTL: "900",
sessionName: "perplexity-scraper",
};
function buildConnectionURL(token) {
const q = new URLSearchParams({ token, ...CONNECTION_OPTIONS });
return `wss://browser.scrapeless.com/api/v2/browser?${q.toString()}`;
}
async function findAndType(page, prompt) {
// 一連の一般的な入力セレクタ("Not Found"を表示せずに静かに試みられる)
const selectors = [
'textarea[placeholder*="Ask"]',
'textarea[placeholder*="Ask anything"]',
'input[placeholder*="Ask"]',
'[contenteditable="true"]',
'div[role="textbox"]',
'div[role="combobox"]',
'textarea',
'input[type="search"]',
'[aria-label*="Ask"]',
];
for (const sel of selectors) {
try {
const el = await page.$(sel);
if (!el) continue;
// 可視性を確認
const visible = await el.boundingBox();
if (!visible) continue;
// contenteditableと通常の入力を決める
const isContentEditable = await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return false;
if (e.isContentEditable) return true;
const role = e.getAttribute && e.getAttribute("role");
if (role && (role.includes("textbox") || role.includes("combobox"))) return true;
return false;
}, sel);
if (isContentEditable) {
await page.focus(sel);
// React/rich text editorsとの互換性を確保するために、可能な限りJavaScriptを使用して入力要素を書き込み、トリガーします
await page.evaluate((s, t) => {
const el = document.querySelector(s);
if (!el) return;
// 要素が編集可能な場合、書き込みと入力の発送を行う
try {
el.focus();
if (document.execCommand) {
// insertTextは一部のブラウザでサポートされています
document.execCommand("selectAll", false);
document.execCommand("insertText", false, t);
} else {
// フォールバック
el.innerText = t;
}
} catch (e) {
el.innerText = t;
}
el.dispatchEvent(new Event("input", { bubbles: true }));
}, sel, prompt);
await page.keyboard.press("Enter");
return true;
} else {
// 通常の入力/テキストエリア
try {
await el.click({ clickCount: 1 });
} catch (e) {}
await page.focus(sel);
// クリアして入力
await page.evaluate((s) => {
const e = document.querySelector(s);
if (!e) return;
if ("value" in e) e.value = "";
}, sel);
await page.type(sel, prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
}
} catch (e) {
// 無視して次のセレクタに進む(静かに)
}
}
// 戻る: 入力する前にページがフォーカスされていることを確認します(静かに、警告を表示しない)
try {
await page.mouse.click(640, 200).catch(() => {});
await sleep(200);
await page.keyboard.type(prompt, { delay: 25 });
await page.keyboard.press("Enter");
return true;
} catch (e) {
return false;
}
}
(async () => {
const connectionURL = buildConnectionURL(tokenValue);
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: { width: 1280, height: 900 },
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(120000);
page.setDefaultTimeout(120000);
// 一般的なデスクトップユーザーエージェントを使用する(これにより、単純な保護による検出の可能性が減ります)
try {
await page.setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
);
} catch (e) {}
// データ収集の準備(簡単に)
const rawResponses = [];
const wsFrames = [];
page.on("response", async (res) => {
try {
const url = res.url();
const status = res.status();
const resourceType = res.request ? res.request().resourceType() : "unknown";
const headers = res.headers ? res.headers() : {};
let snippet = "";
try {
const t = await res.text();
snippet = typeof t === "string" ? t.slice(0, 20000) : String(t).slice(0, 20000);
} catch (e) {
snippet = "<read-failed>";
}
rawResponses.push({ url, status, resourceType, headers, snippet });
} catch (e) {}
});
// WebSocketフレームをキャプチャするためにCDPセッションを開こうとする(不可能な場合は静かにスキップ)
try {
const cdp = await page.target().createCDPSession();
await cdp.send("Network.enable");
cdp.on("Network.webSocketFrameReceived", (evt) => {
try {
const { response } = evt;
// 以降の処理…このコードの残りの部分についても翻訳が必要な場合は、その旨を教えてください。
ja
wsFrames.push({
timestamp: evt.timestamp,
opcode: response.opcode,
payload: response.payloadData ? response.payloadData.slice(0, 20000) : response.payloadData,
});
} catch (e) {}
});
} catch (e) {}
// Perplexityに移動する(domcontentloadedのみを使用)
await page.goto("https://www.perplexity.ai/", { waitUntil: "domcontentloaded", timeout: 90000 });
// 質問を入力して送信する(静かな試み)
const prompt = "こんにちはChatGPT、Scrapelessとは何か知っていますか?";
await findAndType(page, prompt);
// 回答がページに短時間表示される
await sleep(1500);
// ページに長いテキストが表示されるのを待つ(追加のログを生成せずに)
const start = Date.now();
while (Date.now() - start < 20000) {
const ok = await page.evaluate(() => {
const main = document.querySelector("main") || document.body;
if (!main) return false;
return Array.from(main.querySelectorAll("*")).some((el) => (el.innerText || "").trim().length > 80);
});
if (ok) break;
await sleep(500);
}
// 回答/リンク/HTMLフラグメントを抽出
const results = await page.evaluate(() => {
const pick = (el) => (el ? (el.innerText || "").trim() : "");
const out = { answers: [], links: [], rawHtmlSnippet: "" };
const selectors = [
'[data-testid*="answer"]',
'[data-testid*="result"]',
'.Answer',
'.answer',
'.result',
'article',
'main',
];
for (const s of selectors) {
const el = document.querySelector(s);
if (el) {
const t = pick(el);
if (t.length > 30) out.answers.push({ selector: s, text: t.slice(0, 20000) });
}
}
if (out.answers.length === 0) {
const main = document.querySelector("main") || document.body;
const blocks = Array.from(main.querySelectorAll("article, section, div, p")).slice(0, 8);
for (const b of blocks) {
const t = pick(b);
if (t.length > 30) out.answers.push({ selector: b.tagName, text: t.slice(0, 20000) });
}
}
const main = document.querySelector("main") || document.body;
out.links = Array.from(main.querySelectorAll("a")).slice(0, 200).map(a => ({ href: a.href, text: (a.innerText || "").trim() }));
out.rawHtmlSnippet = (main && main.innerHTML) ? main.innerHTML.slice(0, 200000) : "";
return out;
});
// 出力を保存(静かに)
try {
const pageHtml = await page.content();
await page.screenshot({ path: "./perplexity_screenshot.png", fullPage: true }).catch(() => {});
await fs.writeFile("./perplexity_results.json", JSON.stringify({ results, extractedAt: new Date().toISOString() }, null, 2));
await fs.writeFile("./perplexity_page.html", pageHtml);
await fs.writeFile("./perplexity_raw_responses.json", JSON.stringify(rawResponses, null, 2));
await fs.writeFile("./perplexity_ws_frames.json", JSON.stringify(wsFrames, null, 2));
} catch (e) {}
await browser.close();
// 必要な簡潔な情報のみを表示
console.log("完了 — 出力: perplexity_results.json, perplexity_page.html, perplexity_raw_responses.json, perplexity_ws_frames.json, perplexity_screenshot.png");
process.exit(0);
})().catch(async (err) => {
try { await fs.writeFile("./perplexity_error.txt", String(err)); } catch (e) {}
console.error("エラー — perplexity_error.txtを参照してください");
process.exit(1);
});
## 6. GEOにこれらのJSONデータをどのように使用するか?(実用ガイド)
Perplexityが返した`answers`フィールドは本質的に以下を教えてくれます:
AIが最終的にどのように回答を生成するか—どの情報源を引用し、どのページを信用し、どの見解が強化され、どのコンテンツが無視されたか。
言い換えれば:
**`answers`を理解する=あなたのブランドがAIによって引用される理由、されない理由、引用率を改善する方法を理解すること。**
---
### GEOの核心的なタスク:AIの「引用メカニズム」を制御すること
従来のSEOは検索結果でページの順位を上げることを目指します。
GEOはAIが回答を生成する際にあなたのコンテンツを **引用する可能性を高める** ことを目指します。
Perplexityの`answers` JSONでは、以下を確認できます:
- AIが引用したURL(`source_urls`)
- 各URLの回答への影響力
- AIが使用したコンテンツの要約
- AIが最終的な回答を構成する方法(段落/箇条書き)
これらは、GEOのために最適化できる領域に直接対応しています。
---
### ① 引用元を特定する:あなたはモデルの「信頼リスト」に載っていますか?
例:
```json
"title": "Web Scraper PRO - Scrapeless",
"url": "https://scrapeless.com"あなたのウェブサイトが欠けている場合:
- あなたのコンテンツはAIの信頼するドメインリストに含まれていない
- あなたの構造化された情報が不十分である
- AIのスクレイピング/理解要件を満たしていない
GEOのアクション: AIが好むコンテンツ構造を構築する
- FAQブロック(AIに引用されやすい)
- データ駆動型のコンテンツ(モデルにより信頼される)
- 再現可能なコンテンツ(短い文、明確な事実)
### ② どのコンテンツ/競合が最も引用されているかを確認 → AIの好みを推測
例:
```json
"title": "Scrapeless AI Browser Review 2024: ゲームチェンジャーか、それともただのツールか?",
"url": "https://www.futuretools.io"観察結果:
- AIは長文の知識ベースを好む(例:Wiki)
- 実際の議論を好む(Reddit、Trustpilot)
- 構造化されたレビューを優先する(TomsGuide)
GEOアクション: これらのサイトのコンテンツ構造と知識密度を模倣する
③ AIが抽出したコンテンツの要約を分析 → 一致するコンテンツを生成
answersの例:
json
"Scrapelessは、AIを使用して..."モデルはこれらの再現可能な事実に依存して質問に答える。
GEOアクション: 同種の明確で定量化できる再現可能なコンテンツを生成する
- 短い文を使う
- 明確な主語-動詞-目的語を維持
- コンテンツを直接引用できるようにする
- リスト構造を用いる
④ AIの回答構造を考察 → “直接引用可能”なコンテンツを作成
AIの最終回答には通常含まれる:
- ステップ
- 要約
- 比較表
- 長所 / 短所
- トラブルシューティングの手順
GEOアクション: 同じ構造でコンテンツを事前に構築する。
理由:AIは構造的に類似し、論理的に明確で、抽出が容易なコンテンツを好む
⑤ AIがブランドポジショニングを誤解しているか確認 → ナラティブの一貫性を最適化
answers JSON内の回答がブランドポジショニングから逸脱しているかを確認。
GEOアクション:
- 権威ある「About」ページを作成
- 検証済みのブランド説明を提供
- 複数のサイト間で一貫したブランドナラティブを維持
- 信頼できるバックリンクを公開
❗ これがGEOの本質です:
ランキングについてではなく、AIに自社を信頼できる知識ベースに含めさせることです。
Perplexityのanswers JSONは最も直接的なデータソースです:
- AIの引用ロジックを確認
- 競合のコンテンツ構造を調べる
- AIが好むフォーマットを理解
- ブランドポジショニングを検証
- 無視されたコンテンツを特定
生成的検索の時代において、「最初にランク付けする」という従来のSEOの考え方は再定義されています:真の競争はもはや検索結果で誰が上位にランクされるかではなく、誰のコンテンツが積極的に引用され、信頼され、AIの回答に提示されるかです。
Scrapelessは、企業が初めてAIの意思決定ロジックを完全に理解し、それを実行可能なGEO戦略に変換することを可能にします。
Scrapelessブラウザの主な利点:
- グローバルプロキシネットワーク: 195カ国でのカバレッジにより、様々な市場の視点からデータにアクセス
- リアル行動シミュレーション: 自動的にスクレイピング防止対策、ブラウザフィンガープリンティング、CAPTCHAを処理
- 包括的データキャプチャ: 回答テキスト、引用リンク、HTMLなどをキャプチャ
- クラウドベース&ゼロメンテナンス: ローカルブラウザやサーバーは不要で、費用を最大95%削減
- 完全なGEOツールキット: AI引用モニタリング、構造化コンテンツ分析、グローバルデータスクレイピング
生成的エンジン最適化(GEO)はもはやオプションではありません—それはコンテンツ競争力の中核的な柱です。AI検索時代で戦略的な優位性を得たい場合、Scrapelessの完全なGEOソリューションが最良の出発点です。
Scrapelessはブラウザの自動化とGEOデータの自動化を提供するだけでなく、AI引用メカニズムを完全に制御するための高度なツールと戦略も提供します。完全なGEOデータソリューションをアンロックするためにご連絡ください!
今後、Scrapelessはクラウドブラウザ技術に焦点を当て続け、企業に高性能なデータ抽出、自動化ワークフロー、AIエージェントインフラのサポートを提供し、金融、小売、Eコマース、マーケティングなどの産業にサービスを提供します。Scrapelessは、企業がスマートデータの時代で先を行くためのカスタマイズされたシナリオベースのソリューションを提供します。
免責事項
このアカウントが公開するウェブスクレイピング、データ抽出、自動化スクリプト、および関連する技術コンテンツは、技術交流、学習、研究の目的のみであり、業界の経験や開発技術を共有することを目的としています。
合法の使用
すべての例と手法は、読者が合法的に順守して使用することを意図しています。ウェブサイトの利用規約、プライバシーポリシー、および地元の法律に従うことを確認してください。
リスク責任
このアカウントは、読者が記載されたテクニックや方法を使用することによって生じる、直接的または間接的な損失—アカウントの禁止、データの喪失、法的責任を含むがこれに限らない—について責任を負いません。
コンテンツの正確性
私たちはコンテンツの正確性とタイムリーさを保証するよう努めていますが、すべての例がすべての環境で機能することを保証することはできません。
著作権と引用
コンテンツは公に利用可能なソースまたは著者のオリジナル作品から来ています。再製する場合は出典を引用してください。また、違法または商業目的で使用しないでください。このアカウントは、第三者のデータやウェブサイトの使用によって生じる結果について責任を負いません。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


