
Node-Fetch APIを使ったNode.jsでのHTTPリクエストの送り方
Specialist in Anti-Bot Strategies
私たちの現在のウェブサイトは、画像、CSS、フォント、JavaScript、JSONデータなどの膨大な数の異なるリソースに依存しているのが一般的です。しかし、世界初のウェブサイトはHTMLのみで記述されていました。
JavaScriptは優れたクライアントサイドスクリプト言語として、ウェブサイトの進化において重要な役割を果たしてきました。XMLHttpRequestまたはXHRオブジェクトの助けを借りて、JavaScriptはページをリロードすることなくクライアントとサーバー間の通信を実現できます。
しかし、この動的なプロセスはFetch APIによって課題を突きつけられています。Fetch APIとは何でしょうか?Node.jsでFetch APIをどのように使用するか?Fetch APIがより良い選択肢である理由とは?
この記事から今すぐ答えを得始めましょう!
Node.jsにおけるHTTPリクエストとは?
Node.jsにおいて、HTTPリクエストはウェブアプリケーションの構築やウェブサービスとのやり取りにおいて基本的な部分です。これにより、クライアント(ブラウザや他のアプリケーションなど)はサーバーにデータを送信したり、サーバーからデータのリクエストを行うことができます。これらのリクエストは、ウェブ上のデータ通信の基礎であるHypertext Transfer Protocol(HTTP)を使用します。
- HTTPリクエスト: HTTPリクエストは、通常、データを取得する(ウェブページやAPIレスポンスなど)ため、またはサーバーにデータを送信する(フォームを送信するなど)ために、クライアントからサーバーに送信されます。
- HTTPメソッド: HTTPリクエストには通常、クライアントがサーバーに実行してほしいアクションを示すメソッドが含まれています。一般的なHTTPメソッドには以下が含まれます。
- GET: サーバーからデータを取得します。
- POST: サーバーにデータを送信します(例:フォームの送信)。
- PUT: サーバー上の既存のデータを更新します。
- DELETE: サーバーからデータを削除します。
- Node.js HTTPモジュール: Node.jsは、HTTPリクエストを処理するための組み込みのhttpモジュールを提供しています。このモジュールを使用すると、HTTPサーバーを作成し、リクエストをリッスンし、それに応答することができます。
Node.jsがウェブスクレイピングと自動化に最適な理由
Node.jsはその独自の特性、堅牢なエコシステム、非同期非ブロッキングアーキテクチャにより、ウェブスクレイピングと自動化タスクのための主要なテクノロジーの1つになっています。
Node.jsがウェブスクレイピングと自動化に最適な理由を解明しましょう!
- 非同期非ブロッキングI/O
- 速度と効率性
- ライブラリとフレームワークの豊富なエコシステム
- ヘッドレスブラウザによる動的コンテンツの処理
- クロスプラットフォーム互換性
- リアルタイムデータ処理
- 高速開発のためのシンプルな構文
- プロキシローテーションと検知回避のサポート
Node-Fetch APIとは?
node-fetchは、Fetch APIをNode.js環境にもたらす軽量なモジュールです。HTTPリクエストの作成とレスポンスの処理のプロセスを簡素化します。
Fetch APIはPromiseに基づいて構築されており、ウェブサイトからのデータのスクレイピング、RESTful APIとのやり取り、タスクの自動化など、非同期操作に適しています。
Node.JSでFetch APIを使用する方法
Fetch APIは、従来のXMLHttpRequestオブジェクトと比較して、より効率的で柔軟な方法でネットワークリクエストを処理するように設計された、最新のPromiseベースのインターフェースです。
現代のブラウザではネイティブにサポートされているため、追加のライブラリやプラグインは必要ありません。このガイドでは、Fetch APIを使用してGETリクエストとPOSTリクエストを実行する方法、およびレスポンスとエラーを効果的に管理する方法について説明します。
💬 注意: コンピューターにNode.jsがインストールされていない場合は、最初にインストールする必要があります。お使いのオペレーティングシステムに適したNode.jsインストールパッケージはこちらからダウンロードできます。推奨されるNode.jsのバージョンは18以上です。
ステップ1. Node.jsプロジェクトの初期化
まだプロジェクトを作成していない場合は、次のコマンドを使用して新しいプロジェクトを作成できます。
Bash
mkdir fetch-api-tutorial
cd fetch-api-tutorial
npm init -ypackage.jsonファイルを開き、typeフィールドを追加してmoduleに設定します。
JSON
{
"name": "fetch-api-tutorial",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}ステップ2. node-fetchライブラリのダウンロードとインストール
これはNode.jsでFetch APIを使用するためのライブラリです。次のコマンドを使用してnode-fetchライブラリをインストールできます。
Bash
npm install node-fetchダウンロードが完了したら、Fetch APIを使用してネットワークリクエストを送信し始めることができます。プロジェクトのルートディレクトリに新しいファイルindex.jsを作成し、次のコードを追加します。
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts')
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));次のコマンドを実行してコードを実行します。
Bash
node index.js次の出力が表示されます。
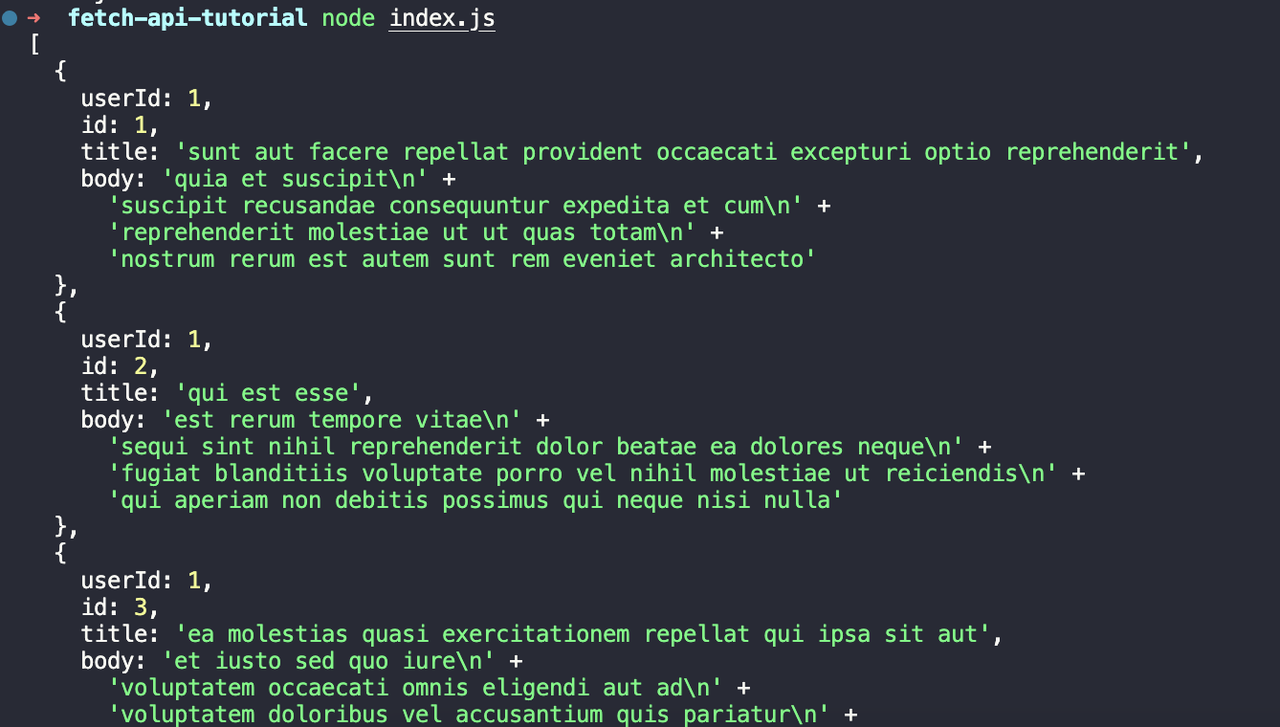
ステップ3. Fetch APIを使用してPOSTリクエストを送信する
Fetch APIを使用してPOSTリクエストを送信するには、次の方法を参照してください。プロジェクトのルートディレクトリに新しいファイルpost.jsを作成し、次のコードを追加します。
JavaScript
import fetch from 'node-fetch';
const postData = {
title: 'foo',
body: 'bar',
userId: 1,
};
fetch('https://jsonplaceholder.typicode.com/posts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(postData),
})
.then((response) => response.json())
.then((data) => console.log(data))
.catch((error) => console.error(error));このコードを分析しましょう。
- まず、送信したいデータを含む
postDataというオブジェクトを定義します。 - 次に、
fetch関数を使用して、https://jsonplaceholder.typicode.com/postsにPOSTリクエストを送信し、2番目のパラメーターとして構成オブジェクトを渡します。 - 構成オブジェクトには、リクエスト
method、リクエストheaders、リクエストbodyが含まれています。
次のコマンドを実行してコードを実行します。
Bash
node post.js次の出力が表示されます。

ステップ4. Fetch APIのレスポンス結果とエラーの処理
プロジェクトのルートディレクトリに新しいファイルresponse.jsを作成し、次のコードを追加する必要があります。
JavaScript
import fetch from 'node-fetch';
fetch('https://jsonplaceholder.typicode.com/posts-response')
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
})
.then((data) => console.log(data))
.catch((error) => console.error(error));上記のコードでは、最初に間違ったURLアドレスを入力してHTTPエラーを発生させます。次に、thenメソッドで結果のレスポンスのステータスコードをチェックし、ステータスコードが200でない場合はエラーをスローします。最後に、catchメソッドでエラーをキャッチして出力します。
次のコマンドを実行してコードを実行します。
Bash
node response.jsコードの実行後、次の出力が表示されます。

ウェブスクレイピングにおける3つの一般的な課題
1. CAPTCHA
CAPTCHA(Completely Automated Public Turing tests to tell Computers and Humans Apart)は、ウェブスクレイパーなどの自動化されたシステムがウェブサイトにアクセスするのを防ぐために設計されています。通常、ユーザーはパズルを解いたり、画像内のオブジェクトを特定したり、歪んだ文字を入力したりすることで、人間であることを証明する必要があります。
2. 動的コンテンツ
多くの最新のウェブサイトは、React、Angular、Vue.jsなどのJavaScriptフレームワークを使用してコンテンツを動的に読み込んでいます。これは、ブラウザに表示されるコンテンツが多くの場合、ページの読み込み後にレンダリングされることを意味し、静的なHTMLに依存する従来の方法ではスクレイピングが困難になります。
3. IPブロック
ウェブサイトは多くの場合、スクレイピング活動を検出してブロックするための対策を実装しており、最も一般的な方法の1つはIPブロックです。これは、短期間に同じIPアドレスから多数のリクエストが送信されると、ウェブサイトがそのIPをフラグ付けしてブロックする場合に発生します。
Scrapelessスクレイピングツールキット - 高効率スクレイピングツール
Scrapelessは、IPブロック、CAPTCHAの課題、JavaScriptレンダリングなど、ウェブサイトのブロックをリアルタイムで回避できるため、最高の包括的なスクレイピングツールの1つです。IPローテーション、TLSフィンガープリント管理、CAPTCHA解決などの高度な機能をサポートしているため、大規模なウェブスクレイピングに最適です。
ScrapelessがNode.jsウェブスクレイピングプロジェクトを強化する方法
Node.jsとの簡単な統合と検知回避の高い成功率により、Scrapelessは最新のアンチボット対策を回避し、スムーズで途切れることのないスクレイピング操作を保証する信頼性が高く効率的な選択肢となっています。
手動スクレイピングと比べてScrapelessのようなスクレイピングツールキットを使用する利点
- ウェブサイトのブロックの効率的な処理:Scrapelessは、IPブロック、CAPTCHA、JavaScriptレンダリングなどの一般的なアンチスクレイピング対策をリアルタイムで回避できますが、手動スクレイピングでは効率的に処理できません。
- 信頼性と成功率:Scrapelessは、IPローテーションとTLSフィンガープリント管理などの高度な機能を使用して検知を回避し、手動スクレイピングと比較して、より高い成功率と途切れることのないスクレイピングを保証します。
- 簡単な統合と自動化:Node.jsとシームレスに統合し、スクレイピングワークフロー全体を自動化するため、手動データ収集と比較して時間を節約し、人的ミスを削減します。
いくつかの簡単な手順に従うだけで、ScrapelessをNode.jsプロジェクトに統合できます。
スクロールを続けましょう!以下はさらに素晴らしいものになるでしょう!
ScrapelessスクレイピングツールキットをNode.jsプロジェクトに統合する
始める前に、Scrapelessアカウントを登録する必要があります。Scrapelessの詳細については、公式ウェブサイトを参照することもできます。
ステップ1. Node.jsでScrapelessスクレイピングAPIにアクセスする
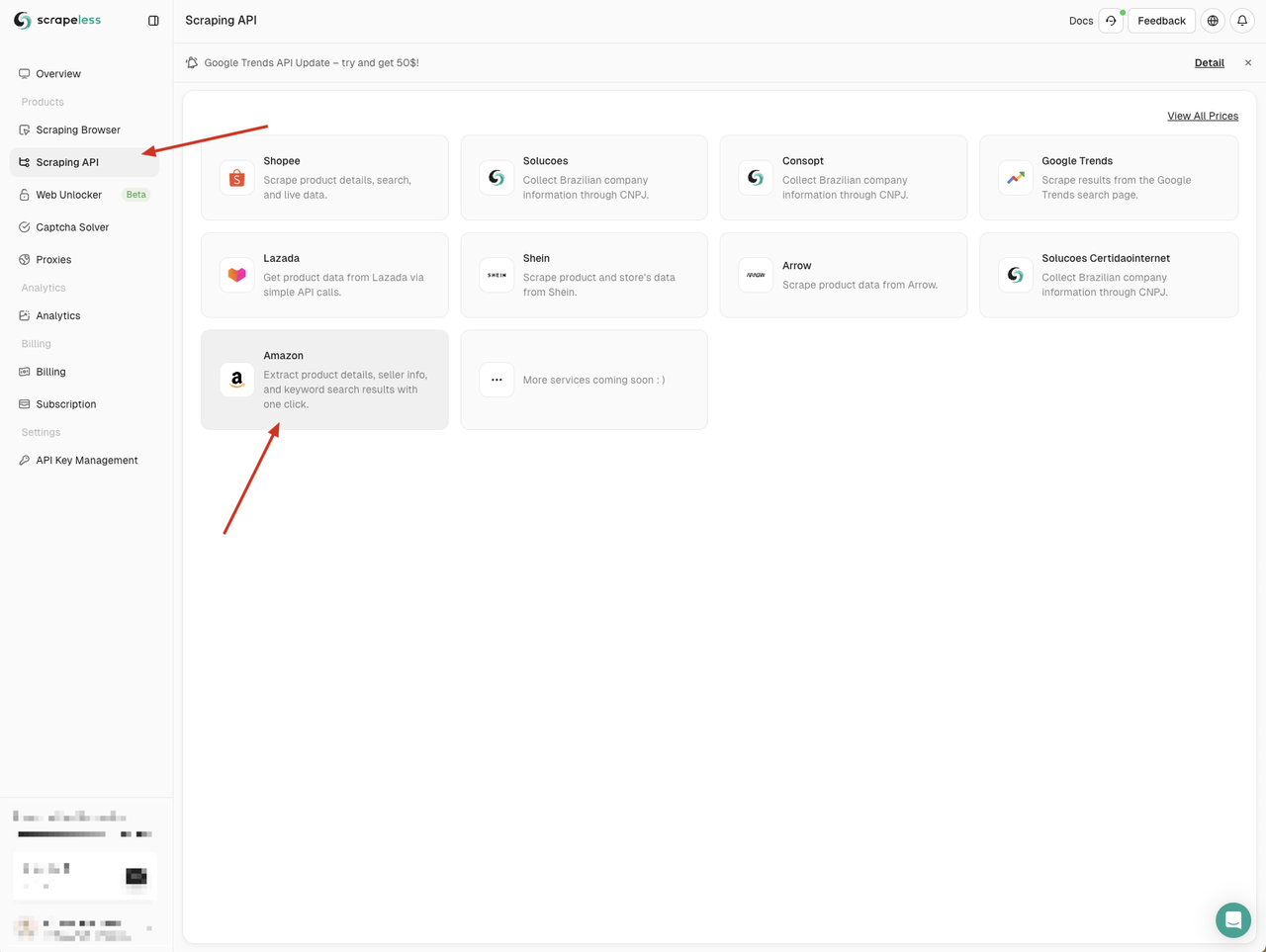
Scrapelessのダッシュボードにアクセスし、左側の「Scraping API」メニューをクリックして、使用したいサービスを選択します。
ここでは「Amazon」サービスを使用できます。
Amazon APIページに入ると、Scrapelessは3つの言語でデフォルトのパラメーターとコード例を提供しています。
- Python
- Go
- Node.js
ここではNode.jsを選択し、コード例をプロジェクトにコピーします。
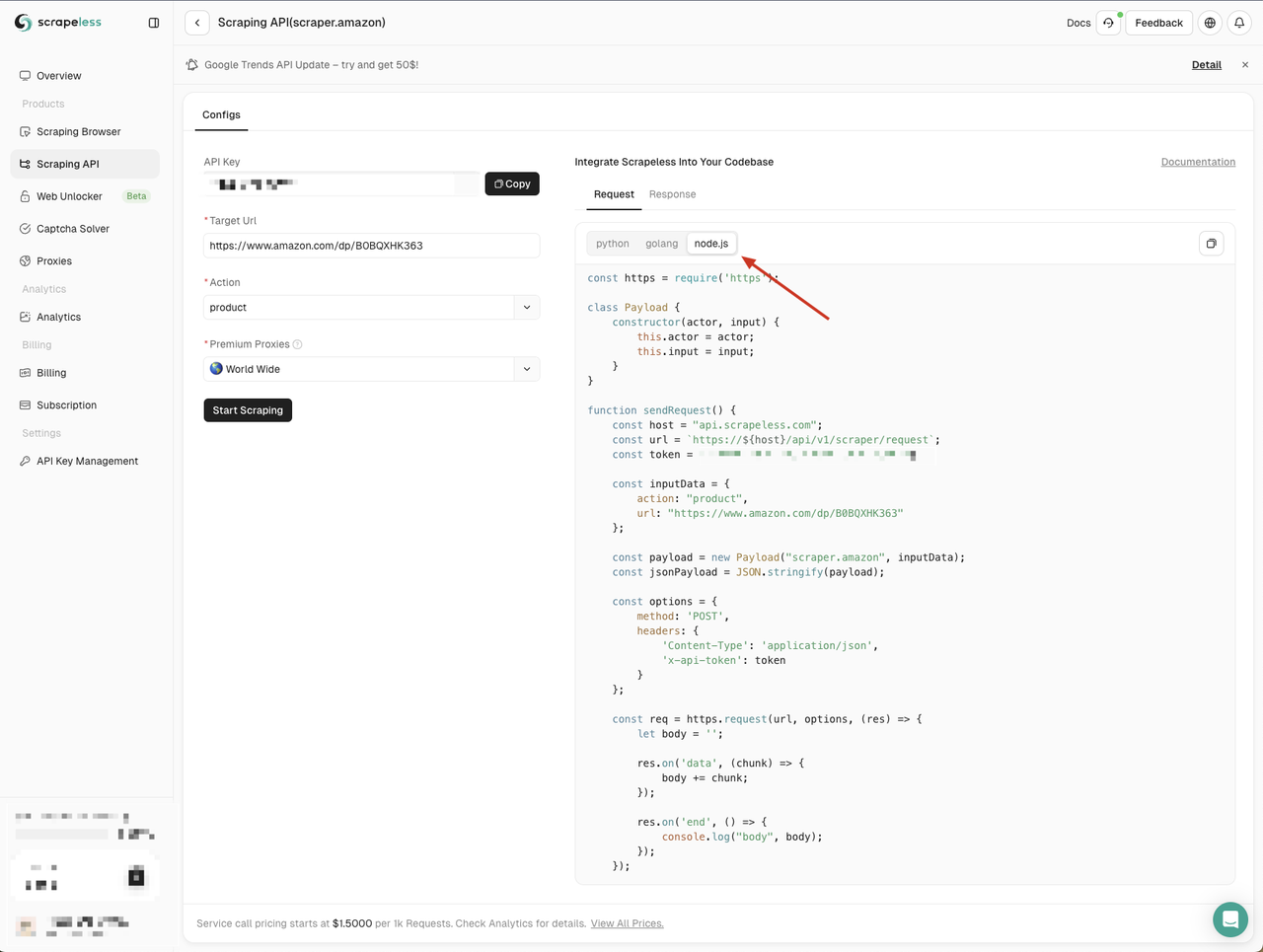
ScrapelessのNode.jsコード例は、デフォルトでhttpモジュールを使用しています。node-fetchモジュールを使用してhttpモジュールを置き換えることで、Fetch APIを使用してネットワークリクエストを送信できます。
まず、プロジェクトにscraping-api-amazon.jsファイルを作成し、Scrapelessによって提供されたコード例を次のコード例で置き換えます。
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/scraper/request`;
const token = ''; // Your API token
const inputData = {
action: 'product',
url: 'https://www.amazon.com/dp/B0BQXHK363',
};
const payload = new Payload('scraper.amazon', inputData);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP Error: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();次のコマンドを実行してコードを実行します。
Bash
node scraping-api-amazon.js Scrapeless APIによって返された結果が表示されます。ここでは単に出力するだけです。必要に応じて返された結果を処理できます。
ステップ2. ウェブアンロッカーを利用して一般的なアンチスクレイピング対策を回避する
Scrapelessは、CAPTCHAバイパス、IPブロックなど、一般的なアンチスクレイピング対策を回避するのに役立つウェブアンロッカーサービスを提供しています。ウェブアンロッカーサービスは、一般的なクロール問題の解決に役立ち、クロールタスクをよりスムーズに行うことができます。
ウェブアンロッカーサービスの有効性を検証するために、最初にcurlコマンドを使用してCAPTCHAを必要とするウェブサイトにアクセスし、次にScrapelessウェブアンロッカーサービスを使用して同じウェブサイトにアクセスして、CAPTCHAが正常に回避できるかどうかを確認できます。
- curlコマンドを使用して、
https://identity.getpostman.com/loginなど、確認コードを必要とするウェブサイトにアクセスします。
Bash
curl https://identity.getpostman.com/login返された結果を見ると、このウェブサイトはCloudflare検証メカニズムに接続されており、ウェブサイトへのアクセスを続けるには検証コードを入力する必要があることがわかります。

- Scrapelessウェブアンロッカーサービスを使用して同じウェブサイトにアクセスします。
- Scrapelessダッシュボードにアクセスします。
- 左側のウェブアンロッカーメニューをクリックします
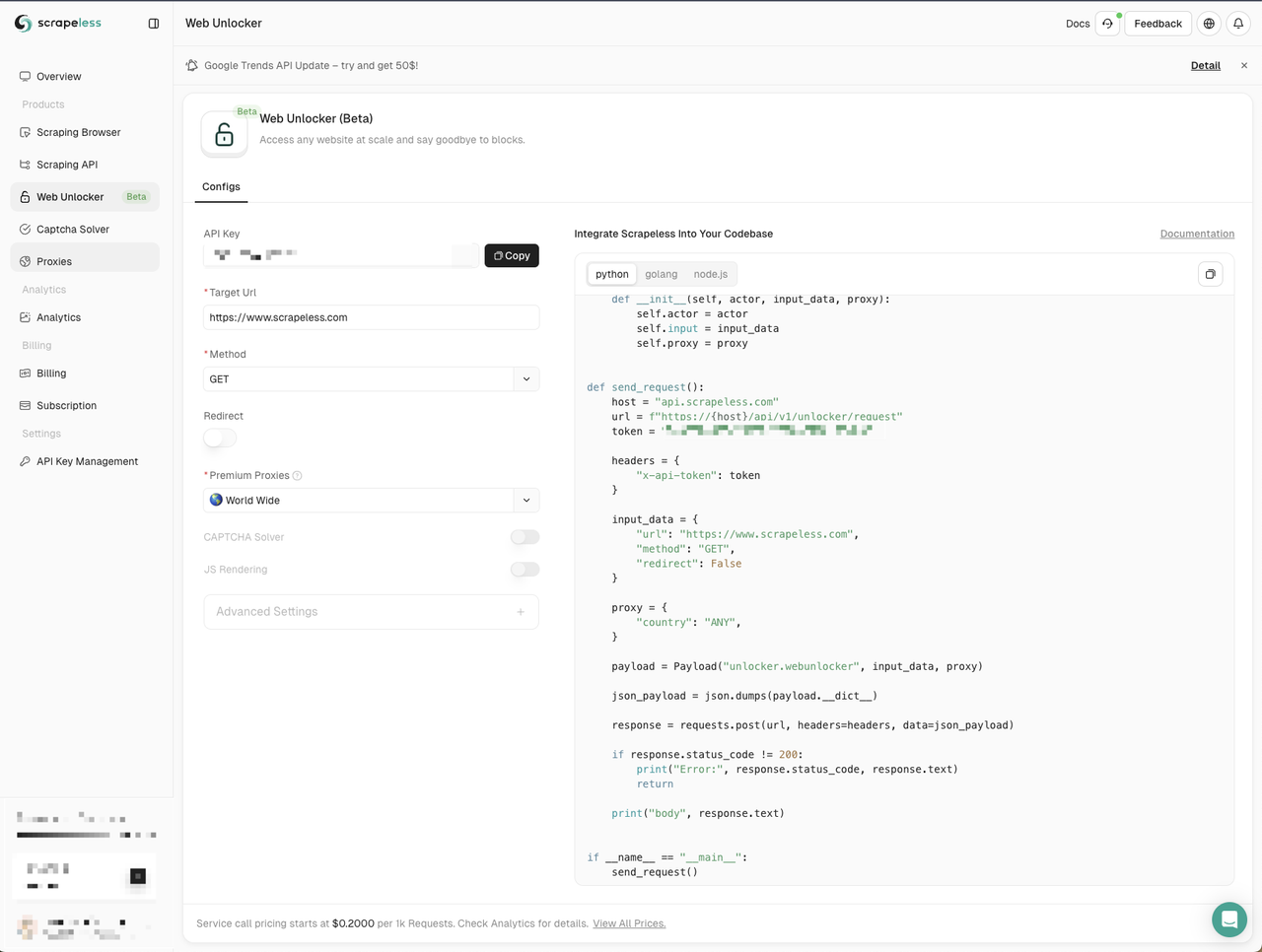
- Node.jsコード例をプロジェクトにコピーします
ここでは、新しいweb-unlocker.jsファイルを作成します。ネットワークリクエストを送信するためにnode-fetchモジュールを使用する必要があるため、Scrapelessによって提供されたコード例内のhttpモジュールをnode-fetchモジュールで置き換える必要があります。
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // Your API token
const inputData = {
url: 'https://identity.getpostman.com/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();次のコマンドを実行してスクリプトを実行します。
JavaScript
web-unlocker.js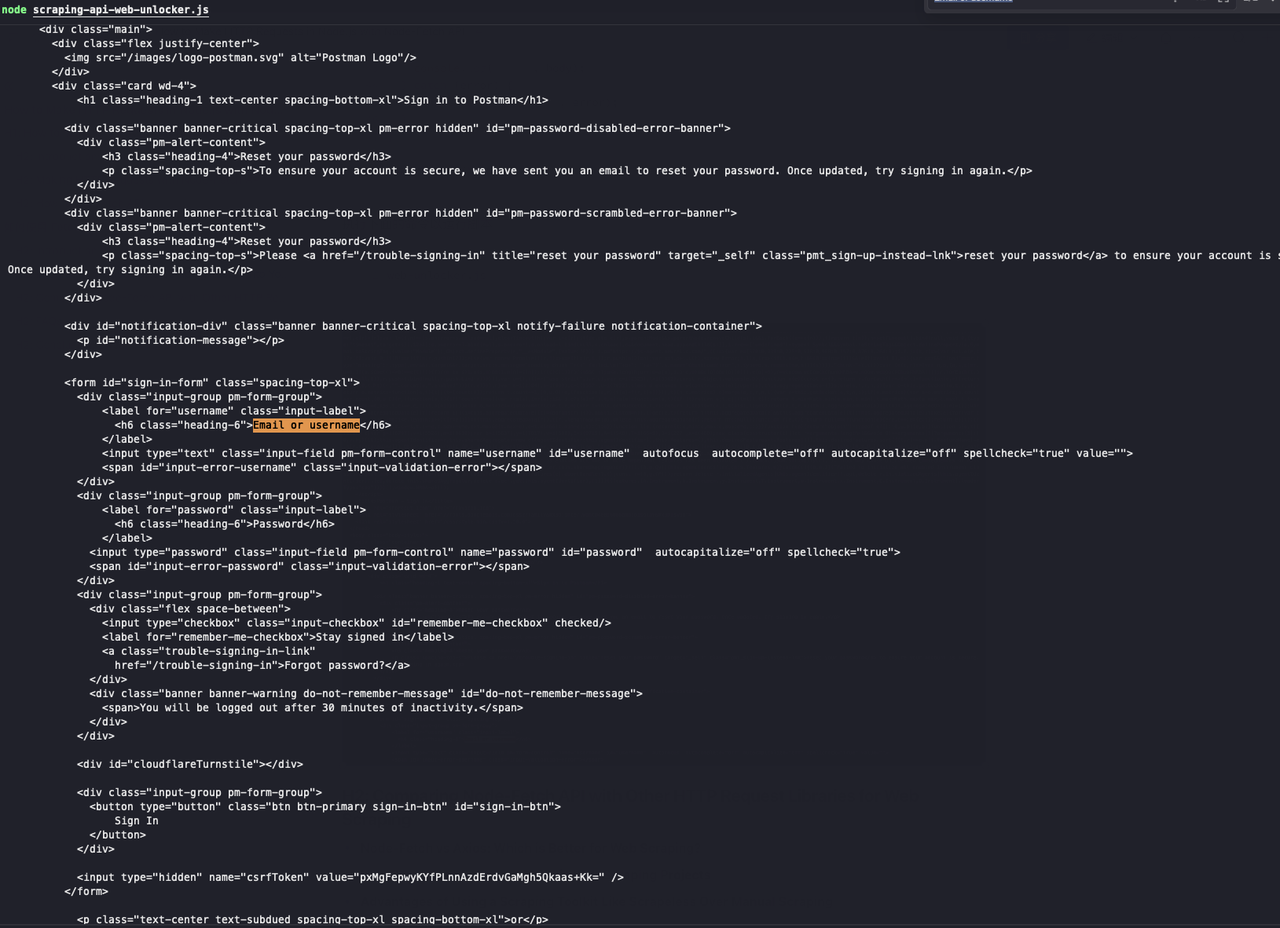
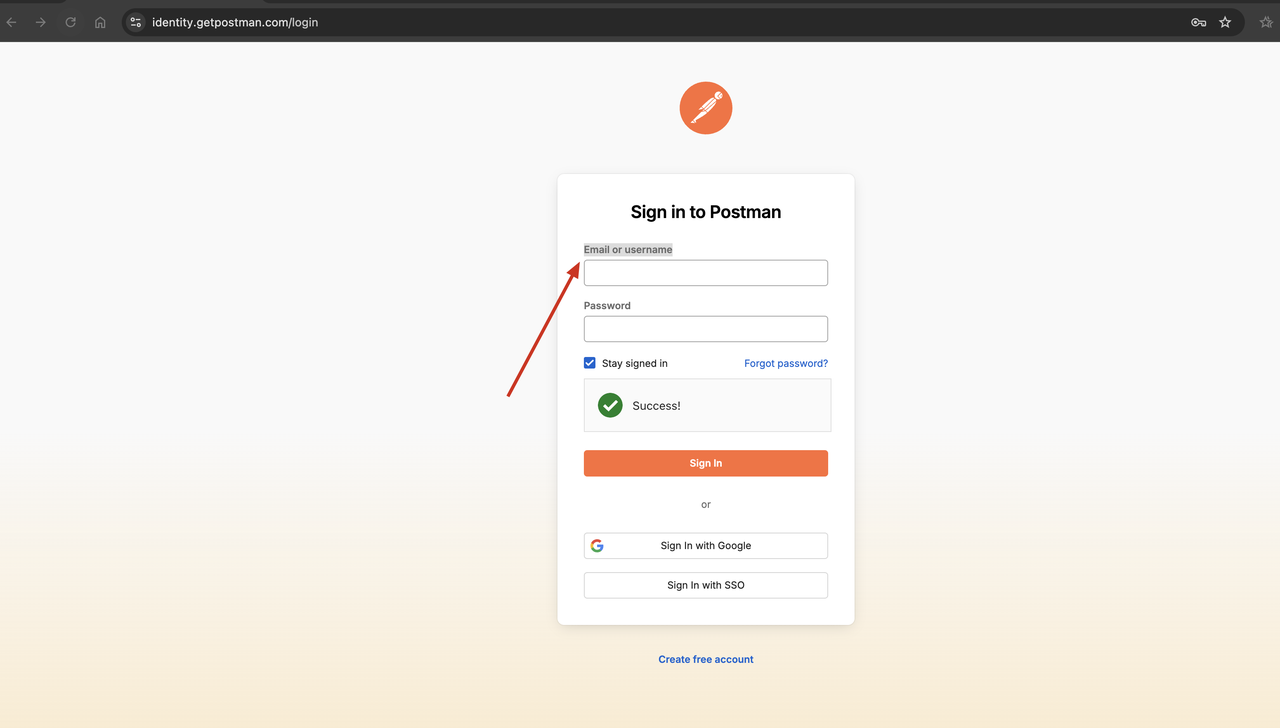
見てください!Scrapelessウェブアンロッカーは検証コードを正常に回避し、返された結果に必要なウェブページコンテンツが含まれていることがわかります。
FAQ
Q1. Node-FetchとAxios:ウェブスクレイピングにはどちらが良いですか?
選択を容易にするために、AxiosとFetch APIには次の違いがあります。
- Fetch APIはリクエストのbodyプロパティを使用するのに対し、Axiosはdataプロパティを使用します。
- AxiosではJSONデータを直接送信できますが、Fetch APIでは文字列に変換する必要があります。
- AxiosはJSONを直接処理できます。Fetch APIは、最初にresponse.json()メソッドを呼び出してJSON形式のレスポンスを取得する必要があります。
- Axiosの場合、レスポンスデータの変数名はdataでなければなりませんが、Fetch APIの場合、レスポンスデータの変数名は何でもかまいません。
- Axiosは、進行状況イベントを使用して進行状況の簡単な監視と更新を可能にします。Fetch APIには直接的な方法がありません。
- Fetch APIはインターセプターをサポートしませんが、Axiosはサポートします。
- Fetch APIはストリーミングレスポンスを許可しますが、Axiosは許可しません。
Q2. node-fetchは安定していますか?
Node.js v21で最も注目すべき機能は、Fetch APIの安定化です。
Q3. Fetch APIはAJAXよりも優れていますか?
新しいプロジェクトでは、その最新の機能とシンプルさのためにFetch APIを使用することをお勧めします。ただし、非常に古いブラウザをサポートする必要がある場合や、レガシーコードを保守している場合は、Ajaxが必要になる可能性があります。
まとめ
Node.jsへのFetch APIの追加は、長らく待望されていた機能です。Node.jsでFetch APIを使用すると、スクレイピング作業を容易に行うことができます。ただし、Node Fetch APIを使用すると、深刻なネットワーク封鎖に遭遇することは避けられません。
IPブロックとCAPTCHAを完全に解決したいですか? Scrapelessを使用して、ウェブサイトの監視とIPブロックを簡単に回避してください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


